自動圖像標(biāo)注技術(shù)綜述
2020-11-10 12:18:38馬艷春劉永堅熊盛武唐伶俐
計算機研究與發(fā)展 2020年11期
馬艷春 劉永堅 解 慶 熊盛武 唐伶俐
(武漢理工大學(xué)計算機科學(xué)與技術(shù)學(xué)院 武漢 430070)(mayanchun@whut.edu.cn)
隨著計算機軟硬件、互聯(lián)網(wǎng)、大數(shù)據(jù)及分布式存儲等技術(shù)的不斷成熟和快速發(fā)展,圖像數(shù)據(jù)在數(shù)量和內(nèi)容上呈現(xiàn)爆炸式增長.2017年1月中國互聯(lián)網(wǎng)絡(luò)信息中心(China Internet Network Information Center, CNNIC)發(fā)布的《中國互聯(lián)網(wǎng)發(fā)展?fàn)顩r統(tǒng)計報告》顯示,網(wǎng)頁中的圖片所占比率已達總的多媒體形式的79.63%,以數(shù)字圖像作為載體也是文化資源數(shù)字化的最主要方式.然而,在數(shù)字圖像數(shù)據(jù)保持高速增長的同時,人們對圖像數(shù)據(jù)的利用能力卻沒有隨之增強.究其原因,是計算機難以通過圖像的低層視覺特征提取出可供人類理解的高層語義信息,低層視覺特征和高層語義特征之間存在“語義鴻溝”的缺陷.這也導(dǎo)致我們在應(yīng)對大規(guī)模圖像數(shù)據(jù)時缺少有效的檢索方案,從而難以獲取所需信息.
圖像自動標(biāo)注技術(shù)是減少“語義鴻溝”的最有效的途徑之一,其以圖像為研究目標(biāo),以知識為研究手段,利用人工智能和模式識別等方法完成對圖像內(nèi)容的語義解釋,使計算機系統(tǒng)自動獲取圖像蘊含的信息內(nèi)容,從而協(xié)助人們完成對圖像信息的獲取,檢索到感興趣的內(nèi)容.因此研究圖像的自動標(biāo)注技術(shù)和算法,對于幫助人類從海量圖像數(shù)據(jù)中檢索興趣內(nèi)容,獲取所需信息,具有重要現(xiàn)實意義.
在2003年以前,國內(nèi)外學(xué)者對圖像自動標(biāo)注技術(shù)的研究仍然處于初級探索階段,隨后廣大學(xué)者不但加強了對該技術(shù)的關(guān)注度,同時也取得了一定的研究成果.考察已有研究成果,大部分工作仍是將解決或縮小圖像的視覺特征表達與高層語義信息之間的鴻溝問題作為研究重點,主要探索方向為:1)選取魯棒性強、適應(yīng)廣泛的圖像特征;2)建立有效的計算模型;3)設(shè)計更加適用的標(biāo)注算法,使圖像標(biāo)注的上下文信息得到更加充分的利用;4)針對圖像本身數(shù)據(jù)量大、標(biāo)簽空間特征維度高、已有圖像標(biāo)簽環(huán)境復(fù)雜的特點,如何在不影響性能的情況下降低標(biāo)簽空間維度,去除已有圖像的標(biāo)簽噪聲.到目前為止,對各種已經(jīng)出現(xiàn)的圖像標(biāo)注模型進行統(tǒng)一分類、梳理的綜述性工作仍然相對缺乏,少量的綜述性研究工作[1-4]往往存在分類單一、歸類模糊以及綜合性不強等問題.因此,本文旨在通過深入分析和研究公開發(fā)表的圖像標(biāo)注文獻,系統(tǒng)歸類已有圖像標(biāo)注模型,總結(jié)各類模型的優(yōu)缺點、一般性問題及一般性框架,為后續(xù)圖像自動標(biāo)注領(lǐng)域的研究工作提供幫助與思路.
本文的貢獻:1)通過研究近20年公開發(fā)表的圖像標(biāo)注文獻,總結(jié)了圖像標(biāo)注模型的一般性框架;并通過該框架結(jié)合各種具體工作,分析出在圖像標(biāo)注問題中需要解決的一般性問題.2)對各種圖像標(biāo)注模型按照其主要使用的方法類型進行了歸類;對每一類方法類型的圖像標(biāo)注模型,首先進行了基本的原理介紹,然后對該方法類型下的圖像標(biāo)注模型之間的差異進行了具體的分析,最后對每一類方法類型的標(biāo)注模型做簡單總結(jié).3)總結(jié)了一些比較著名的標(biāo)注模型的性能和實驗數(shù)據(jù),并據(jù)此對各種方法類型的標(biāo)注模型做了優(yōu)缺點分析.4)總結(jié)了圖像標(biāo)注模型常用的一些數(shù)據(jù)集和評測指標(biāo).5)給出了圖像標(biāo)注領(lǐng)域一些開放式問題和研究方向.
1 圖像標(biāo)注的一般問題
圖像的自動標(biāo)注是利用人工智能或模式識別等計算機方法對數(shù)字圖像的低層視覺特征進行分析,從而對圖像打上特定語義標(biāo)簽的一個過程.本文通過對近20年各種圖像標(biāo)注模型(方法)進行深入分析與研究,總結(jié)出圖像標(biāo)注模型的通用框架(如圖1所示),并依據(jù)通用框架中對應(yīng)的各部分內(nèi)容,歸納出圖像標(biāo)注技術(shù)中存在的一些一般性問題.
如圖1所示,圖像的標(biāo)注框架總體可分為3個模塊,包括2個特征提取模塊和1個標(biāo)注模型模塊.其中,2個特征提取模塊表示通過圖像的特征提取方法以及詞匯(標(biāo)簽)的特征提取方法可分別得到對應(yīng)的圖像低層視覺特征與標(biāo)注詞特征(也稱為標(biāo)簽特征).圖像的標(biāo)注模型表示通過需要建立最關(guān)鍵的“圖像-標(biāo)簽(I-W)”之間的關(guān)聯(lián)關(guān)系,并通過該關(guān)聯(lián)關(guān)系和低層視覺特征對未標(biāo)注圖像進行標(biāo)簽預(yù)測;同時,更進一步地充分利用“圖像-圖像(I-I)”、“標(biāo)簽-標(biāo)簽(W-W)”關(guān)系對標(biāo)注模型進行優(yōu)化,使其得到更加穩(wěn)健和魯棒的標(biāo)注結(jié)果.

Fig. 1 General framework of the image annotation model
圖像的低層視覺特征提取方法包括全局特征提取方法(如顏色、形狀、紋理、直方圖等)以及局部特征提取方法(如SIFT(scale invariant feature trans-form)角點、斑點等);詞匯的特征提取方法包括“one-hot”以及“word2vec”等.根據(jù)標(biāo)注模型的不同,研究人員往往需要選擇不同的特征提取方法使選取的特征能夠適應(yīng)特定的應(yīng)用場景,從而促進模型性能的提升.由于本文關(guān)注的重心在于標(biāo)注模型本身,因此對特征提取方法不做過多討論.
圖像的標(biāo)注模型最關(guān)鍵的是需要充分利用低層視覺特征和標(biāo)注詞特征,建立起“圖像-圖像”、“圖像-標(biāo)簽”以及“標(biāo)簽-標(biāo)簽”3種關(guān)系.但是由于圖像訓(xùn)練集本身存在的固有特點、特征提取算法存在差別以及模型對各種特征的適應(yīng)性不同,所以標(biāo)注模型在建立3種關(guān)系的同時,還需要考慮7個一般性問題:
1) 標(biāo)簽的不均衡問題.在圖像的訓(xùn)練集中,有少部分標(biāo)簽只存在于較少的圖像之中,而另外一些標(biāo)簽則出現(xiàn)頻率較高,這種標(biāo)簽分布的不均衡有可能會影響模型的精確性.造成這種問題的原因是在制作訓(xùn)練集時,人們往往傾向用更加廣泛和一般性的詞匯來進行標(biāo)注,從而導(dǎo)致標(biāo)簽的頻率不盡相同.
2) 弱標(biāo)簽問題.這種問題通常在社交領(lǐng)域圖像集上出現(xiàn),即訓(xùn)練集圖像中的標(biāo)注并不能完整地表現(xiàn)圖1中反映的所有語義信息,存在標(biāo)簽缺失或錯誤的情況.產(chǎn)生這種現(xiàn)象的原因是人們在標(biāo)注時的主觀性不同.
3) 特征的高維度問題.從圖像中提取的特征往往維度過高,導(dǎo)致模型計算量增加;此外,維度過高也會產(chǎn)生特征的冗余與噪聲.
4) 特征內(nèi)維度不均衡問題.由于標(biāo)注模型往往需要使用多種低層的圖像特征共同作用進行標(biāo)簽預(yù)測,而每種特征以及特征內(nèi)的每一維度對標(biāo)簽預(yù)測的貢獻程度不一致,影響模型精確性.
5) 特征的選擇問題.針對特定標(biāo)注模型所選取、設(shè)計的視覺特征,在其他模型上通常表現(xiàn)較差.因此,在設(shè)計新的標(biāo)注模型時需考慮在多種圖像特征之中選取具有更加泛化性能的特征.
6) 3種關(guān)系利用不全的問題.由于在“圖像-圖像”、“圖像-標(biāo)簽”以及“標(biāo)簽-標(biāo)簽”3種關(guān)系中,只需通過最關(guān)鍵的“圖像-標(biāo)簽”間相關(guān)關(guān)系即可對未標(biāo)注圖像進行標(biāo)簽預(yù)測.因此,很多模型忽視了“圖像-圖像”、“標(biāo)簽-標(biāo)簽”2種關(guān)系,影響了標(biāo)注精度的進一步提升.
7) 標(biāo)注模型的計算量和運行效率問題.
圖像自動標(biāo)注模型的研究重點基本聚焦于解決上述7個問題,從而使標(biāo)注結(jié)果更加精確、模型運行高效并能適用于更多的應(yīng)用場景.
2 圖像標(biāo)注模型
圖像標(biāo)注領(lǐng)域自本世紀(jì)初進入快速發(fā)展時期以來,出現(xiàn)了各種不同的方法和模型,也有學(xué)者對各種圖像標(biāo)注模型進行綜述性研究.然而,需要說明的是,這些研究工作往往存在分類單一和不夠清晰的問題.如文獻[1-2]主要以基于內(nèi)容的圖像檢索角度進行綜述,文獻[3]主要以統(tǒng)計方法的角度進行綜述,文獻[4]雖以相對綜合的方式進行綜述,但是其對方法的類型和標(biāo)注問題進行了混合,使得歸類不夠清晰.本文針對這些問題,將眾多的圖像標(biāo)注算法和模型依據(jù)其主要使用的方法類型分為相關(guān)模型、隱Markov模型、主題模型、矩陣分解模型、近鄰模型、基于支持向量機的模型、圖模型、典型相關(guān)分析模型以及深度學(xué)習(xí)模型9個大類方法類型,并依次對每種方法類型的圖像標(biāo)注模型進行分析與總結(jié).在每種方法類型的相關(guān)小節(jié),首先對共性的原理進行介紹,再分別介紹每一種圖像標(biāo)注模型的差異.
2.1 相關(guān)模型
相關(guān)模型是圖像標(biāo)注領(lǐng)域受到關(guān)注之后最早出現(xiàn)的一類模型,相關(guān)模型的代表有TM(translation model)模型[5]、CMRM(cross-media relevance model)模型[6]、CRM(continuous-space relevance model)模型[7]以及MBRM(multiple Bernoulli relevance model)模型[8].其基本思想為:首先將圖像分塊,假定分塊的圖像特征和標(biāo)簽之間存在某種特定的概率;然后建立分塊圖像的特征和標(biāo)簽之間的聯(lián)合概率密度;最后根據(jù)待標(biāo)注圖像的分塊信息,求得其針對每個標(biāo)簽的后驗概率.
TM模型[5]借鑒了一種詞匯翻譯模型的思想.詞匯翻譯模型的原理是:給定一段分別用2種語言翻譯過的文檔,其在2種語言上的對應(yīng)關(guān)系僅僅在粗粒度(如段落或句子)上已知,而細粒度(如單詞與單詞)之間的對應(yīng)關(guān)系未知,詞匯翻譯模型即需要求解這種精確的細粒度的單詞與單詞之間的對應(yīng)關(guān)系.同理,圖像標(biāo)注問題可類比為:給定了訓(xùn)練集每幅圖像以及和其對應(yīng)的標(biāo)注詞匯,但是細化的圖像區(qū)域與每個單詞之間的對應(yīng)關(guān)系未知,模型即需要求解細粒度的圖像區(qū)域與單詞之間的對應(yīng)關(guān)系.TM模型首先將圖像按照分割算法分塊,然后用K-means算法對這些塊的圖像特征進行聚類,每一個聚類稱之為1個blob.假定每一個blob對應(yīng)1個單詞,則所有的blob和單詞之間存在詳細的對應(yīng)關(guān)系,即“probability table”.由于訓(xùn)練集中的圖像和標(biāo)注詞匯的對應(yīng)關(guān)系已知,因此,可采用EM(expectation-maximization)算法求解“probability table”.對于待標(biāo)注圖像,先求出其對應(yīng)的blob,然后根據(jù)“pro-bability table”選擇具有最高概率值的單詞作為該圖像的標(biāo)注.
CMRM模型[6]同樣需要先將圖像進行分塊,然后根據(jù)圖像塊的特征聚類成blob,并假定每副圖像I符合一個潛在的概率分布P(·|I).對于圖像標(biāo)注問題來說,假定圖像I可以由blob近似表示為{b1,b2,…,bm},單詞表示為w,則待求的P(w|I)可以近似地由貝葉斯公式得到:

(1)
針對訓(xùn)練集τ,如果假定w和b1,b2,…,bm相互獨立,則P(w,b1,b2,…,bm)可根據(jù)全概率公式得到:

(2)
由于訓(xùn)練集為固定大小,所以可認(rèn)為先驗概率P(J)為定值.P(w|J)和P(bi|J)可根據(jù)訓(xùn)練集中的統(tǒng)計信息獲得:
(3)
(4)
其中,#(w,J)表示某一個單詞在圖像J中出現(xiàn)的次數(shù)(一般來說為0或者1),#(w,τ)表示該單詞w在整個訓(xùn)練集τ中出現(xiàn)的次數(shù).#(b,J)表示圖像J中被標(biāo)記為b的blob個數(shù),#(b,τ)表示在整個訓(xùn)練集中被標(biāo)記為b的blob個數(shù).|τ|為整個訓(xùn)練集的大小,αJ和βJ為平滑因子,控制單詞和blob在圖像和訓(xùn)練集中的占比.
CRM模型[7]沒有像TM模型和CMRM模型采取將圖像分塊的方法,而是將圖像看作很多包含了顯著物體的區(qū)域{r1,r2,…,rn}疊加的結(jié)果.假定1幅圖像可以被表示為R=CM×H,每一個區(qū)域為一個r,r中的部分像素代表了圖像中的某個顯著物體,其余部分像素被設(shè)置為“透明”,多個區(qū)域疊加即構(gòu)成圖像R,詞匯{w1,w2,…,wm}用來描述區(qū)域{r1,r2,…,rn}.G為映射函數(shù),其功能為將區(qū)域r∈R映射成為一個實值特征向量g∈Rk,用來表示區(qū)域r的圖像特征.則訓(xùn)練集τ中的任一圖像J可表示為1組圖像區(qū)域和標(biāo)注詞匯的組合{RA,WB},其中RA={r1,r2,…,rnA},WB={w1,w2,…,wnB}.{RA,WB}的生成過程可分為3個獨立的步驟:
1) 從訓(xùn)練集τ中抽樣圖像J,圖像J在訓(xùn)練集中的先驗概率記為Pτ(J);
2) 在PV(·|J)的分布下,依次對WB中的每個單詞w進行抽樣,其中PV(·|J)表示單詞在圖像J條件下的概率,其中V代表潛在的概率映射函數(shù);
3) 在PR(·|J)的分布下,依次對RA中的每個區(qū)域r進行抽樣,其中PR(·|J)表示區(qū)域在圖像J條件下的概率;
則{RA,WB}的聯(lián)合概率密度可表示為

(5)

(6)

(7)
(8)
Ng是所有可以令G(r)=g的區(qū)域的總數(shù),由于無法精確估計因此取某一不依賴于g的常數(shù).Σ表示向量g每一維特征的協(xié)方差矩陣,Nw,J代表單詞w在WJ中出現(xiàn)的次數(shù),pw是單詞w在訓(xùn)練集中出現(xiàn)的頻率,w′指圖像J中出現(xiàn)的所有單詞.
CRM模型直接求取區(qū)域與詞匯的聯(lián)合概率密度,而非像TM模型中將單詞和圖像中分塊做一一對應(yīng).此外,由于其不需要生成blob,因此不會像TM模型和CMRM模型一樣受到聚類算法的影響.最后,由于其直接建模的是連續(xù)特征,因此也不會受到特征離散化的干擾.
MBRM模型[8]為基于CRM模型的改進,CRM,TM,CMRM模型都是基于詞的多項式分布,而MBRM模型是將詞的分布看作為多重伯努利分布.基于詞的多重伯努利分布在于解決多項式分布中存在的一個缺點,即在訓(xùn)練集中圖像標(biāo)注詞匯長短不一或具有層次結(jié)構(gòu)時會存在索引精度降低的問題.此外,MBRM模型為解決圖像分塊受聚類算法影響的問題,直接將圖像分成固定大小的方塊,降低了計算時間,使模型參數(shù)更容易估計,更容易關(guān)聯(lián)上下文和模型.MBRM模型對{RA,WB}的聯(lián)合概率密度可表示為

(9)
在實際標(biāo)注過程中,WB由于不可能遍歷所有詞匯組合,因此只選取1個詞,然后根據(jù)式(10)選取所需詞匯數(shù)量即可:
(10)
PV(w|J)即為采用的多重伯努利分布:
(11)
其中,Nw代表訓(xùn)練集中標(biāo)注有單詞w的圖像個數(shù),N代表訓(xùn)練集圖像總數(shù).如果w是J的標(biāo)注,則δw,J=1否則δw,J=0,μ是平滑參數(shù).
總體來說,相關(guān)模型建立了“圖像-標(biāo)簽(I-W)”之間的關(guān)聯(lián)關(guān)系,但是此類模型標(biāo)注精度并不高,其主要原因是相關(guān)模型需要假定圖像中的目標(biāo)與標(biāo)注詞匯之間存在某種概率分布關(guān)系,而由于訓(xùn)練集中的圖片數(shù)量有限,所建立的概率分布模型往往只能反映特定的訓(xùn)練集,泛化性能不高.此外,模型對圖像中的目標(biāo)需要依賴于分塊、分割以及聚類算法的先序處理,其精度、圖像中目標(biāo)的特征構(gòu)建也會受分塊以及聚類算法的影響.從速度方面來看,相關(guān)模型的計算也比較復(fù)雜,如EM算法需要大量迭代,因此耗時較高.
2.2 隱Markov模型
隱Markov模型(hidden Markov model, HMM)類似于相關(guān)模型,同樣需要根據(jù)圖像塊和標(biāo)注詞的聯(lián)合概率密度來求得最終的標(biāo)注,但不同之處在于隱Markov模型是通過隱Markov鏈來建立這種相關(guān)關(guān)系.HMM的代表模型有文獻[9-13]等.
HMM模型[9]利用I={i1,i2,…,iT}代表圖像中被分割的有序區(qū)域,圖像區(qū)域按照固定個數(shù)4×6來進行劃分.每一區(qū)域的圖像特征為d維向量xt∈Rd,{c1,c2,…,cN}代表圖像的標(biāo)注詞匯.模型將標(biāo)注詞匯看作是隱Markov鏈,也即鏈上的隱含狀態(tài)st∈{c1,c2,…,cN},xt由潛在的分布函數(shù)f(·|st)產(chǎn)生.根據(jù)Markov鏈公式,由有序區(qū)域r1={x1,x2,…,xT}和某一有序標(biāo)注詞匯S1={s1,s2,…,sT}組成的聯(lián)合概率密度可表示為
f(x1,x2,…,xT,s1,s2,…,sT|s0)=
(12)
其中s0認(rèn)為已知,由于圖像的標(biāo)注詞匯是無序的,用最大似然的方法去掉式(12)中標(biāo)注詞匯的序列性即有:
(13)
其中C為所有的詞匯序列組合.對未知圖像是否標(biāo)注某一詞匯c,可根據(jù)貝葉斯公式得到:

(14)

(15)
式(15)為定值,因此

(16)

(17)
f(x|c)表示隱Markov模型的混淆矩陣概率,其中wm,c表示權(quán)值,μm,c代表在所有詞匯V中c所對應(yīng)的所有區(qū)域特征x的均值,Σm,c代表向量x元素間協(xié)方差矩陣.
TSVM-HMM(transductive support vector machine based HMM)模型[10]的提出,是為了改善HMM模型中存在的問題,即若訓(xùn)練集中已標(biāo)注的圖像區(qū)域過少,會導(dǎo)致對HMM中混合概率密度f(feature|word)估計不準(zhǔn)確.TSVM-HMM即基于支持向量機(support vector machine, SVM)的半監(jiān)督學(xué)習(xí)方法,首先利用訓(xùn)練集中已標(biāo)注的圖像區(qū)域訓(xùn)練一個二分類的SVM分類器,接著根據(jù)該分類器對訓(xùn)練集中未標(biāo)注區(qū)域進行分類,將其中最可能的相關(guān)區(qū)域和非相關(guān)區(qū)域分別加入到對應(yīng)的訓(xùn)練集中;然后根據(jù)新擴展的訓(xùn)練集重新訓(xùn)練SVM,并重復(fù)對未標(biāo)注區(qū)域的分類過程,直到重復(fù)次數(shù)達到預(yù)設(shè)的最大迭代次數(shù).最后,由于新擴展的訓(xùn)練集之中,具有更多的已標(biāo)注圖像區(qū)域,因此對HMM中混合概率密度的建模也會更加準(zhǔn)確.
SHMM(spatial HMM)模型[11]以及SMK(spatial Markov kernels)模型[12]為HMM模型在垂直方向上的擴展,也即對于圖像的分塊來說,SHMM模型分別考慮了水平和垂直方向前一相鄰圖像分塊對當(dāng)前圖像分塊的影響:
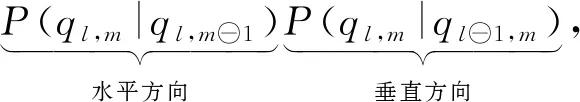
(18)
l,m表示圖像分塊的位置下標(biāo),q代表圖像分塊的狀態(tài),?可理解為減號,代表在橫向或縱向的位置下標(biāo)做向前移動的操作.
HMM-SVM模型[13]首先分別對顏色和紋理特征用Markov模型進行建模,據(jù)此可分別得到基于顏色和紋理特征的對圖像分塊區(qū)域的標(biāo)注概率,在此過程之后,每個圖像分塊都可以得到一個二元的預(yù)測組{Pcolor,Ptexture},其中Pcolor和Ptexture分別代表某圖像塊基于顏色和基于紋理特征的預(yù)測結(jié)果.然后,將此二元預(yù)測組{Pcolor,Ptexture}作為中級的圖像輸入特征,標(biāo)注單詞作為分類結(jié)果,訓(xùn)練出多個one-against-all的SVM分類器.最后,根據(jù)訓(xùn)練出的SVM分類器對圖像進行標(biāo)注.
基于HMM的模型用一種很自然的方式建模了每個單詞和圖像特征之間的關(guān)系f(feature|word),也即“圖像-標(biāo)簽(I-W)”之間的關(guān)聯(lián)關(guān)系,從可解釋性上提供了有效的推導(dǎo)過程;而且相較于相關(guān)模型,基于HMM的模型更關(guān)注抽象信息,如對整個語料庫來說,僅保留了如均值和方差等圖像的高層次特征,因此模型計算效率較高.然而基于HMM的模型也繼承了Markov模型的固有缺陷,即在給定的標(biāo)注詞條件下,圖像的特征是條件獨立的,沒有利用圖像內(nèi)容上的相關(guān)性,并且對于“標(biāo)簽-標(biāo)簽(W-W)”與“圖像-圖像(I-I)”特征之間所存在的復(fù)雜語義關(guān)系,僅通過混合矩陣進行建模也不夠精確.
2.3 主題模型
LSA(latent semantic analysis)模型是主題建模的基礎(chǔ),其最早的用途是對文檔進行檢索[14],它的核心思想是把對應(yīng)的“文檔-項”矩陣分解成相互獨立的“文檔-主題”矩陣和“主題-項”矩陣,從而在隱藏的主題空間建立文檔和詞匯之間的語義關(guān)系.在文檔檢索領(lǐng)域,“項”即對應(yīng)檢索詞匯.在圖像標(biāo)注領(lǐng)域,LSA模型將圖像作為一個獨立的文檔,標(biāo)注詞匯或者視覺特征等被定義為“項”.假定“文檔-項”矩陣表示為A∈RN×M,N為文檔的數(shù)量,M為項的數(shù)量,則矩陣A可通過奇異值分解(singular value decomposition, SVD)為
A≈USVT,
(19)
其中U∈RN×K,S∈RK×K,V∈RM×K,K表示降維后的主題空間維度,U的每一行代表訓(xùn)練集圖像在主題空間中的特征表示,該主題空間(也稱為隱語義空間)可表示“項”之間的語義關(guān)聯(lián)關(guān)系.當(dāng)利用訓(xùn)練集圖像求解U與V之后,對未標(biāo)注圖像q∈R1×M來說,可先將其映射至主題空間

(20)

對LSA模型的改進一般集中在對“文檔-項”矩陣中“項”的表征方面.如文獻[15]首先將圖像劃分為上、中、下3個區(qū)域,然后通過圖像的標(biāo)注詞以及每個區(qū)域的RGB顏色直方圖、區(qū)域號和區(qū)域坐標(biāo)串聯(lián)起來,形成的向量表征“文檔-項”矩陣中“項”.
文獻[16]將圖像視覺特征和標(biāo)注詞匯特征融合的結(jié)果作為“文檔-項(document-term)”矩陣中的“項”.對于每幅圖像中的視覺特征,其采用了一種視覺詞袋(bag of words, BOW)的模型進行構(gòu)建.首先對每幅圖像按矩形柵格以及分割算法分塊,同時求出每幅圖像的角點;然后,串聯(lián)每個圖像塊的質(zhì)心位置、RGB直方圖、Gabor系數(shù)以及每個角點的SIFT特征[17]作為圖像的視覺特征;之后再用K-means聚類算法將圖像集中所有的視覺特征聚類為k個簇,每幅訓(xùn)練圖像即可根據(jù)其視覺特征在聚類簇中出現(xiàn)的次數(shù)離散化為一種“次數(shù)向量”作為該圖像的“視覺項”;最后,訓(xùn)練集中所有圖像即可形成新的“文檔-視覺項”矩陣Md,v.對于每幅圖像中標(biāo)注詞匯的特征,其采用向量空間模型(vector space model, VSM)進行構(gòu)建,也即獲得其詞頻以及逆文檔詞頻作為“詞匯項”,從而使訓(xùn)練集中所有圖像形成新的“文檔-詞匯項”矩陣Md,t.在Md,v與Md,t獲取之后,根據(jù)原始標(biāo)注圖像視覺特征與標(biāo)注詞匯之間的對應(yīng)關(guān)系獲取“視覺項”與“詞匯項”的互相關(guān)矩陣Mt,v,之后即可將Mt,v降維到主題空間,盡管取得了一定的成功,基于SVD的LSA仍然存在計算量較大的缺點,而且從概率的意義上也缺乏可解釋性.
PLSA(probabilistic latent semantic analysis)模型[18]是一種在概率意義上具有可解釋性的主題模型.模型假定主題zk為基于“文檔”和“項”的生成模型中存在的一個隱藏主題空間中的元素,“文檔”與“項”之間相互獨立.則包含有“文檔-項-主題”三者的聯(lián)合概率密度可表示為
P(xj,zk,di)=P(di)P(zk|di)P(xj|zk),
(21)
其中,x,z,d分別代表“項”、“主題”與“文檔”,i,j,k分別為其對應(yīng)的索引.通過求解z的邊緣概率密度即可求得“文檔-項”的聯(lián)合概率密度:
(22)
類似于相關(guān)模型,這里P(di)代表某文檔在整個訓(xùn)練集中的占比,P(z|d)和P(x|z)分別代表選定文檔包含某一主題的概率以及選定主題包含某一“項”的概率,在訓(xùn)練階段,可根據(jù)訓(xùn)練集由EM算法求解.在圖像標(biāo)注領(lǐng)域,P(di)表示圖像在訓(xùn)練集中的占比,“項”x可表示普通變量,也可表示特征向量,其物理含義根據(jù)各種模型變體略有不同.如文獻[15]中的PLSA-MIXED模型,串聯(lián)單詞特征與視覺特征形成x=(word,visual).在測試階段,對于未標(biāo)注圖像,則將其標(biāo)注部分置0為xnew=(0,visualnew),然后根據(jù)folding-in算法[18]求得其P(z|dnew),從而進一步得到P(x|dnew),圖像的標(biāo)注P(word|dnew)即可從P(x|dnew)抽取得到.對PLSA模型的改進大多集中在對多種模態(tài)的利用方式上以及多種圖像視覺特征的使用方式層面.如文獻[19-20]中的PLSA-WORD模型,將圖像與標(biāo)注詞匯視為2種不對等模態(tài),通過不對稱的學(xué)習(xí)算法從標(biāo)注詞匯的數(shù)據(jù)中學(xué)習(xí)一個潛在的空間,并將其關(guān)聯(lián)到視覺模態(tài),從而改進了PLSA-MIXED模型中將標(biāo)注詞匯與圖像視覺特征2種模態(tài)視為同等重要的缺陷,也即改善了標(biāo)注詞匯數(shù)量和圖像視覺特征數(shù)量之間的不平衡問題.文獻[21]提出的PLSA-FUSION模型和文獻[22]提出的MM-PLSA(multilayer multimodal PLSA)模型在PLSA-WORD模型基礎(chǔ)上進一步使用2組潛在主題分別從標(biāo)注詞匯和圖像視覺特征2種模態(tài)中學(xué)習(xí),然后再融合為一個共同的潛在空間.其中,PLSA-FUSION模型采用了一種自適應(yīng)的動態(tài)方法進行學(xué)習(xí),根據(jù)每幅圖像各自的視覺詞分布確定各不相同的權(quán)值對2組主題進行融合;MM-PLSA模型將標(biāo)注詞匯和圖像視覺特征的2種模態(tài)學(xué)習(xí)到的主題作為2片葉子,再通過1個頂層的PLSA根節(jié)點構(gòu)建1個多層次的主題空間樹,進而對2組主題進行融合.文獻[23]提出的MF-PLSA(multi-feature PLSA)模型在原始模型基礎(chǔ)上采用了多特征組合而非融合的方式進行改進,其將圖像的SIFT[17]特征v和局部變換顏色直方圖特征(local transformed color histogram, LTCH)w分別作為條件獨立于主題z的變量,從而求得圖像視覺特征(SIFT和LTCH)與文檔d的聯(lián)合概率密度變?yōu)?/p>
(23)
其中N(w,v,d)代表(w,v,d)的共現(xiàn)次數(shù).
主題模型最早用于對文檔的檢索,解決了檢索問題中的“一詞多義”以及“一義多詞”問題.在圖像標(biāo)注領(lǐng)域,主題模型同樣通過構(gòu)建隱藏的主題空間,使得具有語義相似度的模態(tài)能夠映射到同一主題,或者同一主題可被多種模態(tài)所表示.因此,隱藏的主題空間能夠較好地建立起圖像底層視覺特征同自然語義之間的聯(lián)系,也即“圖像-標(biāo)簽(I-W)”之間的關(guān)聯(lián)關(guān)系.但由于主題模型依然是通過選取訓(xùn)練集圖像中相應(yīng)的底層視覺特征和標(biāo)注詞匯來進行概率運算,因此其概率分布難以有效描述樣本外的情況,泛化性能不高.對于選取何種底層視覺特征、標(biāo)注詞匯特征,以及對特征的融合利用也是主題模型需要解決的難題.此外,主題模型中需用到SVD分解以及EM算法等,都需要耗費大量時間以及運算資源.
2.4 矩陣分解模型
基于矩陣分解的圖像標(biāo)注通過矩陣分解的方式來建立圖像、標(biāo)簽等之間的相關(guān)關(guān)系.本文歸類于主題模型中的LSA模型,通過SVD分解的方式建立隱語義空間,因此也可歸類于矩陣分解模型,但由于其分解之后的物理意義更偏重隱藏的語義主題,因此本文將其歸類于主題模型.
另一類矩陣分解如非負矩陣分解(nonnegative matrix factorization, NMF)模型最初是用來做人臉識別任務(wù)[24],其核心思想是將圖像的特征矩陣V分解為2個非負的矩陣因子W和H:
V≈WH,
s.t. ?Wi,j,Hi,j≥0,
(24)
其中,W代表特征在新的空間形成的基,H可代表某樣本在基W下的坐標(biāo),因此如果將W形成的空間看做新的語義空間,則H·,j可代表樣本在語義空間下的特征表示,因此基于NMF的圖像標(biāo)注模型關(guān)鍵在于尋找可靠的矩陣分解因子W和H.基于矩陣分解的圖像標(biāo)注模型代表有文獻[25-30]等.
文獻[25]類似于文獻[16],首先利用SIFT特征建立的視覺詞項作為圖像特征.接著,對于訓(xùn)練集所有圖像來說,根據(jù)圖像特征即可構(gòu)建“視覺詞匯-文檔”矩陣V,對V做非負矩陣分解V≈WH.由于H可視為樣本在語義空間下的特征,則對于未標(biāo)注圖像的語義特征,可通過hquery=W-1q求得,其中q為圖像的原始特征.然后,通過cos距離計算,得到其在語義空間中的近鄰圖像.最后,將最近鄰的圖像標(biāo)簽擴散至未標(biāo)注圖像.

文獻[27]提出了一種松散的聯(lián)合框架,同時對圖像的視覺特征和詞匯特征進行非負矩陣分解.如式(25)所示,統(tǒng)一空間中視覺模式和詞匯模式之間的相似性越高,則其距離越近:

(25)
其中,V和T分別代表圖像的視覺特征和詞匯特征.α1,α2,α3分別代表正則化系數(shù),ΔH=H1-λH2則用來控制統(tǒng)一空間視覺模式和詞匯模式之間的相似性.
文獻[28]在文獻[27]的基礎(chǔ)上,進一步將所有的視覺特征種類包括詞匯特征都視為一種視圖(view).在同一框架中:1)對每種視圖同時做非負矩陣分解;2)同時降低所有視圖在統(tǒng)一空間的相互距離;3)對所有視圖做拉普拉斯正則化操作.融合3種操作即可得到優(yōu)化目標(biāo):

(26)
其中,n為訓(xùn)練集樣本個數(shù),N為視覺特征個數(shù),+1代表將詞匯特征也作為一種視圖,Q用來控制在統(tǒng)一空間中模式之間的相似性,L表示拉普拉斯正則化約束.
傳統(tǒng)的NMF模型通過非負矩陣分解求得新的特征基之后,往往還需要額外的分類步驟對未標(biāo)注圖像進行標(biāo)注,導(dǎo)致效率低下.文獻[29]針對此問題,提出了一個可以同時進行矩陣分解和分類步驟的框架.具體來說,對圖像的特征矩陣F進行非負矩陣分解F≈WH,但有別于傳統(tǒng)NMF模型,該模型將H視為圖像的近似標(biāo)簽矩陣,用來決策某一圖像是否屬于標(biāo)簽i.因此,H應(yīng)當(dāng)與圖像原始標(biāo)簽矩陣L具有一致性.據(jù)此可得優(yōu)化目標(biāo)式為

(27)
其中D用來度量H和原始標(biāo)簽矩陣L的相似性.
文獻[30]提出了一種具有結(jié)構(gòu)化信息的NMF模型,其核心思想是具有相同標(biāo)簽的圖像特征經(jīng)分解過后應(yīng)該處在相同的子空間中,也即分解過后的圖像特征矩陣應(yīng)當(dāng)具有對角的塊狀結(jié)構(gòu).假定V為分解過后的特征矩陣,為了保持V的塊狀結(jié)構(gòu),模型定義了指示矩陣I:
(28)
其中C表示標(biāo)簽的個數(shù),并以指示矩陣I定義最小化正則化項(式):
(29)
其中⊙表示矩陣元素的對應(yīng)相乘運算.因此,模型總的優(yōu)化目標(biāo)可被定義為

(30)
由于分解過后的特征矩陣V中每個塊結(jié)構(gòu)對應(yīng)一個標(biāo)簽類別,因此特征具有較強的判別能力,更容易區(qū)分不同標(biāo)簽類別的圖像.
文獻[31-32]采用了多層次矩陣分解的方法建立圖像視覺特征、標(biāo)簽特征以及其相關(guān)關(guān)系.文獻[31]假定X表示圖像的視覺特征矩陣,F(xiàn)表示標(biāo)簽矩陣,則:
(31)
通過多層次的矩陣分解,將F與X統(tǒng)一到一個潛在的語義空間,也即第M層.Wm(m=1,2,…,M)表示第m層的變換矩陣,V表示潛在的標(biāo)簽特征矩陣,Um表示第m層的圖像特征矩陣.其目標(biāo)函數(shù)(式(32))類似于傳統(tǒng)的NMF模型:

(32)
其中后2項分別代表正則化操作.文獻[32]在文獻[31]的基礎(chǔ)上,進一步對UM-1,U,V增加了拉普拉斯約束,如式(33)所示,使?jié)撛谡Z義空間中的特征矩陣以及標(biāo)簽矩陣具有更好的聚類特性.

(33)
其中,rm表示第m層矩陣分解的節(jié)點個數(shù).
此外,還有其他的矩陣分解模型如文獻[33]提出了一種多模態(tài)的概率矩陣分解(probabilistic matrix factorization, PMF)模型用來建立“特征-標(biāo)簽”、“特征-特征”以及“標(biāo)簽-標(biāo)簽”之間的相關(guān)關(guān)系,然后通過分解得到的代表潛在語義空間的矩陣因子來連接3種相關(guān)關(guān)系.文獻[34]采用弱監(jiān)督的方法使隱語義空間中“標(biāo)簽相似矩陣”和“特征相似矩陣”與原始空間中的“標(biāo)簽相似矩陣”和“特征相似矩陣”相似度最小,文獻[35]通過低秩矩陣分解來尋找更加本質(zhì)和符合感官“特征-標(biāo)簽”矩陣.
矩陣分解模型如NMF可以很好地表征圖像的局部特征,從直觀上來說,圖像總體是由各局部特征疊加而成,因此具有很好的解釋性.此外,矩陣分解模型對于標(biāo)簽具有噪聲和缺失的情況具有較高的魯棒性.然而,如何選取合適的矩陣分解因子中的隱語義空間維度,以及如何有效、快速求解由矩陣分解轉(zhuǎn)化而來的優(yōu)化目標(biāo),仍然是矩陣分解模型面臨的問題.
2.5 近鄰模型
近鄰模型在圖像標(biāo)注模型中思想比較簡單,其基本原理是具有相似低層視覺特征的圖像應(yīng)該具有相似的語義.因此,利用近鄰模型進行圖像標(biāo)注的一般步驟為:1)構(gòu)建圖像低層視覺特征;2)通過對低層視覺特征采用某種距離度量策略,選擇與待標(biāo)注圖像距離較近的已標(biāo)注圖像;3)通過合適的標(biāo)簽擴散方法將已標(biāo)注圖像中的標(biāo)簽應(yīng)用到待標(biāo)注圖像.相應(yīng)地,對近鄰模型的改進也基本集中在:1)選取或構(gòu)造更適合用來標(biāo)簽擴散的視覺特征;2)采取更合適的距離度量策略,使圖像集中視覺特征的距離遠近符合語義空間上的距離遠近;3)采用更加優(yōu)化的標(biāo)簽擴散算法使標(biāo)簽?zāi)軌蛄己脭U散.近鄰模型的代表模型有JEC(joint equal contribution)模型[36]、TagProp(tag propagation)模型[37]、2PKNN(2-passk-nearest neighbor)模型[38]、VS-KNN(visual semantic KNN)模型[39]、SNLWL(semantic neighborhood learning for weakly label)模型[40]、SEM(semantic extension model)模型[41]、weight-KNN(weight KNN)模型[42]、AWD-IKNN(adaptive weighted distance method based on improved KNN)模型[43]、NMF-KNN模型[44]、AL(active learning)模型[45]等.

TagProp模型[37]為了解決近鄰圖像之間權(quán)值不均衡以及各種視覺特征之間權(quán)值不均衡的問題,提出了一種加權(quán)的近鄰模型.即假定單詞w出現(xiàn)在圖像i的預(yù)測值p(yi,w=+1)(+1-1表示標(biāo)簽是否存在)可由所有近鄰圖像j對i的條件預(yù)測值加權(quán)得到:
(34)
從而進一步求得對數(shù)似然函數(shù)L:
(35)
其中,ci,w即為近鄰圖像間權(quán)值,用來解決某一標(biāo)簽對應(yīng)的負樣本遠大于正樣本的問題,也即對某一單詞,不包含該單詞的圖像個數(shù)要遠大于包含該單詞的圖像個數(shù)所帶來的不均衡問題.其中,若yi,w=+1,則令ci,w=1n+;若yi,w=-1,則令ci,w=1n-,n+和n-分別代表正負樣本個數(shù).對于各種視覺特征之間權(quán)值不均衡的問題,TagProp模型定義πi,j為
(36)
從而使得πi,j可以根據(jù)圖像j依據(jù)到圖像i的距離而衰減,W表示每種視覺特征的權(quán)值向量,di,j表示圖像i和圖像j各種視覺特征的基礎(chǔ)距離所構(gòu)成的向量.此外,為解決標(biāo)簽不平衡問題,也即使用頻率較少的標(biāo)簽召回率低的問題,該模型利用sigmoid函數(shù)改進對圖像i的預(yù)測:
p(yi,c=+1)=σ(αwxi,w+βw),
(37)
使得相對稀少的標(biāo)簽權(quán)重增強,而減弱出現(xiàn)頻率較高的標(biāo)簽權(quán)重.其中sigmoid函數(shù)σ(z)=(1+exp(-z))-1.
2PKNN模型[38,46]為解決標(biāo)簽的不平衡問題,采取了一種語義近鄰組的方式來構(gòu)建圖像的近鄰集合.假定將訓(xùn)練集中每個標(biāo)簽yi看作為一個分類,則訓(xùn)練集τ可被劃分為l個“標(biāo)簽-圖像”對,即τ={(τ1,y1),(τ2,y2),…,(τl,yl)},其中l(wèi)代表標(biāo)簽個數(shù),τi表示標(biāo)簽yi對應(yīng)的圖像集合,每一個集合τi稱之為一個語義組.給定未標(biāo)注圖像J,從每個語義組中選擇K1個視覺相似的近鄰構(gòu)成新的集合τJ.由此方式構(gòu)建的近鄰集合τJ,每個標(biāo)簽在其中至少會出現(xiàn)K1次,因此解決了標(biāo)簽不平衡的問題.根據(jù)近鄰集合τJ可以定義未標(biāo)注圖像J對于標(biāo)簽yk∈Y的后驗概率:

(38)
其中,如果標(biāo)簽yk屬于某一近鄰圖像Ii的標(biāo)簽集合Yi,則δ(yk∈Yi)=1,否則δ(yk∈Yi)=0.exp(-D(J,Ii))表示基于近鄰圖像間視覺特征的距離對于后驗概率的貢獻.為了解決各種視覺特征之間以及特征向量內(nèi)部的不均衡問題,2PKNN為視覺特征距離D(A,B)分別定義了距離空間權(quán)值w以及特征空間權(quán)值v:
(39)
n為視覺特征的個數(shù),Ni為對應(yīng)視覺特征的維度,di,j(A,B)表示對應(yīng)視覺特征的基礎(chǔ)距離.然后,根據(jù)組間最大、組內(nèi)最小的原則定義LOSS函數(shù),并采用隨機梯度下降求解參數(shù).在P(J|yk)求解之后,最后可根據(jù)貝葉斯公式求解后驗概率:
(40)
其中先驗概率P(yk)和P(J)可認(rèn)為是定值.

S(xj,xk)=αD(xj,xk)+(1-α)dis(xj,xk),
(41)
其中xj表示某一標(biāo)簽的語義近鄰組內(nèi)的圖片,xk表示該標(biāo)簽對應(yīng)的語義近鄰組外的圖片,α表示平滑參數(shù),D和dis分別表示圖像的視覺特征距離和標(biāo)簽距離.根據(jù)式(41)求得每一個近鄰組內(nèi)圖片K2個近鄰組外的鄰居,再求并集即可得到對應(yīng)次近鄰圖像集合τ′.
SNLWL模型[40]構(gòu)建語義近鄰的方式類似于2PKNN模型[38,46],但是為了解決弱標(biāo)簽和標(biāo)簽不平衡問題,通過在構(gòu)建語義近鄰組之前求解其定義的學(xué)習(xí)誤差函數(shù)(如式(42))來平衡訓(xùn)練集樣本標(biāo)簽,進而使低頻標(biāo)簽可以更有效地參與標(biāo)注.

(42)

SEM模型[41]和weight-KNN模型[42]針對傳統(tǒng)模型需要手動設(shè)計視覺特征并且視覺特征性能泛化程度不高的問題,采用了從預(yù)訓(xùn)練的經(jīng)典深度學(xué)習(xí)模型中抽取特征的方法來構(gòu)建具有更泛化的視覺特征,此外,weight-KNN模型為了解決視覺特征元素之間的不平衡問題以及充分利用標(biāo)簽之間的相關(guān)信息,采用了一種多標(biāo)簽線性判別(multiple linear discriminant analysis, MLDA)方法[47],在KNN的距離計算中給元素賦值適當(dāng)?shù)臋?quán)重W.假定圖像的每個標(biāo)簽為1個類別,則權(quán)重W需要滿足條件使得類內(nèi)距離最近、類間距離最遠.因此,根據(jù)MLDA方法可定義目標(biāo)函數(shù)為
(43)
其中,類內(nèi)散布矩陣Sb、類間散布矩陣Sw以及總散布矩陣St分別定義為
(44)
K和k分別為標(biāo)簽個數(shù)和索引,N和Nk分別為訓(xùn)練集圖像數(shù)目和第k個標(biāo)簽對應(yīng)的圖像數(shù)目,mk和m分別代表第k個標(biāo)簽對應(yīng)圖像的特征向量均值和總的圖像特征向量均值,fi表示第i幅圖像的特征向量.對于標(biāo)簽之間相關(guān)信息的利用,weight-KNN模型重定義了標(biāo)簽矩陣L:
L=YC,
(45)
其中,Y為原始標(biāo)簽矩陣,C∈RK×K代表標(biāo)簽之間的相關(guān)關(guān)系矩陣,元素Ck,l表示任意第k個和第l個標(biāo)簽之間的相關(guān)性:
(46)
將包含有標(biāo)簽關(guān)系的新標(biāo)簽矩陣引入之后可得到新的散布矩陣為
(47)
Sw=St-Sb,

AWD-IKNN模型[43]集成了圖像的CNN(con-volutional neural networks)特征與傳統(tǒng)視覺特征,并且針對標(biāo)簽的不平衡問題設(shè)計了一種加權(quán)模型(如式(48)):

(48)
D(i,j)表示圖像i和j之間的視覺特征距離,Ω1和Ω2分別表示圖像i和圖像j對應(yīng)的標(biāo)簽集合,W(l,k)表示在對應(yīng)圖像中,針對第k種特征,標(biāo)簽l對應(yīng)的權(quán)值,N為圖像特征數(shù)目,dk(xi,k,xj,k)為第k種特征的基礎(chǔ)距離.由式(48)可知,如果2個圖像之間存在共同的標(biāo)簽,則該標(biāo)簽的權(quán)重將被重復(fù)計算,也即表明這些標(biāo)簽的相應(yīng)特征在圖像之間的距離運算中權(quán)重更大.所有標(biāo)簽都會被同等對待即使某些標(biāo)簽出現(xiàn)頻率較小,如果2個圖像有相同標(biāo)簽,則2個圖像之間的距離會更短,從而解決標(biāo)簽不平衡的問題.根據(jù)正樣本(具有相同標(biāo)簽的圖像)間距最小、負樣本間距最大的原則來定義LOSS函數(shù):
(49)

NMF-KNN模型[44]借鑒了NMF多視圖聚類[48]的思想,將每一種視覺特征以及圖像的標(biāo)簽特征視作為一種視圖(view).訓(xùn)練集所有圖像針對任意一種特征都可構(gòu)成特征矩陣X(f),X(f)可通過NMF分解成為1組由基U(f)和系數(shù)相關(guān)表達式V(f)組成的矩陣.在NMF分解之后,系數(shù)表達式V(f)應(yīng)當(dāng)與潛在的表達空間V*有近似的語義.由此,可定義LOSS函數(shù)為

s.t. ?1≤f≤F+1,U(f),V(f),V*≥0,
(50)

AL模型[45]類似于2PKNN模型,仍然采取了語義近鄰組的方法來避免標(biāo)簽不平衡問題;此外,與傳統(tǒng)方法[36-38]選擇固定數(shù)量的近鄰數(shù)量有所不同,AL模型采取了一種動態(tài)閾值的方法選取近鄰圖像.其中閾值定義為
τ=Sm-ε,
(51)
其中,Sm為圖像視覺特征相似度均值,ε為控制召回率大小的容忍值參數(shù).
此外,還有其他的基于KNN的圖像標(biāo)注模型,如文獻[49]定義了一個最優(yōu)化的框架,分別集成了標(biāo)簽集合與圖像之間的相關(guān)關(guān)系以及圖像集合之間的相關(guān)關(guān)系2種因素,用以提高標(biāo)注精度.文獻[50]采用了SIFT以及SURF(speeded up robust features)的圖像局部特征進行單標(biāo)簽圖像分類.文獻[51]在JEC模型基礎(chǔ)上增加了一種標(biāo)簽過濾機制,用以去除大部分圖像中不相關(guān)標(biāo)簽,從而提高標(biāo)注的精度.文獻[52]進一步將近鄰圖像劃分為強相關(guān)圖像近鄰與弱相關(guān)圖像近鄰,同時提出了基于范圍約束視覺鄰域的標(biāo)簽相關(guān)隨機搜索方法,可以找出每個候選標(biāo)簽的可信部分,從而增強注釋性能的魯棒性.
近鄰模型的基礎(chǔ)思想相對比較簡單,通常聚焦于解決圖像標(biāo)注的一般性問題(如弱標(biāo)簽、標(biāo)簽不平衡、特征的選取與權(quán)值賦值等),并且與其他方法的結(jié)合也比較靈活.由于其標(biāo)注效果相對較好,近年來得到了廣泛的研究和應(yīng)用.近鄰模型由于需要與訓(xùn)練集中的圖片進行輪詢對比,因此只適用于較小或中型的數(shù)據(jù)集,在面對超大規(guī)模數(shù)據(jù)集時往往耗時較長.
2.6 基于SVM的模型
SVM是專門用于解決二分類問題的分類器,而圖像的標(biāo)注問題可被視為圖像的多分類問題.因此,最基本的基于SVM的圖像標(biāo)注模型[53]是通過訓(xùn)練多個SVM分類器并采取一定的策略結(jié)合多個分類器的結(jié)果來完成分類.常用的2種策略包括“one-against-all”和“one-against-one”2種,假定將每個標(biāo)簽作為1個類別,“one-against-all”策略是對每個標(biāo)簽訓(xùn)練1個“本標(biāo)簽相對于其他標(biāo)簽”的SVM,每個SVM分類器都會定義1個判別函數(shù)fi用來區(qū)分某一圖像是否屬于標(biāo)簽i或?qū)儆谄渌麡?biāo)簽,多分類器的輸出即為具有最大輸出的判別函數(shù)fi所對應(yīng)的標(biāo)簽類別.最常用的判別函數(shù)可表示為
(52)
其中,x表示圖像的視覺特征,wi和bi分別表示為第i個標(biāo)簽所對應(yīng)SVM分類器的權(quán)值和偏置.對待標(biāo)注圖像的標(biāo)注為:
(53)
其中K表示標(biāo)簽個數(shù).
“one-against-one”策略是對任意2個標(biāo)簽都訓(xùn)練1個SVM.然后對未標(biāo)注圖像的分類結(jié)果進行投票,投票最多的標(biāo)簽即認(rèn)為是圖像標(biāo)簽.
文獻[54]結(jié)合了多實例學(xué)習(xí)的方法,針對圖像的“包特征(bag-features)”與全局特征分別構(gòu)建2類SVM,并針對2類SVM的分類結(jié)果進行融合得到最終的標(biāo)注結(jié)果.假定依據(jù)“包特征”所構(gòu)建SVM的輸出作為概率向量表示為pm,依據(jù)全局特征所構(gòu)建SVM的輸出作為概率向量表示為pg,則融合2類SVM的最終概率向量p可表示為
p=w⊙pm+(1-w)⊙pg,
(54)
其中⊙表示對應(yīng)元素相乘,概率向量的長度與標(biāo)簽個數(shù)相同,概率向量pm與pg的每個元素表示圖像屬于某一標(biāo)簽的概率.w表示對應(yīng)的權(quán)值,可以通過“包特征”和“全局特征”分別對應(yīng)的權(quán)值向量wm與wg進行估計:
(55)
其中除法表示為對應(yīng)元素相除.wm,wg中的元素可通過式(56)進行估計:
(56)
其中Lm(n,c)與Lg(n,c)分別表示圖像n依據(jù)“包特征”屬于標(biāo)簽c的概率和依據(jù)“全局特征”屬于標(biāo)簽c的概率.
文獻[55]為改善傳統(tǒng)SVM在訓(xùn)練過程中因約束過強導(dǎo)致過擬合的問題,提出了一種松弛的SVM分類方法,允許有少量樣本不受約束;同時為了更好地利用標(biāo)簽與圖像特征的一致性,在框架中增加了對標(biāo)簽特征和圖像特征的拉普拉斯約束,如式(57)的后2項.其標(biāo)注框架的總體目標(biāo)函數(shù)可表示為:

(57)


(58)
此外,還有文獻[57]對SVM的分類輸出通過標(biāo)簽關(guān)系矩陣重新加權(quán)作為標(biāo)注結(jié)果;文獻[58]通過為生成模型和SVM分類輸出設(shè)置不同的權(quán)重,用來作為標(biāo)注結(jié)果.
由于SVM專門用于解決二分類問題,因此大多基于SVM的語義標(biāo)注模型也繼承了SVM的缺點,在標(biāo)注詞(也意味著分類個數(shù))較多時,需要訓(xùn)練大量的分類器,因此模型在訓(xùn)練階段的速度往往比較低下.此外,由于SVM模型本身的構(gòu)建方式比較固定,對性能的提升主要集中在選取更加泛化和魯棒的特征之上,而對圖像標(biāo)注的一般性問題如標(biāo)簽不平衡、弱標(biāo)簽、特征的權(quán)值賦值以及對“圖像-圖像(I-I)”、“標(biāo)簽-標(biāo)簽(W-W)”之間的關(guān)系利用等,難以融合其他方法進行有效解決.
2.7 圖模型
圖模型的基本思想是通過圖來集成樣本間的相似關(guān)系,包括樣本間視覺特征之間的相似性、標(biāo)簽特征之間的相似性以及視覺特征和標(biāo)簽特征的對應(yīng)關(guān)系,然后再利用相關(guān)的圖論技術(shù)建立圖結(jié)構(gòu)中樣本以及各種特征的關(guān)聯(lián)模型,從而對標(biāo)簽進行預(yù)測.因此,大多基于圖的標(biāo)注模型的區(qū)別在于圖的構(gòu)建方式以及選擇的圖論技術(shù)存在差別.描述基于圖的圖像標(biāo)注模型的代表文獻有[59-72]等.
文獻[59]首先利用分割算法將圖像分塊,提取每個圖像塊的視覺特征.構(gòu)建圖的時候,將圖像的視覺特征和標(biāo)簽特征統(tǒng)一視為圖的節(jié)點,并將這些節(jié)點分為3層.其中,作為視覺特征的節(jié)點為1層,圖像節(jié)點作為1層,標(biāo)簽特征作為1層,視覺特征節(jié)點和標(biāo)簽特征節(jié)點作為圖像節(jié)點的屬性節(jié)點.將圖像節(jié)點與其對應(yīng)的視覺特征節(jié)點和標(biāo)簽特征節(jié)點通過邊連接起來即可構(gòu)成“圖像-屬性”的連接;再通過KNN方法對每個視覺特征的近鄰?fù)ㄟ^邊連接起來,構(gòu)成“近鄰連接”關(guān)系.據(jù)此,即可得到對應(yīng)的關(guān)系圖.對于待標(biāo)注圖像I節(jié)點來說,通過對建立的關(guān)系圖采用重啟隨機游走算法(random walking with restart, RWR),即可獲得圖中所有節(jié)點的穩(wěn)定概率,具有最高穩(wěn)定概率的標(biāo)簽特征節(jié)點,即可作為圖像I的標(biāo)注結(jié)果.文獻[67]只是將節(jié)點分為2層,并按照圖像和標(biāo)簽的對應(yīng)關(guān)系進行雙向連接,更加細致地定義了從標(biāo)簽到標(biāo)簽、標(biāo)簽到視覺特征、視覺特征到標(biāo)簽的3種轉(zhuǎn)移概率.
文獻[60,62,64]首先用基于圖像特征的圖學(xué)習(xí)方法得到每幅圖像的備選標(biāo)注,然后再采用基于標(biāo)簽特征的圖學(xué)習(xí)方式來優(yōu)化圖像和標(biāo)注之間的關(guān)聯(lián)關(guān)系,進而得到最終的標(biāo)注結(jié)果.其中,文獻[60,64]的新穎之處在于,為了利用圖像間的結(jié)構(gòu)化信息,提出了一種最近生成鏈(nearest spanning chain, NSC)的圖模型用來建立節(jié)點間的相似性關(guān)系.NSC的構(gòu)建原則為:1)N個節(jié)點通過N-1條邊構(gòu)成1條鏈,除了鏈的2個端點只有1條邊相連,其余節(jié)點均有2條邊相連;2)每個節(jié)點在構(gòu)建鏈的時候,選擇剩余節(jié)點中最近的節(jié)點作為相連節(jié)點.因此,若將圖像視作節(jié)點構(gòu)建NSC圖,則通過統(tǒng)計建立的多條NSC的統(tǒng)計信息,即可得到圖像i和圖像j間的統(tǒng)計性描述關(guān)系Ci,j:
(59)

(60)
其中Wi,j表示原始的圖像間相似關(guān)系,xi和xj分別表示圖像i和j的視覺特征.將W歸一化為S之后,即可通過迭代式(61)直到收斂從而得到每幅圖像的備選標(biāo)注:

(61)
其中,Y為原始標(biāo)簽矩陣,t表示迭代次數(shù).從標(biāo)簽關(guān)系的角度,為了使低頻且具有更高判別性能的標(biāo)簽有更大的權(quán)值,可設(shè)計標(biāo)簽之間的統(tǒng)計性描述關(guān)系K*為
(62)
K(x,y)為原始的標(biāo)簽相似性矩陣K中的元素,表示標(biāo)簽x與標(biāo)簽y的相似性;nx表示標(biāo)簽x在訓(xùn)練集圖像中出現(xiàn)的次數(shù);NT表示訓(xùn)練集總數(shù).類似地,再繼續(xù)采用式(61)中的迭代方法,預(yù)測最終的標(biāo)注結(jié)果,其中把式(61)中S用K*代入,Y用收斂后的圖像備選標(biāo)注代入即可.
文獻[61]采用類似譜聚類的方式分別為圖像和標(biāo)簽建立相似性關(guān)系圖,然后再將2種相似性關(guān)系整合到一個統(tǒng)一的標(biāo)注框架.以圖像本身作為圖的節(jié)點,圖像i和j的相似度Wi,j作為邊(Wi,j的定義見式(60)),根據(jù)相似的圖像標(biāo)簽也應(yīng)該類似的原則,即可定義二次能量函數(shù)E(f)為
(63)
其中f代表對圖像的實值預(yù)測函數(shù).同理,可定義標(biāo)簽的二次能量函數(shù)E′(g)為
(64)

(65)
通過對式(65)的解f進行排序,即可得到未標(biāo)注圖像的標(biāo)注.

(66)
其中:

(67)
據(jù)此,任意多實例包Bi都通過映射得到一個單實例特征描述:
[s(x1,Bi),s(x2,Bi),…,s(xm,Bi)],
(68)


(69)

文獻[65]針對每個標(biāo)簽類別分別構(gòu)建圖,包含該標(biāo)簽的圖像作為正節(jié)點,反之為負節(jié)點,其中正節(jié)點之間和負節(jié)點之間通過實線邊進行連接,表示其具有標(biāo)簽一致性,正負節(jié)點用虛線連接,表示具有標(biāo)簽的非一致性.對于某一類標(biāo)簽,其目標(biāo)就是構(gòu)建具有最大數(shù)量實線邊的圖,使其具有最大一致性.考慮到節(jié)點之間的相似性Wi,j,其目標(biāo)函數(shù)可被定義為

(70)
其中,S+和S-分別表示正節(jié)點和負節(jié)點.求解式(70)即可得到針對每一個標(biāo)簽的二分類分類器,之后再利用每個標(biāo)簽的分類器對未標(biāo)注圖像進行標(biāo)注.
文獻[66]針對每幅圖像設(shè)計了一種基于KNN的稀疏圖用來建立圖像與近鄰的潛在映射關(guān)系W,并假定該圖像的標(biāo)簽與其近鄰的標(biāo)簽具有相同的映射關(guān)系,然后通過這種映射關(guān)系來建立預(yù)測標(biāo)簽與真實標(biāo)簽的損失函數(shù),從而對待標(biāo)注圖像進行標(biāo)注.其中,W可通過式(71)進行求解:
(71)
其中,xi表示圖像i的視覺特征向量,Bi表示由圖像i的近鄰所構(gòu)成的特征矩陣,wi表示映射關(guān)系.由于標(biāo)簽具有相同的映射關(guān)系,因此有:
(72)

此外,還有文獻[68,70-71]同時利用了圖像的視覺信息和標(biāo)簽信息,以及文獻[72]同時利用了圖像搜索引擎的返回結(jié)果和候選標(biāo)注詞在Web頁面中的重要程度進行特征相似圖的構(gòu)建.文獻[68]更進一步地在目標(biāo)框架中嵌入了潛語義空間中的信息.文獻[69]利用圖和KNN相結(jié)合的方法對圖像特征進行降維,使相關(guān)聯(lián)的圖像特征距離更近,而不相關(guān)的圖像特征距離更遠.
由于多數(shù)基于圖的標(biāo)注模型是通過與其他方法相結(jié)合的方式來融合各自的優(yōu)點,因此對于解決一般性的圖像標(biāo)注問題(如特征的不平衡、特征選取、“圖像-圖像(I-I)”、“標(biāo)簽-標(biāo)簽(W-W)”之間的關(guān)系利用等)更加取決于與其結(jié)合的方法的特性,并且構(gòu)建關(guān)系圖的方式非常多樣,使得基于圖的標(biāo)注模型具有相當(dāng)?shù)撵`活性.
2.8 典型相關(guān)分析模型
典型相關(guān)分析(canonical correlation analysis, CCA)模型與KCCA(kernel CCA)模型的本質(zhì)是用來尋找2組特征變量的最大相關(guān)關(guān)系,最早被用于基于語義的圖像檢索領(lǐng)域[73-74],其基本思想為:假定圖像的視覺特征與對應(yīng)的標(biāo)簽特征分別為異構(gòu)的2種特征,則CCA模型通過2組對應(yīng)的基可將2種異構(gòu)特征分別映射到一個具有最大相關(guān)性的可對比的隱藏語義空間,進而再通過適當(dāng)?shù)木嚯x運算或比較模型,獲得與圖像最相關(guān)的標(biāo)簽.由于KCCA模型是在CCA模型基礎(chǔ)上,通過核函數(shù)的方式增強了模型的非線性特征,其本質(zhì)與CCA并無區(qū)別,因此,本文統(tǒng)一將CCA模型和KCCA模型都稱之為CCA模型.基于CCA的圖像標(biāo)注模型代表有文獻[75-81]等.
由于基于CCA的圖像標(biāo)注模型的基本思想類似,區(qū)別大多集中在特征的選擇、距離運算以及比較模型方面.因此,本文先以文獻[79]為例,介紹CCA模型方法,在此基礎(chǔ)上進一步描述各模型的區(qū)別.

(73)

(74)
其中α和β分別為新的映射方向,Kv和Kt分別表示對訓(xùn)練集N幅圖片經(jīng)由視覺特征和標(biāo)簽特征各自的核函數(shù)映射過后的內(nèi)積矩陣.經(jīng)正則化[82]之后,可轉(zhuǎn)化為標(biāo)準(zhǔn)的特征向量問題:
(Kv+kI)-1Kt(Kt+kI)-1Kvα=λ2α,
(75)
最大的D個特征值分別對應(yīng)的特征向量組成的矩陣A=(α(1),α(2),…,α(D))和B=(β(1),β(2),…,β(D))即可作為圖像特征與標(biāo)簽特征的基矩陣,映射2種特征到具有最大相關(guān)性的隱藏空間.
文獻[75]采用SIFT特征[17]構(gòu)成的視覺詞袋(BOW)作為圖像的視覺特征,對圖像的標(biāo)簽采用“詞頻-逆文檔頻率(term frequency inverse document frequency, TFIDF)”P{TFIDF}作為特征:
P{TFIDF}(di,wj)=
|{wj∈di}|lg(l|di∈D:wj∈di|-1)|,
(76)
利用TFIDF作為標(biāo)簽特征是一種擴大在文檔中經(jīng)常出現(xiàn)但在整個集合中較少出現(xiàn)的單詞影響的方法.其中di代表視作為文檔的圖像,wj代表標(biāo)簽,l為訓(xùn)練集中總的圖像數(shù)量.
文獻[76]中提出的PLSA+CCA模型,首先利用CCA模型將圖像視覺特征與標(biāo)簽特征映射至隱藏的語義空間,然后再通過PLSA模型[18]中的方法,建立起聯(lián)合2種特征之間的聯(lián)合概率密度.
文獻[79]將Gist、顏色直方圖以及由SIFT特征構(gòu)成的視覺詞袋作為圖像的視覺特征分別來表征圖像的全局和局部特征.針對每種視覺特征的距離采用χ2核函數(shù)增強其非線性關(guān)系:

(77)
其中,A為訓(xùn)練集中所有特征的χ2距離均值,d為某種視覺特征f的維度,h表示其視覺特征的表示函數(shù).從而,針對2幅圖像總的視覺特征距離,其核函數(shù)可定義為
(78)

(79)
最后通過KCCA方法建立隱藏空間.對于待標(biāo)注圖像,則可通過圖像在隱藏空間的視覺特征與標(biāo)簽特征的內(nèi)積來尋找近鄰標(biāo)簽并進行標(biāo)簽擴散.
文獻[77]在文獻[79]的視覺特征基礎(chǔ)上,將訓(xùn)練圖像中每幅圖像的標(biāo)簽順序進行建模,從而使被標(biāo)注的圖像能夠更符合人類的感官.其基本依據(jù)是,人們在對圖像進行標(biāo)注時往往會先對圖像中最顯著的目標(biāo)進行標(biāo)注,從而使得每幅圖像的標(biāo)注詞列表中帶有目標(biāo)的重要性信息,也即越顯著的物體其標(biāo)注詞在列表中越靠前.標(biāo)簽的相對順序與絕對順序分別定義為
(80)
(81)
其中,wi,k表示第i個標(biāo)簽在第k幅圖像中出現(xiàn)的次序,N為訓(xùn)練集圖像總數(shù),J=min(ai,H),H為選定的閾值,為了防止wi,k出現(xiàn)在超長列表中排序過于靠后的情況.ai代表第i個標(biāo)簽在所有圖像中的平均排序.其對于核函數(shù)的建立與文獻[79]保持一致.
文獻[78]通過K-means算法對所有圖像的標(biāo)簽特征先進行聚類,并假定聚類可得到c個具有語義相似性的簇.針對所有的n幅訓(xùn)練圖像,可得到C∈Rn×c,其中Ci,j∈{1,0}表示第i幅圖像是否屬于第j個聚類簇,每幅圖像也就對應(yīng)有了一個c維向量作為其語義特征.然后,類似于CCA,建立“視覺特征-標(biāo)簽特征”、“視覺特征-語義特征”、“標(biāo)簽特征-語義特征”三者之間的最大相關(guān)關(guān)系:
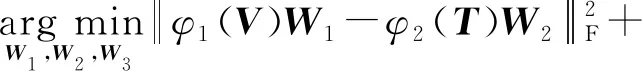
(82)
其中φ1(V),φ2(T),φ3(C)分別代表圖像的視覺特征、標(biāo)簽特征以及語義特征.
文獻[80-81]都采用從預(yù)訓(xùn)練的CNN模型中提取的特征作為視覺特征,其中文獻[80]選用了詞向量(word2vec[83])作為標(biāo)簽特征.
CCA,KCCA模型的構(gòu)建模式比較固定,最關(guān)鍵的步驟在于尋找到映射2種異構(gòu)特征到具有最大相關(guān)性的潛語義空間中的基.對于圖像標(biāo)注的一般性問題來說,由于與其他類型方法結(jié)合的靈活性也較差,使得可供解決這些問題的方法不夠充分,從而也導(dǎo)致相關(guān)的研究工作不夠充足.此外,由于解決CCA,KCCA模型的核心問題最終會演變?yōu)閷ふ揖仃嚨奶卣髦岛吞卣飨蛄浚虼嗽诿鎸Υ笠?guī)模數(shù)據(jù)集時,同樣也會遭遇到運算效率低下的問題.
2.9 深度學(xué)習(xí)模型
近年來,由于硬件運算設(shè)備如GPU,NPU(neural-network process unit)等運算性能的大幅提升,以深度學(xué)習(xí)為基礎(chǔ)的模型克服了早期存在的運算瓶頸,并且在計算機視覺、文本處理、電子商務(wù)[84]等各應(yīng)用領(lǐng)域,以高泛化性和優(yōu)異的性能得到了廣泛的應(yīng)用和發(fā)展.深度學(xué)習(xí)模型通過若干層的卷積神經(jīng)網(wǎng)絡(luò)(CNN)、非線性激活函數(shù)和池化層相連接,直接建立從圖像原始像素到圖像標(biāo)簽的端到端關(guān)系映射.深度學(xué)習(xí)模型具有2個重要優(yōu)勢:1)與傳統(tǒng)方法中手工設(shè)計的圖像特征相比,通過預(yù)訓(xùn)練的深度學(xué)習(xí)模型提取出的圖像特征具有更高的泛化性以及抽象性[85-88];2)通過基于深度學(xué)習(xí)的文本處理模型提取出的標(biāo)簽特征[83]具有高層的語義相關(guān)關(guān)系.
深度學(xué)習(xí)模型近年來成為計算機視覺領(lǐng)域研究熱點,源于以AlexNet(Alex net)模型[89]、VGG(visual geometry group)模型[90]、GoogLeNet(Google net)模型[91]、ResNet(residual network)模型[92]等著名深度學(xué)習(xí)模型在大規(guī)模圖像分類競賽ILSVRC(image-net large scale visual recognition challenge)中的大放異彩.ILSVRC競賽任務(wù)為單一類別圖像分類問題,而圖像標(biāo)注從分類角度可歸類于圖像的多分類問題,因此這些深度學(xué)習(xí)模型的模型結(jié)構(gòu)大多適用于圖像標(biāo)注任務(wù),區(qū)別僅在于對每一類別的預(yù)測得分選取方法有所不同.此外,各模型均基于前饋神經(jīng)網(wǎng)絡(luò)[93],差異大多集中在模型結(jié)構(gòu)、激活函數(shù)、超參數(shù)調(diào)節(jié)等方面.因此,本文僅以AlexNet模型為例介紹深度模型結(jié)構(gòu),并在此基礎(chǔ)上進一步描述各模型的區(qū)別.
AlexNet模型[89]的輸入為RGB圖像,包括5個卷積層、3個全連接層,最后通過Softmax函數(shù)輸出預(yù)測,并通過預(yù)測結(jié)果與標(biāo)簽建立的損失函數(shù)對模型進行訓(xùn)練.其中,在第1,2,5卷積層之后使用了最大池化操作,避免了傳統(tǒng)CNN模型使用平均池化所帶來的模糊化效果.模型采用了ReLU作為每層卷積之后的非線性激活函數(shù),從而減緩傳統(tǒng)CNN模型采取sigmoid函數(shù)所面對網(wǎng)絡(luò)較深時的梯度彌散問題,ReLU函數(shù)定義為
f(x)=max(0,x).
(83)
同時,提出了局部響應(yīng)歸一化(local response normalization, LRN)層,用來抑制反饋較小的神經(jīng)元,從而使相應(yīng)比較大的神經(jīng)元值變得相對更大,從而增加模型泛化能力.對在ReLU層第i個卷積核(x,y)位置的LRN值定義為
(84)

VGG模型[90]相對AlexNet模型采用了更小的卷積核,也即3×3和1×1卷積核,而AlexNet模型中包括11×11以及5×5卷積核.采用小卷積核的原因是經(jīng)試驗驗證,在卷積步長相同的情況下,不同卷積核大小對網(wǎng)絡(luò)參數(shù)量差別影響不大,但大的卷積核會導(dǎo)致計算量增大,而大的卷積核所覆蓋的感受野可通過小卷積核的疊加實現(xiàn).同時,模型將卷積層增加到了19層,另有一個分支模型為16層,其中分支的VGG16模型中的若干層采用了1×1卷積核做線性映射.
GoogLeNet[91]采用了一種inception模型作為構(gòu)建深度模型的基本模塊,通過多個inception的模塊串聯(lián)形成最終的深度網(wǎng)絡(luò)結(jié)構(gòu).inception模塊由4個分支組成,每個分支都包含一個1×1且步長為1的卷積核,第2,3個分支分別在1×1卷積核后串聯(lián)3×3以及5×5卷積核來增加感受野,第4個分支在1×1卷積核之前采用3×3最大池化層獲取局部關(guān)鍵信息;最后,將4個分支的輸出在維度上進行串聯(lián),作為下一個inception模塊的輸入.其中,采用4分支的并行結(jié)構(gòu)依據(jù)為:首先在直觀感覺上對多個尺度同時進行卷積,可提取到不同尺度的特征,使得最后分類判斷更加準(zhǔn)確;其次,根據(jù)Hebbian原則,4個分支分別代表4種具有高度聚類相關(guān)性的神經(jīng)元,由于訓(xùn)練收斂的最終目的就是要提取出獨立的特征,所以預(yù)先把相關(guān)性強的特征匯聚,就能起到加速收斂的作用.而在每個分支采用的1×1卷積核,其采用的依據(jù)為在相同尺寸的感受野中疊加更多的卷積,可提取到更豐富的特征[94],同時也降低了特征的維度,減少了計算復(fù)雜度.此外,由于每個卷積核后串聯(lián)ReLU函數(shù),因此還可增強模型的非線性關(guān)系.
ResNet模型[92]針對深度網(wǎng)絡(luò)模型的層數(shù)加深達到一定數(shù)量之后模型準(zhǔn)確率不升反降的問題,提出采用恒等映射(identity mapping)的方式使得網(wǎng)絡(luò)加深的同時不會導(dǎo)致誤差增加,也即通過“shortcut connections(捷徑鏈接)”之間將輸入x傳到輸出作為結(jié)果.假設(shè)某一段網(wǎng)絡(luò)的輸入為x,期望輸出為H(x)=F(x)+x,則當(dāng)網(wǎng)絡(luò)已經(jīng)學(xué)習(xí)到較飽和準(zhǔn)確率時,F(xiàn)(x)=0,從而相當(dāng)于H(x)=x,也即此時學(xué)習(xí)的目標(biāo)為恒等映射.F(x)H(x)-x即代表網(wǎng)絡(luò)中的殘差.ResNet通過引入殘差的結(jié)構(gòu),打破了傳統(tǒng)神經(jīng)網(wǎng)絡(luò)第n層的輸出只能作為第n+1層輸入的慣例,使得某一層的輸出可以直接跨過幾層作為后面某一層的輸入,在某種程度上解決了網(wǎng)絡(luò)模型疊加多層之后精度不升反降的問題.
在深度學(xué)習(xí)的基礎(chǔ)上,文獻[95]針對社交網(wǎng)絡(luò)圖像的標(biāo)注問題,有效結(jié)合了圖像領(lǐng)域的元數(shù)據(jù)信息作為原始圖像信息的補充.模型將圖像的標(biāo)簽、圖像上傳時所屬的集合以及圖像的分組信息作為圖像的元數(shù)據(jù),然后利用這些元數(shù)據(jù)的相似性可獲取某一圖像的近鄰集合.對圖像及其近鄰利用深度模型提取特征之后,采用最大池化的方式對所有特征進行融合,并將融合后的特征作為圖像特征,最后訓(xùn)練模型.文獻[96]類似于文獻[95],也是利用了圖像的拍攝時間和位置作為上下文信息.不同的是,文獻[96]針對上下文信息建立了一個和原圖像并行的網(wǎng)絡(luò),合并由原圖像作為輸入的深度網(wǎng)絡(luò)輸出結(jié)果和上下文信息作為輸入的深度網(wǎng)絡(luò)輸出結(jié)果,作為總的網(wǎng)絡(luò)結(jié)構(gòu)的預(yù)測結(jié)果,從而訓(xùn)練深度學(xué)習(xí)模型,進而完成標(biāo)注任務(wù).
文獻[97]將不同類型的視覺特征看作不同的視圖(view),首先為不同的view建立深度模型作為encoder,并以此encoder輸出的分布作為圖像的標(biāo)簽特征,然后再利用圖像本身結(jié)合標(biāo)簽特征作為輸入,訓(xùn)練另外一個深度模型,從而得到最終的圖像預(yù)測結(jié)果.
文獻[98]為了建模提取標(biāo)簽之間的相關(guān)關(guān)系,將RNN(recurrent neural networks)模型與CNN模型相結(jié)合形成了一個統(tǒng)一的框架.其中,CNN用來提取圖像的視覺信息并作為RNN模型在每一個節(jié)點的輸入,從而使得RNN模型可提取到“圖像-標(biāo)簽”、“標(biāo)簽-標(biāo)簽”之間的相互關(guān)系.文獻[99]同樣是為了利用標(biāo)簽之間的相關(guān)關(guān)系,但不同于文獻[98],文獻[99]將原始圖像和標(biāo)簽特征統(tǒng)一到了一個深度學(xué)習(xí)框架中,讓原始圖像和標(biāo)簽特征統(tǒng)一作為模型的輸入.
文獻[100]首先利用分塊算法將圖像中包含有目標(biāo)的區(qū)域劃分為很多個候選塊,由于多個候選塊會對應(yīng)至少一個標(biāo)簽,因此將這種對應(yīng)關(guān)系轉(zhuǎn)化為多實例學(xué)習(xí)問題,最后再利用多實例學(xué)習(xí)的模型框架來完成圖像標(biāo)注.文獻[101]類似于文獻[100],也是先將圖像分解成包含有目標(biāo)區(qū)域的多個候選塊,多個候選塊分別進入深度網(wǎng)絡(luò)會形成多個預(yù)測向量,模型再將多個預(yù)測向量做最大池化操作,形成最終的多分類預(yù)測結(jié)果.
文獻[102-103]分別在VGG網(wǎng)絡(luò)[90]和GAN網(wǎng)絡(luò)[104]的基礎(chǔ)上引入了一種行列式點過程(DPP[105]).為了去除候選標(biāo)簽集合中的同義詞等冗余標(biāo)簽,將最終的標(biāo)注詞的選定視為一種標(biāo)簽子集選擇過程,在所有可能的標(biāo)記中檢索K個大小的標(biāo)記子集作為最終的圖像標(biāo)注.文獻[106]針對網(wǎng)絡(luò)社交圖像進行語義標(biāo)注,利用具有相似視覺特征、相似主題、相似地標(biāo)信息等元數(shù)據(jù)的圖像構(gòu)建近鄰關(guān)系圖,并引入到ResNet[92]網(wǎng)絡(luò),進一步提升視覺特征不明顯的圖像標(biāo)注精度.文獻[107]在VGG的訓(xùn)練過程中,加入了視覺特征一致性、標(biāo)簽關(guān)系一致性以及用戶誤標(biāo)注的稀疏性作為每一批訓(xùn)練樣本的限制,從而強化“圖像-圖像(I-I)”、“標(biāo)簽-標(biāo)簽(W-W)”關(guān)系.
由于傳統(tǒng)的深度學(xué)習(xí)模型大多為針對特定領(lǐng)域大型數(shù)據(jù)集的分類任務(wù)而設(shè)計,在面對新領(lǐng)域視覺任務(wù)、小數(shù)據(jù)集或新數(shù)據(jù)集標(biāo)簽類別較少等特定情況下,重新設(shè)計或訓(xùn)練網(wǎng)絡(luò)會造成網(wǎng)絡(luò)過擬合、增加運算負擔(dān)等一系列問題.因此,有學(xué)者提出利用深度遷移學(xué)習(xí)的思想將某個領(lǐng)域或任務(wù)上學(xué)習(xí)到的知識或模式(如樣本特征、網(wǎng)絡(luò)的部分層次結(jié)構(gòu)等)應(yīng)用到不同領(lǐng)域或問題中,如文獻[86,108-111]等.
文獻[108]設(shè)計了一系列有2個不同但相關(guān)領(lǐng)域的分類任務(wù)A和B,通過對網(wǎng)絡(luò)結(jié)構(gòu)不同層數(shù)遷移、微調(diào)、預(yù)訓(xùn)練參數(shù)等實驗,表明了神經(jīng)網(wǎng)絡(luò)的前幾層通常表示圖像的通用特征.此外該工作與文獻[86]的實驗結(jié)果都可反映,經(jīng)大型數(shù)據(jù)集(如ImageNet)訓(xùn)練的網(wǎng)絡(luò)結(jié)構(gòu),其網(wǎng)絡(luò)參數(shù)可用來初始化其他未經(jīng)訓(xùn)練的同構(gòu)網(wǎng)絡(luò).這種優(yōu)勢使模型在面對相似領(lǐng)域但數(shù)據(jù)集不同的視覺任務(wù)(如圖像標(biāo)注)時,僅通過新的數(shù)據(jù)集對網(wǎng)絡(luò)某些層進行微調(diào)(fine-tune)即可達到較好的效果,從而避免了重新訓(xùn)練的代價,是小數(shù)據(jù)集、標(biāo)簽數(shù)量少等問題的有效解決方案.例如文獻[109]即采用了同AlexNet模型相同的網(wǎng)絡(luò)結(jié)構(gòu),針對圖像的標(biāo)注問題,將最后的Softmax層輸出進行排序,排序結(jié)果最大的topN個向量元素對應(yīng)的標(biāo)簽作為圖像的標(biāo)注結(jié)果.
此外,實驗還表明由預(yù)訓(xùn)練模型的全連接層提取出的向量,可作為其他視覺任務(wù)的中級特征,并且具有良好的泛化性能.如本文歸類于近鄰模型的SEM模型[41]和weight-KNN模型[42],以及歸類于CCA模型的文獻[80-81]都利用了從深度學(xué)習(xí)的預(yù)訓(xùn)練模型中提取圖像特征的方法.
文獻[110-111]更進一步地針對數(shù)據(jù)集的領(lǐng)域不同問題,利用處于2個不同領(lǐng)域之間的若干領(lǐng)域,將知識傳遞式地完成遷移.
基于深度學(xué)習(xí)的圖像標(biāo)注模型大多聚焦于對網(wǎng)絡(luò)結(jié)構(gòu)的變換以及利用深度模型提取“標(biāo)簽-標(biāo)簽(W-W)”之間相關(guān)關(guān)系.由于深度學(xué)習(xí)中的深層網(wǎng)絡(luò)結(jié)構(gòu)較之其他模型建立的相關(guān)關(guān)系具有更加復(fù)雜、非線性的特性,因此具有良好的標(biāo)注性能.此外,從深度學(xué)習(xí)網(wǎng)絡(luò)結(jié)構(gòu)中提取出的圖像特征也具有較強的泛化性能,因此近年來得到了廣泛的應(yīng)用和發(fā)展.但基于深度學(xué)習(xí)的模型也存在4方面不足:1)缺乏可解釋性,即對于模型結(jié)構(gòu)的調(diào)參以及如何使模型收斂缺乏理論指導(dǎo)依據(jù),也是基于此原因,近年來的深度學(xué)習(xí)模型大部分集中于對模型結(jié)構(gòu)的改進;2)傳統(tǒng)深度模型需要較大的訓(xùn)練集,對于某些樣本難以獲取的圖像領(lǐng)域任務(wù)來說代價及開銷過大;3)模型過度依賴于硬件設(shè)備的性能如GPU,NPU等;4)現(xiàn)有的深度學(xué)習(xí)模型始終無法跳出人類設(shè)計的框架,無法自動化地生成具有高性能、高泛化性能的網(wǎng)絡(luò)結(jié)構(gòu).
3 模型特點及對比
本文選取了一些有代表性的圖像標(biāo)注模型,針對其在公用數(shù)據(jù)集上的性能指標(biāo)進行對比(如表1和表2所示,其中相關(guān)指標(biāo)P(precision),R(recall),F(xiàn)1(balanced score),N+在本文4.2節(jié)中有詳細說明),并將各種圖像標(biāo)注模型所采用的主要方法類型歸為9種類型,分別為相關(guān)模型、隱Markov模型、主題模型、矩陣分解模型、近鄰模型、基于支持向量機的模型、圖模型、典型相關(guān)分析模型以及深度學(xué)習(xí)模型,通過表3概要列出了每種方法類型所對應(yīng)的優(yōu)缺點,其中,“相關(guān)文獻(年份)”列表示本文所引用的各種類型相關(guān)文獻公開發(fā)表的起始年份和該類模型活躍的平均年份.

Table 1 Comparison of Traditional Models(1)

Continued (Table 1)

Table 2 Comparison of Traditional Models(2)
通過分析表1中的數(shù)據(jù)以及對比表3中各種模型的優(yōu)缺點可知,早期的圖像標(biāo)注模型如相關(guān)模型、隱Markov模型等,有較強的可解釋性,但這類模型比較依賴于其他算法,圖像的標(biāo)注性能和泛化能力往往一般;近些年取得廣泛研究成果的矩陣分解模型、近鄰模型、CCA(KCCA)模型等,其泛化性能有所提高,但可解釋性有所降低;深度學(xué)習(xí)模型可以處理超大規(guī)模的數(shù)據(jù)集,性能相比其他模型也更高,但可解釋性最差;在如何與其他的計算機方法相結(jié)合來解決標(biāo)注的一般性問題,以及對“I-I”,“W-W”關(guān)系的利用程度等方面,每一類模型各有不同;此外,由于圖像標(biāo)注模型存在的一些固有特征(如使用的數(shù)據(jù)集過大、優(yōu)化求解算法復(fù)雜等),幾乎所有的模型運算速度都有待提升.
從各類模型出現(xiàn)的相關(guān)年份可反映出,標(biāo)注模型的性能隨著時間往越來越高的方向演進,所能處理的數(shù)據(jù)集也由早期的小型逐漸過渡到大型與超大型,深度學(xué)習(xí)模型以其優(yōu)異的標(biāo)注性能成為近年來標(biāo)注模型的主流;同時,近鄰模型以及矩陣分解模型等也有相當(dāng)?shù)陌l(fā)展.不難理解,造成這種趨勢的原因是隨著時代的發(fā)展,硬件處理、運算能力不斷提升,以及大型超大型數(shù)據(jù)集的出現(xiàn)對深度學(xué)習(xí)等依賴于運算能力和數(shù)據(jù)集的模型有顯著的促進作用,而其他類型標(biāo)注模型根據(jù)其自身特點也可被運用于一些僅需要處理中小型數(shù)據(jù)集、運算需求較小的應(yīng)用場景.

Table 3 Comparison of Advantages and Disadvantages of Different Type Models
4 圖像標(biāo)注數(shù)據(jù)集與評測指標(biāo)
圖像數(shù)據(jù)集常用來對各種任務(wù)模型進行訓(xùn)練,并可以結(jié)合各種評測指標(biāo)對不同的模型進行對比.由于任務(wù)的不同,圖像數(shù)據(jù)集的具體針對情況可能會存在偏差,但多數(shù)都可用于圖像標(biāo)注任務(wù).因此,本文對已有標(biāo)注工作中常用的部分圖像數(shù)據(jù)集以及各種標(biāo)注模型評測指標(biāo)進行了歸納總結(jié).
4.1 圖像標(biāo)注數(shù)據(jù)集
1) Corel5K.Corel5K數(shù)據(jù)集包含科雷爾(Corel)公司收集整理的5 000幅圖片,因此命名為Corel5K.自從第1次被提出用于圖像目標(biāo)識別[5]實驗后,已經(jīng)成為圖像實驗的標(biāo)準(zhǔn)數(shù)據(jù)集,被廣泛應(yīng)用于標(biāo)注算法性能的比較,也常用于圖像的分類、檢索等任務(wù).圖像集涵蓋50個語義主題,如公共汽車、恐龍、海灘等,每個主題包含100張大小相等的圖像,可以轉(zhuǎn)換成多種格式.5 000幅圖片常被分為3個部分,其中訓(xùn)練集包含4 000幅,驗證集和測試集各500幅.集合共包含260個標(biāo)簽,每幅圖像包含1~5個標(biāo)簽.
2) ESP-Game.ESP-Game數(shù)據(jù)集[112]源自一款雙人標(biāo)注游戲,游戲的內(nèi)容是讓2個人在不進行交流的情況下對同一圖像進行標(biāo)注,然后選取相同的詞作為圖像的標(biāo)注.常用作圖像標(biāo)注的數(shù)據(jù)集共包含20 770幅圖像和268個標(biāo)簽,其中訓(xùn)練集包含18 689幅圖像,測試集包含2 081幅圖像,每幅圖像包含3~5個標(biāo)簽.
3) IAPR TC-12.IAPR TC-12數(shù)據(jù)集[113]包含19 627幅從世界各地拍攝的自然圖像,其中包括各種語義場景,如體育運動、人物、動物、城市、海灘等.訓(xùn)練集圖像為17 665幅,測試集圖像為1 962幅,并包含291個語義標(biāo)簽.
4) NUS-WIDE.NUS-WIDE數(shù)據(jù)集[114]是由新加坡國立大學(xué)NUS實驗室收集整理的網(wǎng)絡(luò)圖像數(shù)據(jù)集,圖像內(nèi)容側(cè)重于人們的日常生活和事件.數(shù)據(jù)集被劃分為3個集合:第1個集合包含81個從Flickr網(wǎng)站中獲取到的基本標(biāo)簽,包括通用標(biāo)簽(如動物、植物)和特殊標(biāo)簽(如狗、花),而且標(biāo)簽大部分是由高校學(xué)生提供,因此標(biāo)簽噪聲相對其他從網(wǎng)絡(luò)上搜集的圖像要少;第2個和第3個集合中的圖像也來自于Flickr網(wǎng)站,分別包含1 000和5 000個原始標(biāo)簽.圖像集共包含269 648幅圖像,訓(xùn)練集和測試集根據(jù)任務(wù)需求可自行設(shè)置.
5) MS-COCO.MS-COCO數(shù)據(jù)集[115]是微軟團隊發(fā)布的一個可以用于圖像識別、分割和標(biāo)注的多任務(wù)用途數(shù)據(jù)集,其內(nèi)容主要從復(fù)雜的日常場景中截取.數(shù)據(jù)集共包含91個類別,平均每張圖片包含3.5個類別和7.7個實例目標(biāo),僅有不到20%的圖片只包含1個類別,僅有10%的圖片包含1個實例目標(biāo),也即每一類所包含的圖像較多,有利于獲得更多的每類中位于某種特定場景的能力.MS-COCO數(shù)據(jù)集分2部分發(fā)布,前部分發(fā)布于2014年,后部分發(fā)布于2015年,其中2014年的版本中包含82 783訓(xùn)練集圖像、40 504驗證集圖像和40 775測試集圖像,還有27萬的被分割出來的人物目標(biāo)和88.6萬的實物目標(biāo);2015年的版本其訓(xùn)練集、驗證集和測試集圖像數(shù)量分別為165 482,81 208,81 434.
6) PASCAL VOC.PASCAL VOC數(shù)據(jù)集是由每年一度的PASCAL VOC挑戰(zhàn)賽所發(fā)布的數(shù)據(jù)集,其主要任務(wù)包括圖像分類、目標(biāo)識別、目標(biāo)分割、人物定位以及行為識別等.以PASCAL VOC 2012為例,數(shù)據(jù)集總共分4個大類20個小類.數(shù)據(jù)集共包含23 080幅圖像,其中訓(xùn)練集圖像數(shù)量為5 717幅,驗證集圖像數(shù)量為5 823幅,測試集圖像數(shù)量為11 540幅,共包含54 900個目標(biāo).
7) ImageNet.ImageNet圖像數(shù)據(jù)集始于2009年文獻[116]中的計算機視覺系統(tǒng)識別項目工作,而后從2010年開始每年基于ImageNet數(shù)據(jù)集會舉辦大規(guī)模視覺識別挑戰(zhàn)賽,到2017年后截止.比賽項目包括:圖像分類、目標(biāo)定位、目標(biāo)檢測、視頻目標(biāo)檢測、場景分類、場景解析等.ImageNet數(shù)據(jù)集共包含14 197 122幅圖像,常用于競賽ISLVRC使用的公開數(shù)據(jù)集是ImageNet的子集,以2012年ILSVRC分類數(shù)據(jù)集為例,其訓(xùn)練集為1 281 167張圖像,驗證集為50 000張圖像,測試集為100 000張圖像在每次競賽中單獨發(fā)布,共包含1 000個不同的類別.
此外,還有其他如MIRFlickr,F(xiàn)lickr25k,F(xiàn)lickr30k等從Flickr網(wǎng)站獲取的帶有描述性標(biāo)題的圖像集合,也常被用于圖像的標(biāo)注任務(wù).
4.2 常用評測指標(biāo)
圖像標(biāo)注算法的評測指標(biāo)常用來檢驗各種模型的優(yōu)劣,其中包括精確度P、召回率R、F1、N+、平均精度(average precision,AP)、平均準(zhǔn)確率(mean average precision,MAP)等,下文將對這些指標(biāo)進行簡單介紹.
精確度用來表明預(yù)測為正的樣本中有多少是真正的正樣本,它表示的結(jié)果為:某一標(biāo)簽預(yù)測正確的圖像數(shù)量對該標(biāo)簽的總預(yù)測圖像數(shù)量的占比.P值可表示為:
(85)
召回率用來表明樣本中的正例有多少被正確預(yù)測,它表示的結(jié)果為:某一標(biāo)簽預(yù)測正確的圖像數(shù)量對該標(biāo)簽的總的真實圖像數(shù)量的占比.R值可表示為:
(86)
其中,Correct(wk)表示針對第k個標(biāo)簽預(yù)測正確的圖像數(shù)量,Predicted(wk)表示針對第k個標(biāo)簽預(yù)測圖像的總數(shù)量,GroundTruth(wk)表示所有標(biāo)注有第k個標(biāo)簽的總的圖像數(shù)量.
在判斷模型優(yōu)劣的時候往往希望P,R值都是越高越好,但這兩者之間有時會存在矛盾.F1可以綜合兩者之間的關(guān)系,也即對兩者進行調(diào)和:
(87)
F1綜合了P,R兩者的結(jié)果,當(dāng)F1的值較高時說明模型方法比較理想.
N+值表示至少被正確標(biāo)注過一次的標(biāo)簽數(shù)量.對于具有標(biāo)簽不平衡問題的測試數(shù)據(jù),該指標(biāo)具有很大參考意義.
P,R,F(xiàn)1,N+即為圖像標(biāo)注最常用的評測指標(biāo).此外,還有相對復(fù)雜的指標(biāo)如AP和MAP,也是綜合考慮了P,R的值.AP的計算方法相對復(fù)雜,該指標(biāo)表示針對某一標(biāo)簽,在一組設(shè)定的R閾值之下,每個R值對應(yīng)最大的P值的平均值.MAP指標(biāo)表示對所有標(biāo)簽AP求均值.
5 總 結(jié)
本文通過對近年來公開發(fā)表的圖像標(biāo)注文獻的研究,總結(jié)了圖像標(biāo)注模型的一般性框架,并通過該框架結(jié)合各種具體工作,分析出在圖像標(biāo)注問題中需要解決的一般性問題.此外,在對各種標(biāo)注模型的歸類方面,本文通過其主要使用的方法類型對各種模型進行了歸類.首先介紹了每種方法類型的基本原理,然后具體分析了各種圖像標(biāo)注模型之間的差異,最后簡單總結(jié)了每一類方法類型的標(biāo)注模型,并結(jié)合了圖像標(biāo)注模型常用的一些數(shù)據(jù)集、評測指標(biāo)以及比較著名的標(biāo)注模型的性能和實驗數(shù)據(jù),對各種方法類型的標(biāo)注模型做了優(yōu)缺點分析.
總而言之,圖像標(biāo)注技術(shù)仍然是一個廣泛、開放且具有挑戰(zhàn)性的研究領(lǐng)域,其最主要的目標(biāo)仍然是縮短圖像的高級語義信息同低層視覺特征之間的語義鴻溝問題.本文結(jié)合標(biāo)注領(lǐng)域的一般性問題以及各種方法類型的標(biāo)注模型,有針對性地提出5個改善圖像標(biāo)注性能的方向:
1) 由于近年來社交網(wǎng)站的快速發(fā)展,用于圖像標(biāo)注領(lǐng)域的數(shù)據(jù)集往往是由不同的用戶進行標(biāo)注,標(biāo)簽里面夾雜著大量不相關(guān)或者錯誤的標(biāo)注詞匯.這些主觀性的問題會導(dǎo)致生成的數(shù)據(jù)集產(chǎn)生標(biāo)簽不平衡、弱標(biāo)簽等問題.因此,如何采取自動化的方法剔除不相關(guān)標(biāo)簽仍然是標(biāo)注模型亟待解決的問題之一.
2) 一些專業(yè)或特殊領(lǐng)域的圖像集(如醫(yī)學(xué)圖像數(shù)據(jù)集、商品圖像數(shù)據(jù)集等)擁有很多復(fù)雜特性,如:①圖像中需要標(biāo)注的目標(biāo)之間具有環(huán)繞、遮擋情況;②關(guān)注的目標(biāo)是細微的物品,在圖像占比太小,不夠顯著;③關(guān)注的目標(biāo)與圖像中其他目標(biāo)非常相似.因此,在特定的應(yīng)用場景下還需要解決這類特定問題.
3) 圖像的標(biāo)注模型性能和速度往往會受到所采用的圖像視覺特征的干擾,因此,如何使得選取的特征具有強大的泛化性能且低維是需要改進的方向.
4) 充分利用“圖像-圖像”、“標(biāo)簽-標(biāo)簽”之間的關(guān)聯(lián)信息有助于提升標(biāo)注的性能,而高層的語義關(guān)聯(lián)信息在其他研究領(lǐng)域如自然語言處理(NLP)中也得到了廣泛研究.因此,如何結(jié)合其他領(lǐng)域的研究方法也可作為提升圖像標(biāo)注性能的方向之一.
5) 由于近年來深度學(xué)習(xí)模型在圖像標(biāo)注領(lǐng)域表現(xiàn)出了良好的性能但可解釋性低的特性,而較低的可解釋性意味著深度學(xué)習(xí)模型的架構(gòu)往往存在可復(fù)現(xiàn)及調(diào)參的問題.因此,深度學(xué)習(xí)模型在圖像標(biāo)注領(lǐng)域中的模型構(gòu)建依據(jù)以及調(diào)參技巧也是需要研究的課題.此外,由于遷移學(xué)習(xí)表現(xiàn)出的可將已學(xué)習(xí)知識應(yīng)用到新領(lǐng)域的強大性能,研發(fā)新的遷移學(xué)習(xí)理論和模型方法也成為改善圖像標(biāo)注性能的新思路.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
