地震科普問答中的語義相似度研究
2020-12-24 03:16:24張正霞
山西地震 2020年4期
王 寧,張正霞,羅 勇
(1.山西省地震局,山西 太原 030021;2.太原大陸裂谷動力學國家野外科學觀測研究站,山西 太原 030025)
0 引言
隨著互聯網的發展,電子媒介已超越傳統媒介,成為當今信息傳播的主流方式。地震科普也隨之轉型,通過微信公眾號、微博等多種方式向公眾傳遞科普知識[1-3]。公眾通過搜索、自動問答的方式主動獲取科普知識,成為學習、了解的重要途徑,但根據公眾提出的問題,如何在科普問答庫中找出相似的問答對,給出理想的答案,是其中的關鍵。
問答系統的基本技術路線都是文本比較,包括用戶問題與庫中問題的比較,用戶問題與庫中答案文本的比較等,在技術實現上主要是句子與句子的比較,實質就是計算句子的相似度。因此,句子相似度計算是自動問答系統的關鍵技術,直接影響自動問答系統的性能[4]。由于其在自然語言處理領域具有非常廣泛的應用,對其相關研究也一直在進行。根據其特點,將句子相似度計算方法分為字面匹配相似度、語義相似度和結構相似度三種類型[5]。字面相似度一般采用最小編輯距離、Jaccard距離等方法;語義相似度包括詞頻-逆向文檔頻率(Term Frequency-inverse Document Frequency,TF-IDF)向量方法、余弦相似度等;結構相似度計算的關鍵在于分析句子的句法結構。
在一般應用中,只計算句子的語義相似度就能夠達到要求。該文在地震科普問答庫的基礎上,分別研究TF-IDF向量方法、余弦相似度、改進的編輯距離等方法在地震科普問答中的應用結果,并根據防震減災術語制作自定義詞典,研究該詞典在算法中的有效性。
1 相似句檢索的原理及方法
問答系統根據用戶輸入的問題對問答庫進行檢索并返回檢索結果,其核心技術在于檢索與輸入問題相似的句子,檢索過程分為三步,如圖1所示。首先,對輸入句進行分詞,分詞結果的準確性對后續過程有一定的影響;其次,提取相似句子候選集,即從句子庫中找出與輸入句相似的句子組成集合,可以提高相似句檢索的效率;最后,將輸入句與候選集中的句子進行相似度計算,選擇相似度最大的句子作為最終結果。

圖1 相似句檢索過程Fig.1 The process of similar sentence retrieval
1.1 相似句子候選集選擇
如果一個句子中與輸入句相同或者同義的詞越多,兩個句子相似的可能性就越大,即該句的權重越大。因此,采用倒排文檔索引[6]的方法對問題庫進行檢索,按照句子權重由大到小的順序選擇候選集。
1.2 句子相似度計算
由于只計算句子的語義相似度就能滿足研究所需,選取TF-IDF向量方法、余弦相似度、改進的編輯距離等相似度計算方法,研究其在地震科普問答中的應用。
(1) 詞頻-逆向文檔頻率(Term Frequency-inverse Document Frequency,TF-IDF)向量方法。
TF-IDF是一種用于信息檢索(information retrieval)與文本挖掘(text mining)的常用加權技術。其主要思想是:若某個詞或者短語在某個句子中出現的頻率高,并且在其他句子中很少出現,則認為該詞或者短語可以作為區別該句與其他句子的特征[7]。
TF-IDF = TF * IDF,
(1)
式中:TF表示詞條(關鍵字)在文本中出現的頻率;IDF是一個詞語普遍重要性的度量。

(2)
式中:nij表示詞i在該文本j中出現的次數;分母表示文本j中的總詞數。

(3)
式中:分子表示問題庫中的句子總數;分母表示包含詞語i的句子數,如果該詞語不在問題庫中,就會導致分母為0,因此一般情況下分母加1。
(2) 余弦相似度算法。
余弦相似度[8]是用向量空間中兩個向量夾角的余弦值作為衡量兩個個體間差異大小的度量。余弦值越接近1,表明夾角越接近0度,表示兩個向量越相似。計算過程如下:
句子A:斷層是什么意思?
句子B:什么是斷層?
第一步:分詞。
句子A: 斷層 是 什么 意思?
句子B: 什么 是 斷層?
第二步:列出所有詞。
斷層 是 什么 意思
第三步:計算詞頻。
句子A: 斷層1,是1,什么1,意思1。
句子B: 斷層1,是1,什么1,意思0。
第四步:得出詞頻向量。
句子A:[1,1,1,1]
句子B:[1,1,1,0]
第五步:計算兩個句子的向量余弦值。
(4)
根據式(4)得到句子A與句子B的向量余弦值為0.85。
(3) 基于編輯距離的算法。
編輯距離是量化不同的字符串如何通過最小數目的操作進行轉換[9],編輯操作有“插入”“刪除”“替換”三種。例如:
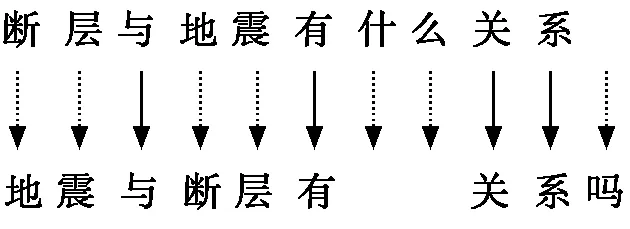
按照傳統的以字為單位計算編輯距離的方法,可以看出這例句中兩個句子的編輯距離為7。但是,在漢字中,單個的字往往是不具備意義的,詞語之間的替換代價不僅局限于字面上,如“喜歡”和“愛”在字面上替換代價大,但在語義層面替換代價很小。因此,車萬翔等人[10]提出了改進的編輯距離算法,以詞語代替字作為單位來計算編輯距離。
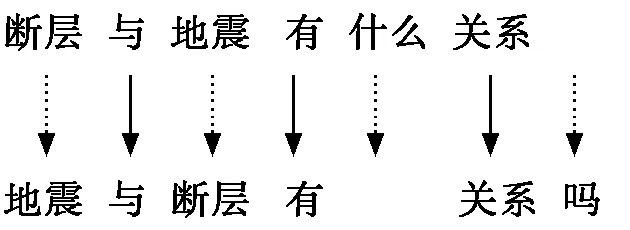
按照改進的編輯距離算法,計算出這兩句話的編輯距離為4。因此,該文選用改進的編輯距離算法進行實驗。
以上三種方法中,若候選集中多條句子的權重或者編輯距離相同,則選擇句子長度與輸入句最相近的句子作為最終結果。
2 實驗結果與分析
2.1 實驗語料與評價標準
趙臻等人[11]曾采用初始數據集結合百度知識庫的方法構建問題庫,筆者借鑒此方法,選用《地震與防震減災知識200問答》[12]中的問題與百度知道地震專題中的問題作為初始數據集T。依次選取T中的問句作為百度知道的查詢條件,選擇查詢結果中的前5個標題,篩除相同結果或者無查詢結果的句子,最終共采集340條句子作為數據集TS。對TS中的問句與數據集T中的問句依次進行相似度計算。
為了客觀評價算法的整體性能,采用準確率(precision)、召回率(recall)、F值來對算法進行評價。其中,F值是綜合評價指標,為準確率和召回率的調和平均值。當F值較高時,表明實驗方法比較有效。


2.2 實驗結果對比
在實驗語料的基礎上,對TF-IDF算法、余弦相似度算法、改進的編輯距離算法進行對比實驗,結果如表1所示。

表1 3種相似度算法的性能比較Table 1 Performance comparison of three similarity algorithms
表1的實驗結果表明,在地震科普問答的語義相似度檢索中,TF-IDF算法比其他兩種算法取得的效果好,準確率、召回率和F值均高于其他兩種算法。
2.3 自定義詞典對算法的影響
句子相似度算法都是以詞為基礎進行計算,分詞結果準確與否直接影響相似度計算的結果。在地震科普問答中,涉及大量的專有名詞,若分詞工具的詞庫中無該專有名詞,就會導致在分詞時被分開,改變原來的詞義。如:
“地震動的衰減關系有哪些?”—>“地 震動 的 衰減 關系 有 哪些 ?”
若分詞工具的詞庫中包含專有名詞A,不包含專有名詞B,且A和B之間存在包含關系,也可能會導致分詞結果不恰當。如:
“震中距指什么”—>“震中 距指 什么”
鑒于以上情況,在分詞工具中加入自定義詞典,保證較高的準確率。該研究收錄中華人民共和國國家標準《防震減災術語第一部分:基本術語》和《防震減災術語第二部分:專業術語》及一部分特殊詞語,構成防震減災術語詞典,共490個詞。將該詞典運用到分詞工具中,分詞結果如下所示:
“地震動的衰減關系有哪些?”—>“地震動 的 衰減 關系 有 哪些 ?”
“震中距指什么”—>“震中距 指 什么”
在加入自定義詞典的分詞基礎上,運用TF-IDF算法在相同的語料中進行相似度計算,研究自定義詞典對算法的影響,結果如表2所示。

表2 自定義詞典加入前后TF-IDF算法的性能比較Table 2 Performance comparison of TF-IDF algorithms to add custom dictionaries or not
由表2看出,加入防震減災術語詞典后,準確率提高了1.18%,說明自定義詞典對算法有一定的影響。
2.4 實驗結果分析
上述研究結果表明,在地震科普問答中,TF-IDF算法的F值比余弦相似度算法高2.41%,比編輯距離算法高19.61%,在分詞工具中加入防震減災術語詞典,TF-IDF算法的F值提高了1.21%。
對匹配不正確的句子進行分析可知,有部分句子的候選集中已獲取正確結果,但是最終結果未取到,是由于該研究選取了候選集中權重最大且句長與輸入句最接近的句子作為最終結果,因此會導致選擇錯誤。另外,由于候選集選擇時依賴詞的精確匹配,可能也會導致正確結果的流失,出現匹配錯誤。
3 結語
研究時選取三種句子相似度計算的方法,對比其在地震科普問答語料中的性能,選取具有最優性能的算法,加入防震減災術語詞典,研究其對算法性能的影響。實驗結果表明,TF-IDF算法在地震科普問答中獲得較好的結果,加入防震減災術語詞典可以有效提升算法的性能。
越是相似的句子,就擁有越多相同的詞,因此,為了提高算法的性能,今后可以在候選詞選擇模塊和相似度計算模塊中加入同義詞詞林,以Wordnet或者Hownet作為語義資源,計算句子的語義相似度,以再提高算法的準確率和召回率。
