一種分布式異構帶寬環境下的高效數據分區方法
2021-01-05 03:06:12馬卿云季航旭趙宇海毛克明王國仁
計算機研究與發展 2020年12期
馬卿云 季航旭 趙宇海 毛克明 王國仁
1(東北大學計算機科學與工程學院 沈陽 110169)
2(東北大學軟件學院 沈陽 110169)
3(北京理工大學計算機學院 北京 100081)
隨著物聯網、移動互聯網、產業互聯網和社交媒體等技術的飛速發展,每天都會產生大量的數據,人們已經身處大數據時代[1].根據國際數據公司(International Data Corporation, IDC)的預測,到2025年,全球的數據量將是現在的10倍,達到175 ZB.
大數據中有著豐富的信息,并且蘊含著巨大的價值[2].谷歌通過用戶搜索詞頻的變化成功對冬季流感進行了預測,沃爾瑪通過分析消費者購物行為對紙尿褲和啤酒進行共同銷售,這些耳熟能詳的案例都印證了這一點.但隨著數據產生速度的加快,數據量的急劇增長,如何對龐大的數據進行處理成為了新的難題.傳統的單機處理已經無法滿足大數據的需求,分布式的大數據處理框架應運而生.谷歌首先提出了用于大規模數據并行計算的編程模型MapReduce[3],引起了極大的反響,也因此促使了Hadoop[4]的誕生.之后為了改進傳統MapReduce中運行效率低下的問題,基于內存計算的Spark[5]被提出.時至今日,為了追求更快的處理速度、更低的時延,Flink[6]開始嶄露頭角,并得到了飛速的發展.
與此同時,隨著云計算[7]的興起,包括谷歌、微軟、阿里巴巴等在內的互聯網公司都提供了大數據存儲與分析的相關服務,眾多企業開始選擇將自己的業務上“云”.這些提供云服務的公司需要存儲和處理的數據同樣是海量的,為了更好地為客戶提供服務,提供云服務的公司通常都會在各地建立數據中心[8],例如微軟和谷歌在世界各地就分布著超過十個的數據中心.各數據中心之間經常需要聯合進行數據分析,此時分布式大數據處理框架依然是不二之選.跨數據中心的大數據分析業務許多都是數據密集型作業,作業運行過程中,通常需要使用數據分區方法將相同鍵的數據發送到同一數據中心進行處理,而各個數據中心之間通常相隔較遠,這樣會產生大量的網絡傳輸開銷,導致數據在網絡中的傳輸時間成為大數據分析作業的瓶頸.由于網絡提供商硬件設備的不同,各數據中心之間的帶寬通常差異較大,這樣便會形成異構帶寬的分布式環境[9].當然,即使在同構的集群中,也可能因為某些節點上的作業搶占了帶寬而導致集群環境中各節點帶寬異構.綜上所述,在異構帶寬環境下,如何高效地進行數據分區是一個急需解決的問題.
數據分區是大數據框架的一個基本功能,通過數據分區可以將各分區數據交給不同的節點進行處理.常用的數據分區方式有隨機分區、Hash分區和Range分區[10].其中Hash分區和Range分區都能保證具有相同鍵的數據分發到同一節點,這也為許多需要這種保證的算子提供了保障.現有的研究很少在數據分區時對節點的帶寬進行考慮,在節點間異構帶寬的情況下,傳統的數據分區方法效率低下,完成數據分區的時間開銷較大.針對該問題,本文提出了一種基于帶寬的數據分區方法,在帶寬異構的集群環境下可以有效減少數據分區完成的時間.
本文的主要貢獻有3個方面:
1) 提出了一種基于帶寬的數據分區方法,該方法在異構帶寬的集群下能有效減少數據分區所需的時間;
2) 在新一代大數據計算框架Flink中,對基于帶寬的數據分區方法進行了實現;
3) 通過實驗對基于帶寬的數據分區方法進行了驗證,實驗結果顯示該方法可以有效地減少完成數據分區所需的時間.
1 相關工作
針對異構集群環境下的大數據框架優化的研究已有不少,主要的研究方向是針對節點間計算能力的不同,為各節點分配不同的數據量或者不同的計算任務.如在異構Hadoop集群中,文獻[11]針對集群中節點計算性能不同的特點,以數據本地性策略為基礎,通過在計算能力更強的節點放置更多的數據塊,使得計算能力強的節點處理更多的數據,從而提升系統的性能;文獻[12-13]則針對異構的Hadoop集群,考慮提交至集群的作業運行時需要的資源大小和集群中可用資源的數量,提出了一種新的調度系統COSHH,該調度系統可以結合Hadoop中原始的調度策略進行使用,進一步減少異構Hadoop集群中作業的平均完成時間,使得MapReduce模型在異構集群中的運行效率更高.
在異構Spark集群中同樣有著相應的研究,如文獻[14]提出了一種在異構Spark集群下的自適應任務調度策略,其主要考慮的是集群中各節點的計算能力不同,通過對各節點的負載和資源利用率進行監測來動態地調整節點任務的分配;文獻[15]則采用了一種主動式的數據放置策略,通過對任務所需的計算時間進行預測,在初始數據加載過程中將數據放置在適當的節點上,并在作業執行的過程中進一步對數據的放置進行調整,縮短作業的整體運行時間.
對于數據在節點之間的傳輸,主要的研究方向是針對同構集群中的數據傾斜問題,比如文獻[16]提出了一種用于MapReduce的采樣算法,在Hadoop集群中不需要對輸入數據運行額外的預采樣程序,就能比較精確地估計出中間結果的分布,從而均衡各節點的數據量;同樣是針對MapReduce框架中出現的數據傾斜問題,文獻[17]基于對Map端中間結果的采樣,提出了一種基于動態劃分的負載均衡方法,可以保證每個Reduce任務處理的數據量盡量均衡;文獻[18]則針對Spark提出了一種基于鍵重分配和分區切分的算法,該算法作用于中間結果的產生和shuffle過程中,同樣用于解決數據傾斜問題;針對數據傳輸過程的優化通常都需要使用采樣算法來獲取數據的信息,文獻[19]針對大規模數據流,提出了一種改進的水塘抽樣方法,Flink中使用該抽樣方法實現了Range分區.
以上研究都沒有考慮在異構帶寬情況下,如何對數據分區方法進行優化.對于數據密集型作業,網絡傳輸往往是瓶頸所在,在異構帶寬條件下,傳統考慮負載均衡的數據分區方法運行效率反而低下.針對該問題,本文通過建立基于傳輸時間的數據分發模型,提供了一種基于帶寬的數據分區方法,在異構帶寬的集群環境下可以有效地減少數據的傳輸時間.
2 相關概念介紹
2.1 Flink框架
Flink與大多數大數據框架一樣也可以分為Master和Slave節點,如圖1所示,其中充當Master的稱為JobManager,充當Slave的稱為TaskManager,除此之外,提交作業的節點通常稱為Client.
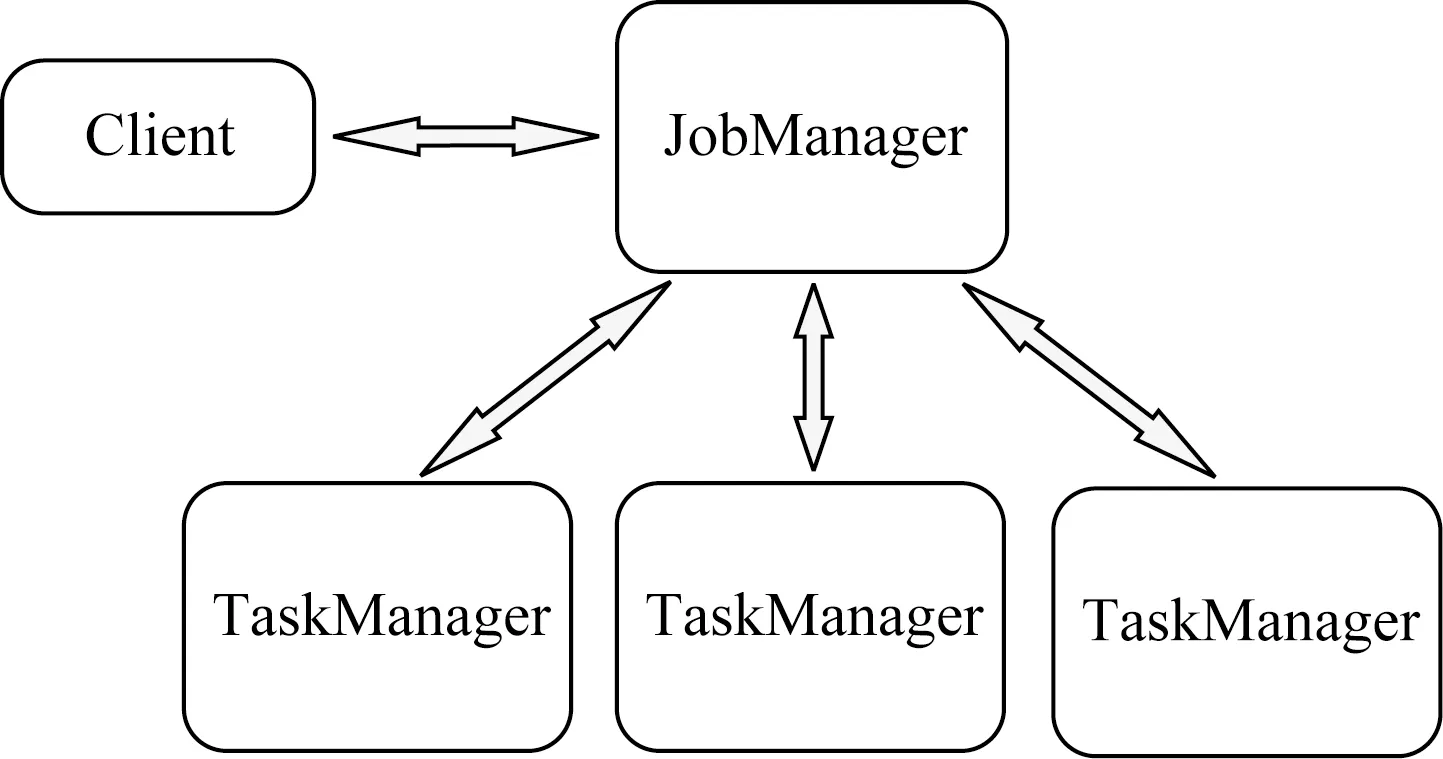
Fig. 1 The architecture of Flink圖1 Flink架構圖
Flink中JobManager將接收Client提交的作業,對作業進行調度并選定TaskManager進行任務的執行,收集作業運行的狀態,并在作業運行失敗時進行容錯和恢復,TaskManager上則真正運行著作業的各個子任務[20].通常Flink集群中會有一個JobManager和多個TaskManager.
Flink中作業會被抽象為數據流圖,通常都是一個DAG結構[21].具體來講,作業在Client端提交后,如果是批處理作業會通過優化器生成Optimized-Plan,如果是流處理作業則會生成StreamGraph,之后會繼續在Client統一轉化為JobGraph,提交給JobManager.在JobManager處接收到JobGraph之后,會將其轉化為ExecutionGraph,最后調度執行.
2.2 Flink中的分區方法
大數據計算框架通常都會為用戶提供數據分區的功能[22],Flink在其批處理API中也提供了3種常用的數據分區方法,包括Rebalance分區、Hash分區和Range分區.
2.2.1 Rebalance分區
Rebalance分區是Flink中最簡單的數據分區方法,通過該分區方法可以很好地均衡每個節點上的數據,但其無法保證具有相同鍵的數據分發到同一節點上.Flink中使用Round-Robin算法實現了Rebalance分區,具體算法如算法1所示:
算法1.Rebalance分區算法.
輸入:待分區的記錄record、分區數量numPartitions、當前分區編號partitionToSendTo;
輸出:待分區記錄的分區編號partitionToSendTo.
①partitionToSendTo++;
② IFpartitionToSendTo≥numPartitions
③partitionToSendTo=0;
④ END IF
⑤ RETURNpartitionToSendTo.
2.2.2 Hash分區
Hash分區是使用最普遍的數據分區方法,該分區方法是基于Hash算法實現的[23].使用該分區方法首先會根據待分區記錄的key值得到相應的Hash值,之后利用Hash值對分區數量取余,得到的結果作為該條記錄所屬的分區編號.因為相同的key值一定有相同的Hash值,因此Hash分區可以保證鍵相同的記錄分發到同一節點上.具體算法如算法2所示:
算法2.Hash分區算法.
輸入:待分區的記錄record、分區數量numPartitions;
輸出:待分區記錄的分區編號partitionToSendTo.
①key=extractKey(record); /*提取記錄的key*/
② IFkey==null
③partitionToSendTo=0;
④ ELSE
⑤hash=key.hashCode;
⑥partitionToSendTo=Hash%numPartitions;
⑦ END IF
⑧ RETURNpartitionToSendTo.
2.2.3 Range分區
Range分區是一種根據所有待分區記錄的鍵的范圍進行數據分區的方法[24],也就是說每個分區結果都包含互不相交的鍵在一定范圍內的記錄,也因此使用Range分區方法時需要確定每個分區的邊界.為了確定每個分區的邊界,通常使用的方式是對輸入數據進行抽樣.Flink中使用的抽樣算法是改進后的蓄水池抽樣算法,各分區邊界的確定則是對抽樣數據進行排序后按等比例獲取各個分區的邊界.
舉例來說,假設抽樣得到的數據按鍵排序后的結果為{(10,value1),(20,value2),(30,value3),(40,value4),(50,value5),(60,value6),(70,value7),(80,value8),(90,value9)},分區數量為3,則計算得到的邊界為{30,60},也就是說key≤30的記錄將會被發往第1個分區,key∈(30,60]之間的數據會發往第2個分區,key>60的數據則會發往第3個分區.Range分區方法通過抽樣并等比例劃分各個分區的邊界,可以在保證鍵相同的記錄發往同一節點的同時,使得各分區擁有的數據大致相等.具體算法如算法3所示:
算法3.Range分區算法.
輸入:輸入源的分區數量numInputPartitions、待分區的記錄record、分區數量numPartitions;
輸出:待分區記錄的分區編號partitionToSendTo.
① 使用改進后的蓄水池抽樣算法在每個輸入源分區上進行抽樣;
② 將各輸入源分區上的抽樣結果進行匯總,得到sampleData[],并排序;
③ 根據分區數量numPartitions和sampleData[],計算出分區邊界rangeBoundary[];
④ 對于每條待分區的記錄record,在分區邊界rangeBoundary[]中查找出所屬的分區編號partitionToSendTo;
⑤ RETURNpartitionToSendTo.
3 基于帶寬的數據分區方法
本節我們先對最優數據分發比例的計算建立模型.之后舉例說明異構帶寬的集群中不同的數據分發比例對數據分區完成時間的影響,體現基于帶寬的數據分區方法的重要性.最后介紹針對異構帶寬的數據分區方法的算法流程以及在Flink中的實現.
3.1 最優數據分發比例建模
本節對異構帶寬環境下各節點最優數據分發比例的計算建立模型,首先對所要用到的變量進行定義.
Di:節點i上的初始數據量大小;
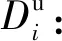
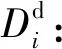
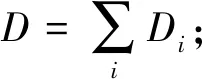
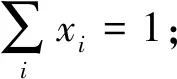
ui:節點i的上行帶寬;
di:節點i的下行帶寬;
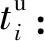
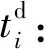
cost:數據分發所要花費的總時間.
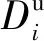
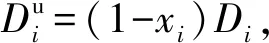
(1)

(2)
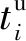
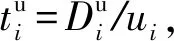
(3)
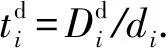
(4)
數據分發所要花費的總時間cost則是各節點傳輸數據所需時間的最大值.我們的目標是最小化數據分發所需的時間,則形式化地針對數據傳輸時間的優化模型表示為
mincost
s.t. ?i:xi≥0,
該模型是一個典型的線性規劃問題,使用計算機可以比較方便地求解.
3.2 示 例
考慮集群中參與數據分區的2個節點Slave1和Slave2,它們初始的節點信息如表1所示:

Table 1 Information of Nodes表1 節點信息表
其中Slave1節點上的初始數據量D1=320 MB,上行帶寬u1=2 Mbps,下行帶寬d1=10 Mbps.Slave2節點上的初始數據量D2=160 MB,上行帶寬u2=10 Mbps,下行帶寬d2=10 Mbps.
當Slave1和Slave2以50%和50%的比例進行數據分發時,可以分別計算出Slave1和Slave2傳輸的數據量大小和所需時間,具體如表2所示:

Table 2 Transmission Information on Proportional 50%∶50%表2 50%∶50%比例分配數據傳輸信息表
其中Slave1需要傳出50%的數據,即160 MB,接收來自Slave2的80 MB數據.Slave2則需傳出80 MB數據,接收來自Slave1的160 MB數據.根據Slave1和Slave2的上下行帶寬可以計算得出相應的傳輸時間,而最終數據分區完成需要取決于傳輸最慢的節點,也就是說以50%和50%的比例進行數據分區,最終需要花費640 s來完成.
考慮以90%和10%的比例進行數據分發,也就是說數據分發結束后Slave1保留90%的數據,Slave2保留10%的數據.同樣可以計算出各節點所需傳輸數據量大小和相應的時間,如表3所示:

Table 3 Transmission Information on Proportional 90%∶10%表3 90%∶10%比例分配數據傳輸信息表
其中Slave1需要傳出10%的數據,即32 MB,接收來自Slave2的144 MB的數據.Slave2則需傳出144 MB數據,接收來自Slave1的32 MB數據.同理計算出傳輸時間后,可以得到最終傳輸結束所需時間為128 s,與分配比例為50%時相比速度提高了4倍.
3.3 算法設計
以建立的最優數據分發比例模型為基礎,可以設計出基于帶寬的數據分區算法,如算法4所示:
算法4.基于帶寬的數據分區算法.
輸入:輸入源的分區數量numInputPartitions、待分區的記錄record、分區數量numPartitions、參與分區的節點信息instanceInfo;
輸出:待分區記錄的分區編號partitionToSendTo.
① 使用改進后的蓄水池抽樣算法在每個輸入源分區上進行抽樣;
② 將各輸入源分區上的抽樣結果進行匯總,得到sampleData[],并排序;
③ 根據參與分區的節點信息instanceInfo計算出最優數據分發比例ratio[];
④ 根據最優數據分發比例ratio[]和得到的抽樣結果sampleData[],計算出分區邊界rangeBoundary[];
⑤ 對于每條待分區的記錄record,在分區邊界rangeBoundary[]中查找出所屬的分區編號partitionToSendTo;
⑥ RETURNpartitionToSendTo.
3.4 算法實現
鑒于新一代大數據計算框架Flink的出色性能,選用Flink對基于帶寬的數據分區算法進行了實現.
實現基于帶寬的數據分區方法,需要完成最優數據分發比例的計算和作業圖邏輯的修改.3.4節已經提到過,計算節點的最優數據分發比例需要節點的帶寬信息和數據量.原始的Flink無法獲取集群中各節點的帶寬信息,考慮實現簡便性,我們在Flink的配置文件中添加了各節點上下行帶寬的配置項,在Flink集群啟動時,各TaskManager會將自身的帶寬信息匯總到JobManager處.各節點的數據量則根據作業JobGraph中的Source算子,獲取相應的數據源分布情況后推算得出.作業圖邏輯的修改包括采樣算法的加入和分區方法的重寫,這部分將在生成OptimizedPlan時完成,這樣可以減少JobManager處的負載.
圖2對一個基于帶寬的數據分區作業的整體流程進行了詳細描述.如圖2中Step1~3所示,作業在Client端提交后,首先會通過優化器優化生成OptimizedPlan,之后將以生成的OptimizedPlan為基礎,生成作業圖JobGraph.在作業圖生成的過程中我們添加了采樣的邏輯和用于計算分區邊界的算子,并重寫了數據分區的方法.其中計算分區邊界的算子會根據最優數據分發比例得到數據分區的界,該結果將會通過廣播的方式發送到每個分區算子.需要注意的是,此時還在Client端,計算分區邊界的算子還沒有實際獲取到最優數據分發比例,最優數據分發比例的獲取需要在JobManager處完成.完成作業邏輯的修改后, 通過Step3生成的JobGraph將被提交到JobManager.
如圖2中Step4~7所示,JobManager收到作業的JobGraph后,首先會遍歷JobGraph中的算子并找到Source算子,通過Source算子中存儲的數據源信息去獲取待處理數據在集群中的分布情況,并結合作業的并行度選擇運行該作業的節點.考慮網絡傳輸是作業運行的瓶頸,節點的選擇策略是盡可能選擇擁有數據的節點來運行作業,這樣根據數據本地性策略,可以減少Source算子讀取數據源時的網絡傳輸.確定作業運行的節點后,通過節點的帶寬信息和初始數據量大小,使用數據分發比例計算模塊就可以計算出各節點的最優數據比例,該比例將會被寫回JobGraph中用于計算分界的算子.至此,包含最終作業執行邏輯的作業圖JobGraph才真正構建完成.最后根據JobGraph中各算子的并行度,會生成對應的執行圖ExecutionGraph,執行圖中的每個任務通過Step7將部署至對應的節點,進行調度執行.
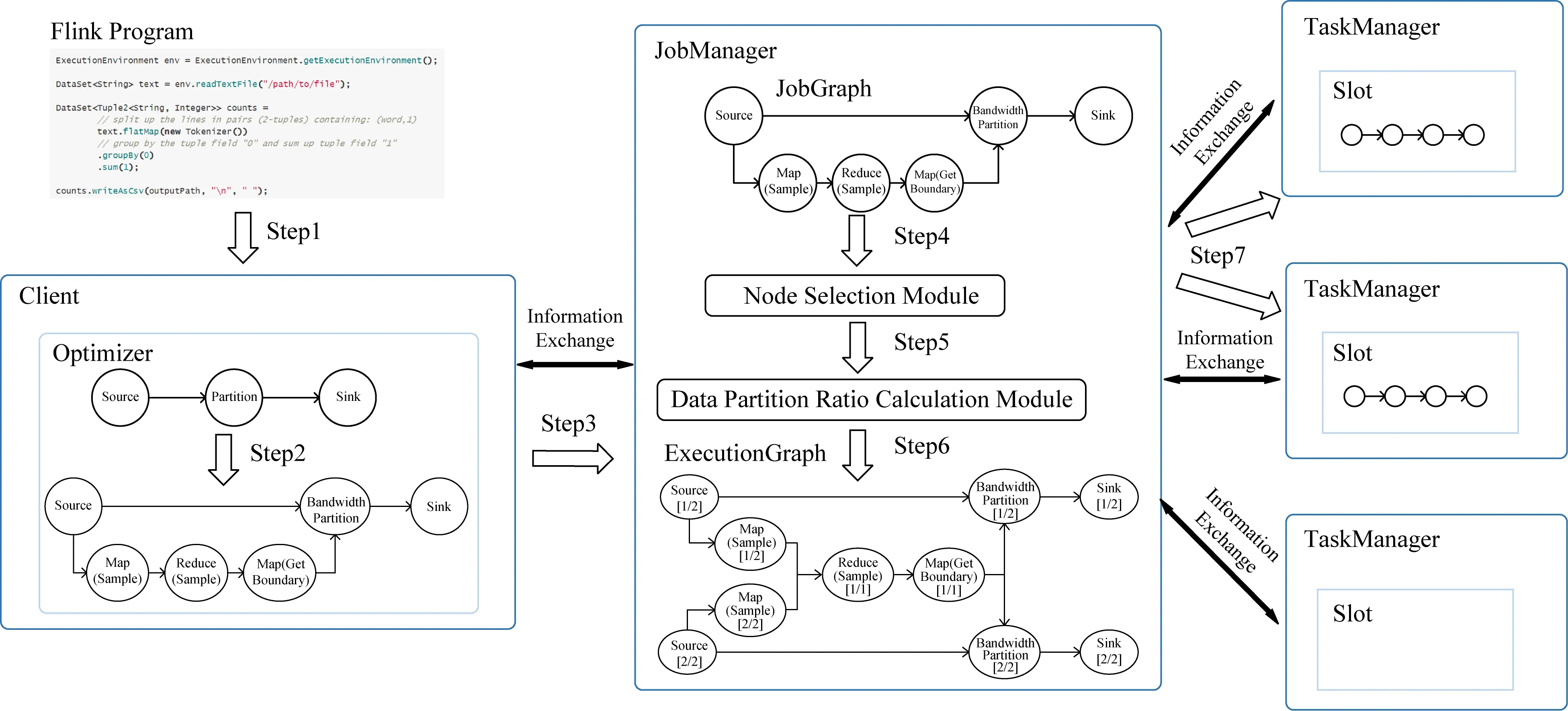
Fig. 2 The process of bandwidth partitioning job圖2 基于帶寬的數據分區方法作業運行過程
4 實驗與分析
4.1 實驗環境
實驗所用環境為4個節點的分布式集群,每個節點的處理器為Intel Xeon E5-2603 V4(6核6線程),內存為64 GB,節點間通過千兆以太網連接,安裝的操作系統為CentOS7.集群上通過Standalone模式搭建了修改后的Flink集群,其中1臺master節點作為JobManager,另外3臺Slave節點作為TaskManager,使用的版本為Flink1.7.2.除此之外集群中還基于Hadoop2.7.5搭建了Hadoop集群,使用其中的HDFS作為分布式文件存儲系統.集群中各節點帶寬的控制則通過工具Wondershaper[25]來實現.
4.2 數據集
實驗使用的數據是通過TPC-H[26]基準測試工具生成的數據集,該工具可以生成8種表,選取了其中較大的Lineitem表和Orders表作為數據源.其中Lineitem有16個字段,前3個字段Orderkey,Partkey,Suppkey,其中Suppkey是主鍵.Orders表有9個字段,前2個字段Orderkey和Custkey,其中Custkey是主鍵.
4.3 實驗結果與分析
本節從算法開銷和算法效果2方面進行實驗結果的說明與分析.
4.3.1 算法開銷
基于帶寬的數據分區方法的算法開銷主要包括作業圖邏輯修改、最優數據分發比例的計算、數據采樣3部分,本文針對這3部分所需的開銷分別進行了實驗.
作業圖邏輯的修改發生在Flink作業圖生成的過程中,主要包括采樣算子的添加、計算分界算子的添加以及分區方法的重寫等步驟.通過與未修改作業圖邏輯進行對比,可以得到作業圖邏輯修改所需的時間.經過5次實驗并取平均值,得到從作業提交到作業圖生成完畢所需的平均時間為185 ms,如果進行作業圖邏輯的修改,所需的平均時間則為232 ms,即作業圖邏輯修改平均所需時間為47 ms.
最優數據分發比例的計算是利用數學規劃優化器Gurobi Optimizer[27]實現的數據分發比例計算模塊完成的,實驗對不同節點數量下最優比例計算所需的時間進行了測試,每個節點的帶寬和數據量大小則隨機生成.實驗結果如圖3所示,當節點數量為5時所需的計算時間為32 ms,節點數量擴大至1 000時計算時間仍在100 ms以內,當節點數量達到6 000時所需的計算時間也僅為293 ms.

Fig. 3 The time of optimal ratio calculation圖3 最優比例計算時間
為了測試數據采樣所需的開銷,我們分別運行了添加了采樣過程的作業和未添加采樣過程的作業,使用作業運行的時間差作為采樣所需的開銷.實驗中使用了不同數據量大小的Lineitem表作為輸入,具體實驗結果如圖4所示,在數據量大小分別為3.6 GB,7.2 GB,14.6 GB,29.4 GB時,所需的采樣時間分別為21 s,44 s,86 s,167 s,平均每GB數據所需的采樣時間約為5.8 s.
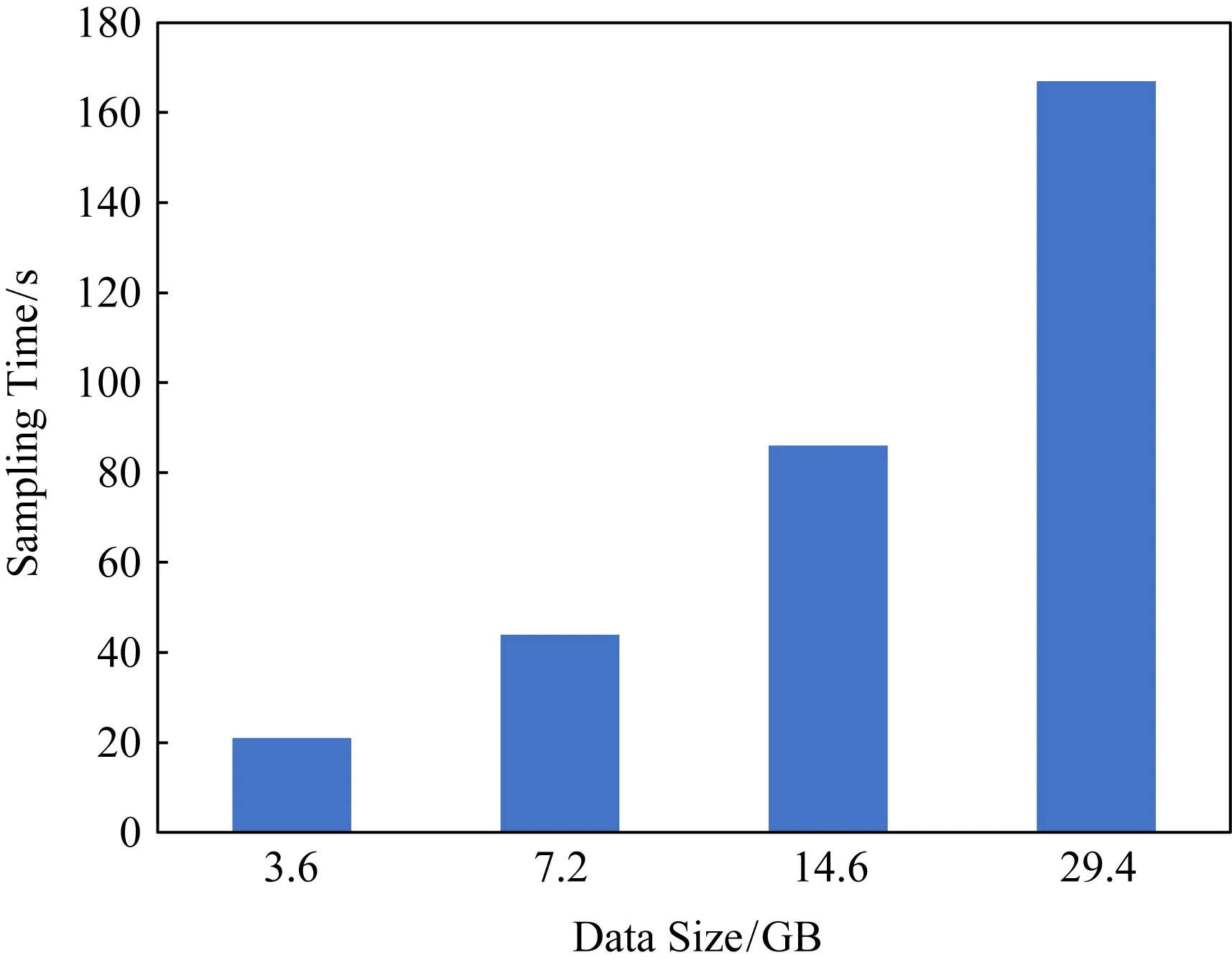
Fig. 4 The time of sampling圖4 采樣時間
總體來說,基于帶寬的數據分區方法在作業圖邏輯修改和最優數據分發比例的計算過程中所需的時間開銷都較小,為毫秒級別.數據采樣則相對時間開銷較大,且與數據量大小相關,但在計算資源更為充足的情況下,采樣所需時間可以進一步減少.
4.3.2 算法效果
為了探究本文提出的算法在不同的異構帶寬條件下的效果,我們設置了帶寬異構程度不同的4個實驗.同時為了實驗的方便,主要針對Slave1節點設置了不同的下行帶寬,這樣已經可以涵蓋不同的數據分發比例,其他情形的異構帶寬集群則與此類似.實驗中各節點的具體帶寬如表4所示,表4中上行帶寬在前、下行帶寬在后.
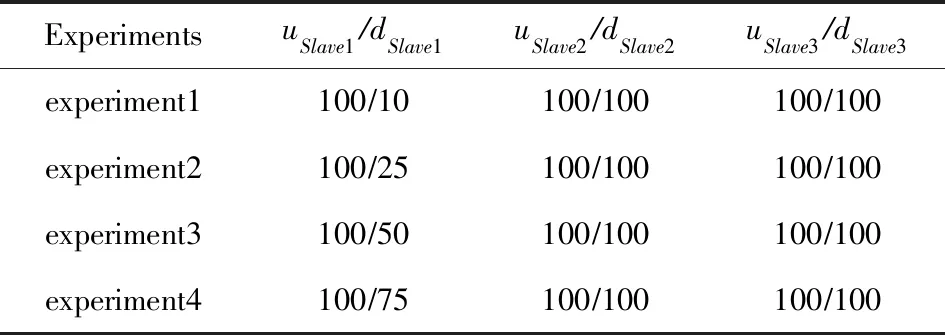
Table 4 Bandwidth Information表4 帶寬信息表 Mbps
實驗中使用的數據為3.6 GB的Lineitem表和1.63 GB的Orders表.實驗程序會先對數據集進行分區操作,數據分區結束之后將在每個分區中進行一次聚合,統計各分區最終的記錄數量,以便計算出最終各分區數據的比例.程序的執行模式設置為Batch模式,分區方法使用Hash分區、Range分區與基于帶寬的Bandwidth分區進行比較,驗證基于帶寬的Bandwidth分區效果.
因為實驗主要針對的是節點帶寬的影響,而實驗所使用的集群TaskManager的數量是3,因此作業運行的并行度同樣設置為3.使用的數據源則被上傳到HDFS中,3個節點上的數據量幾乎是相等的,因此可以認為Source算子的每個并行度讀入的數據量都是相同的.對數據集進行介紹時有過說明,Lineitem表中有3個字段是主鍵,Orders表中有2個字段是主鍵,在實驗過程中我們發現這2個表中并沒有明顯的數據傾斜,通過主鍵中的任一字段做數據分區,實驗結果都是相似的.后續的實驗結果都是以各個表的第1個字段作為鍵來進行數據分區,也就是說數據源Lineitem和Orders都使用Orderkey作為鍵進行數據分區.
如圖5所示,在實驗1條件下,使用Bandwidth分區的作業時間在Lineitem上所需時間為198 s,在Orders上所需時間為92 s,明顯小于Hash分區和Range分區所需時間,作業運行完成整體速度提升了為2.5~3倍.
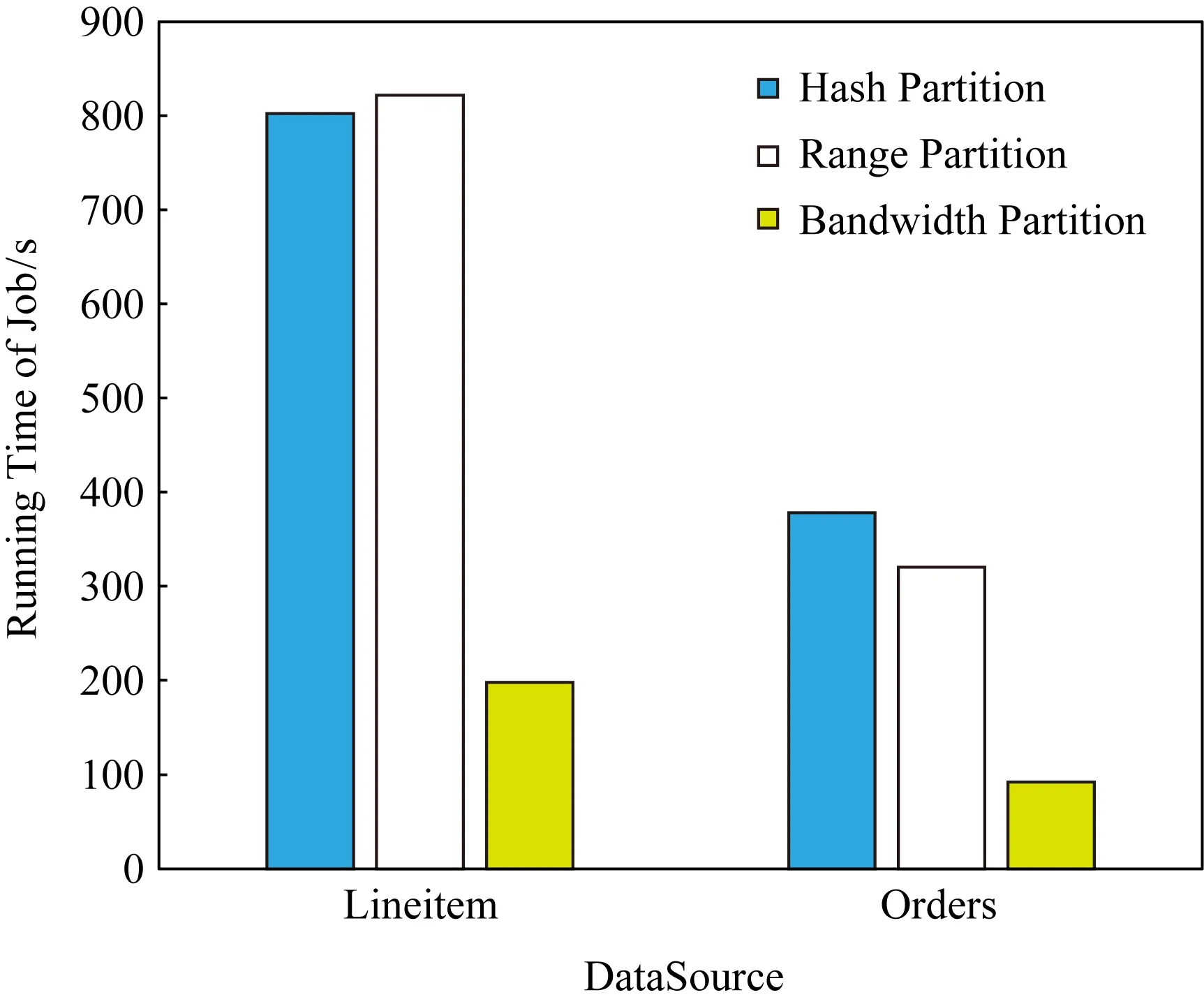
Fig. 5 Running time in different partition modes in experiment 1圖5 實驗1中不同分區模式下的執行時間
在實驗1的條件下,可以計算出3個節點數據的最優分配比例為4∶48∶48,通過表5和表6可以看出,使用Bandwidth分區很好地契合了最優數據分配比例,特別是在Lineitem上實際數據分區比例與最優比例幾乎完全相同.
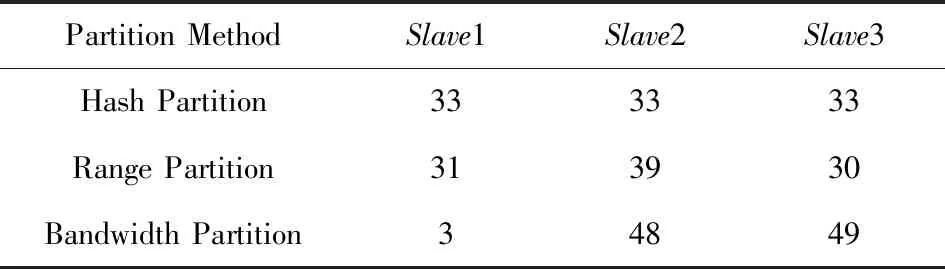
Table 5 Proportion of Lineitem After Partition in Experiment 1表5 實驗1中Lineitem分區后各節點數據比例 %
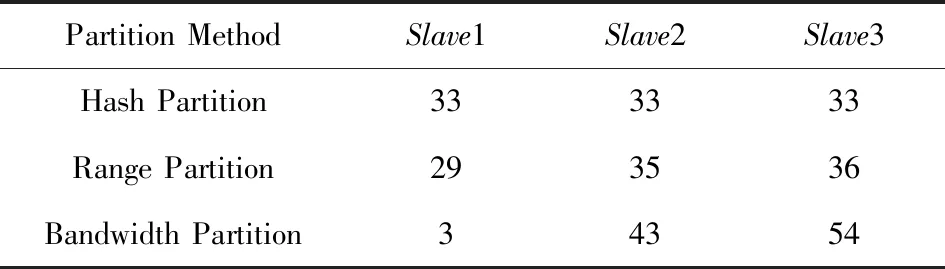
Table 6 Proportion of Orders After Partition in Experiment 1表6 實驗1中Orders分區后各節點數據比例 %
如圖6所示,在實驗2條件下,使用Bandwidth分區的作業時間在Lineitem上所需時間為209 s,在Orders上所需時間為99 s,相較于Hash分區和Range分區,效果同樣不錯,提升為0.6~0.7倍.
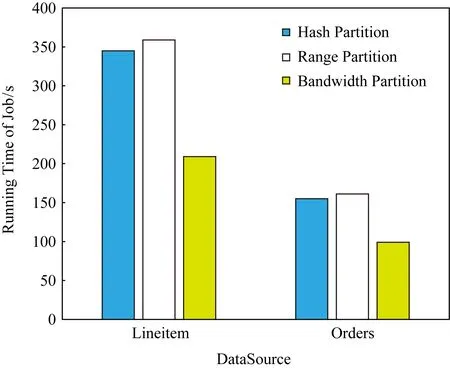
Fig. 6 Running time in different partition modes in experiment 2圖6 實驗2中不同分區模式下的執行時間
在實驗2的條件下,計算出的各節點數據的最優分配比例為11∶44∶44,通過表7和表8可以看出,使用Bandwidth分區后的數據分布也與最優數據分配比例比較契合.
如圖7所示,在實驗3條件下,使用Bandwidth分區的作業時間在Lineitem上所需時間為184 s,在Orders上Bandwidth分區所需時間為68 s,相較Hash分區所需時間194 s和88 s已經沒有太大的優勢,但仍然能節省一些時間.
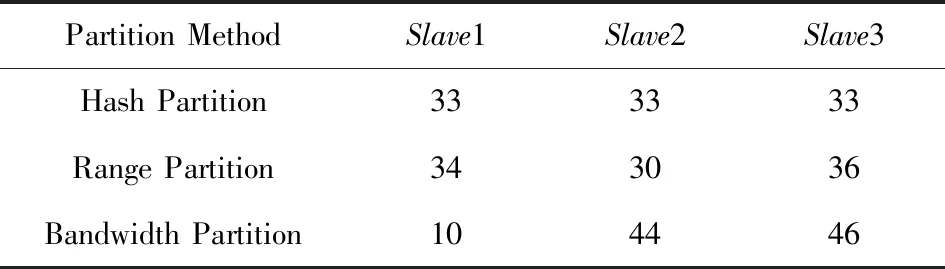
Table 7 Proportion of Lineitem After Partition in Experiment 2表7 實驗2中Lineitem分區后各節點數據比例 %
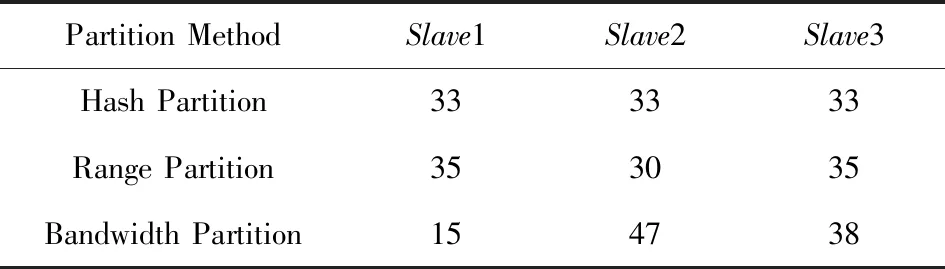
Table 8 Proportion of Orders After Partition in Experiment 2表8 實驗2中Orders分區后各節點數據比例 %
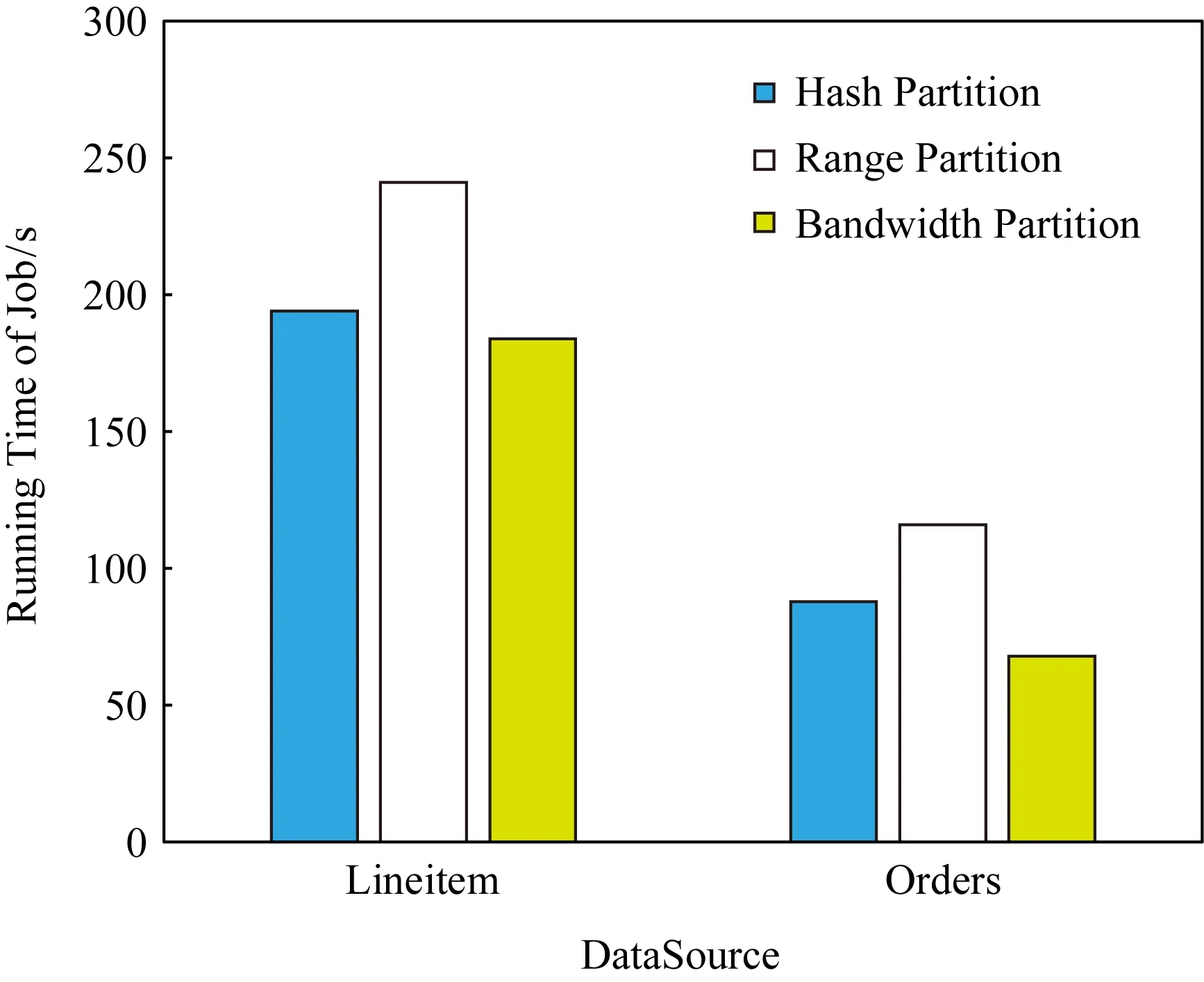
Fig. 7 Running time in different partition modes in experiment 3圖7 實驗3中不同分區模式下的執行時間
此時節點之間數據傳輸的最優比例已經是20∶40∶40,與平均分配差距已經沒有那么大,同時還可以發現,此次實驗條件下Range分區表現較差,分區完成所用時間與其他實驗相比明顯變長.分析表9和表10可以發現,Range分區在實驗4中,對需要數據比例少的Slave1節點反而分配了更多的數據,導致Range分區所需時間遠超了其他2種分區方法.
如圖8所示,在實驗4條件下,與Hash分區相比,Bandwidth分區所需時間反而變得更長.此時節點間的最優比例是27∶36∶36,與平均分配比例已經十分接近,而Range分區和Bandwidth分區需要額外的采樣時間.除此之外,結合表11和表12可以發現,采樣得到的結果并不是特別準確,導致并不能完全按計算得到的最優比例進行數據分發.
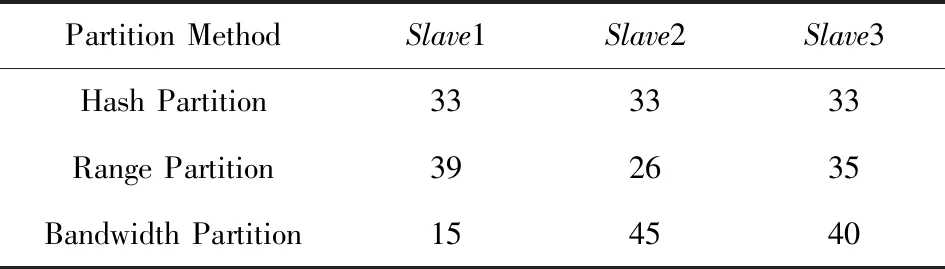
Table 9 Proportion of Lineitem After Partition in Experiment 3表9 實驗3中Lineitem分區后各節點數據比例 %
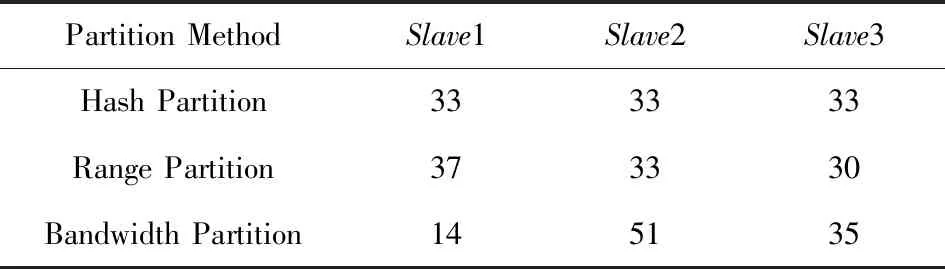
Table 10 Proportion of Orders After Partition in Experiment 3表10 實驗3中Orders分區后各節點數據比例 %
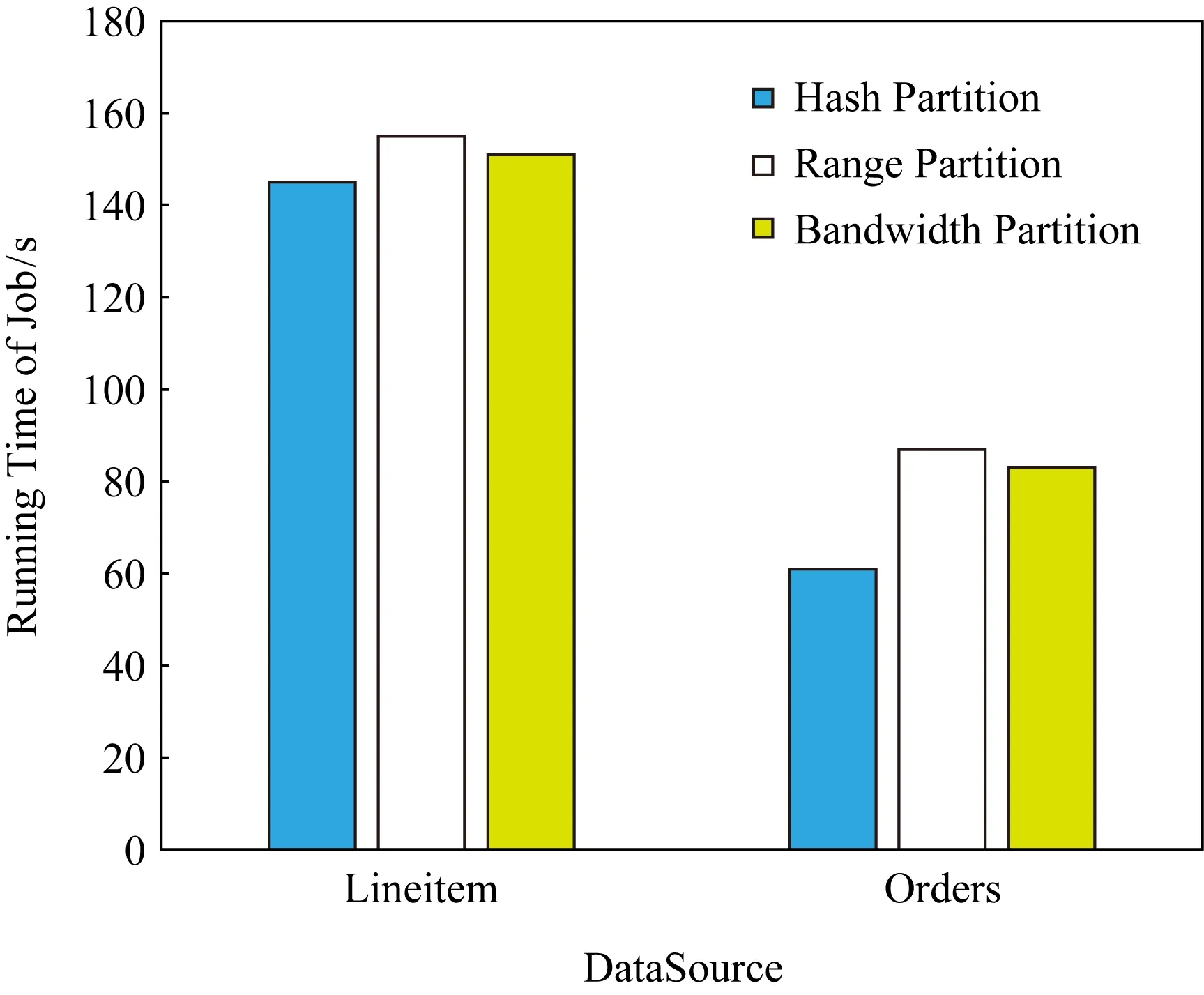
Fig. 8 Running time in different partition modes in experiment 4圖8 實驗4中不同分區模式下的執行時間
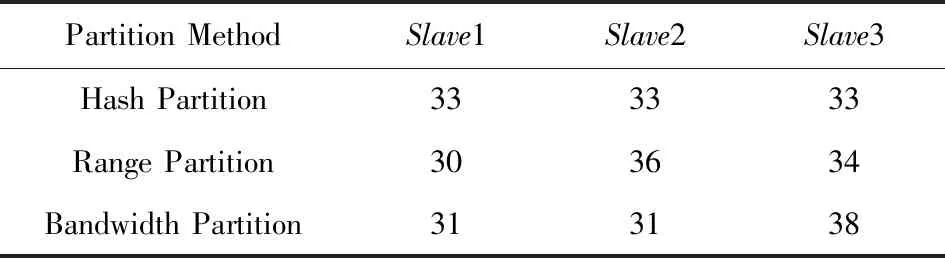
Table 11 Proportion of Lineitem After Partition in Experiment 4表11 實驗4中Lineitem分區后各節點數據比例 %
結合4個實驗,可以發現Hash分區十分穩定,每次實驗分區結果都十分均衡,說明數據源中并沒有明顯的數據傾斜.Range分區和Bandwidth分區則并不能每次都保證數據按預設的比例分配,主要是因為它們都需要使用采樣算法來估計數據分布,有時候采樣的結果并不是十分精確.同樣由于采樣算法的存在,Range分區和Bandwidth分區都需要額外的開銷,這也導致大多數時候Range分區都比Hash分區花費更多的時間.唯一例外的是在實驗1中對Orders表進行分區,原因是Range分區恰好給瓶頸節點Slave1分配了更小的比例,而Slave1下行帶寬很小,較小的數據量就會對傳輸時間產生較大的影響.

Table 12 Proportion of Orders After Partition in Experiment 4表12 實驗4中Orders分區后各節點數據比例 %
綜合來看,當帶寬異構性強,各節點之間最優數據分發比例比較不均衡時,基于帶寬的數據分區方法可以取得較好的效果,甚至帶來數倍的速度提升.當帶寬異構性較弱時,由于采樣算法需要額外的開銷,基于帶寬的數據分區方法所需時間可能會長于Hash分區方法,這種情況下可以通過更充足的計算資源來降低采樣過程所需的開銷.在實際應用過程中,則可以綜合考慮最優比例的計算結果和采樣所需的時間,在速度提升較為明顯時選擇使用基于帶寬的數據分區方法.
5 總 結
在異構帶寬的條件下,傳統的數據分區方法會因為瓶頸節點的存在,導致數據分發效率低下.通過對各節點之間數據傳輸模型進行分析,本文提出了一種針對異構帶寬集群的數據分區方法,并在Flink中進行了實現.實驗證明:在節點間帶寬異構的情況下,基于帶寬的數據分區方法可以極大地提升數據分區完成的速度.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
新作文·小學低年級版(2021年9期)2021-11-27 07:57:46
學生天地(2020年17期)2020-08-25 09:28:54
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
故事大王(2016年7期)2016-09-22 17:30:08
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
兒童故事畫報(2013年3期)2013-06-24 05:40:30
