基于廣播信道的分布式事務處理方法
2020-10-09 10:23:04溫宇強邵孟良
電腦知識與技術 2020年18期
溫宇強 邵孟良

摘要:本文提出的基于廣播信道的分布式事務處理方法,該方法在廣域網環境下仍然適用且高效。相比于基于消息傳遞的分布式事務處理的算法,針對某類分布式問題,在滿足ACID( Atomicity.Consistency.lsolation,Durability)條件下,本文通過實例展示基于廣播信道的分布式事務處理方法在處理某類分布式問題時的優勢:計算量通信量減少,系統擴展性增強,算法調試簡單。
關鍵詞:分布式計算;事務處理;廣播信道
中圖分類號:TP311 文獻標識碼:A
文章編號:1009-3044(2020)18-0001-04
開放科學(資源服務)標識碼(OSID):
1 引言
在分布式系統中,為了提高數據的可用性,增強系統的擴展性,數據經通過存儲多份的方式來實現系統能力的擴展。然而,一些異常情況將導致數據出現不一致性,因此高可用事務處理系統的并發控制在可擴展性、副本恢復和單點性能等方面面臨著諸多挑戰。基于消息傳遞的共識協議算法,對消息傳遞的質量和延時是非常敏感的。在一個數據中心的環境下,節點之間的網絡通信質量和帶寬是有保證的。所以這些算法多用于一個數據中心內,或僅用于通過廣域網連接的少數節點。
在Internet應用情況下,我們需要處理的分布式計算任務往往是地理上非常分散的節點參與的。由于網絡環境的不穩定性和復雜性,如果使用現有的基于消息的共識算法,在執行效率和系統可用性等方面會遇到極大挑戰。
本文提出的基于廣播信道的分布式事務處理方法,是在廣域網環境下仍然適用且高效。在同一個數據中心的這種環境下,找到合適的廣播媒介(比如:基于DTMB技術的廣播信道),相比于基于消息傳遞的分布式事務處理的算法,仍有系統處理簡單高效的優勢。
2 基于廣播信道的系統模型
針對分布式事務處理,學者們提出了多種解決分布式事務處理問題的算法,即共識協議算法。比如:兩階段提交(2PC)[1],三階段提交(3PC)[2],Paxos算法[3],Raft算法[4]或ZAB算法[5]。這類算法以應用于數據中心環境下,而Internet的網絡環境,比數據中心的網絡環境要更不可控。盡管現有業界提出了一些web服務環境下的事務組合及控制,例如google的chubbv[6]以及Apache的ZooKepper[7],他們都使用復制狀態機來為少量配置數據提供鍵值(Key-Value)存儲。這類復制狀態機系統通常只由3個或5個服務器組成。但Web環境下的分布式計算問題需要更大的規模,目前仍存在多方面的挑戰。
面對Internet環境,若采用分而治之的方案,比如:
在這些系統中,需要在待處理的問題中有可以進行分層或分塊到較小的系統中數據。但如果系統中某些數據就是全系統唯一的,所有子系統都會用到的數據,系統分層或分塊處理都會導致這類數據的一致性(ACID)受到破壞。所以可能不得不在廣域網下使用基于消息的共識協議算法。而廣域網環境下,共識協議算法還不能在大規模系統上應用。
然而利用作者提出的信道異構CDN( CHCND)系統架構[8],針對分布式事務處理中,共享數據可累計的更新,且只有總量變化會對業務邏輯產生影響,而操作順序并無要求的操作。例如:電子購物系統,電子訂票系統等的某些類型數據更新。本文提出了一種分布式事務處理方法,可以有效解決數據副本更新問題,使得這類系統的事務更有效率。系統結構如圖1。
本文利用CHCDN系統的傳輸效率高的特性,將共享數據通過中心節點進行事務更新,再通過廣播信道進行副本更新。分布處理節點在數據需要更新時,將逐級匯總,最后在中心節點完成數據更新,我們稱此方案為信道異構共識協議。針對某些類型的分布式事務處理,異構共識協議可以更加有效率。
3 信道異構共識協議
結合廣播信道通信的優勢,我們提出的信道異構共識協議如下:
算法所有參與方都是節點Ni,i∈[0,n],運行算法之初,對Ni.產生一個節點的偏序集Pi,i∈[0,n]。Pi的選擇都是根據具體應用來定義的。其中的第一個服務器PO便是主服務器,其他服務器成為從服務器。中心節點為C,C可以把數據發送到廣播信道傳輸。偏序集合的依據有很多種,比如:以節點P2到中心節點C的雙向點對點網絡(可以是WAN網絡)的延遲,作為產生偏序集合的依據。P0對只提供服務,最終客戶通過P2獲取服務器,其中Pi,i∈[0,n]。另外,c可以是只中的一員,也可以是一個獨立的節點。只都可以與P0通過點對點網絡通信。Po可以通過點對點網絡與C通信。系統初始化時統計出
對于要通過分布式系統更新的數據項,算法引入廣播變量類型,其狀態有:fboardcast-read.boardcast-lock),同時還有更新版本號boardcast_revision,數據項的更新版本號會隨著數據更新提交的次數變化,為敘述方便,我們假設變量更新版本號從0開始遞增。廣播變量類型的屬性,都存儲在主服務器PO上。其他節點會通過廣播信道得到對應數據項的更新狀態。則在只系統中,要更新的數據便有了廣播變量類型。其值在Pi系統中,對Pi中的應用程序為只讀的屬性。通過廣播信道,可以實現所有節點的系統時間統一,并且這個時間精度可以足夠用于分布式事務的先后區分。如果有相同的兩個更新請求的時間戳一樣,則再利用節點的排序,人為定義相同時間戳的更新請求先后次序。
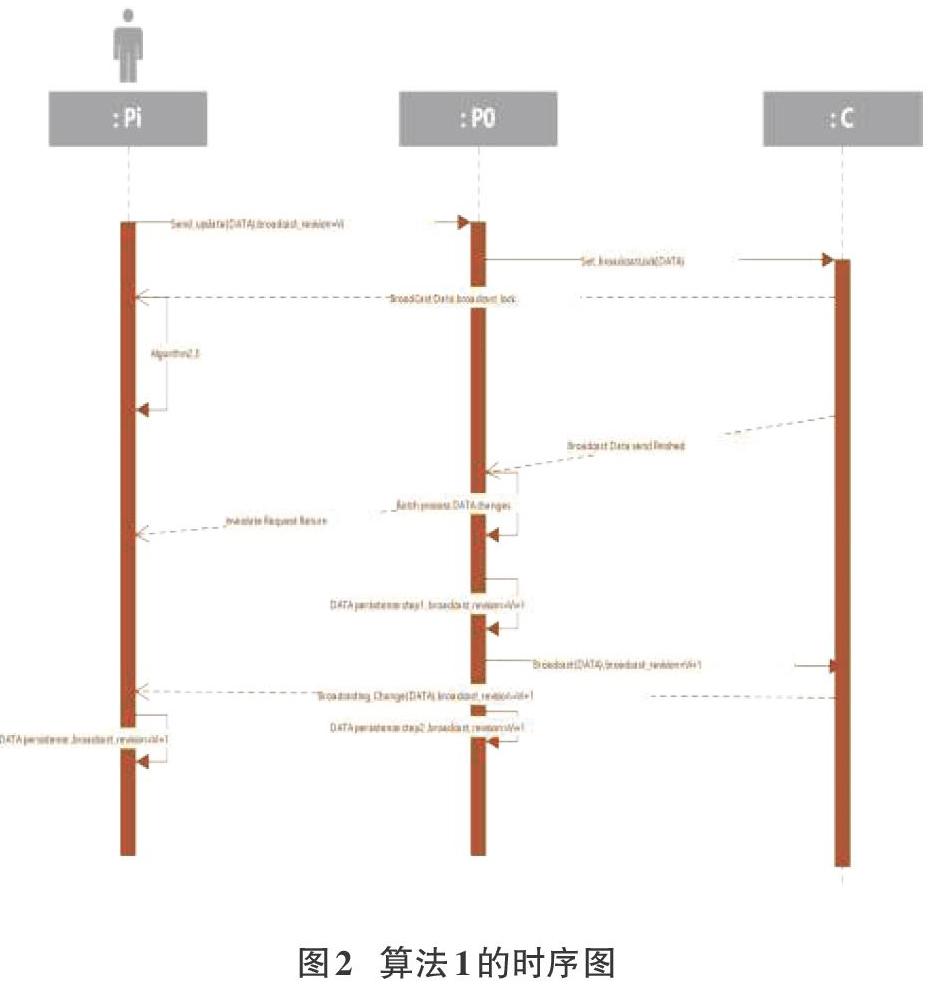
系統事務處理具體處理流程如下,算法1:
Stepl節點Pi發出數據的修改請求,通過點對點網絡,請求送達PO。
PI中對于狀態為boardcast-read的數據項,只若要執行數據更新的操作,則節點Pi需通過點對點網絡提交該數據項的更新請求給P0,請求信息帶有時間戳,以及當前數據項的更新版本號boardcast_revision=Vi。
Step2 Po在接到對某廣播類型變量boardcasLrevision=Vi的第一個更新請求后,通知C,C通過廣播信道把對應數據項的狀態變為boardcast-lock的消息發送出去.廣播信道發送出去該消息的當前時間戳為to.
to+ TB時間過后,所有的節點都應收到這個消息,并把系統內對應的數據項的狀態由boardcast-read變為boardcast-lock。則此時以后的對此數據的修改請求將會視為無效。這些有效的boardcast_revision=Vi更改請求中,最遲會到達PO的時間為Tmax;io,如果超過了這個時間到達,也視為無效數據,并且會根據到達時間修訂Tmax:i-0,具體修訂算法不屬于本文討論的內容。
所以,Po對boardcast_revision=K時間標簽為to+ TB+ Tmax:io以后的數據提交請求,以及,boardcast_revi-sion=Vi但是在t0+TB+Tmax:i-0以后才到達的數據更新請求都會忽略。
PO收到有效的的更新請求,順序進行處理。其他的處理可以并行:返回結果給對應的節點;對無效的數據請求,直接給節點返回對應的錯代碼;發送結果的反饋,使用的是點對點網絡。
假設順序處理完當前時間窗內的有效更改需求后,分兩步提交這個數據項的持久化存儲:
Step2.1,PO將結果在持久化系統中(數據庫)更新,并設置新的boardcast_revision=Vi+i,并發送更改后的數據項給C,C通過廣播信道發送對應數據項的更新信息。從t0+TB+Tmax:i-0開始處理更新請求到C收到更改后的數據值并把值更新消息發送到廣播信道,耗時為g;
Step2.2,當PO收到廣播信道中的數據更改信息,時刻為to+ 2TB+Tmax:i-0 +9,執行持久化系統的更新確認。
由于數據更新的請求多數是值更新類的請求,所以批量處理在一定時間間隔內的更新請求,有合并對同一變量的操作的可能,而減輕數據庫持久化的1/0壓力。提高系統的響應速度。
同理只節點也會在tc)+ '2TB+Tmax:t一0+g時刻收到廣播更新信息,數據項狀態則由boardcast-lock轉化為boardcast-read,boardcasLrevision也做相應的更新,所以白t0+2TB+ Tmaxi-0+g開始的數據請求將會是有效的,對應的數據項更新請求將是boardcasLrevision=Vi+1
Step3只節點通過廣播信道接收數據庫的更新,對比自己的數據庫中的條目,進行更新。某些條目也許不在本節點的數據庫中,則不用管。某些更新失敗的節點,需要重新檢查廣播數據項的狀態,再提交新的更新請求。
Step4提交新的請求即重復上面的1-3的過程。
本系統數據更新最小間隔Tsp,也就是響應速度為。Trsp與分布式系統的規模無關,有下列關系:TB是基于系統所選擇的廣播信道而決定的,其值為:TB=電磁信號在空中傳播時間+調制解調時間
如果選擇同步衛星,則TB大概是0.27秒;如果選擇低軌道衛星,TB則很小大概是同步衛星的1/36-1/6;若采用高空氣球或高空無人機作為信號中繼,則B的值更小。( )與( )的值有賴于分布式系統節點間的網絡環境,系統在運行過程中可以動態監控這些值;g是PO處理時間窗內請求需要的時間。所以,本算法的系統的可用性是有保證的。
對應上面的系統事務處理流程流程,Pi節點內的處理流程描述如下:
假設Data為我們感興趣的全局一致的廣播類型數據,Val-ueChange為本地應用對Data變化的期望,realchange為本地應用最終得到的Data變化。由于boardcast_revision更新主要是通過廣播信道更新,所以下面算法主要敘述Data的狀態和值的更新。 只節點廣播信道更新數據的處理流程的偽代碼片段如下,算法2:
1:
2:
if(Data.status==boardcast-read)(
//new value change command can be send now
3:Send_update(Data, ValueChange);// Asynic messagesend
4: ) else if(Data.status==boardcast-lock)(
5:Invalidate(Data);// local variables need to bechecked. Data value maybe changed
6: j
Pi節點收到P0返回的異步消息處理結果的處理流程為代碼如下,算法3:
0:
1:
value=Get_CurrentValue(Data)
2: if(resuh.status==sucess){
3:realchange=ValueChange;
4: )else if(result.status==fail)(
5:
realchange=0;
6: 1
7
Pi節點的數據處理邏輯,應該基于ValueChange和real-change,而不是基于廣播類型數據Data的value。
通過引入廣播數據類型,分布式程序的設計上可以不需要為分布式變量操作的同步而消耗時間等待。廣播數據類型的修改采用異步的方式,不會影響本地的應用效率。只是在應用設計上,要正確靈活地使用廣播數據類型。這大大簡化了分布式系統的設計。分布節點Pi對應用邏輯的處理中,不需要執行對數據庫的持久化操作,所有的持久化操作集中在Po做。這會讓應用程序負擔小,跑得更快。在Po中,對值更新類型的數據操作,可以在Trsp時間內合并對相同數據操作,最后只需一次數據庫的持久化寫入,這種合并處理對PO的數據庫10操作的減少也是有很大幫助的,此部分的處理可以在Po系統中劃分一個中間件子系統來處理;另外在每次提交的操作間隔中,已經包括了p0數據庫的提交,所以Po的處理速度會因為數據量的增大有所減慢(g增加),從而增加系統最小更新時間間隔Trsp。但目前有很多比較成熟的技術可以提高這部分的執行效率[1][2]。
對數據項的操作盡量多使用更新類型的數據操作,而不是設置類型的數據操作。這是分布式系統數據處理中常見的情況,比如:對金額,計數等的操作,主要是更新類型操作。
4 模擬仿真
例如:全國鐵路售票系統使用本算法實現全國范圍內的列車剩余車票數據的更新事務處理。全國所有的鐵路售票系統通過網站為全國人民服務,全國人民可以訪問網站來訂票,訂票的規則是先到先得。
現此系統準備使用本算法,實施如下。
1.對全國所有的鐵路售票系統通過網站,按CHCDN的方式,在全國建立多個鏡像服務器。假設全國每個小區都有一個邊緣計算中心,則可以在每個小區的邊緣計算中心中,利用CHCDN系統部署鏡像站點,為小區中的居民服務。
2.每個鏡像站點初始時有一致的數據庫,里面保存了全國各列車的售票情況數據。
3.通過本算法,系統初始化后,選擇了一個在北京交通部的服務節點作為Po,同時在交通部內有一個服務器C可以把數據傳到中星9號上的某個數據頻點。系統中的所有節點,都安裝有廣播接收子系統可以獲取中星9號上的這個數據頻點中的數據。系統經過初始化后,確認的系統響應間隔Trsp為0.8秒。
4.通過廣播信道,可以直接更新系統中各節點的全國各列車的售票情況數據。
5.這樣,各節點中的網站設計,大部分沒有什么區別,只是把用戶部分的用戶信息,作為各節點自己管理的數據。用戶信息的數據,在全網也保持一致,此部分信息可以不用存在一個單一的節點內,而是分布式的存于客戶登錄過的節點中,不同節點之間的用戶信息之間是可以確保一致的。(這不是本算法要討論的內容,所以不詳細展開)
6.系統中某小區a有用戶Ua登錄到該小區內的全國所有的鐵路售票系統網站鏡像,這個網站鏡像運行在節點Pa,Ua在網站上瀏覽L列車的剩余車票時,還有100張,在時刻to,Ua在鏡像網站上訂了一張L列車的車票,這時網站顯示“車票訂票執行中…”。由于鏡像網站運行在Pa,Pa中有足夠的資源保證Ua的體驗,用戶體驗到的就是分布式系統處理的速度。
8.ta到tz的時間中,假設tz最大,tz
9.PO在to +0.5前的時間內(t。+0.5對應于算法1中的to+ TB+Tmax:i_o)接收Pa到Pz發來的boardcast_revision=0的更新請求,其中只有Pa到Pj的請求是有效的,假設他們都在ta+0.5之前到達PO。Po處理了這些請求后,L列車的余票為9張。Po把這個結果提交本地數據庫,數據版本更新為board-cast_revision=1,把結果通過C傳到中星9的廣播信道中。同時,Po通過點對點的網絡對Pa到Pz的請求進行應答。
10.在to +0.8時刻(to +0.8對應于算法1中t0+2TB+Tmax:i-0 +9),所有節點收到廣播信道更新。Uk到Uz的用戶界面上可以瀏覽新的余票信息,只有9張了,重新調整訂票數為每人1張。
11.假設Uk到Uz在重新提交訂票請求的時候,又同時進行了提交(這在實際系統中幾乎不可能,但是為了說明系統對這種極端情況的處理,我們假設同時條件成立)。由于Uk到Uz提交的請求需要16張票,但是現在系統只有9張票,所以只能滿足部分用戶的請求。最)收到這些更新請求后,會根據Pk到Pz在系統中的排序,定義這些請求的執行順序;假設就按照k-z的順序,則Uk到Us可以每個人得到1張票,Ut到Uz還是沒有搶到票。這時系統中L列車的余票為0張。
同樣的方式,在處理更多的列車數據和更多的用戶的時候方法類似。
這個例子體現了利用本算法后的系統的分布式系統的可擴展性和在事務處理中的高效和公平。
5 結論
基于廣播信道的分布式事務處理模型的提出,雖然不能把所有的事務處理問題都解決。但是針對大量存在的公共變量更新問題,該模型提出了十分有效方法,在計算量、通信量、算法調試復雜度等方面都大大改善。基于廣播信道的分布式事務處理在這類問題的應用,將會推動分布式事務處理方式的改變。
參考文獻:
[1] Lechtenborger J.Two-Phase Commit Protocol. In: Liu L.,Ozsu M. (eds) Encyclopedia of Database Systems[M]. Springer,New York, NY, 2016
[2]Al-Houmaily Y.J., Samaras G.Three-Phase Commit. In: LiuL., Ozsu M.T. (eds) Encyclopedia of Database Systems[M].Springer, Boston, MA. 2009
[3]Lamport Leslie,Ceneralized Consensus and Paxos,Microsoft Re-search Technical Report MSR-TR-2005-33, 2005
[4]Ongaro D,Ousterhout J. In search of an understandable consen-sus algorithm[C]. usenix annual technical conference, 2014:305-320+
[5]Junqueira F,Reed B,Serafini M,et al.Zab: High-performancebroadcast for primary-backup systems[C]. dependable systemsand networks. 2011: 245-256.
[6]Burrows M. The Chubby lock service for loosely-coupled dis-tributed systems[C]. operating systems design and implementa-tion。2006: 335-350.
[7]Hunt P D,Konar M, Junqueira F,et al.ZooKeeper: wait-freecoordination for internet-scale systems[C]. usenix annual tech-nical conference. 2010: 11-11.
[8]溫宇強.CDN系統中數據請求、發送的方法、裝置及系統結構:中國專利,ZL 2014 1 0271393.X [P].2014-08-27
【通聯編輯:梁書】
基金項目:2018年廣州市科技計劃項目“實時大數據處理中間件關鍵技術研究與開發”(201804010402);2018年廣州南洋理工職業學院創新強校工程項目“信息技術創新與應用基地”(NY-2018coPT-01);2019年廣東省普通高校重點研究(自然)項目“實時大數據處理平臺關鍵技術研究與開發”
專利:CDN系統中數據請求、發送的方法、裝置及系統結構專利號:ZL 2014 1 0271393.X
作者簡介:溫宇強(1978-),男,碩士,主要研究方向為分布式計算、大數據等;邵孟良,副教授,碩士。
