基于近紅外光譜技術的電子煙油煙堿含量快速檢測研究
2020-11-09 10:53:56楊雙艷沈彥文楊紫剛張四偉
分析測試學報 2020年11期
楊雙艷,周 瑾,沈彥文,楊紫剛,費 宇,張四偉
(1.云南巴菰生物科技有限公司,云南 昆明 650000;2.云南財經大學 統計與數學學院,云南 昆明 650000;3.云南省煙草公司文山州公司,云南 文山 663000)
電子煙在傳遞尼古丁的過程中不需要對煙草進行燃燒,相比傳統香煙更加安全且具有更少的有害成分,因此逐漸成為傳統香煙新的替代品[1]。煙堿作為電子煙煙油中最主要的成分,其含量決定了電子煙油的風味口感及產品的安全性,一些國家和地區相繼將電子煙煙油中的煙堿納入監管范圍。目前,對電子煙煙油中煙堿的檢測大多參考卷煙煙草的檢測方法,主要采用氣相色譜法和液相色譜法進行測定,但這些方法存在檢測時間長、樣品預處理繁瑣、費用高、對操作人員要求高等缺點。因此,研究開發一種準確、快速、無損的檢測方法獲得電子煙油的煙堿指標對于控制電子煙油的品質和工藝具有重大意義。
近紅外光譜(NIR)分析技術具有簡便、快速、前處理簡單、對樣品無破壞性、無污染并可多組分同時測定等優點[2],在農業[3-4]、石油[5-6]、煙草[7-9]等領域有著廣泛應用,但目前尚未見采用近紅外光譜對電子煙油進行檢測的研究。電子煙油中有機組分的化學和物理信息在近紅外光譜中均有體現,因此近紅外光譜非常適合對電子煙油進行分析檢測。
為了解決反向傳播算法(Backward probagation)學習效率低、參數設定繁瑣的問題,2004年Huang等[10]提出極限學習機(Extreme learning machine,ELM)算法,并發表于當年的IEEE國際交互會議(IEEE International Joint Conference)。ELM是一類基于前饋神經網絡(Feedforward neuron network)的機器學習算法,其主要特點是隱含層節點參數可以隨機或人為給定且不需要調整,學習過程僅需計算輸出權重。ELM具有學習效率高和泛化能力強的優點,被廣泛應用于分類[11]、回歸[12]、聚類[13]、特征學習[14]等問題中,但尚未見應用于電子煙油近紅外光譜分析的相關研究。
本文以近紅外光譜分析技術為基礎,結合ELM算法對電子煙油的近紅外光譜數據和煙堿指標進行定量建模。與現有檢測方法相比,本文所提出的方法具有快速準確、綠色無損等優點,能夠實現電子煙油煙堿指標的快速準確測量,為電子煙油重要理化指標的實時在線監測和其它質量參數的快速測量奠定了良好的基礎。
1 極限學習機算法的基本理論
極限學習機與傳統的梯度下降學習算法相比具有較大優勢:(1)隨機給定隱含層的連接權值,訓練過程不需要迭代調整,計算速度非常快;(2)傳統的梯度下降算法容易陷入局部極小,而ELM算法由于求解輸出權值最小二乘解的過程是一個凸優化問題,因此不會陷入局部最優;(3)參數選擇簡單,只需選擇合適的隱含層結點便可獲得良好的性能,而傳統的梯度下降算法,如BP網絡等,需要選擇合適的學習率、訓練步長等,選擇不當會影響網絡的泛化性。
對于一個單隱層神經網絡,假設有個任意的樣本(ti,Xi),其中:
Xi=[xi1,xi2,…,xin]T∈Rn
(1)
ti=[ti1,ti2,…,tin]T∈Rm
(2)
對于一個有N個隱層節點的單隱層神經網絡可以表示為:
(3)
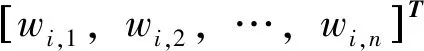
單隱層神經網絡學習的目標是使輸出的誤差最小,可以表示為:
(4)
即存在βi,Wi和bi,使得:
(5)
可以矩陣表示為:
Hβ=T
(6)
其中,H是隱層節點的輸出,β為輸出權重,T為期望輸出。
(7)
(8)
(9)
其中,i=1,…,L,這等價于最小化損失函數:
(10)
傳統的一些基于梯度下降法的算法,可以用來求解式(10)中的問題,但是基本的基于梯度的學習算法需要在迭代的過程中調整所有參數。而在ELM算法中,一旦輸入權重Wi和隱層的偏置bi被隨機確定,隱層的輸出矩陣H就被唯一確定。訓練單隱層神經網絡可以轉化為求解一個線性系統Hβ=T。并且輸出權重可以被確定:
(11)
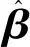
2 實驗部分
2.1 儀器與樣本
樣本的近紅外光譜采集使用Antaris傅里葉變換近紅外光譜儀(Thermo Nicolet,USA),配有透射檢測器,采樣系統和Result、TQ Analyst等數據處理軟件;實驗樣本由云南巴菰生物科技有限公司提供,共70個樣本。實驗過程中,按照樣本煙堿含量從低到高均勻分布的原則選取40個樣本作為訓練樣本,30個樣本作為測試樣本;使用氣相色譜儀/氫火焰離子化檢測器獲取電子煙油的煙堿含量,訓練樣本的煙堿含量范圍為1~60 mg/g,平均值為27.98 mg/g,標準差為15.96;測試樣本的煙堿含量范圍為3~52 mg/g,平均值為27.37 mg/g,標準差為14.80。實驗樣本的詳細信息見表1。

表1 實驗樣本的詳細信息Table 1 Detail information of experimental samples
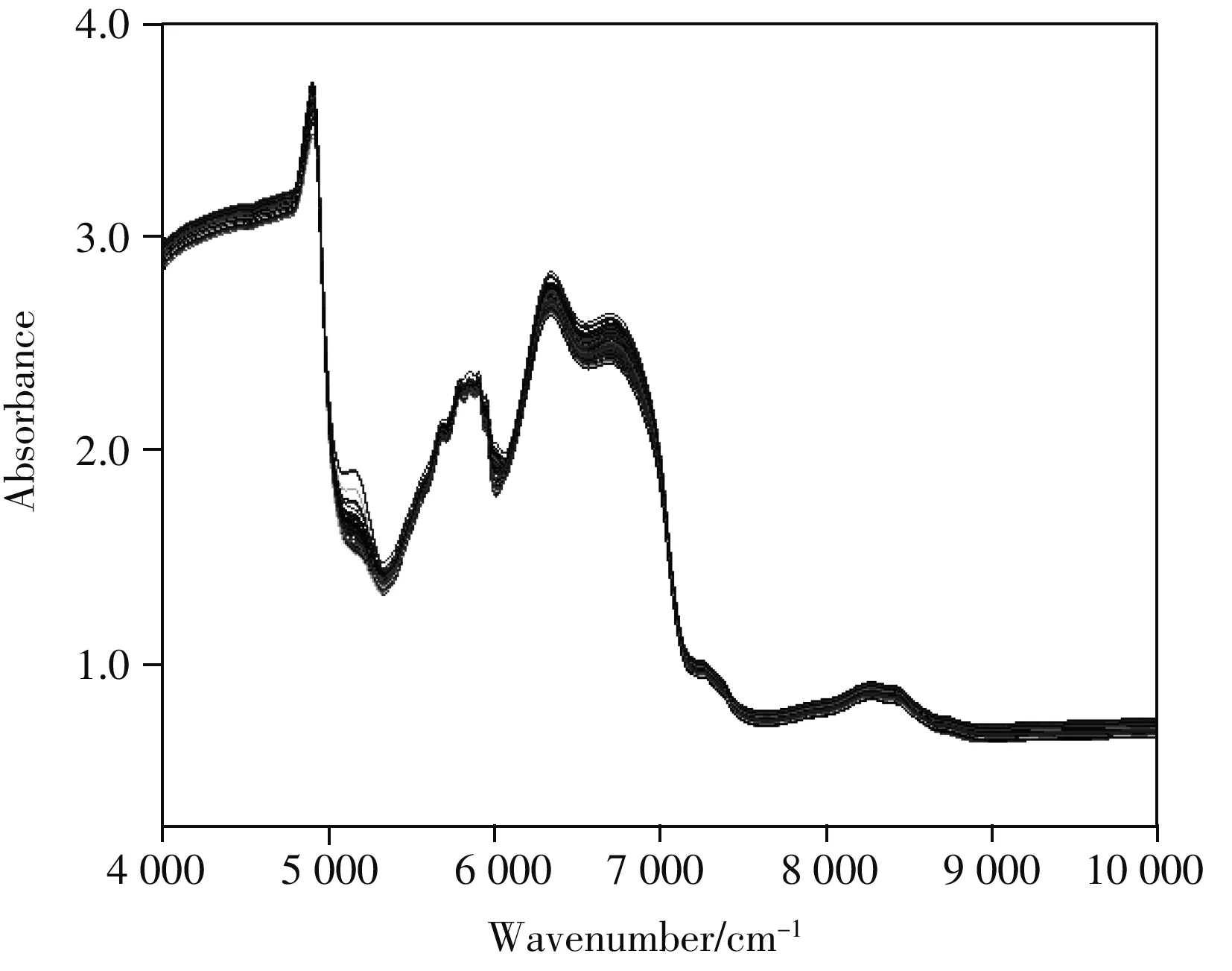
圖1 實驗樣本的原始近紅外光譜數據Fig.1 Original NIR data of the samples
2.2 近紅外光譜采集
近紅外光譜儀的相關參數設置:光譜采集模式為透射模型,數據格式為Absorbance,掃描次數為32,分辨率為4 cm-1,光纖透射式探頭光程為2 mm,以空氣為參比,光譜掃描范圍為4 000~10 000 cm-1。將煙油樣本滴入石英皿中,每個樣本重復采樣3次,取3次光譜的平均值作為樣本的最終光譜。實驗樣本的原始近紅外光譜數據如圖1所示。
2.3 數據處理方法與模型性能評價指標
首先對采集的電子煙油的近紅外光譜數據進行預處理操作,并選擇合適的波段,分別采用主成分回歸(Principal component regression,PCR)[15]、偏最小二乘回歸(Partial least squares regression,PLSR)[16]和極限學習機回歸(Extreme learning machine regression,ELMR)建立近紅外光譜數據與煙堿含量之間的定量校正模型。使用決定系數(R2)、校正均方根誤差(Root mean square error of calibration,RMSEC)、預測均方根誤差(Root mean square error of prediction,RMSEP)為指標優化建模參數,用以考察模型性能,以上參數的計算方法見文獻[17-18]。
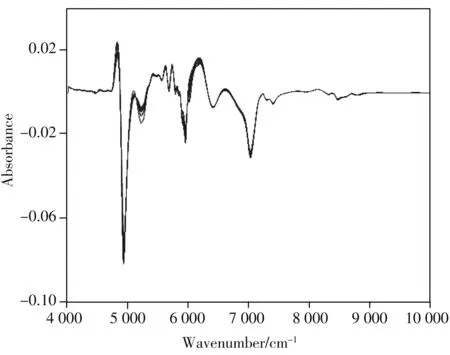
圖2 原始光譜經過多元散射校正和Savitzky-Golay一階導數(窗口大小為5,3次多項式)濾波后的預處理結果Fig.2 Pretreatment result of spectral data by means of using multiplicative scatter correction and Savitzky-Golay first derivative with a 5-point window and three polynomial order
3 結果與討論
對近紅外光譜數據進行分析和處理時,其中一個重要步驟是對光譜數據進行預處理操作。光譜的預處理操作能夠降低或消除非目標因素對光譜信息的影響,通過對其進行適當的數學操作,能夠最大程度去除冗余信息,從而更利于從復雜光譜中提取有效信息,在一定程度上提高校正模型的穩健性。本文通過多元散射校正和Savitzky-Golay一階導數(窗口大小為5,3次多項式)濾波的方法進行預處理操作,處理結果如圖2所示。可以看出,經過預處理的光譜圖像有效消除了光譜的基線漂移現象。從圖2還可以看出,光譜的吸收波長區間主要集中在4 492~7 864 cm-1。因此,隨后將主要使用此波長區間對電子煙油的近紅外光譜數據與樣本的煙堿含量進行定量建模。
分別采用PCR、PLSR和ELMR建立近紅外光譜數據和傳統化學方法測量所獲得的煙堿含量之間的定量校正模型,并以R2、RMSEC、RMSEP為指標優化建模參數,建模結果和測試結果分別如表2和表3所示。其中,使用PCR和PLSR進行光譜建模時,首先對光譜數據進行主成分降維處理,所選用的主成分數為5。設置ELM算法的隱含層神經元數為30,以Sigmoidal函數為隱含層神經元激勵函數。由ELM算法的基本理論得知,輸入權重Wi和隱層的偏置bi將會在訓練過程中隨機確定,不需人工設定。
由表2可以看出,使用ELMR算法所建立校正集模型的R2為0.950 0,遠高于PCR和PLSR算法;同時,ELMR算法的RMSEC為0.014 9,遠低于PCR和PLSR算法。表3顯示,在預測方面,ELMR算法預測模型的R2為0.926 2,遠高于PCR和PLSR算法;同時,使用ELMR算法的RMSEP為0.026 8,遠低于PCR和PLSR算法。因此,ELMR算法在建模效果和預測結果方面,都取得了最高的決定系數和最小的均方根誤差。上述結果證明,采用近紅外光譜技術快速測定電子煙油的煙堿含量時,使用ELMR算法建立的模型性能優于經典的PCR和PLSR算法。相對于傳統方法,ELMR提高了訓練集的數據利用率,具有更好的范化性能和更高的回歸預測精度,算法的預測精度高,泛化能力強,不容易出現過擬合傾向。

表2 不同建模方法的煙堿訓練結果Table 2 Training results of nicotine using different modeling methods

表3 不同建模方法測試樣本的預測結果Table 3 Prediction results of testing samples using different modeling methods
4 結 論
本文以近紅外光譜分析技術為基礎,結合極限學習機算法對電子煙油進行近紅外光譜定量建模。與現有檢測方法相比,本文所提出的檢測方法具有快速準確、綠色無損等優點,能夠實現電子煙油煙堿含量的快速準確測量,為電子煙油煙堿含量的實時在線監測和其它質量參數的快速測量奠定了良好的基礎。
