多語種網(wǎng)站平行語料采集與對齊研究
2020-11-16 06:56:38劉佳雨程南昌
數(shù)字技術(shù)與應(yīng)用 2020年9期
劉佳雨 程南昌

摘要:豐富的平行語料庫對提升機器翻譯準(zhǔn)確度意義重大,然而目前研究中缺乏有效的平行語料獲取方法,本文提出一種從多語種網(wǎng)站中自動獲取平行語料的方法,并且通過6個多語種網(wǎng)站的平行語料采集和對齊研究,驗證通過多語種網(wǎng)站獲取大規(guī)模平行語料具有較高的可行性,這說明通過多語種網(wǎng)站獲取大規(guī)模平行語料具有較高的可行性。
關(guān)鍵詞:多語種;新聞網(wǎng)站;平行語料;篇章對齊;機器翻譯
中圖分類號:TP391.2 文獻標(biāo)識碼:A 文章編號:1007-9416(2020)09-0214-04
0 引言
統(tǒng)計機器翻譯通常需要大規(guī)模的平行語料來不斷提高翻譯的準(zhǔn)確度,因此語料庫的規(guī)模與持續(xù)擴充是提高機器翻譯質(zhì)量的重要因素。平行語料的人工標(biāo)注難度很大,特別是小語種語料,而互聯(lián)網(wǎng)上存在著大量多語平行語料資源,并且這些語料是持續(xù)增長的。如何通過網(wǎng)絡(luò)爬蟲技術(shù)和雙語自動對齊技術(shù)從多語種網(wǎng)站采集并對齊語料,在機器翻譯領(lǐng)域是一件值得研究的事。
1 相關(guān)研究
1.1 機器翻譯的發(fā)展
Koehn[1]將機器翻譯的過程定義為計算機自動將一種語言轉(zhuǎn)化成具有相同意義的其他語言,機器翻譯已經(jīng)逐漸成為了互聯(lián)網(wǎng)信息服務(wù)中不可或缺的一環(huán)。朱杰[2]指出人們普遍認(rèn)為基于規(guī)則的方法和基于語料庫的方法是機器翻譯最常用的兩大類方法。隨著研究的深入,基于規(guī)則的方法逐漸暴露出質(zhì)量低,成本高等缺點,基于語料庫的方法開始流行。基于語料庫的方法又可分為基于統(tǒng)計和基于實例兩種,馮志偉[3]提到這兩種方法都需要將語料庫作為翻譯訓(xùn)練的來源,通過大量的語料統(tǒng)計來進行翻譯學(xué)習(xí)的數(shù)據(jù)獲取。但在統(tǒng)計翻譯模型面世很長一段時間內(nèi),語料的匱乏和缺失使得這種機器翻譯的人工成本增高。之后通過基于序列的遞歸神經(jīng)網(wǎng)絡(luò)自動獲取并記錄詞匯特征的方法出現(xiàn),機器翻譯在深度學(xué)習(xí)的發(fā)展中取得了突破性進展。
1.2 平行語料庫
機器翻譯相關(guān)的語料庫有平行語料、多語語料、可比語料這三種。平行語料指使用不同語言撰寫且存在對應(yīng)翻譯關(guān)系的文本數(shù)據(jù)集。肖維青[4]研究發(fā)現(xiàn)雙語平行語料庫在機器翻譯應(yīng)用中的作用越來越重要。目前用于機器翻譯的平行語料主要為多語或雙語平行句對。語料的規(guī)模影響著機器翻譯的質(zhì)量,另一個影響機器翻譯質(zhì)量的語料因素是語料的純凈度。邵健[5]將建立平行語料庫的方法總結(jié)為兩種:一是從數(shù)據(jù)庫或權(quán)威文檔中挖掘語料,二是從雙語網(wǎng)站獲取并整理生成平行語料。平行語料庫的建立主要是通過對已有數(shù)據(jù)庫的改造與處理,在權(quán)威的多語種文獻中提取可作為平行語料的語句。此外,隨著雙語網(wǎng)站的不斷增多,從互聯(lián)網(wǎng)獲取平行語料成為了語料擴充的重要渠道。
1.3 語料對齊
王斌[6]將語料對齊定義為確定源文本和目標(biāo)文本是否互為翻譯關(guān)系的過程。對于獲取的原始語料存在噪音的問題,因為不能直接使用在機器翻譯的模型訓(xùn)練中,所以需要通過篇章對齊等技術(shù)的處理,目前對齊主要思路是根據(jù)多語種語料間句子的特征尋找匹配度最高的句子,通過句子長度,詞匯信息等因素來匹配最合適的句子。
2 實驗過程
2.1 主要思路
選擇主流官方媒體人民網(wǎng),中國青年網(wǎng),外交部官方網(wǎng)站等擁有多語種的網(wǎng)站作為采集目標(biāo),官方新聞網(wǎng)站在不同語種頻道發(fā)布的新聞主要分為獨立編輯新聞和翻譯漢語新聞,根據(jù)需求進行篇章對齊的是后者。通過網(wǎng)頁代碼制定抓取規(guī)則,使用數(shù)據(jù)采集系統(tǒng)分別對上述網(wǎng)站的新聞進行抓取,分別選取其漢語、英語、日語、韓語、法語、俄語等多個不同語種頻道的新聞。抓取內(nèi)容包括標(biāo)題布時間、內(nèi)容等容易進行匹配的特征。
2.2 互聯(lián)網(wǎng)平行語料調(diào)研
目前互聯(lián)網(wǎng)上的多語種平行語料主要有精準(zhǔn)翻譯語料、雙語詞條語料、多語種新聞網(wǎng)站平行語料。
精準(zhǔn)翻譯語料以雙語詞條語料多存在于網(wǎng)絡(luò)詞典中。詞典語料的優(yōu)點對齊精度最高,主要是對齊到詞匯一級,但針對網(wǎng)絡(luò)詞典句子級采集有難度,而且例句之間有重復(fù)性,通過雙語詞典獲取的通常是一對多關(guān)系,其語料來源為已有實體詞典,更新頻率慢。
雙語詞條語料主要是發(fā)布的雙語對照新聞,以外交部發(fā)言人辦公室官方微信公眾號為例,在發(fā)布的例行記者發(fā)布會內(nèi)容中為一對一翻譯的雙語新聞,這種平行語料質(zhì)量高,可以直接作為機器翻譯的語料,但是這種平行語料較少且大部分只有中英對照,數(shù)據(jù)缺乏規(guī)模和普遍性。
多語種新聞網(wǎng)站平行語料是本次實驗所探究采集的語料,在國家級政府機構(gòu)的新聞網(wǎng)站會分為不同的語種頻道,一些新聞報道會在間隔較短的時間內(nèi)以不同語言發(fā)布在對應(yīng)網(wǎng)站。這些語料雖然不是精確到一對一翻譯,但能夠從相同事件的文本中獲取機器翻譯語料,同時數(shù)據(jù)每天更新,可以不斷豐富平行語料庫。
2.3 平行采集
使用爬蟲技術(shù)對選擇的多語種網(wǎng)站進行抓取,數(shù)據(jù)從互聯(lián)網(wǎng)采集到本地之后,將按照統(tǒng)一的標(biāo)準(zhǔn)進行數(shù)據(jù)分類,以.txt的格式存儲在對應(yīng)的文件夾中,通過設(shè)置對應(yīng)的路徑方便篇章對齊中文本數(shù)據(jù)的選取。
2.4 篇章對齊
對采集的語料進行分類后開始篇章對齊處理。如果篇章處理后發(fā)現(xiàn)網(wǎng)站的不同語種新聞存在較高的相似度,就可以將這些語料用于機器翻譯的學(xué)習(xí)中。在篇章對齊的實現(xiàn)過程中主要接入百度通用翻譯API,在調(diào)入接口的過程中設(shè)置自動識別語言,同時設(shè)置發(fā)送字符的換行符便于一次請求中翻譯多段文本。之前已經(jīng)對采集到的語料按照網(wǎng)站名稱和語種進行了分類,因此在篇章對齊的過程中只需要選中需要進行對齊操作的文件夾,通過采集新聞標(biāo)題中的時間進行匹配,設(shè)置好相似度即可。設(shè)置相似度的目的是為了根據(jù)需求來調(diào)控所需語料的精確度,同時也為了驗證選擇的網(wǎng)站在多語種頻道發(fā)布的新聞相關(guān)程度。
2.5 對齊質(zhì)量分析
采集對象主要是多語種網(wǎng)站,第一階段實現(xiàn)篇對篇對齊。第二階段開始考慮句子,詞匯。根據(jù)不同的相似度對采集的文本進行篇章對齊,對齊后的多語種文本以其中第一篇新聞標(biāo)題為名稱歸類于同一文件夾,同時進行漢語翻譯,用于判斷對齊質(zhì)量。篇章對齊后利用翻譯后的文本對比判斷多語種的新聞內(nèi)容關(guān)鍵詞是否相關(guān)。在本次實驗中主要確定觀察篇章對齊后新聞文本是否滿足作為雙語語料的基本條件,具體的判斷標(biāo)準(zhǔn)分為以下幾個層次:(1)文章內(nèi)容大致相同,逐句對應(yīng)程度高;(2)文章內(nèi)容不同,但是主題相對應(yīng);(3)文章內(nèi)容與主題不相同,其中只有幾個關(guān)鍵詞可對應(yīng)。
3 實驗結(jié)果分析
3.1 數(shù)據(jù)采集結(jié)果
本次實驗使用正則采集規(guī)則,從互聯(lián)網(wǎng)中采集到人民網(wǎng)、外交部官網(wǎng)、新華網(wǎng)、國際在線、中國青年網(wǎng)、中國網(wǎng)六個網(wǎng)站的不同語種頻道(主要為英、法、德、俄、日、韓)共1987條新聞數(shù)據(jù)。每條新聞為單獨的一個.txt文件,并按照來源、語種和時間進行了分類處理。
3.2 篇章對齊結(jié)果
對收集到的語料進行自動篇章對齊,選取2019年9月1日-2019年10月20日的新聞文本為對齊對象,通過相似比得到不同的對齊結(jié)果,從而分析不同網(wǎng)站多語頻道的文本對齊程度。先通過人工翻譯將相似文章進行人工對齊,然后導(dǎo)入軟件進行自動對齊,通過比較人工和軟件的篇章對齊結(jié)果,評測多語種網(wǎng)站是否具有作為平行語料的資質(zhì)。
3.2.1 人民網(wǎng)對齊結(jié)果分析
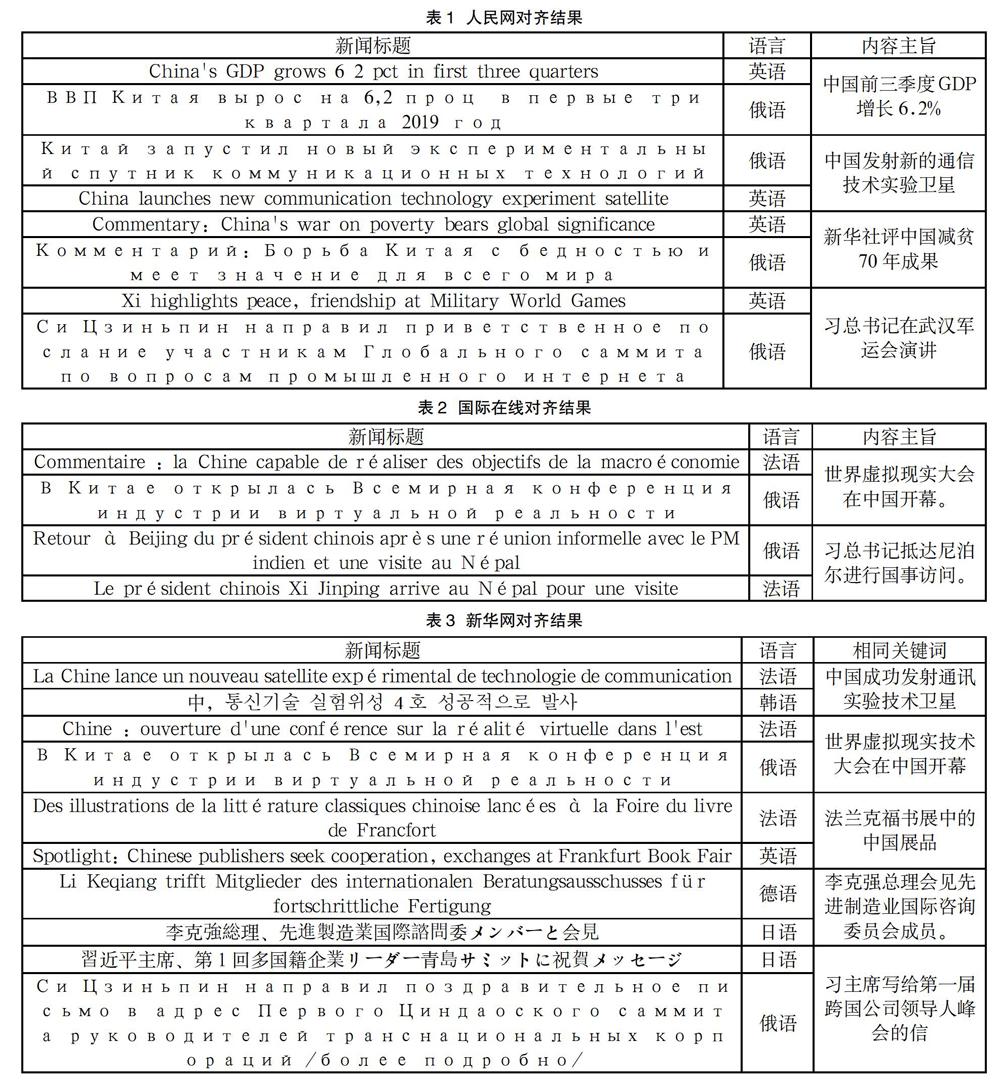
人民網(wǎng)采集數(shù)量如下:德語30篇、法語62篇、俄語85篇、韓語91篇、日語10篇、英語79篇。對人民網(wǎng)的新聞?wù)Z料進行人工對齊,共計有11項新聞?wù)Z料使用不同語種陳述相同事情,在相似度0.9的情況下進行篇章對齊,結(jié)果顯示在對齊的17項主題中,有4項主題與文本內(nèi)容一致,其余13項均為關(guān)鍵詞相同,與人工比對結(jié)果相比對齊效果較好,作為平行語料具有參考價值,文本對齊結(jié)果如表1所示。
3.2.2 外交部官網(wǎng)對齊結(jié)果分析
外交部官網(wǎng)采集數(shù)量如下:法語16篇、英語15篇、截止采集日期,外交部官網(wǎng)俄語頻道2018年3月份后無更新。人工對齊4篇相似主題新聞文章,在相似度比為0.9的情況下進行自動對齊結(jié)果為4篇同語種文章對齊,通過觀察發(fā)現(xiàn)原因是因為外交部官方網(wǎng)站采集的語料較少,無法覆蓋自動篇章對齊所需的數(shù)據(jù)量。但由于主要內(nèi)容針對的新聞方向是外交與國際,采集結(jié)果文本多以外交新聞為主,因此關(guān)鍵詞匹配度較高。
3.2.3 國際在線對齊結(jié)果分析
國際在線采集數(shù)量如下:德語26篇、法語37篇、俄語50篇、英語40篇。國際在線新聞文本人工對齊共8篇,4個主題。在相似度對為0.9的情況下使用軟件進行篇章對齊結(jié)果在9項對齊結(jié)果中有2項主題和文本內(nèi)容一致,其余7項均為部分關(guān)鍵詞相同,新聞采集和初步篇章對齊結(jié)果顯示國際在線多語種新聞文本可作為平行語料。文本內(nèi)容對齊結(jié)果如表2所示。
3.2.4 新華網(wǎng)對齊結(jié)果分析
新華網(wǎng)共采集新聞348篇,采集語料數(shù)量如下:德語51篇、法語50篇、俄語51篇、韓語64篇、日語67篇、英語65篇。人工對齊結(jié)果為8個主題,共18篇文章在新聞內(nèi)容上一致。對數(shù)據(jù)進行清洗后,在相似比為0.9的情況下對采集數(shù)據(jù)進行自動篇章對齊,在對篇章對齊結(jié)果進行數(shù)據(jù)清理后得到13項結(jié)果,其中5項對齊程度高新聞主題和內(nèi)容相同,剩余8項為部分關(guān)鍵詞相同。在篇章自動對齊結(jié)果中,新華網(wǎng)文本基本滿足了多語種語料篇章對齊的要求,對齊結(jié)果質(zhì)量較高,可以作為平行語料采用,具體對齊情況如表3所示。
3.2.5 中國青年網(wǎng)對齊結(jié)果分析
中國青年網(wǎng)共采集74篇,采集語料數(shù)量如下:法語20篇、俄語32篇、英語22篇。由于中國青年網(wǎng)部分網(wǎng)站運營出現(xiàn)問題,導(dǎo)致數(shù)據(jù)采集缺失。在后期人工對齊中,共有兩項主題內(nèi)容相同。通過軟件進行自動篇章對齊,無準(zhǔn)確結(jié)果,因此中國青年網(wǎng)不作為平行語料的采集對象。
3.2.6 中國網(wǎng)對齊結(jié)果分析
中國網(wǎng)共采集280篇,采集語料數(shù)量如下:德語44篇、法語60篇、俄語70篇、日語53篇、韓語54。人工對齊結(jié)果共有7項,16篇文本。使用軟件進行自動篇章對齊結(jié)果一共有7項,其中2項主題內(nèi)容相同,剩余5項為關(guān)鍵詞對齊。綜合對齊效果來看,中國網(wǎng)無論是從文章主題還是關(guān)鍵詞的角度對齊數(shù)量少,因此不適合作為平行語料的數(shù)據(jù)采集庫。
4 實驗結(jié)果分析
本文通過對六個多語種網(wǎng)站(人民網(wǎng)、新華網(wǎng)、中國青年網(wǎng)、外交部官方網(wǎng)站、中國網(wǎng)、國際在線)的不同語言頻道新聞進行采集和篇章對齊處理,得到以下結(jié)論:
(1)具備作為平行語料采集價值的多語種網(wǎng)站,其中人民網(wǎng)、新華網(wǎng)、外交部官網(wǎng)、國際在線這四個網(wǎng)站作為采集對象,通過篇章對齊后得到的文本對齊率高,自動對齊的文本較精準(zhǔn),可作為平行語料。另外兩個網(wǎng)站由于更新問題,暫時還不具備作為多語種平行語料的價值。
(2)傳統(tǒng)的平行語料大多來源自雙語數(shù)據(jù)庫,對擁有多語種頻道的新聞網(wǎng)站而言,通過篇章對齊獲得的平行語料相較傳統(tǒng)數(shù)據(jù)庫而言缺乏一定的精確性,但由于新聞需要每天更新,因此文本數(shù)據(jù)始終在增加,這樣平行語料就會處于一直增加的狀態(tài),同時多語種網(wǎng)站提供了不同的語種組合,所以可以獲得更多種語言的平行語料。下一步的工作主要是提高篇章對齊的準(zhǔn)確度,從篇章對齊延伸至句子對齊,同時從具有平行語料價值的網(wǎng)站中獲取更多的多語種文本。
參考文獻
[1] Koehn P.Statistical machine translation[M].Cambridge:Cambridge University Press,2010.
[2] 朱杰,古明.基于語料庫的機器翻譯[J].現(xiàn)代交際,2019(17):100-101.
[3] 馮志偉.基于語料庫的機器翻譯系統(tǒng)[J].術(shù)語標(biāo)準(zhǔn)化與信息技術(shù),2010(1):28-35.
[4] 肖維青.平行語料庫與應(yīng)用翻譯研究[J].中國科技翻譯,2007(3):25-28.
[5] 邵健,章成志.從互聯(lián)網(wǎng)上自動獲取領(lǐng)域平行語料[J].現(xiàn)代圖書情報技術(shù),2014(12):36-43.
[6] 王斌.漢英雙語語料庫自動對齊研究[D].北京:中國科學(xué)院研究生院(計算技術(shù)研究所),1999.
