多策略融合的微博數據獲取技術探究
2020-12-09 06:52:48張輝周成祖
網絡安全技術與應用 2020年12期
◆張輝 周成祖
(1.北京市公安局網絡安全保衛總隊北京 100000;2.廈門市美亞柏科信息股份有限公司福建 361008)
社會網點與傳統的互聯網站點有所不同,無論是微博,還是人人網,都是為了滿足用戶的需要運行的。社會網點主要的資源是用戶,一個用于將自己個人的狀態與其他的用戶分享,每個人所呈現出來的狀態有所不同。為微博作為社會網站,其主要的作用是傳播公共信息,其傳播效率是非常高的,可以做到實時傳播,可以使得整個的網絡在短時間內被引爆。所以,微博中信息是非常值得采集的,特別是的用戶信息、用戶所發布的信息以及用戶之間所建立的關系網等等方面的信息都要采集。現在微博技術已經成熟,在平臺上采集數據信息是可行的,確保實驗數據更加集中,所獲得的數據具有權威性[1]。與國外的微博相比較,中國的微博出現時間短,雖然借鑒了國外的一些微博平臺,而且也將一些新技術引進來,但是,API接口沒有完全開放,就會出現信息采集效率不高的問題,導致覆蓋性差不是很好。
1 相關技術的發展情況
移動終端的發展速度不斷加快,我們迎來了大數據時代,各種數據呈現出指數增長態勢,每一條數據中都所涵蓋的信息都有一定的價值,還包括關鍵信息,諸如用戶的虛擬身份賬號、用戶的手機號捆綁身份證號以及銀行卡號等等。如果將這些數據收集起來存儲在數據庫中,就可對用戶的需求全面了解,這也是大數據所發揮的重要價值[2]。在進行數據提取中,由于數據提取方法存在特殊性,特別是自適應匹配和可變滑動窗口的數據,要將其中有價值的數據信息提取出來,就要運用自適應匹配算法,所提取的數據信息才能有較高的精準度,如果采用可變滑動窗口算法,可以比對原始數據,即便不知道屬于那種類型,也可以通過循環比對,直到獲得有價值的數據。采用這種提取方式,被漏提的有價值數據所占有的比例減少,大數據分析定位能力有所提升,對于核心線索能夠快速準確定位。
2 數據提取技術的不足之處以及改進方案
(1)數據提取技術的不足之處
由于原始數據有很多,而且數據的結構非常復雜,從當前的數據提取方法來看,主要是采用模板方法提取或者采用正則表達式提取有價值的數據。這些數據提取方法雖然存在優勢,但是也有諸多的不足。主要體現在如下方面。
其一,在數據的匹配通常應用單一的模板,或者采用正則表達式,進行匹配,如果是在復雜特征場景下的數據,要將有價值信息提取出來是存在一定的難度的。
其二,根據數據分析所獲得的結果對于數據匹配的范圍進行分析,從中能夠認識到,進行匹配的數據往往是每行所呈現出來的原始數據,或者對特定范圍內所讀取的數據匹配,而起局限于原始數據的匹配。
其三,如果數據分布在不同的范圍內,有價值的數據就不能用這種方法提取出來[3]。
(2)改進方案
對于數據提取所存在的不足之處,需要采取有效的措施解決,所采用的提取方法是,采用自適應匹配算法將自適應匹配提取出來,采用可變滑動窗口算法提取可變滑動窗口的數據,可以將更多有價值的數據信息提取出來,可以提高數據提取的準確率,大數據技術得以充分利用起來[4]。
采用這種方法提取數據,不同的數據匹配方法,采用自適應匹配算法可以獲得良好的效果。具體操作中,將類型不同的原始數據動態調整,能夠將更多有價值的數據提取出來,而且保證數據提取的準確率。
屬于不同的數據匹配范圍,在數據提取的時候使用可變滑動窗口算法,可以循環匹配特征引擎以及原始數據內容,將有關的記錄放到內存中,組合附近匹配結果,有價值的數據盡管屬于不同的類型,也可以提取出來[5]。
3 技術方案
(1)提取的數據結構
要提高數據分析效果以及數據提取能力,可以發揮分析程序的作用,使用提取引擎將有價值的數據信息提取出來,將可變滑動窗口充分利用起來,對于所屬類型不同的數據信息提取。在數據提取的過程中,還在特征規則庫和數據塊庫的基礎上展開(表 1:特征規則庫;表2:數據塊庫)。

表1 特征規則庫

表2 數據塊庫
在對數據信息分析的過程中需要按照流程進行,具體分析流程見圖1。原始數據量非常大,要從中將有價值數據信息提取出來,就需要將相應的場景建立起來[6]。本研究所采用的數據提取技術是發揮自適應匹配算法和可變滑動窗口算法,如果數據為已知類型,使用自動匹配提取引擎就可以將有價值信息提取出來, 不僅提取的速度快,而且精確度高。對于不同類型的數據采用多種提取,比如在運用引擎循環方法的時候,就可以將某一特征的數據信息提取出來,這樣,有價值的數據信息就可以準確地被提取出來,大數據分析能力提高,對于核心數據的定位能力也加快[7](圖1:數據信息分析流程)。
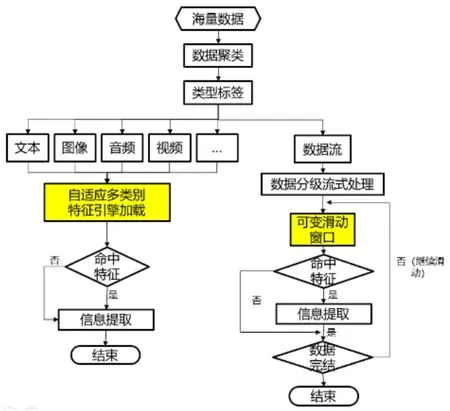
圖1 數據信息分析流程
(2)提取數據的方案
采用這種數據提取方法所獲得的有價值信息更多。對這種方法進行分析需要使用模型。
使用自適應匹配算法的時候,通常原始數據的格式比較復雜,其復雜特征通常超過兩個,在一個文件中很有可能會涵蓋多個特征,諸如視頻特征、音頻特征、圖像特征和文本特征等等。如果特征匹配方式比較單一,就會降低執行效率,會存在數據提取不全的問題,運用概率分布算法,對于特征不同數據可以計算,即便處于不同業務場景,也會有同時出現的概率,采用自動匹配的方法對引擎處理,使得復雜特征數據中提取有價值數據的效率更高[8](圖2:自適應匹配方法提取數據需要遵循的流程)。

圖2 自適應匹配方法提取數據需要遵循的流程
在對信息進行提取的時候,需要依據數據聚類標識的類型標簽,還要結合特征規則庫,將相應的特征處理引擎Cn予以調用,識別引擎之后返回Cn,將結構數據提取出來。
運用關聯引擎算法,就是在相同業務場景中,數據類型相同的情況下,包含的特征有較大概率一樣,所以執行達到設置閥值,且去掉關聯比例為 0的關聯引擎,就可以較低資源代價提取出更多的有價值數據。
算法描述:如果特征規則庫中Cn有關聯比例已經超過引擎Cm,即其甚至閥值的25%,就可以將Cm調取,提取數據;如果一些新特征引擎與Cn沒有關聯性,或者特征引擎與Cn之間的關聯性介于5%至25%之間,比對特征;如果與Cn之間的關聯比例是0%-5%的特征引擎,則不需要進行比對[9]。
采用合并關聯引擎算法將特征處理引擎調用,所獲得的操作結果可以看作是最終的結果集,將所獲得的數據信息存儲在數據庫當中。
應用可變滑動窗口算法,就是從海量數據流中提取有價值數據,具體而言,是通過運用數據塊標識的方法、特征模糊匹配的方法以及可變滑動窗口的方法,將有關聯的數據塊進行合并之后提取,提取效率提高了,而且保證了準確性[10](圖3:可變滑動窗口提取流程算法的運行流程)。
數據塊:對數據流的內容進行分析,明確前1K和最后1K是可以截取的內容,與數據流的長度結合起來,對MD5值予以計算,所獲得的結果就是數據流的唯一標識 ID,在分塊的時候,每次 10000行的頻率都要按照規定的順序操作,數據集合S就能夠獲得,在數據塊表中存儲標識ID存儲,還要將順序號編號。
特征匹配:循環遍歷數據集合 S,使用特征引擎充比如集合 Sn的特征要素,計算Sn的特征要素與特征規則庫之間所存在的一致性,如果從吻合度到設置閥值超過50%,就要將滑動窗口啟動,實施特征比對。
滑動窗口:按照數據流標識ID和順序號,將各個數據集合Sn合并,將下一個數據集合Sn+1以及上一個數據集合Sn-1都納入其中,就可以形成Mn,此為新的數據集合,將特征引擎合理運用,對Mn的特征要素進行比對,將Mn的特征要素與特征規則庫之間的吻合度計算出來,即計算出upSinilarity,如果兩者之間的吻合度upSinilarity計算結果是“算結,就可以進入到下一個環節,即信息提取環節,如果吻合度沒有達到“就可,就意味新的數據集合Mn還需要繼續合并,將Sn-2和Sn+2都結合起來,如此循環往復地執行。
信息提取:在提取信息的時候,需要將特征提取引擎充分利用起來,提取新數據集合Mn中的有價值信息,保存結果。
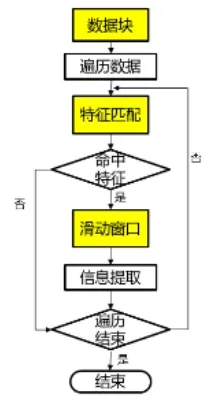
圖3 可變滑動窗口提取流程算法的運行流程
4 結束語
通過上面的研究可以明確,現在的互聯網環境中,信息挖掘已經成為重點研究的問題。在對微博數據信息的挖掘技術分析中,需要考慮網絡挖掘技術的應用,做到全面采集,對于所采集的方法全面了解,予以分析,掌握用戶的個人信息以及用戶關注信息,并對垃圾信息有效處理,提高信息的價值。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
商周刊(2017年22期)2017-11-09 05:08:31
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
文理導航·科普童話(2016年7期)2017-02-04 15:09:20
小天使·四年級語數英綜合(2016年11期)2016-11-29 22:37:30
河南電力(2015年5期)2015-06-08 06:01:46
皖西學院學報(2015年5期)2015-02-28 17:52:46
河南科技(2014年23期)2014-02-27 14:19:15
中學生英語·外語教學與研究(2008年4期)2008-03-18 08:59:18
