基于三線互連應用交換系統的設計與實現
2020-12-28 06:37:38鄒昀辛王曉光謝紅亮
計算機工程與設計 2020年12期
關鍵詞:系統
鄒昀辛,王曉光,楊 帆,謝紅亮
(中國航天科工集團第二研究院 七〇六所,北京 100854)
0 引 言
隨著集群和云計算等互聯網技術的蓬勃發展,應用交換產品已成為數據中心應用中的一種常見的網絡交換設備[1,2]。這種設備需要實現2-7層數據交換的功能,有兩種常見的實現方式:
第一種是在計算主板上集成專用網卡或高速以太網卡,通過軟件方式完成2-7層的數據交換[3,4],底層內核與操作系統上層應用軟件共同處理網絡交換請求,網絡數據需要在空間棧中被頻繁拷貝與調用。該方案的缺陷是:缺少交換芯片,數據處理完全依賴于軟件實現,性能受限于計算CPU的性能,滿足不了高吞吐量網絡的負載需求。
第二種是將計算主板和交換主板通過網絡相連,計算主板實現4-7層數據交換,交換主板實現2-3層的數據交換,從而增加網絡數據的處理能力[5]。但這種方案也存在一定的缺陷:需要由兩個電路主板來實現2-7層的數據交換,增加了功耗和成本;兩主板間的數據通信經過多次信號轉換,增加了延遲;多電路板的實現方式降低了設備的可靠性。
此外還有基于彈性擴展的云交換架構、基于分布式的交換卸載架構,都是通過軟件技術實現的2-7層數據交換,由于是基于集群方式實現,并非單一設備實現方案,所以不在本文的討論范圍內。
本文研究一種計算芯片和交換芯片三線互連的主板設計方案,通過一個電路主板實現2-7層的網絡交換,降低了網絡部署成本和復雜度,降低了網絡延遲,增加了網絡帶寬,提升了網絡處理性能。
1 應用交換技術介紹
根據OSI七層網絡標準,傳統的網絡交換設備通常只工作在二三層,對網絡中的MAC數據包和IP數據包進行轉發或廣播,應用交換設備除了處理二三層的網絡數據包外,還能對數據包中四七層數據進行識別和轉發,從而提升整個應用系統的并發能力,也稱應用交付網關。由于四七層的網絡數據應用場景多,硬件解析難度大,所以一般是通過CPU來輔助進行數據處理,常見的應用交換架構有兩種:
計算板獨立實現的應用交換架構如圖1所示,其中NIC指的是網卡,如1G/10G等以太網卡,Intel PCH橋片上集成多個以太網卡,CPU與Intel PCH橋片通過高速PCIe信號相連[6]。在這種架構中,缺少交換芯片,二至七層的網絡數據都得通過CPU來進行計算處理,性能受限,滿足不了高吞吐量網絡的負載需求。
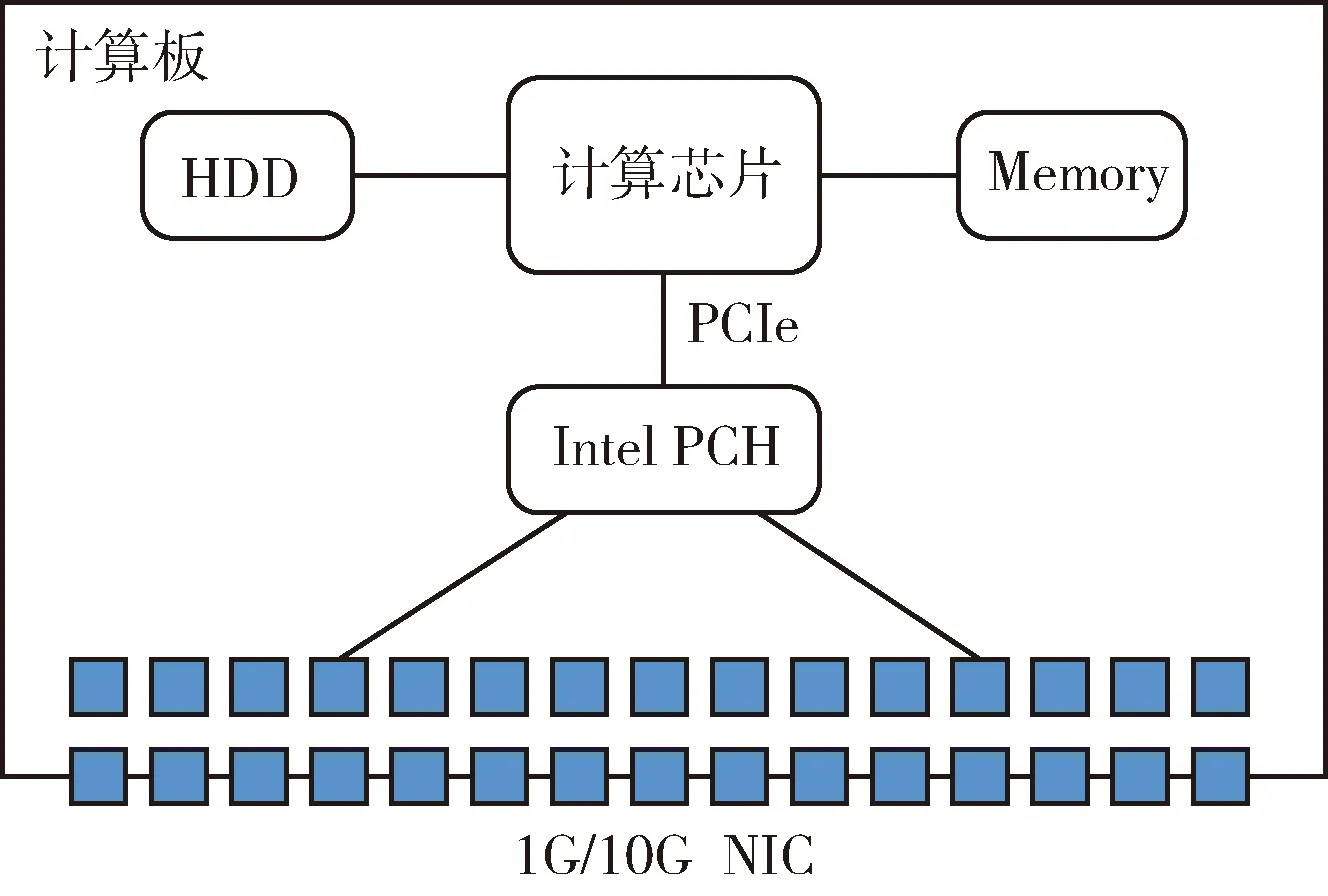
圖1 計算板實現的應用交換架構
計算板與交換板組合實現的應用交換架構如圖2所示,計算板上CPU通過高速PCIe信號直連兩個網絡芯片,交換板通過交換芯片引出多個網絡接口,兩板卡之間通過網絡信號互連[7]。在這種架構中,交換板處理二三層網絡數據,計算板處理四七層網絡數據,從而實現高吞吐量網絡的負載需求。

圖2 計算板與交換板組合實現的應用交換架構
2 計算與交換芯片三線互連的應用交換技術
2.1 芯片三線互連架構
計算與交換芯片三線互連的架構如圖3所示,計算芯片通過直連的PCIe信號控制交換芯片的啟動,并通過兩網絡芯片與交換芯片互連。相比于傳統的互連方式,該架構將交換芯片模塊移至計算板內部,而計算芯片從交換芯片直取網絡數據的方式,不存在額外的轉換延遲,提高了網絡處理效率。

圖3 計算與交換芯片三線互連架構
二三層的網絡數據完全由交換芯片來進行處理,不占用計算芯片的處理資源。四七層網絡數據通過板級PCIe信號直接傳輸給計算芯片,具有更高的穩定性和傳輸速率,同時采用兩PCIe通道傳輸數據的方式,是綜合考慮了四七層應用數據內外轉發的特點,實現了兩個網絡隔離子域,從而滿足更多應用交換場景的需求。
圖4是該技術方案的系統硬件結構,主板上主要包括計算電路和交換電路兩部分。
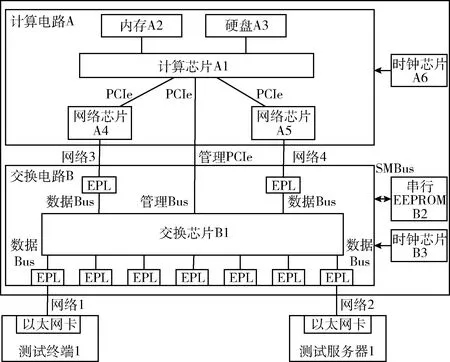
圖4 系統硬件結構
在計算電路A中,內存A2與計算芯片A1直連,硬盤A3與計算芯片A1直連,網絡芯片A4與計算芯片A1連接,網絡芯片A5與計算芯片A1連接,時鐘芯片A6的輸出端與計算芯片A1的輸入端連接;在交換電路B中,串行EEPROM B2通過SMBus與交換芯片B1雙向連接,時鐘芯片B3的輸出端與交換芯片B1的輸入端連接;計算芯片A1與交換芯片B1通過管理PCIe總線雙向連接,網絡芯片A3連接交換芯片的一個EPL,網絡芯片A4連接交換芯片的一個EPL。
主板電路主要包括計算電路A和交換電路B兩部分,計算電路A主要由計算芯片、內存、硬盤、網絡芯片和時鐘芯片組成,交換電路B主要由交換芯片、串行EEPROM、時鐘芯片和若干EPL組成。各部件的功能如下:計算芯片A1實現4-7層的網絡數據轉發,并對交換芯片B1進行初始化、配置、監控和管理;內存和硬盤輔助實現計算芯片A1上操作系統的運行;網絡芯片A4和A5用于與交換芯片B1間的以太網絡通信;時鐘芯片A6和B3分別用于計算芯片A1和交換芯片B1的時鐘頻率初始化;交換芯片B1是核心的網絡處理模塊,實現2-3層的網絡數據的轉發和處理;EPL即Ethernet Port Logic,用于與外部以太網連接,完成以太網與交換芯片間的數據轉發;控制板用于對交換芯片進行初始化、配置、監控和管理;串行EEPROM用于保存交換芯片的配置信息。系統初始化過程如下:① 計算芯片A1啟動,時鐘芯片A6復位,讀取硬盤A3信息,初始化內存A2和網絡芯片A4,并掃描各PCIe總線上的設備;② 交換芯片B1復位,其中包括:時鐘芯片B3復位、以太網端口EPL復位、讀取串行EEPROM B2的配置信息;③ 計算芯片A1進入操作系統,并驅動管理PCIe控制交換芯片B1,完成交換芯片B1的配置文件導入和端口的初始化;④ 網絡芯片A4和A5分別與交換芯片B1進行速率協商,完成握手,開始網絡通信。
計算芯片一般具有豐富的PCIe接口,可以通過擴展多個網口的形式增加計算芯片的處理帶寬,所以在計算電路設計時,網絡芯片的理論吞吐量應與計算芯片的吞吐性能相一致,才能最大限度地提高整體的四七層處理性能。以上的電路設計是兩類傳統應用交換技術的綜合,兼具高性能、高吞吐、低功耗、低成本的特點。
2.2 交換數據分離設計
為了增加四七層網絡數據的處理能力,將二三層網絡數據的處理進行卸載,網絡數據的流入流出分兩種情況進行處理,過程步驟詳見圖5(硬件結構名請參考圖4)。
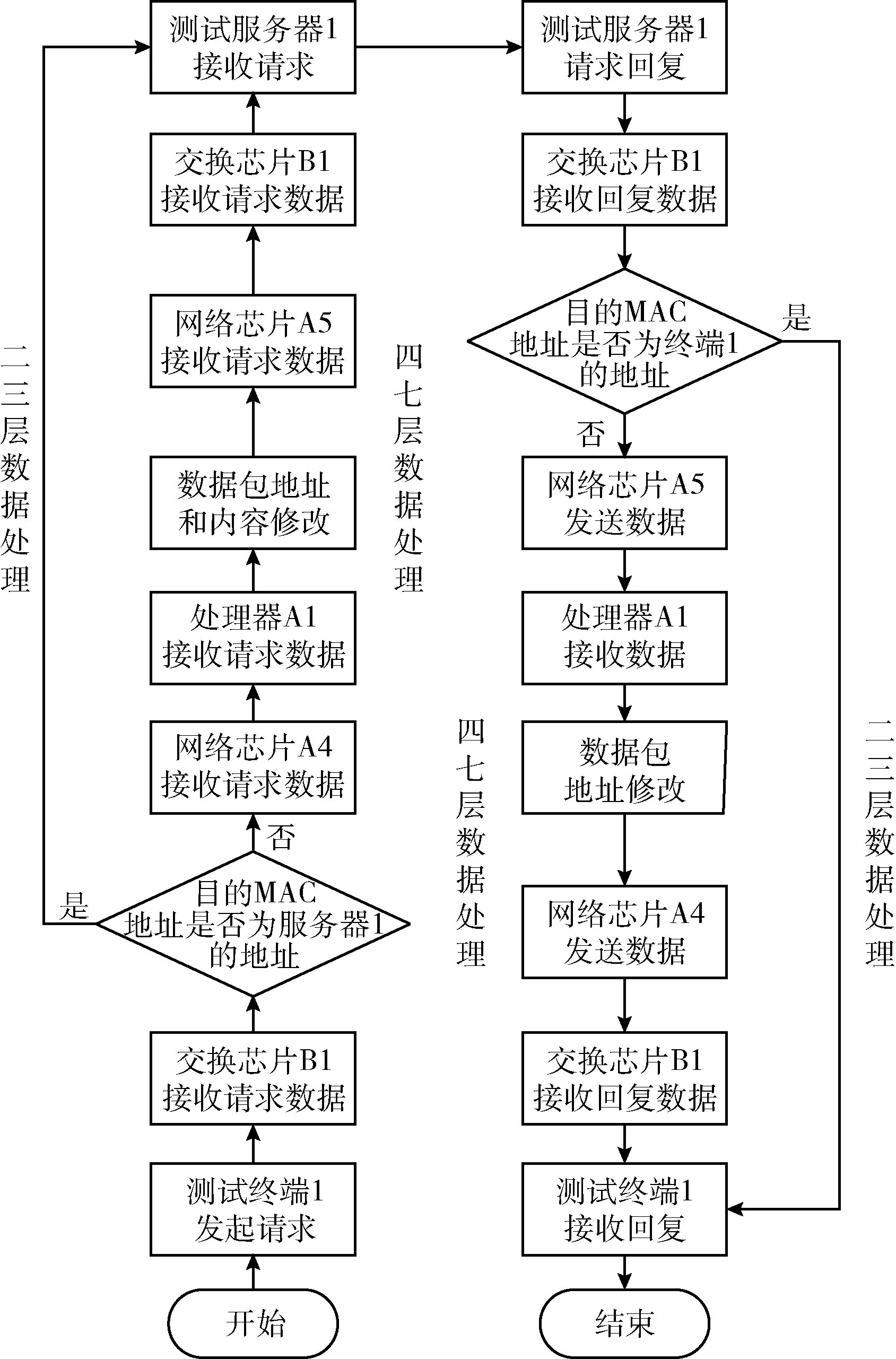
圖5 系統七層數據交換流程
(1)交換芯片處理二三層交換數據
①測試終端1通過網絡1發起一個請求數據包;②交換芯片B1檢測到從網絡1接收的一個數據包,交換芯片B1對數據包進行校驗,其中包括IPV4頭部、TCP/UDP頭部和VLAN頭部等,如果數據校驗錯誤則將被丟棄,否則進行下一步;③交換芯片B1對數據包進行2-3層頭部解析,獲取目的MAC和目的IP地址等信息;④交換芯片B1對數據包目的MAC和IP地址的解析結果,與測試服務器1的MAC或IP對應,則將數據通過網絡2轉發給測試服務器1;⑤測試服務器對請求的數據響應,并將回復的數據包經過交換芯片發送給測試客戶端1,完成2-3層的數據響應。
(2)計算芯片處理四七層交換數據
①測試終端1通過網絡1發起一個請求數據包;②交換芯片B1檢測到從網絡1接收的一個數據包。交換芯片B1對數據包進行校驗,其中包括IPV4頭部、TCP/UDP頭部和VLAN頭部等,如果數據校驗錯誤則將被丟棄,否則進行下一步;③交換芯片B1對數據包進行2-3層頭部解析,獲取目的MAC和目的IP地址等信息;④交換芯片B1對數據包目的MAC和IP地址的解析結果,如果與網絡芯片A4的MAC或IP對應,則將數據通過網絡3轉發給網絡芯片A4;⑤計算芯片A1接收到網絡芯片A4的數據,進行四七層的網絡報文解析,修改地址、端口或內容字段等信息后,將處理后的數據通過網絡芯片A5轉發到網絡4;⑥交換芯片B1接收網絡4的數據,并對數據包進行校驗,其中包括IPV4頭部、TCP/UDP頭部和VLAN頭部等;⑦交換芯片B1對數據包進行二三層頭部解析,獲取目的MAC和目的IP地址等信息;⑧交換芯片B1對數據包目的MAC和IP地址的解析結果,與網絡芯片A4的MAC或IP對應,則將數據通過網絡2轉發給測試服務器1;⑨測試服務器對請求的數據響應,并將回復的數據包依次經過交換芯片B1、網絡芯片A5、計算芯片A1、網絡芯片A4、交換芯片B1,最后發送回測試客戶端1,完成4-7層的數據響應。
2.3 跨內核網絡直取技術
主機間的數據通信通常會涉及網卡、驅動、協議棧的處理,其處理動作會包括:網卡設備接收網絡數據、網卡觸發中斷喚醒計算芯片、驅動程序填充內核空間讀寫緩沖區、數據報文經過內核協議棧解包、數據從內核空間復制到用戶空間、應用程序調用Socket庫獲取并處理數據,該過程涉及到數據在內核空間和用戶空間的兩次拷貝[8]。隨著硬件帶寬的不斷擴容,作為一個部署在數據中心的應用交換系統,其四七層的網絡吞吐帶寬也通常在萬兆以上,如果采用傳統的計算芯片中斷和內核協議棧的復制來處理數據,當吞吐量較大時,計算芯片中斷和網絡轉發延遲將越發明顯[9]。故此,本文基于DPDK庫實現了一種跨內核的網絡數據直取技術,將網卡隊列數據直接映射到用戶空間,實現數據包零拷貝的收發處理,實現數據高速交換。
如圖6所示,左側是基于內核協議棧的網絡數據包收發流程,右側是本文基于跨內核數據直取技術實現的網絡數據包收發流程,底層網卡采用的是一種加速網卡,該網卡可以實現與計算芯片間的多核多隊列綁定。UIO即Userspace I/O,是基于DPDK實現的通用網卡驅動[10,11],它輔助用戶程序直接訪問硬件IO的數據。MMAP即內存共享映射,將內核空間映射到用戶空間,避免內核空間與用戶空間頻繁拷貝帶來的計算芯片開銷。PMD即Poll Mode Driver輪詢驅動,通過輪詢和中斷服務歷程的方式實現,避免了頻繁的中斷上下文切換所帶來計算芯片資源消耗,適用于高吞吐量的網絡場景,兼具高性能、低能耗的特點。Fast TCP是運行于用戶空間的四層網絡數據包協議,適用于FTP、EMAIL等網絡服務的數據轉發。Fast HTTP是運行于用戶空間的七層網絡數據包協議,適用于WEB等網絡服務的數據轉發。Fast TCP和Fast HTTP是自主研發的高速數據接口協議,是專用的虛擬服務進行轉發的接口,與通用的基于內核轉發的數據協議不同,該協議在DPDK模塊的協助下,能快速直取網卡緩沖區隊列的數據,在一定程度上加快了數據的收發速度,降低了數據包延遲,提高了系統性能。
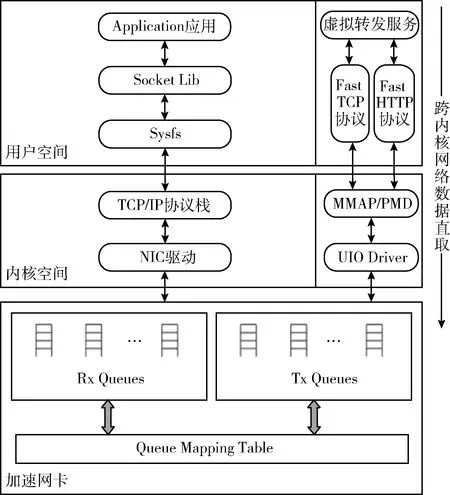
圖6 跨內核網絡數據直取機制
3 性能測試與分析
采用LoadRunner壓力測試機和國產化應用系統搭建性能測試環境,從四層和七層交換性能兩個方面對文中涉及到的3種應用交換系統(見前文第1節和第2節)進行比較。LoadRunner是最為常用的應用系統測試軟件,可以對系統的吞吐量、TPS(transactions per second)、CPS(connections per second)和RPS(responses per second)等指標進行專業的評估[12,13],其結果具有較強的參考性。
3.1 測試環境
測試時主要采用國產化的WEB應用環境,原因如下:應用交換系統主要采用的是國產化的軟硬件架構,適用于國產化應用系統環境;測試主要針對四七層的應用交換能力測試,需要搭建四七層的應用環境,所以采用最為常見的WEB應用系統。主要測試環境拓撲如圖7所示,主要分壓力機、應用交換、WEB應用3部分,其中,環境配置參數見表1。
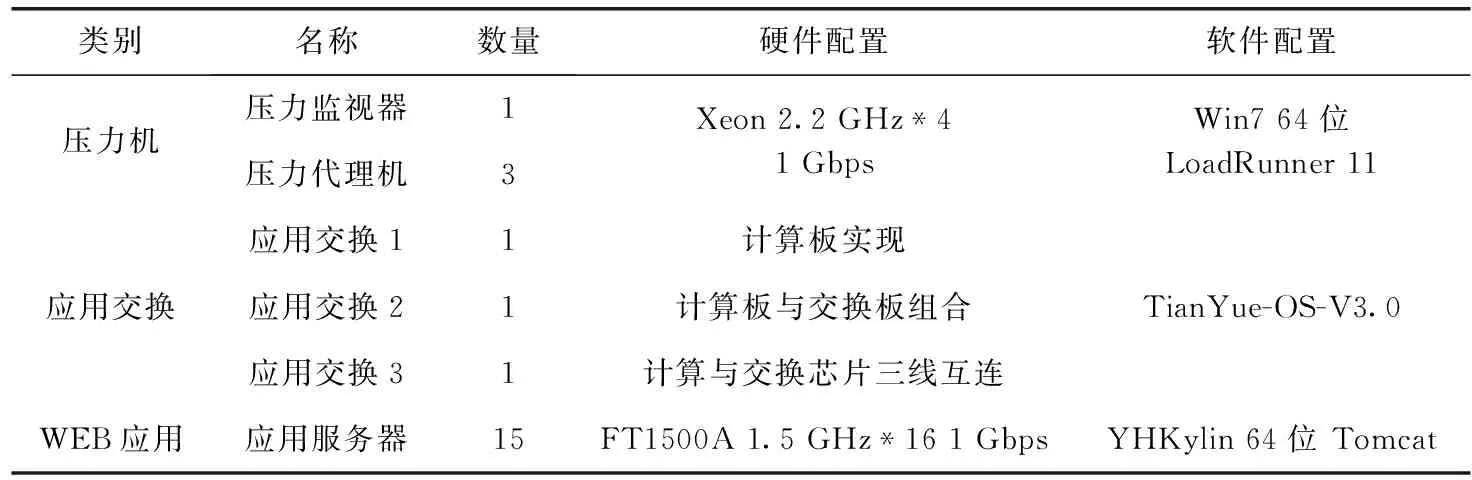
表1 測試環境配置
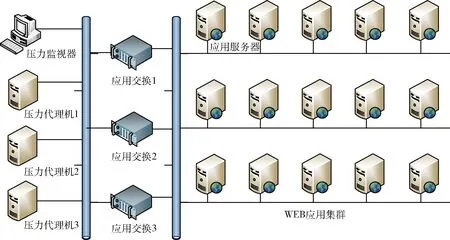
圖7 測試環境拓撲
應用交換1代表以計算板獨立實現的應用交換設備,應用交換2代表將計算板與交換板組合實現的應用交換設備,應用交換3代表基于計算芯片與交換芯片三線互連技術實現的應用交換設備。3種應用交換設備上都部署了同一個負載均衡軟件TianYue-LB-3.0,該軟件能提供二三層的網絡端口管理、四層TCP協議數據轉發、七層HTTP協議數據轉發,并且支持普通輪詢、加權輪詢、源地址綁定和最少連接等多種負載均衡策略,為國產自主研發軟件。3種應用交換設備單獨分開測試,客戶端或壓力機通過識別應用交換設備的IP來區分不同的設備。當客戶端或壓力機向應用交換設備的一側端口發送http請求時,應用交換設備將該請求通過另一側端口分發到相應的Web應用服務器上,經過Web應用服務器處理后的響應數據包再返回給應用交換設備,最后達到客戶端。該過程有點類似于代理服務器的NAT功能。壓力測試過程中,為了避免端口的網絡帶寬瓶頸,通常也會將多個網卡綁定起來,從而增加帶寬。
WEB應用集群提供應用服務。本文作者在上面部署了一個性能較優的國產中間件“東方通”和一個運行較為穩定的郵件應用服務。15臺應用服務器具有相同的Web處理能力,能提供郵件系統的用戶登陸、郵件查詢、郵件發送和用戶登出等功能。為了避免數據庫和磁盤陣列對集群性能的影響,應用服務器采用訪問本地數據庫和磁盤的方式。從理論上講,15臺應用服務同時運行時,其吞吐量應該是單臺應用服務的15倍,但是通常會受到分發策略、網絡吞吐能力的限制,實驗結果驗證了該結論,請看結果分析。
3.2 測試方法
仿真測試采用一個專業的測試工具Loadrunner。該軟件可以模擬幾千個用戶進行自動負載測試和實時性能監測。該軟件具有用戶腳本、場景模擬和結果分析3大功能模塊。
首先,監控機上創建Web測試腳本,該腳本具有用戶登陸、郵件查詢、郵件發送和用戶登出的4個功能,基本滿足模擬環境的測試要求。其次,應用交換和WEB應用共同構成一個應用集群系統,當壓力場景運行時,監控機將該腳本發送到壓力代理機上執行,并通過調整模擬用戶的數目來增減并發量和吞吐量,從而測試該應用集群系統的性能上限。場景運行時,監控機實時監控整個系統的吞吐量和TPS,并在運行結束后收集數據并進行分析,生成統計分析結果。
測試主要從吞吐量、TPS、CPS和RPS這4種數據來對比分析交換設備的性能:
吞吐量是測量網絡性能的一個重要指標,它可以測出應用系統的總帶寬。與網絡帶寬不同,它不僅與鏈路傳輸速度有關,還受到網卡收發速度、cpu處理能力、交換機和應用程序性能等多種因素的影響。實驗中的所有服務器的網卡性能都接近于1000 M,而實測中的總吞吐量在500 M左右,所以基本上可以排除網卡對集群吞吐量的影響。
TPS(transactions per second),也就是事務響應數,它可以測出應用系統的每秒能處理的事務數。不同的事務(如登錄、查詢等)會消耗不同的系統資源,就會有不同的響應時間。壓力測試時,采用的是混合場景,通過TPS指標,我們可以清楚地了解集群系統的服務能力。
CPS(connections per second),指四層每秒新建TCP連接數;RPS(responses per second),指服務端每秒回復的http請求的數目。通過這兩個指標,可以窺探出該應用系統的并發用戶數(也就是允許多少個用戶同時在線)。
3.3 結果分析
四七層的網絡交換能力,分別是指TCP和HTTP數據包的轉發能力。如果數據轉發的能力強,網絡中的請求和響應的速度就快,應用系統在單位時間內的數據處理能力就強。所以,可以從整個應用集群系統的吞吐量、TPS、CPS和RPS數據來比較3種應用交換系統性能。
(1)四層交換性能
四層交換能力,主要指根據網絡數據報文的IP或端口進行改寫并轉發的能力。由圖8的結果分析可知,3種應用交換下,應用系統的最大吞吐量分別為:30 MBps,62 Mbps,71 Mbps。最大TPS分別為:49 tps,71 tps,83 tps。最大CPS分別為:26 cps,36 cps,43 cps。最大RPS分別為:1721 rps,2510 rps,2987 rps。隨著并發數的增加,應用交換3(計算與交換芯片三線互連架構)的吞吐量、TPS、CPS和RPS的性能均有顯著提高。當并發數達到最大80時,應用交換3相比其它兩種應用交換架構可提升12%以上吞吐量。可見,應用交換3(即基于計算芯片與交換芯片三線互連技術實現的應用交換)適用于高帶寬高并發的應用集群領域。
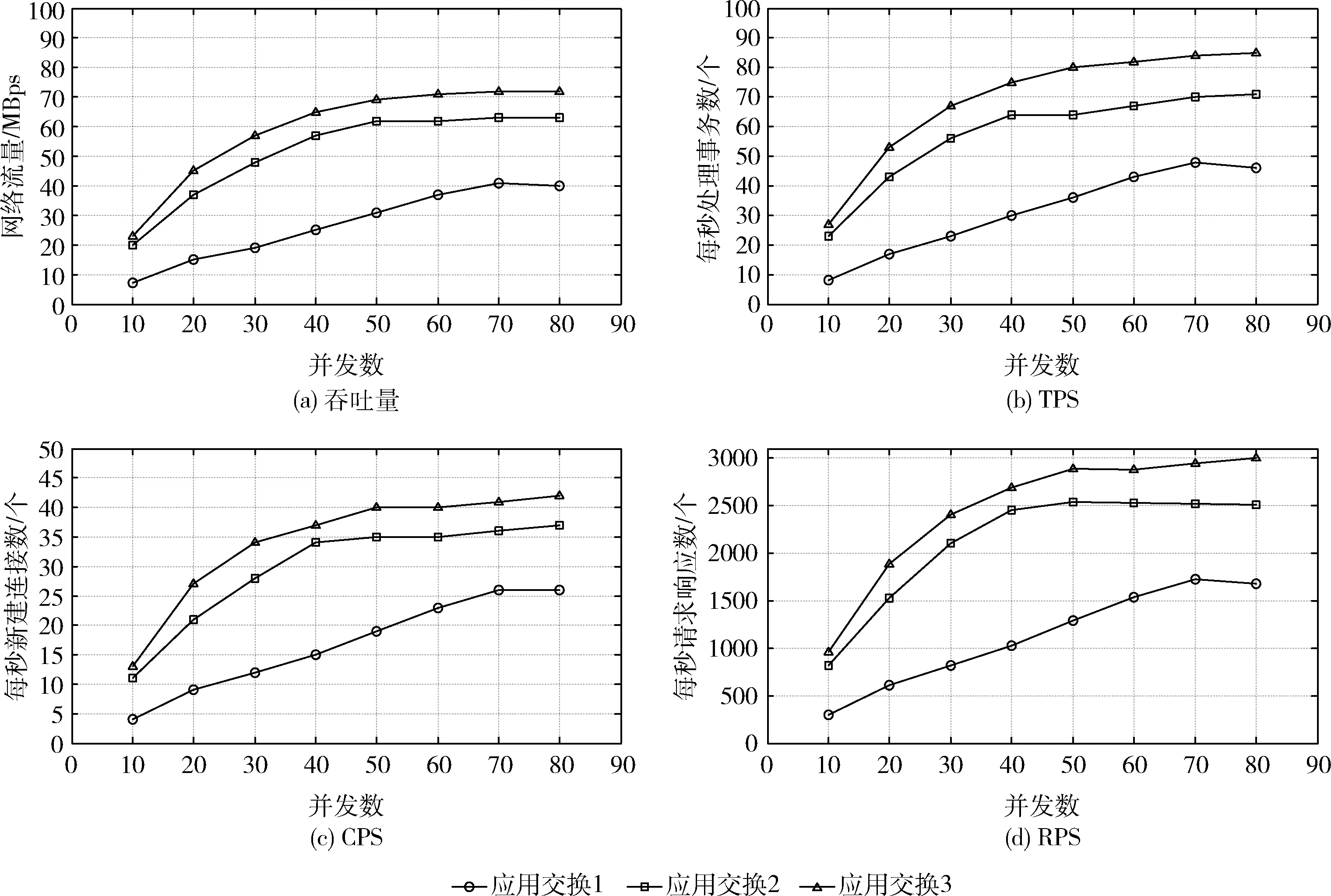
圖8 四層交換性能測試
(2)七層交換性能
七層交換能力,主要指根據網絡數據報文的HTTP頭或Session進行改寫并轉發的能力。由圖9的結果分析可知,3種應用交換下,應用系統的最大吞吐量分別為:30 MBps,52 Mbps,61 Mbps。最大TPS分別為:40 tps,60 tps,71 tps。最大CPS分別為:17 cps,26 cps,38 cps。最大RPS分別為:1427 rps,2211 rps,2547 rps。隨著并發數的增加,應用交換3(計算與交換芯片三線互連架構)的吞吐量、TPS、CPS和RPS的性能均有顯著提高。當并發數達到最大80時,應用交換3相比其它兩種應用交換架構可提升15%以上吞吐量。可見,應用交換3(即基于計算芯片與交換芯片三線互連技術實現的應用交換)系統適用于高帶寬高并發的應用集群領域。
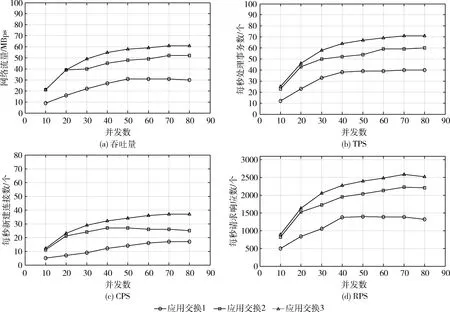
圖9 七層交換性能測試
此外,從理論上分析,相比于四層交換處理,七層交換處理的解析層次更深入,對數據轉發的要求更高,對應用系統的資源消耗更多,其性能普遍比四層交換性能弱。由實驗結果看,對于同一種應用交換系統,當吞吐量增大時,四層和七層的數據轉發的性能差距會變大,當并發數達到最大80時,四層轉發的性能會比七層數據轉發的性能高10%-20%,符合理論預期值。
4 結束語
針對應用交換系統對吞吐量和轉發處理能力的要求,本文在傳統應用交換技術架構的基礎上,提出了一個芯片三線互連的交換體系架構,從測試結果可以看出,該系統能充分利用四七層的網絡帶寬,對應用集群系統在網絡吞吐能力和事務處理能力等性能的提升尤為突出,相比傳統的兩種應用交換技術架構,四層交換性能可提升約12%以上,七層交換性能可提升約15%以上,適用于高帶寬高并發的應用集群領域。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
