智能無人機軌跡與任務卸載聯合優化
2020-11-10 07:10:16張夢琳江沸菠
計算機工程與應用 2020年21期
關鍵詞:優化
張夢琳,江沸菠,董 莉,高 穎
1.湖南師范大學 智能計算與語言信息處理湖南省重點實驗室,長沙 410081
2.湖南工商大學 新零售虛擬現實技術湖南省重點實驗室,長沙 410205
1 引言
在萬物互聯的時代,越來越多的計算密集,延遲敏感和能耗高的新型應用不斷涌現,例如自動駕駛、虛擬現實、體感網絡等。由于用戶設備(UE)的計算資源和電池容量有限,使得這些新興應用無法在用戶端有效執行[1]。移動邊緣計算(MEC)被廣泛認為是用于實現下一代物聯網的關鍵技術[2]。MEC 是一種新型的移動計算方法,它打破傳統云計算方式,不斷提高用戶服務質量(QoS)。與移動云計算相比,MEC減少了因數據中心網絡堵塞而可能導致的延遲,通過將服務器部署到網絡邊緣(如接入點,小型基站等)使得云計算能力和IT 服務接近用戶端[3],這一技術不僅滿足UE低延遲的要求,同時也降低了能耗,延長了設備的使用壽命。
在MEC 系統中,服務器的位置部署和計算卸載是實現能耗優化的關鍵點。由于服務器與UE是端到端的通信模式,所以它們之間相對較短的距離將消耗更少的傳輸時間和能量[4]。計算卸載包括數據傳輸、資源分配、MEC 執行計算和結果返回。雖然MEC 系統可以提供給UE 云計算的功能,但是也無法同時為所有UE 提供計算資源。所以,通過優化MEC 系統中服務器的位置部署和UE的計算卸載來平衡計算任務并提高系統能效至關重要。
目前,在MEC 系統中服務器的位置部署和任務卸載領域均已有較多專門的研究[5-12],但很少有文獻同時優化服務器位置和計算卸載來減少系統能耗。本文在無人機(UAV)上加載了3C 資源即緩存(Cache)、計算(Compute)和通信(Communication)資源,把無人機作為移動邊緣服務器,為地面用戶提供靈活的計算和通信服務,最大限度地減少服務時延,提高服務質量。基于以上分析,將MEC 服務器集成到UAV 上,并對UAV 的位置部署,計算卸載和資源分配進行聯合優化。
考慮一種多用戶-多無人機的移動邊緣計算系統。通過重點優化UAV 的位置部署、計算卸載來減少能量消耗。特別是,UE 不僅需要決定是否卸載而且還需要確定卸載位置。本文提出了一種雙層優化方法,上層利用h-SOM 神經網絡根據信道增益作為判別依據對UE進行實時聚類得到UAV 的最佳位置,下層通過IDE 算法優化得到卸載矩陣。本文的主要貢獻如下:
(1)研究了一種基于多用戶-多無人機的移動邊緣計算系統模型,依據此系統設計了一種具有時延約束的最小能耗計算問題,并針對該問題設計了一種雙層優化方法對無人機軌跡和任務卸載決策進行聯合優化。
(2)雙層優化方法的上層采用無監督學習的h-SOM神經網絡,對于網絡的輸入即每個UE 的坐標以信道增益作為判別指標,SOM網絡能夠自動找出UE之間的類似度,達到對UE 進行實時聚類的效果,從而得到UAV的最佳位置。
(3)雙層優化方法的下層用一種改進的差分進化算法求解任務卸載決策和計算資源分配。首先將上層UE的聚類結果轉化為一組可行解作為IDE 算法的初始解之一,然后利用帶有精英初始策略和自適應雙變異策略的差分進化算法對目標函數進行全局搜索,得到任務卸載決策和計算資源分配的全局次優解。
(4)針對本文所提方法,考慮了一個大規模場景,包含上百個UE 和多個UAV。研究了聯合雙層優化方法的可行性,并與傳統算法進行了比較,驗證了該方法的有效性。
2 相關工作
UAV的軌跡優化和計算任務卸載都是MEC系統中的研究熱點。
在UAV的軌跡優化領域:Mozaffari等人[5]使用圓填充理論(Circle packing theory)設計將多個UAV有效的部署為無線基站,使UAV 的總覆蓋面積和覆蓋壽命最大化;Liu 等人[6]將塊坐標下降法和連續凸逼近算法(Successive Convex Approximation)相結合提出一種新的SCA 算法來優化UAV 位置和無線回程容量的分配;Chen 等人[7]以誤碼率作為可靠指標,研究了基于最大可靠性的中繼UAV 的最佳位置部署。Mozaffari等人[8]還研究了UAV的3D放置和移動性,以便最大化從地面接受物聯網設備的數據等。
在計算卸載和資源分配領域:Wang等人[9]將深度學習技術和聯合學習框架與移動邊緣系統相結合,設計了“邊緣AI框架”以優化移動邊緣計算系統中的緩存和通信;Huang 等人[10]提出了一個基于深度強化學習的在線卸載DROO算法,該框架采用了深度強化學習來生成卸載決策;Chen 等人[11]研究了UAV 的最佳位置和UAV上緩存的內容,提出了一種基于概念的回聲狀態網絡(Echo State Networks)的機器學習新算法;Wang等人[12]提出了帶有移動云計算(MCC)的C-RAN 網絡,研究了在給定任務時間約束下,MCC在C-RAN網絡中的能量最小化和最優資源分配等。
與上述工作不同,研究了一個大規模場景下的聯合優化方案,考慮到任務的時延約束和系統能耗,提出聯合優化UAV的位置部署和計算任務卸載決策的雙層優化方法。上述文獻UAV的位置部署大多采用凸優化或分支界定法的方法來求解問題,雖然降低了問題的復雜性,但隨著系統變量的增多,求解復雜度急劇增加,因此不適合大規模應用場景的問題。計算卸載用AI算法固然可以縮短時間,但算法中的神經網絡需要大量樣本,這在實際系統應用中難以獲得。綜合以上特點,本文考慮了一個多用戶-多無人機的實際場景。針對該場景建立系統模型,并提出了一種雙層優化方法,首先用一種無監督學習的h-SOM 神經網絡對UE 進行實時聚類從而得到UAV 的最佳位置部署。該方法無需樣本,并且可以在相對較短時間內得到UE的聚類結果。然后根據UE 的聚類結果,得到UAV 的最佳部署。最后采用IDE算法求解計算任務卸載決策。
3 系統模型
3.1 基于無人機的移動邊緣計算系統
考慮由i∈I={1 ,2,…,I}個UE和j∈J={1,2,…,J}個UAV組成的MEC系統,如圖1所示。UE隨機分布在規定區域內。每個UE 有一個計算密集型任務要執行,該任務采用二進制卸載策略。和文獻[13]相似,計算任務可以用數學模型描述為Ui=(Fi,Di,T),?i∈I。其中Fi是完成任務Ui所需的CPU 周期總數,Di是任務Ui的卸載數據量,T是時間約束或用戶的QoS要求。
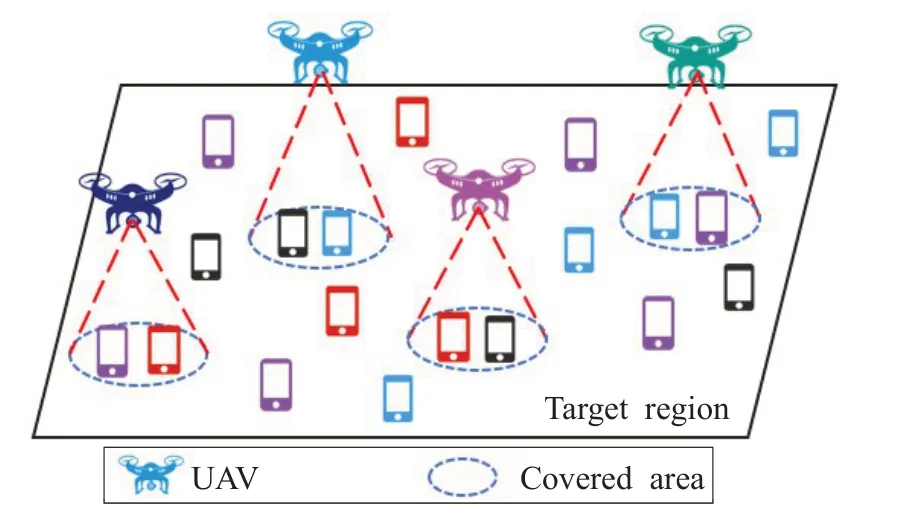
圖1 系統模型
計算卸載包含三個部分:(1)數據傳輸,(2)執行計算,(3)結果返回。本文參考文獻[14],只關心前兩個部分,忽略結果返回。
3.2 通信模型
本節所述的通信模型體現在上行鏈路的傳輸。將aij={0 ,1},?i∈I,?j∈J表示UE的卸載決策。當aij=1時,表示第i個UE將計算卸載到第j個UAV上,當aij=0時,在本地執行計算。同時上述決策滿足?i=I,該公式意味著每個任務最多只能在一個UAV上執行。
假設UE 在數據傳輸中保持靜止[15]。當UEi滿足aij=1 時,第i個UE 卸載到第j個UAV 的傳輸速率rij可以用下式表示:
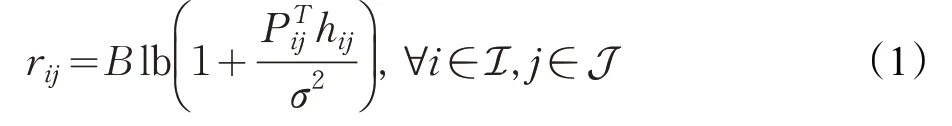
其中,B是信道帶寬,是發射功率,hij是信道增益表示為是第j個 UAV 的高度,Rij是第i個UE和第j個UAV的水平距離,α是小尺度衰落分量。本文中設置UAV在相同的高度。
3.3 計算模型
本節介紹計算模型,主要描述計算任務在本地和UAV上執行的計算時間和能量消耗。
(1)本地執行。假設每個UE 在本地的計算能力為fiL,任務Ui所需的CPU 總周期表示為Fi,那么,第i個UE在本地計算所需時間為:

因此,第i個UE在本地執行所需要的功率PiE為:

式中,ki=10-27是有效開關電容,vi=3 是正常數[16]。
(2)UAV上執行。當UE決定將任務卸載到UAV上時,首先需要確定UE 是否在UAV 覆蓋范圍內,然后定義傳輸時間和UAV 上的計算時間,最后定義計算卸載所需能耗。根據下式判斷第i個UE 是否符合第j個UAV的覆蓋范圍:
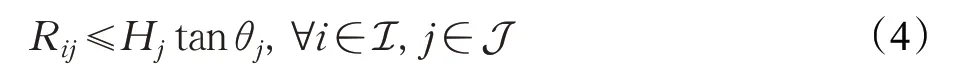
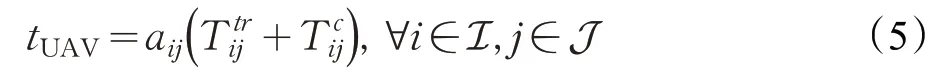
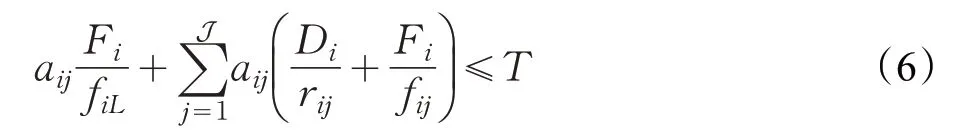
T為總時間。考慮到UAV 資源有限,所以fij必須滿足以下約束這意味著每個UAV分配給UE的計算資源不能超過自身總計算資源。和文獻[18]一樣,忽略無人機懸停和計算所消耗的能量,第i個UE卸載到第j個UAV的能量消耗表示如下:
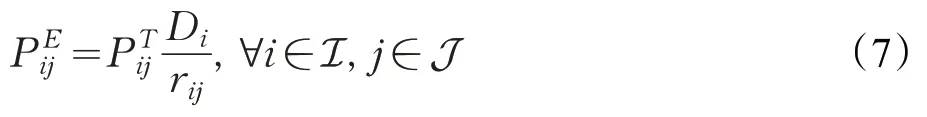
4 問題擬定與分析
4.1 問題擬定
基于以上系統模型分析,給出目標函數Q1如下:
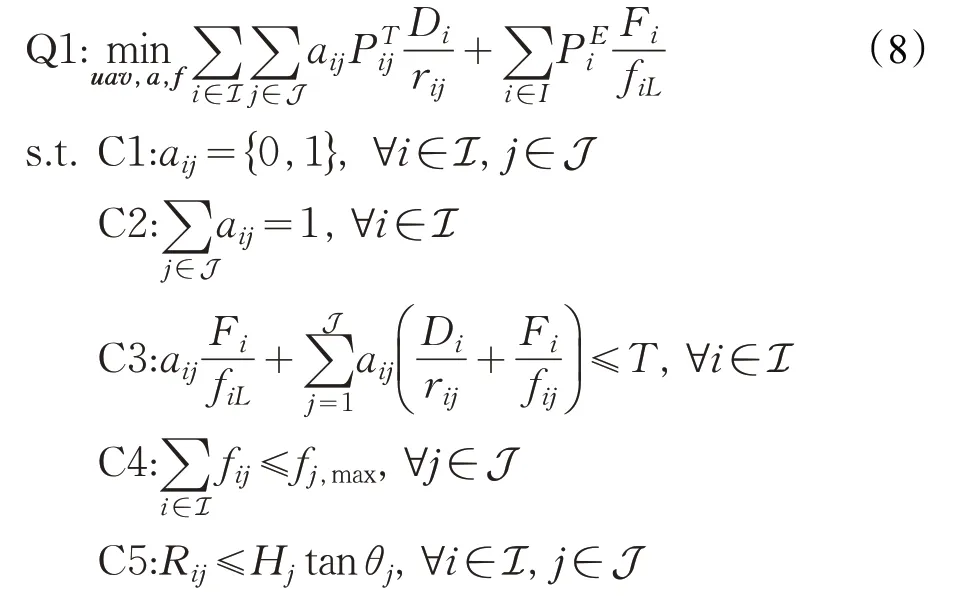
式中,變量uav、a、f分別是UAV 位置矩陣、任務卸載矩陣和資源分配矩陣。約束條件的意義如下:C1 確保所有任務在UAV 或者本地執行;C2 表示如果任務選擇卸載,則每個任務只能在一個UAV上卸載;C3是時延約束;C4 表示UAV 分配給UE 的資源不得超過自身總計算資源;C5表示UAV的覆蓋范圍約束。
4.2 問題分析
上述問題可以描述為一個混合整數非線性規劃問題(MINLP)。針對該問題,提出了一種雙層優化方法對無人機軌跡和任務卸載決策進行聯合優化。首先,用一種無監督學習的h-SOM神經網絡獲得上層的部署。該網絡是一種無導師學習方法,具有良好的自組織、可視化特性。網絡根據輸入的UE坐標自適應地調整權值達到聚類效果,當網絡完成聚類后可以對新的UE 直接進行聚類無需重新訓練。該方法相對于一般的算法減少了優化時間,因為如果增加大量UE,一般的算法需要再次迭代求解,而h-SOM 網絡直接輸入可以得到聚類結果,能夠實時地分析UE 與UAV 的關系,從而得到UAV最優位置部署。然后,對于下層的計算卸載,使用啟發式算法,即用于求解整數優化問題的IDE算法。因為在計算卸載中,包含大量的變量、參數、約束條件,運用啟發式算法可以降低該部分的計算復雜度,迭代得到最佳卸載矩陣使得系統能耗最小。資源分配矩陣f的求解,則參考文獻[16],根據時間約束公式(6)令T取最大時延求每個UE分配的最小資源。此時上述雙層優化方法,上層打開了下層的可行性,下層提高了上層性能評估的準確性,為解決MEC 系統的優化問題提供了一種新思路。
5 自組織特征映射網絡和改進差分進化算法
本文所提出的雙層優化方法如圖2 所示。首先介紹聯合雙層優化方法的算法流程,然后具體介紹h-SOM網絡和IDE算法在該問題中的應用,最后分析了算法的特點與優勢。
5.1 算法流程
如圖2 所示聯合雙層優化方法。首先用h-SOM 網絡對UE 進行實時聚類從而得到UAV 的最優位置。然后利用IDE 算法迭代優化直到收斂或者達到最大迭代次數獲得最終最優解。下面詳細介紹h-SOM 網絡和IDE算法。
5.2 改進自組織特征映射網絡
自組織特征映射網絡(Self-Organizing Feature Map,SOM)也稱Kohonen網絡。該網絡是一個由全連接的神經元陣列組成的無導師、自組織、自學習網絡。SOM網絡能夠以自適應的方式實現任意維度輸入信號的聚類[19]。在本研究中使用SOM網絡描述如下。
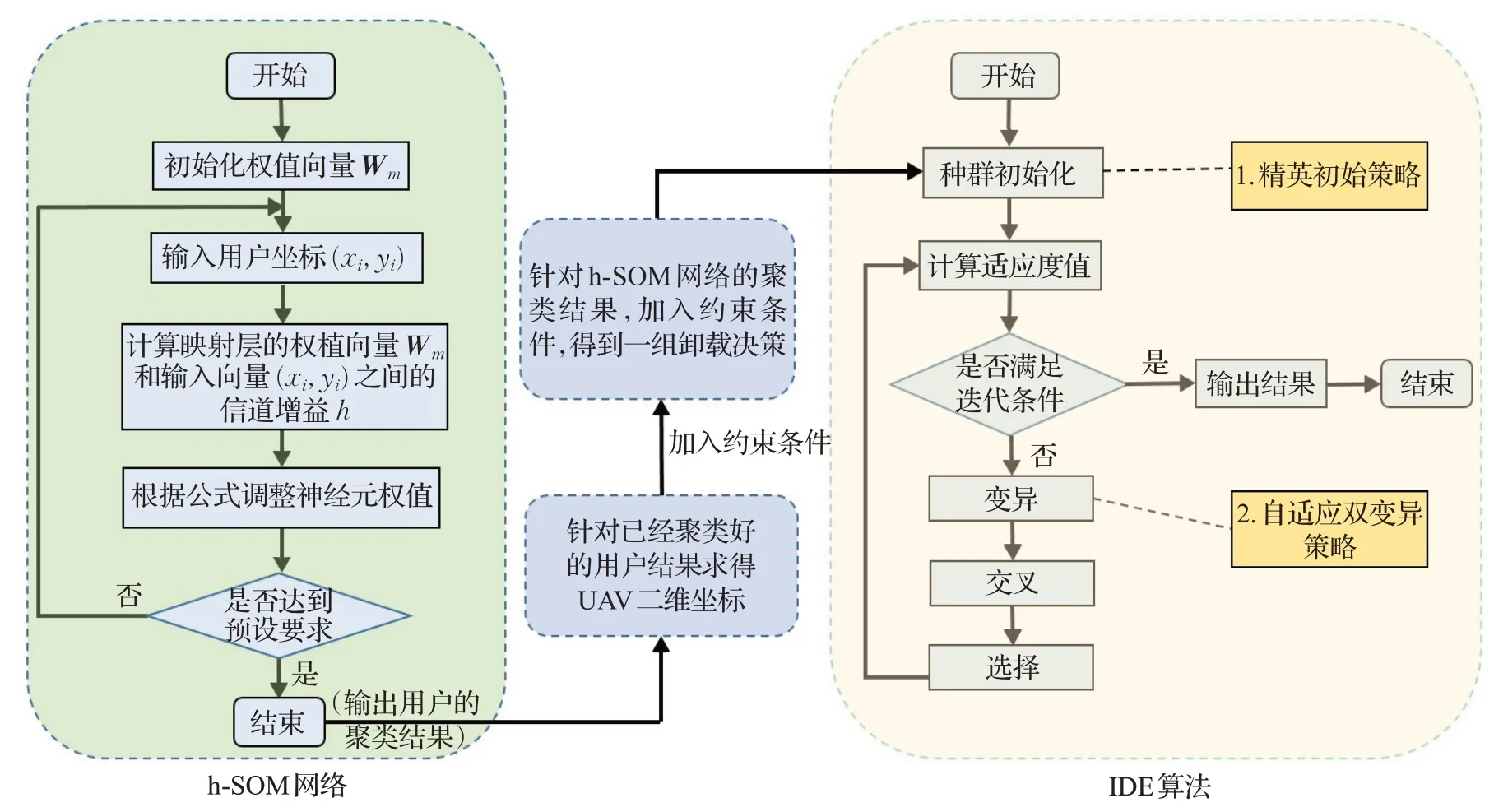
圖2 算法流程
5.2.1 SOM神經網絡結構
SOM 網絡結構如圖3 所示,由輸入層和輸出層(競爭層)組成。輸入層神經元個數為n,輸出層由m個神經元組成的二維平面陣列,輸入層與輸出層各神經元之間實現全連接。SOM網絡能將任意維度的輸入模式在輸出層映射成二維圖形,并保持其拓撲結構不變。網絡通過反復學習輸入向量使權重向量與輸入向量分布趨于一致。
5.2.2 h-SOM神經網絡學習算法
本文針對Q1 問題,對SOM 網絡進行改進,利用信道質量h來衡量樣本與網絡權值之間的匹配程度。首先用矢量(xi,yi) 表示輸入數據即UE 的坐標,i∈{1,2,…,k}表示數據個數,輸入數據的維度與輸入層的神經元一一對應。然后隨機初始化輸入層與競爭層神經元之間的權值Wm,Wm即為第m個UAV 的平面坐標。計算第i個輸入樣本zi=(xi,yi)與第m個神經元的權值Wm=(Wm1,Wm2)的匹配程度:

其中,α是小尺度衰落分量,H是無人機的高度,dim=取具有最大值h(zi,Wm)的神經元即為勝出神經元m*,然后根據下式修正輸出神經元m*的權值,而其他神經元權值不變。
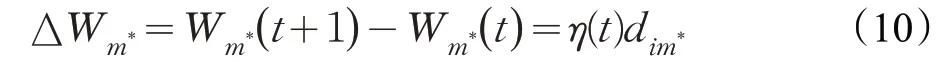
式中,0 <η<1 為常數,隨著時間t的變化逐漸下降。這種權值更新規則通過學習輸入樣本讓最靠近輸入樣本的神經元權值向量被修正,使之更靠近,使得獲勝的神經元在下一次相似的輸入向量出現時,獲勝的可能性會更大;而對于相差很遠的輸入向量,獲勝的可能性將變得很小。
最后,輸出網絡h(zi,Wm)的權值Wm即為UAV 的最佳坐標。
5.3 改進差分進化算法
5.3.1 標準差分進化算法
差分進化算法(DE)主要用于求解整數優化問題。在DE 算法尋優的過程中分為變異、交叉和選擇三個過程。其中,差分變異是DE算法的核心。首先,從父代個體間選擇兩個個體進行向量做差生成差分矢量;其次,選擇另外一個個體與差分矢量求和生成實驗個體;然后,對父代個體與相應的實驗個體進行變異操作,生成新的子代個體;最后在父代個體和子代個體之間進行選擇操作,將符合要求的個體保存到下一代群體中去[20]。
本工作中使用的算法詳細表述如下。為簡單起見,使用實數編碼。在算法中,每個個體是一個卸載矩陣,個體的維度即為UE 個數,每個個體維度的范圍即為J。為進一步提高DE 算法解的精度以及收斂速度,做了如下兩種改進。
5.3.2 精英初始策略
精英初始策略就是把h-SOM網絡聚類結果轉化成一組符合約束條件的可行解代入IDE 算法中作為初始解之一。其轉化思想是把h-SOM網絡聚類結果依次代入公式(8)中的約束條件,若符合所有約束條件,則保留當前聚類結果,若不符合約束條件,則給定在本地執行。在IDE算法中,運用精英初始策略為算法提供了優秀的初始解。
5.3.3 自適應雙變異策略
在群智能算法中,種群的搜索范圍與收斂速度是兩個相互制約的因素。比如,如果只擴大搜索閾值,雖然提高了種群的多樣性,但在面對復雜問題時勢必會影響算法的收斂速度;反之,如果單方面提高收斂速度,雖然能快速找到最優解,但算法易陷入“早熟”階段,穩定性差。基于上述原因,在DE算法中,通常從變異策略來解決,這樣既增加算法種群多樣性還增加了收斂速度。本文中,使用兩種變異策略,但是,如何平衡這兩個變異策略,本文引入自適應算子。公式如下:
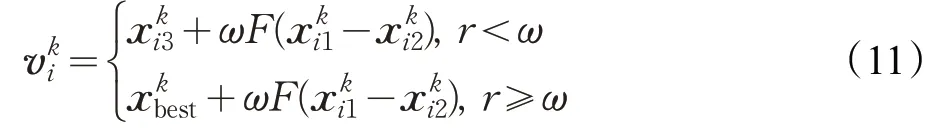
其中,F是變異因子;是第k代變異產生的新向量;分別是第k代種群中互不相同的三個向量;是第k代種群中最優適應度的向量;隨機數r∈(0-1);ω為自適應權重,公式如下:

式中,k為迭代次數,Tmax為最大迭代次數,式(12)中,ω前期變化較慢,取值較大,結合公式(11),有大的概率采用第一個式子進行變異,增加了種群的多樣性,維持了算法的全局搜索能力;隨著迭代的進行,ω逐漸減小,有大的概率使用第二個式子能夠進行精確搜索,極大地提高了算法的局部尋優能力[21]。通過這種ω權重的變化函數,能夠使算法在迭代過程中不易陷入早熟收斂,這樣在整個搜索過程中既高效又不失精確性。
5.4 算法的特點與優勢
在移動邊緣計算中,目標函數往往是一個大規模動態場景的優化問題,本文所用的聯合優化算法優于傳統的方法,具體表現在:(1)針對動態場景的優化問題,算法的上層h-SOM 網絡是基于分類的神經網絡,訓練好以后能夠實時進行定位和分類。傳統的聚類算法例如k-means 或FCM 則需要經過迭代才能夠對UAV 進行定位,不利于快速變化的動態場景。(2)在大規模應用場景下,傳統的凸優化或分支界定法隨著系統變量的增多,求解復雜度急劇增加,而IDE 算法的計算復雜度相對較低且具有高效的全局搜索能力,經過變異、交叉和選擇三種操作同時配合h-SOM 網絡聚類的初始解能夠快速地迭代找到更優的任務卸載矩陣達到能耗最小。
6 仿真實驗及分析
6.1 模型設置
本實驗中,設定實驗區域100 m×100 m,用戶在該區域內隨機分布。仿真平臺為MATLAB R2012a,CPU為酷睿i5-7200U,內存大小為4 GB。首先給出了h-SOM網絡的聚類結果圖,同時與在UAV 軌跡優化中的其他經典機器學習算法進行了對比,然后評估了IDE算法的收斂性,同時與其他傳統算法進行比較。通信參數設置于表1。
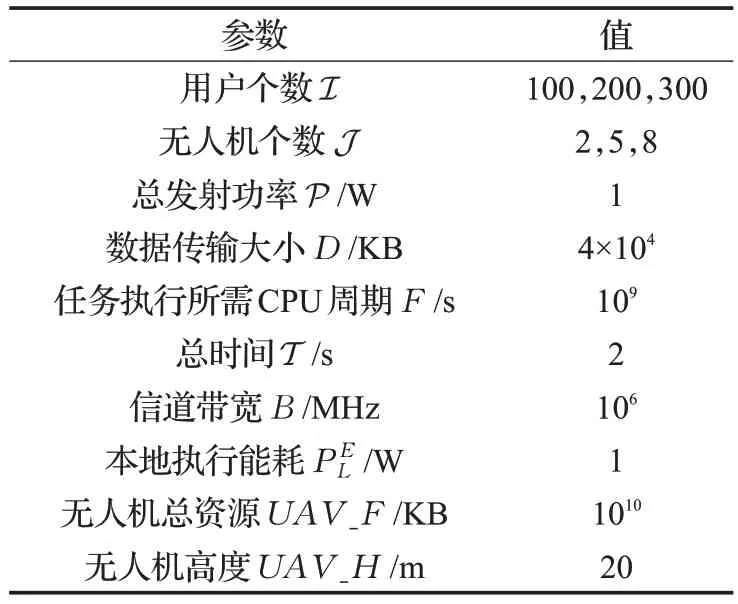
表1 參數設置
6.2 結果分析
本節中,首先給出了h-SOM 網絡拓撲圖與聚類結果。在h-SOM 網絡中,設定樣本數量為100,輸入神經元個數為2。如圖4(a)所示為神經元輸出情況。圖中小正六邊形代表神經元,可以看出輸出層神經元有2×2=4個,本研究中輸出神經元的個數即為UAV 數量。圖中的橫縱坐標為六角形拓撲結構坐標。每個菱形中的線代表神經元之間直接連接,菱形中的顏色表示神經元之間距離的遠近,從黃色到黑色,顏色越深說明神經元之間的距離越遠。圖4(b)為網絡的聚類結果,圖中神經元中間的數字表示每個神經元包含UE 的個數,相對來說數字越大神經元面積越大,數字越小神經元面積越小,但不會改變原始神經元的拓撲結構。
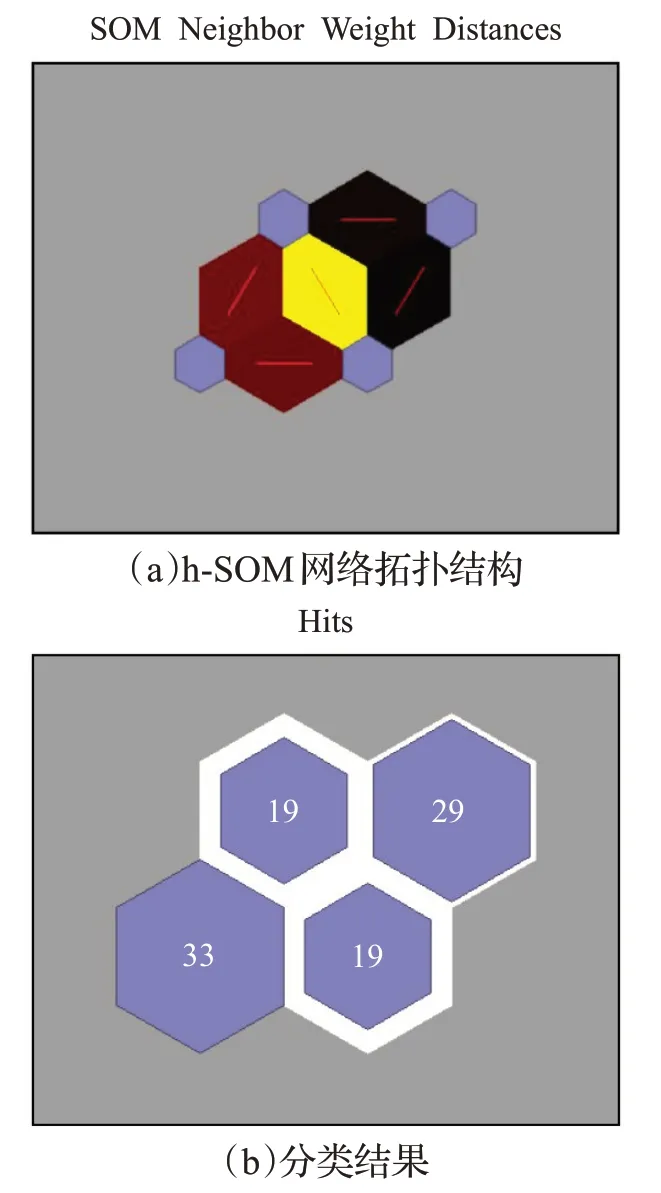
圖4 h-SOM網絡拓撲圖與分類結果
表2 將本文算法與UAV 定位中的經典算法模糊C均值聚類(FCM)算法[22]和K-Means 算法[23]進行了能耗的比較,每個表格中有三個指標,分別是Best、Mean 和SD,用來描述算法在多次執行時的穩定性。Best 表示相同迭代次數下算法的最優解;Mean 表示相同迭代次數下所有解的平均值;SD 表示相同迭代次數下解的方差。可以看出h-SOM網絡相對于其他兩種算法的結果略優一些,具有最低的能耗和方差。
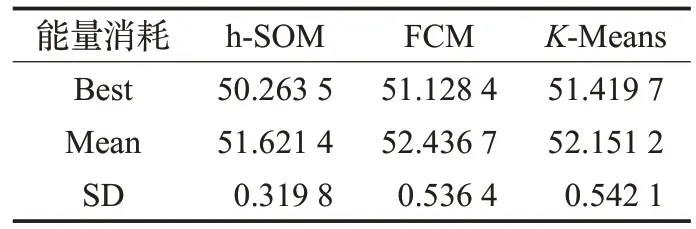
表2 不同算法所得UAV位置的能耗結果
基于上述相對最優UAV的部署和初始用戶的聚類結果,接下來首先研究上述結果對本問題精確度的影響,如表3 所示;然后研究IDE 算法中不同參數對該算法收斂性的影響,如表4~表6所示。最后研究不同自適應算子對該算法收斂性的影響,如表7 所示。表3 所示為加入精英初始策略和不加精英初始策略的IDE 算法迭代結果。從表中可以看出,加入精英初始策略的IDE算法最優解優于不加精英初始策略最優解。因為h-SOM 網絡本身是基于聚類的神經網絡,在此基礎上用IDE算法尋優,為算法提供了優質的初始解。
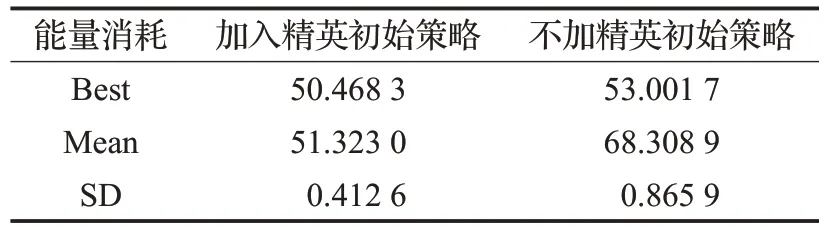
表3 不同初始值的IDE算法結果
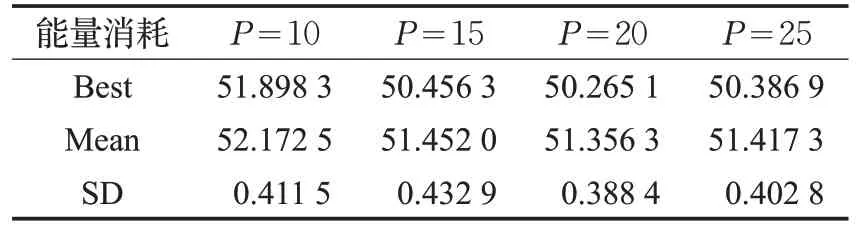
表4 IDE算法中不同種群數量的能量消耗
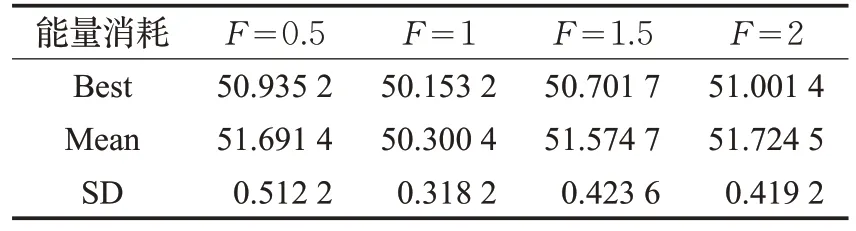
表5 IDE算法中不同F 值的能量消耗
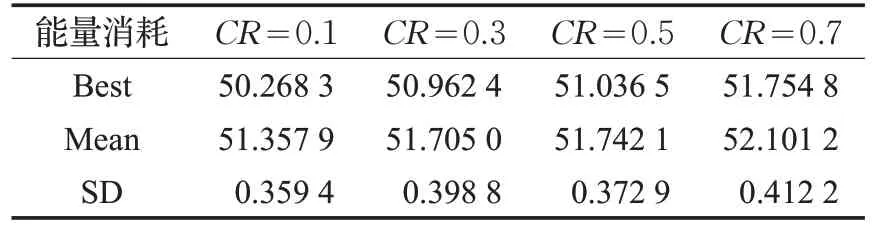
表6 IDE算法中不同CR值的能量消耗
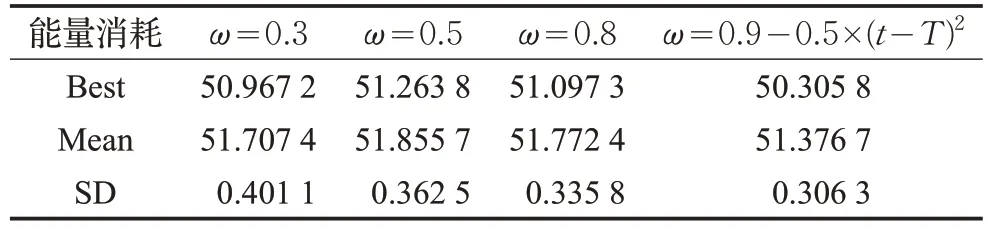
表7 IDE算法中不同ω 值的能量消耗
然后,針對不同參數對IDE算法的影響如表4~表6所示,本實驗中設置相同的初始值。在IDE 算法中,有三個重要的基本參數,即種群大小P、差分放大系數F和交叉因子CR。從表4 可以看出,所提出的算法在P=20 時保持最佳。這是因為當P很大時,小的差分放大系數會阻礙它得到最優解,同時增加迭代次數才能收斂;當P很小時,種群多樣性減小。如表5 所示,能量消耗隨著F的減小而變化,并且當F=1 時,收斂效果最好。這是因為小的差分系數對群體多樣性的貢獻比較小,而大的差分方法系數可能導致問題無解。因此,適當的差分放大系數很重要。如表6 所示,所提算法的性能隨著CR的增長而下降,原因為交叉是隨機的,不涉及任何已知的信息,例如最優解。設計交叉因子的目的是增加種群的多樣性,而在本問題中太大反而影響結果。因此,本文對IDE算法設定P=20,F=1和CR=0.1。
接著,為了評估自適應算子對算法性能的影響,比較了固定算子與自適應算子的性能,分別取ω值0.2、0.5、0.8。如表7所示,明顯看出自適應算子的優化效果較好。這是因為在迭代初期,自適應算子值大于隨機數,增加種群多樣性,增加全局搜索能力;后期,自適應算子隨著迭代次數的增加而逐漸減小,進行局部搜索已達到迭代次數或者最優值,這種自適應算子平衡了算法全局與局部搜索提高了搜索效率。
為了驗證算法的有效性,還將本文算法與貪婪算法、隨機算法以及標準的DE 算法進行比較。本文所用的貪婪算法依據貪婪原則即每個UE隨機將任務卸載到就近的UAV,如果就近的UAV 計算資源不足,則UE 在本地執行計算。所用的隨機算法是UE隨機將任務卸載到某個UAV 上,如果分配的UAV 計算資源不足,UE 將在本地執行計算。
如圖5 所示,繪制了不同算法具有5 個UAV 的100到300個UE數量的能量消耗。從圖5可以看出,能量的消耗隨著UE的數量而增加,原因是任務數量增加,能耗增加。當用戶數量分別為100、200 和300 時,圖中IDE算法的能耗分別是51.241 1、140.915 6、239.262 5,同比貪婪算法降低了約10.95%、3.82%和2.24%,同比隨機算法降低了約38.39%、19.87%和7.96%,同比DE算法降低了約6.98%、3.34%和1.83%。由此可以看出在UAV 數量和時延一定的情況下,圖中IDE 算法的能耗最低,比最高隨機算法降低了約38.39%。
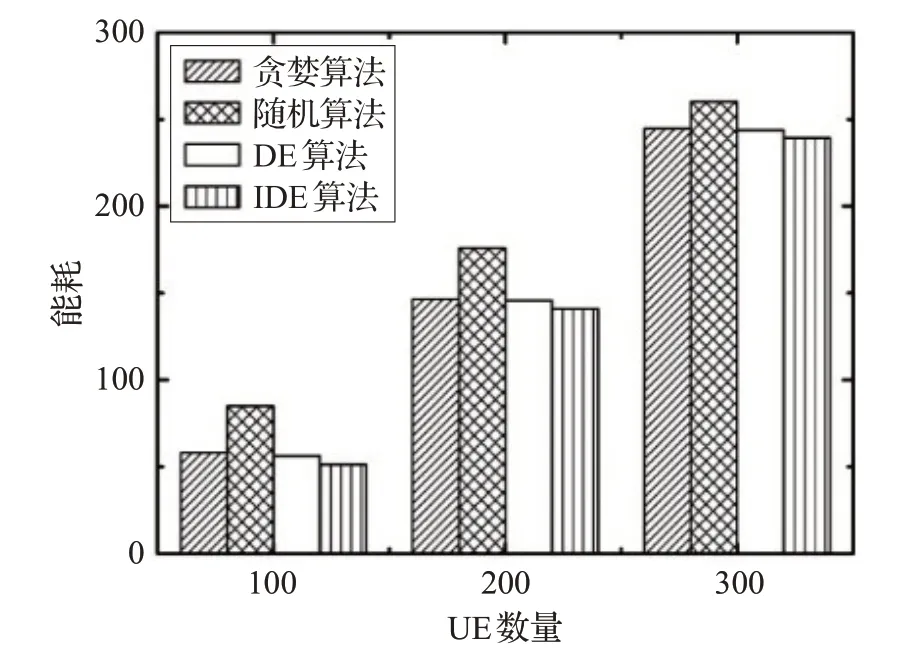
圖5 貪婪、隨機、DE和IDE算法在不同UE數量下的能耗圖
圖6 展示了不同算法具有 100 個 UE 的 2~8 個 UAV數量的能量消耗。從圖6可以看出,貪婪算法、DE算法和IDE算法實現了能量消耗隨著UAV數量的增加而明顯下降,然而對于傳統的隨機算法,由于卸載是隨機分配的,因此無法確保其性能,所以下降幅度不明顯。當UAV 數量分別為 2、5 和 8 時,圖中 IDE 算法的能耗分別是79.462 9、50.144 1、36.525 8,同比貪婪算法降低了約5.73%、9.32%和10.47%,同比隨機算法降低了約12.31%、42.45%和54.33%,同比DE 算法降低了約3.37%、7.61%和6.93%。由此可以看出在UE數量和時延一定的情況下,圖中依然是IDE 算法的能耗最低,隨機算法的能耗最高。可以看出最高能耗和最低能耗相對于圖5 的能耗還要降低得多,因為圖6 實驗中無人機數量相對較多,可以將更多的任務合理地在無人機上進行卸載。

圖6 貪婪、隨機、DE和IDE算法在不同UAV數量下的能耗圖
圖7 展示了不同算法具有 100 個 UE,5 個 UAV 的2~6 s時間延遲的能量消耗。在圖7中,可以明顯看到隨著延遲的增大,系統的能耗只做出了微小的改變,但是本文所提的IDE 算法仍然保持最低能耗。這是因為該算法在搜索方面功能強大,不易陷入局部最優點,進而獲得更優的解。當時延分別為2 s、4 s 和6 s 時,圖中IDE 算法的能耗分別是50.456 9、45.243 2、40.925 8,同比貪婪算法降低了約8.91%、7.13%和9.51%,同比隨機算法降低了約42.49%、46.17%和50.67%,同比DE 算法降低了約6.92%、4.22%和5.38%。可以看出在UAV 數量和UE 數量一定的情況下,圖中能耗最低的依然是IDE算法,最高是隨機算法,而貪婪算法和DE算法的能耗相對于IDE算法的能耗略高些。
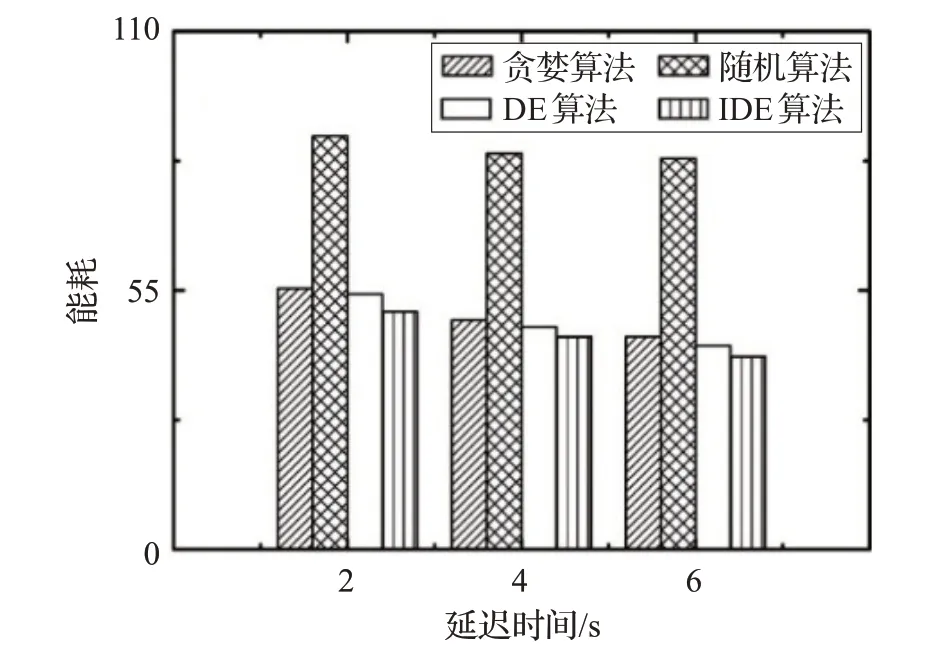
圖7 貪婪、隨機、DE和IDE算法在不同時延T下的能耗圖
從圖5、圖6 和圖7 中可以看出,本文所提的聯合雙層優化方法即h-SOM 網絡和IDE算法的性能優于其他兩種傳統算法。對于傳統的隨機算法,UE 隨機做出決定,可能導致UE 卸載到距離自己較遠的UAV 上,在這種情況下,傳輸能量消耗就變得異常大,同時對于卸載UE 有可能變得無效,因此它保持最高的能量消耗。貪婪算法、標準DE算法和IDE算法執行計算分配,可以控制UE的卸載數量,從而為UE節省能量,所以這三種算法的表現優于隨機算法。貪婪算法在求解該問題時基于一定的貪婪策略即每個UE把任務卸載到離自己最近的UAV 上,這樣雖然減少了UE 在傳輸過程中的能耗,但并未全局考慮UAV 的計算資源限制。DE 算法是一種基于全局搜索的群智能算法,它將差分操作迭代地應用于群體,直到達到最優解,所以標準DE算法比貪婪算法有更好的性能。在DE算法的基礎上引入精英初始策略和自適應雙變異策略,每次迭代產生隨機數與自適應算子進行比較采取不同的變異策略,使得算法在迭代初期保持解的多樣性,在迭代后期局部搜索更加準確,提高算法的精確度。因此,IDE算法比其他三種算法的性能優越。
6.3 復雜度分析
表8比較了h-SOM網絡和FCM及K-Means算法的計算時間。從表8 可以看出,本文所用的h-SOM 網絡由于初始時需要進行迭代訓練,訓練時間高于FCM 和K-Means算法,但是訓練好后的h-SOM只需要執行神經網絡的前向計算就可以得到分類結果,其計算復雜度遠低于FCM 及K-Means 算法,適合求解實時的動態優化問題。
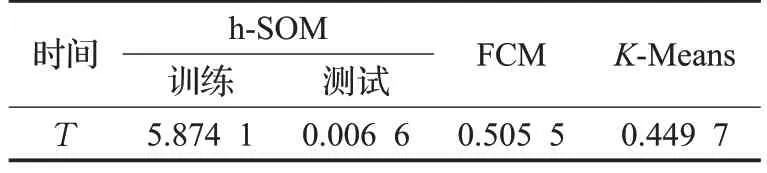
表8 不同算法的時間消耗s
圖8展示了IDE算法與貪婪算法、隨機算法以及標準的DE算法在不同UE數目下計算時間的對比圖。從圖8中可以看出,貪婪算法和隨機算法的計算復雜度相對較低,但是根據前面的實驗結果,兩種方法解的質量均不高。DE算法和IDE算法均具有較好的全局搜索能力,計算復雜度相當,但是由于IDE 算法引入了精英初始策略和自適應雙變異策略,所以IDE算法能夠較快收斂,計算時間更少,結果更優。因此,相對來說,本文所用的算法整體性能更優。
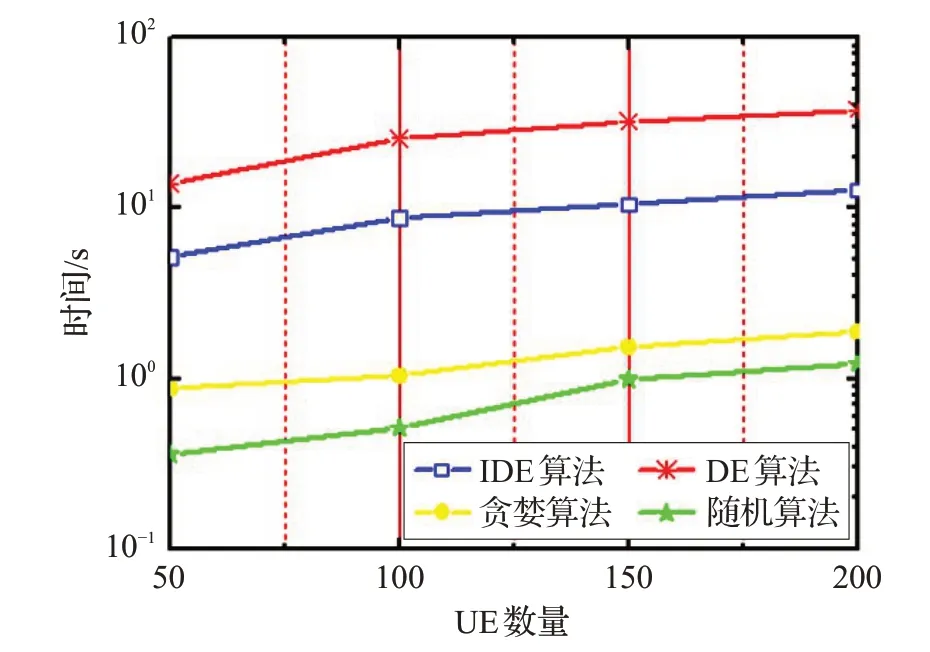
圖8 貪婪、隨機、DE和IDE算法不同UE下的時間消耗圖
7 結論
本文研究了多用戶-多無人機MEC 系統的計算卸載方案,通過用多個UAV 提高傳統MEC 系統的性能。在該系統中需要聯合優化UAV 的位置部署和計算卸載。一般方法來解決這一聯合優化問題時,將面臨兩個問題:混合決策變量和解空間較大,同時忽略了UAV的部署和任務卸載之間的關系。本文提出的這種雙層優化方法,以UAV的部署為上層優化問題,任務卸載為下層優化問題的兩層優化方法。在上層中,用h-SOM 神經網絡,根據UE的位置求解UAV的最佳部署。該方法不僅減少了計算時間,而且針對新用戶能夠快速聚類,無需重新求解。接著,IDE 作為下層優化算法,針對多變量,多目標優化問題能夠提高全局搜索能力,自適應地調整卸載策略達到最優。
最后,針對本文所提算法性能進行了仿真實驗,并通過各種性能指標驗證了本文算法的有效性。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
