基于八叉樹的卷積神經網絡三維模型分割
2020-09-29 08:08:54楊曉文韓慧妍
計算機工程與設計 2020年9期
楊曉文,李 靜,韓 燮,韓慧妍,陶 謙
(中北大學 大數據學院,山西 太原 030051)
0 引 言
由于獲取3D信息設備的不斷發展,通過建模工具所創建的三維模型不斷增多,對其進行研究成為熱點問題。其中,三維模型的分割包括對點云與網格模型的分割,根據語義上的不同,把完整的三維模型分割為相鄰子部分[1]。三維模型的分割有利于進一步理解和分析三維模型,包括變形、簡化、檢索以及曲面重建等[2],同時也是古文物保護、建筑物及城市場景三維建模、動植物外形建模、醫學檢測、幾何壓縮與傳輸等工作的基礎,在許多模型處理和視覺應用上也越來越重要。
1 相關研究
卷積神經網絡(convolutional neural networks, CNN)不斷應用在各領域中,國內外研究學者根據對三維形狀的分析,利用卷積神經網絡對三維模型的分割進行了研究,其中,主要為基于體素,流形以及多視圖3類方法。
基于體素的方法是指以三維空間的體素作為定義域進行3D卷積,將CNN拓展到三維空間進行學習。Maturana等[3]將3D形狀光柵化并在密集體素上采樣距離函數,在整個體素上應用3D CNN。Wu NZ等[4]在體素上定義3D CNN以進行形狀分析,提出了用于物體識別和形狀分析的3D ShapeNets,但是該方法只適合于低分辨率的三維模型。為了降低基于全體素方法的計算成本,Graham B[5]提出了3D稀疏CNN,對于深層CNN,該方法的計算和存儲成本仍然很高。這些方法計算量大,不易儲存,不適用于高分辨率模型。
基于流形的方法是指對流形網格上定義的特征進行CNN操作。Boscaini等[6]將3D表面參數化為2D圖像,將采樣的特征圖像饋送到CNN中以進行形狀分析。Bronstein等[7]將CNN擴展到由不規則三角形網格定義的圖形上。這些方法對于三維模型的等距變形較為穩健,但是它們被約束為平滑的流形網格時難以提取局部特征,噪聲較大。
基于多視圖的方法是指利用空間投影將三維模型轉化為多個視圖下的二維影像,并將圖像堆棧作為2D CNN的輸入。謝智歌等[8]提出了基于全卷積的多角度多層次極限學習機的三維模型分割方法,該方法通過對深度圖像的多標簽訓練、預測以及把標簽回投到三維模型的三角面片上得到分割結果。Kalogerakis等[9]設計了一個投影卷積網絡應用于三維形狀的分割。這些方法直接利用基于圖像的CNN進行3D形狀分析并處理高分辨率輸入,但是不能確定視圖數量以完全覆蓋三維模型,無法避免遺失三維信息。
本文利用八叉樹表示三維點云模型,將卷積計算限制在八叉樹節點上,使計算量只和八叉樹節點數目相關,卷積、反卷積、池化、反池化操作由于八叉樹的數據和層次結構在迭代過程中計算高效,減少了計算與存儲成本,避免了視圖選擇問題,可以處理高分辨率的點云輸入。實驗及評估度量結果表明,實驗數據集中大多數模型取得了良好的分割效果。
2 背景知識
2.1 卷積神經網絡
卷積神經網絡是一種前饋神經網絡,包含卷積計算并具有深層結構,其不斷應用在深度學習中[10]。CNN的本質是多層感知機,局部連接和權值共享的方式減少了權值的數量更易于優化網絡,降低模型的復雜度,減小過擬合的風險。通過構建多層網絡提取數據中具有抽象語義信息的高層次特征,得到更好的特征魯棒性。
CNN是基于監督學習的神經網絡,實現特征提取功能的核心模塊位于隱含層的卷積層和池化層,每層有多個特征圖,每個特征圖有多個神經元,并使用大小不等的卷積濾波器提取特征。其中,卷積層為特征提取層,通過權值共享的卷積核使每一層的特征都由上一層的局部區域激勵得到,即將每個神經元的輸入與上一層的局部感知野相連,并由激活函數形成并輸出特征映射圖[11]。池化層位于連續的卷積層中,用于壓縮數據和參數量,去除冗余信息,防止過擬合。
2.2 八叉樹結構
二維圖像通常結構化表示為二維平面上的矩陣,但是三維形狀是非結構化的,尤其點云數據是不規則和無序的。因此,利用卷積神經網絡處理點云數據時,由于輸入數據的不穩定性使得卷積操作難以直接應用到點云數據上。
利用自適應的空間剖分來壓縮存儲點云數據,八叉樹[12]是一個非常好的選擇。八叉樹是一種遞歸、軸對齊且空間分隔的數據結構,將空間分成等體積的立方體可以加速細分運算,且單元大小的存儲也可以節省空間。三維空間根據是否含有三維點云的一部分決定是否一分為八,并在子塊里重復劃分。八叉樹結構常用于計算機幾何進行優化碰撞檢測、最鄰近搜索等,且常用于三維數據的表達。
3 基于八叉樹的卷積神經網絡的三維模型分割
本文使用八叉樹結構化表示三維點云模型,在點云模型的邊界表面占據的稀疏八分體上執行CNN操作對三維點云模型進行分割。本文方法流程包括:①對點云模型進行預處理并在此基礎上構建表示點云的八叉樹結構,八叉樹的最深葉節點處存儲點云的信息,提取最大深度的葉子八分體中采樣點云的平均法向量與平均曲率,并將其融合作為卷積網絡的輸入特征,存儲在相對應的葉節點上;②將卷積計算限制在八叉樹節點上,計算每個深度的相鄰水平節點的特征,池化合并之后,將特征下采樣到父節點并且被傳送到下一八叉樹深度層。級聯反卷積神經網絡進行逐點預測,遍歷整個神經網絡,不斷迭代神經網絡層訓練并測試,得出點云模型分割預測標簽;③使用CRF優化并進行分割可視化得出三維點云模型分割結果。本文方法流程如圖1所示。
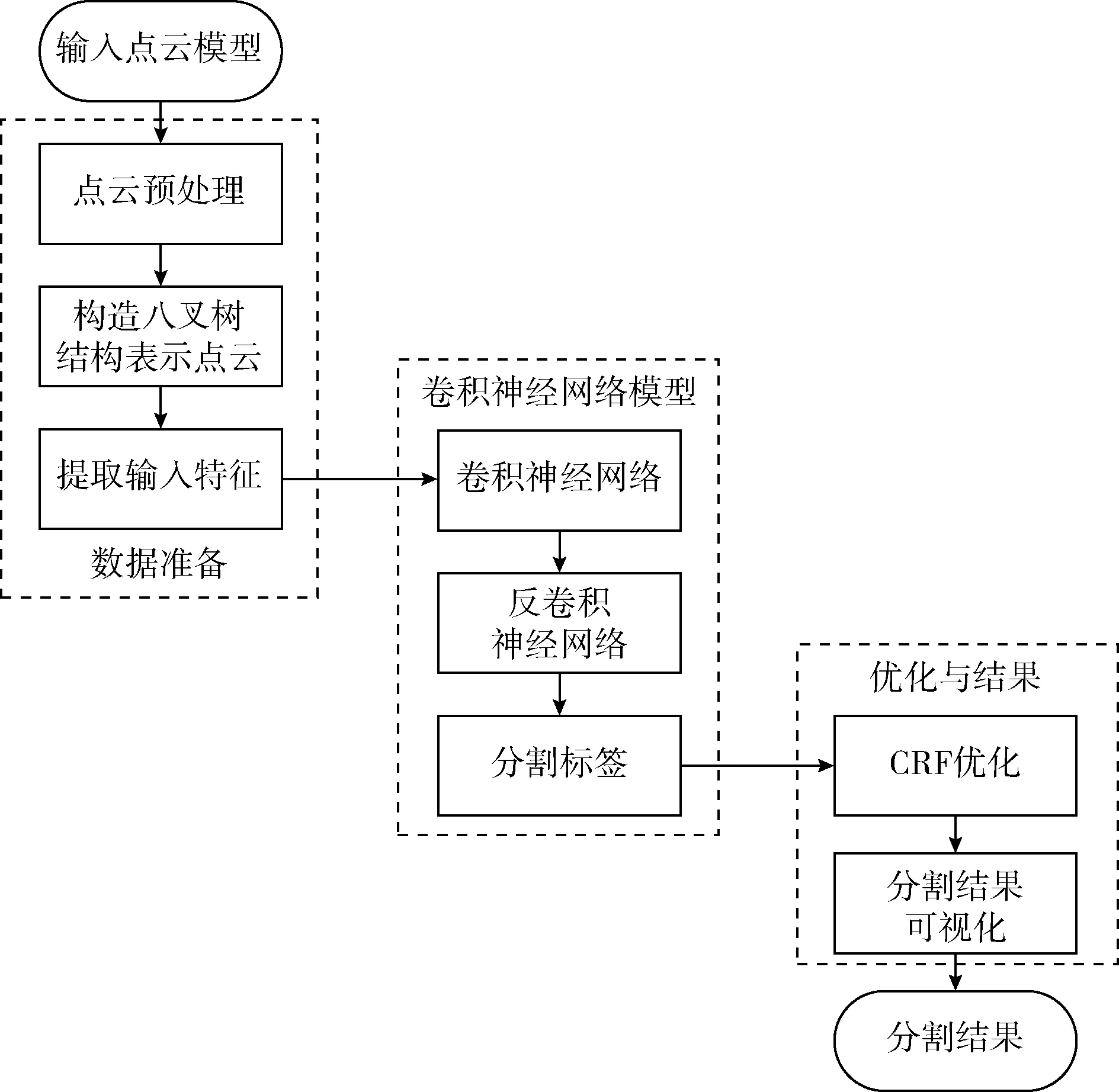
圖1 本文方法流程
3.1 數據準備過程
3.1.1 點云預處理
實驗所用原始模型是稀疏點云,并且點云模型缺失了對應的法線信息,為此將點云模型與相應的3D網格對齊,并將點投影到三角面片中,然后采用射線射擊算法在三角網格中確定密集點,將密集點所在的三角面片的法線分配給該點,得到預處理的點云模型。射線射擊算法具體來說,在將點云模型投影到三角面片的基礎上,根據點云中每個點所在的三角面片確定包含該點云模型的邊界立方體(該邊界立方體是根據三角面片統一采樣來確定的),將多個虛擬相機均勻放置在包含點云模型的邊界立方體的各個面中心,從每個方向均勻地對模型發射平行光線,計算光線與三角面片的交點,如果此三角面片中包含了點云模型中的點,即將該點的法線指向相機,不相交的點被舍棄,得到點云模型的密集點,以此預處理點云得到具有定向法線和密集點的點云數據。
3.1.2 構造八叉樹結構
為了構造表示三維點云的八叉樹結構,首先將三維點云模型縮放于軸對稱的3D立方體中,然后采用廣度優先算法,細分點云模型的邊界立方體,并不斷迭代,直到將深度為d處的點云模型邊界所占據的所有非空八分體細分到下一深度d+1處的八個子八分體,即達到指定的八叉樹深度,迭代停止。八叉樹的每一層由排序后的隨機鍵數組和標記非空節點序號的標簽數組組成[13],通過這些數組可以快速訪問節點鄰居。八叉樹構造過程如圖2所示。
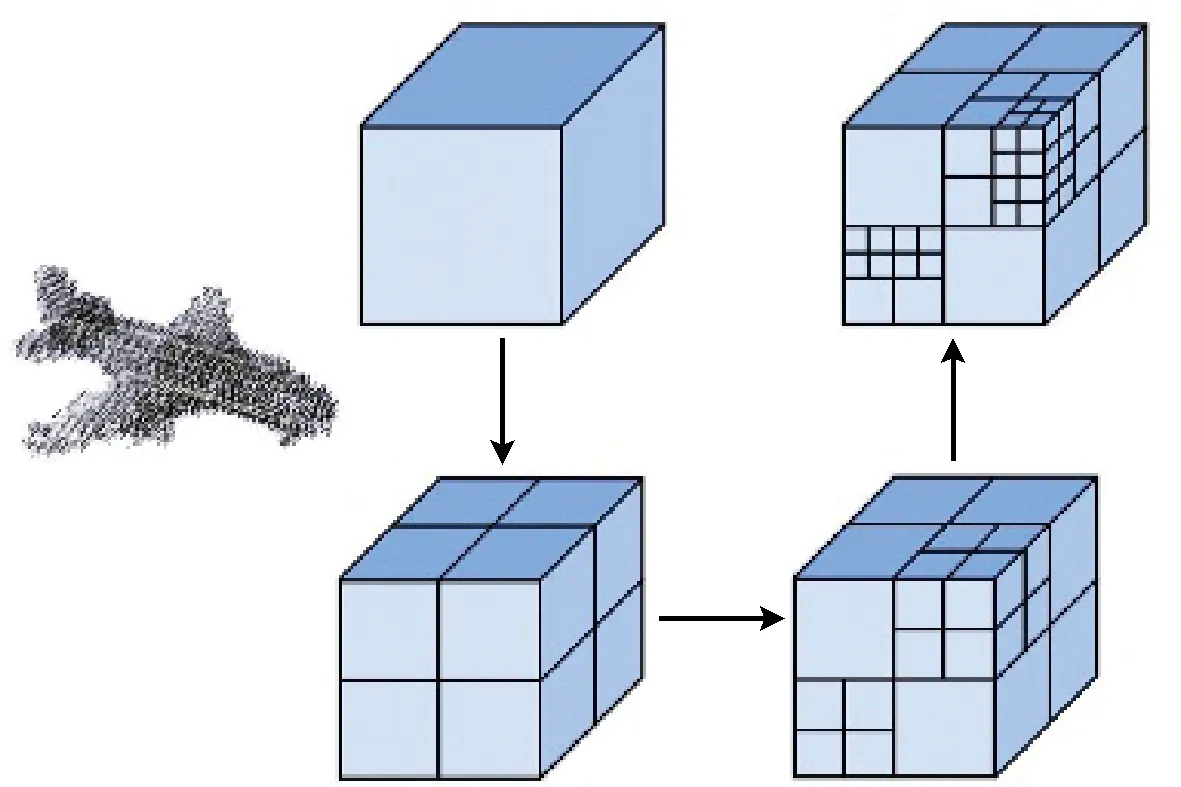
圖2 八叉樹構造過程
其中,隨機鍵是用來表示深度為d的八分體O在3D空間中的相對位置:key(O)∶x1y1z1x2y2z2..xdydzd,xiyizi∈{0,d}。 通過隨機鍵升序排列八分體,第d深度的所有八分體中排序后的隨機鍵存儲在隨機鍵矢量Sd中,矢量的長度是當前深度的八分體的數量,該矢量用于構建3D卷積中八分體的鄰域。類比四叉樹節點的隨機鍵與每個深度的相應隨機鍵數組如圖3所示。
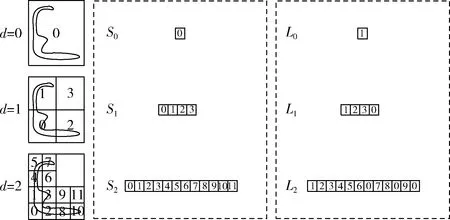
圖3 四叉樹隨機鍵與標簽
描述相鄰深度的父子八分體之間的關系,通過池化操作將深度為d的八分體處計算得到的特征經過下采樣計算后連接到深度為d+1的子八分體,并為非空八分體指定標簽p, 并將該深度處的所有八分體的標簽存儲在標簽矢量Ld中。詳細定義請參見文獻[13]。在第d深度的一個非空節點處定義索引j,計算第d+1深度處其第一個子八分體的索引k=8*(Ld[j]-1), 從而可以快速找到父節點到其子節點的對應關系。類比四叉樹每個深度的標簽矢量如圖3所示。
3.1.3 提取特征
構造點云的八叉樹結構之后,提取最大深度的葉子八分體中采樣點云的平均法向量[14]與平均曲率,兩者相融合作為CNN的輸入特征。對于空葉子八分體,將其指定為零向量作為輸入特征;對于非空葉子八分體,對嵌入葉子八分體中的點云形狀表面的一組點進行采樣,利用點云預處理過程中分配給各點的定向法線計算平均法向量。
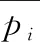
(1)
式中:NP(i) 表示點pi在該葉子八分體區域,N表示該葉子八分體內點的個數,pj是pi在此葉子八分體內的鄰域點,從而得到pi的協方差如式(2)所示
(2)
式中:C是一個半正定矩陣,可以取3個非負特征值λi(i=0,1,2)。 當λ0<λ1<λ2, 并定義λi的對應正交特征向量為ni(i=0,1,2), 又由式(3)所示
(3)
此時T(x) 表示點pi的最小二乘平面,近似看作點pi切平面。n0表示點pi在局部區域內的法矢,特征值λ表示為該曲面的變分。由Pualy等[16]定義可得該曲面變分近似于點pi處的曲率,如式(4)所示
(4)
并根據平均曲率定義求得點pi處平均曲率。
特征融合[16]是指從多個相關原始特征集中獲得最具差異性的信息,能夠消除因不同特征集之間的相關性而產生的冗余信息。本文方法中計算出平均法向量和平均曲率之后,利用并行特征融合策略將其合并成一個比單個輸入特征更具有判別能力的特征并將其作為卷積神經網絡的輸入特征。并行特征融合策略的思想是:假設α,β是同一樣本的兩組特征向量,用復向量來表示樣本的并行組合特征[16],融合公式如式(5)所示
γ=α+iβ(i是虛數)
(5)
最后將融合后的特征作為卷積神經網絡的輸入特征并將其存儲到輸入特征矢量中。
3.2 卷積神經網絡結構
卷積神經網絡對點云的八叉樹結構反復應用卷積和池化操作,本文中激活函數使用ReLU(f∶x∈R→max(0,x)), 并使用批量標準化(BN)來減少內部協變量偏移。將“convolution+BN+ReLU+pooling”作為基本單元,當卷積操作應用于深度為d的八分體時,由Ud表示,Ud的特征映射的通道數設置為2max(d,9-d), 卷積核大小為3*3*3。 該部分網絡結構定義為CNN(d):輸入→Ud→Ud-1→…→U2。
本文方法參考圖像語義分割網絡DeconvNet[17],在卷積網絡之后級聯反卷積網絡進行密集逐點預測。卷積網絡被設置為CNN(d),反卷積網絡是CNN(d)的鏡像,其中卷積和池化運算符由反卷積和上池化代替。將“unpooling+deconvolution+BN+ReLU”作為一個基本單位,將反卷積操作應用于深度為d的八分體時,則由DUd表示。所以整體卷積神經網絡結構定義為: CNN(d)→DU2→DU3→…DUd。 網絡結構如圖4所示。
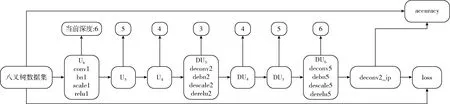
圖4 網絡結構
3.2.1 3D卷積
3D卷積(3D convolution)是指卷積核的維度為三維,最早提出用于行為識別等領域。在本文方法中,將卷積運算應用于某個深度處的所有八分體,需要在該八叉樹深度處連接其相鄰八分體,卷積運算φc如式(6)所示
(6)

3.2.2 池 化
池化(pooling)的目的是逐步壓縮空間大小,是對卷積層輸出的特征圖做下采樣操作。池化層在每個通道上獨立運行,并在空間上調整其大小,去除冗余信息,最常見的形式是max-pooling和avy pooling,本文采用max-pooling操作。八叉樹結構上應用max-pooling可以從每8個連續存儲的子八分體屬性值中挑選出最大值。
3.2.3 上池化
上池化(unpooling)操作是匯集和執行上采樣的逆向操作,一般指的是max-pooling的逆過程,廣泛用于CNN可視化和圖像分割。應用max-pooling之后,每個池區域中最大值的位置記錄并存儲在一組變量中,這些變量將當前特征映射放入上采樣特征映射的適當位置。在CNN中,最大池化操作是不可逆的,可以通過使用一組轉換變量記錄每個池化區域內最大值的位置獲得一個近似的逆操作結果。
3.2.4 反卷積
反卷積(deconvolution),也稱為轉置卷積和反向卷積,用來放大和加密特征圖,步長為k的反卷積核可以實現特征圖的k倍放大效果。卷積層的反向傳播過程是反卷積層的前向傳播過程,基于先前描述的八叉樹上的卷積操作,可以相應地實現反卷積操作。
3.2.5 神經網絡優化算法
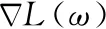
(7)
ωt+1=ωt+Vt+1
(8)
其中, ?是負梯度的學習率(base_lr),μ是上一次梯度值的權重(momentum),用來加權之前梯度對現在梯度下降方向的影響,這兩個參數值需要通過不斷調整得到最合適的值。
3.2.6 損失函數
損失函數[19]在CNN中是用來衡量預測標簽與初始標簽一致性的度量指標。本文中使用SoftmaxWithLoss計算訓練過程中的損失值,卷積過程中,SoftmaxWithLossLayer主要使用了兩個概率統計原理:邏輯回歸和最大似然估計。
邏輯回歸對應于Softmax,其將神經網絡的輸出特征轉化成概率,最大似然估計用于計算損失函數,其核心公式如式(9)、式(10)所示
(9)
(10)
其中,yi為標簽值,k為輸入點云標簽所對應的神經元,m為輸出的最大值,主要考慮數值穩定性。而反向傳播時loss計算公式如式(11)所示
(11)
對輸入的zk求導可得式(12)
(12)
3.3 CRF優化
本文使用條件隨機場CRF(conditional random field algorithm)[20]優化分割結果。由于反卷積網絡分別對每個點進行預測,分割后的點云模型中相鄰區域之間仍然存在噪聲,因此使用CRF對結果進行調整。
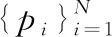
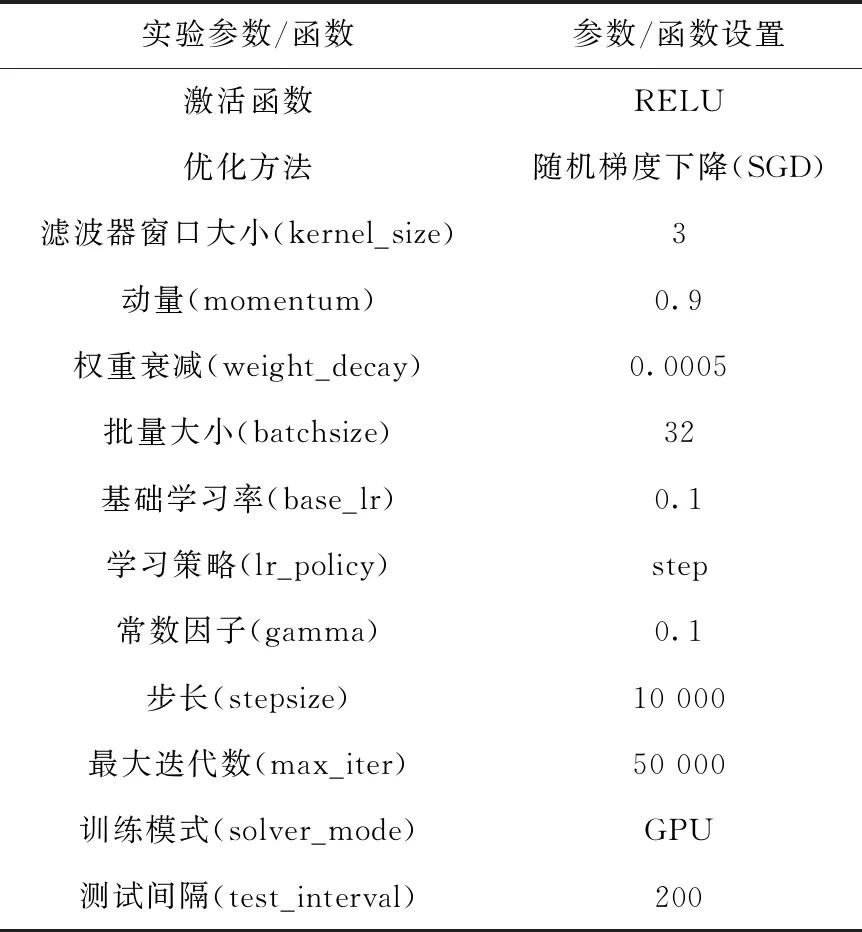
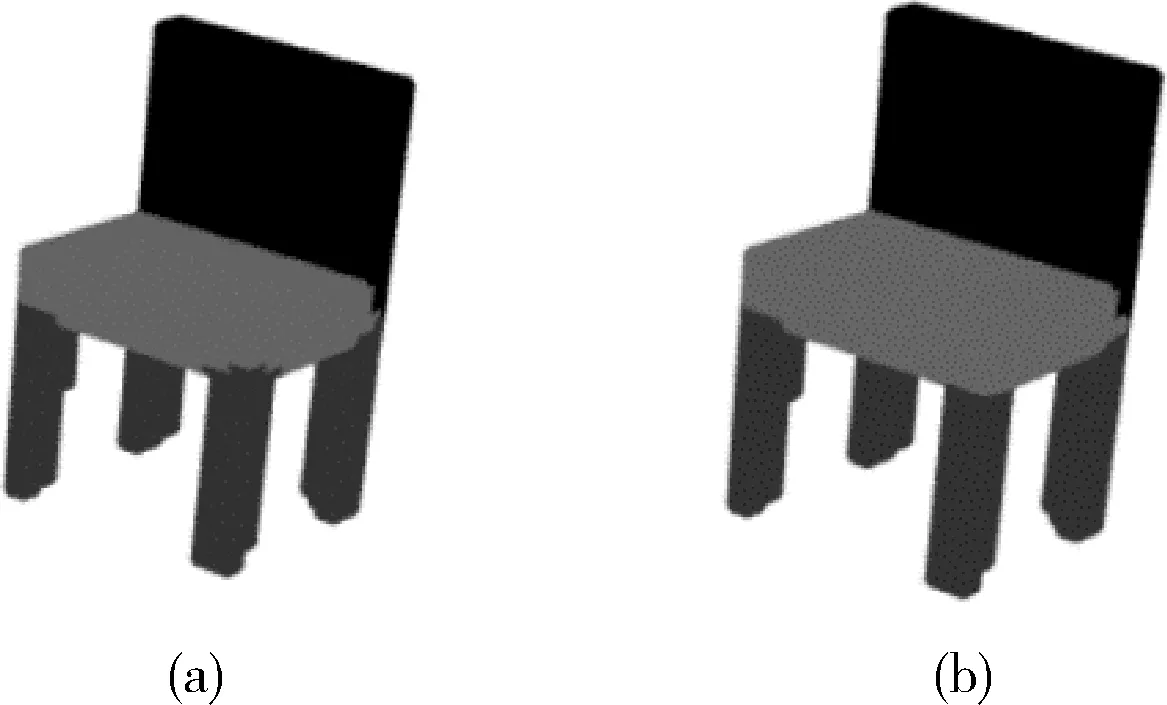
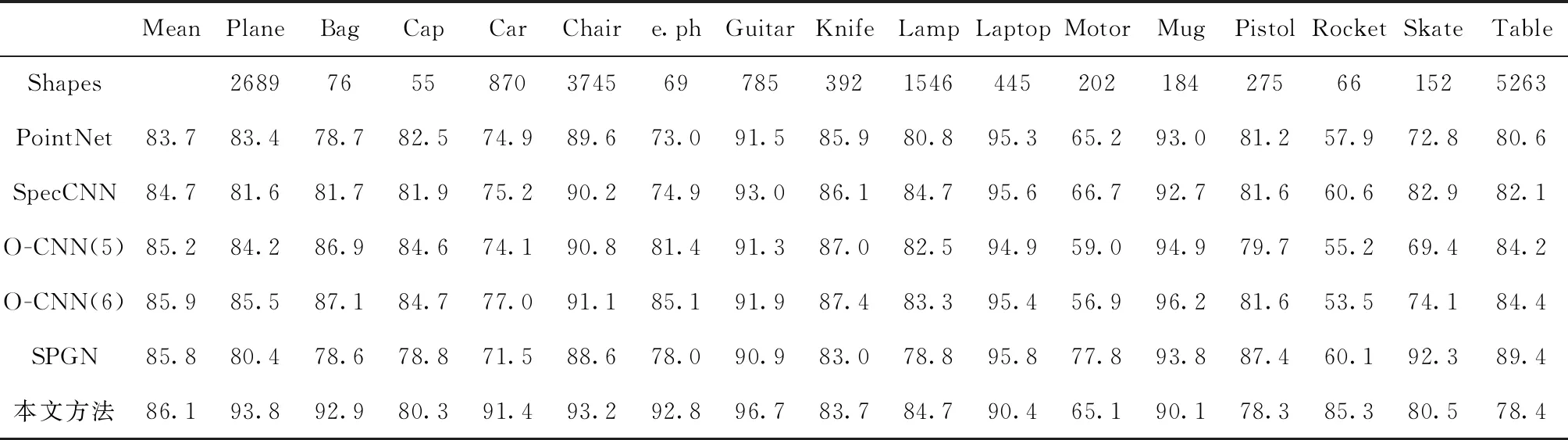
E(x)=∑iφu(xi)+∑i (13) 式中:i和j的范圍從1到N。φu(xi) 用來約束最終輸出結果,定義為φu(xi)=-log(p(xi)), 其中p(xi) 是神經網絡生成標簽的概率。φp(xi,xj) 用于合并信息以輸出精確結果,如式(14)所示 (14) 式中:Wθi表示具有標準差θi的高斯函數,μ(xi,xj) 是標簽函數,ωi和θi是超參數。通過CRF優化算法之后,點云模型的不同分割區域之間噪聲減小,邊緣更平滑。 本文實驗使用數據集ShapeNetCore的一個子集,包含16種形狀類別,大約17 000個點云模型,每個類別有2到6個部分,總共有50類不同區域的標簽注釋。在實驗中,對于每一類的點云模型分別以模型總數90%的數據量作訓練數據,10%的數據量作測試數據。 實驗環境:以Caffe為深度學習框架,支持GPU運算;Intel(R)Core(TM)i7,CPU@2.80 GHz,NVIDIA GeForce GTX 1050 Ti 4 GB,VS2015+anaconda 3.4.2,CUDA8.0+cudnn-8.0-windows10-x64-v5.0。 實驗中神經網絡的參數和函數設置見表1。網絡模型采用SDG優化算法,迭代學習中隨機均勻采樣訓練數據,更新模型參數,逐層調節權重參數,使用SoftmaxWithLoss通過大量的迭代訓練提高網絡的精度,并計算迭代過程中的損失值。針對不同類別的個別參數進行調整,其中基礎學習率變化范圍在0.1到0.001之間;批量大小和測試間隔隨測試集的數量大小進行調整,調整規則為2的整數次冪;最大迭代數根據訓練集的大小調整。 表1 實驗參數/函數設置 在卷積神經網絡訓練過程中,訓練與測試同時進行,并將測試間隔設置為200,即每訓練200次測試一次,同時計算各自的準確率與損失值。在訓練迭代結束后,生成caffemodel(caffemodel里不僅存儲了權重和偏置等信息,還存儲了整個訓練網絡的結構信息)。在測試階段,調用每個類別的caffemodel獲得每個最精細葉節點的輸出標簽和預測概率,此時可以得到通過神經網絡輸出的逐點的預測標簽。 本文使用pcl工具可視化分割結果。簡單來說,使用八叉樹結構中的葉節點表示點云模型,使用神經網絡得到的預測標簽分別以不同顏色分類顯示分割結果的不同區域。經過CRF優化之后,本文方法得到的分割效果如圖5所示。 圖5 本文方法應用于ShapeNetCore子集的分割效果 本文還分別使用PointNet[21],SpecCNN[22],O-CNN(5)[13],O-CNN(6)[13],SPGN[23]的方法進行實驗并且與本文方法進行比較,如圖6所示,可以看出,O-CNN(6)方法在模型右側椅腿與椅座連接處噪聲明顯,本文方法則在分割相鄰區域處以及邊界處噪聲較小,邊緣更平滑,分割效果更好。為了更準確地描述分割效果的優劣,采用IoU(intersection over union)標準對以上不同方法和本文方法進行度量,該標準用于測量實際標簽值和預測標簽值之間的相關度,相關度越高,度量值越高,分割效果越好,對比結果見表2。對比結果表明,本文方法對飛機,椅子,汽車,吉他等三維點云模型都有較好的分割結果。 圖6 O-CNN(6)分割結果(a)與本文結果(b)對比 本文針對三維點云數據的計算量大以及存儲成本高的問題,使用八叉樹數據結構表示三維點云模型,同時為了避免顯式的特征提取帶來的局限性,使用兩種基礎特征相融合作為卷積神經網絡的輸入特征,利用卷積神經網絡級聯反卷積神經網絡對三維點云模型進行分割,實現了分割結果可視化,提高了實驗數據集中大多數類別的分割準確率。但是由于使用八叉樹結構表示點云模型,對于部分類的分割結果的分割區域之間存在噪聲,模型邊界處鋸齒狀明顯,在分割可視化時部分模型效果欠佳。其次由于數據量不同以及在訓練過程中存在擬合問題使各類點云的預測標簽存在誤差,需要進一步研究處理。 表2 以IoU為評價度量的對比結果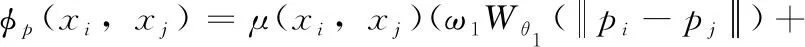
4 實驗討論
4.1 數據集與實驗環境
4.2 訓練與測試
4.3 結果與對比

5 結束語
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
