雙模態(tài)Logistic Regression及其應(yīng)用
2020-12-14 10:21:34孔前進(jìn)王世勛孫東山翟怡星
計(jì)算機(jī)應(yīng)用與軟件 2020年12期
吳 蕊 孔前進(jìn) 王世勛,2* 孫東山 翟怡星
1(河南師范大學(xué)計(jì)算機(jī)與信息工程學(xué)院 河南 新鄉(xiāng) 453007)2(河南師范大學(xué)智慧商務(wù)與物聯(lián)網(wǎng)技術(shù)河南省工程實(shí)驗(yàn)室 河南 新鄉(xiāng) 453007)
0 引 言
如今,智能手機(jī)等移動(dòng)終端設(shè)備已十分普及,多媒體數(shù)據(jù)已經(jīng)成為人們?nèi)粘I钪械闹匾畔碓础_@些數(shù)據(jù)來源豐富、結(jié)構(gòu)各異、數(shù)量龐大,為了更好地挖掘多源異構(gòu)數(shù)據(jù)中的信息,人們往往使用分類算法來處理這些數(shù)據(jù)。Logistic Regression是一種有效的分類算法,它能夠很好地處理單一模態(tài)數(shù)據(jù)的分類問題。然而在處理這些多源異構(gòu)數(shù)據(jù)時(shí),現(xiàn)有的Logistic Regression不能很好地利用模態(tài)間的語義相關(guān)性,降低了分類性能。基于這個(gè)問題,本文提出可以妥善保存模態(tài)內(nèi)語義信息與模態(tài)間語義相關(guān)性的雙模態(tài)Logistic Regression模型,從而可對(duì)雙模態(tài)數(shù)據(jù)統(tǒng)一建模。先設(shè)計(jì)一個(gè)同時(shí)包含模態(tài)內(nèi)損耗與模態(tài)間損耗的目標(biāo)函數(shù),再用梯度下降法交替地對(duì)各個(gè)模態(tài)進(jìn)行優(yōu)化求解。具體地,給定一個(gè)模態(tài)的參數(shù)初始值,按照一定策略更新另一模態(tài)的參數(shù),利用更新過的參數(shù)再更新前一個(gè)模態(tài)的參數(shù),從而迭代地交替更新不同模態(tài)的參數(shù)。當(dāng)?shù)Y(jié)束之后,利用Sigmoid函數(shù)將最優(yōu)預(yù)測(cè)器所產(chǎn)生的邊緣轉(zhuǎn)換成語義概念類的后驗(yàn)概率,進(jìn)而完成雙模態(tài)數(shù)據(jù)的二分類與檢索任務(wù)。
1 相關(guān)工作
許多學(xué)者利用分類算法解決了實(shí)際問題,并根據(jù)具體情況改進(jìn)了分類算法。為了實(shí)現(xiàn)對(duì)短文本的分類,王楊等[1]提出了一種基于支持向量機(jī)的分類模型。為了提高分類精度;周緒達(dá)[2]利用KNN算法提出了一種識(shí)別算法,該算法能實(shí)現(xiàn)中文手寫數(shù)字識(shí)別。此外,李佳燁等[3]提出了一種加權(quán)K近鄰?fù)镀狈诸惙椒ǎ摲椒▽?duì)樣本數(shù)據(jù)集的近鄰加上合適的權(quán)值因子,并保持了傳統(tǒng)多數(shù)投票分類的簡單性。相對(duì)于上述算法,Logistic Regression分類算法因其原理簡單而被廣泛應(yīng)用。文獻(xiàn)[4]利用Logistic Regression方法訓(xùn)練數(shù)據(jù),進(jìn)而預(yù)測(cè)樣例的類標(biāo)簽;文獻(xiàn)[5]利用Logistic Regression方法求后驗(yàn)概率。在將二分類Logistic Regression推廣至多分類Logistic Regression的問題上,學(xué)者們也做了相應(yīng)的工作。通過提前為分類集設(shè)定結(jié)果值列,基于HBase的多分類邏輯回歸算法[6]利用塊批量梯度下降法得出每個(gè)分類的回歸系數(shù),從而實(shí)現(xiàn)了多分類。李慧民等[7]利用多分類Logistic Regression方法建立舊工業(yè)建筑再生模式選擇模型。Lin等[8]將核Logistic Regression應(yīng)用于哈希函數(shù),進(jìn)而更好地實(shí)現(xiàn)從特征到哈希碼的非線性投影。當(dāng)數(shù)據(jù)類別不平衡時(shí),周瑜等[9]在多元Logistic Regression中定義一個(gè)新的似然函數(shù),從而提高分類性能。王鵬[10]利用核函數(shù)方法擴(kuò)展邏輯回歸模型,從而提高了分類性能。但上述Logistic Regression只能解決單一模態(tài)數(shù)據(jù)分類問題,無法直接處理多模態(tài)數(shù)據(jù)。多模態(tài)數(shù)據(jù)具有低層特征異構(gòu)、高層語義相關(guān)的特點(diǎn)[11]。傳統(tǒng)的Logistic Regression在處理多模態(tài)數(shù)據(jù)時(shí)只考慮了模態(tài)內(nèi)信息,沒有考慮模態(tài)間的語義相關(guān)性,這會(huì)影響到分類效果。為此提出同時(shí)包含模態(tài)內(nèi)信息與模態(tài)間語義相關(guān)性的雙模態(tài)Logistic Regression模型。
多模態(tài)數(shù)據(jù)包括語義相關(guān)信息,很多專家學(xué)者在挖掘多模態(tài)數(shù)據(jù)中的語義信息與建立分類模型方面做出了不懈的努力。通過設(shè)計(jì)一種多核模糊粗糙模型,張靈均[12]對(duì)多模態(tài)數(shù)據(jù)屬性進(jìn)行約簡,實(shí)現(xiàn)對(duì)數(shù)據(jù)集的粗糙分類。此外,葉婷婷[13]首先對(duì)每個(gè)模態(tài)數(shù)據(jù)訓(xùn)練一個(gè)相應(yīng)的線性回歸模型,然后聯(lián)合地選擇多模態(tài)數(shù)據(jù)的共同特征,最后利用多核SVM的方法實(shí)現(xiàn)對(duì)多模態(tài)數(shù)據(jù)的分類。在處理多模態(tài)數(shù)據(jù)類別不平衡問題時(shí),楊楊[14]劃分了不同模態(tài)數(shù)據(jù)的強(qiáng)弱,并提取弱模態(tài)數(shù)據(jù)的最具有判別分析子空間,從而獲得較好的強(qiáng)模態(tài)數(shù)據(jù)的預(yù)測(cè)性能。王世勛[15]提出了包含模態(tài)內(nèi)損耗和模態(tài)間損耗的多模態(tài)多分類Boosting目標(biāo)函數(shù),并使用梯度下降法交替地求解每一種模態(tài)的最優(yōu)預(yù)測(cè)器,實(shí)現(xiàn)了對(duì)多模態(tài)數(shù)據(jù)的多分類。此外,多模態(tài)分類可對(duì)跨模態(tài)檢索提供技術(shù)支持[16-17]。
2 單模態(tài)Logistic Regression
已標(biāo)注的數(shù)據(jù)集為(X,H)={(x1,h1),(x2,h2),…,(xn,hn)},其中:X表示數(shù)據(jù)集;H表示語義詞匯表;n是數(shù)據(jù)集的大小;hi∈{+1,-1}是第i個(gè)樣本的標(biāo)簽。m維特征向量(xi1,xi2,…,xim)是從已標(biāo)注的數(shù)據(jù)集中獨(dú)立抽取的樣本數(shù)據(jù),若要判斷其是否屬于某一類l,則只有兩種情況:xi屬于l類或者不屬于l類。w表示特征向量的參數(shù),Logistic Regression通過判別評(píng)分值的符號(hào)預(yù)測(cè)標(biāo)簽未知的樣本。若評(píng)分值符號(hào)為正,該組數(shù)據(jù)屬于第l類,否則不屬于第l類。通過構(gòu)造損失函數(shù)求解參數(shù)w。為提高模型的泛化性能,可在損失函數(shù)后加上正則項(xiàng),表達(dá)式[8]為:
(1)
式中:λ是正則項(xiàng)系數(shù)。
對(duì)于無約束優(yōu)化問題,可利用梯度下降法求解特征向量參數(shù)w。對(duì)于給定的無標(biāo)簽測(cè)試樣本x,可根據(jù)以下的預(yù)測(cè)器判斷其是否屬于某語義類。
φ=sgn(xwT)
(2)
單模態(tài)Logistic Regression在多個(gè)模態(tài)數(shù)據(jù)上的分類精度并不高,這是因?yàn)樗鼪]有考慮多模態(tài)數(shù)據(jù)間的語義相關(guān)性。此外,對(duì)不同模態(tài)的數(shù)據(jù)只能分別建模并訓(xùn)練參數(shù)。若將單模態(tài)Logistic Regression推廣到雙模態(tài)Logistic Regression,也許能提高分類的性能。
3 雙模態(tài)Logistic Regression
3.1 構(gòu)造模型

(3)
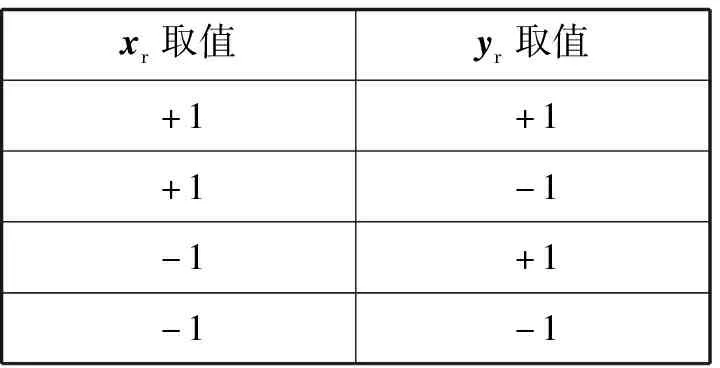
表1 兩種模態(tài)的預(yù)測(cè)情況組合
為尋找不同模態(tài)的最優(yōu)參數(shù),定義風(fēng)險(xiǎn)函數(shù)如下:
R[wt,wp]=J1(wt)+J2(wp)+J3(wt,wp)
(4)
其中:
(5)
(6)
對(duì)于式(5),當(dāng)k=1時(shí),zi代指X的一個(gè)樣本,hi表示其相應(yīng)的標(biāo)簽,w表示文本特征參數(shù);當(dāng)k=2時(shí),zi代指Y的一個(gè)樣本,hi表示其相應(yīng)的標(biāo)簽,w表示圖像特征參數(shù)。
3.2 求 解
通常,梯度下降法可用于無約束優(yōu)化問題的求解。固定文本特征的參數(shù),式(4)中風(fēng)險(xiǎn)函數(shù)關(guān)于圖像特征參數(shù)的一階偏導(dǎo)數(shù)(其中▽表示梯度)為:
(7)
其中:
(8)
(9)
(10)
利用梯度下降法迭代地更新圖像特征的參數(shù):
(11)
其中:
(12)
式中:α0為初始步長;αj為第j次迭代的步長。隨著迭代次數(shù)逐漸增大,步長逐漸減小,從而使梯度收斂。
同樣地,固定圖像特征向量的參數(shù),式(4)中風(fēng)險(xiǎn)函數(shù)關(guān)于文本特征參數(shù)的一階偏導(dǎo)為:
(13)
(14)
(15)
(16)
利用梯度下降法迭代地更新文本特征的參數(shù):
(17)
對(duì)每一個(gè)模態(tài)輪流地求解,可以得到文本與圖像的特征參數(shù)。給出任意未知標(biāo)簽的測(cè)試樣本q,可通過如下的預(yù)測(cè)器來判斷其是否屬于某一類:
(18)
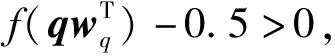
3.3 算法描述
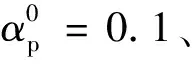
算法1雙模態(tài)LR

“ABB矢志與全中國的客戶一起共創(chuàng)數(shù)字化未來。扎根中國,我們?cè)谥袊幕A(chǔ)設(shè)施發(fā)展中扮演了重要角色,同時(shí)一直致力于科技創(chuàng)新領(lǐng)域的推廣和投資。”ABB集團(tuán)首席執(zhí)行官史畢福表示。“今天,我們運(yùn)用領(lǐng)先的ABB AbilityTM數(shù)字化解決方案和服務(wù),幫助能源、工業(yè)、交通與基礎(chǔ)設(shè)施領(lǐng)域的客戶充分發(fā)掘大數(shù)據(jù)的優(yōu)勢(shì)來提升生產(chǎn)力,增強(qiáng)創(chuàng)新力,提升核心競(jìng)爭力。自2017年在中國發(fā)布ABB AbilityTM以來,我們的數(shù)字化業(yè)務(wù)已實(shí)現(xiàn)雙位增長,完美契合中國十三五計(jì)劃和中國制造2025中謀劃的重點(diǎn)產(chǎn)業(yè)。自去年在中國發(fā)布ABB AbilityTM以來,ABB中國的數(shù)字化業(yè)務(wù)已實(shí)現(xiàn)翻番。”
輸出:wp,wt。
1.初始化:迭代次數(shù)j=0,文本參數(shù)與圖像參數(shù)wt=0,wp=0
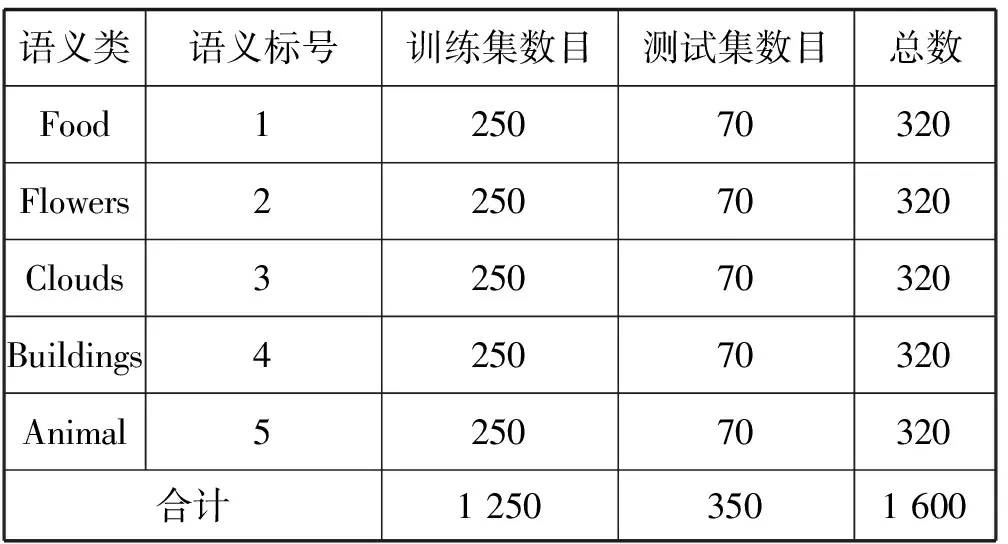
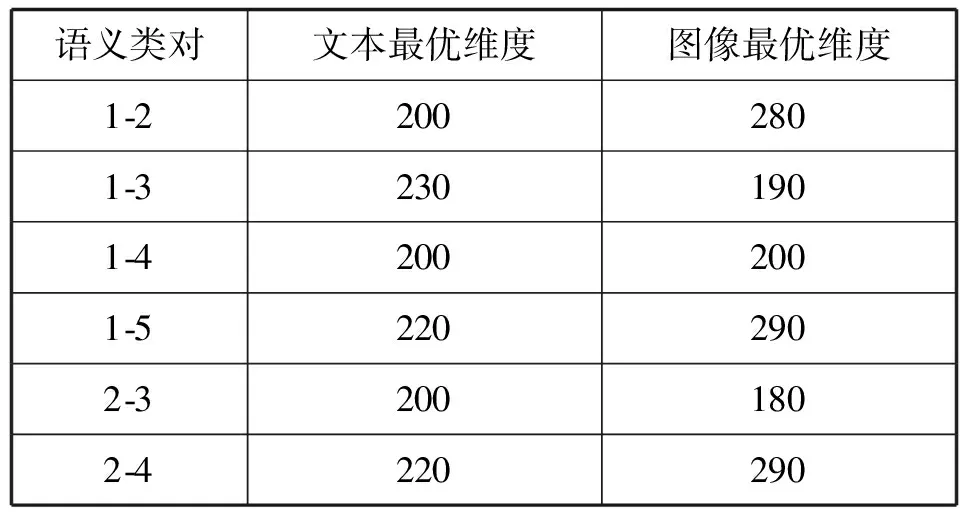
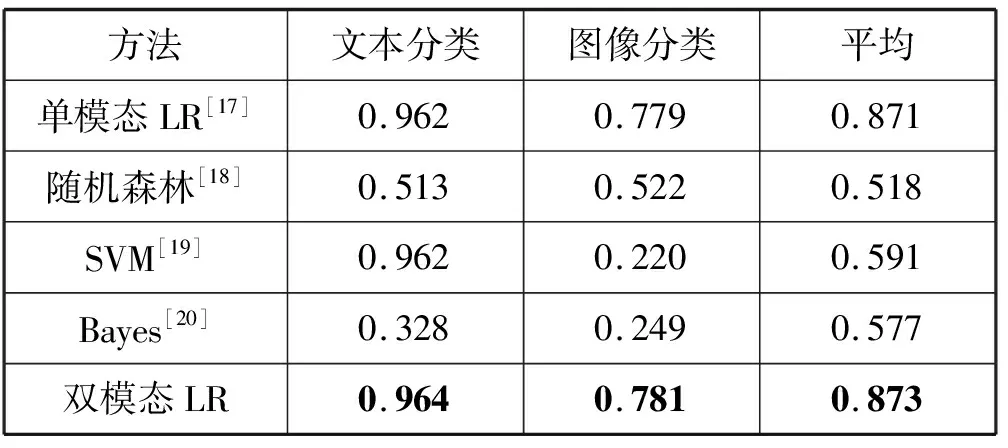
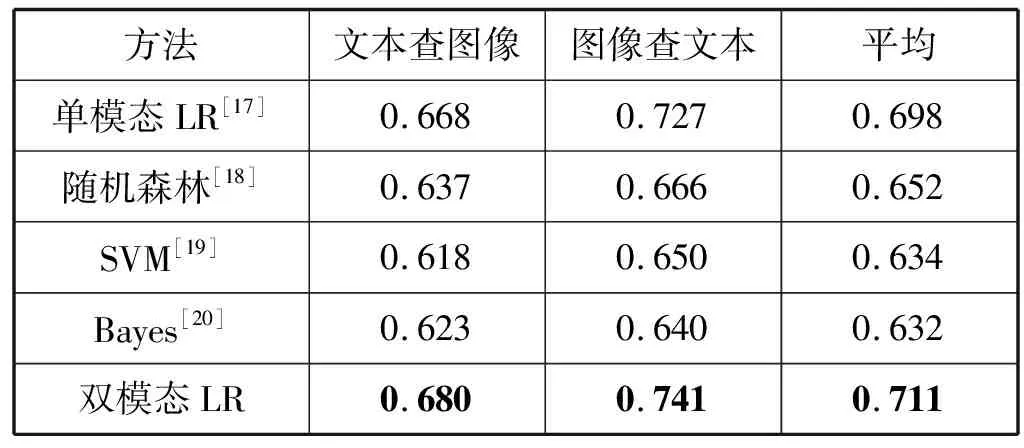
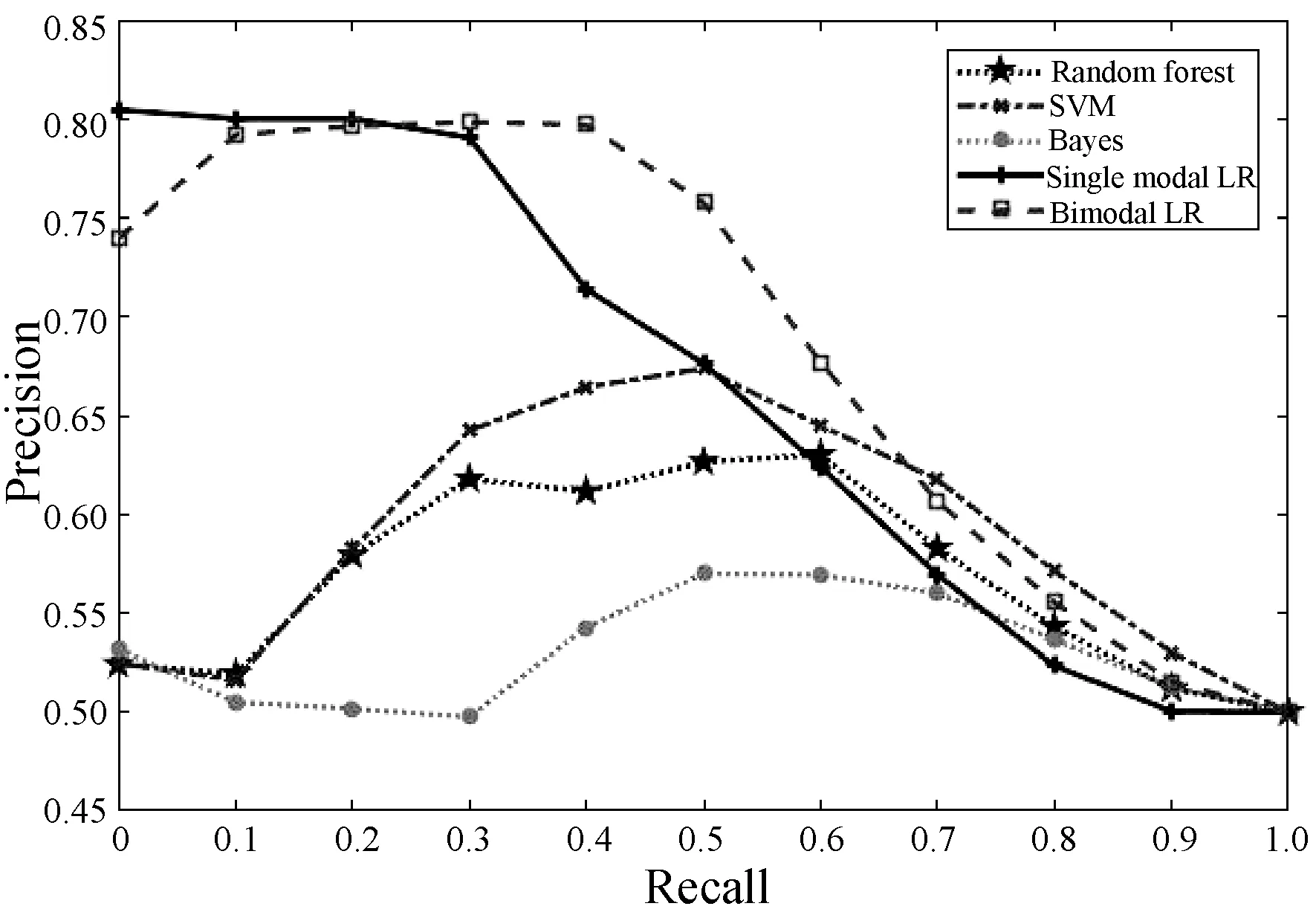
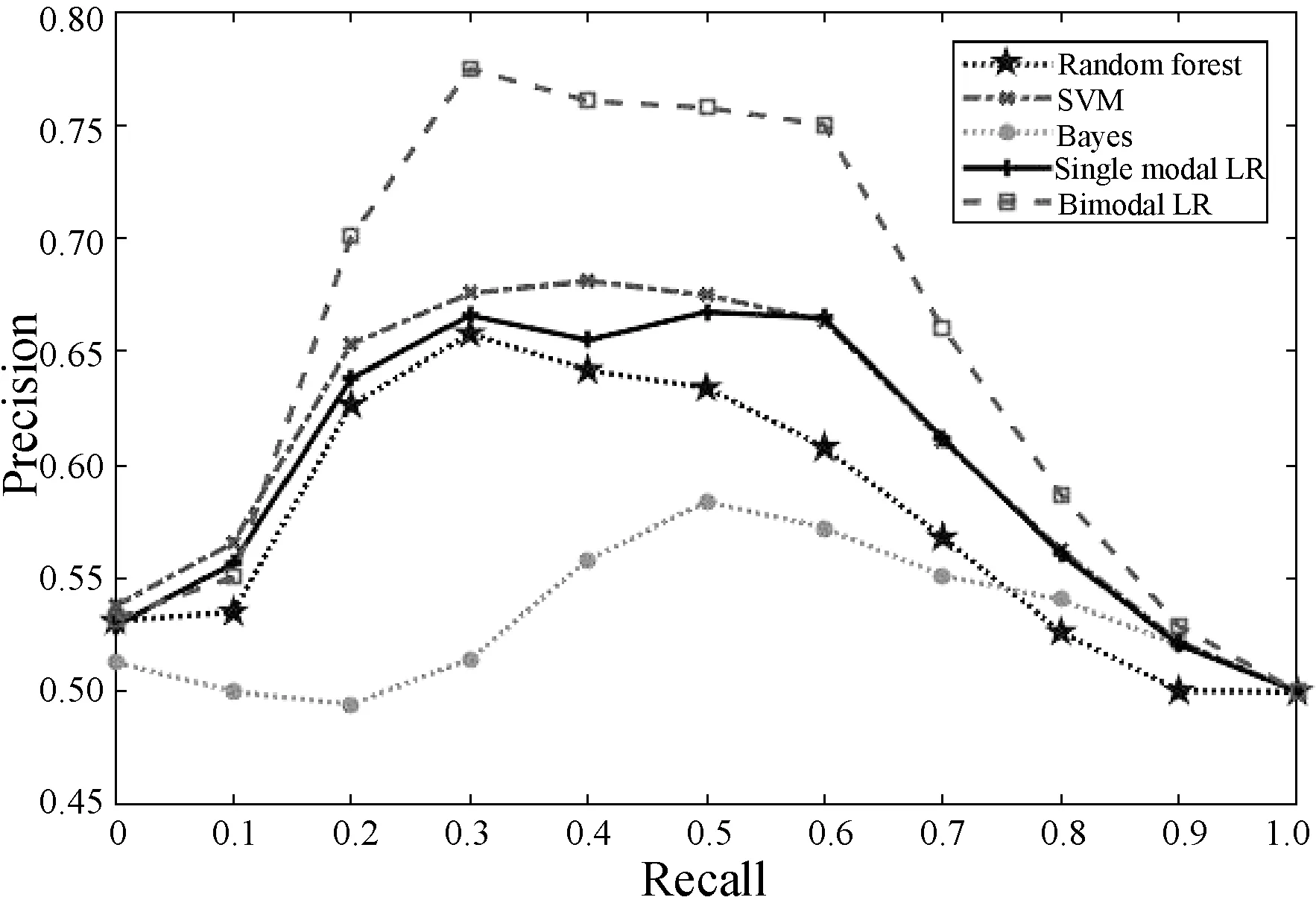
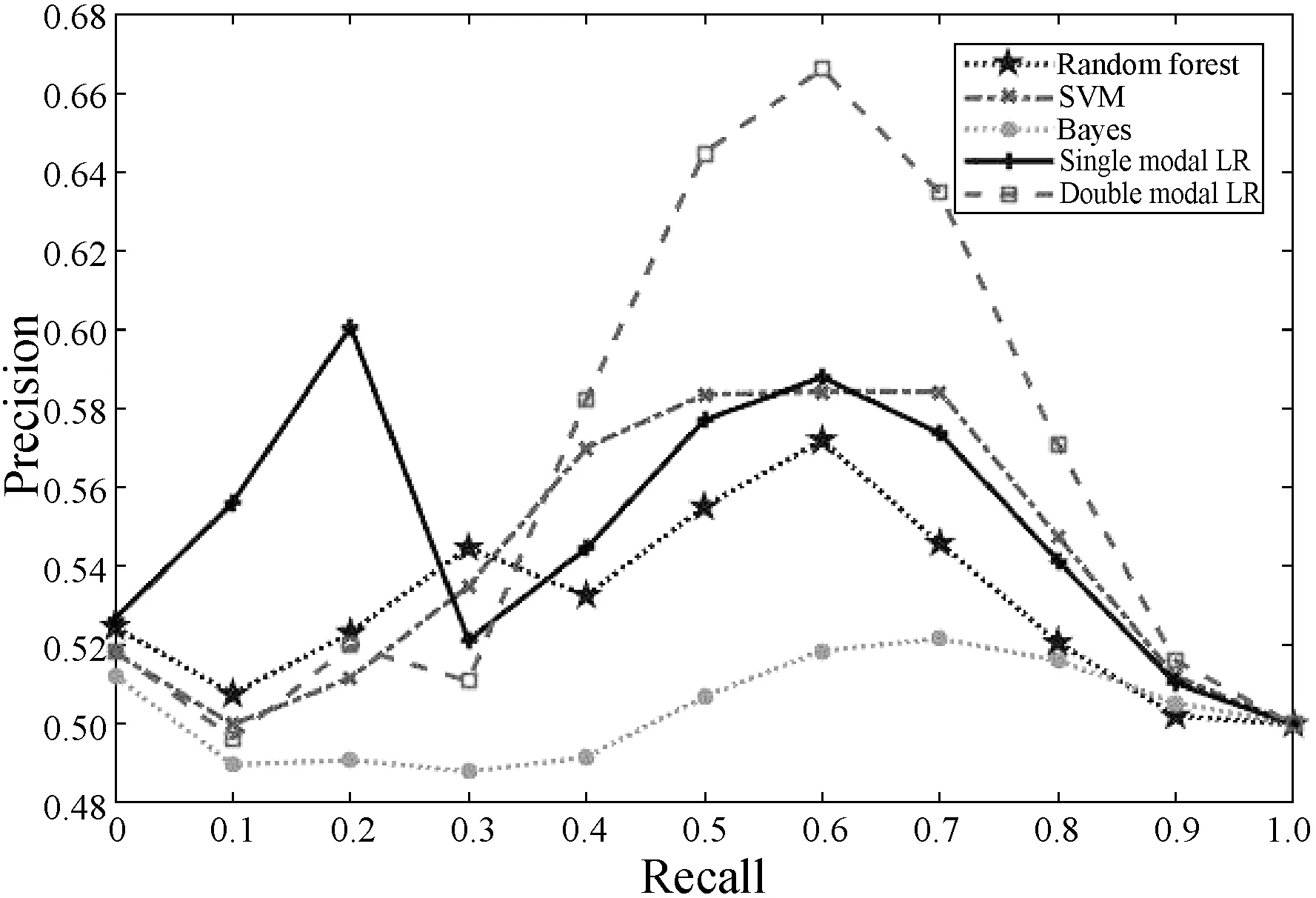
2.Whilej 8.j=j+1 9.End while NUS數(shù)據(jù)集的來源是Flickr上的圖像與標(biāo)注,該數(shù)據(jù)集最初包含269 648幅圖像以及由81個(gè)真實(shí)語義概念所組成的詞匯表。Flickr為所有的圖像均提供了一些有意義的標(biāo)注,因此每一個(gè)圖像與其對(duì)應(yīng)的標(biāo)注構(gòu)成了一個(gè)雙模態(tài)文檔,即圖像文本對(duì)。類似于文獻(xiàn)[15],采用NUS數(shù)據(jù)集中出現(xiàn)頻率次數(shù)隨機(jī)地抽取了1 600個(gè)多模態(tài)文檔,并將這5個(gè)語義概念依次序標(biāo)號(hào)為1、2、3、4、5。每一個(gè)多模態(tài)文檔只有一個(gè)語義概念類,例如 “Food” 和“Flowers”等。每一個(gè)語義概念類包含320個(gè)多模態(tài)文檔,最終的訓(xùn)練集與測(cè)試集分別包含了1 250個(gè)與350個(gè)多模態(tài)文檔,數(shù)據(jù)集概況如表2所示。 表2 NUS數(shù)據(jù)集的概況 表3 NUS文本和圖像數(shù)據(jù)集10個(gè)類對(duì)的最優(yōu)維度 表3中,文本語義類對(duì)1-2最優(yōu)維度為200,表示將文本Food-Flowers組降至200維。實(shí)驗(yàn)表明,表中每一個(gè)維度都能夠保證85%以上的數(shù)據(jù)信息,并且能夠很好地檢索樣本數(shù)據(jù),這是因?yàn)榻稻S操作要保證數(shù)據(jù)的可靠性。表3中得到的維度是在能夠保留85%原始信息的前提下的最優(yōu)維度。 先將每組NUS數(shù)據(jù)集降維到表3中對(duì)應(yīng)的維度,再將雙模態(tài)Logistic Regression算法與單模態(tài)Logistic Regression算法、隨機(jī)森林算法、SVM算法、樸素Bayes算法在同一數(shù)據(jù)集上進(jìn)行分類性能和檢索效果的比較。采用AUC指標(biāo)評(píng)價(jià)二分類,AUC可表述模型整體性能。AUC越大,分類器分類效果越好。雙模態(tài)Logistic Regression與其他方法的AUC值如表4所示。 表4 不同方法在NUS數(shù)據(jù)集上的平均AUC 從表4中可得出SVM算法對(duì)于文本數(shù)據(jù)集分類性能較好,然而對(duì)于圖像數(shù)據(jù)集卻遠(yuǎn)遠(yuǎn)沒有雙模態(tài)Logistic Regression方法效果好。結(jié)合文本數(shù)據(jù)集與圖像數(shù)據(jù)集的分類結(jié)果,雙模態(tài)Logistic Regression比單模態(tài)Logistic Regression平均AUC值增長了0.229%。 平均的精度均值MAP是檢索任務(wù)中常用的評(píng)價(jià)指標(biāo),它能夠有效地描述模型的檢索性能。MAP值越大,檢索效果越好。表5中給出雙模態(tài)Logistic Regression等5種方法在NUS數(shù)據(jù)集上的平均MAP值。 表5 不同方法在NUS數(shù)據(jù)集上的平均MAP 可以看出,雙模態(tài)Logistic Regression方法在文本檢索圖像和圖像檢索文本這2個(gè)跨模態(tài)檢索任務(wù)中超過了其他4個(gè)方法,獲得了較好的平均檢索性能。例如,與單模態(tài)Logistic Regression的平均MAP值相比,雙模態(tài)Logistic Regression的平均MAP值為0.711,提高了1.862%。雙模態(tài)Logistic Regression模型同時(shí)考慮了模態(tài)內(nèi)的語義信息和模態(tài)間的語義相關(guān)性,因此,其檢索性能優(yōu)于單模態(tài)Logistic Regression。 此外,比較了各種模型在NUS兩對(duì)數(shù)據(jù)集上的PR曲線,如圖1-圖4所示。可以看出,不管是文本檢索圖像還是圖像檢索文本,在這兩對(duì)數(shù)據(jù)集上,雙模態(tài)Logistic Regression檢索效果都更好。在檢索任務(wù)中,不考慮語義相關(guān)性會(huì)影響檢索的性能,而雙模態(tài)Logistic Regression不僅考慮了模態(tài)內(nèi)的語義信息,還考慮了模態(tài)間的語義相關(guān)性,因此,檢索效果比其他方法要好。 圖1 Clouds vs Animal類對(duì)上圖像查詢文本的PR曲線 圖2 Flowers vs Animal類對(duì)上文本查詢圖像的PR曲線 圖3 Flowers vs Animal類對(duì)上圖像查詢文本的PR曲線 圖4 Clouds vs Animal類對(duì)上圖像查詢文本的PR曲線 在雙模態(tài)Logistic Regression分類方法中,建立一個(gè)同時(shí)包含模態(tài)內(nèi)損耗和模態(tài)間損耗的目標(biāo)函數(shù)。在做檢索任務(wù)時(shí),采用子空間方法,將多模態(tài)數(shù)據(jù)投影到同一個(gè)潛在的語義空間,然后進(jìn)行相似性比較。在NUS數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果表明,雙模態(tài)Logistic Regression方法檢索效果比其他方法好。然而在處理高維度數(shù)據(jù)時(shí),其訓(xùn)練以及測(cè)試所需時(shí)間較大,需要進(jìn)一步改進(jìn)。
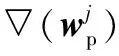

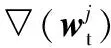

4 結(jié)果分析
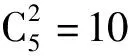
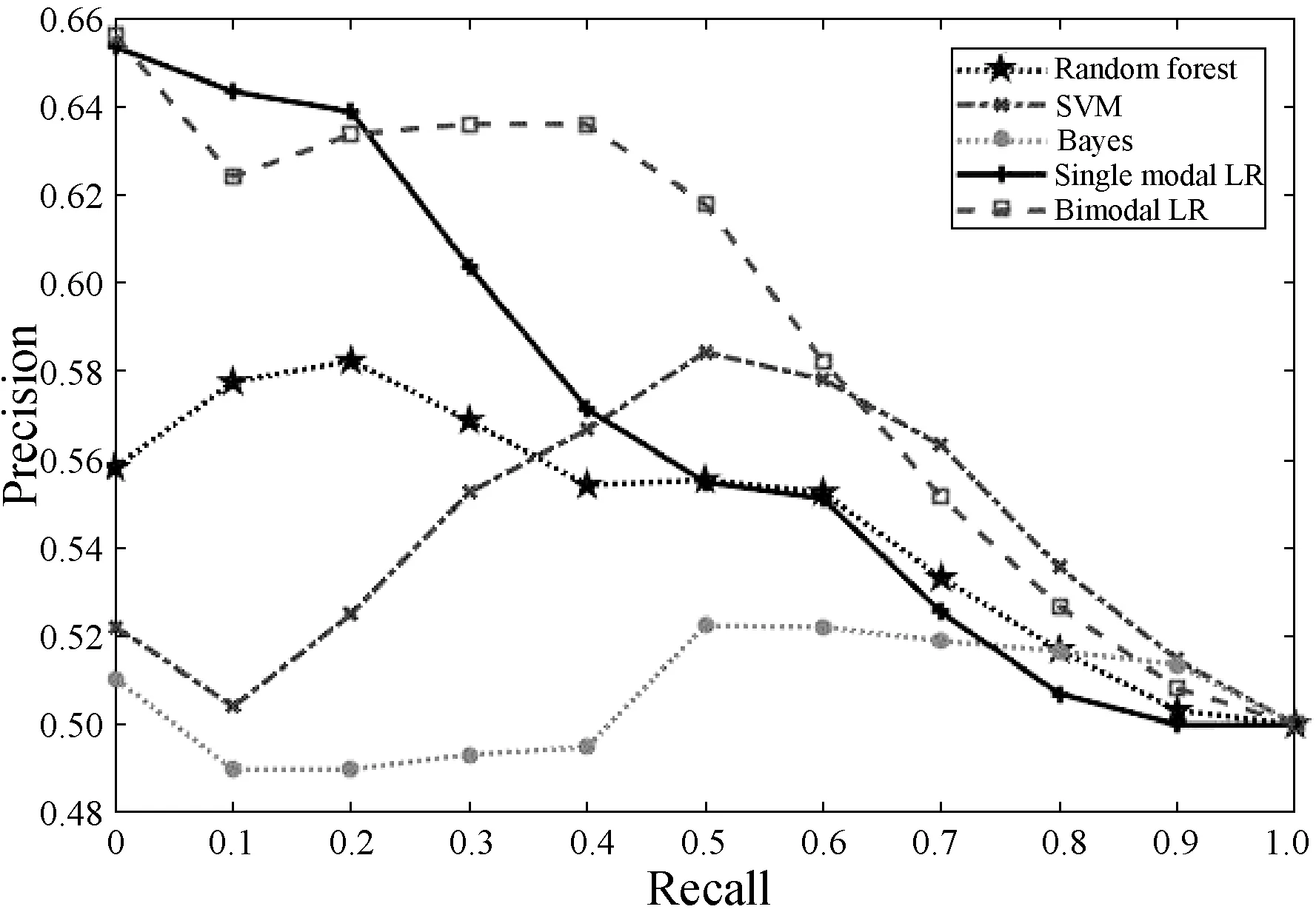
5 結(jié) 語
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
湖北經(jīng)濟(jì)學(xué)院學(xué)報(bào)·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機(jī)學(xué)院學(xué)報(bào)(2015年4期)2015-02-28 14:30:00
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
計(jì)算物理(2014年2期)2014-03-11 17:01:39
