面向互聯(lián)網(wǎng)應(yīng)用的大規(guī)模數(shù)據(jù)實(shí)時(shí)查詢優(yōu)化方法研究
2020-12-07 06:03:42沙夢(mèng)釩徐蘭梅滕慶勇王小林
軟件工程 2020年11期
沙夢(mèng)釩 徐蘭梅 滕慶勇 王小林

摘? 要:JSON通常被廣泛應(yīng)用于服務(wù)器與客戶端瀏覽器之間的數(shù)據(jù)交互。某些場(chǎng)景下,由于客戶端請(qǐng)求數(shù)據(jù)量過(guò)大,會(huì)導(dǎo)致服務(wù)器運(yùn)算時(shí)間及網(wǎng)絡(luò)傳輸時(shí)間加長(zhǎng),嚴(yán)重影響用戶體驗(yàn)。針對(duì)此問(wèn)題,提出了一種數(shù)據(jù)壓縮、數(shù)據(jù)緩存及分頁(yè)傳輸?shù)膬?yōu)化處理策略,查詢數(shù)據(jù)庫(kù)的數(shù)據(jù)緩存至服務(wù)器內(nèi)存中,在相同的查詢條件下不再查詢數(shù)據(jù)庫(kù)而是通過(guò)讀取內(nèi)存數(shù)據(jù)庫(kù)Redis直接調(diào)取數(shù)據(jù),并通過(guò)Gzip將數(shù)據(jù)壓縮之后再通過(guò)分頁(yè)方法,每次僅傳輸數(shù)據(jù)量的一部分到客戶端瀏覽器。通過(guò)真實(shí)金融大規(guī)模數(shù)據(jù)集進(jìn)行方法驗(yàn)證,結(jié)果表明,該方法能提高了45%以上的查詢效率,有效地改善用戶體驗(yàn)。
關(guān)鍵詞:數(shù)據(jù)壓縮;緩存;內(nèi)存數(shù)據(jù)庫(kù);分頁(yè)
中圖分類號(hào):TP393.01? ? ?文獻(xiàn)標(biāo)識(shí)碼:A
Abstract: JSON (JavaScript Object Notation) is widely used for data exchange between server and client. However, large amount of data requests may result in long time delay on searching and transmission which will seriously affect users' experience. To solve these problems, this paper proposes an optimization strategy of data compression, data cache and paging transmission. Data of the query database is cached in memory. Next time with the same query conditions, data can be directly retrieved by reading Redis, a memory-based database, instead of being queried from within a disk-based database. The data will be compressed by Gzip compression technology and then transferred only a part by paging method to the browser each time. It is verified though the real large-scale financial data sets. The results show that the proposed strategy can effectively improve query efficiency by more than 45%, with improved user experience.
Keywords: data compression; cache; memory database; paging
1? ?引言(Introduction)
隨著社會(huì)的不斷發(fā)展,計(jì)算機(jī)技術(shù)越來(lái)越成熟,大量的軟件系統(tǒng)不斷地被研發(fā)出來(lái)服務(wù)于人們。人們一般通過(guò)瀏覽器或者APP去獲取一些自己需要的信息或者對(duì)一些信息進(jìn)行操作,前后端的信息交互就是實(shí)現(xiàn)各類需求的一種重要的手段。然而有些時(shí)候我們需要實(shí)時(shí)查詢一些大規(guī)模數(shù)據(jù),這些大型數(shù)據(jù)的傳輸會(huì)產(chǎn)生費(fèi)時(shí)、占用過(guò)多網(wǎng)絡(luò)資源等不利影響,嚴(yán)重影響用戶體驗(yàn)。如何解決這個(gè)問(wèn)題成為一個(gè)重要課題。目前已有人提出過(guò)幾種類型的解決方案:第一類是查詢優(yōu)化,通常為對(duì)數(shù)據(jù)結(jié)構(gòu)的優(yōu)化[1]或者對(duì)索引的優(yōu)化,索引是為了加速對(duì)表中數(shù)據(jù)行的檢索而創(chuàng)建的一種分散的存儲(chǔ)結(jié)構(gòu)。索引是針對(duì)表而建立的,它是由數(shù)據(jù)頁(yè)面以外的索引頁(yè)面組成的,每個(gè)索引頁(yè)面中的行都會(huì)含有邏輯指針,以便加速檢索物理數(shù)據(jù)[2,3]。第二類是采用了分布式儲(chǔ)存查詢,分布式網(wǎng)絡(luò)存儲(chǔ)采用可擴(kuò)展的系統(tǒng)結(jié)構(gòu),利用多臺(tái)存儲(chǔ)服務(wù)器分擔(dān)存儲(chǔ)負(fù)荷,利用位置服務(wù)器定位存儲(chǔ)信息,提高了系統(tǒng)的可靠性、可用性和存取效率[4]。第三類是數(shù)據(jù)壓縮,通過(guò)對(duì)數(shù)據(jù)量的壓縮再進(jìn)行查詢,之后再進(jìn)行解壓,該方案在查詢效率上有很大提升[5,6]。
本文提出了一種思路,把查詢數(shù)據(jù)或查詢條件存入內(nèi)存數(shù)據(jù)庫(kù),再次做相同請(qǐng)求的時(shí)候不再查詢數(shù)據(jù)庫(kù)而是直接讀取緩存,并通過(guò)分頁(yè)的方法將大規(guī)模數(shù)據(jù)切割成許多部分,每次僅傳輸一部分給前端[7,8]。并在傳輸?shù)倪^(guò)程中利用Gzip壓縮技術(shù)壓縮數(shù)據(jù)的方法[9]。本文在查詢數(shù)百萬(wàn)級(jí)及更大量的數(shù)據(jù)的情況下,進(jìn)行了多次實(shí)驗(yàn),通過(guò)設(shè)置對(duì)照實(shí)驗(yàn)得出結(jié)論。
2? ?相關(guān)知識(shí)(Relevant knowledge)
Redis(Remote Dictionary Server),即遠(yuǎn)程字典服務(wù),是一個(gè)開(kāi)源的使用ANSI C語(yǔ)言編寫、支持網(wǎng)絡(luò)、可基于內(nèi)存亦可持久化的日志型、Key-Value數(shù)據(jù)庫(kù),并提供多種語(yǔ)言的API。Redis是一個(gè)key-value存儲(chǔ)系統(tǒng),支持各種不同方式的排序。為了保證效率,數(shù)據(jù)都是緩存在內(nèi)存中。Redis會(huì)周期性的把更新的數(shù)據(jù)寫入磁盤或者把修改操作寫入追加的記錄文件,并且在此基礎(chǔ)上實(shí)現(xiàn)了master-slave(主從)同步。Redis支持主從同步。數(shù)據(jù)可以從主服務(wù)器向任意數(shù)量的從服務(wù)器上同步,從服務(wù)器可以是關(guān)聯(lián)其他從服務(wù)器的主服務(wù)器。同步對(duì)讀取操作的可擴(kuò)展性和數(shù)據(jù)冗余很有幫助。
在Web開(kāi)發(fā)的過(guò)程中,通常會(huì)遇到分頁(yè)技術(shù)。分頁(yè)技術(shù)的核心思想就是當(dāng)人們需要提取大量數(shù)據(jù)的時(shí)候,不可能一次提取所有的數(shù)據(jù),通過(guò)提取其中的一部分給用戶,在用戶需要的情況下再次提取剩下的部分。做到了大塊切割成小塊,每次只利用小塊部分。常見(jiàn)的分頁(yè)方法為客戶端分頁(yè)、數(shù)據(jù)庫(kù)分頁(yè)和服務(wù)器分頁(yè)三種方法。
(1)客戶端分頁(yè)。將全部或多頁(yè)結(jié)果數(shù)據(jù)一次返回給客戶端,客戶端通過(guò)展現(xiàn)組件進(jìn)行分頁(yè)控制,優(yōu)點(diǎn)是減少了客戶端和服務(wù)器的交互次數(shù),客戶端進(jìn)行數(shù)據(jù)緩存,提高了系統(tǒng)交互性,缺點(diǎn)則是增加了第一次交互的負(fù)荷。
(2)數(shù)據(jù)庫(kù)分頁(yè)。進(jìn)行數(shù)據(jù)查詢時(shí),數(shù)據(jù)庫(kù)返回一頁(yè)數(shù)據(jù)給客戶端。優(yōu)點(diǎn)是每次從返回的數(shù)據(jù)庫(kù)返回較少數(shù)據(jù),當(dāng)次交互負(fù)荷較輕。缺點(diǎn)則是每次切頁(yè)都需要訪問(wèn)數(shù)據(jù)庫(kù),增加了數(shù)據(jù)庫(kù)訪問(wèn)并發(fā)性。
(3)服務(wù)器分頁(yè)。是介于上述兩種方法之間的方法。優(yōu)點(diǎn)是在1、2之間達(dá)到了平衡,既減少了數(shù)據(jù)庫(kù)并發(fā)又使服務(wù)器和客戶端當(dāng)次交互的負(fù)荷減少,缺點(diǎn)則是需要考慮數(shù)據(jù)緩存,數(shù)據(jù)同步等問(wèn)題,增加了系統(tǒng)復(fù)雜性。
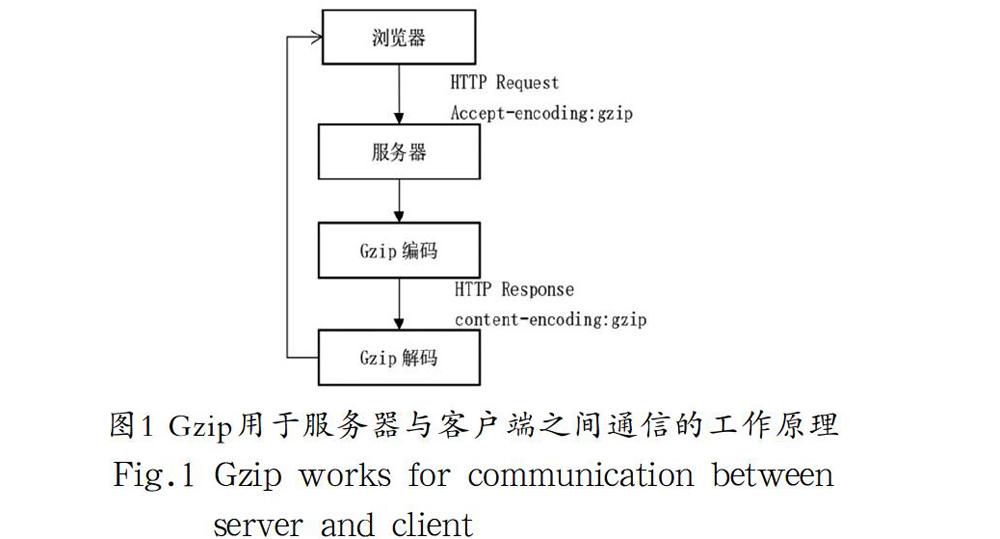
Gzip是GNUzip的縮寫,最早用于UNIX系統(tǒng)的文件壓縮。HTTP協(xié)議上的Gzip編碼是一種用來(lái)改進(jìn)web應(yīng)用程序性能的技術(shù),web服務(wù)器和客戶端(瀏覽器)必須共同支持Gzip。目前主流的瀏覽器,Chrome、firefox、IE等都支持該協(xié)議。常見(jiàn)的服務(wù)器如Apache、Nginx、IIS同樣支持Gzip。Gzip壓縮比率在3到10倍左右,可以大大節(jié)省服務(wù)器的網(wǎng)絡(luò)帶寬。Gzip 對(duì)于要壓縮的文件,首先使用LZ77算法的一個(gè)變種進(jìn)行壓縮,對(duì)得到的結(jié)果再使用Huffman編碼的方法(實(shí)際上gzip根據(jù)情況,選擇使用靜態(tài)Huffman編碼或者動(dòng)態(tài)Huffman編碼)進(jìn)行壓縮。其工作原理如下:
首先由瀏覽器請(qǐng)求url,并在request header中設(shè)置屬性accept-encoding:gzip。表明瀏覽器支持Gzip。在服務(wù)器收到瀏覽器發(fā)送的請(qǐng)求之后,判斷瀏覽器是否支持Gzip,如果支持Gzip,則向?yàn)g覽器傳送壓縮過(guò)的內(nèi)容,不支持則向?yàn)g覽器發(fā)送未經(jīng)壓縮的內(nèi)容。一般情況下,瀏覽器和服務(wù)器都支持Gzip,response headers返回包含content-encoding:Gzip。最后瀏覽器接收到服務(wù)器的響應(yīng)之后判斷內(nèi)容是否被壓縮,如果被壓縮則解壓縮顯示頁(yè)面內(nèi)容。如圖1所示。
3? ?實(shí)時(shí)查詢優(yōu)化方法(Real-time query optimization strategy)
本文針對(duì)大規(guī)模數(shù)據(jù)實(shí)時(shí)查詢的情況進(jìn)行了方法優(yōu)化,當(dāng)我們需要查詢大規(guī)模的數(shù)據(jù)時(shí),將數(shù)據(jù)通過(guò)key-value的形式儲(chǔ)存在Redis里。在后續(xù)的查詢請(qǐng)求里,我們可以直接查詢Redis數(shù)據(jù)庫(kù)調(diào)取出相應(yīng)的數(shù)據(jù)。該操作大大減少了連接數(shù)據(jù)庫(kù)的時(shí)間,減少了resultSet封裝成對(duì)象的過(guò)程,避免了重復(fù)查詢數(shù)據(jù)庫(kù)的操作。在本文實(shí)驗(yàn)中并沒(méi)有直接將百萬(wàn)級(jí)數(shù)據(jù)放在Redis數(shù)據(jù)庫(kù)中,因?yàn)閿?shù)據(jù)量龐大,不適合這樣操作處理。本次采取的方法是將構(gòu)造特殊的查詢參數(shù)放入Redis中,在查詢數(shù)據(jù)的時(shí)候從數(shù)據(jù)庫(kù)中取出,并結(jié)合相應(yīng)算法快速得出前端所需要的部分并返回給前端。
本次實(shí)驗(yàn)的數(shù)據(jù)采用金融資產(chǎn)原始數(shù)據(jù),對(duì)于整張視圖查出來(lái)的數(shù)據(jù),要根據(jù)nvc_code和dtm_share_date這兩個(gè)字段進(jìn)行排序返回前端進(jìn)行顯示。按照這兩個(gè)字段進(jìn)行排序。每次后臺(tái)只向前臺(tái)返回n條數(shù)據(jù)。如何正確地選出這n條數(shù)據(jù)很關(guān)鍵。思路的關(guān)鍵就是從數(shù)據(jù)庫(kù)count出每個(gè)資產(chǎn)的總條數(shù),保存在numberList[i],i指該資產(chǎn)在所選的資產(chǎn)里排序第幾。對(duì)于某些頁(yè)顯示的數(shù)據(jù)存在多個(gè)資產(chǎn)的數(shù)據(jù),因此,把某頁(yè)的數(shù)據(jù)的組成,用下面這句話來(lái)描述:第page頁(yè)的數(shù)據(jù)由A資產(chǎn)的第start到第end,一共end-start+1條數(shù)據(jù)和B資產(chǎn)的第begin到stop,一共top-begin+1條數(shù)據(jù)和C資產(chǎn)組成。為了確定這些start、end、begin、stop等值,定義一個(gè)數(shù)組remaList。把該資產(chǎn)數(shù)據(jù)填充完之后,位于第幾頁(yè)還剩多少條數(shù)據(jù)需要后面資產(chǎn)填充的,這個(gè)多少條數(shù)據(jù)的數(shù)值存在remaList[i],i指該資產(chǎn)在所選的資產(chǎn)里排序第幾。為了與前端傳來(lái)的page字段掛鉤,需要在定義一個(gè)數(shù)組pageList。該數(shù)組存放每個(gè)資產(chǎn)填充完之后的起始頁(yè),若該資產(chǎn)的總條數(shù)小于需要填充的條數(shù),該資產(chǎn)存放的值等于前一個(gè)資產(chǎn)存放的pageList中的值。下式描述了每一頁(yè)的分頁(yè)條數(shù)n與資產(chǎn)數(shù)據(jù)Xi的填充關(guān)系。
n為設(shè)置的分頁(yè)數(shù),即每一頁(yè)有多少條數(shù)據(jù),m為資產(chǎn)數(shù),α為第i個(gè)資產(chǎn)所需要填充的數(shù)據(jù)量,λ為常量,取值為0或者1,當(dāng)Xi資產(chǎn)的總條數(shù)大于分頁(yè)數(shù)n時(shí),λ取0,否則λ取1。
將上述List數(shù)組存入redis中后,每當(dāng)瀏覽器傳回page頁(yè)請(qǐng)求相應(yīng)數(shù)據(jù)時(shí),可以通過(guò)讀取redis中的數(shù)組快速計(jì)算出前端所需要的那部分?jǐn)?shù)據(jù)并返回給瀏覽器。
再取得數(shù)據(jù)后,開(kāi)始通過(guò)服務(wù)器開(kāi)啟Gzip壓縮,以NGINX為例,首先設(shè)置gzip on參數(shù)開(kāi)gzip模式,接下來(lái)通過(guò)gzip_min_length參數(shù)配置壓縮起點(diǎn),例如文件至少大于1k才開(kāi)啟壓縮,然后通過(guò)gzip_comp_level設(shè)置gzip的壓縮級(jí)別,該級(jí)別分為1—9級(jí),級(jí)別越大壓縮的程度越大,同時(shí)對(duì)CPU的負(fù)擔(dān)也會(huì)逐漸增大。再通過(guò)gzip_type參數(shù)設(shè)置一下壓縮的文件類型,本文中為了解決請(qǐng)求大規(guī)模數(shù)據(jù)的優(yōu)化策略,前后端交互是采取json的數(shù)據(jù)格式,因此這里配置的文本類型一般設(shè)置為application/json,這樣就可以針對(duì)此類型的請(qǐng)求操作進(jìn)行壓縮。接下來(lái)通過(guò)gzip_vary參數(shù)配置是否在http-header開(kāi)啟Accept-Encoding,開(kāi)啟該參數(shù)配置是為了讓瀏覽器通知服務(wù)器自己是支持Gzip壓縮模式的,當(dāng)瀏覽器接收到壓縮數(shù)據(jù)后會(huì)自動(dòng)解壓操作。再通過(guò)gzip_buffers參數(shù)設(shè)置緩沖區(qū)大小,以4k為單位,若大于4k時(shí),例如7k則分配為2*4k的緩沖區(qū)。最后設(shè)置一下gzip_http_version參數(shù),該參數(shù)是協(xié)議版本,例如版本為1.1則設(shè)置1.1即可。
在壓縮完數(shù)據(jù)后,服務(wù)器向前端開(kāi)始傳輸數(shù)據(jù),此時(shí)通過(guò)頁(yè)數(shù)參數(shù),選擇其中的部分?jǐn)?shù)據(jù)返還給前端瀏覽器。例如頁(yè)碼參數(shù)為1時(shí),我們可以傳第1至100條的數(shù)據(jù),假設(shè)此時(shí)查詢的數(shù)據(jù)共計(jì)100萬(wàn)條,本次僅僅只傳輸了萬(wàn)分之一,當(dāng)用戶需要下一批數(shù)據(jù)時(shí),我們?cè)谕ㄟ^(guò)頁(yè)碼參數(shù)2再次請(qǐng)求服務(wù)器,服務(wù)器從redis緩存的100萬(wàn)條數(shù)據(jù)中直接取出第101至200條數(shù)據(jù)。在每一次的請(qǐng)求操作過(guò)程中,用戶都只拿到大規(guī)模數(shù)據(jù)的一小部分。每一次請(qǐng)求的數(shù)據(jù)量可以根據(jù)具體需求做出改變。
4? 實(shí)驗(yàn)結(jié)果及分析(Experimental results and analysis)
本次實(shí)驗(yàn)環(huán)境為一臺(tái)PC機(jī),8G內(nèi)存,i5-5200U,2.20GHz處理器,100M移動(dòng)寬帶,瀏覽器為Chrome。服務(wù)器部分是采用分布式系統(tǒng)架構(gòu),每臺(tái)服務(wù)器的硬件環(huán)境為CPU:4核Intel(R) Xeon(R) Gold 6130 CPU @ 2.10GHz,內(nèi)存16GB,硬盤200GB,操作系統(tǒng)采用Linux發(fā)行版之一的Centos 7.8版本。
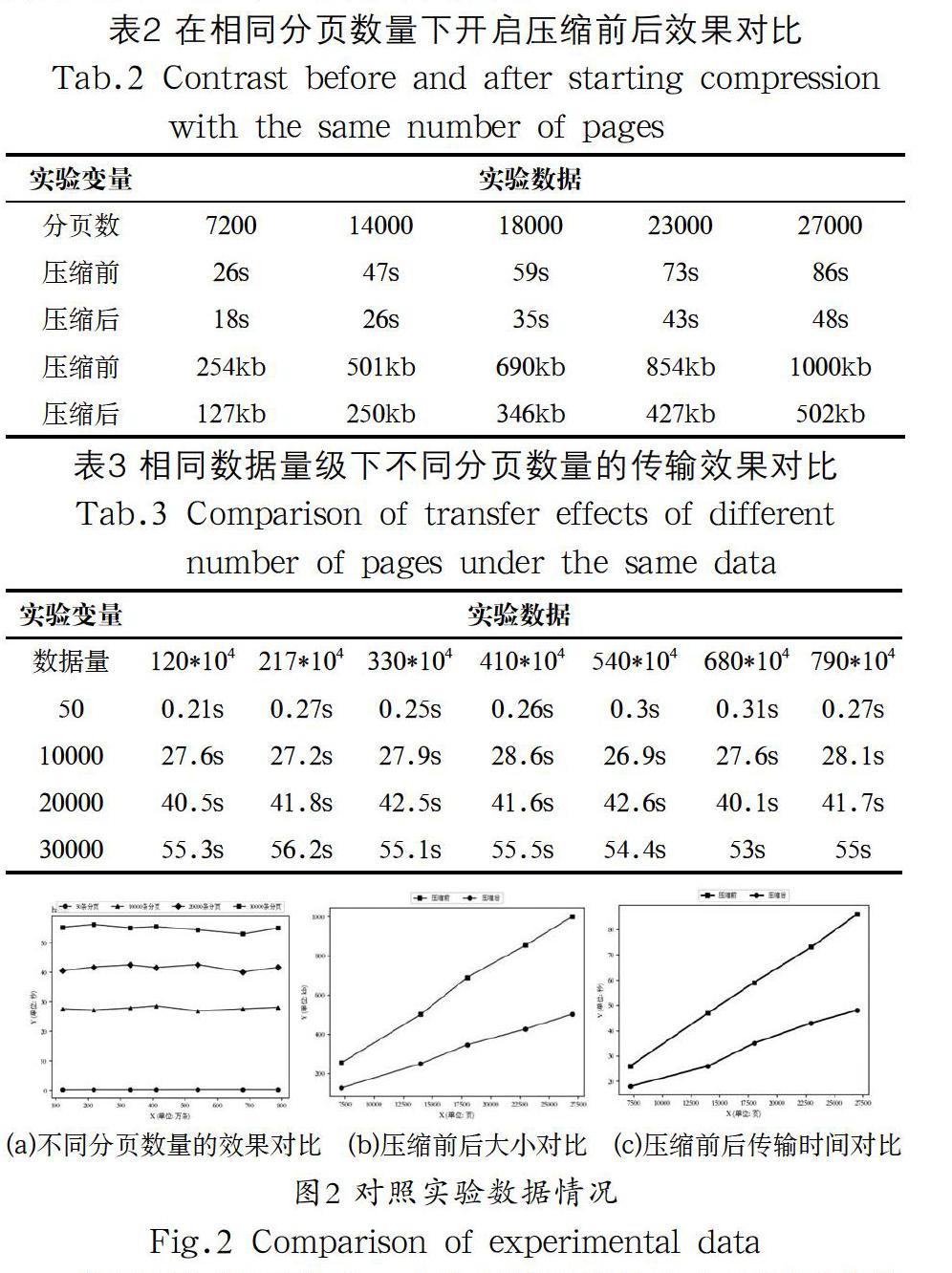
本文通過(guò)設(shè)置對(duì)照實(shí)驗(yàn),開(kāi)啟Gzip壓縮和未開(kāi)啟Gzip壓縮時(shí)的效果對(duì)比、分頁(yè)傳輸效果對(duì)比試驗(yàn)。本文中的實(shí)例因數(shù)據(jù)查詢條件過(guò)于復(fù)雜,在未分頁(yè)的情況下,百萬(wàn)級(jí)數(shù)據(jù)會(huì)顯示超時(shí),且對(duì)瀏覽器負(fù)擔(dān)較重。所以在Gzip壓縮對(duì)比實(shí)驗(yàn)中在保證相同的分頁(yè)數(shù)情況下獲取實(shí)驗(yàn)數(shù)據(jù)以此觀察壓縮效果(表2),在分頁(yè)效果對(duì)比實(shí)驗(yàn)中,在相同數(shù)據(jù)量級(jí)下不同級(jí)別的分頁(yè)數(shù)量來(lái)獲取實(shí)驗(yàn)數(shù)據(jù)以此觀察出分頁(yè)效果(表3)。以百萬(wàn)級(jí)的數(shù)據(jù)為基準(zhǔn),逐漸增大數(shù)據(jù)量,通過(guò)10次采樣取平均值的方法開(kāi)始試驗(yàn)。試驗(yàn)對(duì)比結(jié)果如圖2所示。
從圖2和表2可得知,本次實(shí)驗(yàn)開(kāi)啟的Gzip壓縮率約為50%,在分頁(yè)數(shù)量分別設(shè)置為一頁(yè)傳輸7200條數(shù)據(jù),一頁(yè)傳輸14000條數(shù)據(jù),一頁(yè)傳輸18000條數(shù)據(jù),一頁(yè)傳輸23000條數(shù)據(jù),一頁(yè)傳輸27000條數(shù)據(jù)共五組情況下,在壓縮前文件大小分別約為254kB、501kB、690kB、854kB、1000kB,傳輸數(shù)據(jù)所需要的時(shí)間分別約為26秒、47秒、59秒、73秒、86秒。當(dāng)開(kāi)啟Gzip壓縮后文件大小分別約為127kB、250kB、346kB、427kB、502kB,傳輸數(shù)據(jù)所需要的時(shí)間分別約為18秒、26秒、35秒、43秒、48秒。兩組數(shù)據(jù)的對(duì)比可以明顯看出,隨著每一頁(yè)分頁(yè)量的增加,從查詢到傳輸給前端的時(shí)間也逐漸增加,呈線性增長(zhǎng)。開(kāi)啟Gzip壓縮后,數(shù)據(jù)的大小減少了約50%,所花費(fèi)的時(shí)間也是比未壓縮時(shí)少了很多,通過(guò)此次類比可以得出:在百萬(wàn)級(jí)的數(shù)據(jù)量級(jí)別下,Gzip壓縮有著非常有效地優(yōu)化效果。
從圖2和表3可知,在都設(shè)置了Gzip壓縮的條件下,分別設(shè)置了分頁(yè)數(shù)為50、10000、20000、30000的四組對(duì)照實(shí)驗(yàn)。由圖中可得知,在分頁(yè)數(shù)為50條一頁(yè)的情況下,平均僅僅需要0.2秒便可獲取到數(shù)據(jù),并且隨著量的增加,最后到700百萬(wàn)的時(shí)候時(shí)間也保持著穩(wěn)定,在0.27秒左右便可傳輸完畢。在分頁(yè)數(shù)為10000時(shí),七組數(shù)據(jù)量的實(shí)驗(yàn)下,時(shí)間平均在27秒左右。在分頁(yè)數(shù)為20000時(shí),七組數(shù)據(jù)量的時(shí)間則平均在41秒左右。在分頁(yè)數(shù)為30000時(shí),七組數(shù)據(jù)量的時(shí)間則平均在55秒左右。四組的對(duì)照實(shí)驗(yàn)可以看出,時(shí)間在數(shù)據(jù)量的增大下,幾乎保持著水平趨勢(shì),相對(duì)穩(wěn)定。且隨著分頁(yè)數(shù)越來(lái)越小,所需要的時(shí)間也越來(lái)越少。由此可以推斷出,在大規(guī)模數(shù)據(jù)傳輸下,合理的分頁(yè)能有效地提高傳輸效率,縮短傳輸時(shí)間,很好的改善用戶的體驗(yàn)。
試驗(yàn)結(jié)果表明,未采用內(nèi)存數(shù)據(jù)庫(kù)、Gzip壓縮及分頁(yè)傳輸?shù)臄?shù)據(jù)查詢?cè)跀?shù)據(jù)規(guī)模較小時(shí),處理時(shí)間在接受范圍之內(nèi)。當(dāng)數(shù)據(jù)規(guī)模足夠龐大時(shí),處理時(shí)間過(guò)長(zhǎng),客戶端瀏覽器負(fù)擔(dān)很重。而基于內(nèi)存數(shù)據(jù)庫(kù)、Gzip壓縮和分頁(yè)傳輸?shù)拇笠?guī)模數(shù)據(jù)查詢時(shí),較好地解決了困難,在不同等級(jí)的數(shù)據(jù)量下均有良好的表現(xiàn)。
5? ?結(jié)論(Conclusion)
在傳統(tǒng)的B/S模式的互聯(lián)網(wǎng)應(yīng)用遇到大規(guī)模數(shù)據(jù)查詢時(shí)的高計(jì)算延時(shí)、高傳輸時(shí)間問(wèn)題下,本文從內(nèi)存數(shù)據(jù)庫(kù)、Gzip壓縮及分頁(yè)傳輸?shù)慕嵌热ジ纳菩蕟?wèn)題。從大量數(shù)據(jù)實(shí)驗(yàn)測(cè)試,該方案的確改善了效率問(wèn)題,減少了查詢時(shí)間,提高了網(wǎng)絡(luò)傳輸效率,證實(shí)了該方案的可行性。該方案雖然有較為良好的效果,但是從實(shí)際應(yīng)用的效果分析,還有著進(jìn)一步改善提高的空間。
參考文獻(xiàn)(References)
[1] 王小林,劉敏,徐宏,等.一種移動(dòng)互聯(lián)網(wǎng)序列化數(shù)據(jù)的傳輸優(yōu)化方法[J].安徽工業(yè)大學(xué)學(xué)報(bào)(自然科學(xué)版),2017,34(01):71-75.
[2] 夏秀峰,張劉暢,劉向宇.面向大規(guī)模圖數(shù)據(jù)的分布式可達(dá)性索引與查詢策略[J].計(jì)算機(jī)工程,2018,44(03):65-72.
[3] 陳大偉,張清,劉敏.試論云計(jì)算環(huán)境下的分布式存儲(chǔ)技術(shù)[J].科技展望,2016,26(31):16.
[4] 郭慶,朱一凡,謝瑩瑩,等.面向大規(guī)模網(wǎng)絡(luò)流量數(shù)據(jù)的實(shí)時(shí)匯聚查詢關(guān)鍵技術(shù)研究[J].小型微型計(jì)算機(jī)系統(tǒng),2020,41(06):1314-1320.
[5] FuTao Ni, Jian Zhang, Mohammad N.? Noori. Deep learning for data anomaly detection and data compression of a long‐span suspension bridge[J]. Computer Aided Civil and Infrastructure Engineering, 2020,35(7):685-700.
[6] Rui-Peng Hu, Chun-Xiong Huang. Optimized compression technology for spatial data network transmission[J]. Journal of Discrete Mathematical Sciences and Cryptography, 2018,21(2):557-562.
[7] 奚科芳.常見(jiàn)關(guān)系數(shù)據(jù)庫(kù)實(shí)現(xiàn)分頁(yè)[J].數(shù)字技術(shù)與應(yīng)用,2020,38(01):44-45.
[8] 王志娟,班婭萌,平金珍.基于AJAX技術(shù)和JAVAEE的分頁(yè)查詢優(yōu)化[J].信息通信,2019(01):118-119.
[9] 趙雅倩,李龍,郭躍超,等.基于OpenCL的Gzip數(shù)據(jù)壓縮算法[J].計(jì)算機(jī)應(yīng)用,2018,38(S1):112-115;130.
