基于改進隨機森林算法的不平衡數據分類方法研究
2020-10-14 01:04:00楊霞霞蘇鋒黃戌霞
網絡安全技術與應用 2020年10期
◆楊霞霞 蘇鋒 黃戌霞
基于改進隨機森林算法的不平衡數據分類方法研究
◆楊霞霞 蘇鋒 黃戌霞
(寧德職業技術學院 福建 355000)
傳統的分類算法難以滿足不平衡數據的分類要求,研究一種有效、準確率高的不平衡數據分類算法具有重要意義。目前的研究主要以欠采樣和過采樣以及對應的一些改進方法提供實驗數據。然而大多數實驗方法不是使用范圍有限就是側重點不同,使少數類分類性能不佳,同時也難以區分強弱分類器。本研究從數據分布入手,提出一種改進隨機森林分類算法。即先采用ADASYN算法進行過采樣,再采用ENN算法進行欠采樣。為了能更好區分強分類器和弱分類器的分類性能,最后采用加權投票機制。實驗結果表明,該算法有較好的分類性能和準確度。
不平衡數據;欠采樣;過采樣;隨機森林;分類算法
1 引言
分類是機器學習中的一種重要手段,它的作用主要是查找分類器,根據約束條件對一部分訓練樣本集構建一個抽象的模型,然后用這個模型對新的樣本數據進行歸類。常見的分類算法有決策樹、神經網絡、KNN算法、RF、樸素貝葉斯等算法[1]。這些分類算法通常假定數據集是平衡的,但現實生活中大部分數據集是分布不平衡的。例如,地震監測、醫療診斷、網絡攻擊檢測、信用卡欺詐監測等信息[2]。而傳統的分類算法難以滿足不平衡數據的分類要求,因此,研究一種有效的不平衡數據分類算法十分有意義。
近年來,大量學者對于不平衡數據集的分類處理方法主要分為兩個方面,即數據分布和算法改進[3]。從數據分布層面而言,主要是通過欠采樣和過采樣的改進。通過增加小眾訓練樣本數的過采樣和減少大眾樣本數的欠采樣使不平衡樣本分布較為平衡,從而提高分類器對小眾的識別率。過采樣需生成新樣本,如果數據不平衡則會有小眾樣本被復制多份,導致訓練出來的分類器會有一定的過擬合。SMOTE是典型的過采樣算法,雖然增加了原始數據中小眾的比例,但增加了類之間重疊的可能性,模糊了正負類邊界,且容易生成一些沒有提供有益信息的樣本。而欠采樣是通過舍棄部分多數類實例平衡訓練集,可能會導致決策邊界失真。
目前,隨機森林算法被廣泛應用于各領域。楊宏宇等人選取Permission和Intent兩類信息特征屬性進行優化選擇,可以區分強、弱分類器,但對于其他特征如API、指令特征等沒有檢測[4]。鄭建華等人提出了過采樣和欠采樣的混合策略的改進隨機森林不平衡數據分類算法[5],該算法有利于不平衡比例較大的數據集,但對沒有噪聲的訓練集不能夠生成少數類樣本。本文從數據分布入手,先采用ADASYN算法進行過采樣,再采用ENN算法進行欠采樣。為了能更好區分強分類器和弱分類器的分類性能,最后采用加權投票機制,該算法簡寫為AEIRF(ADASYN ENN Improved Random Forest)。實驗表明,該算法有較好的分類性能和準確度。
2 隨機森林算法
隨機森林算法由Leo Breiman于2001年提出[6],該算法是由多棵相互獨立的決策樹分類器集成的大規模、高維度數據學習分類器。每棵決策樹都是一個分類器,用重采樣技術和隨機抽取特征屬性分類,最終通過投票原則確定較高準確率的測試樣本類別。隨機森林算法具體如下:
(1)應用bagging重采樣技術從原始訓練集S中有放回地隨機抽取m個自助樣本集,并設M個特征屬性;
(2)在每一棵樹的每個節點處隨機抽取Mtry個屬性,并對抽取的訓練子集建立決策樹;
(3)不斷重復有放回地訓練n次,直到建立所需的N棵決策樹生成多棵分類樹組成的隨機森林;
(4)測試樣本集中每棵決策樹,均按該算法投票原則進行分類,最終確定分類結果。
對于一個含有m個樣本的訓練樣本集隨機采樣中,n次采樣都沒有被采集到的概率為(1-1/m)n。當n趨向于無窮大時大約36.8%的樣本沒有被采集,這部分樣本稱為袋外數據,從而保證了訓練樣本集的差異性。

3 隨機森林的改進算法
隨機森林算法雖然有較高的準確率,對于缺省值問題也能夠獲得良好的結果,但采用的決策樹投票原則,沒有考慮強、弱分類器的差異,決策樹采用相同的投票權重,不能充分利用分類效果好的決策樹。因此,本文結合欠采樣和過采樣的混合采樣策略和加權投票原則,對隨機森林算法進行改進。在決策樹的生成過程中,使用過采樣和欠采樣的混合采樣方法生成訓練子集,然后對各決策樹通過加權投票方式,選出票數最多的樣本為最終分類結果。算法具體如圖1:
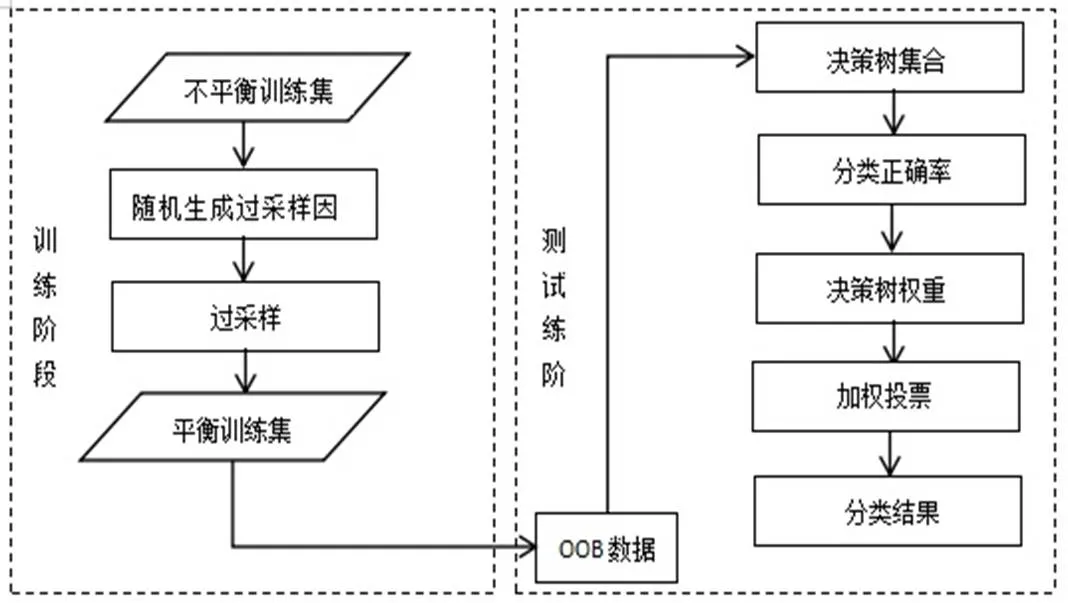
圖1 改進的隨機森林算法流程
4 實驗與分析
4.1 數據集和評價指標
本研究使用的實驗數據集是UCI中不同實際應用背景的6組公開數據集。其樣本信息如表1所示。

表1 實驗數據集
對于不平衡數據集的分類性能評價以少數類分類的準確率和召回率作為評價標準。本文采用ROC曲線特征和坐標軸圍成的區域面積來衡量準確率,當區域面積越大,分類器的預測性能越好。采用G-mean作為召回率評價指標,G-mean表示正類和負類召回率情況,只有當G-mean值高時,分類器性能越好。參數如表2。

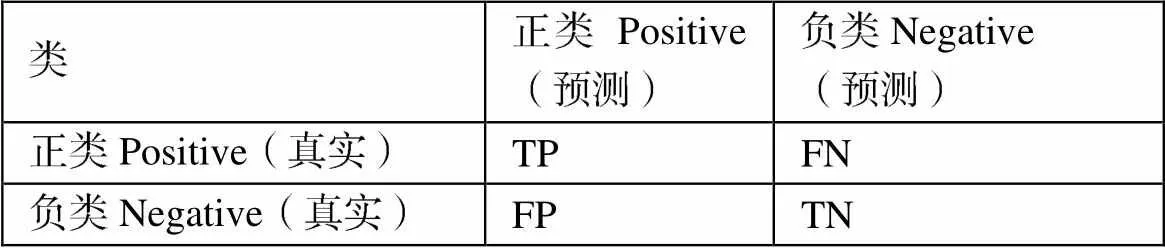
表2 混淆矩陣
4.2 實驗設計及結果
本文選用4種常見的處理不平衡數據的分類算法,分別是CART、ADASYN、SMOTE+ ENN、RF。將其與本文提出的改進算法進行分類比較,分別計算各種分類器的兩種評價指標。本實驗過程中過采樣因子都是取最大值,并按照表1所示的順序樣本集進行分類,結果如表3所示。

表3 相關分類算法準確率和召回率的結果比較
從表3可以看出,本算法的準確率高于其他3個數據集,與另外3個數據集相當;召回率有4個取得最優結果,在另外2個數據集上排名第二。該算法相比上述分類算法而言,分類性能提升了不少。比如在Sati_mage數據集上,AEIRF算法的準確率比SMOTE+ENN算法提升4%,比ADASYN和RF算法提升7%左右。
5 結論
為了研究不平衡數據集的有效分類算法,本文提出了一種改進隨機森林分類算法。一方面結合決策樹分類得到較好的分類效果,另一方面利用隨機森林算法的加權投票原則進行處理。實驗表明在6個數據集上,該算法有較好的分類性能和準確度。該實驗的數據集不夠完備和全面,今后的研究可進一步擴展數據集和提取更多地分類特征進行實驗驗證和分析,以便提高檢測效率,也可以將該算法用于應用領域,并驗證其泛化能力。
[1]王彩文,楊有龍.針對不平衡數據的改進的緊鄰分類算法[J].計算機工程與應用,2020(07):30-38.
[2]杜臻.基于特征提取和異常分類的網絡異常檢查方法[D].南京:南京郵電大學,2019:6-7
[3]趙楠,張小芳,張利軍.不平衡數據分類研究綜述[J].計算機科學,2018,46(6A):22-27.
[4]楊宏宇,徐晉.基于改進隨機森林算法的Android惡意軟件檢測[J].通信學報,2017,38(4):8-16.
[5]鄭建華,劉雙印等.基于混合采樣策略的改進隨機森林不平衡數據分類算法[J].重慶理工大學學報(自然科學),2019,33(7):113-123.
[6]BREIMAN L.Random forest[J]. Machine Learning,2001,45(1):5-32.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
