端到端語音識別研究綜述
2020-12-21 03:44:27郭宗昱劉博吳可欣李姝怡蔣昊軒李云潔
科技風 2020年34期
關鍵詞:深度學習
郭宗昱 劉博 吳可欣 李姝怡 蔣昊軒 李云潔
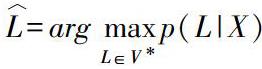
摘?要:語音識別(ASR)是機器學習領域的熱點研究問題。長期以來,隱馬爾可夫模型-高斯混合模型(HMM-GMM)是傳統語音識別主要框架,隨著深度學習的快速發展,DNN模塊取代GMM,語音識別性能有了一定程度的提升。然而,HMM-DNN模型本身受到各種不利因素的限制,而端到端模型(End-To-End ASR)具有流程簡化等優點。因此,端到端模型是語音識別未來的重要研究方向。本文首先介紹傳統語音識別的基礎理論;然后介紹了HMM-GMM模型和HMM-DNN模型構架;其次,重點介紹了兩種不同類型的端到端模型的基本原理;通過以上對比研究,最后總結了語音識別存在的問題和未來發展方向。
關鍵詞:語音識別;端到端;深度學習;CTC;注意力機制
1 緒論
因此,ASR的基本工作是建立一個可以準確計算后驗分布p(L|X)的模型。
與基于HMM的模型相比,端到端模型使用單個模型將音頻直接映射到字符或單詞,更易于構建和訓練等優點使其迅速成為大型詞匯連續語音識別研究的熱點。
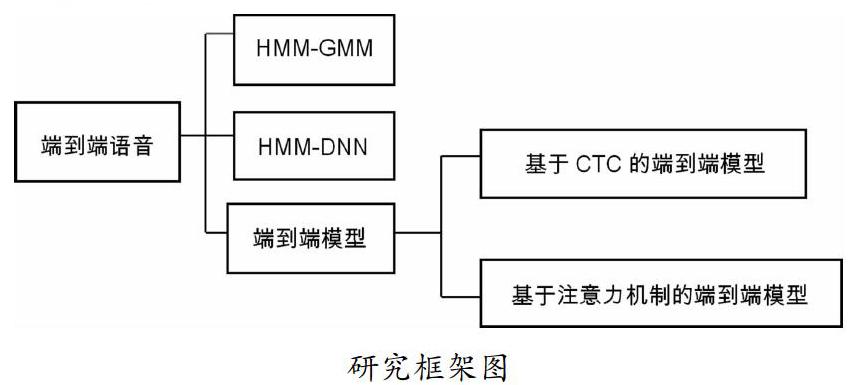
本文的整體框架如下圖所示:分別介紹傳統語音識別模型(HMM-GMM)、基于傳統模型改進的語音識別模型(HMM-DNN)、基于神經網絡的端對端語音識別模型;端到端模型又分別介紹了基于CTC和注意力機制的模型。
2 基于HMM-GMM的語音識別模型
基于HMM的模型可以分為彼此獨立并發揮不同作用的三個部分:聲學模型、發音模型和語言模型。聲學模型P(X|S),從隱藏序列S觀察X的概率,用于對語音輸入和功能序列之間的映射進行建模。發音模型P(S|L),也稱為字典,是為了實現音素(或子音素)到音素之間的映射,建立聲音序列和語言序列之間的聯系。語言模型P(L)由大量語料訓練,使用m-1階馬爾可夫假設生成m-gram語言模型,將字符序列映射到流暢的最終轉錄[1]。HMM-GMM模型是語音識別的通用結構,但隨著深度學習技術的發展,DNN(深度神經網絡)被引入語音識別的聲學建模[2]。與傳統的基于HMM-GMM的聲學模型相比,它的不同點在于用DNN替換了GMM來對輸入語音信號的觀察概率進行建模。其作用是計算HMM狀態的后驗概率,從而取代傳統的GMM輸出概率[3]。在基于HMM的模型中,不同的模塊使用不同的技術并發揮不同的作用。HMM主要用于幀級別的動態時間規整,GMM和DNN用于計算HMM隱藏狀態的發射概率[4]。
3 端到端模型
端到端模型是直接將輸入音頻序列映射到單詞或其他字素序列的系統。大多端到端語音識別模型包括:編碼器,將語音輸入序列映射到特征序列;對齊器,實現特征序列和語言之間的對齊;解碼器,對最終的識別結果進行解碼。該模型與由多個模塊組成的基于HMM的模型不同,它用一個深層網絡替換了多個模塊,實現從聲信號直接映射到標簽序列,大大簡化了語音識別模型的構建和訓練。
3.1 基于CTC的端到端模型
CTC在計算損失時解決了硬對齊問題。對于端到端LVCSR模型,CTC主要克服了數據對齊問題和直接輸出目標轉錄兩個困難,它使用單個網絡結構將輸入序列直接映射到標簽序列,實現端到端語音識別。
CTC過程可以看作兩個子過程:路徑概率計算和路徑聚合。其中最重要的是引入新的空白標簽和中間概念路徑。由于CTC的計算過程相當確定,因此大多數基于CTC的ASR都主要研究如何有效地構建神經網絡聲學模型。
(1)模型結構。CTC的一大優勢是消除了數據分段對齊的必要性。Li等人提出了由CTC為LVCSR任務訓練的端到端模型[5]。他們設計了一個三層網絡,第一層是78維前饋層,第二層是含有120個記憶體的LSTM層,第三層是含有27個記憶體的LSTM層。結果表明,增加網絡的深度和隱藏單元的數量可以有效地提高識別效果[6]。關于結構,Song等人引入CNN并將其與RNN結合用于ASR[7],設計的結構包括了四個CNN層。另外,還有人設計了一個僅使用CNN和CTC的模型[8]。該模型使用十層CNN和三層完全連接,并在時間和頻率維度上執行卷積操作。結果表明,更深的模型可以獲得更好地識別效果。關于網絡深度,Amodei等人使用CTC訓練具有九層(其中七層是RNN)的網絡,該模型可以在某些任務上勝過人類[9]。Zweig等人使用CTC訓練了一個由九層雙向RNN組成神經網絡,其隱藏單元維數為1024,在各自的數據集上獲得最佳結果[10]。綜上所述,網絡模型的結構和深度趨勢并不意味著更深、更復雜的網絡在任何情況下都可以取得更好的結果。
(2)大規模數據訓練。復雜的深度模型需要大量的數據進行訓練以進行語音識別。為了有效地訓練一個五層網絡模型,Hannun等人使用超過7000h的干凈語音數據,加上合成噪聲語音,總共超過100,000小時的語音數據[2]。借助大規模數據集,他們在自己構建的嘈雜數據集上取得了最佳結果,勝過了Apple,Google等多家商業公司。Amodei等人使用11,940h的英語語音和9400h的中文語音數據來訓練九層網絡模型,最終在常規中文識別中達到了高于人類的水平[9]。
(3)語言模型。語言模型對于提高基于CTC的端到端ASR的性能非常有幫助。Graves等人的研究[11]表明,在WSJ數據集上,僅RNN+CTC模型單詞錯誤率(WER)為30.1%。若引入單詞詞典,WER為24%。若引入三元語法語言模型(LM),WER降至8.7%。語言模型對于在單詞水平上取得良好的表現發揮著至關重要的作用。受到這些啟發,Li,Maas,Hwang等人的研究也將語言模型與CTC集成在一起[6][12][13]。結果表明,語言模型可以大大提高識別的準確性,對于具有復雜結構和大量訓練數據的模型也有顯著效果。
3.2 基于注意力的端到端模型
基于注意力的端到端模型可以分為三個部分:編碼器,對齊器和解碼器,主要是對齊器部分使用了注意力機制。其中編碼器起聲學模型的作用,與HMM-DNN混合模型相同,因此面臨著相同的問題。在相同的解決方案下,它還會出現新的問題。
(1)基于注意力端到端模型框架。該模型由編碼網絡、解碼網絡和注意力子網絡三個模塊組成,編碼網絡和解碼網絡均包含循環神經網絡單元。編碼網絡為深層循環神經網絡,目的是學習和挖掘語音特征序列的上下文關聯信息,從原始特征中提取高層信息,增強特征的區分度和表征能力。注意子網絡的主體是含有單隱含層的多層感知器,網絡輸入是編碼網絡的輸出和解碼網絡的隱含層單元狀態,輸出是它們的關聯度分數。解碼網絡由單層循環神經網絡和maxout網絡連接而成。它先根據注意力子網絡得到注意力系數對所有編碼網絡的輸出加權求和得到目標向量,再將目標向量作為網絡輸入,計算輸出序列每個位置上各個音素出現的后驗概率[14]。
(2)網絡結構。為了提高編碼能力,基于注意力的模型中的編碼器也變得越來越復雜。早期的編碼器基本上位于三層之內[15][16],并逐漸發展為四層[17][18][19]、五層[20][21]、六層[22][23]。使用網絡中的網絡,批處理規范化,殘差網絡,卷積LSTM構建了一個15層編碼器網絡[24],最終在不使用字典或語言模型的情況下,在華爾街日報數據集上實現了10.53%的WER。
(3)基于注意力的工作。從功能上注意力機制可以分為以下三種類型:①基于內容:僅使用輸入特征序列F和先前的隱藏狀態su-1計算每個位置的權重。但它存在相似性語音片段問題。②基于位置:在每個步驟中,先前的權重αu-1被用作位置信息,以計算當前權重αu。③混合:考慮了輸入特征序列F,先前的權重αu-1和先前的隱藏狀態su-1,使其能夠結合基于上下文和基于位置的注意力的優勢。
4 結語
基于超大語料庫的前提下,端到端模型已經超過了HMM-GMM模型,但其性能仍然低于或僅與使用深度學習技術的HMM-DNN模型相當。為了真正利用端到端模型,至少需要在模型延遲、語言知識學習等方面進行改進。基于HMM-GMM的模型的構建和訓練,同時,經過多年的發展,HMM-GMM模型已達到瓶頸,并且幾乎沒有進一步改進性能的空間。而深度學習的技術推動了HMM-DNN模型和端到端模型的興起和發展,這些模型在某些方面的性能已超越HMM-GMM。端到端模型則具有簡化模型、聯合訓練、直接輸出和無需要強制數據對齊等優點,且學習曲線較為平緩。因此,端到端模型是LVCSR的當前重點,也是未來的重要研究方向。
參考文獻:
[1]Rao,K.;Sak,H.;Prabhavalkar,R.Exploring architectures,data and units for streaming end-to-end speech recognition with RNN-transducer.In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop(ASRU),Okinawa,Japan,16-20 December2017;pp.193-199.
[2]Hannun,A.;Case,C.;Casper,J.;Catanzaro,B.;Diamos,G.;Elsen,E.;Prenger,R.;Satheesh,S.;Sengupta,S.;Coates,A.;et al.DeepSpeech:Scaling up end-to-end speech recognition.arXiv 2014,arXiv:1412.5567.
[3]Lu,L.;Zhang,X.;Cho,K.;Renals,S.A study of the recurrent neural network encoder-decoder for large vocabulary speech recognition.In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association,Dresden,Germany,6-10 September 2015;pp.3249-3253.
[4]Miao,Y.;Gowayyed,M.;Metze,F.EESEN:End-to-end speech recognition using deep RNN models and WFST-based decoding.In Proceedings of the 2015 IEEE Workshop on Automatic,Speech,Recognition,and,Understanding(ASRU),Scottsdale,AZ,USA,13-17December2015;pp.167-174.
[5]Eyben,F.;Wllmer,M.;Schuller,B.;Graves,A.From speech to letters-using a novel neural networ architecture for grapheme based asr.In Proceedings of the 2009 IEEE Workshop on Automatic Speech Recognition & Understanding,Merano/Meran,Italy,13-17 December 2009;pp.376-380.
[6]Li,J.;Zhang,H.;Cai,X.;Xu,B.Towards end-to-end speech recognition for Chinese Mandarin using long short-term memory recurrent neural networks.In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association,Dresden,Germany,6-10 September 2015;pp.3615-3619.
[7]Song,W.;Cai,J.End-to-end deep neural network for automatic speech recognition.Standford CS224D Rep.2015.Available online:https://cs224d.stanford.edu/reports/SongWilliam.pdf(accessed on 14 August 2019).
[8]Zhang,Y.;Pezeshki,M.;Brakel,P.;Zhang,S.;Laurent,C.;Bengio,Y.;Courville,A.Towards End-to-End Speech Recognition with Deep Convolutional Neural Networks.arXiv 2017,[CrossRef].
[9]Amodei,D.;Ananthanarayanan,S.;Anubhai,R.;Bai,J.;Battenberg,E.;Case,C.;Casper,J.;Catanzaro,B.;Cheng,Q.;Chen,G.;et al.Deep speech 2:End-to-end speech recognition in english and mandarin.In Proceedings of the International Conference on Machine Learning,New York,NY,USA,19-24 June 2016;pp.173-182.
[10]Soltau,H.;Liao,H.;Sak,H.Neural Speech Recognizer:Acoustic-to-Word LSTM Model for Large Vocabulary Speech Recognition.arXiv 2017,3707-3711,arXiv:1610.09975.
[11]Graves,A.;Jaitly,N.Towards end-to-end speech recognition with recurrent neural networks.In Proceedings of the International Conference on Machine Learning,Beijing,China,21 June-26 June 2014;pp.1764-1772.
[12]Maas,A.;Xie,Z.;Jurafsky,D.;Ng,A.Lexicon-free conversational speech recognition with neural networks.In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,Denver,CO,USA,31 May-5 June 2015;pp.345-354.
[13]Hwang,K.;Sung,W.Character-level incremental speech recognition with recurrent neural networks.In Proceedings of the 2016 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),Shanghai,China,20-25 March 2016;pp.5335-5339.
[14]龍星延.基于注意力機制的端到端語音識別技術研究.2018,4,24:12-14.
[15]Chan,W.;Lane,I.On Online Attention-Based Speech Recognition and Joint Mandarin Character-Pinyin Training.In Proceedings of the Interspeech,San Francisco,CA,USA,8-12 September 2016;pp.3404-3408.
[16]Chan,W.;Zhang,Y.;Le,Q.V.;Jaitly,N.Latent Sequence Decompositions.In Proceedings of the 5th International Conference on Learning Representations,ICLR 2017,Toulon,France,24-26 April 2017.
[17]Bahdanau,D.;Chorowski,J.;Serdyuk,D.;Brakel,P.;Bengio,Y.End-to-end attention-based large vocabulary speech recognition.In Proceedings of the 2016 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),Shanghai,China,20-25 March 2016;pp.4945-4949.
[18]Watanabe,S.;Hori,T.;Kim,S.;Hershey,J.R.;Hayashi,T.Hybrid CTC/attention architecture for end-to-end speech recognition.IEEE J.Sel.Top.Signal Process.2017,11,1240-1253.[CrossRef].
[19]Chorowski,J.;Jaitly,N.Towards better decoding and language model integration in sequence to sequence models.arXiv 2016,arXiv:1612.02695.
[20]Chiu,C.;Sainath,T.N.;Wu,Y.;Prabhavalkar,R.;Nguyen,P.;Chen,Z.;Kannan,A.;Weiss,R.J.;Rao,K.;Gonina,E.;et al.State-of-the-Art Speech Recognition with Sequence-to-Sequence Models.In Proceedings of the 2018 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),Calgary,AB,Canada,15-20 April 2018;pp.4774-4778.
[21]Prabhavalkar,R.;Sainath,T.N.;Wu,Y.;Nguyen,P.;Chen,Z.;Chiu,C.;Kannan,A.Minimum Word Error Rate Training for Attention-Based Sequence-to-Sequence Models.In Proceedings of the 2018 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),Calgary,AB,Canada,15-20 April 2018;pp.4839-4843.
[22]Hayashi,T.;Watanabe,S.;Toda,T.;Takeda,K.Multi-Head Decoder for End-to-End Speech Recognition.arXiv 2018,arXiv:1804.08050.
[23]Weng,C.;Cui,J.;Wang,G.;Wang,J.;Yu,C.;Su,D.;Yu,D.Improving Attention Based Sequence-to-Sequence Models for End-to-End English Conversational Speech Recognition.In Proceedings of the Interspeech ISCA,Hyderabad,Indian,2-6 September 2018;pp.761-765.
[24]Zhang,Y.;Chan,W.;Jaitly,N.Very deep convolutional networks for end-to-end speech recognition.In Proceedings of the 2017 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),New Orleans,LA,USA,5-9 March 2017;pp.4845-4849.
項目基金:空中交通管理創新創業實踐基地(項目編號:202010059083)
作者簡介:郭宗昱(2000—),女,漢族,湖南人,本科,端到端語音識別;吳可欣(2000—),女,漢族,湖北人,本科,端到端語音識別;李殊儀(2000—),女,漢族,云南人,本科,端到端語音識別;蔣昊軒(2001—),男,漢族,四川人,本科,端到端語音識別;李云潔(1998—),男,漢族,云南人,本科,端到端語音識別。
通訊作者:劉博(1985—),男,漢族,陜西人,碩士,中級,空中交通管理、機器學習。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
