基于Mahout的相似重復數據清洗策略研究*
2020-10-24 03:00:10李碧秋王佳斌
科技與創新 2020年20期
李碧秋,王佳斌
基于Mahout的相似重復數據清洗策略研究*
李碧秋,王佳斌
(華僑大學 工學院,福建 泉州 362021)
針對在海量日志記錄中無法有效抽取高價值的數據問題,提出一種基于Mahout的k-means短文本聚類清洗算法,利用開源機器學習算法庫Mahout,將文本聚類與數據清洗相結合,通過聚類檢測相似重復記錄,有效提升重復數據清洗速率。實驗結果表明,該方法在保證較高查全率與查準率的同時,比傳統相似重復數據清洗算法更具有擴展性,這對大數據的處理有較強的實用意義。
數據清洗;k-means;相似重復記錄;文本聚類
1 引言
在信息爆炸的大數據時代,大數據系統已被許多領域廣泛采用,提供有效的數據解決方案。大數據系統產生大量的非結構化日志,其中隱藏了許多有價值的信息。但是僅注意數據分析而不重視數據質量問題可能會使研究或分析變得毫無意義,甚至導致災難性的后果。因此,對于大數據分析和挖掘,數據質量起著關鍵作用,數據清理是保證數據質量的強大工具。目前,對大數據的數據清理包括保證數據一致性和完整性、實體標識、數據預處理等,其中針對冗余數據的檢測與刪除具有顯著的優勢,可以減少冗余數據的存儲與不必要的網絡帶寬,提高系統的可伸縮性。傳統的重復數據清洗主要是針對結構化數據在本地處理,這種方法已經不能滿足海量待處理數據的需求,而Hadoop作為一種著名的開源大數據編程框架,為人們提供了分布式存儲和分布式計算技術,已經被應用于谷歌、Facebook、騰訊、阿里巴巴等大型互聯網公司。其生態圈的組件之一Mahout集成了多種聚類、分類等算法,為人們更好地處理大數據提供了可能。
2 相關知識介紹
2.1 Mahout介紹
Apache Mahout是Apache Software Foundation(ASF)旗下的一個開源項目,針對大規模數據集提供了一些可伸縮的機器學習領域經典算法的實現,Apache Mahout的算法通常運行在Apache Hadoop平臺下,它通過MapReduce模式實現。MapReduce計算框架如圖1所示。
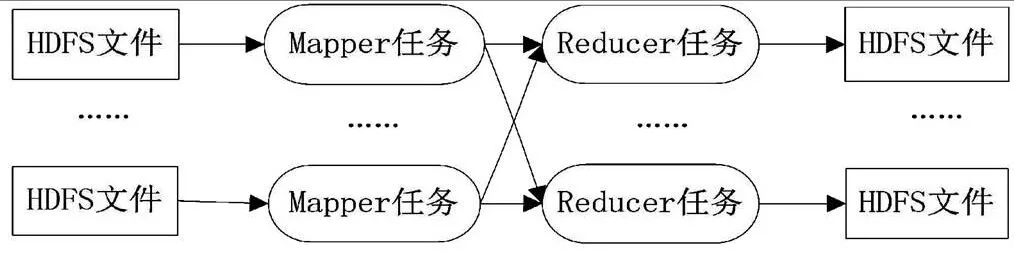
圖1 MapReduce計算框架
Mahout集成的算法包括聚類、分類、推薦過濾、頻繁子項挖掘等,也提供了很多處理數據、提取特征、訓練算法模型的類和方法在具體的項目中,用戶根據實際需求在Mahout源代碼基礎上進行二次開發以滿足具體的實際應用情況。Mahout腳本通過調用Hadoop在分布式平臺運行或調用jre在本地運行,然后調用Mahout工程的總入口org.apache.mahout.driver.MahoutDriver類。Mahout啟動的總入口流程如圖2所示。
以k-means聚類算法為例,Mahout利用Hadoop實現數據挖掘算法并行化實驗框架,如圖3所示。
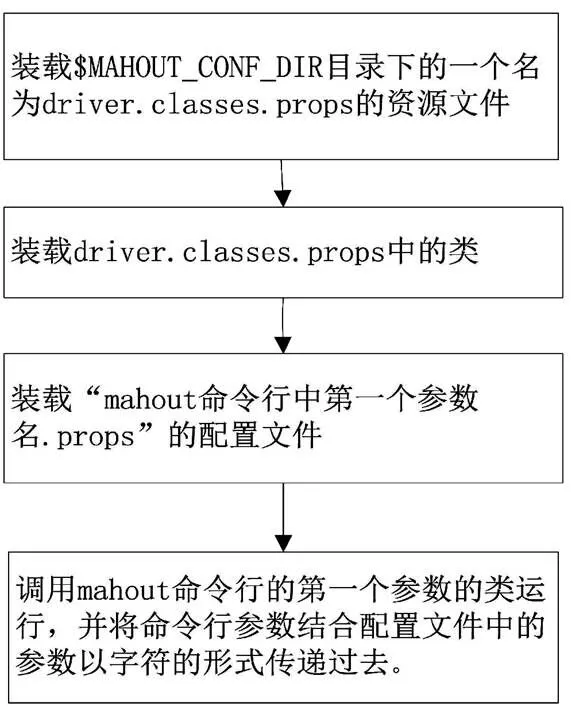
圖2 Mahout啟動流程
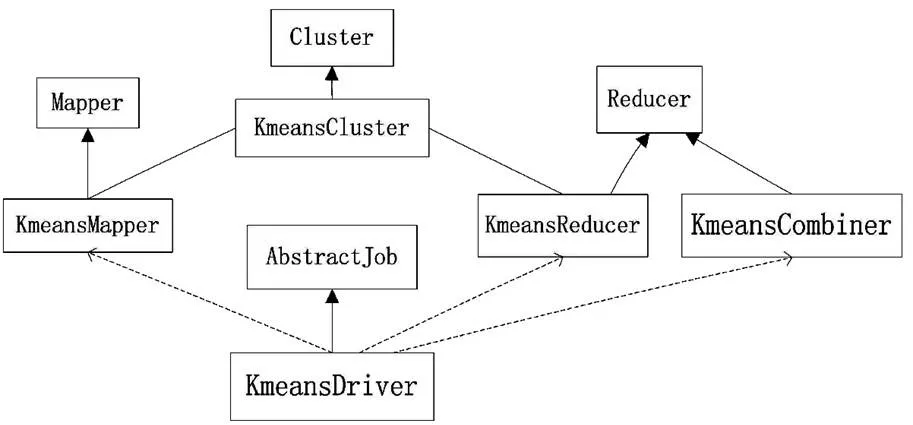
圖3 k-means的Mahout實現框架
2.2 相似重復數據清洗概述
數據清洗是識別和消除數據噪聲的過程,數據清洗關注數據實例層面的問題,主要集中在幾個方面:相似重復記錄消除、缺失數據處理、異常數據處理、不一致數據處理等[1]。
傳統的相似重復數據清洗主要是針對結構化數據,有以下幾種經典算法:基于排序合并的近鄰排序算法SNM、多趟近鄰排序算法MPN、R樹建索引、機器學習等。
隨著處理數據的種類逐漸多樣化,針對web文本的相似重復記錄檢測研究很快發展起來:文獻[2]提出了一種用于估計文檔之間相似程度的技術[2],這種技術稱為“帶狀拼寫”,它不依賴于任何語言知識,而是具有將文檔標記成單詞列表的能力,也就是說,它僅僅是句法上的。文獻[3]提出了一種對Web文檔執行復制檢測的新方法確定相似的Web文檔,以圖形方式捕獲任意兩個Web文檔中的相似的句子[3]。除了處理范圍廣泛的文檔外,這種復制檢測方法還適用于不同主題領域的Web文檔,因為它不需要靜態單詞列表。上述學者對特定領域的大數據清洗方法進行了研究,但仍然缺乏通用的大數據清洗方法。
當已知淺部地層剖面、地震數據及測井資料時,可通過地層剖面大致確定淺層氣的范圍及深度,提取地震屬性來對淺水流進行識別,結合測井資料進行驗證及校核。某深水井測井曲線見圖3。
2.3 k-means聚類算法與canopy聚類算法
k均值聚類算法是由STEINHAUS在1955年、LIOYED在1957年、BALL和HALL在1965年在各自的科學領域獨立提出的[4]。k-means是一種最簡單的無監督學習方法,是求解聚類問題的一種簡單迭代方法,可以找到局部最優解。在分區聚類中,k-means算法的主要目標是確定每個聚類的最合適的中心。
k-means聚類算法的主要步驟如圖4所示。
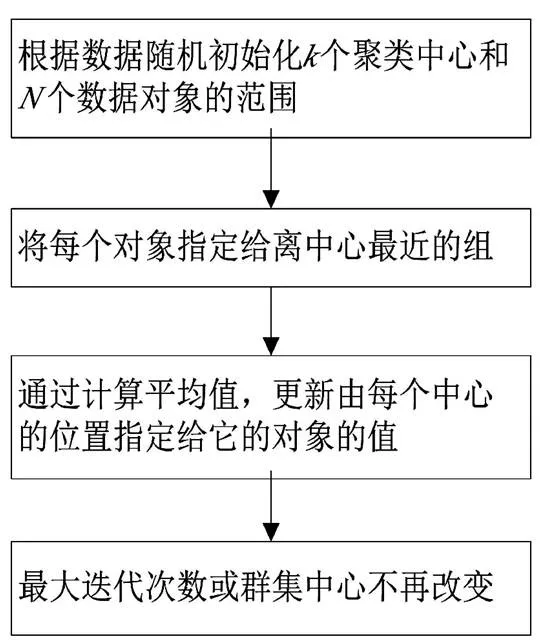
圖4 k-means算法流程
canopy聚類算法是一種粗聚類算法,不能準確地對給定數據集中的每個數據對象進行分類。該算法使用一種簡單、快捷的距離計算方法將數據集分為若干可重疊的子集canopy,這種算法不需要指定值,但精度較低。canopy算法流程如圖5所示。
依賴聚類思想實現相似重復數據清洗,主要是將數據集中由于多源異構數據庫集成導致的不一致記錄識別出來,并清洗掉多余記錄,如華僑大學與華大,傳統算法認為這是兩條不相同的記錄,但是利用k-means聚類,可以將其識別為標識同一個地址的相似記錄并聚類到一個簇中,從而檢測冗余并刪除重復的一項,以使存儲空間擁有最大有效利用率。
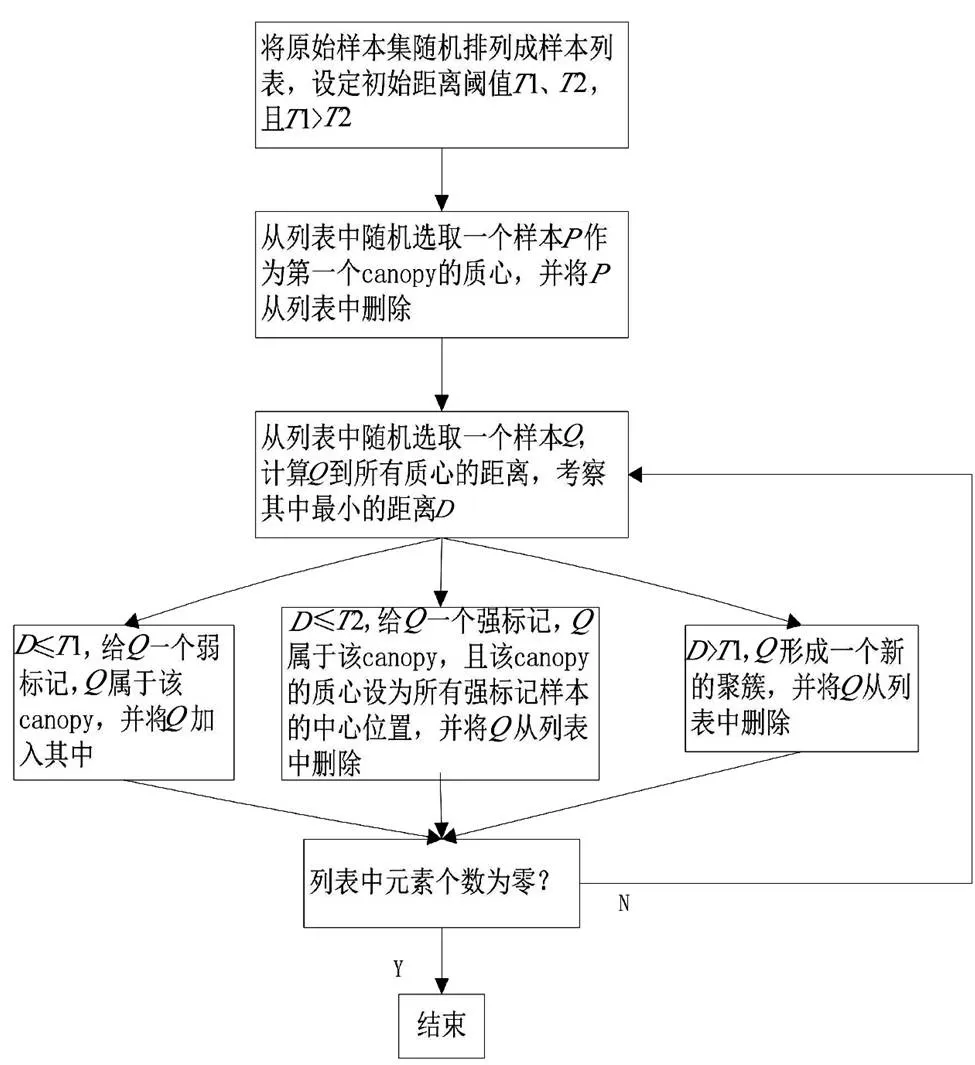
圖5 canopy算法流程
3 基于mahout的相似重復記錄清洗算法
3.1 實驗環境
本實驗搭建的Hadoop集群由3個節點組成,其中有1個Master節點,2個Slave節點,每個節點采用的服務器配置如下:芯片型號為Intel (R) Xeon (R) CPU E5-2407@2.20 GHz,內核個數為4,運行內存大小為8 GB,硬盤大小為12 TB,操作系統采用CentOS 7.5,Hadoop版本使用Hadoop2.6。
3.2 實驗過程
本實驗的數據來源是某仿真程序的運行日志記錄,一個日志文件包含14萬條記錄,總共10個日志文件,140萬條記錄。
前文已經提到,即使k-means算法的復雜度呈線性,適合大數據的處理,但是該算法仍然受到初始值的個數與位置的影響,不同的的取值會得到不同的聚類結果。而且在大數據背景下,很難知道聚類的個數。對于該類問題通常有兩種解決辦法,一種是在所給的數據集里取樣,隨機選擇小數據量,在小數據量范圍內預估類簇數的值,這種方法簡單,但是會受到取樣方法的影響,不能覆蓋全部數據類型的取樣數據預估的值會嚴重偏離真實值,從而影響整體聚類效果。基于此,本文先利用canopy得到個聚類中心,之后基于Mahout執行k-means聚類時不再人為指定的個數,而是直接選用canopy的結果,這就避免了主觀判斷的失誤,大大提高了聚類精度。實驗流程如圖6所示。詳細步驟如下。
預處理過程將獲取到的日志文件編碼通過iconv -f gbk -t utf8 20200628.log命令改為Linux系統可處理的utf-8形式,將每個文件中的每行日志分割成一個小文件,暫存至本地。

圖6 實驗流程
使用內置的seqdirectory命令,完成文本目錄到SequenceFile的轉換過程。mahout seqdirectory -i 輸入文件路徑 -o 輸出文件路徑 -c utf-8 -chunk 64 -xm sequential,轉化后的文件類型變成二進制文件。
將序列文件轉化為向量文件,mahout seq2sparse -i /user/root/20200705-seq -o /user/root/20200705-sparse -ow --weight tfidf --maxDFPercent 85 –namedVector。
該過程完成文本分詞、抽取特征、生成字典,利用詞頻逆文檔頻率計算特征權重,生成文檔詞矩陣。這個過程會生成7個文件,分別是df-count、dictionary.file-0、frequency.file-0、tf-vectors、tfidf-vectors、tokenized-document、wordcount。
接下來,進行相似重復數據聚類的實現:①執行canopy算法。mahout canopy -i /user/root/clean3-ck/log-sparse/tfidf- vectors -o /user/root/clean3-ck/canopy-output-0.76-0.38 -dm org.apache.mahout.common.distance.CosineDistanceMeasure -t1 0.76 -t2 0.38 -ow,其中-i為輸入數據路徑,-o為輸出數據路徑,-dm為算法采用的距離計算公式,-t1取t2*2,-t2取所有文檔之間的平均距離,-ow為重寫之前的結果。②執行k-means算法。mahout kmeans -i /user/root/clean3-ck/log- sparse/tfidf-vectors -c /user/clean3-ck/canopy-output-0.76-0.38/ clusters-0-final -o /user/coder4/reuters-kmeans-dmorg.apache. mahout.common.distance.CosineDistanceMeasure -x 200 -ow --clustering,其中-i為輸入數據路徑,-o為輸出數據路徑,-c為聚類中心,-dm為算法采用的距離計算公式,-x為最大迭代次數,--clustering為以map-reduce模式運行。
執行結束會生成聚類中心clusterdPoints以及聚類結果clusters-k-final,文檔被聚到的類簇,如圖7所示。mahout seqdumper -i /user/root/cleans/output/clusteredPoints/。
從圖7可以發現,100000.txt、100001.txt、100002.txt、100003.txt、100004.txt都被聚類到4419號類里。原文本內容如圖8所示,可以發現上述聚類結果正確率為100%。
4 實驗結果與分析
本實驗分別從查準率、查全率、1值說明本實驗的實驗效果。
假設(true positive)代表實際上是重復的記錄同時也被預測為重復記錄;(false positive)代表實際上是非重復記錄但被預測為重復記錄;(true negative)代表實際上是非重復記錄,同時也被預測為非重復記錄;(false negative)代表實際上是重復記錄,但被預測為非重復記錄,+++=測試數據總數。

圖7 聚類結果
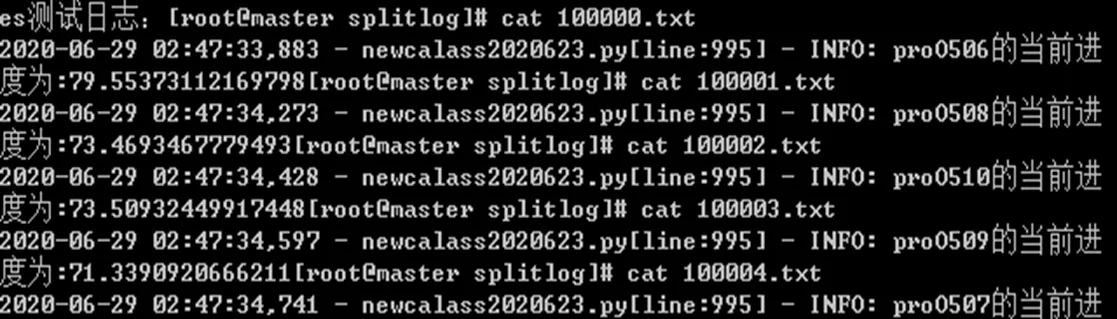
圖8 4419號類簇數據集
4.1 查準率
查準率(Precision)指預測為重復的樣例中有多少是真正的重復樣例,計算公式為:

對隨機選擇的10 000、20 000、40 000、80 000、100 000、120 000條記錄的實驗結果進行分析,結果如表1所示。
4.2 查全率
查全率(Recall)指樣本中的重復記錄有多少被檢測出來,計算公式為:
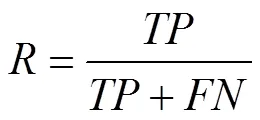
結果如表2所示。
表1 查準率結果
記錄數10 00020 00040 00080 000100 000120 000 查準率74.1%79.32%81.76%81.99%83.1%85%
表2 查全率結果
記錄數10 00020 00040 00080 000100 000120 000 查全率89.09%90.7%90.1%90.98%92.01%94%
從上述結果可以看出,本實驗有較好的查全率,但是查準率略有不足,這是因為查全率和查準率是一對矛盾的度量,為了獲取更高的查全率,相似度的閾值會降低,以便將所有可能相似的記錄都檢測出來,只有這樣,才有更大把握得到真正的重復記錄。同理,若想得到很高的查準率,那么可能會漏掉許多相似度不那么高的記錄,從而查全率降低。通常情況下,用1度量尋找兩者之間的平衡,1度量是加權調和平均,計算公式為:

該值在查全率與查準率上給予了相同的權重,它在一定程度上表征了算法在查全率與查準率上同時取得最優值的比例。通過計算得知1值,如表3所示。
表3 值
記錄數10 00020 00040 00080 000100 000120 000 F10.8090.8460.8570.8630.8730.893
以上結果說明該實驗有相對較好的相似重復數據檢測效率。
5 結語
本文闡述了數據清洗在數據應用方面的重要地位,介紹了大數據背景下的分布式存儲與分布式計算框架,詳細描述了基于mahout的聚類算法檢測相似重復數據的實驗過程,該實驗結果表明,聚類算法可以有效地檢測相似重復記錄,
為大量非結構化的文本數據清洗提供了解決方案,為后續數據挖掘奠定了重要基礎。
[1]郭志懋,周傲英.數據質量和數據清洗研究綜述[J].軟件學報,2002(11):2076-2082.
[2]KHADER M,HADI A,AI-NAYMAT G.HDFS file operation fingerprints for forensic investigations[J]. Digital Investigation,2018(5):50-61.
[3]SVEC P,CHYLO L,FILIPIK J.Web Log data preprocessing using raspberry pi cluster and hadoop cluster DIVAI 2018[C]//12th International Scientific Conference on Distance Learning in Applied Informatics,2018.
[4]Bigdata-based anomaly detection technology in web services environment[J].Asia-pacific Journal of Multimedia Services Convergent with Art,Humanities,and Sociology,2018,4(8):231-250.
2095-6835(2020)20-0015-04
TP311.13
A
10.15913/j.cnki.kjycx.2020.20.005
李碧秋(1996—),女,山西朔州人,華僑大學碩士研究生,研究方向為大數據。王佳斌(1974—),男,副教授,研究生導師,研究方向為嵌入式系統、物聯網、云計算、大數據、軟計算及其應用。
華僑大學研究生科研創新基金資助項目(編號:18014084003)
〔編輯:嚴麗琴〕
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
