圖像OCR識別在機頂盒信息檢測中的應用分析
2020-11-30 08:36:36靳國榮
科學與信息化 2020年31期


摘 要 隨著生活水平的提高,機頂盒已成為每個家庭必備的設備,因此,機頂盒的質量就顯得尤為重要。但如果機頂盒寫入的信息有誤,將導致機頂盒無法正常運行,會極大地影響用戶的觀看體驗。現有技術對機頂盒等視頻盒子的信息檢測還停留在傳統的人工測試判定,即通過人工的方式對視頻圖像上的信息進行比對來檢驗正誤,但是人工檢測的方式帶有很多個人主觀觀點,無法快速準確地發現機頂盒中信息有誤的問題。
關鍵詞 OCR;圖像預處理;文字識別
引言
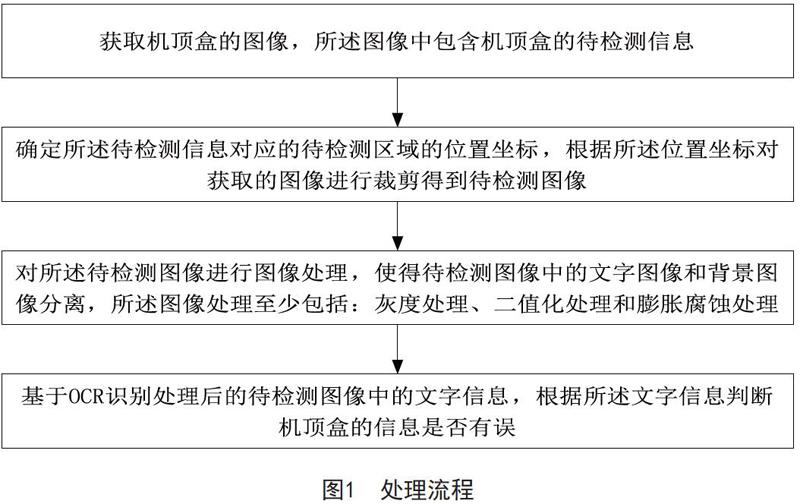
本文提出的圖像OCR識別的機頂盒信息檢測方法及系統,技術方案概括為:獲取機頂盒的圖像,所述圖像中包含機頂盒的待檢測信息;確定所述待檢測信息對應的待檢測區域的位置坐標,根據所述位置坐標對獲取的圖像進行裁剪得到待檢測圖像;對所述待檢測圖像進行圖像處理,使得待檢測圖像中的文字圖像和背景圖像分離,所述圖像處理至少包括:灰度處理、二值化處理和膨脹腐蝕處理;基于OCR識別處理后的待檢測圖像中的文字信息,根據所述文字信息判斷機頂盒的信息是否有誤。
圖像OCR識別的機頂盒信息檢測方法的處理流程如圖1所示。
1圖像采集處理
1.1 圖像采集
機頂盒的圖像可以通過HDMI設備獲取,機頂盒的待檢測信息可以是機頂盒生產序列號、機頂盒加密序列號、鎖定模式序列號、機頂盒加密卡序列號等。采集出來的圖像如圖2所示。
1.2 定位檢測區域
根據所述位置坐標對獲取的圖像進行裁剪得到待檢測圖像;具體而言,可以根據待檢測信息在圖像中的位置確定出裁剪區域的位置坐標,然后根據裁剪區域的位置坐標對獲取的圖像進行裁剪得到待檢測圖像,待檢測圖像中包含了機頂盒的待檢測信息。如圖3所示。
1.3 圖像預處理
待檢測圖像進行圖像處理,使得待檢測圖像中的文字圖像和背景圖像分離,所述圖像處理至少包括:灰度處理、二值化處理和膨脹腐蝕處理;
可以理解,灰度處理、二值化處理和膨脹腐蝕處理是依次進行的,其中,灰度處理包括:
對待檢測圖像進行灰化處理,得到只包含一種灰度值的灰度圖像,灰化公式如下:
式中,表示灰度圖像中像素的灰度值,R表示紅色分量值,G表示綠分量值,B表示藍色分量值。
二值化處理包括:確定灰度閾值,根據所述灰度閾值對灰度圖像進行二值化處理得到二值圖像,二值圖像就是只有黑白兩種顏色表示的圖像,在數字上用0 表示黑色(0),1表示白色(255) 。圖像中屬于同一物體的像素在灰度值上存在極大相似性,相反,不同物體在灰度值上通常表現為較大差異。因而,本實施例通過自動閾值化技術,選取能夠充分體現前景和背景差異的分割灰度值,使待識別的文字大致分離出來。
根據自動閾值化技術確定灰度閾值的方法包括:設定初始灰度閾值,對于灰度圖像的每個像素,計算其Kirsh算子,根據初始灰度閾值與Kirsh算子的大小對初始灰度閾值進行動態調整得到灰度閾值。
膨脹處理包括:遍歷所述二值圖像的每一個像素,用結構元素的中心點對準當前正在遍歷的像素,獲取當前結構元素所覆蓋下的二值圖像對應區域內的所有像素的最大值,用該最大值替換當前像素值[1];由于二值圖像最大值就是1,所以就是用1替換,即變成了白色前景物體。如果當前結構元素覆蓋下,全部都是背景,那么就不會對原圖做出改動,因為都是0;如果全部都是前景像素,也不會對原圖做出改動,因為都是1;只有結構元素位于前景物體邊緣的時候,它覆蓋的區域內才會出現0和1兩種不同的像素值,這個時候把當前像素替換成1就有變化了。膨脹后的圖像的整體亮度會有提高,圖形中較亮物體的尺寸變大,而較暗物體的尺寸會減小甚至消失。
腐蝕處理包括:遍歷所述二值圖像的每一個像素,用結構元素的中心點對準當前正在遍歷的像素,獲取當前結構元素所覆蓋下的二值圖像對應區域內的所有像素的最小值,用該最小值替換當前像素值;由于二值圖像最小值就是0,所以就是用0替換,即變成了黑色背景。如果當前結構元素覆蓋下,全部都是背景,那么就不會對原圖做出改動,因為都是0;如果全部都是前景像素,也不會對原圖做出改動,因為都是1,只有結構元素位于前景物體邊緣的時候,它覆蓋的區域內才會出現0和1兩種不同的像素值,這個時候把當前像素替換成0就有變化了。腐蝕后的圖像整體會變暗,圖像中比較亮的區域的面積會變小甚至消失,而比較暗的區域會增大一些。
2OCR識別
通過對待檢測圖像進行處理后,能夠得到更加易于文字識別的圖像,本實施例中,將處理后的待檢測圖像輸入至Tesseract-OCR引擎中,Tesseract-OCR引擎對待檢測圖像進行文字識別得到待檢測圖像的文字信息。
Tesseract-OCR引擎使用到的靜態字符分類器,包含一種特別的設計思想,即分類器訓練與分類識別過程的分離。大多數分類器,其訓練樣本和識別字符具有同樣的處理方式,因而,只有當待識別字符與訓練樣本接近時,識別成功率才能夠到保證。Tesseract-OCR引擎使用了一種突破性的解決方式,在訓練樣本集時,系統選取字符的近似多邊形段作為特征;而在識別過程中,系統選取屬于字符邊界的固定長度的短線段作為特征,并使用多對一方式對應于系統的標準特征。
其文字識別的具體步驟如下[2]:
精選出可能與待檢測特征匹配的類別,未知字符每一個待識別特征通過查表可以得到一組可能與其匹配類別的向量,系統將這些匹配向量相加,選取出得分最高的幾個類別作為最有可能未知字符匹配的名單;
通過計算相似度確定最終類別,每一個標準字符都由一個邏輯合式代表,由此待識別特征與標準字符的“距離”可以被計算出來。最后,綜合得到的具有最短距離的類別,就是與未知字符相似度最高的類別。
Tesseract-OCR引擎的分類設計能夠識別受損字符,具有較強的魯棒性,所以在選取分類器的訓練樣本時就不需要引入損傷字符,并且其識別的速度和準確率較高。
識別出文字信息后,比較所述文字信息與預設文字信息是否一致,若一致,則表示機頂盒的信息正確,否則,表示機頂盒的信息有誤。
3結束語
經過實際實驗及實用,該方法在機頂盒自動檢測上具有非常好的效果。達到了預期設計目標。
參考文獻
[1] 章專,仲林國,朱志剛.基于圖像采集與處理的自動抄表系統[J].電測與儀表,2004,(1):19.
[2] 昝元寶,靳國榮.機械式水表讀數識別圖像預處理研究[J].信息化技術應用,2019(7):26-27.
