基于TextRank的軟件變更任務(wù)搜索術(shù)語識別①
2020-11-13 07:12:36王杉
計算機系統(tǒng)應(yīng)用 2020年10期
王 杉
(云南大學滇池學院 理工學院,昆明 650228)
軟件工程研究表明,在軟件開發(fā)過程中,用于軟件維護和演進的投入占總投入的大約70%?80%[1].在軟件維護期,開發(fā)者通常會處理很多軟件變更的請求,這需要確定變更任務(wù)在軟件項目中的確切位置(更改的類或方法).變更請求通常是由用戶提出的,因此一般都用自然語言編寫,并且軟件用戶雖然熟悉軟件產(chǎn)品的應(yīng)用領(lǐng)域,但他們卻很難具備在源代碼中實現(xiàn)功能的能力.另一方面,參與維護的人員也不了解項目的底層架構(gòu),他們在識別需要更改的源碼位置也有困難.因此需要進行一種從軟件變更處到源碼位置(類、方法等)的映射,該映射任務(wù)通過一個或多個搜索項,從項目內(nèi)進行搜索,最終得到映射位置,以快速而準確地完成軟件變更任務(wù).
在以往的研究中,有一些嘗試通過搜索查詢以支持開發(fā)者進行功能定位任務(wù)的方法,例如輕量級啟發(fā)式方法[2]、查詢重構(gòu)或擴展策略[3]、查詢質(zhì)量分析法[4]、數(shù)據(jù)字典及挖掘方法[5]等.這些方法都要求開發(fā)者能提供可改進的初始搜索查詢,而對于開發(fā)者來說,這也是一項繁重的任務(wù).其中,Kevic 和Fritz 提出了一種用于自動識別軟件變更任務(wù)的初始搜索項的啟發(fā)式模型[2],模型考慮了與搜索頻率、位置、詞性和任務(wù)描述術(shù)語符號相關(guān)的啟發(fā)法.該模型在一定程度上解決了上述問題,但也存在兩個不足:首先,模型使用有限數(shù)量的變更任務(wù)進行訓練,缺乏其他項目的變更任務(wù)進行交叉驗證,成熟度和可靠性有限;其次,模型把tfidf 作為主要度量參數(shù),而idf 計算受測試數(shù)據(jù)集大小的影響,對于不同大小的測試數(shù)據(jù)集,會造成相同模型呈現(xiàn)不同的表現(xiàn),并且模型可能需要頻繁的重新訓練以保持其可用性.
在本文中,提出了一種基于TextRank 進行自動識別并得到軟件變更任務(wù)搜索術(shù)語的方法.TextRank 方法是PageRank 方法的改進[6],對于自然語言文本,其中的文本可被視為詞匯的詞匯或語義網(wǎng)絡(luò).TextRank 技術(shù)被廣泛應(yīng)用于各類信息檢索中,例如關(guān)鍵字提取、摘要提取、詞義消歧、詞法分析和其他基于圖的屬于加權(quán)任務(wù).因此該算法適合在特征定位任務(wù)的上下文中進行搜索項提取,這是因為軟件變更請求通常由開發(fā)團隊以外的人員進行,他們通過相關(guān)問題域的概念和自然語言文本來表達需求,并可以使用基于圖的任務(wù)描述來揭示不同術(shù)語之間的重要語義關(guān)系.其次,TextRank 算法利用圖中術(shù)語的連通性,用于確定該術(shù)語的權(quán)重(即重要性),然后遞歸執(zhí)行該過程,從而確定出搜索術(shù)語.
例如,在表1中顯示的軟件變更任務(wù)可以圖的方式表示為圖1中的文本圖.本文提出的方法分析圖中術(shù)語的連通性,計算每個術(shù)語的權(quán)重(即重要性),然后提取最高權(quán)重和最適合的五個術(shù)語:Mac,selection,installs,improvement 和JREs,作為搜索任務(wù)的初始搜索項進行查詢.
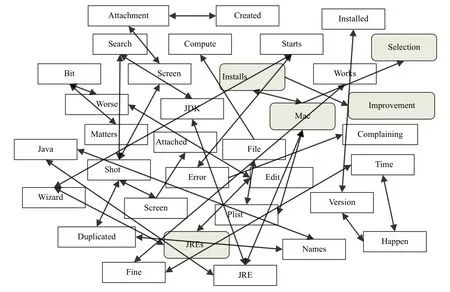
圖1 表1中的變更請求文本圖
并且選取了兩個主題系統(tǒng)Apache Log4j(日志分析)和Eclipse JDT Debug 中的336 個變更任務(wù)進行實驗,實驗表明了提出的方法可以返回49.65%的變更任務(wù)相關(guān)結(jié)果(即Java 類),平均精度為58.00%,召回率達63.48%.與Kevic 和Fritz 的方法[2]比較,本文提出的方法在各項評價指標上有更好的表現(xiàn).因此,本文做了以下工作:
① 展示了TextRank 算法在識別和獲取軟件變更任務(wù)的相關(guān)搜索術(shù)語中的新用途.
② 通過一個涉及兩個主題系統(tǒng)的軟件變更任務(wù)案例研究,并與Kevic 和Fritz 的現(xiàn)有方法進行比較,展示了所提出方法的有效性.
1 方法
圖2展示了提出方法的搜索識別技術(shù)示意圖和變更任務(wù)的基本步驟.接下來將討論該方法涉及的步驟.

圖2 所提出方法的示意圖
1.1 變更任務(wù)的數(shù)據(jù)采集
通常,同戶提供的軟件變更任務(wù)是使用自然語言描述的(如表1所示),通過收集了336 個開發(fā)實際任務(wù)作為數(shù)據(jù)集進行分析.這些任務(wù)用半結(jié)構(gòu)化的方式提交,包含了問題ID、產(chǎn)品、組件、摘要、描述等幾個字段,由于任務(wù)變更的具體問題基本都只在摘要和描述中提及,因此分析僅選取最后兩個字段的內(nèi)容.同時為了保持算法的簡單性和輕量級,也暫時不考慮其他附加到更改任務(wù)中的額外信息.
1.2 文本預處理
在這一步驟中,將分析軟件變更請求中的摘要和描述,并在將文本轉(zhuǎn)化為文本圖之前進行多個預處理.預處理將每個句子視為一個邏輯文本單元,這樣有助于整體任務(wù)描述,接下來從每個句子中提取能傳達有用語義或表達軟件問題域的術(shù)語,然后從句子里刪除副詞、介詞等非重要詞,并將包含分隔符號(例如“.”)的詞分解為組成它們的更簡單的詞.這樣的分解有助于單獨分析每個概念.例如:”org.eclipse.ui.part.PageBook View.createPartControl”,這個句子包含了一個包名(org.eclipse.ui.part)、一個類名(PageBookView)和一個方法名(createPartControl).需要指出的是,在這里不采用軟件代碼標識符命名規(guī)則里常用的“駝峰大小寫”表示法進行拆分,因為變更請求可能包含不同的技術(shù)工件,例如庫名、類名、方法名等,這些名稱往往已經(jīng)使用了“駝峰大小寫”,那么進一步拆分會破壞工件的完整性.
1.3 文本圖開發(fā)
在文本預處理之后,將會得到一個句子列表,每個句子都包含有在語義上很重要的術(shù)語以及與問題域相關(guān)的術(shù)語,然后使用這些術(shù)語來描述任務(wù)的開發(fā)術(shù)語圖.可以將每一個術(shù)語表示為圖中的不同節(jié)點,并考慮句子中這些術(shù)語的“同現(xiàn)”,作為它們之間語義關(guān)系(依賴關(guān)系)的指征[6].例如考慮句子“This works fine most of the time,but if you happen to have more than one of the same version of VM installed they are added with the same name”(表1),預處理會形成一個有序的術(shù)語短句:“works fine time happen version installed”.轉(zhuǎn)換后的句子會包含“works fine”、“version installed”等短語,這些短語中的術(shù)語在語義上依賴,當“窗口大小”以2 作為單詞的語義單位時[6],可獲得以下關(guān)系:works←→fine,fine←→time,time←→happen,happen←→version,version←→installed.然后將這種關(guān)系表示為文本圖中相應(yīng)節(jié)點之間的鄰接邊.
1.4 TextRank 計算
為了計算文本圖中每個術(shù)語的權(quán)重(重要性),方法采用了一種基于Web 鏈接分析的PageRank 改進的TextRank 算法[6].該算法遞歸分析文本圖中每個術(shù)語的傳入鏈接和傳出鏈接等細節(jié),并計算其權(quán)重W(Vi),如下式所示:
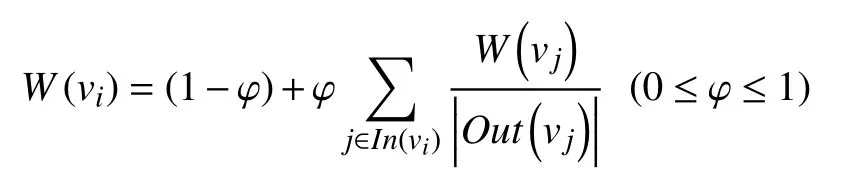
這里,In(vi)表示通過輸入鏈路指向vi的節(jié)點集合,Out(vj)表示由vj發(fā)出的輸出鏈路指向的節(jié)點集合,φ表示阻尼系數(shù).在文本圖中,每條邊都是無向邊(即術(shù)語彼此依賴),因此節(jié)點入度等于出度.對于φ的取值,通常按一般取值為0.85,然后采用0.25 的默認值初始化圖中每個術(shù)語,并開始迭代計算,直到項的分數(shù)收斂到0.0001 的極限值或達到最大迭代限制值100.基于TextRank 的推薦機制,如果術(shù)語B 以任何方式補充術(shù)語A 的語義,則術(shù)語A 就推薦術(shù)語B[6],那么這個算法將根據(jù)文本圖中個的傳入鏈接獲得對術(shù)語的推薦,并確定術(shù)語的重要性.一旦計算結(jié)束,圖中的每個術(shù)語都會得到一個分值,該分值可被認為是這個術(shù)語在文本中的權(quán)重(重要性).
1.5 搜索術(shù)語選擇
計算TextRank 后,會根據(jù)權(quán)重對術(shù)語進行排序,并以啟發(fā)方式選擇變更任務(wù)的搜索術(shù)語,其中任務(wù)“摘要”和“描述”中的術(shù)語最適合作為搜索術(shù)語.但是這些字段中的術(shù)語存在重疊而不足以形成搜索查詢,因此需對其進行調(diào)整.首先在變更任務(wù)的摘要中查找權(quán)重最高的術(shù)語,如果摘要內(nèi)容太少而無法提供所有條件,那么就從任務(wù)描述中收集其余內(nèi)容.然后基于它們的權(quán)重或等級來選擇術(shù)語,這些術(shù)語是通過遞歸分析文本圖中該術(shù)語周圍的術(shù)語計算出的.例如表1所示的變更任務(wù),得到搜索項:Mac (權(quán)重0.64)、selection (權(quán)重0.27)、installs (權(quán)重0.27)、improvement (權(quán)重0.25)和JREs (權(quán)重1.0,來源于描述).
2 實驗
為了驗證本文所提出的方法,將使用了兩個開源的主題系統(tǒng)的變更任務(wù)進行實驗,分別是eclipse 中的調(diào)試模型插件eclipse.jdt.debug,以及Apache 的日志操作包Log4j.并與一種現(xiàn)有的方法進行了比較.
2.1 數(shù)據(jù)集和文件搜索
實驗中,選擇了兩個開源主題系統(tǒng)的變更請求任務(wù).首先從缺陷追蹤數(shù)據(jù)庫BugZilla 中收集變更任務(wù),分析其BugID(變更任務(wù)的標識),然后根據(jù)BugID 從來源代碼數(shù)據(jù)庫GitHub 中找到相應(yīng)的項目(GitHub中,每個軟件錯誤解決和變更請求的提交操作通常會在其提交消息中提到相應(yīng)BugID).基于此,在Log4j 中發(fā)現(xiàn)了223 次提交,在eclipse.jdt.debug 中發(fā)現(xiàn)了113次提交,共計336 個變更任務(wù).
然后,為每個變更任務(wù)收集變更集(即已更改文件列表),并開發(fā)解決方案集.為了搜索變更任務(wù)的文件,采用了基于向量空間模型的搜索引擎Apache Lucene[7].由于項目中的源文件會包含常規(guī)文本外的內(nèi)容(例如代碼段),那么將對每個源文件應(yīng)用有限的預處理,刪除所有標點符號,這就會將源代碼轉(zhuǎn)換為純文本,有助于搜索引擎更有效地執(zhí)行.啟動搜索后,搜索引擎使用布爾搜索模型過濾語料庫中的無關(guān)文件,并應(yīng)用基于tf-idf 的評分技術(shù)來返回相關(guān)文檔的排序列表,最后選擇返回的排名前10 以內(nèi)的結(jié)果項進行操作.
2.2 評價指標
為了清晰地評價提出方法的效果和性能,會采用K值平均精確率(MAPK)和平均召回率(MR)兩個主要指標,對搜索結(jié)果進行評價.K值平均精確率用于表示所有搜索結(jié)果的平均相關(guān)精度,即查準率;平均召回率用于表示搜索到的結(jié)果集的返回率,即查全率.
2.3 實驗結(jié)果
對兩個開源的主題系統(tǒng)的336 個變更任務(wù)進行了實驗,并應(yīng)用解決任務(wù)數(shù)、解決任務(wù)百分比、平均精確率和平均召回率4 個不同的指標進行總結(jié).結(jié)果如表2所示.
從實驗結(jié)果表中可以看到,當使用5 個搜索詞時,查詢效果最佳.例如,它們返回了來自Log4j 的223 個更改任務(wù)中的107 個(47.98%)的相關(guān)結(jié)果,以及來自eclipse.jdt.debug 的113 個更改任務(wù)中的58 個(51.33%),這是預期良好的.因此,平均而言,該查詢從數(shù)據(jù)集中檢索63.48%的解決方案,平均精度為58.00%.

表2 實驗結(jié)果指標
為了從其他方面評估提出方法的性能,還從以下幾個方面進行了實驗:
① 使用6 個搜索詞進行查詢,但是查詢結(jié)果在這兩個主題系統(tǒng)中表現(xiàn)相對較差.
② 在沒有預處理的情況下,基于現(xiàn)有語料庫重新進行了實驗,沒有出現(xiàn)較明顯的性能下降,證明了提出的搜索術(shù)語對于變更任務(wù)的穩(wěn)健性.
③ 在變更任務(wù)中,不采用TextRank 計算,而是隨機選擇了五個搜索詞進行查詢,結(jié)果非常糟糕,從log4j只返回最多52 個任務(wù)的相關(guān)結(jié)果,從eclipse.jdt.debug只返回37 個任務(wù)(本文的方法返回了107 個和58 個結(jié)果).
④ 將變更任務(wù)調(diào)整為中文描述,按中文文法進行預處理后,該方法仍能以較好的召回率和精度得到搜索結(jié)果,說明該方法有良好的語言通用性.
因此,實驗結(jié)果表明,本文提出的搜索詞方法和技術(shù)能完成任務(wù),并且有不錯的可靠性、穩(wěn)定性和通用性.
3 結(jié)論和未來工作
總而言之,本文提出了一種新的基于TextRank 的技術(shù)方法,可以自動識別并得到軟件更改任務(wù)的搜索項.通過來自兩個主題系統(tǒng)的336 個更改任務(wù)的實驗表明,該方法平均可以返回49.65%的變更任務(wù)的相關(guān)結(jié)果(即Java 類),平均精度為58.00%,召回率為63.48%.方法能完成預期目標,并具有良好的性能.
雖然這些初步研究結(jié)果證明了該方法的潛力,但需要驗證更多不同類型和變化任務(wù)的主題系統(tǒng),例如更大體量的中文數(shù)據(jù)集等,以期進一步改進該方法的性能,獲得更好的應(yīng)用前景.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
