基于DPI數據的人群分析方法及實踐
2020-11-30 09:08:49范家杰宮云平
移動通信 2020年10期
范家杰 宮云平
【摘? 要】隨著社會的發展,人們對公眾場合安全問題越來越重視,對熱點區域人流監控的需求日益旺盛。傳統的方法是通過攝像頭、紅外等設備進行監控[1],但是這種方法投入大,耗時耗力,不太適合大范圍監控區域。針對這一問題,提出一種基于DPI數據的實時人群分析方案,通過采集用戶上網行為形成的海量DPI數據,對DPI數據進行實時解析,可以獲得包括地理位置、訪問網站、使用時長等信息,然后根據地理位置劃分出不同區域,最后按區域進行分類匯總分析,并輸出人群分布以及使用愛好等情況。本方案已經成功應用于實際系統,取得良好效果。
【關鍵詞】DPI;結構化流;人群分析
doi:10.3969/j.issn.1006-1010.2020.10.011? ? ? ? 中圖分類號:TN91
文獻標志碼:A? ? ? ? 文章編號:1006-1010(2020)10-0061-05
引用格式:范家杰,宮云平. 基于DPI數據的人群分析方法及實踐[J]. 移動通信, 2020,44(10): 61-65.
0? ?引言
隨著移動互聯網的不斷發展以及各類智能設備日益深入民眾日常生活中,人類社會產生的數據量正在以指數級快速增長,人類已經正式邁入大數據時代[2]。如今,運營商能夠獲得的用戶數據越來越豐富,通過DPI(Deep Packet Inspector,深度分組檢測)分析技術,能夠較好地識別網絡上的流量類別、應用層上的應用種類等[3]。在這個“數據為王”的時代,如何充分利用這筆重要的戰略資產已經成為重中之重的問題[4]。
另一方面,隨著社會發展,針對熱點區域的人群分析也越來越重要。而傳統的通過攝像頭、紅外等設備的監控方法,不僅需要投入巨大的硬件成本、人力成本,而且在顯示器能看到的監控區域還很有限,可見傳統方法針對大范圍的監控力不從心。運營商通過收集用戶收集上報的DPI信息,可以獲得手機用戶的地理位置、上網時長等內容,因此可以通過DPI信息從另一方面感知熱點區域人流聚集情況,達到人群分析的目的。
本文結合電信運營商的數據以及人群分析的需求,提出一種基于DPI數據的人群分析方法,能夠實時分析DPI數據,提取出其中蘊含的地理位置信息、用戶上網信息等,并按不同熱點區域進行分類匯總分析。本方法在不增加設備、不增加用戶負擔的前提下,可以實時獲得熱門區域人群聚集情況、上網行為等信息,方便進行人員管理以及精準營銷,具備極高的性價比。
1? ?Spark結構化流
Spark結構化流是一個基于Spark SQL執行引擎的流處理引擎,是Spark 2.X時代新推出的一種流處理框架,目前最新版本為Spark2.4[5]。Spark結構化流具有高可擴展性、高容錯性的特點,提供快速、端到端的一次性消費能力[6]。Spark結構化流能非常好地融入現有大數據平臺,不需要安裝其他軟件,集成度高,底層封裝了大量接口,對開發能力的要求較低。
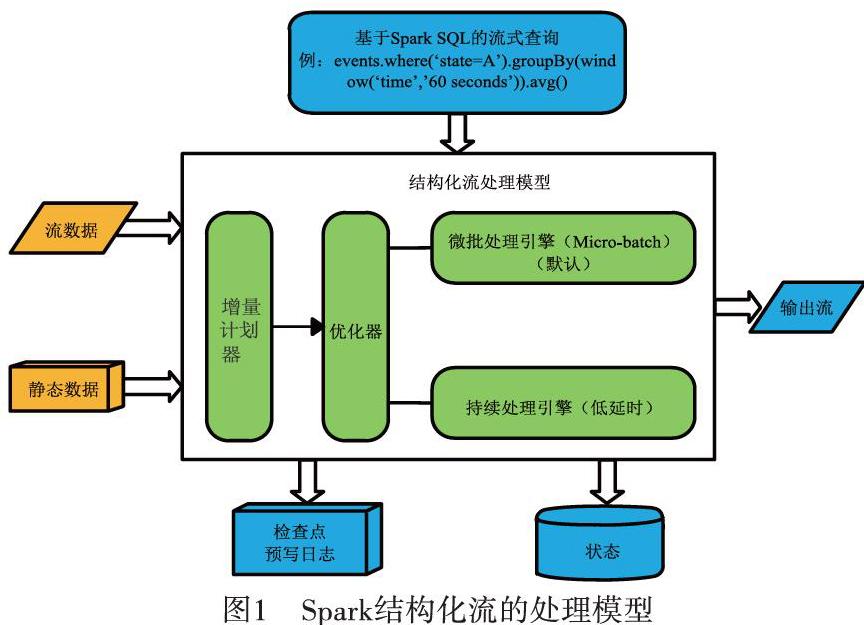
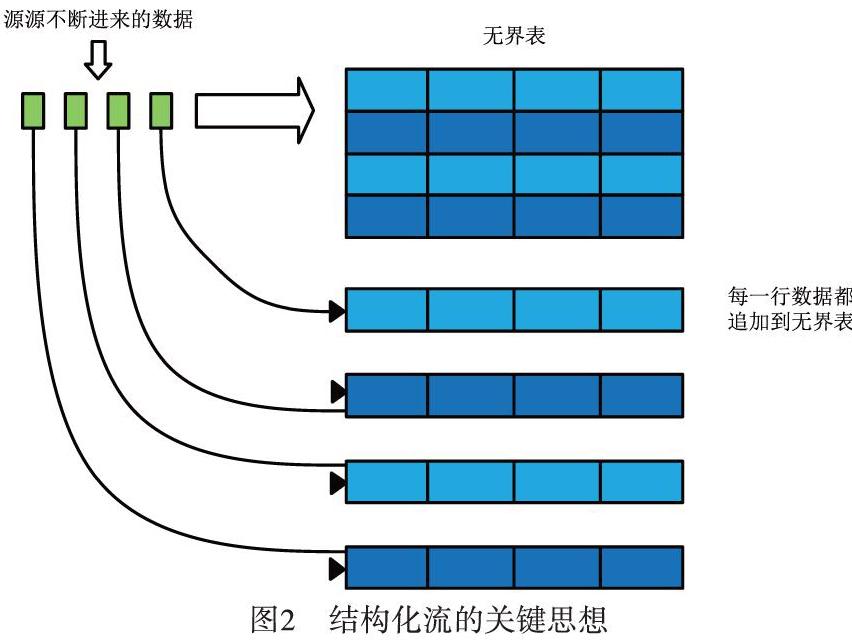
Spark結構化流的處理模型如圖1所示。結構化流的關鍵思想是把實時數據變成一張不斷延伸的表格,不斷進來的數據追加到該表格,形成一行新數據,如圖2所示[7]。所有的操作都是針對這張不斷更新無邊界的大表,最后把處理結果增量或者全量輸出到不同的文件系統或數據庫等。
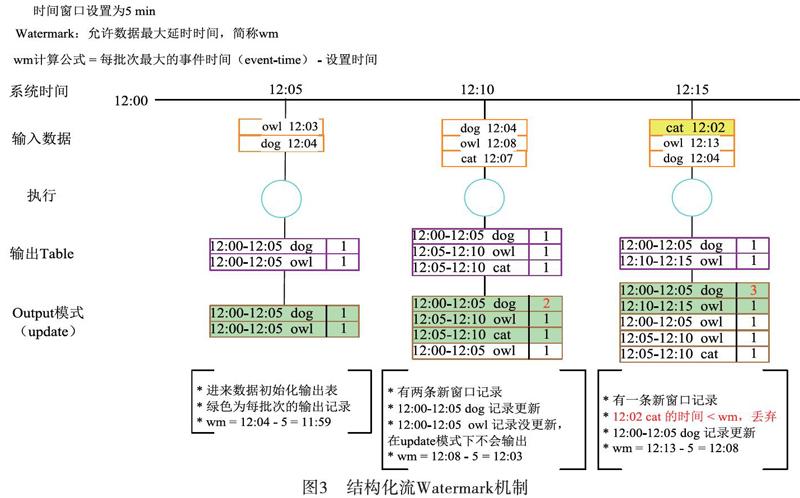
事件時間是事件發生時間而不是數據到達時間[8]。更多情況下流式處理都是針對事件時間,而結構化流原生支持事件時間,也支持基于事件時間窗口的聚合操作[9]。當存在延遲數據時,程序可以設置最大允許延遲時間Watermark,在Watermark內到達的數據都會被統計,而超出部分數據將被拋棄掉,同時自動跟蹤數據中的事件時間,相應地清除舊狀態。如圖3所示。
Spark結構化流使用的前提是數據必須是能夠結構化的,在這個基礎上,結構化流提供了豐富的、集成度高的API,來對數據進行靈活轉換。整個過程具備高可用性、高容錯性,以及一次性保證、斷點續傳的特點,特別適合用來處理能夠結構化的數據。
Spark Streaming基于微批次實現了準實時處理(秒級處理時延),也在Spark計算引擎技術棧之中[10]。Spark Streaming可以實現高吞吐量的、具備容錯機制的實時流數據的處理,是一種常見的流式框架[11]。Spark Streaming是基于RDD開發的,數據模型是Dstream。而結構化流是基于Sql開發的,數據模型是DataFrame。另外Spark Streaming的處理是基于處理時間,而結構化流是基于事件時間。因此能結構化的數據并且更加關注事件時間的,適合使用Spark結構化流。
2? ?人群分析方案
本方案如圖4所示。設備廠商把包含DPI信息的壓縮文件通過Ftp的方式推送到大數據平臺,保存在HDFS上。Spark結構化流直接讀取并實時分析DPI數據,并將結果輸出到HDFS或者Mysql中。
Flume是Cloudera提供的一個高可用的、高可靠的、分布式的海量日志采集、聚合和傳輸的系統,可以滿足大數據采集的需求。Kafka是一種高吞吐量的分布式發布訂閱消息系統,通常用作數據緩存。對于流式處理而言,常見的方案通常會用Flume進行數據采集,用Kafka進行數據緩存,最后流式處理工具去消費Kafka的數據,這樣不會因為瞬間的大量數據導致流式計算崩潰。而本文通過自定義的方式直接讀取Hdfs文件,這樣不僅可以加快處理速度,節省處理時間,還可以減少中間件運維成本。
Spark結構化流程序在遍歷根目錄尋找最新文件的時候,都會讀取到一些過時的文件。雖然結構化流有Watermark機制,但也是把數據讀取后再進行過濾,這在處理上有很大的浪費。同時由于缺少數據緩沖,瞬時的大量數據非常容易導致程序崩潰。為了解決這一問題,本文采取改造掃描方式,增加realTime、readHour兩個參數直接在讀取文件名的時候過濾超時數據,同時通過結構化流的maxFilesPerTrigger參數來控制每次讀取文件的數量,通過latestFirst參數來控制優先讀取新文件,保證每次處理文件都是最新的。
Spark結構化流需要監控的區域每天都會變,因此需要實時更新配置數據,這樣才能及時監控到新區域。為了達到這一目的,程序在不重啟的情況下每隔10分鐘會去更新配置數據,并同步到Spark的每個節點上,這樣每個節點計算時會把新區域監控上。
實時讀取到的DPI數據會被切割成不同字段,包括用戶號碼MDN、基站ECGI、流量FLOW等信息。通過不同基站的組合可以劃分出不同的區域,如把廣州琶洲展館附近基站組合在一起,就可以感知到展館附近人流情況。而根據不同的區域對流量、訪問網站等分析,就可以進一步獲取該區域人流的行為特征。如在區域A中,通過統計去重用戶號碼,就可以獲取該區域的人流量;通過統計用戶訪問的網站,即可獲取該區域用戶上網愛好習慣;通過統計用戶使用的手機型號,可以獲取該區域的消費能力等,如圖5所示。
在結構化流中,數據切割出的字段會映射成一張無邊界表,然后使用Sql對臨時表進行查詢。這些查詢統計結果會根據陸續到達的數據而不斷更新,達到一定時間閾值后,數據將會被輸出到Hdfs或者Mysql。為了更好實現Spark可擴展性強的特點,系統增加了動態SQL注入機制。該機制通過配置文件的形式自定義SQL計數器,程序再將SQL轉換成SparkSQL底層代碼,并啟動計數器計數。同時通過配置文件為每個計數器指定輸出通道,將結果輸出到指定路徑。這樣需求人員可以自定義計數器,并把結果輸出到想要的位置,可擴展性大大增強。
為了更好觀察流式處理系統處理狀態,系統引入監控功能。該監控功能可以實時監控程序是否在正常處理文件,同時還可以監控文件是否有積壓情況,實時處理性能以及延遲情況。如發現程序狀態異常,可以記錄系統異常記錄同時重啟程序,保證程序始終有數據輸出。
本文介紹的方案只需要部署一個Spark結構化流組件,即可完成從數據采集、分析、輸出全過程,解決了數據更新、數據緩沖、多業務通道、多業務輸出的難點,具有運維簡單、可靠性強、擴展方便的特點。
3? ?實踐及分析
本項目使用Spark 2.4.0進行開發,資源配置如下:40個Executor實例,每個Executor配置10 G內存和5個Core。根據該資源和實際測試效果,限制了每批次最大處理文件為200個(約20 G,耗時約4分鐘),即最高處理效率為每秒8.8萬條,且默認優先處理最新的文件。在高峰的情況下,DPI文件個數約為3 500個,DPI文件產生后,2分鐘內能輸出結果,整體時延在5分鐘內。
與文獻[4]所述的基于KafkaStream的流式處理方案相比,本文所述方案僅用了400 G內存,而文獻[4]使用了6臺256 G內存的機器,資源消耗大大減低。同時減少了Flume、Kafka、ELK等一系列組件,降低了運維成本。在時間方面,本文的整體時延僅為5分鐘,而文獻[4]由于組件多,程序處理邏輯復雜,整體時延將近30分鐘,因此本文在資源消耗、耗時等一系列指標均優于基于KafkaStream流式框架。
目前系統日均處理200億條數據,為70多個區域提供監控能力,并且監控區域在不斷增長。目前的SQL統計包含5分鐘區域用戶數/流量統計,1小時區域用戶瀏覽統計等,另外用戶可以通過配置文件自己個性化增加統計功能。
在前端頁面應用中,通過統計區域內每小時的去重用戶數,可以繪制出人群熱力圖,直觀看到人群聚集情況,如圖6所示。通過統計每小時用戶使用的App,可以繪制出該區域最常瀏覽的Top10應用,如圖7(a)所示,區域最熱應用為微信。通過統計預期內每5分鐘的去重用戶數,可以繪制出每5分鐘4G上網用戶數,如圖7(b)所示,9點50分區域內有33名用戶同時在線。
本系統已經在廣東省試點實施,監控區域包括廣州各大熱門場所如白云機場、廣州南站以及琶洲展館等。系統連續3年應用于廣州春運期間火車站,并為2017年廣州財富論壇、第十五屆廣東省運動會提供監控服務,取得良好效果。
4? ?存在的問題
在開發過程中,也發現結構化流的一些不足。如一次統計多項業務時,由于結構化流基于Spark SQL的底層,其執行過程是生成邏輯計劃,再優化成物理計劃執行,因此每項業務得獨自統計,形成多個通道,會導致每個通道都各自讀取數據源,對于大規模數據而言,帶來了大量額外消耗。
在業務層面上,目前應用較少,僅能提供5分鐘/1小時維度的關于流量、人數、使用情況的統計,而沒有進行更深一步的分析。后期考慮加入人數達到一定閾值觸發預警機制,結合用戶需求做實時推薦等功能。
5? ?結束語
本文首先介紹了目前傳統監控手段的缺點以及運營商擁有的海量DPI數據,然后結合熱點區域人群分析需求和DPI數據,提出一種基于DPI數據的人群分析方法,并概述了Spark結構化流具有高可用性、高容錯性、開發簡單的特性。該方案已經在實際項目中應用,能夠實時分析DPI數據的位置、上網行為等信息,統計5分鐘不同區域人流情況以及1小時不同區域訪問網站情況,并且在前端頁面展示,很好地結合了監控需求以及運營商DPI資源,取得良好的效果。
目前系統應用的計數器偏少,后續可以根據需要增加Sql統計。Spark結構化流是一個新生事物,目前還在迭代優化中,其中不免存在一些問題,對多業務統計不夠友好,目前應用的項目不多,中文資料也較少。但瑕不掩瑜,Spark結構化背靠Spark這棵大樹,本身性能不弱,并集成了大量API,入門簡單,未來前景可期。
參考文獻:
[1]? ? 董迦勒. 基于大數據的區域人流監控平臺的設計與實現[D]. 北京: 北京交通大學, 2018.
[2]? ? 陳康,付華崢,陳翀,等. 基于DPI的用戶興趣實時分類[J]. 電信科學, 2016,32(12): 109-115.
[3]? ? 孫大為,張廣艷,鄭緯民. 大數據流式計算:關鍵技術及系統實例[J]. 軟件學報, 2014,25(4): 839-862.
[4]? ? 范家杰,田熙清,鄭博. 基于流式計算的DPI數據處理方案及實踐[J]. 移動通信, 2018,42(1): 80-86.
[5]? ? NightPxy. [Spark]-結構化流之初識篇(待重修)[EB/OL]. (2018-07-05)[2019-10-08]. https://www.cnblogs.com/NightPxy/p/9271453.html.
[6]? ? ?博客園. Spark譯文(三)[EB/OL]. (2019-04-29)[2019-10-08]. https://www.cnblogs.com/fenghuoliancheng/p/10790307.html.
[7]? ? Spark. Structured Streaming Programming Guide[EB/OL]. [2019-10-08]. http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html.
[8]? ? ?于秀金. 類型學視野下的英漢時體研究[D]. 上海: 上海外國語大學, 2013.
[9]? ?BillowX. StructuredStreaming編程指南[EB/OL]. (2019-01-23)[2019-10-08]. https://www.jianshu.com/p/43d11948ad11.
[10]? ?韋鈺. 一種基于Spark Streaming的實時數據處理方法[C]//2019年全國公共安全通信學術研討會. 中國通信學會, 2019: 5.
[11]? ?楊伯宇. 基于Spark Streaming的實時DDoS檢測系統[D]. 濟南: 山東大學, 2019.
