融合對抗主動學(xué)習(xí)的網(wǎng)絡(luò)安全知識三元組抽取
2020-11-03 06:53:52李濤郭淵博琚安康
通信學(xué)報 2020年10期
李濤,郭淵博,琚安康
(信息工程大學(xué)密碼工程學(xué)院,河南 鄭州 450001)
1 引言
對威脅信息的持續(xù)跟蹤與分析,已成為增強網(wǎng)絡(luò)安全防護的一項重要舉措。以威脅情報為主的網(wǎng)絡(luò)威脅信息通常以網(wǎng)絡(luò)安全文本的形式披露,包括各類網(wǎng)絡(luò)安全社區(qū)發(fā)布的博客、白皮書;軟件廠商發(fā)布的安全公告等。然而,近年來層出不窮的網(wǎng)絡(luò)安全事件導(dǎo)致網(wǎng)絡(luò)威脅情報海量增長。由于非結(jié)構(gòu)化形式的網(wǎng)絡(luò)威脅情報不能被機器所理解,繼續(xù)依靠人工方式從文本形式的威脅情報中識別、提取諸如新型漏洞信息、漏洞利用方式、網(wǎng)絡(luò)攻擊工具以及攻擊模式等關(guān)鍵威脅信息,并進行關(guān)聯(lián)分析已無法滿足網(wǎng)絡(luò)安全防御的現(xiàn)實需求。為此,利用信息抽取技術(shù),從網(wǎng)絡(luò)安全文本中自動地抽取安全相關(guān)的實體、概念以及關(guān)系,將非結(jié)構(gòu)化的數(shù)據(jù)轉(zhuǎn)換成易于共享和集成的結(jié)構(gòu)化表達,形成網(wǎng)絡(luò)安全鏈接數(shù)據(jù)[1],并構(gòu)建網(wǎng)絡(luò)安全知識圖譜,賦予機器認知智能以實現(xiàn)網(wǎng)絡(luò)安全文本的挖掘與智能化分析,將在網(wǎng)絡(luò)安全主動防御體系的構(gòu)建中發(fā)揮重要作用。
信息抽取作為文本挖掘的關(guān)鍵技術(shù),已被廣泛應(yīng)用于摘要生成、自動問答、知識圖譜等領(lǐng)域[2]。信息抽取可細分為命名實體識別、實體關(guān)系抽取和事件抽取3 個子任務(wù),其中通過實體識別和實體關(guān)系抽取來獲取語義三元組,是構(gòu)建知識圖譜、理解自然語言的重要前提。由于網(wǎng)絡(luò)安全領(lǐng)域所關(guān)注的實體包括攻擊者、攻擊方式、漏洞名、資產(chǎn)等特定類別,且關(guān)系抽取所針對的是此類與網(wǎng)絡(luò)威脅相關(guān)的特定實體間的語義表達,而現(xiàn)有的信息抽取系統(tǒng)無法適用于網(wǎng)絡(luò)安全領(lǐng)域?qū)嶓w與關(guān)系的抽取。為滿足應(yīng)用的需求,需開發(fā)面向網(wǎng)絡(luò)安全領(lǐng)域的知識抽取系統(tǒng)。
相較于在通用領(lǐng)域以及金融、法律、生物醫(yī)學(xué)等領(lǐng)域的成功應(yīng)用,面向網(wǎng)絡(luò)安全領(lǐng)域的知識抽取研究才剛起步。2018 年,第十二屆國際語義評測比賽中的任務(wù)8 旨在運用自然語言處理技術(shù)實現(xiàn)網(wǎng)絡(luò)安全文本的語義信息抽取[3],其中包含了針對惡意軟件相關(guān)文本中實體、關(guān)系及其屬性進行標(biāo)簽預(yù)測的子任務(wù)。當(dāng)前面向網(wǎng)絡(luò)安全領(lǐng)域的知識抽取研究是通過流水線模式進行的,即首先通過命名實體識別來獲取網(wǎng)絡(luò)安全相關(guān)的實體[4],在此基礎(chǔ)上再根據(jù)預(yù)定義的實體關(guān)系類別進行候選實體對間的關(guān)系預(yù)測[5],進而得到網(wǎng)絡(luò)安全知識三元組。盡管流水線框架具有集成不同數(shù)據(jù)源和學(xué)習(xí)算法的靈活性,但也存在一定的問題[6]:1) 關(guān)系抽取依賴實體識別的結(jié)果,而實體識別階段產(chǎn)生的錯誤將傳播到關(guān)系預(yù)測階段,影響關(guān)系抽取效果;2) 將實體識別與關(guān)系抽取分開執(zhí)行,無法充分利用2 個任務(wù)間的語義聯(lián)系;3) 先識別實體,再進行關(guān)系預(yù)測,導(dǎo)致流水線框架下信息抽取效率較低。
不同于流水線框架,實體與關(guān)系的聯(lián)合抽取旨在對2 個任務(wù)同時建模,當(dāng)前實體與關(guān)系的聯(lián)合抽取得到研究者的廣泛關(guān)注[7]。早期關(guān)于聯(lián)合抽取的研究依賴復(fù)雜的特征工程以及自然語言處理工具,隨著深度神經(jīng)網(wǎng)絡(luò)的廣泛應(yīng)用,研究人員提出端到端的實體?關(guān)系聯(lián)合抽取模式。現(xiàn)有的實體關(guān)系聯(lián)合學(xué)習(xí)方法包括基于參數(shù)共享的方法和基于序列標(biāo)注的方法。前者對實體識別和關(guān)系抽取任務(wù)通過共享編碼層模型進行聯(lián)合學(xué)習(xí),其在訓(xùn)練時共享部分參數(shù),此方法本質(zhì)上仍將2 個任務(wù)分開執(zhí)行,會產(chǎn)生冗余信息;后者將實體與關(guān)系聯(lián)合抽取任務(wù)轉(zhuǎn)換成序列標(biāo)注問題,基于實體?關(guān)系的聯(lián)合標(biāo)注策略進行建模,直接得到實體?關(guān)系三元組[2]。Zheng等[8]首次提出基于序列標(biāo)注的實體與關(guān)系聯(lián)合抽取方法,并在通用領(lǐng)域的知識抽取中取得了較好的效果。但由于其假設(shè)一個實體只有一個關(guān)系標(biāo)簽,無法適用于存在重疊關(guān)系的領(lǐng)域文本。為解決面向生物醫(yī)學(xué)文本實體與關(guān)系聯(lián)合抽取中的重疊關(guān)系問題,曹明宇等[7]改進Zheng 等[8]提出的聯(lián)合標(biāo)注模式,在藥物?藥物關(guān)系抽取中取得了較好的效果。通過類比生物醫(yī)學(xué)文本發(fā)現(xiàn),在網(wǎng)絡(luò)安全文本中同一個實體也可能參與多個語義關(guān)系,因此面向網(wǎng)絡(luò)安全領(lǐng)域的實體與關(guān)系聯(lián)合抽取中也存在重疊關(guān)系問題。
盡管端到端的神經(jīng)網(wǎng)絡(luò)模型在諸多任務(wù)中性能突出,但其在實際應(yīng)用中依賴大規(guī)模的標(biāo)簽數(shù)據(jù)。相較于通用領(lǐng)域大量可獲取的標(biāo)注語料,網(wǎng)絡(luò)安全領(lǐng)域的標(biāo)注語料極其缺乏,導(dǎo)致同一模型應(yīng)用于網(wǎng)絡(luò)安全領(lǐng)域的實體識別與關(guān)系抽取任務(wù)時效果不佳。而不需要標(biāo)簽數(shù)據(jù)的無監(jiān)督學(xué)習(xí)方法性能通常弱于監(jiān)督學(xué)習(xí)。為此,面向網(wǎng)絡(luò)安全領(lǐng)域的語料標(biāo)注仍然是提升實體識別與關(guān)系抽取性能的一項關(guān)鍵任務(wù)。然而針對網(wǎng)絡(luò)安全文本的標(biāo)注通常存在兩方面的問題:1) 需要網(wǎng)絡(luò)安全領(lǐng)域的專家或具備一定網(wǎng)絡(luò)安全知識的從業(yè)人員才能完成對網(wǎng)絡(luò)安全文本的標(biāo)注;2) 相較于通用領(lǐng)域的文本語料,網(wǎng)絡(luò)安全文本中含有更多的對象實例,因此需要投入更多的人工成本去標(biāo)注。為減輕人工標(biāo)注數(shù)據(jù)的負擔(dān),主動學(xué)習(xí)算法能夠從未標(biāo)注數(shù)據(jù)池中增量地采樣出富有信息的樣本,由專家進行標(biāo)注后補充到標(biāo)簽數(shù)據(jù)集中,并通過迭代訓(xùn)練提升模型學(xué)習(xí)的性能。然而,盡管現(xiàn)有的主動學(xué)習(xí)算法在數(shù)據(jù)分類任務(wù)中性能良好,但此類采樣策略應(yīng)用于具有豐富標(biāo)簽空間的序列標(biāo)注任務(wù)時將變得極其復(fù)雜。
為解決網(wǎng)絡(luò)安全領(lǐng)域知識抽取中存在的上述問題,本文提出一種融合對抗主動學(xué)習(xí)的實體與關(guān)系聯(lián)合抽取方案。基于聯(lián)合標(biāo)注策略將實體識別與關(guān)系抽取任務(wù)轉(zhuǎn)化為序列標(biāo)注問題,并通過對抗學(xué)習(xí)機制訓(xùn)練一個判別器模型來篩選出富有信息量的樣本進行人工標(biāo)注,實現(xiàn)以較低的數(shù)據(jù)標(biāo)注代價完成聯(lián)合模型的訓(xùn)練。本文的主要貢獻包含3 個方面。
1) 不同于流水線模式的網(wǎng)絡(luò)安全實體識別與關(guān)系抽取,本文將2 個子任務(wù)聯(lián)合起來建模為序列標(biāo)注,提出一種基于端到端的網(wǎng)絡(luò)安全實體與關(guān)系聯(lián)合抽取框架。
2) 面向網(wǎng)絡(luò)安全文本知識抽取,基于長短時記憶(LSTM,long short-term memory neural)網(wǎng)絡(luò)和雙向長短時記憶(BiLSTM,bidirectional LSTM)網(wǎng)絡(luò),提出一種融合動態(tài)注意力機制的BiLSTMLSTM 序列標(biāo)注模型。
3) 針對網(wǎng)絡(luò)安全領(lǐng)域標(biāo)注語料缺乏的問題,基于主動學(xué)習(xí)思想,并融合對抗學(xué)習(xí)機制,提出一種對抗主動學(xué)習(xí)框架下的待標(biāo)注語料采樣方法。
2 相關(guān)工作
隨著網(wǎng)絡(luò)威脅的激增,詳細的威脅內(nèi)容以非結(jié)構(gòu)化的自然語言文本形式存在,諸如安全報告、白皮書、博客、公告等。而針對此類威脅信息的分析與集成對于安全人員來說是煩瑣且復(fù)雜的工作。因此,對威脅信息的自動化提取是亟待解決的問題。Liao[9]開發(fā)了一套iACE 系統(tǒng),用于自動地從威脅情報文本中提取威脅失陷指標(biāo)(IoC,indicator of compromise)及其上下文關(guān)系。Panwar[10]基于IoC的提取框架,可以從Cuckoo 沙箱結(jié)果中生成結(jié)構(gòu)化威脅信息表達(STIX,structured threat information expression)格式的IoC。Gasmi 等[11]將自然語言處理領(lǐng)域中的命名實體識別方法非結(jié)構(gòu)化安全信息的抽取中,結(jié)合LSTM 模型和條件隨機場(CRF,conditional random field),提出一種基于LSTM-CRF的模型,對安全領(lǐng)域文檔中相關(guān)實體,如產(chǎn)品、版本以及攻擊名稱等進行識別。Chambers 等[12]基于自然語言處理(NLP,natural language processing)的思想,通過訓(xùn)練前饋神經(jīng)網(wǎng)絡(luò)和文檔主題生成(LDA,latent Dirichlet allocation)模型,從社交媒體數(shù)據(jù)中提取表征攻擊行為的實體,進而實現(xiàn)分布式拒絕服務(wù)(DDoS,distributed denial of service)攻擊的檢測。Zhou 等[13]和Long 等[14]運用端到端的神經(jīng)網(wǎng)絡(luò)并結(jié)合注意力機制,針對威脅情報語料建立模型,訓(xùn)練得到IoC 提取器,在實際的IoC 抽取效果上表現(xiàn)出較高的準(zhǔn)確率。由于對威脅情報的利用不僅限于IoC,威脅情報報告中提供了更多有關(guān)網(wǎng)絡(luò)攻擊的詳細信息,尤其是有關(guān)攻擊者、攻擊技術(shù)、攻擊工具等的語義信息。秦婭等[15]在對威脅情報語料分析的基礎(chǔ)上,利用卷積神經(jīng)網(wǎng)絡(luò)(CNN,convolutional neural network)獲取語料字符嵌入特征,提出一種融合特征模板的CNN-BiLSTM-CRF 的網(wǎng)絡(luò)安全實體識別方法,在對網(wǎng)絡(luò)安全文本數(shù)據(jù)涉及的人名、地名、組織名、軟件名、網(wǎng)絡(luò)相關(guān)術(shù)語以及漏洞編號的識別上取得了不錯的效果。張若彬等[16]針對安全漏洞領(lǐng)域的命名實體,提出一種基于BLSTM-CRF 的識別模型,并結(jié)合領(lǐng)域詞典對識別結(jié)果進行校正,實現(xiàn)對漏洞編號、漏洞名、漏洞類型、漏洞利用條件(軟件供應(yīng)商、操作系統(tǒng)、應(yīng)用軟件)、攻擊方式共7 類漏洞相關(guān)命名實體的有效識別。此外,Pingle 等[5]開發(fā)了一套基于深度學(xué)習(xí)的威脅情報語義關(guān)系抽取系統(tǒng),從開源威脅情報中獲取語義三元組,并與安全運營中心結(jié)合進一步提升網(wǎng)絡(luò)安全防御能力。上述研究均屬于流水線模式,而目前尚未出現(xiàn)面向網(wǎng)絡(luò)安全領(lǐng)域的知識聯(lián)合抽取研究。
主動學(xué)習(xí)算法旨在逐步選擇用于標(biāo)注的樣本,從而以較低的標(biāo)記成本實現(xiàn)模型較高的分類性能。當(dāng)前主動學(xué)習(xí)領(lǐng)域的研究包括基于樣本生成的主動學(xué)習(xí)和基于池的主動學(xué)習(xí)。基于樣本生成的主動學(xué)習(xí)方法屬于生成模型范疇,通過生成富有信息的樣本,再由專家進行樣本標(biāo)記。Zhu 等[17]首次通過生成式對抗網(wǎng)絡(luò)(GAN,generative adversarial network)來合成待標(biāo)注樣本,建立主動學(xué)習(xí)模型。但由于GAN模型存在訓(xùn)練困難以及模式崩壞的情況,生成的樣本可能不滿足真實樣本的數(shù)據(jù)分布,當(dāng)生成無意義的樣本時,很難對其進行人工標(biāo)注。因此,此類方法依賴于生成樣本的質(zhì)量和多樣性。
基于池的主動學(xué)習(xí)是從數(shù)據(jù)池中篩選樣本進行人工標(biāo)注,當(dāng)前基于池的主動學(xué)習(xí)算法是主動學(xué)習(xí)的主要研究領(lǐng)域,并已在圖像分類、語音識別、文本分類以及信息檢索等諸多實際場景中得到廣泛應(yīng)用。基于池的主動學(xué)習(xí)方法中具有代表性的采樣策略包括基于不確實性的方法、基于集成的方法以及基于核心集的方法等。Culotta 等[18]利用最小置信度準(zhǔn)則評估線性CRF 模型在序列預(yù)測任務(wù)上的不確定性,實現(xiàn)主動學(xué)習(xí)算法在序列標(biāo)注任務(wù)上的應(yīng)用。Houlsby 等[19]提出了一種貝葉斯不一致主動學(xué)習(xí)算法,其中采樣函數(shù)通過訓(xùn)練樣本關(guān)于模型參數(shù)的互信息來進行不確定性度量。Gal 等[20]通過揭露不確定性和正則化之間的關(guān)系來度量神經(jīng)網(wǎng)絡(luò)預(yù)測中的不確定性,并將其應(yīng)用于主動學(xué)習(xí)。Sener 等[21]提出基于核心集的主動學(xué)習(xí)算法,該算法使采樣數(shù)據(jù)點和訓(xùn)練模型的特征空間中未采樣點間的歐幾里得距離達到最小化。Kuo 等[22]提出一種基于集成的主動學(xué)習(xí)算法來表示不確定性,但該算法容易造成對樣本的冗余采樣。此外,Shen 等[23]將深度主動學(xué)習(xí)算法運用于命名實體識別任務(wù)中,并比較了最小置信度算法、貝葉斯非一致主動學(xué)習(xí)和最大歸一化對數(shù)概率這3 類采樣策略的性能。
3 方法描述
3.1 模型架構(gòu)
本節(jié)對所提模型進行詳細描述,模型整體架構(gòu)如圖1 所示。模型由2 個模塊組成:實體?關(guān)系聯(lián)合抽取的序列標(biāo)注模塊和對抗主動學(xué)習(xí)模塊,其中聯(lián)合抽取模塊包含表示層、編碼層、動態(tài)注意力層、解碼層。
對于三元組聯(lián)合抽取模塊,首先,在表示層利用word2vec 基于所收集的網(wǎng)絡(luò)安全文本訓(xùn)練得到詞向量表,將輸入序列映射成對應(yīng)的詞向量表示,此外,獲取每個詞所對應(yīng)的字符特征向量,并將其與詞向量進行拼接,組成模型的輸入;然后,利用BiLSTM 作為編碼層,得到輸入數(shù)據(jù)的特征編碼,并結(jié)合動態(tài)注意力機制進一步捕獲序列的上下文依存特征,將所得注意力向量輸入LSTM 解碼層得到標(biāo)簽序列的向量表示;最后,根據(jù)softmax 分類器的標(biāo)簽得分來輸出文本的標(biāo)簽序列。在對抗主動學(xué)習(xí)模塊,基于BiLSTM 得到標(biāo)注語句與未標(biāo)注語句的特征向量,將其輸入判別網(wǎng)絡(luò)通過比較數(shù)據(jù)分布的相似性,篩選出需要標(biāo)記的數(shù)據(jù)交由專家進行標(biāo)記,并將標(biāo)記后的數(shù)據(jù)加入標(biāo)簽訓(xùn)練集中,以此對聯(lián)合抽取模型迭代進行訓(xùn)練。
3.2 標(biāo)注策略及匹配規(guī)則
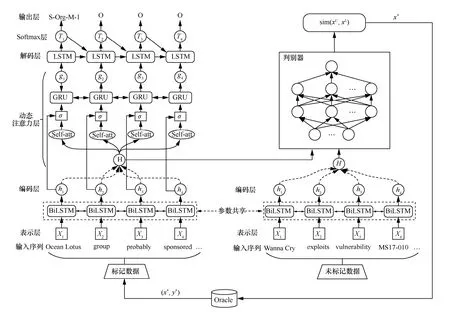
圖1 模型整體架構(gòu)
本節(jié)對所采用的標(biāo)注策略進行詳細闡述。Zheng 等[8]首次將實體與關(guān)系的聯(lián)合抽取問題轉(zhuǎn)換成序列標(biāo)注任務(wù),提出了實體與關(guān)系的聯(lián)合標(biāo)注策略。然而,由于其無法解決重疊關(guān)系問題,曹明宇等[7]在其基礎(chǔ)上改進了聯(lián)合標(biāo)注策略,能夠較好地解決部分情形下的重疊關(guān)系問題。在類比網(wǎng)絡(luò)安全文本與生物醫(yī)學(xué)文本的領(lǐng)域特性基礎(chǔ)上,本文采用曹明宇等[7]提出的標(biāo)注策略及三元組匹配規(guī)則,在實現(xiàn)網(wǎng)絡(luò)安全實體?關(guān)系聯(lián)合抽取的同時,解決聯(lián)合抽取中部分情形下的重疊關(guān)系問題。
參照曹明宇等[7]的聯(lián)合標(biāo)注策略,本文在進行網(wǎng)絡(luò)安全文本序列標(biāo)注時,標(biāo)簽由實體邊界、實體類別、關(guān)系類別、實體位置共4 個部分組成,具體表示如下。
1) 實體邊界。針對當(dāng)前句子序列,采用“BIOES(B-begin,I-inside,O-outside,E-end,S-single)”模式來標(biāo)識單詞在實體中的位置信息,即B 表示對應(yīng)單詞為實體的開始位置,I 表示對應(yīng)單詞為實體的內(nèi)部,E 表示對應(yīng)單詞為實體的結(jié)束位置,S表示對應(yīng)單詞為單個實體,O 表示對應(yīng)單詞為非實體。
2) 實體類別。分析網(wǎng)絡(luò)安全語料并結(jié)合網(wǎng)絡(luò)安全本體UCO2.0[5],給出10 種實體類別:Organization,Location,Software,Malware,Indicator,Vulnerability,Course-of-action,Tool,Attack-pattern,Campaign。
3) 關(guān)系類別。分析網(wǎng)絡(luò)安全語料并結(jié)合UCO2.0,給出9 種網(wǎng)絡(luò)安全實體語義關(guān)系類別:comes-from,hasProduct,hasVulnerability,mitigates,uses,indicates,attributed-to,related-to,located-at。此外,增加一個M 標(biāo)簽來表示當(dāng)前單詞所屬的實體參與了多種不同類型的關(guān)系[7]。
4) 實體位置。實體位置由數(shù)字“1”“2”來標(biāo)識,“1”表示該實體為三元組中的頭實體,“2”表示該實體為三元組中的尾實體。
圖2 給出了該標(biāo)注策略下的一個示例。輸入序列中包含2 個三元組:(OceanLotus,Comes-From,Vietnam)和(OceanLotus,Uses,watering hole attack),其中Comes-From 和Uses 為預(yù)定義的關(guān)系類別。根據(jù)上述標(biāo)注策略,序列中每個單詞都被賦予相應(yīng)的標(biāo)簽,非實體用O來標(biāo)注。如單詞OceanLotus 為單個詞表示的實體,實體類別為Organization,其同時參與了Comes-From 和Uses 2 種關(guān)系,此類情形屬于重疊關(guān)系。此外,由于OceanLotus 實體在兩類關(guān)系中都處于頭實體的位置,因此其標(biāo)簽為S-Org-M-1。
在對網(wǎng)絡(luò)安全文本輸入序列完成標(biāo)注的基礎(chǔ)上,本文根據(jù)文獻[7]中提出的匹配規(guī)則實現(xiàn)實體與關(guān)系的組合。首先根據(jù)標(biāo)注結(jié)果中的實體邊界和類別得到網(wǎng)絡(luò)安全實體,進而再根據(jù)實體關(guān)系類別和實體位置形成知識三元組。對于實體關(guān)系的確定,則根據(jù)最鄰近原則。當(dāng)實體關(guān)系類別為非M 時,若實體位置標(biāo)識為“1”,則其向后查找與之距離最近、具有相同關(guān)系類別且實體位置標(biāo)識為“2”的實體來組成三元組;若實體位置標(biāo)識為“2”,則其向前查找實體位置標(biāo)識為“1”的能與之匹配的實體。當(dāng)實體關(guān)系類別標(biāo)注為M 時,該實體查找前后2 個方向上能與之匹配的實體,來組成知識三元組。
3.3 表示層和BiLSTM 特征編碼層
本文利用BiLSTM 模型實現(xiàn)對輸入序列的特征編碼,而在此之前需先在表示層將網(wǎng)絡(luò)安全文本轉(zhuǎn)化為低維、稠密的向量表示。為此,本文收集了大量網(wǎng)絡(luò)安全文本語料,包括AlienVault 威脅情報博客、welivesecurity 網(wǎng)絡(luò)安全博客、思科安全威脅類博客、CVE 漏洞描述以及近年來的APT 報告等,并利用word2vec 訓(xùn)練得到100 維的詞向量表示,用于獲取輸入序列詞級別的特征。此外,為進一步加強序列的輸入特征表示,本文采用與文獻[24]中相同結(jié)構(gòu)的CNN 模塊來抽取所輸入的網(wǎng)絡(luò)安全句子序列的字符特征,最后將其與前述所得的詞級別特征拼接后共同輸入模型中。
在此基礎(chǔ)上,利用BiLSTM 模型實現(xiàn)對輸入序列的特征抽取。假設(shè)當(dāng)前時刻輸入向量xt,上一時刻所得隱藏狀態(tài)為ht?1,則在當(dāng)前時刻根據(jù)上下文信息學(xué)習(xí)到的特征可簡要表示為
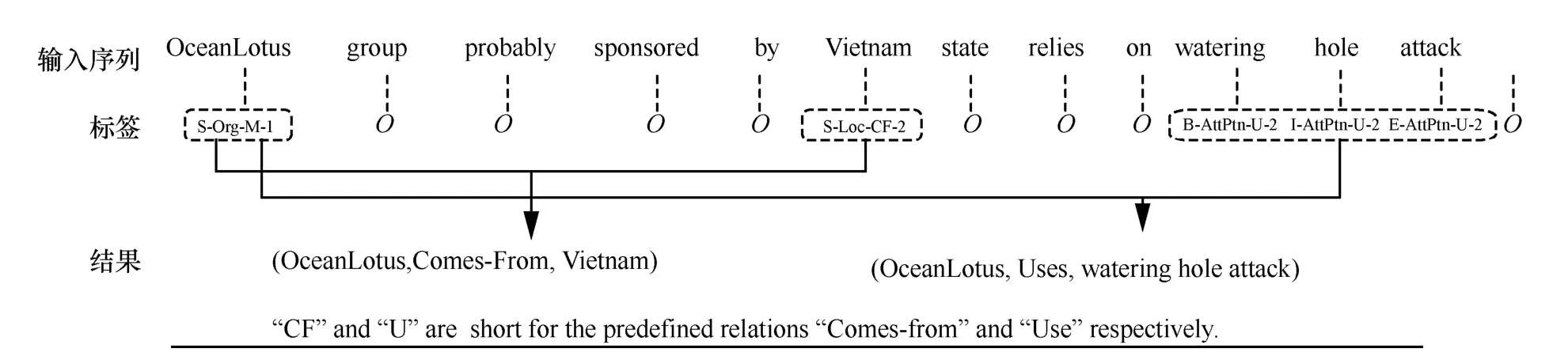
圖2 標(biāo)注策略示例
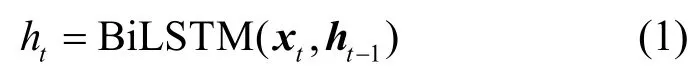
進一步地,H={h1,h2,…,hT}作為BiLSTM 層的輸出,表示對輸入文本序列的特征編碼。
3.4 動態(tài)注意力機制
自注意力機制能夠直接學(xué)習(xí)句子中任意2 個詞之間的依存關(guān)系,并捕獲句子的內(nèi)部結(jié)構(gòu)信息,其在機器翻譯和語義角色標(biāo)注中已得到成功應(yīng)用。Cao 等[25]將自注意力機制用于中文命名實體識別任務(wù)中,使模型性能得到較大提升。具體地,文本序列經(jīng)過 BiLSTM 層編碼后,得到特征向量H={h1,h2,…,hT},則自注意力機制計算過程為

盡管上述注意力機制在序列建模過程中有助于捕獲詞之間的依存性,但對句子中的不同詞而言,其注意力在對序列的上下文權(quán)重影響分配時保持不變,未考慮注意力分布的實際差異。本文借鑒文獻[26]的思路,結(jié)合前述自注意力機制,提出一種動態(tài)注意力機制,以準(zhǔn)確捕獲詞之間的相互影響。在動態(tài)注意力層,t時刻,將BiLSTM 層輸出的特征編碼th與自注意力機制對應(yīng)輸出ta的拼接結(jié)果[ht,at]通過sigmod 函數(shù)進行濾波得到γt,接著進行點乘操作得到εt,并將其作為門控循環(huán)單元(GRU,gated recurrent unit)的輸入,具體計算過程為
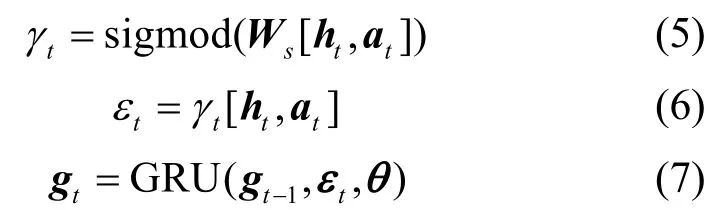
其中,Ws和θ為超參數(shù)矩陣。將G={g1,g2,…,gt}記作動態(tài)注意力層的最終輸出結(jié)果,并將其輸入下層進行解碼。
3.5 LSTM 解碼層
相比于采用CRF 作為標(biāo)簽解碼器,采用LSTM作為解碼器能夠顯著加快模型訓(xùn)練速度,且能夠達到與CRF 相當(dāng)?shù)男阅躘23]。面對序列標(biāo)注時存在的豐富的標(biāo)簽空間,本文參考Zheng等[8]使用的LSTM網(wǎng)絡(luò)作為解碼層以得到標(biāo)簽序列,解碼層LSTM 單元結(jié)構(gòu)如圖3 所示。
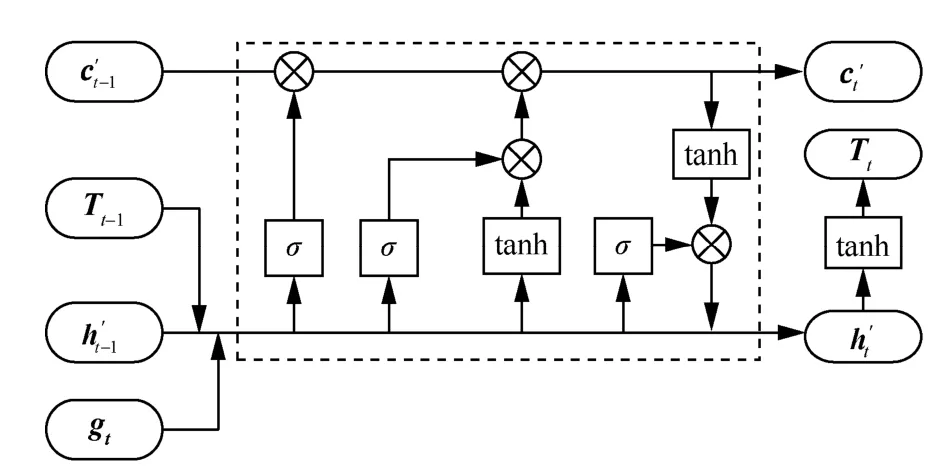
圖3 解碼層LSTM 單元結(jié)構(gòu)
對于當(dāng)前時刻單詞xt,使用LSTM 解碼獲得其標(biāo)簽時,gt表示當(dāng)前時刻從動態(tài)注意力層獲得的向量表示,Tt?1表示上一時刻詞的預(yù)測標(biāo)簽向量,表示上一時刻標(biāo)簽解碼輸出隱狀態(tài),表示上一時刻解碼所得細胞狀態(tài),則LSTM 解碼單元可形式化表示為

其中,σ和tanh 表示非線性激活函數(shù),分別表示LSTM 解碼單元的輸入門、遺忘門和輸出門,表示t時刻的細胞狀態(tài),表示輸出的隱狀態(tài)向量,則tT表示當(dāng)前單詞對應(yīng)的預(yù)測標(biāo)簽的向量。
在獲得預(yù)測標(biāo)簽向量的基礎(chǔ)上,進一步運用softmax 分類器計算標(biāo)簽概率,得到當(dāng)前單詞tx對應(yīng)第i個類別標(biāo)簽的概率為
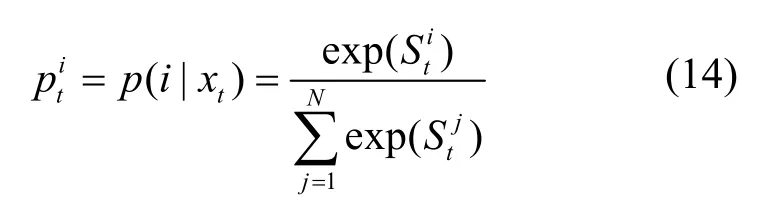
其中,St=WsTt+bs表示當(dāng)前單詞xt在所有標(biāo)簽類別上的評分值,Ws表示softmax 分類器的權(quán)重矩陣,bs表示其偏置項。最終,得到對當(dāng)前單詞xt的預(yù)測標(biāo)簽為

3.6 對抗主動學(xué)習(xí)
不同于傳統(tǒng)的基于不確定性采樣的主動學(xué)習(xí)方式,本文融合對抗學(xué)習(xí)思想來評估標(biāo)記數(shù)據(jù)和未標(biāo)記數(shù)據(jù)間的相似性,提出對抗主動學(xué)習(xí)模式,以此增量地篩選出數(shù)據(jù)進行標(biāo)記。
假設(shè)現(xiàn)有少量已標(biāo)記的數(shù)據(jù)構(gòu)成集合SL,未標(biāo)記的數(shù)據(jù)構(gòu)成集合SU。用sL和sU分別表示標(biāo)記數(shù)據(jù)和未標(biāo)記數(shù)據(jù),則從標(biāo)記數(shù)據(jù)集中選擇樣本記作sL~SL,從未標(biāo)記數(shù)據(jù)集中選擇樣本記作sU~SU。在對抗主動學(xué)習(xí)模塊中,標(biāo)記樣本sL和未標(biāo)記樣本sU首先依次經(jīng)過表示層和BiLSTM 特征編碼層,得到隱層空間的特征向量表示HL和HU。通過訓(xùn)練一個判別器來評估隱空間中特征向量的相似性,而BiLSTM 特征編碼模型則與判別器模型構(gòu)成一個對抗網(wǎng)絡(luò)。在該對抗網(wǎng)絡(luò)中,編碼器BiLSTM 通過特征編碼,盡可能地使判別器誤認為特征向量均來自標(biāo)記數(shù)據(jù)集,而判別器則盡可能地對隱空間中特征向量進行區(qū)分。完成訓(xùn)練后,對于輸入的未標(biāo)記樣本,判別器輸出一個概率值來表示樣本來自兩類數(shù)據(jù)集合的概率,將其記作與標(biāo)記樣本的相似性得分。相似性得分高,表明未標(biāo)記樣本所包含的信息量已經(jīng)在標(biāo)記樣本中有所表達;相似性得分低,表明未標(biāo)記樣本所包含的信息量標(biāo)記樣本未曾包含,該樣本需交專家進行標(biāo)注。將標(biāo)注后的樣本加入標(biāo)簽訓(xùn)練集中,并對前述的聯(lián)合抽取模型重新進行訓(xùn)練。
在對抗主動學(xué)習(xí)模塊中,BiLSTM 特征編碼器類似于對抗網(wǎng)絡(luò)中的生成器模型,其目標(biāo)函數(shù)為最小化如式(18)所示的損失函數(shù)。
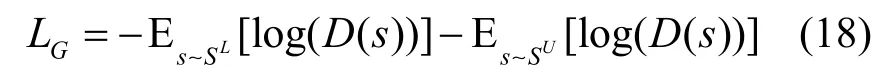
判別器的目標(biāo)函數(shù)為最小化如式(19)所示的損失函數(shù)。
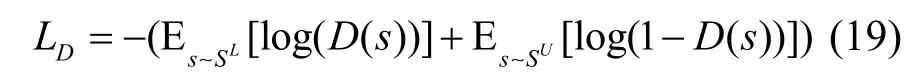
綜合考慮前述聯(lián)合抽取模塊和對抗主動學(xué)習(xí)中編碼器模塊,引入超參數(shù)λ調(diào)整兩類損失函數(shù),可得其在整個模型中的目標(biāo)函數(shù)為

上述對本文模型中聯(lián)合抽取模塊和對抗主動學(xué)習(xí)模塊分別進行了詳細的描述。基于對抗主動學(xué)習(xí)算法增量地篩選出需要標(biāo)注的數(shù)據(jù),將其標(biāo)注后加入標(biāo)簽訓(xùn)練集,并對模型重新進行訓(xùn)練。本文模型實現(xiàn)算法如算法1 所示。
算法1對抗主動學(xué)習(xí)下的網(wǎng)絡(luò)安全知識三元組抽取算法.
輸入初始標(biāo)注訓(xùn)練集SL,未標(biāo)注數(shù)據(jù)集SU
輸出實體?關(guān)系三元組聯(lián)合抽取模型
epoch 從1 到N循環(huán)
1) 選擇標(biāo)記樣本sL~SL
2) 計算式(16)中的目標(biāo)函數(shù)LJE
3) 選擇未標(biāo)記樣本sU~SU
4) 計算式(18)中的目標(biāo)函數(shù)LG
5) 最小化式(20)中的目標(biāo)函數(shù)L來更新參數(shù)θJE和θG
6)最小化式(19)中的目標(biāo)函數(shù)LD來更新參數(shù)θD
7)計算所選樣本sU和sL間的相似性得分,并標(biāo)注得分較低的樣本
8) 將新標(biāo)注樣本添加到標(biāo)注訓(xùn)練集SL
結(jié)束循環(huán)
4 實驗
4.1 實驗設(shè)置
本文實驗所使用的數(shù)據(jù)語料采集自兩部分:1)針對SemEval 2018 Task 8 發(fā)布的網(wǎng)絡(luò)安全語料,從中篩選得到500 條涉及惡意軟件行為和屬性的句子作為初始訓(xùn)練語料,另外篩選出1 464 條句子作為測試語料,并按照前文所述聯(lián)合標(biāo)注策略進行標(biāo)注;2) 從AlienVault 社區(qū)、welivesecurity 社區(qū)、Amazon 安全博客以及近兩年的APT 報告中篩選得到7 425 條威脅情報語句,標(biāo)注后添加到訓(xùn)練集,用于對抗主動學(xué)習(xí)模型的性能測試。此外,為比較聯(lián)合抽取模型與流水線模型的性能,針對上述所采集的語料,單獨構(gòu)建了流水線模式中用于命名實體識別和實體關(guān)系抽取的標(biāo)簽數(shù)據(jù)集。
本文在評價網(wǎng)絡(luò)安全實體?關(guān)系三元組聯(lián)合抽取結(jié)果時,類比文獻[7]中對藥物實體?關(guān)系三元組識別結(jié)果的判斷方式可得,若網(wǎng)絡(luò)安全實體邊界及其類別均被模型標(biāo)記正確,則認為實體識別結(jié)果正確;若網(wǎng)絡(luò)安全實體邊界、實體類別及所屬關(guān)系類別均被模型標(biāo)記正確,則判定關(guān)系抽取結(jié)果正確。針對網(wǎng)絡(luò)安全實體?關(guān)系聯(lián)合抽取性能的評價,本文采用信息抽取任務(wù)中通用的評價指標(biāo),即通過準(zhǔn)確率P(precision)、召回率R(recall)以及F1 值(F1-score)3 項指標(biāo)來評價聯(lián)合抽取模型的性能,并將F1 值作為評價模型性能的綜合性指標(biāo)。本文模型涉及的主要超參數(shù)如表1 所示。

表1 本文模型涉及的主要超參數(shù)
4.2 序列標(biāo)注模型性能對比實驗
由于本文將實體與關(guān)系的抽取聯(lián)合建模為序列標(biāo)注任務(wù),本節(jié)將所提聯(lián)合標(biāo)注模型與NLP 領(lǐng)域典型的序列標(biāo)注模型進行比較,包括CRF 模型、BiLSTM-CRF 模型、基于自注意力機制的BiLSTMCRF 模型、基于自注意力機制的BiLSTM-LSTM 模型,并查看使用字符特征與否對模型性能的影響。將上述所列模型在完整的標(biāo)簽訓(xùn)練集上訓(xùn)練后評估模型性能,實驗結(jié)果如表2 所示。表2 中“○”表示對應(yīng)模型使用了字符級的嵌入特征,“×”表示模型未使用該特征。
在完整標(biāo)簽訓(xùn)練集上完成訓(xùn)練后,相比幾類典型的序列標(biāo)注模型,本文所提融合動態(tài)注意力機制的BiLSTM-LSTM 模型在實體與關(guān)系聯(lián)合標(biāo)注任務(wù)上性能最優(yōu),取得了64.57%的F1 值。通過比較可以看出,相較于單一使用CRF模型,在增添BiLSTM網(wǎng)絡(luò)進行特征獲取后,模型性能得到提升,其原因可能是BiLSTM 在一定程度上解決了序列建模過程中的長距離依賴問題,在識別過程中能夠有效利用上下文信息。從表2 中可以看出,由于字符更關(guān)注詞本身的特征,在添加字符級別的嵌入特征后,BiLSTM-CRF 模型性能得到進一步的提升,其F1值增加了1.6%,表明增加字符向量對于序列標(biāo)注的重要性。在此基礎(chǔ)上,再向BiLSTM-CRF 模型添加自注意力機制Self-att,BiLSTM-CRF 模型性能進一步得到提升。通過對比可以得出,模型性能得到提升的原因可歸結(jié)為Self-att 機制的運用,其通過捕獲詞之間的依存性,使所抽取的文本特征進一步得到增強,進而使模型識別性能得到提升。此外,再將自注意力機制下BiLSTM-CRF 模型中的解碼器由CRF 更換為LSTM 網(wǎng)絡(luò)。可以看出,兩者性能基本保持一致,表明LSTM 解碼能夠達到與傳統(tǒng)CRF 模型相當(dāng)?shù)男ЧG矣捎谠趶?fù)雜標(biāo)簽空間中,LSTM 解碼優(yōu)于CRF 模型,模型F1 值有0.13%的微小提升。最后,將自注意力機制替換為本文的動態(tài)注意力機制,由于考慮了自注意力權(quán)重分布的差異性,模型性能在F1 值上增加了1.46%,同時也證明本文所設(shè)計的動態(tài)注意力機制是有效的。
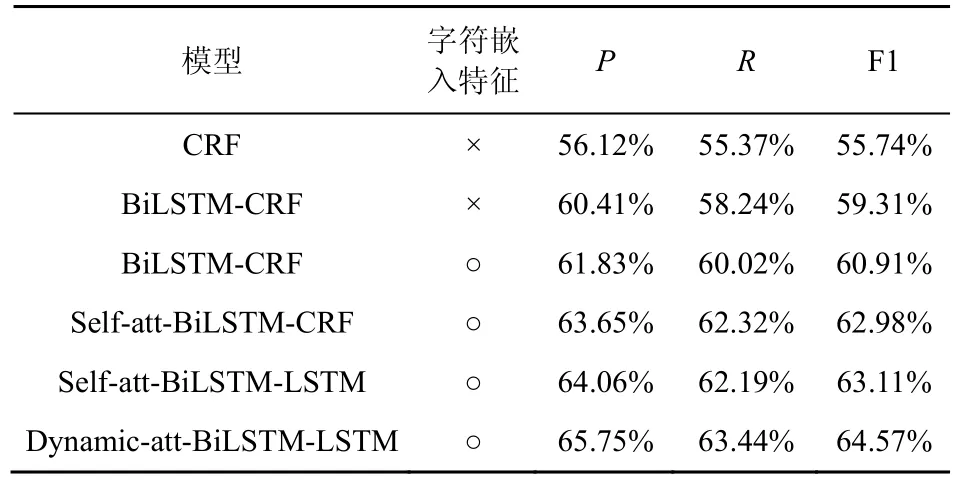
表2 模型性能比較
4.3 三元組抽取方法對比
如前文所述,當(dāng)前知識三元組的抽取主要分為基于先識別實體、后抽取關(guān)系的流水線框架,以及實體與關(guān)系的聯(lián)合抽取方法。本節(jié)利用典型的流水線框架與聯(lián)合抽取方法對網(wǎng)絡(luò)安全知識三元組的抽取性能進行比較。
針對傳統(tǒng)的流水線框架,首先需要識別網(wǎng)絡(luò)安全語料中的命名實體,采用傳統(tǒng)方法中廣泛使用的BiLSTM-CRF 模型作為序列標(biāo)注工具來識別實體。在獲得實體識別結(jié)果的基礎(chǔ)上,對于網(wǎng)絡(luò)安全語義關(guān)系抽取任務(wù),本文分別采用端到端的 Att-PCNN_BiLSTM 模型[28]以及融合句法特征的SDP-LSTM 模型[29]進行關(guān)系分類。針對聯(lián)合抽取方法,除本文提出的聯(lián)合抽取模型外,還采用傳統(tǒng)基于參數(shù)共享的聯(lián)合抽取方法,包括性能較好的BiLSTM_Bi-TreeLSTM 模 型[30]以 及 BiLSTMCRF-Multi_head 模型[31]。實驗對比結(jié)果如表3 所示。
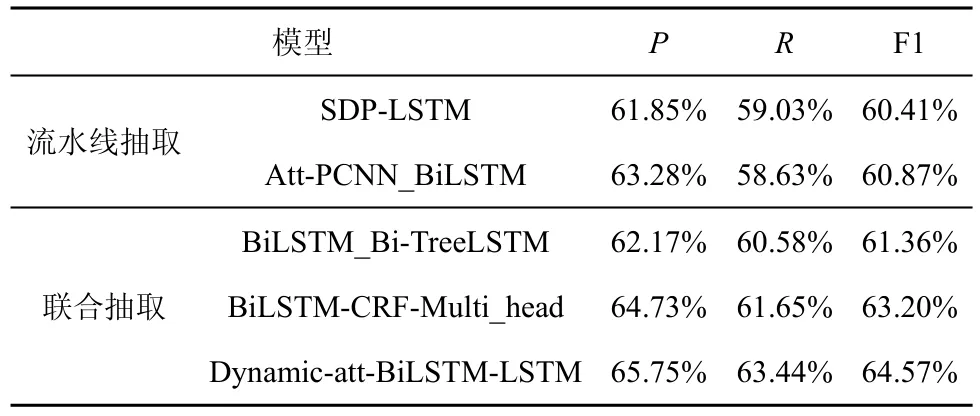
表3 三元組抽取方法比較
通過表3 可以看出,本文提出的融合了動態(tài)注意力機制的BiLSTM-LSTM 模型在知識三元組抽取任務(wù)上表現(xiàn)出最優(yōu)的性能,取得了64.57%的F1 值。本文方法直接實現(xiàn)實體與關(guān)系端到端的聯(lián)合抽取,其有效利用了實體識別和關(guān)系抽取任務(wù)間的語義聯(lián)系,相較于流水線方式中性能較好的關(guān)系分類模型,模型性能有較大提升,表現(xiàn)為F1 值增加了3.7%。相較于基于參數(shù)共享的聯(lián)合抽取模型,本文的聯(lián)合抽取方法性能也更優(yōu),評估后發(fā)現(xiàn)F1 值比BiLSTM-CRF-Multi_head 模型提升了1.37%。雖然基于參數(shù)共享的聯(lián)合抽取方法也取得了不錯的效果,但由于其本質(zhì)上還是先識別實體、后識別關(guān)系,仍然存在一定程度的錯誤傳播與冗余信息。而本文提出的聯(lián)合抽取模型,基于對實體與關(guān)系的聯(lián)合標(biāo)注策略,隱式地考慮了實體識別與關(guān)系抽取任務(wù)間的聯(lián)系,表現(xiàn)出更優(yōu)的性能。
4.4 三元組抽取實例分析
4.3 節(jié)對比了幾類知識三元組抽取方法,相較于流水線模式以及傳統(tǒng)的聯(lián)合抽取方法,本文模型整體上表現(xiàn)更佳。本節(jié)進一步查看傳統(tǒng)流水線的Att-PCNN_BiLSTM 模型、BiLSTM-CRF-Multi_head聯(lián)合抽取模型以及本文聯(lián)合抽取模型對網(wǎng)絡(luò)安全知識三元組的抽取效果。示例結(jié)果如表4 所示,“[]”加粗表示能夠正確識別的實體,“”下劃線表示未能被識別的實體,實體下標(biāo)標(biāo)識了該實體所屬的關(guān)系類別。
針對示例1 中的網(wǎng)絡(luò)安全句子序列,相較于標(biāo)準(zhǔn)的抽取結(jié)果,所用的三類模型均能夠正確識別出相應(yīng)的實體及其類別。然而,對于流水線框架,基于此實體識別結(jié)果進行關(guān)系預(yù)測時,其將實體對間原本的語義關(guān)系“hasVulnerability”錯誤地分類為關(guān)系“uses”,此結(jié)果可能由于未考慮實體識別與關(guān)系抽取任務(wù)間的聯(lián)系所致。而兩類聯(lián)合抽取模型則準(zhǔn)確地表達了其語義關(guān)系。
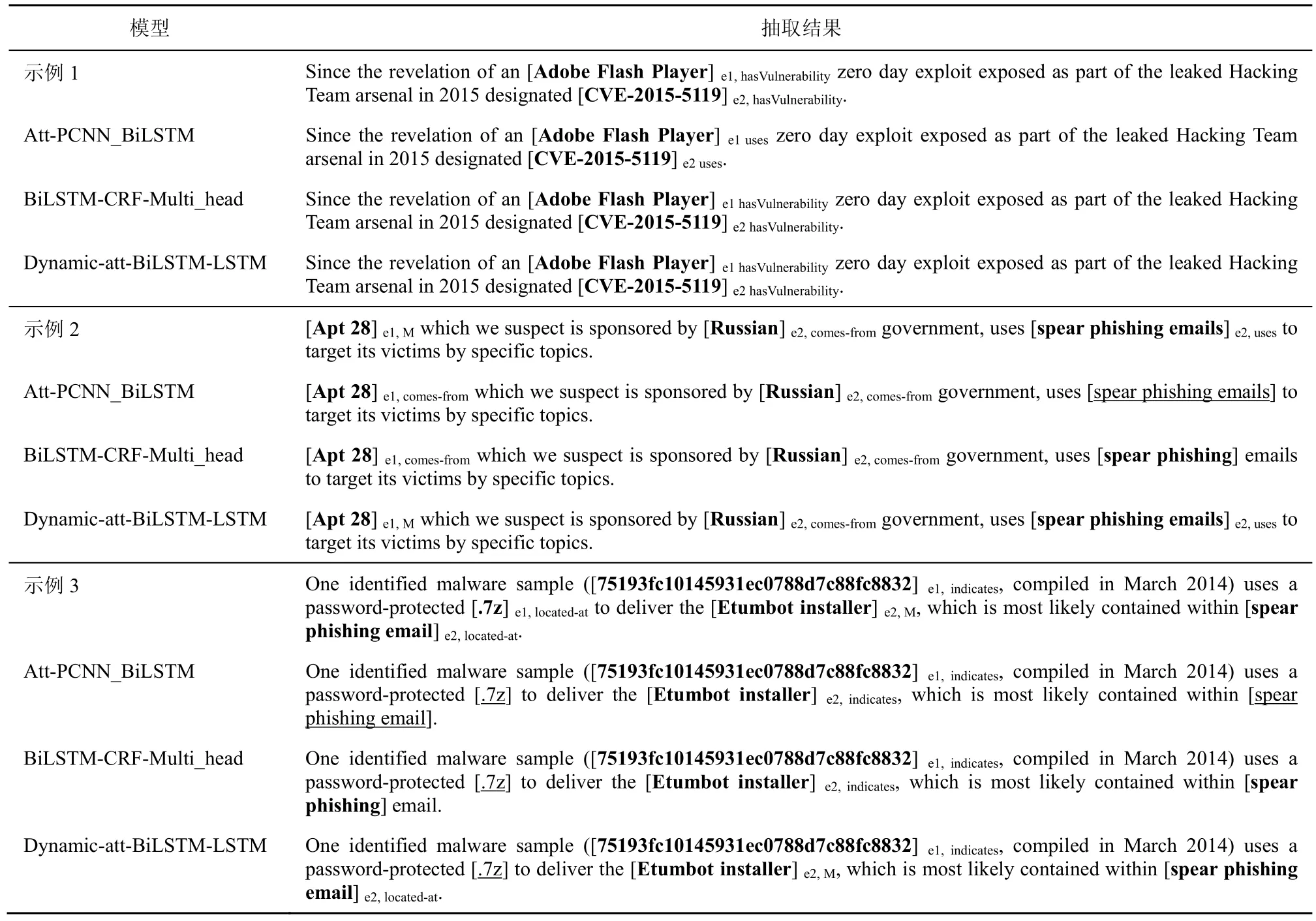
表4 三元組抽取結(jié)果示例
針對示例2,標(biāo)準(zhǔn)抽取結(jié)果應(yīng)該含有3 個實體,且實體“APT 28”參與了多重關(guān)系,對于此標(biāo)注結(jié)果,本文模型在準(zhǔn)確識別實體的同時還能準(zhǔn)確表達所有實體的關(guān)系類別。在流水線框架中,其未能識別出實體“spear phishing emails”。而基于參數(shù)共享的聯(lián)合抽取模型,對于實體“spear phishing emails”的識別出現(xiàn)邊界錯誤,且其無法處理重疊關(guān)系問題。
針對示例3,標(biāo)準(zhǔn)抽取結(jié)果理應(yīng)包含4 個相關(guān)實體,而三類模型均未能準(zhǔn)確識別出這些實體。對于流水線框架,其在實體識別時就產(chǎn)生較大的誤差,相應(yīng)地也只表達了惡意軟件及其指示器之間的“indicates”關(guān)系。對于基于參數(shù)共享的聯(lián)合抽取模型,其未能識別實體“.7z”,且實體“spear phishing email”邊界識別有誤,其三元組抽取結(jié)果也只表達了“indicates”關(guān)系。對于本文模型,雖然只遺漏了實體“.7z”,但其對實體“spear phishing email”的實體位置標(biāo)注錯誤,導(dǎo)致其在組成三元組時未能被匹配,由此說明本文方法在實體與關(guān)系的聯(lián)合識別中還有待改進與優(yōu)化。
4.5 對抗主動學(xué)習(xí)算法性能評估
為驗證本文所提對抗主動學(xué)習(xí)模塊的有效性,分別以完整的標(biāo)簽訓(xùn)練集和通過對抗主動學(xué)習(xí)篩選獲得的訓(xùn)練集來評估本文實體與關(guān)系聯(lián)合抽取模型的性能,評估結(jié)果如表5 所示。可以看出,隨著標(biāo)注數(shù)據(jù)量的增加,模型整體性能不斷提升。當(dāng)獲得全部標(biāo)注數(shù)據(jù)的45%,并對模型重新進行訓(xùn)練時,模型性能與使用完整標(biāo)簽訓(xùn)練集訓(xùn)練后的模型性能已經(jīng)非常接近,證明了本文所提對抗主動學(xué)習(xí)算法的有效性。
此外,將本文提出的對抗主動學(xué)習(xí),與常規(guī)的主動學(xué)習(xí)算法進行比較,包括最小置信度(LC,least confidence)算法、貝葉斯非一致主動學(xué)習(xí)(BALD,Bayesian active learning by disagreement)以及最大歸一化對數(shù)概率(MNLP,maximum normalized log-probability)算法。運用各模型逐次篩選得到不同規(guī)模的標(biāo)簽數(shù)據(jù),并評估模型性能,結(jié)果如圖4所示。相比之下,本文所提對抗主動學(xué)習(xí)模型表現(xiàn)出最優(yōu)的性能。而基于LC 的主動學(xué)習(xí)算法性能最差,其原因是LC 算法在采樣時通過序列標(biāo)注模型的輸出來計算不確定性,而復(fù)雜的標(biāo)簽空間導(dǎo)致其采樣準(zhǔn)確性較差。MNLP 算法和BALD 算法雖然在主動采樣時對模型不確定性的計算進行了一定的優(yōu)化,但其性能仍受到標(biāo)簽空間的影響。不同于復(fù)雜的不確定性計算,本文所提對抗主動學(xué)習(xí)算法通過直接比較未標(biāo)記數(shù)據(jù)和標(biāo)記數(shù)據(jù)的相似性進行采樣,在降低計算復(fù)雜度的同時提高了模型采樣的準(zhǔn)確率,其可實現(xiàn)以相對較低的數(shù)據(jù)標(biāo)注代價來逐步提升三元組抽取效果。
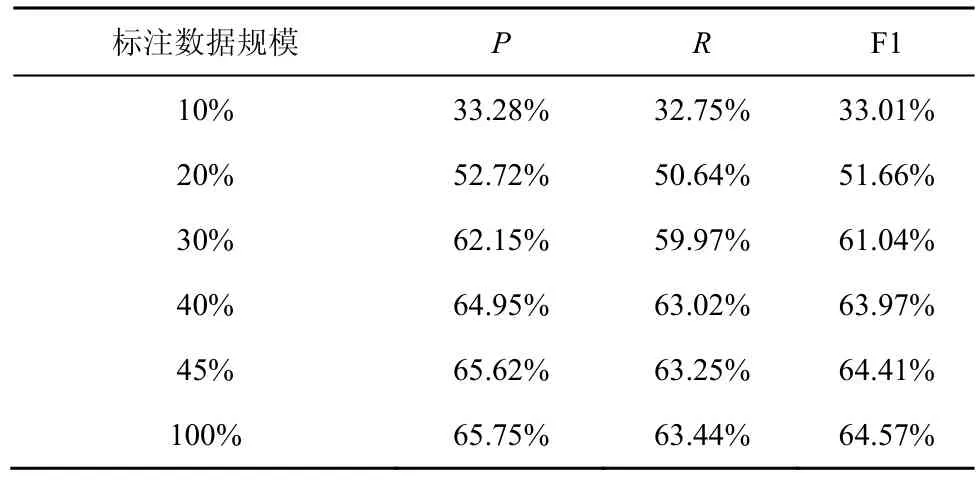
表5 不同規(guī)模標(biāo)注數(shù)據(jù)下的性能比較
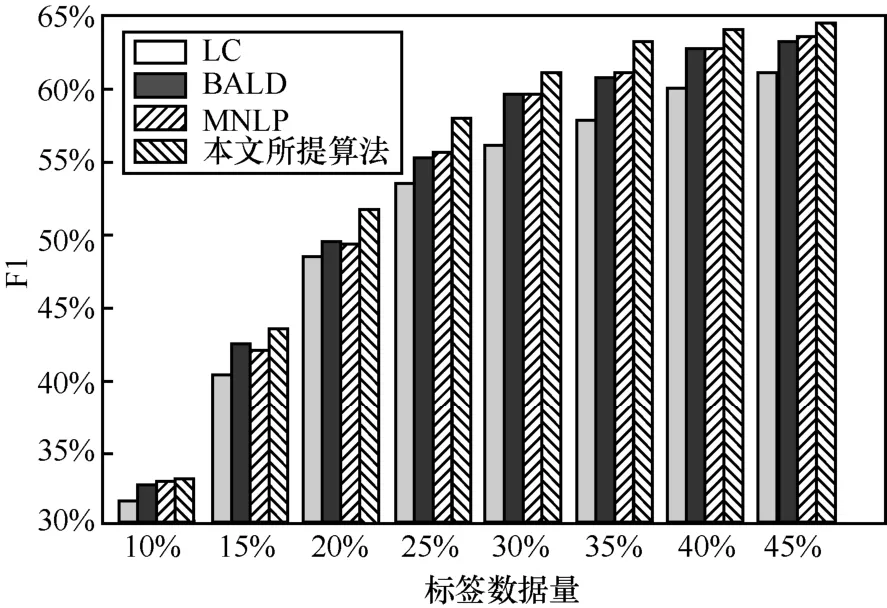
圖4 主動學(xué)習(xí)算法性能對比
5 結(jié)束語
為實現(xiàn)面向網(wǎng)絡(luò)安全領(lǐng)域知識三元組的抽取,本文提出了一種融合對抗主動學(xué)習(xí)的網(wǎng)絡(luò)安全實體與關(guān)系聯(lián)合抽取模型。對于當(dāng)前網(wǎng)絡(luò)安全領(lǐng)域知識抽取流水線模式存在的問題,提出基于聯(lián)合標(biāo)注策略將實體識別與關(guān)系抽取同時建模為一個序列標(biāo)注任務(wù),通過BiLSTM 網(wǎng)絡(luò)對輸入序列進行特征編碼,并基于動態(tài)注意力機制準(zhǔn)確捕獲詞之間的影響權(quán)重,在此基礎(chǔ)上利用LSTM 對標(biāo)簽進行解碼預(yù)測。此外,針對網(wǎng)絡(luò)安全領(lǐng)域標(biāo)簽數(shù)據(jù)缺乏的問題,提出基于對抗主動學(xué)習(xí)框架,評估標(biāo)記樣本與未標(biāo)記樣本間的相似性得分,篩選出高質(zhì)量的樣本進行標(biāo)注,實現(xiàn)以較低的標(biāo)注代價來提升模型性能。實驗驗證了本文所提對抗主動學(xué)習(xí)框架的有效性,并對比已有網(wǎng)絡(luò)安全實體與關(guān)系抽取模型,表明本文所提序列標(biāo)注模型的性能更優(yōu)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
中國生殖健康(2019年10期)2019-01-07 01:21:04
信息安全研究(2018年12期)2018-12-29 11:01:46
電子制作(2018年18期)2018-11-14 01:48:06
小學(xué)生必讀(中年級版)(2018年4期)2018-07-05 06:00:48
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
