基于多種聚類算法和多元線性回歸的多分類主動學習算法
2020-12-31 02:23:52武禹伯
計算機應用 2020年12期
關鍵詞:分類
汪 敏,武禹伯,閔 帆
(1.西南石油大學電氣信息學院,成都 610500;2.西南石油大學計算機科學學院,成都 610500)
(?通信作者電子郵箱minfanphd@163.com)
0 引言
在油氣測井中,儲層巖性復雜多樣,基于測井資料開展巖性識別在儲層評價過程中具有重要意義[1]。在測井資料中攜帶著大量地層巖性、物性的地質信息,準確的地質信息對于無論是巖性識別還是儲層評價都有著至關重要的影響。隨著石油行業的快速發展,海量的測井數據處理對于測井人員來說費時費力,而且極大地影響了如巖性識別等石油相關領域的工作效率。近些年來,隨著機器學習領域的不斷發展,許多學者和石油領域工作者把目光放到了這兩者的結合上。現階段,有許多機器學習方法都被應用到了巖性識別領域,包括多元統計方法[2]、主成分分析方法[3]、模糊數學[4]、支持向量機[5]和人工神經網絡[6]等。
主成分分析方法是一種統計方法,通過正交變換將一組可能存在相關性的變量轉換為一組線性不相關的變量,并將這組變量稱為主成分。陳伏兵等[7]提出了分塊二維主成分分析法,在與傳統二維主成分分析法的對比中,通過使用低維的鑒別特征矩陣,使得識別精度得到了進一步提高。周非等[8]提出了一種基于主成分分析和卡方距離的信號強度差指紋定位算法,通過使用主成分分析算法進行信號強度差數據降維和相關性冗余消除,使得定位誤差得到了明顯的減小。目前主成分分析方法已被廣泛應用于石油相關等許多領域。
支持向量機是一類按監督學習方式對數據進行二元分類的廣義線性分類器,其決策邊界是對學習樣本求解的最大邊距超平面。張進等[9]提出了一種改進的支持向量機算法,通過使用粒子群優化和特征選擇與參數聯合優化,使得算法在分類精度上得到了明顯提高。章少平等[10]針對不平衡數據集提出了一種優化的支持向量機集成分類模型,通過預處理不平衡數據并優化參數使得其算法相較于傳統支持向量機算法具有更高的分類精度。目前支持向量機已被廣泛應用于圖像分類等許多領域。
人工神經網絡是從信息處理角度對人腦神經網絡進行抽象,建立某種簡單模型,按不同的連接方式組成不同的網絡。史興宇等[11]提出了一種對汽車車牌進行智能數字識別的人工神經網絡方法,通過引入離散型神經網絡的聯想記憶功能,使得該模型相較于傳統人工神經網絡具有更快的收斂速度和更高的識別精度。程宇等[12]提出了一種基于卷積神經網絡的弱光照圖像增強算法,通過將處理弱光照圖像得到的派生圖輸入到卷積神經網絡中,使得輸出的圖像擁有更好的視覺效果和圖像質量。目前人工神經網絡已被廣泛應用于人工智能等許多領域。
主動學習方法[13-14]通過選擇具有代表性的樣本交由專家進行標記,將專家經驗與機器學習進行結合。目前比較常見的主動學習方法有不確定性抽樣法、基于聚類方法和基于委員會投票采樣法。其中基于聚類主動學習致力于將聚類算法應用到樣本選擇策略中,利用數據的結構來選擇代表性樣本。Wang等[15]提出了基于密度峰值聚類算法的主動學習算法,通過將密度峰值聚類算法應用到樣本選擇策略中,在相同訓練樣本基礎上使得算法的分類精度得到提升。賈俊芳[16]提出了基于層次聚類的主動學習算法,通過采用分層細化、逐步求精的方法提高了學習器的學習效率,獲得滿意的泛化能力。目前主動學習方法已被廣泛應用于數據分類等許多領域。
應用到巖性識別領域中的機器學習算法雖將測井資料和機器學習算法進行了結合,但是想要獲得良好的識別效果需要大量的標記樣本。實際工程中,具有標記的樣本是稀有且昂貴的。如何通過引入專家經驗獲取少量的標記樣本,達到良好的識別效果,是本文首先考慮的問題。機器學習領域中的主動學習方法能夠很好地解決這一問題,所以本文引入基于聚類算法的主動學習思想,但是基于單一聚類主動學習方法對于不同分布數據集的識別效果是不同的,因此,本文提出了基于多種聚類算法和多元線性回歸的多分類主動學習算法(multi-category Active Learning algorithm based on multiple Clustering algorithms and multivariate Linear regression algorithm,ALCL),來解決上述提到的問題。首先,應用四種異構聚類算法對數據進行聚類,通過比較每種算法的聚類結果對數據進行初始標記與分類。然后,選取關鍵實例并求解目標函數得到每種聚類算法的權重系數。最后,引入權重系數進行決策分類的綜合計算,將計算結果高于分類閾值的樣本進行分類。分類閾值一般設置較高,如在所有迭代終止后仍存在無法分類的樣本,則將截至目前所有的已分類樣本作為訓練集,采用K 最近鄰(K Nearest Neighbor,KNN)分類方法[17]進行投票分類。
在大慶油田油井的6 個已公開測井巖性數據集上進行實驗。在不同的查詢比例下,實驗對比了3 種經典監督學習算法和3種較新主動學習算法,通過Friedman和Nemenyi事后檢驗[18]驗證了所提ALCL 與其他算法之間的顯著性差異,在查詢比例相同的情況下,ALCL有效提高了巖性識別精度。
1 相關工作
本文的數據實例模型是決策信息系統,決策信息系統定義成一個三元組:

式中:X代表一個數據集向量;X=Xtrain∪Xtest,Xtrain是訓練集,Xtest是測試集;A代表一個條件屬性向量;Y代表一個真實標簽向量。
本文根據主成分分析方法、支持向量機和人工神經網絡三種方法在巖性識別領域中的應用做了如下調研。
針對東營凹陷董集洼陷濁積巖巖性復雜的問題,周游等[19]提出基于粒子群算法以及核函數理論的主成分分析方法,通過建立新的主成分計算方法構建五個主成分變量代替原有多維測井信息來對該區巖性進行識別。實驗結果表明該方法有效提升了該地區巖性識別的精度。楊兆栓等[20]針對塔中地區奧陶系碳酸鹽巖巖性復雜的問題,根據該地區測井信息利用主成分分析方法構建了五個綜合變量應用到識別模型中,有效提升了該地區巖性識別精度。傳統主成分分析方法在巖性識別問題中并未考慮所用測井信息的可靠性,這導致新主成分變量在巖性識別中效果減弱,從而使巖性識別精度降低。若能引入專家地質經驗則能更好地對測井信息進行優選,進而幫助到新主成分變量的構建中,進一步提高巖性識別精度。
張昭杰等[21]結合烏夏地區巖芯資料和測井數據,采用支持向量機法對該地區的巖性進行識別。應用遺傳算法挑選出最佳的支持向量機核函數參數和懲罰因子,建立支持向量機巖性識別模型。實驗結果表明該模型實際數據預測符合率達到81.6%。蘇賦等[22]針對測井曲線間存在大量信息冗余的問題,通過合成少數過采樣技術對數據集進行預處理,并提出模糊隸屬度函數改進模糊孿生支持向量機算法。在北美Hugoton 油氣田實際測井數據基礎上應用該算法對其進行巖性識別,并取得了良好的識別效果。上述方法在實際建模過程中需要用到大量帶有標簽的訓練樣本。實際過程中很難獲取大量的訓練樣本,所以基于支持向量機的巖性識別方法在實際應用中存在難以獲取大量訓練樣本的問題。
單敬福等[23]針對蘇里格氣田巖性復雜的問題,提出利用優選輸入向量的人工神經網絡法對其進行識別。實驗結果表明該方法相較傳統人工神經網絡法具有更快的收斂速度和更高的識別精度。陳鋼花等[24]應用卷積神經網絡法將巖性識別從高度非線性問題轉換成多層非線性計算問題,通過構建雙層卷積神經網絡模型對儲層巖性進行判別。實驗結果表明該方法較其他巖性識別方法具有更高的識別精度和更快的速度。人工神經網絡法自設計以來一直存在著無法解釋輸入與輸出之間關系的問題。較其他傳統機器學習算法來說,傳統人工神經網絡法需要更多的帶標記樣本作支撐才能達到良好的識別效果。在巖性識別應用中,若僅用有限的帶標記樣本進行識別,則會導致識別精度不高。
傳統基于聚類算法的主動學習都僅在一種聚類算法上進行應用和優化改進,而每種不同的聚類算法都有其適合的數據分布形式,如K均值(K-Means)聚類算法[25]對于球形數據分布的數據集具有良好的聚類效果,而像密度峰值聚類算法(Density Peak Clustering Algorithm,DPCA)[26]則對非球形數據分布的數據集具有良好的聚類效果。對于基于單一聚類算法的主動學習來說,分類效果的優劣取決于單一聚類算法的質量和是否適用于這一聚類算法的數據集。這導致在實際應用中面對各種各樣不同分布的數據集時,算法的泛化能力較差。
2 本文算法
通過主動融合專家經驗,選取少量關鍵樣本作為訓練樣本,結合過程清晰的聚類算法,并針對基于單一聚類主動學習算法適用數據集有限、泛化能力差的問題,提出了本文的ALCL,其執行步驟如下:
1)對巖性識別數據集進行預分類;
2)根據預分類結果對未分類樣本進行關鍵實例選取;
3)以所選關鍵實例為基礎建立多元線性回歸模型,并求解目標函數獲得聚類算法的權重系數;
4)根據決策分類方法將符合分類標準的樣本進行分類。
圖1給出了ALCL的整體流程。
2.1 聚類算法的預分類方法
巖性識別問題中,不同地層所對應的巖性是不同的,且巖性種類較多,聚類算法對巖性識別數據集進行聚類的同時無法對聚成的每簇進行類別的劃分。本節采用結合K-Means、DPCA、模糊C 均值聚類算法(Fuzzy C Means clustering algorithm,FCM)[27]和層次聚類算法(Hierarchical Clustering Algorithm,HCA)[28]這四種聚類算法聚類,并查詢公共點的方法解決上述問題。預分類方法也為后面關鍵實例的選取以及目標函數的建立與求解打好基礎。預分類方法的具體流程如下:
1)應用四種異構的聚類算法,對同一數據集進行無類別劃分的聚類操作。每種聚類算法根據自身的聚類原則,將數據集劃分成預先設定好的簇數。
2)以其中一種聚類算法為基礎,將這個聚類算法聚成的簇數同其余幾種聚類算法的簇數進行一一的查詢比較。根據交集個數最多被分為一類的原則,依次對每種聚類算法的簇數進行劃分,從而得到所需要的類數。
3)查找每類中的交集部分,將其前幾個樣本點與專家進行交互獲得其真實類別。將這幾個樣本點中,類別相同個數最多的類別定義為這一類中所有點的偽標簽。同時,為保證所有類別都能被標記成偽標簽,在之后的類別交互過程中,已被標記了偽標簽的類別不再計算其類別個數。
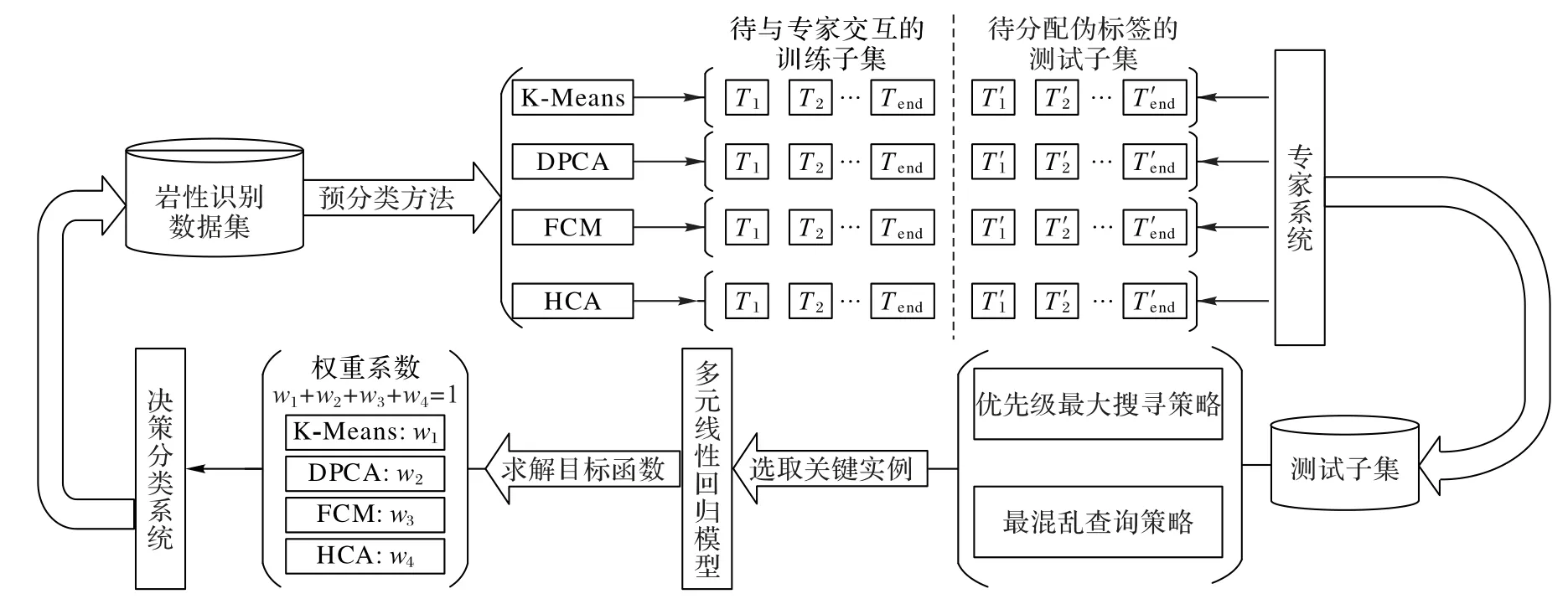
圖1 ALCL流程Fig.1 ALCL flowchart
圖2 通過四個部分展示了在簇數取2 時,對假設的10 個初始樣本進行預分類的具體過程。圖中用黑色方框和灰色方框來區分每種聚類算法聚類獲得的簇分布。在第三和第四部分中,灰色樣本表示當前類中的交集部分,通過將這些灰色樣本與專家進行交互以獲得其真實類別。圖中以正類和負類作為真實類別來區分10個初始樣本的類別。
2.2 關鍵實例選取方法
傳統的巖性識別方法難以和地質經驗進行有效的結合,本文根據樣本的代表性和信息量設計了關鍵實例的兩種選取策略。通過將選取到的關鍵實例交予專家進行標記,實現專家經驗與數據間的交互。經過人機交互后,專家的地質知識也為后面建立訓練模型提供了可靠的幫助,進而優化識別模型,提高巖性識別精度。
2.2.1 優先級最大搜尋策略
在主動學習中,主動地找到對算法影響效果最好的查詢樣本是整個學習過程中非常重要的一環。找到優先級最大的樣本就是為了找到對算法影響效果最好的樣本。對優先級定義的步驟如下:
1)定義局部密度。
樣本x的局部密度ρ定義為:

式中:dc表示截止距離;dist表示兩個樣本之間的歐氏距離;χ()為一個判斷函數。若括號內的值小于0,則χ=1;若括號內的值大于等于0,則χ=0。
2)定義與高密度點之間的最小距離。
樣本x與局部密度更高的樣本點的最小距離定義為:

3)定義優先級。
樣本x的優先級定義為:

根據式(4)計算測試集Xtest中每一個樣本的優先級,找到優先級最大點xmax,根據式(5)循環計算k次,得到離xmax最近的k個樣本xnearest。將xnearest和xmax作為關鍵實例,并加入到訓練集Xtrain中。
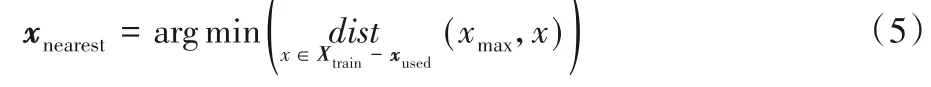
式中:xused為當前已被得到的離xmax最近的樣本點。
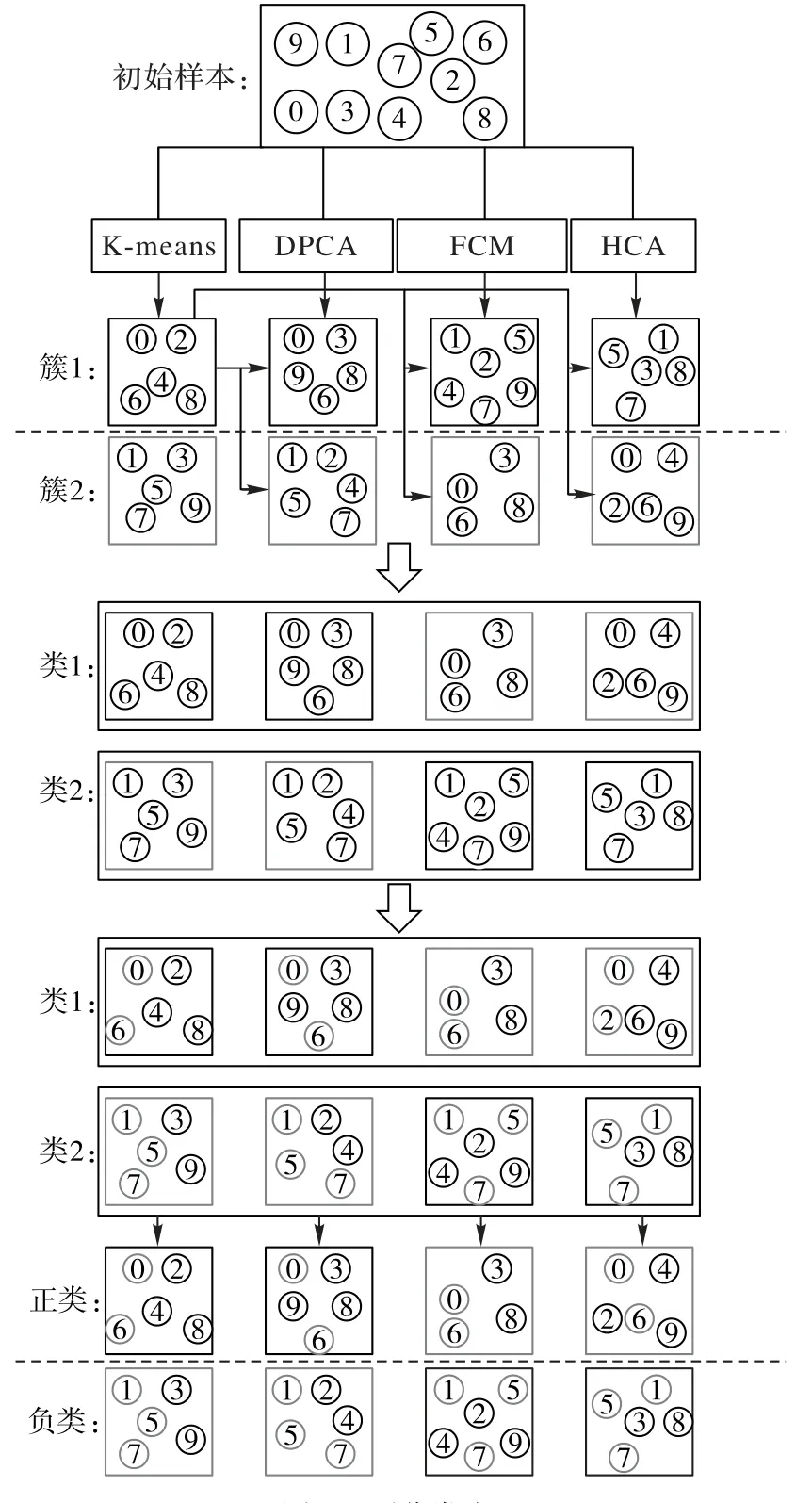
圖2 預分類流程Fig.2 Pre-classification flowchart
2.2.2 最混亂查詢策略
預分類過后,測試集Xtest中每一個樣本點都被4種聚類算法標上了各自的偽標簽。首先,定義最混亂:ALCL 共用到4種聚類算法,在進行了預分類處理之后每種聚類算法都對每一個x∈Xtest標記了各自的偽標簽。若每種聚類算法對應同一個樣本點的偽標簽基本都不相同,那么則稱這個樣本點當前處于最混亂情況,應被交互查詢真實標簽并作為關鍵實例加入到訓練集Xtrain中。然后,圖3 具體地展示了樣本點x的最混亂查詢策略的過程。最后,如圖3 所示,ALCL 所用聚類算法個數為4,因此在偽標簽個數一欄中所能出現的最大值為4,當且僅當偽標簽個數最大值小于等于2 時,當前樣本點被認為處于最混亂狀態,可以被選取為關鍵實例。
2.3 聚類集成方法
本節設計了一種基于多元線性回歸[29]的聚類算法集成模型。在進行了預分類和關鍵實例的選取后,將選取得到的關鍵實例同多元線性回歸模型相結合,構建預測標簽值的計算函數,進而構建用于求解每種聚類算法權重系數的目標求解函數。通過最小化目標求解函數得到每種聚類算法的權重系數。每種聚類算法的權重系數代表著在當前迭代中該聚類算法在樣本預測中所占的比重。權重系數越高,那么該聚類算法在樣本預測中的決定程度就越高;相反,則決定程度就越低。
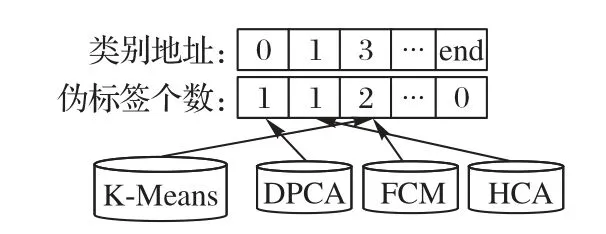
圖3 最混亂查詢策略Fig.3 Most confusing query strategy
首先,根據選取的關鍵實例結合多元線性回歸模型建立樣本標簽值的計算函數,即

然后,根據樣本標簽值計算函數構建用于求解權重系數向量θ的目標函數,即
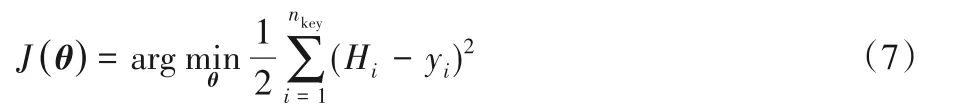
式中:Hi是每個關鍵實例的預測標簽值;yi是真實標簽值。
對式(7)進行最小二乘變形得到:
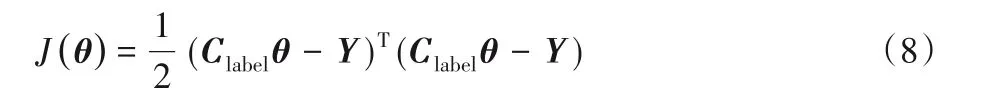
對式(8)進行展開得到:
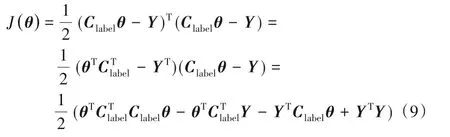
對式(9)進行求導并令導數為0,得到:

最后,通過對式(10)求解,得到最終的求解函數為:

通過對式(11)進行求解后,得到權重系數向量θ=(θ1,θ2,θ3,θ4)。該向量中各系數存在著較大的范圍差異,且系數可能出現為負的情況。這使得在決策分類過程中每種聚類算法的優先級不能夠很好地展現。為解決上述問題,需對權重系數向量θ進行歸一化處理。

式中:w是歸一化權重系數值。通過式(12)對權重系數向量θ進行歸一化處理后,得到歸一化權重系數向量,記為W=(w1,w2,w3,w4)。
2.4 決策分類方法
在獲得歸一化權重系數向量W后,需要根據每種聚類算法的權重系數進行決策分類的綜合計算,將計算結果超過閾值的樣本點進行分類,計算式如下:

式中:εr()是一個判斷函數,若括號內的值等于r則εr=1,否則εr=0;C是每個樣本對應每種聚類算法的偽標簽值;r是數據集的真實類別數;α是決策閾值。
進行決策分類后,可能會出現仍未被分類的樣本點。剩余樣本的分類策略為:通過KNN 分類方法對剩余樣本點進行分類。ALCL 中KNN 分類方法使用的訓練集包含通過決策分類方法得到的分類樣本。這些樣本點的類別標簽并不一定是這些樣本點的真實標簽。但是通過對α大小的設置,可以增加這些分類樣本的可信度。通過這種處理方式,可以盡可能增加KNN分類過程中訓練集的大小,進而提高KNN分類方法的準確率,同時可以減少與專家進行交互時所花費的代價。
2.5 偽代碼及復雜度分析
基于多種聚類算法和多元線性回歸的多分類主動學習算法(ALCL)的框架如算法1 所示。第1)行為數據預處理過程,第4)~6)行為預分類過程,第7)~10)行為選取關鍵實例過程,第13)行為獲取權重系數過程,第14)~21)行為決策分類過程。

表1 列出了ALCL 的時間復雜度,得出算法1 的時間復雜度為:
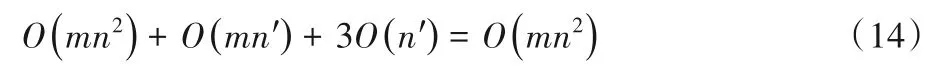
式中:m為條件屬性的個數;n為樣本的總個數;n′為當前未被分類的樣本個數,且n′總是小于n。

表1 ALCL的時間復雜度Tab.1 Time complexity of ALCL
3 實驗與結果分析
本章將展示所用測井巖性數據集上的實驗結果,并進行分析。實驗使用Java軟件并結合Weka,在具有16 GB RAM 和Intel Core i5-9400F CPU @ 2.90 GHz 處理器的Windows 10 64位操作系統上執行了運算,并應用大慶油田油井的6 個公開測井巖性數據集,將ALCL 在巖性識別上的效果與KNN、決策樹分類算法(Decision Tree Classification Algorithm,DTCA)[30]和樸素貝葉斯(Na?ve Bayes,NB)[31]三種傳統監督學習算法,基于委員會投票的主動學習算法(active learning algorithm with Query By Committee,QBC)[32]、基于兩階段聚類的主動學習(Active Learning through Two-stage Clustering,ALTC)算法[33]和基于密度峰值聚類的主動學習(Active Learning through Density Clustering,ALDC)算法三種較新主動學習算法進行比較。實驗代碼將公布在GitHub 上,提供下載和證明。
實驗以自然伽馬(Natural Gamma,NG)、聲波時差(Sonic Jet,SJ)、補償密度(Compensation Density,CD)、微梯度電阻率(Micro Gradient Resistivity,MGR)、淺橫向電阻率(Shallow Lateral Resistivity,SLR)、深側向電阻率(Deep Lateral Resistivity,DLR)等對巖性變化反映比較敏感的測井參數作為輸入參數。每個樣本代表不同儲層深度的位置,樣本個數為611~733。每個數據集的類別個數均為4,分別是頁巖(SHale,SH)、粉砂巖(SIltstone,SI)、砂巖(SAndstone,SA)和鈣質砂巖(Calcareous Sandstone,CS)。實驗所用數據集如表2所示。
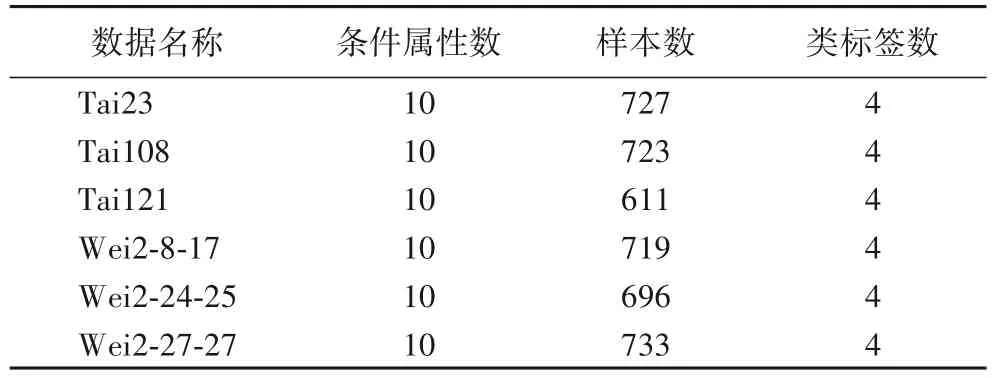
表2 數據集描述Tab.2 Dataset description
實驗采用分類精度accuracy作為評估指標。

式中:|Xtrain|為訓練樣本數;|Xtest|為測試樣本數;error為誤分類數;|X|為總的樣本數。
首先進行了ALCL 同三種主動學習算法的參數調節實驗,得到實驗效果最好的查詢比例。接著,取實驗效果最好的查詢比例,將本文的ALCL 具體地同三種監督學習和三種主動學習算法作比較。
3.1 參數調節實驗
實驗通過不斷增加查詢比例,以期望找到每種算法的最佳查詢比例。每個數據集上共進行5組實驗,每組實驗重復5次,得出分類精度后取平均值,以減小實驗誤差。對于每個數據集,第一組實驗取數據集的1%作為查詢比例,以后每組實驗查詢規模遞增數據集的2%。
通過圖4 得到每種算法在對應同一個數據集上的分類精度變化情況。圖4 分別表示在6 個測井巖性數據集上的實驗結果,縱軸表示對應不同查詢比例時每種算法的分類精度結果。
根據圖4 可以看出,四種算法的分類精度在隨著查詢比例增加時基本呈整體上升趨勢,但ALEC 的增長趨勢并不明顯,基本處于穩定狀態。在圖4(a)、(b)、(d)、(e)中,本文ALCL 在對應不同查詢比例時的分類精度基本都比其他算法高;但在圖4(c)、(f)中,ALCL 的分類精度基本均低于ALTC。在圖4(a)、(c)、(d)中,均有三種算法在查詢比例為5%時取得分類精度最大值。圖4(b)中,更是四種算法全部在查詢比例為5%時取得分類精度最大值。圖4(f)中,也同樣有兩種算法在查詢比例為5%時取得分類精度最大值。因此,可以認為在查詢比例取5%時對應每種算法的分類效果最好。
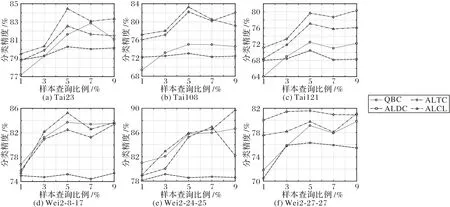
圖4 遞增查詢比例時每種算法的分類精度結果Fig.4 Classification accuracy results of algorithms with query ratio increasing
3.2 與監督學習算法對比
3.1 節中,通過將ALCL 同三種主動學習算法對比得到最佳查詢比例為5%。本節在查詢比例取5%時將ALCL 同KNN、DTCA、NB 三種經典監督學習算法進行對比,以期望得到更好的巖性識別效果。表3 展示了ALCL 與三種監督學習算法在查詢比例為5%時的分類精度結果。
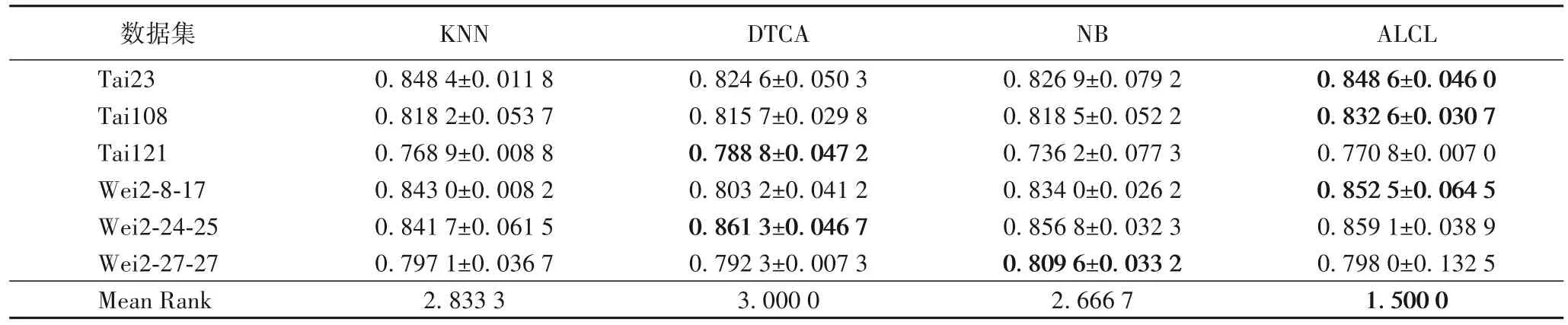
表3 ALCL與3種監督學習算法的分類精度比較結果(均值±標準差)Tab.3 Comparison results of classification accuracy among ALCL algorithm and 3 supervised learning algorithms(mean±standard deviation)
表3 中,本文提出的ALCL 在Tai23、Tai108 和Wei2-8-17三個數據集上的分類精度達到最高,在其余三個數據集上也是達到了第二高的分類精度。使用Friedman 和Nemenyi 事后檢驗分析算法的性能。由Friedman 檢驗得出的排名中,ALCL的排名均值為1.500 0,位于所有算法的第一位。
表4給出了通過Nemenyi檢驗獲得的t值。在顯著性水平因子β取0.1 時,ALCL 對比KNN 算法和DTCA 的t值均小于0.1。因此,ALCL明顯優于KNN和DTCA。ALCL對比NB算法的t值雖大于0.1,但在排名均值上ALCL 小于NB 算法,且t值為0.117 525,僅超出0.017 525。因此,ALCL略優于NB算法。

表4 假設檢驗(Ⅰ)Tab.4 Hypothetical test(Ⅰ)
3.3 與主動學習算法對比
在查詢比例為5%時,每種算法對應每個數據集的分類精度結果如表5 所示。表5 中,本文提出的ALCL 在Tai23、Tai108、Wei2-8-17 和Wei2-24-25 四個數據集上的分類精度達到最高,在Tai121 和Wei2-27-27 兩個數據集上也是達到了第二高的分類精度。使用Friedman 和Nemenyi 事后檢驗分析算法的性能。由Friedman檢驗得出的排名中,ALCL的排名均值為1.333 3,位于所有算法的第一位。
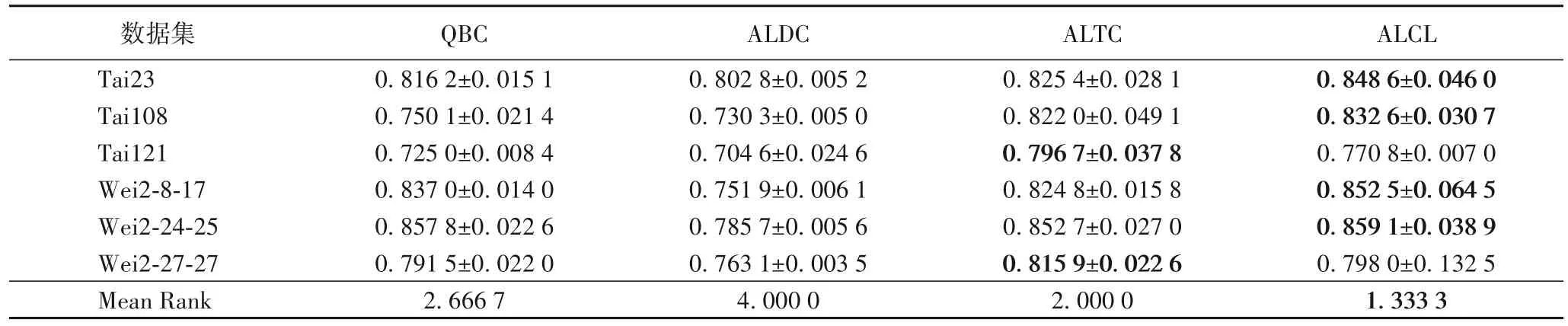
表5 ALCL與3種主動學習算法的分類精度比較結果(均值±標準差)Tab.5 Comparison results of classification accuracy among ALCL and 3 active learning algorithms(mean±standard deviation)
同時,使用Nemenyi 事后檢驗來分析是否存在顯著差異。表6給出了通過Nemenyi檢驗獲得的t值。在顯著性水平因子β取0.1 時,ALCL 相較QBC 算法和ALDC 算法的t值均小于0.1。因此,ALCL 明顯優于QBC 和ALDC 算法。ALCL 相較于ALTC 算法的t值雖大于0.1,但在排名均值上ALCL 小于ALTC算法。因此,ALCL算法略優于ALTC算法。

表6 假設檢驗(Ⅱ)Tab.6 Hypothetical test(Ⅱ)
4 結語
針對傳統機器學習算法需要大量標記樣本,且基于聚類主動學習算法適用于數據集有限、分類精度差的問題,本文提出了一種基于多種聚類算法和多元線性回歸的多分類主動學習算法(ALCL)。基于多元線性回歸模型的聚類算法集成策略能夠很好地將結構完全不同的幾種聚類算法進行結合,通過將求解得到的權重系數與主動學習建立聯系,實現對巖性的識別分類。該算法能夠很好地應用于巖性識別問題。在6個真實巖性識別數據集上的實驗結果表明,該算法可以有效提高巖性識別的精度。未來的研究工作主要包括以下三個方面:1)增加或更換新的聚類算法以提高ALCL 的分類效果;2)改進幾種聚類算法的初始聚類中心選擇策略,從而優化聚類結果;3)研究更優的聚類集成策略。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
