2D人體姿態估計綜述
2020-11-06 14:27:24岳程宇閆勝業
現代信息科技 2020年12期
岳程宇 閆勝業


摘 ?要:在神經網絡深度學習流行的今天,2D人體姿態估計作為其他計算機視覺任務的研究基礎,它的檢測精度和速度對后續其他檢測等任務有著重大的影響,并且引起了學者們的廣泛關注。文章針對該方向的研究內容進行了綜述,闡述了研究意義和應用,對數據庫和評價指標進行介紹,接著結合代表作分析研究了姿態估計的傳統方法、深度學習方法,最后總結討論現階段研究的問題和趨勢。
關鍵詞:計算機視覺;姿態估計;人體關鍵點
中圖分類號:TP391.41 ? ? ?文獻標識碼:A 文章編號:2096-4706(2020)12-0090-03
Abstract:Under the popularity of neural network and deep learning,2D pose estimation,the precision and speed of it has a great influence on the next task,and it has attracted wide attention of scholars. For this research details,this paper expounds the meanings and applications,introduces the databases and the evaluation indexes,then analyses the conventional methods and deep learning methods. Finally,it summarizes and discusses the current research problems and trend.
Keywords:computer vision;pose estimation;key points of human body
0 ?引 ?言
2D人體姿態估計是計算機視覺研究中的一個重要分支,其研究結合了檢測、識別、跟蹤的相關方法。其主要目的是對人體骨骼的關鍵點進行準確快速定位識別,即給出一張RGB的圖像,定位圖中人體的關鍵點位置,并確定其隸屬的人體。
筆者在研究新型人體姿態估計網絡時,發現更進一步的研究需要對2D人體姿態估計的數據庫及其評價指標、傳統方法和主流方法進行綜合了解,并且要把握姿態估計現在的困難以及未來的發展。筆者通過查閱分析近些年來人體姿態估計的相關方法論文,從其研究的意義和應用、數據庫及其評價指標、2D人體姿態估計的傳統方法和深度學習方法、現階段的問題與發展趨勢這4個角度分析進行了總結。
1 ?研究意義與應用
2D人體姿態估計的研究是一些其他計算機視覺問題研究的基礎。它可以作為3D人體姿態估計研究的鋪墊,對于視頻動作識別來說可以作為前處理的來源,在重識別、視頻追蹤問題上,2D姿態估計都可以作為靜態圖像,并為動態處理提供有力的支持。
在現實應用方面,人體姿態估計可以應用于電影VR和AR技術、人體仿真模型的構建、手機短視頻軟件的人體動作特效等;在安全領域中可以作為駕駛輔助對行人進行檢測和其未來動作進行識別、預測;在特殊重大場合下對密集人群危險動作的視頻監控等
2 ?數據庫及評價標準
2D姿態估計的數據庫主要有MS COCO、MPII、FLIC。目前主流研究姿態估計的數據庫是COCO和MPII這兩個數據庫。
COCO數據集[1]是微軟于2014年為用于進行圖像分割檢測,圖片上下文關系研究而出資標注的。它是繼ImageNet競賽后計算機視覺領域最受關注和權威的比賽之一。COCO數據集包含了有20萬張圖片和25萬個帶有17個人體骨骼關鍵點標注實例。
COCO數據集的評價指標為OKS,其中KS是一個關鍵點真值與預測值的相似度,如式(1),P表示的真值中的每個人的ID,pi表示的是某人關鍵點的ID,Vpi=0表示這個關鍵點沒有標注,Vpi=1表示標注了但是圖像中不可見,Vpi=2表示標注了且圖像中可見, 表示的是這個人所占面積的大小的平方根,σi表示第i個骨骼的歸一化因子,dpi表示真值關鍵點與預測關鍵點之間的歐式距離,δ將關鍵點選出的函數。
MPII數據集是2014年發布的關于人體姿態估計的評估基準,它包括大約2.5萬張圖片,其中有超過4萬人的身體關鍵點有注釋,每個人體注釋了16個特征關鍵點。它的評價指標為PCK@0.5,是檢測正確關鍵點的百分比,若預測關節與真實關節之間的距離在特定閾值內,則檢測到的關節被認為是正確的,其閾值大小為頭骨長度的50%。
3 ?2D人體姿態估計研究方法
3.1 ?傳統方法
人體姿態估計的傳統研究的主流方式有兩種。第一類是直接通過一個全局特征,把人體姿態估計問題當成分類問題或回歸問題直接求解。
Randomized Trees for Human Pose Detection[2]中作者提出將人體姿態估計問題當作分類任務來做,他們的姿態估計算法中使用了層次樹和隨機森林的方法,隨機樹和隨機森林可以快速且高效地處理多分類的問題且具有一定的魯棒性。在特征提取方法中,作者使用了當時比較成功的HOG描述子進行特征提取,如圖1所示。
第二類是基于一個圖形結構模型,其思想是,將對象表示成一堆“部件”的集合,而部件的組合是可以發生形變的。一個部件表示目標對象某部分圖形的模板。當部件通過像素位置和方向進行參數化后,其得到的結構可以對與姿態估計非常相關的關鍵點進行建模。
在Pictorial Structures Revisited:People Detection and Articulated Pose Estimation[5]中,作者提出了功能強大且簡單的身體模型,可以精確有效地推斷身體部件的樹模型結構,同時研究了強大的關鍵點檢測器,適用于各種不同場景下對關鍵點的檢測。而且基于形狀上下文描述計算,使用了AdaBoost來訓練分類器。
3.2 ?深度學習方法
在傳統方法中,特征的提取和圖結構模型在姿態估計中都扮演了非常重要的角色。隨著神經網絡的流行、深度學習的運用,它將特征提取、分類和空間位置建模都直接在一個“黑盒”中進行端到端的訓練,這不僅方便研究人員設計與優化,而且計算處理的數據越多,檢測的效果也越好。
2D人體姿態估計的深度學習方法大致可分為自上而下(Top-Down)和自底向上(Bottom-Up)這兩種。
3.2.1 ?Top-Down
這是一種自上而下的方法它是先通過目標檢測算法檢測人體的邊界框,再對圖片進行裁剪,將裁剪圖片進行單人姿態估計。
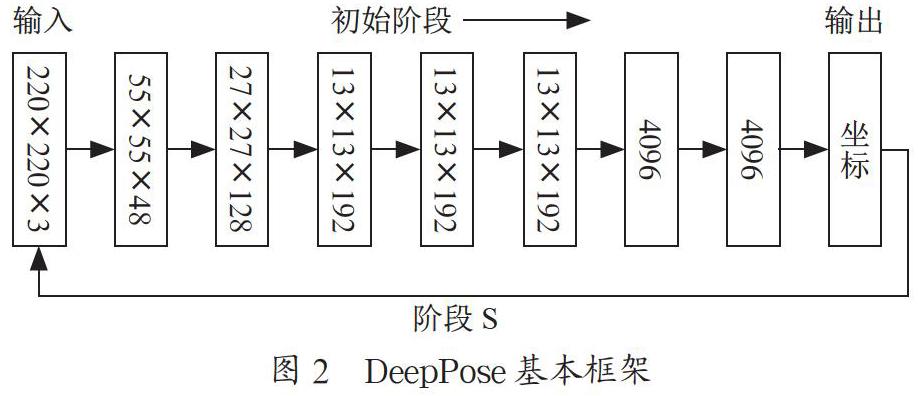
DeepPose:Human Pose Estimation via Deep Neural Networks[3]是第一篇將深度學習應用在人體姿態估計問題的文獻。它把姿態估計設計成一個關鍵點回歸問題,并用神經網絡來實現。首先輸入圖像,用一個7層的卷積神經網絡和使用L2損失對模型進行回歸訓練。它克服了之前只使用局部特征的缺陷,并使用了全局的特征網絡,如圖2所示。
HRNet是2019年提出來的新的單人姿態估計研究的方法。HRNet是通過串聯多個由高分辨到低分辨的子網來建立的,每個子網構成一個階段卷積序列且通過一個下采樣層將分辨率減半。網絡向右側方向,深度不斷加深;網絡向下方向,特征圖分辨率逐漸降低,高分辨率和低分辨率特征圖在中間有互相融合的過程,這樣提升了高分辨下的表示。
3.2.2 ?Bottom-Up
這是一種自下而上的方法,它是先檢測圖片中所有的關鍵點,然后再對關鍵點通過匹配算法進行人體匹配。
在DeepCut中,作者通過CNN提取關鍵點的候選區域,每一個候選區域對應一個關鍵點,所有關鍵點組成一個密集連接圖,關鍵點之間的關聯性作為圖節點的權重,將其作為一個優化問題。我們可以通過歸類得到有多少個人,并且通過圖論節點的聚類,進行非極大值抑制,將優化問題表示為整數線性規劃求解。
在OpenPose[4]中作者將輸入圖片輸入到一個特征提取網絡,提取特征圖后分別使用神經網絡提取關鍵點置信圖和親和場,結構如圖3所示。置信圖和親和向量場已知后,將關鍵點作為圖的頂點,將關鍵點之間的相關性PAF看為圖的邊權,則將多人檢測問題轉化為二分圖匹配問題,并用匈牙利算法求得最優匹配。關鍵點連線聚類問題可看成是各肢體之間獨立優化配對,解決了肢體涉及的兩類關鍵點的連線聚類后,最后依據關鍵點相同銜接組成整個姿態。
4 ?現階段人體姿態估計研究問題趨勢
在擁擠場景下人體關鍵點檢測是目前十分具有挑戰的任務,我們需要研究更多在不同場景、不同著裝、不同姿態、不同尺度下人的標注圖片。同時,這對姿態估計的檢測速度和精度都提出了非常高的要求。
在檢測任務中,網絡大部分都是需要巨大參數量和計算量的大網絡,在計算機上容易實現,但是轉入到嵌入式,移動端的網絡研究還是遠遠不夠的,現在學者們主要的關注點是在提高關鍵點的檢測精度,而在如何提高檢測效率這個問題還需要進一步研究。
目前2D人體關鍵點的研究,有從2D人體姿態估計+匹配的方法推斷3D結構,研究3D人體姿態估計問題,并有向更高維發展的趨勢。
單一的圖像理解已經穩步推進,但視頻理解的進展較為緩慢,在Mask R-CNN的預測基礎上,通過整合相鄰視頻幀的時間信息對CNN進行擴展預測視頻信息,將研究的重點從圖片向視頻的方向發展。
在檢測問題中要想提升性能,往往需要更多的資源和成本,所以要在保證精度不變的情況下提升網絡效率,構建一個輕量級的網絡。我們可以采用知識蒸餾的原理,實現姿態估計快速和低成本部署。
5 ?結 ?論
2D人體姿態估計從傳統方法進入了深度學習的時代,未來新的網絡結構也不會是解決估計問題的核心,應通過數據處理、增強,以及更多的機器學習和數學方面的知識,來共同研究這個問題。從工程方面產品落地角度思考,要研究更輕量、方便的模型進行應用。總之,2D人體姿態估計是當下一個具有很高熱度的計算機視覺研究領域,擁有非常廣闊的研究前景。
參考文獻:
[1] LIN T Y,MAIRE M,BELONGIE S,et al. Microsoft COCO:Common Objects in Context [C]// Conference proceedings ECCV 2014,Zurich,Switzerland:Springer,2014.
[2] ROGEZ G,RIHAN J,RAMALINGAM S,et al. Randomized trees for human pose detection [C]//2008 IEEE Conference on Computer Vision and Pattern Recognition,Anchorage,AK,USA:IEEE,2018.
[3] TOSHEV A,SZEGEDY C. DeepPose:Human Pose Estimation via Deep Neural Networks [J/OL]. arXiv:1312.4659 [cs.CV].(2014-08-20).https://arxiv.org/abs/1312.4659.
[4] CAO Z,SIMON T,WEI S E,et al. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields [J/OL]. arXiv:1611.08050 [cs.CV].(2017-04-14). https://arxiv.org/abs/1611.08050.
作者簡介:岳程宇(1996.01—),男,漢族,江蘇南京人,碩士在讀,研究方向:模式識別;閆勝業(1978.06—),男,漢族,河南新鄉人,教授,博士研究生,工學博士,研究方向:視頻與圖像處理。
