面向大規(guī)模圖像檢索的深度強(qiáng)相關(guān)散列學(xué)習(xí)方法
2020-11-10 12:18:38賀周雨馮旭鵬劉利軍黃青松
計(jì)算機(jī)研究與發(fā)展 2020年11期
賀周雨 馮旭鵬 劉利軍,3 黃青松,4
1(昆明理工大學(xué)信息工程與自動(dòng)化學(xué)院 昆明 650500)
2(昆明理工大學(xué)信息化建設(shè)管理中心 昆明 650500)
3(云南大學(xué)信息學(xué)院 昆明 650091)
4(昆明理工大學(xué)云南省計(jì)算機(jī)技術(shù)應(yīng)用重點(diǎn)實(shí)驗(yàn)室 昆明 650500)(he535040@qq.com)
隨著移動(dòng)設(shè)備和互聯(lián)網(wǎng)的快速發(fā)展,每天有大量的圖像被上傳到網(wǎng)絡(luò).百萬(wàn)級(jí)甚至是千萬(wàn)級(jí)的圖像數(shù)據(jù)量使得準(zhǔn)確、快速地檢索出用戶需要的圖像變得越來(lái)越困難.大規(guī)模圖像檢索是計(jì)算機(jī)視覺(jué)研究的根基,直接關(guān)系到計(jì)算機(jī)視覺(jué)的實(shí)際應(yīng)用[1].圖像檢索主要分為基于文本的圖像檢索(text-based image retrieval, TBIR)以及基于內(nèi)容的圖像檢索(content-based image retrieval, CBIR).TBIR的一般方法是對(duì)圖像進(jìn)行標(biāo)注,再根據(jù)標(biāo)注的文本進(jìn)行基于關(guān)鍵字的檢索[2].TBIR的優(yōu)勢(shì)在于用戶只需要提供關(guān)鍵字就可以得到檢索結(jié)果.但相應(yīng)地,這導(dǎo)致檢索性能的好壞很大程度上取決于用戶輸入的關(guān)鍵字準(zhǔn)確與否[3].然而,在實(shí)際應(yīng)用中,文本很難準(zhǔn)確地描述相應(yīng)的圖像,這直接導(dǎo)致了TBIR的檢索性能差強(qiáng)人意.文本的局限性使得其不適用于圖像信息爆炸增長(zhǎng)的現(xiàn)狀,因此目前主流方法是CBIR.CBIR根據(jù)圖像本身的紋理、顏色、款式等信息進(jìn)行檢索,從根本上解決了TBIR的缺陷.在CBIR中,最為重要的一步是對(duì)圖像信息進(jìn)行提取,提取出的圖像特征信息質(zhì)量將直接決定該圖像檢索系統(tǒng)的性能好壞.目前,CBIR中常用的圖像特征提取方法可分為經(jīng)典方法與深度學(xué)習(xí)方法.常用的經(jīng)典方法主要有3類:1)基于顏色特征.基于顏色特征的圖像檢索方法[4]提取出的圖像特征屬于全局特征,且簡(jiǎn)單、易實(shí)現(xiàn).缺點(diǎn)在于,該方法很難描述圖像中的具體對(duì)象以及無(wú)法考慮到對(duì)象空間位置.2)基于紋理特征.基于紋理特征的圖像檢索方法的優(yōu)點(diǎn)在于特征擁有旋轉(zhuǎn)不變性和一定的抗噪能力.這類方法的缺點(diǎn)在于無(wú)法利用圖像的全局信息,從2維圖像得到的紋理特征不一定是相應(yīng)3維物體的真實(shí)紋理,從而導(dǎo)致檢索性能表現(xiàn)不好.3)基于形狀上下文特征.基于形狀上下文特征的圖像檢索方法相對(duì)于上面2種特征來(lái)說(shuō),能夠描述圖像中的具體對(duì)象,有一定的語(yǔ)義關(guān)系.通常,形狀的描述子可分為輪廓和區(qū)域2種,具體的方法有鏈碼、邊界長(zhǎng)度、小波變換、傅里葉描述子、曲率尺度空間描述子、多邊形逼近等.這類方法的缺點(diǎn)在于計(jì)算復(fù)雜度高,無(wú)法適用于大規(guī)模的圖像檢索[5].可以看出,經(jīng)典方法沒(méi)有使用圖像的全局空間信息,且具有計(jì)算開(kāi)銷大、檢索速度慢等缺點(diǎn).深度卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network, CNN)就此應(yīng)運(yùn)而生,它能夠挖掘到圖像信息之間的內(nèi)在隱含關(guān)系,對(duì)圖像信息進(jìn)行全局編碼.CNN具有多個(gè)層,不同的層進(jìn)行不同的計(jì)算,通過(guò)層與層之間的前向傳播與后向傳播進(jìn)行數(shù)據(jù)更新,多次迭代以學(xué)習(xí)到更好的特征表示.文獻(xiàn)[5]通過(guò)實(shí)驗(yàn)證明了CNN能夠保留圖像的全局空間信息,將原始圖像像素矩陣進(jìn)行卷積、池化、激活、全連接等操作,得到了一個(gè)特征表示,再使用這個(gè)特征表示重構(gòu)出了原始的輸入圖像.自從AlexNet[6]在ILSVRC2012比賽中取得冠軍后,深度學(xué)習(xí)備受關(guān)注并迅速占領(lǐng)主導(dǎo)地位.近2年,在世界信息技術(shù)頂級(jí)會(huì)議CVPR(Conference on Computer Vision and Pattern Recog-nition),ECCV(European Conference on Computer Vision)以及ICCV(International Conference on Computer Vision)中,7成以上的圖像檢索方法研究是基于深度卷積神經(jīng)網(wǎng)絡(luò)的.國(guó)內(nèi)也出現(xiàn)大量改進(jìn)深度卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行圖像檢索的學(xué)術(shù)研究[7-8].可以看到,相對(duì)于傳統(tǒng)方法,基于CNN的方法性能表現(xiàn)良好且具有很大的潛力.
隨著互聯(lián)網(wǎng)的快速發(fā)展,數(shù)據(jù)規(guī)模得到爆炸式增長(zhǎng),與此同時(shí)散列方法與深度學(xué)習(xí)相結(jié)合的方法被廣泛地應(yīng)用在加速圖像檢索任務(wù)中.散列方法在檢索速度以及存儲(chǔ)開(kāi)銷上有其他方法無(wú)法比擬的優(yōu)勢(shì),它能夠?qū)⒏呔S的特征矩陣降維成緊湊的二分散列碼.在圖像檢索中,通過(guò)比較2個(gè)散列碼之間的漢明距離判斷2個(gè)圖像是否屬于同一類別.其中,漢明距離的計(jì)算開(kāi)銷要遠(yuǎn)遠(yuǎn)小于其他距離計(jì)算方法,因此可以很快地返回結(jié)果,以實(shí)現(xiàn)快速地圖像檢索.在散列方法中,最重要的步驟是特征提取部分,這一步驟將直接影響圖像檢索的準(zhǔn)確率.傳統(tǒng)的散列方法大多是基于手工特征的,比如文獻(xiàn)[9]提出的語(yǔ)義散列方法、文獻(xiàn)[10]提出的詞袋散列方法.這些方法不具有泛化性,它們需要大量的人力開(kāi)銷.局部敏感散列[11]是具有代表性的一種散列方法,它預(yù)測(cè)相鄰的數(shù)據(jù)通過(guò)散列計(jì)算后仍然是相鄰的.該方法成功地降低了計(jì)算成本并且具有一定的準(zhǔn)確性.2014年,文獻(xiàn)[12]將深度學(xué)習(xí)與散列方法結(jié)合得到了顯著的實(shí)驗(yàn)效果提升,自此出現(xiàn)了大量的深度學(xué)習(xí)與散列方法結(jié)合的研究.文獻(xiàn)[13]提出了一種監(jiān)督散列檢索方法,與之前的方法相比檢索性能有所提升.但是該方法的網(wǎng)絡(luò)結(jié)構(gòu)需要3個(gè)圖像構(gòu)成的三元組信息作為輸入,需要人為設(shè)計(jì)三元組,使得人為工作量增大以及泛化能力降低.文獻(xiàn)[14]將研究重心轉(zhuǎn)移到漢明距離的計(jì)算方法上,他們使用加權(quán)的漢明距離計(jì)算方法,得到了較好的實(shí)驗(yàn)效果.但加權(quán)漢明矩陣需要三元組圖像作為輸入并生成漢明空間,必然使得計(jì)算開(kāi)銷增大,犧牲了散列方法的部分優(yōu)勢(shì).
目前,對(duì)于散列方法與深度學(xué)習(xí)研究的熱點(diǎn)在于改進(jìn)散列編碼的約束方式.文獻(xiàn)[15]提出一種深度離散散列方法,該方法提供了一種解決離散散列問(wèn)題的最優(yōu)化方法,實(shí)驗(yàn)結(jié)果表明該方法能有效提升檢索準(zhǔn)確率.但是該方法需要圖像進(jìn)行成對(duì)輸入,使得計(jì)算開(kāi)銷變大.文獻(xiàn)[16]通過(guò)精心設(shè)計(jì)的損失函數(shù)得到了更具有區(qū)分性的散列碼,使用成對(duì)的圖像輸入,通過(guò)相應(yīng)的標(biāo)簽判斷2個(gè)樣本是否為同一類別,再根據(jù)相似矩陣改進(jìn)損失函數(shù),最后得到一個(gè)松弛的散列碼用于前向傳播與反向傳播.這樣做的優(yōu)點(diǎn)在于考慮了更多的原始信息以及能夠得到更具有區(qū)分性的散列碼,缺點(diǎn)在于成對(duì)的輸入使得計(jì)算開(kāi)銷增大以及需要制作標(biāo)簽.因此該方法并不適用于大規(guī)模的圖像檢索.目前大多數(shù)散列方法都使用“成對(duì)”或“三元組”的輸入來(lái)尋找隱藏的數(shù)據(jù)關(guān)系.這類方法必然會(huì)增大計(jì)算開(kāi)銷,不適用于大規(guī)模的圖像檢索.為了實(shí)現(xiàn)快速且準(zhǔn)確的大規(guī)模圖像檢索,本文提出一個(gè)深度強(qiáng)相關(guān)散列學(xué)習(xí)方法.該方法具有3個(gè)特點(diǎn):
1) 是一種簡(jiǎn)單、有效、可廣泛使用于各種網(wǎng)絡(luò)結(jié)構(gòu)的深度監(jiān)督散列學(xué)習(xí)方法.
2) 提出了一個(gè)獨(dú)特設(shè)計(jì)的強(qiáng)相關(guān)損失函數(shù).相比于常用的“成對(duì)”、“三元組”策略,在減少計(jì)算開(kāi)銷的同時(shí)能夠保證提取到的特征更具有區(qū)分性.
3) 在CIFAR-10, NUS-WIDE, SVHN這3個(gè)大規(guī)模公開(kāi)數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),結(jié)果表明本文方法在檢索性能上優(yōu)于目前主流方法.
1 相關(guān)工作
1.1 深度監(jiān)督散列學(xué)習(xí)
隨著數(shù)據(jù)的爆炸式增長(zhǎng),散列方法得到了更多的關(guān)注.散列方法能夠?qū)⒏呔S的特征矩陣降維成低維、緊湊的二分散列碼,在檢索速度以及存儲(chǔ)開(kāi)銷上具有其他方法無(wú)法比擬的優(yōu)勢(shì).與此同時(shí),CNN[17-19]在計(jì)算機(jī)視覺(jué)任務(wù)比賽中取得了巨大的成功.CNN在圖像檢索任務(wù)中可以達(dá)到很高的準(zhǔn)確率,而散列方法能夠?qū)崿F(xiàn)快速地圖像檢索.深度散列學(xué)習(xí)就此應(yīng)運(yùn)而生.深度監(jiān)督散列學(xué)習(xí)方法是有監(jiān)督的深度散列方法.典型的深度監(jiān)督散列學(xué)習(xí)方法通過(guò)標(biāo)簽信息生成一個(gè)相似矩陣,利用得到的相似矩陣約束散列碼的生成.在深度監(jiān)督散列學(xué)習(xí)方法中,散列碼直接來(lái)自于神經(jīng)網(wǎng)絡(luò).通過(guò)深度監(jiān)督散列神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)散列函數(shù),能夠挖掘到數(shù)據(jù)間更深層的隱藏關(guān)系.但是,深度監(jiān)督散列方法面臨一個(gè)難題,二分散列碼編碼過(guò)程中的離散約束會(huì)造成量化損失.一些深度監(jiān)督散列學(xué)習(xí)方法[20-21]使用懲罰機(jī)制來(lái)削弱離散約束帶來(lái)的負(fù)面影響,但效果不夠理想.文獻(xiàn)[22]添加一個(gè)全連接層以得到一個(gè)散列碼,再通過(guò)最大值激活輸出.這樣做有一定的提升效果,但并未直接對(duì)散列編碼進(jìn)行約束,不能夠挖掘到特征之間潛在的聯(lián)系.本文方法設(shè)計(jì)了一個(gè)強(qiáng)相關(guān)損失函數(shù),能一定程度地解決這個(gè)問(wèn)題.
1.2 度量學(xué)習(xí)
度量學(xué)習(xí),也叫作相似度學(xué)習(xí),被廣泛地應(yīng)用在計(jì)算機(jī)視覺(jué)領(lǐng)域.度量學(xué)習(xí)的基本思想是,盡量增大特征的類間距離,減小類內(nèi)距離.深度散列學(xué)習(xí)方法是一種特殊的度量學(xué)習(xí).它是深度學(xué)習(xí)與散列方法的結(jié)合,目標(biāo)是學(xué)習(xí)到一個(gè)相似函數(shù),通過(guò)相似函數(shù)生成二分散列碼.目前,大多數(shù)的深度監(jiān)督散列方法使用二元或者三元損失函數(shù)對(duì)散列學(xué)習(xí)進(jìn)行約束.常用的做法是通過(guò)標(biāo)簽信息生成一個(gè)相似矩陣,再利用相似矩陣構(gòu)建損失函數(shù),通過(guò)迭代計(jì)算損失值來(lái)約束散列碼的生成.這類方法的輸入數(shù)據(jù)是一個(gè)二元組或者三元組,使得訓(xùn)練樣本量達(dá)到O(n2)或者O(n3),其中,n為訓(xùn)練樣本數(shù)量.這類方法[16,23-24]犧牲了散列方法最大的優(yōu)勢(shì)——低內(nèi)存消耗、高計(jì)算速度,對(duì)于大規(guī)模數(shù)據(jù)來(lái)說(shuō)計(jì)算開(kāi)銷太大.我們的目標(biāo)是設(shè)計(jì)一個(gè)新的損失函數(shù)來(lái)約束散列碼的生成,實(shí)現(xiàn)在不失準(zhǔn)確率的前提下大幅提升計(jì)算速度.
目前,softmax函數(shù)被廣泛地應(yīng)用在CNN中.softmax函數(shù)是一個(gè)歸一化指數(shù)函數(shù),具有簡(jiǎn)單且能用數(shù)學(xué)概率解釋的特點(diǎn).它可以與交叉熵方法相結(jié)合成為softmax交叉熵?fù)p失函數(shù),一般作為卷積神經(jīng)網(wǎng)絡(luò)中分類器的基本公式.隨后的一些研究,如Center Loss[25],L-softmax[26]等一元損失函數(shù)都是在softmax交叉熵?fù)p失函數(shù)的基礎(chǔ)上進(jìn)行改進(jìn)的,它們能夠?qū)W習(xí)到一個(gè)很好的距離.大量實(shí)驗(yàn)證明,這類一元損失函數(shù)在人臉識(shí)別、圖像檢索等實(shí)驗(yàn)中表現(xiàn)出優(yōu)異的性能[25].本文方法的強(qiáng)相關(guān)損失函數(shù)也是受到一元損失函數(shù)的啟發(fā)并加以改進(jìn).強(qiáng)相關(guān)損失函數(shù)是一個(gè)根據(jù)學(xué)習(xí)目標(biāo)進(jìn)行調(diào)節(jié)的函數(shù),它有4個(gè)優(yōu)點(diǎn):1)能夠調(diào)節(jié)特征之間的距離,通過(guò)增加訓(xùn)練學(xué)習(xí)時(shí)的難度,調(diào)節(jié)權(quán)重矩陣敏感度以學(xué)習(xí)到更具有區(qū)分性的特征.2)能夠適用于各種卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu).3)能夠有效地防止發(fā)生過(guò)擬合.4)內(nèi)存開(kāi)銷小、計(jì)算速度快.

Fig. 1 The pipeline of our proposed method
1.3 深度強(qiáng)相關(guān)
強(qiáng)相關(guān)又稱為高度相關(guān),是數(shù)據(jù)計(jì)量分析法研究的要點(diǎn)之一.強(qiáng)相關(guān)是研究對(duì)象的數(shù)組和另一數(shù)組或者另一復(fù)合數(shù)組之間是否存在高度的相關(guān)關(guān)系.在數(shù)理統(tǒng)計(jì)中存在定理[27]: 當(dāng)且僅當(dāng)隨機(jī)變量矩陣X與Y之間存在線性關(guān)系,即Y=kX+b時(shí),它們的相關(guān)系數(shù)的絕對(duì)值等于1,X與Y為強(qiáng)相關(guān)關(guān)系.為了方便計(jì)算,可以忽略偏置b.在本文方法的強(qiáng)相關(guān)損失函數(shù)中,Z為損失層1的輸出矩陣,其計(jì)算公式為Z=mαXW,其中m為正整數(shù),α為權(quán)重相關(guān)系數(shù),X為損失層1的輸入矩陣,W為權(quán)重矩陣.由上述定理可知,Z與W之間存在線性關(guān)系,且權(quán)重相關(guān)系數(shù)α的設(shè)置使得Z值對(duì)權(quán)重矩陣W更敏感,Z和W之間是高度正相關(guān)的.深度強(qiáng)相關(guān)為深度學(xué)習(xí)與數(shù)據(jù)計(jì)量分析法的結(jié)合.本文提出一個(gè)深度強(qiáng)相關(guān)散列學(xué)習(xí)方法,能夠與各種卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)相結(jié)合,通過(guò)迭代訓(xùn)練學(xué)習(xí)到一組緊湊的二分散列碼,可以實(shí)現(xiàn)高效的大規(guī)模圖像檢索.本文方法學(xué)習(xí)到的二分散列碼在公開(kāi)、大規(guī)模數(shù)據(jù)集的圖像檢索任務(wù)中取得很好的成績(jī).
2 本文方法
2.1 深度強(qiáng)相關(guān)散列學(xué)習(xí)模型
本文方法的主要改進(jìn)在于為卷積神經(jīng)網(wǎng)絡(luò)添加散列層及設(shè)計(jì)強(qiáng)相關(guān)損失層.在散列層做出的改進(jìn)為限制神經(jīng)元個(gè)數(shù),使得輸出一個(gè)低維度的矩陣,再限制該矩陣的取值范圍,從而得到松弛的散列碼.在損失層使用基于常規(guī)損失函數(shù)進(jìn)行改進(jìn)的強(qiáng)相關(guān)損失函數(shù).本文方法保留且遵循卷積神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)及原理,可以應(yīng)用到多種卷積神經(jīng)網(wǎng)絡(luò)中,將在4.3節(jié)驗(yàn)證本文方法的普遍適用性.為了方便介紹本文方法,在本節(jié)采用AlexNet為例進(jìn)行改進(jìn),將深度強(qiáng)相關(guān)散列學(xué)習(xí)方法應(yīng)用在AlexNet中,得到深度強(qiáng)相關(guān)散列(deep highly interrelated hashing, DHIH)模型.圖1為DHIH模型的總體框架,主要分為模型訓(xùn)練與圖像檢索2個(gè)部分.模型訓(xùn)練部分展示了從訓(xùn)練圖像輸入到反饋損失值驅(qū)動(dòng)網(wǎng)絡(luò)更新的整個(gè)訓(xùn)練過(guò)程.圖像檢索部分提供了一個(gè)從待檢索圖像輸入到相似圖像輸出的檢索功能.網(wǎng)絡(luò)配置如表1所示,其中Hash Layer為散列層,code_length為散列碼位數(shù).
圖像相應(yīng)的散列碼提取自訓(xùn)練好的DHIH模型的散列層輸出.DHIH模型的訓(xùn)練過(guò)程為:輸入圖像經(jīng)過(guò)卷積子網(wǎng)絡(luò),把圖像信息映射到特征空間中,得到一個(gè)局部式特征表示;再經(jīng)過(guò)全連接層6以及全連接層7,把上層得到的局部式特征表示映射到樣本標(biāo)記空間中,其中全連接層6的輸出特征矩陣為1×1×4 096,全連接層7的輸出特征矩陣為1×1×4 096;再進(jìn)入散列層進(jìn)行降維及散列編碼,散列層輸出code_length維的圖像特征(code_length為設(shè)置的散列碼位數(shù));再進(jìn)入強(qiáng)相關(guān)損失層,利用強(qiáng)相關(guān)損失函數(shù)計(jì)算出當(dāng)前迭代的損失值;最后返回?fù)p失值,根據(jù)損失值更新網(wǎng)絡(luò)參數(shù),驅(qū)動(dòng)模型的訓(xùn)練.

Table 1 Deep Highly Interrelated Hashing Network Structure Based on AlexNet
DHIH模型完成圖像檢索任務(wù)的過(guò)程為:通過(guò)DHIH模型學(xué)習(xí)到目標(biāo)區(qū)域的特征表示和相應(yīng)的散列碼;分別輸入圖像庫(kù)圖像和待檢索圖像可以得到一個(gè)散列碼特征庫(kù)和待檢索圖像的散列碼;再比較待檢索圖像的散列碼與特征庫(kù)中的散列碼之間的漢明距離;將漢明距離按從小到大的順序排列,然后返回前q個(gè)值對(duì)應(yīng)的圖像,即為該待檢索圖像的檢索結(jié)果.
2.2 散列層
文獻(xiàn)[28]成功將卷積層的特征輸出復(fù)原為原始圖像,證明經(jīng)過(guò)卷積、池化、激活等操作后的特征表示仍然保留著圖像的原始信息.這些提取到的中層圖像特征表示可以直接用于圖像分類、檢索等計(jì)算機(jī)視覺(jué)任務(wù)中,文獻(xiàn)[24]完成了大量相關(guān)實(shí)驗(yàn).但由于中層圖像特征表示的維度太大導(dǎo)致計(jì)算開(kāi)銷太大,一般不會(huì)使用中層圖像特征表示進(jìn)行計(jì)算機(jī)視覺(jué)任務(wù).本文基于這個(gè)思想,為網(wǎng)絡(luò)結(jié)構(gòu)添加一個(gè)散列層.散列層的目的是將高維的中層圖像特征表示轉(zhuǎn)換成低維的松弛散列碼.局部敏感散列認(rèn)為相鄰的數(shù)據(jù)在經(jīng)過(guò)隨機(jī)映射后依然相鄰.同樣地,DHIH的散列層通過(guò)隨機(jī)映射進(jìn)行降維,相鄰的數(shù)據(jù)仍然相鄰,表示為:
fj(xi)=xiwj,
(1)
其中,散列層的上一層為全連接層7,則散列層的輸入為1×1×4 096的特征矩陣,記為xi(i=1,2,…,4 096);wj為權(quán)重矩陣,j的取值范圍為1,2,…,code_length.再使用sigmoid函數(shù)激活特征矩陣,使得特征值屬于[0,1],從而得到一個(gè)松弛的散列碼.sigmoid函數(shù)為:
(2)
其中,fj(xi)由式(1)可得.通過(guò)散列層可以得到一個(gè)松弛的散列碼.在2.4節(jié)中,松弛的散列碼可以轉(zhuǎn)換成完整的二分散列碼,我們使用完整的二分散列碼進(jìn)行圖像檢索.
2.3 強(qiáng)相關(guān)損失層
在CNNs中,通過(guò)比較模型的輸出和目標(biāo)值,最小化損失值來(lái)驅(qū)動(dòng)模型的訓(xùn)練.本文設(shè)計(jì)了一個(gè)強(qiáng)相關(guān)損失函數(shù)來(lái)完成此項(xiàng)任務(wù).該函數(shù)能夠?qū)W習(xí)到更具有區(qū)分性的特征表示.強(qiáng)相關(guān)損失層從散列層接收一個(gè)1×1×code_length的特征矩陣,通過(guò)強(qiáng)相關(guān)損失函數(shù)計(jì)算得到一個(gè)1×1×L(L是類別數(shù))的特征矩陣,再通過(guò)交叉熵函數(shù)計(jì)算損失值.利用得到的損失值進(jìn)行反向傳播,更新模型的參數(shù).為了便于說(shuō)明本文方法,我們將強(qiáng)相關(guān)損失層分為損失層1和損失層2.其中,損失層1是通過(guò)強(qiáng)相關(guān)損失函數(shù)得到1×1×L(L是類別數(shù))的特征矩陣,損失層2是利用損失層1得到的特征矩陣計(jì)算損失值.
我們?yōu)閺?qiáng)相關(guān)損失層設(shè)計(jì)了一個(gè)強(qiáng)相關(guān)損失函數(shù).假設(shè)有樣本集G={G1,G2,…,Gn},該樣本集只擁有類別1和類別2這2個(gè)分類,且每個(gè)樣本只屬于一個(gè)類別.存在樣本G1,它的所屬類別為類別1,則在softmax交叉熵?fù)p失函數(shù)中有:
G1W1>G1W2,
(3)
則分類正確.其中,W1為類別1對(duì)應(yīng)的權(quán)重矩陣,W2為類別2對(duì)應(yīng)的權(quán)重矩陣.在強(qiáng)相關(guān)損失函數(shù)中,我們添加了一個(gè)權(quán)重相關(guān)系數(shù)α,式(3)變?yōu)?/p>
α1G1W1>α2G1W2,
(4)
其中,如能正確分類,則α1>α2.可以通過(guò)加大模型學(xué)習(xí)的難度來(lái)迫使網(wǎng)絡(luò)學(xué)習(xí)到更具有區(qū)分性的特征.因此,增加一個(gè)超參數(shù)m,取值為正整數(shù).使得式(4)變?yōu)?/p>
α1G1W1>mα2G1W2,
(5)
此時(shí),我們?nèi)匀幌M?5)左邊大于右邊,因?yàn)楫?dāng)且僅當(dāng)式(5)左邊大于右邊時(shí),分類正確.通過(guò)超參數(shù)m的設(shè)置使得模型學(xué)習(xí)難度增加,權(quán)重相關(guān)系數(shù)α使得模型對(duì)權(quán)重矩陣更為敏感,以此調(diào)節(jié)特征之間的距離,也就達(dá)到了強(qiáng)迫網(wǎng)絡(luò)學(xué)習(xí)到更具有區(qū)分性特征的目的.
強(qiáng)相關(guān)損失層的具體計(jì)算過(guò)程如下.假定,當(dāng)前樣本的真實(shí)標(biāo)簽為i,其他標(biāo)簽為j.強(qiáng)相關(guān)損失層的輸入為散列層的輸出,記為X,X的維度為1×K.X進(jìn)入損失層1,通過(guò)計(jì)算得到損失層1的輸出矩陣Z,Z的維度為1×L(L是類別數(shù)).zi和zj是矩陣Z的元素,zi表示當(dāng)前樣本的真實(shí)標(biāo)簽對(duì)應(yīng)的值,zj為其余標(biāo)簽對(duì)應(yīng)的值.如果當(dāng)前真實(shí)標(biāo)簽為0,即i=0時(shí),zi的值為Z的第1個(gè)元素.zi和zj可計(jì)算為:
(6)
式(6)為強(qiáng)相關(guān)損失函數(shù).其中,m和β為超參數(shù),m的取值為正整數(shù),β的取值為0~1,wki和wkj是權(quán)重矩陣W的元素,W的維度為K×L,αi和αj為權(quán)重相關(guān)系數(shù).αi,αj可計(jì)算為:
(7)
αi為樣本的真實(shí)標(biāo)簽對(duì)應(yīng)的值,αj為其余標(biāo)簽對(duì)應(yīng)的值.由式(7)可以看出,權(quán)重相關(guān)系數(shù)α的值取決于當(dāng)前標(biāo)簽對(duì)應(yīng)的權(quán)重值.
通過(guò)強(qiáng)相關(guān)損失函數(shù)式(6),我們得到了損失層1的輸出矩陣Z.進(jìn)入損失層2,通過(guò)交叉熵函數(shù)計(jì)算損失值:
(8)
其中,zi和zj來(lái)自Z,由式(6)可得.
以上為強(qiáng)相關(guān)損失層的正向傳播過(guò)程.散列層的輸出為X,損失層1的輸出為Z,損失層2的輸出為損失值.利用強(qiáng)相關(guān)損失層得到的損失值能夠進(jìn)行反向傳播,驅(qū)動(dòng)網(wǎng)絡(luò)的訓(xùn)練.
為了能更直觀地理解強(qiáng)相關(guān)損失函數(shù)能夠得到更具有區(qū)分性的特征,使用數(shù)據(jù)集為CIFAR-10、散列碼位數(shù)為48的DHIH模型進(jìn)行實(shí)驗(yàn),提取模型損失層中的輸出矩陣Z進(jìn)行可視化.圖2為Z降維后的特征可視化圖.使用t-sne方法進(jìn)行特征降維并可視化.t-sne方法將一組高維空間的點(diǎn)映射到低維空間,能在一定程度上保持這些點(diǎn)在高維空間的關(guān)系,得到的可視化圖不能反映簇與簇之間的距離,但是可以反映簇內(nèi)距離.參數(shù)設(shè)置為:特征個(gè)數(shù)為10 000,PCA預(yù)處理使得特征維度由10降到5,高斯分布困惑度為40,迭代次數(shù)為3 000,學(xué)習(xí)率為0.01.圖2(a)為softmax交叉熵?fù)p失函數(shù)計(jì)算出的特征可視化圖;圖2(b)為強(qiáng)相關(guān)損失函數(shù)(β=0.4,m=2)計(jì)算出的特征可視化圖;圖2(c)為強(qiáng)相關(guān)損失函數(shù)(β=0.7,m=2)計(jì)算出的特征可視化圖;圖2(d)為強(qiáng)相關(guān)損失函數(shù)(β=0.7,m=3)計(jì)算出的特征可視化圖.從圖2中可以看出,在同樣的參數(shù)設(shè)置下通過(guò)強(qiáng)相關(guān)損失函數(shù)學(xué)習(xí)到的特征更聚攏,即類內(nèi)距離更小.
2.4 圖像檢索
由2.2節(jié)可知,我們能在DHIH模型中的散列層得到一個(gè)松弛的散列碼.在圖像檢索過(guò)程中,根據(jù)式(9)將松弛的散列碼轉(zhuǎn)換成一個(gè)二分散列碼:

(9)
其中,S(x)由式(2)可得.訓(xùn)練圖像通過(guò)DHIH模型的散列層得到一個(gè)松弛散列碼特征庫(kù),再將松弛的散列碼轉(zhuǎn)換成二分散列碼,得到一個(gè)二分散列碼特征庫(kù).同樣地,待檢索圖像通過(guò)DHIH模型可得到相應(yīng)的松弛散列碼,再將松弛散列碼轉(zhuǎn)換為二分散列碼.本文采用漢明距離來(lái)衡量待檢索圖像的二分散列碼與特征庫(kù)中的二分散列碼之間的相似度.對(duì)這2個(gè)散列碼進(jìn)行異或運(yùn)算,統(tǒng)計(jì)結(jié)果為1的個(gè)數(shù),這個(gè)數(shù)就是漢明距離D(x,y):

(10)
其中,i=0,1,…,K-1,A和B是2個(gè)K位的散列碼.

Fig. 2 Visualization on Z based on CIFAR-10 dataset
漢明距離越大,則待檢索圖像與當(dāng)前特征庫(kù)圖像之間的差異越大,即相似度低.將漢明距離按從小到大排序,采用最近鄰策略選取前q個(gè)相似圖像返回作為檢索結(jié)果.
3 優(yōu)化及實(shí)驗(yàn)準(zhǔn)備
3.1 優(yōu) 化
強(qiáng)相關(guān)損失函數(shù)是一種一元損失函數(shù),本文使用隨機(jī)梯度下降法來(lái)進(jìn)行優(yōu)化.與常用的softmax交叉熵?fù)p失函數(shù)的不同點(diǎn)在于Z值的不同,因此我們可以只計(jì)算Z值的前向傳播值和反向傳播值.式(6)可以化簡(jiǎn)為:
Z=(1-β)XW+βXW[pmαj-(p-1)αi],
(11)

(12)

(13)


(14)
(15)
為了簡(jiǎn)化計(jì)算,我們將αi,αj看作一個(gè)每次迭代都會(huì)更新的參數(shù),即在當(dāng)前迭代的反向傳播過(guò)程中,αi,αj是一個(gè)與權(quán)重?zé)o關(guān)的具體數(shù)值.根據(jù)式(14),可化簡(jiǎn)為
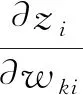
(16)
根據(jù)式(15),可化簡(jiǎn)為

(17)
可以將式(16)與式(17)進(jìn)行合并,得到:
(18)
化簡(jiǎn)式(13)得到:

(19)
其中,p的取值為0,1.當(dāng)Z值為真實(shí)標(biāo)簽對(duì)應(yīng)值時(shí),即zi,p=0;當(dāng)Z值為其他標(biāo)簽對(duì)應(yīng)值時(shí),即zj,p=1.根據(jù)式(11)(18)(19)可以計(jì)算出強(qiáng)相關(guān)損失函數(shù)的前向傳播值和后向傳播值.
3.2 數(shù)據(jù)集
為了驗(yàn)證本文方法的有效性,我們?cè)?個(gè)大規(guī)模公開(kāi)數(shù)據(jù)集上做了相關(guān)實(shí)驗(yàn),分別是CIFAR-10, NUS-WIDE, SVHN.實(shí)驗(yàn)部分選取的3個(gè)數(shù)據(jù)集各有特點(diǎn):CIFAR-10為單標(biāo)簽的自然圖像數(shù)據(jù)集,SVHN為數(shù)據(jù)量不均衡的單標(biāo)簽數(shù)字圖像數(shù)據(jù)集,NUS-WIDE為多標(biāo)簽的自然圖像數(shù)據(jù)集.在這3個(gè)數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),可以很好地評(píng)估本文方法的性能.
CIFAR-10數(shù)據(jù)集包含60 000張尺寸為32×32的彩色圖像,共有10個(gè)類別,每個(gè)類別擁有6 000張圖像.為了更好地訓(xùn)練模型及評(píng)估性能,從每個(gè)類別隨機(jī)抽取1 000張圖像作為驗(yàn)證集,再隨機(jī)抽取1 000張圖像作為檢索測(cè)試集,剩余的4 000張圖像作為訓(xùn)練集.NUS-WIDE是一個(gè)公開(kāi)的大規(guī)模多標(biāo)簽圖像數(shù)據(jù)集,總共有269 648張圖像.該數(shù)據(jù)集共5 018個(gè)標(biāo)簽,每個(gè)圖像對(duì)應(yīng)1個(gè)或多個(gè)標(biāo)簽.我們挑選了21個(gè)標(biāo)簽及其相關(guān)圖像195 834張,每個(gè)標(biāo)簽都擁有500張圖像作為檢索測(cè)試集.SVHN數(shù)據(jù)集包含630 420張32×32尺寸的圖像,這些圖像來(lái)自谷歌街景上的房屋門牌數(shù)字.該數(shù)據(jù)集是一個(gè)不均衡的圖像集.比如,類別“1”包含13 861張圖像,而類別“9”僅有4 659張圖像.為了節(jié)省訓(xùn)練時(shí)間,不同于AlexNet需要227×227的輸入,我們將3個(gè)數(shù)據(jù)集圖像的尺寸均轉(zhuǎn)換成128×128進(jìn)行訓(xùn)練.
3.3 性能評(píng)估
我們采用最廣泛使用的檢索性能評(píng)估方法來(lái)比較DHIH與其他方法的檢索性能.分別是平均準(zhǔn)確率均值、返回最近鄰個(gè)數(shù)-平均準(zhǔn)確率均值曲線、模型訓(xùn)練時(shí)間以及檢索時(shí)間.計(jì)算公式為:
(20)
(21)
其中,Np為測(cè)試集圖像的總圖像數(shù),Ntp為測(cè)試集圖像中正確分類的圖像數(shù),P為查詢結(jié)果中正確分類的結(jié)果所占的比例,Pa為平均分類準(zhǔn)確度,Pm,a為多個(gè)測(cè)試集的查詢結(jié)果的平均準(zhǔn)確率均值.返回最近鄰個(gè)數(shù)-準(zhǔn)確率曲線能反映最近鄰個(gè)數(shù)對(duì)準(zhǔn)確率的影響,是大規(guī)模圖像檢索的重要性能之一.模型訓(xùn)練時(shí)間是模型訓(xùn)練時(shí)進(jìn)行一次迭代所需要的時(shí)間,記為training_time,可以反映當(dāng)前模型的計(jì)算開(kāi)銷大小,是大規(guī)模圖像檢索的重要性能之一.檢索時(shí)間為一張查詢圖像輸入到返回檢索結(jié)果所用的時(shí)間,記為query_time.
4 實(shí) 驗(yàn)
4.1 實(shí)驗(yàn)環(huán)境及參數(shù)設(shè)置
本文實(shí)驗(yàn)的環(huán)境配置是:CPU為Intel?CoreTMi7-8750H,GPU為Nvidia GeForce GTX 1060,操作系統(tǒng)為ubuntu16.04,深度學(xué)習(xí)框架為Caffe,軟件平臺(tái)為Python & Matlab.為了更好地進(jìn)行對(duì)比實(shí)驗(yàn),本文方法與對(duì)比方法使用統(tǒng)一的網(wǎng)絡(luò)結(jié)構(gòu),如表1所示.模型采用預(yù)訓(xùn)練好的AlexNet模型進(jìn)行遷移學(xué)習(xí),使用隨機(jī)梯度下降法來(lái)訓(xùn)練,學(xué)習(xí)率策略為“inv”,權(quán)值衰減量為0.000 5.訓(xùn)練過(guò)程中,基礎(chǔ)學(xué)習(xí)率為0.001,訓(xùn)練以gamma=0.1,power=0.75進(jìn)行迭代下降.
4.2 強(qiáng)相關(guān)損失函數(shù)有效性驗(yàn)證
在數(shù)據(jù)集CIFAR-10上進(jìn)行強(qiáng)相關(guān)損失函數(shù)的有效性驗(yàn)證實(shí)驗(yàn).使用表1的網(wǎng)絡(luò)結(jié)構(gòu)訓(xùn)練出模型,選取的散列碼位數(shù)為48 b,檢索返回最近鄰個(gè)數(shù)為100,accurary為訓(xùn)練模型時(shí)測(cè)試集準(zhǔn)確率.如表2所示,當(dāng)β=0時(shí),當(dāng)前損失函數(shù)為softmax交叉熵?fù)p失函數(shù),Pm,a值最低.隨著β值的增大,測(cè)試集準(zhǔn)確率提高,但檢索的Pm,a值并沒(méi)有持續(xù)提高.進(jìn)一步實(shí)驗(yàn)發(fā)現(xiàn),β值越大,模型越容易出現(xiàn)過(guò)擬合,需要使用較小β值訓(xùn)練出的模型進(jìn)行遷移學(xué)習(xí).通過(guò)與softmax交叉熵?fù)p失函數(shù)進(jìn)行比較可知,本文方法中的強(qiáng)相關(guān)損失函數(shù)能夠有效地提升模型的檢索性能.實(shí)驗(yàn)發(fā)現(xiàn),當(dāng)β=0.7,m=3時(shí),表現(xiàn)出的檢索性能最好,與softmax交叉熵?fù)p失函數(shù)相比Pm,a值提高了近4.1個(gè)百分點(diǎn).所以,我們選用這一組超參數(shù)設(shè)置進(jìn)行之后的對(duì)比實(shí)驗(yàn),即在4.3節(jié)與4.4節(jié)的實(shí)驗(yàn)中,DHIH模型β=0.7,m=3.

Table 2 Comparison of Retrieval Performance Under Different Hyper-Parameters (top_q=100,code_length=48 b)
4.3 本文方法的普遍適用性驗(yàn)證
為了驗(yàn)證深度強(qiáng)相關(guān)散列方法適用于多種卷積神經(jīng)網(wǎng)絡(luò),我們?cè)O(shè)計(jì)了3組實(shí)驗(yàn):第1組實(shí)驗(yàn)的網(wǎng)絡(luò)結(jié)構(gòu)為Vgg16[19]與Resnet50[29];第2組實(shí)驗(yàn)的網(wǎng)絡(luò)結(jié)構(gòu)為Vgg16+Hash與Resnet50+Hash,即在Vgg16與Resnet50的分類器前添加一個(gè)散列層,輸出的散列碼位數(shù)設(shè)置為48;第3組實(shí)驗(yàn)的網(wǎng)絡(luò)結(jié)構(gòu)為Vgg16+DHIH與Resnet50+DHIH,即為網(wǎng)絡(luò)添加散列層并將損失層替換為強(qiáng)相關(guān)損失層,輸出的散列碼位數(shù)設(shè)置為48,β=0.7,m=3.在模型的訓(xùn)練過(guò)程中參數(shù)與4.1節(jié)一致,數(shù)據(jù)集為CIFAR-10,不采用預(yù)訓(xùn)練模型,迭代100 000次后作為當(dāng)前網(wǎng)絡(luò)的預(yù)訓(xùn)練模型進(jìn)行微調(diào).特別地,由于Vgg16與Resnet50缺少散列層而不能輸出散列碼,我們提取Vgg16的第2個(gè)全連接層輸出矩陣(維度為1×4 096)與Resnet50的最后一個(gè)池化層輸出矩陣(維度為1×2048)進(jìn)行檢索.檢索實(shí)驗(yàn)中,top_q=100,除Vgg16與Resnet50使用歐氏距離計(jì)算相似度外,其余采用漢明距離計(jì)算相似度.
實(shí)驗(yàn)結(jié)果見(jiàn)表3,其中,code_length為當(dāng)前輸出矩陣的位數(shù);query_time為進(jìn)行相似度計(jì)算并返回前100個(gè)對(duì)應(yīng)圖像所用時(shí)間.由表3可知,為網(wǎng)絡(luò)結(jié)構(gòu)添加散列層不會(huì)過(guò)多影響模型的檢索準(zhǔn)確率,但是能夠大幅度地減少檢索所需時(shí)間.本文方法能夠很好地與Vgg16和Resnet50相結(jié)合,在提升檢索速度的同時(shí)Pm,a值也有所提升.實(shí)驗(yàn)結(jié)果證明,本文方法具有普遍適用性.

Table 3 Vgg16 and Resnet50 Combined with DHIH (top_q=100)
4.4 模型訓(xùn)練時(shí)間對(duì)比
DHIH是一種一元深度監(jiān)督散列學(xué)習(xí)方法.相對(duì)于二元或者三元的深度監(jiān)督散列學(xué)習(xí)方法,一元深度監(jiān)督散列學(xué)習(xí)方法在訓(xùn)練模型時(shí)速度更快、計(jì)算開(kāi)銷更小[30],更適用于大規(guī)模的圖像檢索任務(wù)中.為了驗(yàn)證DHIH在模型訓(xùn)練時(shí)迭代速度更快、計(jì)算開(kāi)銷更小,設(shè)計(jì)了下面一組實(shí)驗(yàn).選用DSH[16]作為對(duì)比實(shí)驗(yàn).DSH(deep supervised hashing) 是一種二元的深度監(jiān)督散列學(xué)習(xí)方法,主要思想是通過(guò)設(shè)計(jì)損失函數(shù)使得最后一個(gè)全連接層輸出一個(gè)類散列碼.DSH的損失層需要2個(gè)圖像輸入,設(shè)為I1和I2.損失層通過(guò)正則化約束I1和I2得到值為1或-1的輸出.由于在DSH中,散列碼位數(shù)過(guò)大容易出現(xiàn)過(guò)擬合[16],所以在本節(jié)的對(duì)比實(shí)驗(yàn)中,我們選取的散列碼位數(shù)為12 b.本節(jié)實(shí)驗(yàn)使用同一網(wǎng)絡(luò)結(jié)構(gòu),如表1所示,數(shù)據(jù)集為CIFAR-10,參數(shù)設(shè)置與4.1節(jié)一致,使用CPU進(jìn)行訓(xùn)練.
如圖3所示,采用同一預(yù)訓(xùn)練模型進(jìn)行遷移學(xué)習(xí),迭代次數(shù)達(dá)到8 000次時(shí),學(xué)習(xí)率為0.000 648,2個(gè)模型的損失值都趨于穩(wěn)定,模型訓(xùn)練完成.
模型訓(xùn)練時(shí)間可以反映出計(jì)算開(kāi)銷,即完成一次迭代所需時(shí)間越少,說(shuō)明當(dāng)前模型的計(jì)算開(kāi)銷越小.表4記錄了DSH模型與DHIH模型各自的訓(xùn)練時(shí)間及Pm,a值.

Fig. 3 Comparison of training loss

Table 4 Comparison of Training Time and Pm,a Between DHIH and DSH (top_q=100,code_length=12 b)
如表4所示,分別給出了DSH及DHIH兩種方法訓(xùn)練平均每迭代1 000次所需時(shí)間和迭代8 000次后模型的Pm,a值.可以看到,DHIH的模型訓(xùn)練時(shí)間小于DSH,Pm,a值大于DSH.由此可知,本文方法在正確分類及計(jì)算速度上具有優(yōu)勢(shì),能夠適用于大規(guī)模的圖像檢索任務(wù).
4.5 對(duì)比實(shí)驗(yàn)結(jié)果分析
在本節(jié)中,將DHIH與當(dāng)前檢索性能較理想的散列方法做了比較.參與對(duì)比實(shí)驗(yàn)的方法有:迭代量化散列方法(iterative quantization, ITQ)[30]、局部敏感散列(locality-sensitive hashing, LSH)[31]、基于核函數(shù)的監(jiān)督散列(supervised hashing with kernels, KSH)[24]、特征學(xué)習(xí)監(jiān)督散列方法(convolutional neural networks hashing, CNNH)[32]、深度離散散列方法(deep supervised discrete hashing, DSDH)[33]、語(yǔ)義簇一元散列方法(semantic cluster deep hashing, SCDH)[23]、多監(jiān)督離散散列(discrete hashing with multiple supervision, MSDH)[34]、深度監(jiān)督散列(DSH)[16].以上方法基于原理被分成2組:Group1 (LSH,ITQ,KSH,MSDH),傳統(tǒng)特征提取方法與散列相結(jié)合的方法;Group2 (CNNH,DSDH,SCDH,DSH),基于卷積神經(jīng)網(wǎng)絡(luò)提取圖像特征的方法.
表5給出了本文方法與對(duì)比方法在SVHN, CIFAR-10, NUS-WIDE數(shù)據(jù)集上的Pm,a值對(duì)比結(jié)果.

Table 5 Pm,a Comparison of Different Hash Methods
由表5可知:1)本文方法在3個(gè)數(shù)據(jù)集上全都表現(xiàn)優(yōu)異,各項(xiàng)Pm,a值均大幅領(lǐng)先于Group1中的各方法.說(shuō)明相比于傳統(tǒng)散列方法,DHIH模型能夠更好地提取并表示自然圖像的特征,從而提高檢索性能.2)本文方法在單標(biāo)簽數(shù)據(jù)集SVHN和CIFAR-10上的各項(xiàng)Pm,a值均優(yōu)于Group2中的各方法.說(shuō)明相比現(xiàn)有的深度散列方法,DHIH模型使用標(biāo)簽信息作為監(jiān)督信息并使用強(qiáng)相關(guān)損失函數(shù)約束散列碼生成,得到了更具有區(qū)分性的特征表示.3)面對(duì)數(shù)據(jù)量不均衡的數(shù)據(jù)集SVHN,本文方法的各項(xiàng)Pm,a值均達(dá)到0.9以上.說(shuō)明DHIH模型中的強(qiáng)相關(guān)損失函數(shù)能夠有效驅(qū)動(dòng)網(wǎng)絡(luò)去更專注于對(duì)少量樣本的學(xué)習(xí),在面對(duì)不均衡數(shù)據(jù)集時(shí)能體現(xiàn)出較好的魯棒性.4)在多標(biāo)簽數(shù)據(jù)集NUS-WIDE上,當(dāng)散列碼取16 b和32 b時(shí),本文方法的Pm,a值為各方法中最佳;但在散列碼取48 b和96 b時(shí),本文方法的Pm,a值分別低于SCDH方法0.013和0.011.由于SCDH方法在設(shè)計(jì)損失函數(shù)時(shí)特別考慮了標(biāo)簽信息,所以一定程度上加強(qiáng)了多標(biāo)簽數(shù)據(jù)集的學(xué)習(xí)及檢索任務(wù).實(shí)驗(yàn)說(shuō)明DHIH模型在面對(duì)多標(biāo)簽數(shù)據(jù)集學(xué)習(xí)及檢索任務(wù)時(shí),性能仍有提升的空間.
圖4給出了本文方法與對(duì)比方法在其他檢索性能上的實(shí)驗(yàn)對(duì)比.圖4是SVHN數(shù)據(jù)集上的檢索性能對(duì)比;圖5是CIFAR-10數(shù)據(jù)集上的檢索性能對(duì)比;圖6是NUS-WIDE數(shù)據(jù)集上的檢索性能對(duì)比.分別在這3個(gè)數(shù)據(jù)集上比較了Pm,a隨散列碼位數(shù)變化的曲線圖及Pm,a值隨返回最近鄰個(gè)數(shù)變化的曲線圖.其中,在Pm,a隨散列碼位數(shù)變化實(shí)驗(yàn)中,固定返回最近鄰個(gè)數(shù)為100.在Pm,a值隨返回最近鄰個(gè)數(shù)變化實(shí)驗(yàn)中,固定散列碼位數(shù)分別為32 b,48 b,96 b.由圖4~6可知,隨著散列碼位數(shù)的增大,各個(gè)方法的Pm,a值都增大.散列碼位數(shù)越大,散列碼包含更多的圖像信息,更具有區(qū)分性,相應(yīng)的Pm,a值更大.ITQ, LSH, DSDH方法對(duì)返回最近鄰個(gè)數(shù)十分敏感,當(dāng)返回最近鄰個(gè)數(shù)增加,Pm,a值明顯下降,而本文方法對(duì)返回最近鄰個(gè)數(shù)具有穩(wěn)定性.由圖4~6可知,本文方法Pm,a值高且對(duì)返回最近鄰個(gè)數(shù)具有穩(wěn)定性,適用于大規(guī)模的圖像檢索.

Fig. 4 Retrieval performance comparison among different models on SVHN

Fig. 5 Retrieval performance comparison among different models on CIFAR-10

Fig. 6 Retrieval performance comparison among different models on NUS-WIDE
4.6 檢索結(jié)果
散列碼位數(shù)不同時(shí)對(duì)應(yīng)的Pm,a和檢索時(shí)間不同.散列碼位數(shù)越高,漢明距離計(jì)算時(shí)開(kāi)銷越大,則檢索時(shí)間越高.為了找出檢索效果最好的散列碼位數(shù),本文設(shè)計(jì)了一個(gè)性能評(píng)估函數(shù)用來(lái)評(píng)估方法的性能:
(22)
其中,Pm,a是不同散列位數(shù)對(duì)應(yīng)的平均準(zhǔn)確率均值,r為檢索時(shí)間(query_time).由式(22)計(jì)算得到的分?jǐn)?shù)充分考慮到平均準(zhǔn)確率均值和檢索時(shí)間這2個(gè)重要的指標(biāo).最終得分與檢索性能的好壞成正相關(guān),即分?jǐn)?shù)越高,檢索性能越好.
本節(jié)實(shí)驗(yàn)使用的數(shù)據(jù)集為CIFAR-10,返回最近鄰個(gè)數(shù)為100,超參數(shù)設(shè)置為β=0.7,m=3進(jìn)行對(duì)比實(shí)驗(yàn).由表6可知,散列碼位數(shù)與Pm,a值成正相關(guān),與檢索時(shí)間也成正相關(guān).通過(guò)式(22)充分考慮模型的檢索性能最終得到,散列碼位數(shù)為48 b時(shí)DHIH模型得分最高.由此得到,48 b的散列碼表現(xiàn)出的檢索性能最好的.隨后的檢索實(shí)驗(yàn)以散列碼位數(shù)為48 b進(jìn)行.
從SVHN, CIFAR-10, NUS-WIDE三個(gè)數(shù)據(jù)集中的檢索測(cè)試集中隨機(jī)抽取部分圖像進(jìn)行檢索.圖7展示了其中的部分檢索結(jié)果.如圖7所示,本文方法能夠準(zhǔn)確地檢索到相似圖像.

Table 6 Scores in Different Bits (top_q=100)

Fig. 7 Query result
5 總 結(jié)
本文提出了一種適用于大規(guī)模圖像檢索的深度強(qiáng)相關(guān)散列學(xué)習(xí)方法.該方法能夠廣泛地應(yīng)用在各種卷積神經(jīng)網(wǎng)絡(luò)中,具有簡(jiǎn)單、高效的特點(diǎn).本文方法的主要工作在于散列碼的生成與損失函數(shù)的設(shè)計(jì).不同于深度監(jiān)督散列方法中常用的“成對(duì)”策略,為了保留散列方法計(jì)算開(kāi)銷小的優(yōu)勢(shì),該方法是一種一元深度監(jiān)督散列方法,使用隨機(jī)映射產(chǎn)生散列碼,再設(shè)計(jì)強(qiáng)相關(guān)損失函數(shù)約束散列碼的生成.強(qiáng)相關(guān)損失函數(shù)能夠驅(qū)使網(wǎng)絡(luò)學(xué)習(xí)到更具有區(qū)分性的特征.因此,該方法能夠快速且準(zhǔn)確地檢索出相似圖像.基于CIFAR-10, NUS-WIDE, SVHN這3個(gè)大規(guī)模公開(kāi)數(shù)據(jù)集的實(shí)驗(yàn)結(jié)果證明該方法的圖像檢索性能優(yōu)于目前主流方法.但該方法還存在一些不足,人為設(shè)置了2個(gè)超參數(shù),需要進(jìn)行大量的實(shí)驗(yàn)尋找效果最好的超參數(shù)設(shè)置.在今后的工作中,可以進(jìn)一步研究超參數(shù)的優(yōu)化方式.
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年12期)2018-08-26 06:03:48
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
