基于EEMD-ARIMA的年降水預測擬合模型研究
2020-11-12 10:38:46李智強鄒紅霞郭江昆
計算機應用與軟件 2020年11期
李智強 鄒紅霞 齊 斌 郭江昆
(航天工程大學航天信息學院 北京 101400)
0 引 言
年降水量變化一直都是氣象科學界對氣候變化研究的熱點問題。年降水量的變化對河流徑流量有著直接影響,同時還緊密地關系到農業發展和糧食安全,對年降水量序列變化的研究可以為洪澇、干旱災害的預測預防提供參考,為農業生產提供有利條件。年降水量變化受到地理、季風、海洋和太陽等多方面的影響[1],影響降水的特征指標眾多,比如高原積雪、海表溫度、ENSO、季風等多種特征因子[2],其內部機理異常復雜,因此目前大部分的年降水量預測方法主要為氣象學方法。雖然現有的氣象學預測方法已經有了廣泛的應用[3-5],但是由于氣象學方法的自變量難以確定,模型的計算量也異常巨大。時間序列的ARIMA分析方法不用考慮復雜的影響因素,計算量小,因此在降水研究中也有應用[6-7],但是ARIMA方法對于非線性序列的擬合效果不好,而年際降水序列大多都是非線性的[8]。
為解決上述問題,有學者提出了基于集合經驗模態分解(Ensemble Empirical Mode Decomposition,EEMD)的ARIMA時間序列模型[9],主要得益于EEMD能夠自適應地處理任意非線性非平穩時間序列的特點。文獻[10]的研究表明,EEMD-ARIMA模型在短期徑流上的預測精度高于傳統ARIMA模型。
1 相關模型
1.1 EMD和EEMD
由于EEMD是在經驗模態分解EMD基礎上的改進,因此先介紹EMD的方法原理。EMD比小波和傅里葉分解變換具有更好的時頻分辨率和自適應的特點,且其在非平穩、非線性的信號時頻序列處理上表現更加優秀,該方法在海洋、大氣和天體觀測等領域有應用。
經驗模態分解的關鍵就是將復雜的信號分解為有限個本征模函數(Intrinsic Mode Function,IMF),其計算方法如下:
首先取原始序列信號X(t)的所有極值點,通過三次樣條插值函數[11]分別連接所有極大值點和所有極小值點,形成上包絡線和下包絡線,使得整個序列信號都在上下包絡線中,將原序列減去上下包絡線的均值m1,得到新的序列h1(t),即:
X(t)-m1=h1(t)
(1)
一般來說,h1(t)還不是IMF分量,通過一次的篩選不一定能得到平穩序列,因此需要重復以上過程,第二次篩選將h1(t)作為被分解序列。假設h1(t)的包絡均值為m11,則得到的新的序列h11(t),即:
h1(t)-m11=h11(t)
(2)
篩選的目的是消除噪聲波,使波形輪廓對稱,直到第k次的篩選,得到的波形第一個滿足IMF定義的分量h1k(t),將第一個IMF分量h1k(t)用c1表示。
c1(t)=h1k
(3)
一個原始信號一般由多個IMF分量組成,由式(3)可得剩余分量r1(t),然后將剩余分量r1(t)作為新的被分解信號,此過程一直重復,直到滿足以下條件之一:(1) 最后一個剩余量rn(t)或IMF分量cn(t)小于某個給定的常量;(2) 剩余量rn(t)為單調函數。
X(t)-c1(t)=r1(t)
r1(t)-c2(t)=r2(t)
(4)
?
rn-1(t)-cn(t)=rn(t)
最終原始信號被分解為n個不同周期和不同頻率的IMF分量和一個殘差量:
(5)
雖然EMD基于數據本身變化,使得IMF與采樣頻率相關,克服了傅里葉變換的局限性,但是EMD存在的一個重要問題就是IMF分量存在模態混疊[12],為了更好地解決這一問題,Wu等[13]提出了集合經驗模態分解(EEMD)。
EEMD是基于噪聲輔助分析的方法,原理較為簡單,通過在年降水序列中加入白噪聲,白噪聲頻譜均勻分布,使得信號自動分布到合適的尺度上。由EMD的零均值特性,噪聲在多次平均計算后會相互抵消,從而得到的集成均值計算結果即可視為最終結果,最終結果與原始序列的誤差隨著集成平均次數的增加而減小。因此從理論上講,EEMD對抑制EMD的模態重疊有較好的效果。EEMD的算法流程如圖1所示。
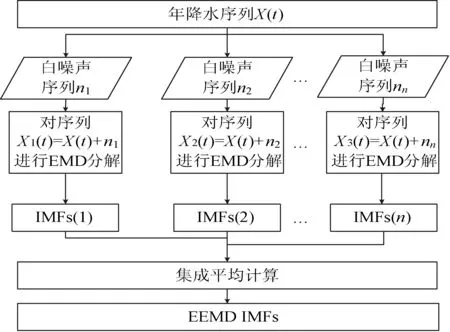
圖1 EEMD算法流程示意圖
1.2 ARIMA模型
通過EEMD分解得到不同周期的IMF分量后,對分量建立擬合模型。差分自回歸移動平均模型ARIMA是在ARMA模型針對非平穩序列模型擬合效果差的基礎上作出的改進,通過將非平穩序列進行一次或多次差分轉換成平穩序列,再進行ARMA擬合,其構成如下:
ARIMA(p,d,q)=AR(p)+Difference(d)+MA(q)
(6)
式中:AR(p)、Difference(d)、MA(q)分別為自回歸模型、差分模型和移動平均模型;p、d、q分別為自回歸項、差分階數和移動平均項數,這三個參數決定了模型的好壞。ARIMA模型預測方程如下:
xt=φ0+φ1xt-1+φ2xt-2+…+φpxt-p+
εt+γ1εt-1+γ2εt-2+…+γqεt-q
(7)
式中:xt為樣本值;εt為當期隨機誤差干擾;φi和γj為模型參數;p、d、q是模型階數。xt為前p階xt-1,xt-2,…,xt-p和前q階εt-1,εt-2,…,εt-q的多元線性函數。ARIMA的建模流程如圖2所示。
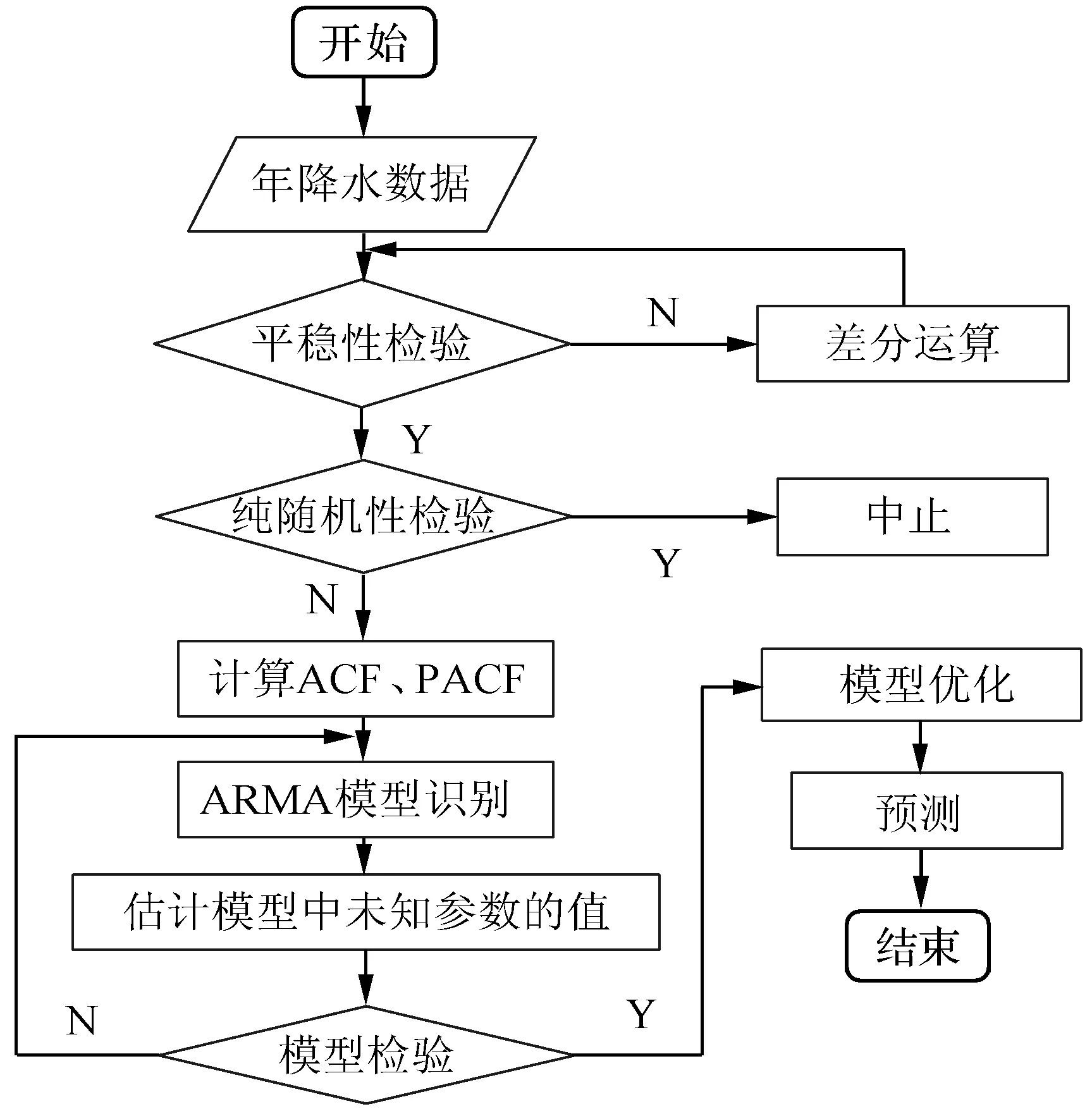
圖2 ARIMA建模流程
2 EEMD-ARIMA模型
2.1 模型框架
EEMD是在對EMD做白噪聲統計實驗時提出的,由于EEMD分解克服了EMD分解過程中產生模態混疊的問題,因此在序列擬合預測中更具優勢。本文針對降水時間序列的特點,首先對降水序列EEMD分解,然后對分解后的序列做白噪聲檢驗,一般EEMD會將高頻的白噪聲分量直接刪除,但這樣會直接影響模型擬合的精度。本文的做法是保留分離出來的白噪聲分量,對其也建立ARIMA模型以降低擬合誤差,對其他的分量進行平穩性判別,然后對平穩序列建立ARMA模型,對非平穩序列建立ARIMA模型,最后對剩余模型擬合分量重構和評價。
本文基于EEMD-ARIMA的年降水序列模型,其整體框架如圖3所示。首先通過EEMD分解得到n-1個分量和一個剩余分量,通過白噪聲檢驗后單獨對白噪聲分量建立ARIMA模型,然后對各IMF分量進行平穩性判別,平穩序列采取ARMA模型擬合,非平穩序列采用ARIMA模型擬合,最后對各個分量進行疊加重構并進行模型評價。其模型框架如圖3所示。

圖3 EEMD-ARIMA模型框架
2.2 評價指標
為了驗證EEMD-ARIMA模型擬合效果是否優于EMD-ARIMA模型以及單一的EMD、ARIMA、EEMD模型,引入均方根誤差(RMSE)和平均相對誤差(MRE)兩個指標來檢驗模型的預測效果。均方根誤差(RMSE)能夠從總體上反映預測值的離散程度,其公式如下:
(8)
平均相對誤差(MRE)能夠反映模型誤差的大小以及模型預測的準確程度,其計算公式如下:
(9)
在實際的年際降水預測中,通常采用趨勢分析的方式,離精準預測的水平還相差甚遠。由于中長期預報的復雜性,當預測值與實際值的相對誤差低于20%時即視為正確[14],正確率公式如下:
(10)
3 模型實證分析
首先通過數據預處理得到原始年降水序列,然后根據EEMD-ARIMA模型框架進行模型的建立和訓練,為了檢驗該模型的應用效果,還建立了EMD、EEMD分解-重構模型、ARIMA模型和EMD-ARIMA模型,以便進行對比分析。
3.1 數據來源及實驗環境
本文的實驗數據來源于《中國地面氣候月值數據集3.0》,選取[52984]臨夏地面氣象觀測站1953年—2012年共60年的逐日降水資料,通過數據預處理得到60年的年降水序列。由于時間序列預測精度隨時間的增加而降低的特性,為了保證模型的穩定性和可靠性,選取前57年數據進行建模訓練,后3年數據用于預測。實證分析使用Python開發語言,使用Jupyter Notebook交互式編程平臺,ARIMA模型構建選取Statsmodels庫。
3.2 數據預處理
《中國地面氣候資料月值數據集3.0》中的文件命名為:SURF_CLI_CHN_MUL_MON-YYYY.txt,其中“SURF_CLI_CHN_MUL_MON”為數據集代碼,文件按年份拆分,文件名中的“YYYY”表示年份。
數據集包括了中國752個基本、基準地面氣象觀測站及自動站自1951年以來的氣候資料月值數據集。本文從數據集中選取了降水數據集,其格式如圖4(a)所示;降水數據集中文件內部數據形式如圖4(b)所示;截取出[52984]臨夏氣象站共60年的逐日降水量數據,其數據格式如圖4(c)所示,可見數據中存在“32766”、“32700”等異常值,分別表示缺測、微量數據,因此均選取零值填充;通過缺失填充、數據集成,將日降水量以年為單位分別累加求和,最終得到年降水序列,如圖4(d)所示。
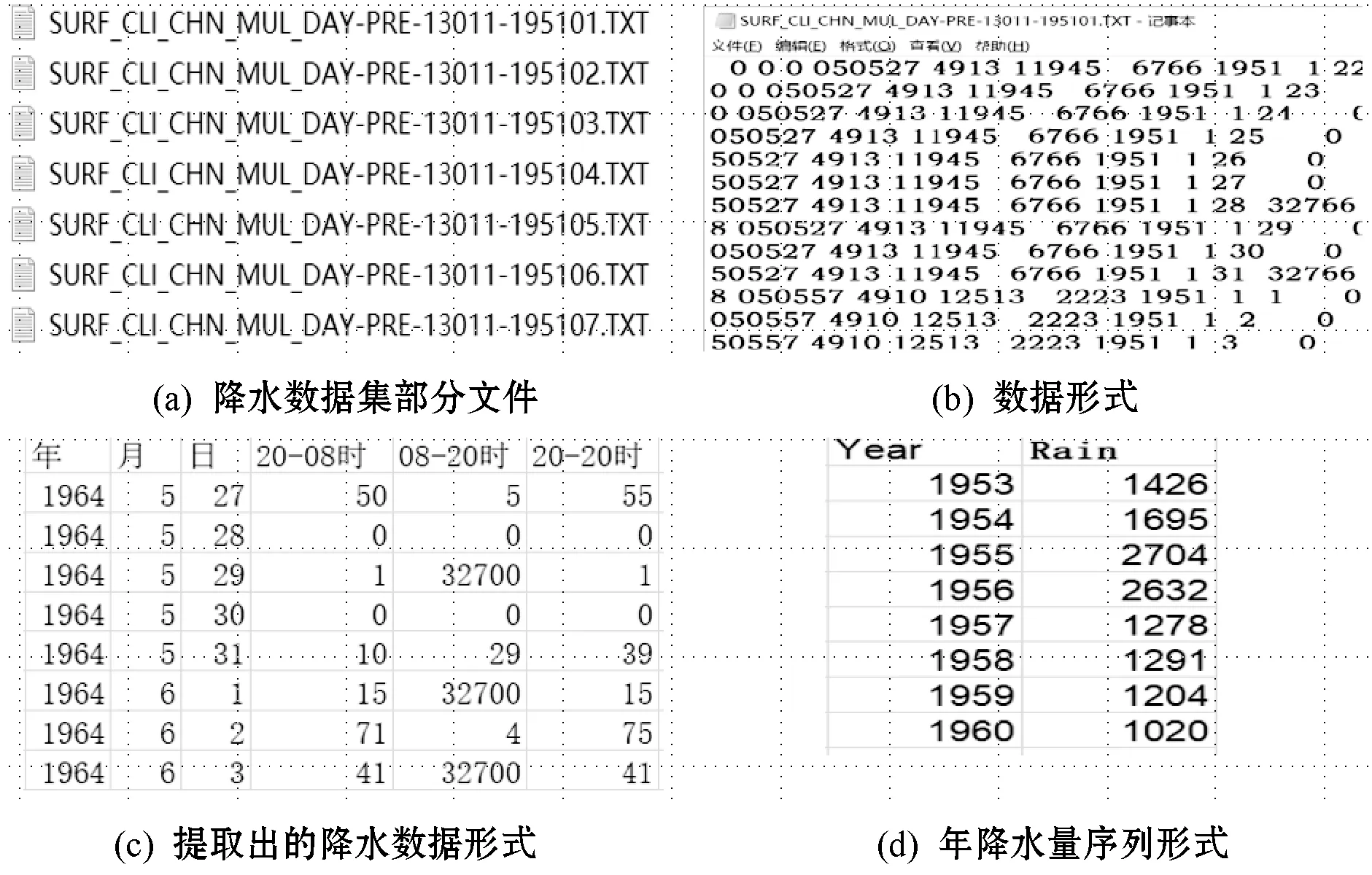
圖4 數據預處理過程
3.3 模型建立
1) EEMD的分解。根據EEMD的算法流程,將57年的年降水序列按照添加噪聲、EMD分解、計算集成的順序,通過Python語言實現EEMD的分解,部分代碼如下:
eemd=EEMD()
eemd.trials=50
eemd.noise_seed(12345)
E_IMFs=eemd.eemd(S, T, max_imf)
imfNo=E_IMFs.shape[0]
最終得到4個IMF分量序列(IMF1-IMF4)和1個剩余分量IMF5,如圖5所示,其中:橫坐標為時間,縱坐標為降水量。
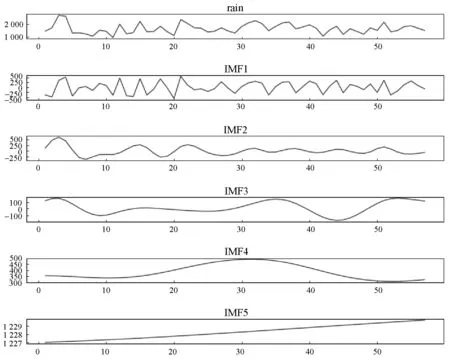
圖5 EEMD年降水序列分解圖
可以看出:IMF1頻率最高,IMF2、IMF3、IMF4頻率依次降低,IMF5為殘余分量,為遞減的單調函數。最高頻率的IMF1代表時間周期較短的隨機波動,一般作為噪聲處理。但是噪聲的直接刪除會導致擬合和預測的精度大大降低,因此同樣將隨機波動也進行擬合,能夠降低模型誤差。
2) 白噪聲檢測。白噪聲檢測又稱為純隨機性檢測,通過白噪聲檢測,檢測各IMF分量中是否含有沒有意義的純隨機序列,一般對于純隨機序列,都采取舍棄的原則。常用的白噪聲檢測方法包括Ljung Box假設檢驗和Box Pierce假設檢驗[15]。除此之外,通過自相關和偏自相關函數圖,也能從經驗上判斷出序列是否是白噪聲序列。首先通過各個IMF分量的自相關和偏自相關圖,可以確定是否存在白噪聲序列,如圖6所示。由于IMF1分量的自相關和偏自相關階數幾乎都落在置信區間內,其自相關性較小,因此判斷IMF1分量為可能的隨機性序列。

圖6 IMF分量自相關和偏自相關圖
3) 平穩性判別。判斷序列的平穩性是為了建立更好的模型,平穩性判斷除了根據圖5進行主觀判斷外,常用擴展迪基-福勒檢驗(Augmented Dickey-Fuller,ADF)[16]進一步確定平穩性。對各個IMF的ADF檢驗結果如表1所示。

表1 ADF 平穩性檢驗結果
可以看出,IMF1、IMF2、IMF3的T統計值均小于各自1%顯著性水平,同時P值接近0,IMF1、IMF2、IMF3分量為平穩序列,IMF4、IMF5的T統計值均大于10%顯著性水平,IMF4、IMF5為非平穩序列,與圖5的結果一致。因此,對前3個IMF分量用ARMA模型擬合,后兩個IMF分量用ARIMA模型進行擬合。
4) 模型擬合。在年際降水預測中,大多學者選擇使用單一ARIMA時間序列模型。本文在考慮時間序列數據含有噪聲和多重頻率特性的基礎上,將序列進行EMD分解,將復雜序列變為多個簡單序列和一個殘差序列。由于EMD分解會產生模態重疊,因此使用EMD的改進算法EEMD,對得到的簡單序列和殘差序進行白噪聲和平穩性檢驗后,得到平穩分量IMF1、IMF2、IMF3和非平穩序列IMF4、IMF5,并分別采用ARMA模型和ARIMA模型進行擬合,通過參數優化。建模及優化部分代碼如下:
order0=st.arma_order_select_ic(imf0,max_ar=5,max_ma=5,ic=[′aic′, ′bic′, ′hqic′])
arma_mod10=ARMA(imf0,(2,0)).fit()
pimf0=arma_mod10.fittedvalues
ax1.plot(imf0)
筆者做完自我介紹和簡單的開場白,考慮和新員工年齡差距較小,設計的PPT可以自動播放和用激光筆遠程控制,對于所講內容成竹在胸,于是就嘗試走進新員工中間去說,拉近了彼此之間的物理距離。這個嘗試,有比較好的收效,全程半個小時的授課過程中,基本沒有看到新員工們有低頭看手機的現象。
ax1.plot(pimf0,′--′,color=′red′)
對IMF1、IMF2、IMF3、IMF4、IMF5分別選取ARMA(2,0)、ARMA(4,2)、ARMA(2,4)、ARIMA(5,0,1)、ARIMA(1,1,1)5個模型進行擬合,擬合結果如圖7所示。

圖7 分量擬合結果
可以看出,ARMA對于IMF1分量的擬合效果還不夠理想,相比于直接舍棄高頻分量,該IMF1分量將大大降低對擬合結果的誤差,IMF2、IMF3、IMF4、IMF5分量的擬合效果較好。EEMD和EMD都具有完備性,即將全部分解的分量直接相加就能重構出原信號。因此通過對各個分量的重構,就能得到非常接近原始序列的新序列,誤差接近0。從模型訓練的結果來看,低頻的分量擬合效果比高頻分量的擬合效果好。
3.4 模型對比分析
3.4.1模型結果
為了得到直觀的對比,同時對同一年降水序列建立了EMD模型、ARIMA模型、EEMD模型和EMD-ARIMA模型,其中EMD模型和EEMD模型均采用了分解-刪除高頻分量-重構的方法,ARIMA模型是直接對年降水序列建立的,經過參數調優,設定為ARIMA(1,0,1)。得到的各個模型最終結果對比如圖8所示。
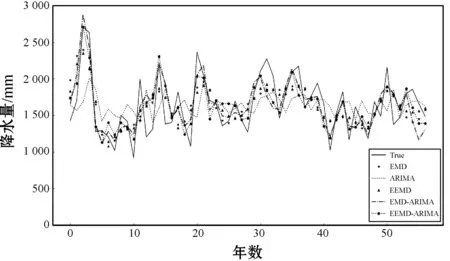
圖8 各模型結果對比
通過圖8的模型結果對比分析,有以下4點結論:(1) 5個模型都能反映出真實年降水序列的波動趨勢;(2) 從EEMD模型和EMD模型的擬合結果看,二者的擬合效果都比較平滑,且EEMD的擬合效果要略好于EMD模型;(3) EMD-ARIMA模型和EEMD-ARIMA模型擬合效果均好于單一模型,單一模型的擬合值波動幅度范圍偏小;(4) EEMD-ARIMA模型和EMD-ARIMA模型結果的走勢大致相同,但EMD-ARIMA在極值點處的擬合效果更加激進,單從擬合效果圖分析,還不能確定兩類模型的優劣。
3.4.2模型評價
5個模型的擬合結果的誤差分析如表2所示。
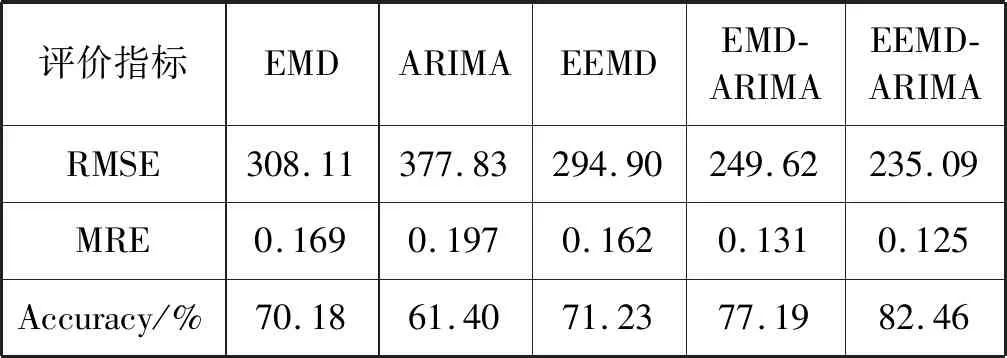
表2 模型評價結果
可以看出EEMD-ARIMA模型的擬合效果最好,其RMSE和MRE均為最小值。本文提出的模型效果較EMD-ARIMA均方根誤差小14.53,平均相對誤差小0.006。在5個模型中,EEMD-ARIMA的預測準確率最高,達到了82.46%。綜合三種模型評價指標來看,EEMD-ARIMA模型的預測結果是最好的。
4 結 語
本文運用結合了EEMD分解的算法和ARIMA時間序列分析模型,針對年降水時間序列進行了分析建模,初步探索了EEMD-ARIMA模型在年降水時間序列的分析應用方法。該模型對年降水量時間序列的預測指導性較高,在年際降水預測中具有實際應用的意義,可以應用于中長期天氣業務工作中。
本文對于EEMD分解后的高頻分量模型選取簡單,未來可選取神經網絡模型,可能對高頻分量擬合得更好。同時,本文使用的EEMD算法解決了模態重疊問題,但還存在分解出現的端點效應,未來可以進一步探索有效的分解算法,提高準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年8期)2016-10-09 02:11:50
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
