基于模塊度和標簽傳遞的推薦算法
2020-09-29 06:56:28盛俊,李斌,陳崚
計算機應用 2020年9期
關鍵詞:用戶
盛 俊,李 斌,陳 崚
(1.揚州大學信息工程學院,江蘇揚州 225000;2.揚州市職業大學信息工程學院,江蘇揚州 225000)
0 引言
隨著網民數量的增加,近年來各種推薦系統得到了廣泛的應用,可以向用戶推薦書籍[1]、產品[2]、視頻[3]和云計算服務[4]等。此外,還能向客戶推介其滿意的領域專家、合作者、娛樂節目、餐廳、服裝、金融服務、人壽保險、交友約會等。推薦系統的核心是推薦算法的設計[5]。推薦算法要能夠快速地從大量的信息中及時發現用戶的喜好與消費習慣,發現與商品有關的有價值的內容,并動態、及時地向用戶推介。根據所基于的數據分析方法的不同,主要有3 類推薦方法:協同過濾方法、基于規則的和基于內容的推薦方法。
協同過濾[6]是最常用的推薦方法。協同過濾方法的基本思想是:如果兩個人所喜好的項目很相似,其中一個人采用過的項目,另一個人很可能也會采用,并且他們會喜歡過去喜歡的類似的東西。雖然協同過濾方法已經被廣泛使用,但它還存在3 個問題需要解決:冷啟動問題、可伸縮性問題和數據稀疏性問題。如何解決這幾個問題,是協同過濾方法性能提高的關鍵。
基于關聯規則的推薦[7-8]是利用關聯規則所提供的信息,通過關聯規則來計算各種商品被用戶所偏好程度的相關性。該方法的缺點是對關聯規則的發現需要大量的計算時間,對于大型的推薦系統,很難滿足實時應用的需要。
推薦系統的另一種常見方法是基于內容的推薦[9-11],這種方法將不同的候選項與用戶先前評價的項目進行比較,推薦最佳匹配項。該類方法比較簡單,而且推薦結果具有可解釋性,易于被理解。
二部網絡是一種重要的復雜網絡形式,通常用于兩種不同類型的對象之間的關系建模。二部網絡可以用圖論中的二部圖來表示,它的頂點可以分成兩個不相交的兩種類型的集合,在同一類型的頂點間不存在連接,只有在不同類型的頂點間才可能有條邊連接。現實中的許多兩種不同類型的對象之間的關系度可以用二部網絡來描述。例如,一個足球運動員和俱樂部的關系可以用二分網絡來描述,如果球員為某俱樂部效力,在該球員和俱樂部之間就會有一個連接。二部網絡的其他的例子包括:用戶與項目的網絡[12]、公司投資者之間形成的股份網絡[13]、論文-作者網[14-15]、蛋白質交互作用網絡[16]、基因-疾病網絡[17-19]等。推薦問題主要是針對二部網絡而言的,二部網絡的加權的鄰接矩陣就是推薦問題中的用戶-項目評分表。已經有一些基于二部網絡的推薦方法,如基于二部網絡的鏈接預測的方法[20]、基于相似度網絡的個性化推薦方法[21]等。
還有一些推薦方法是基于復雜網絡社區挖掘技術的,萬慧等[22]針對電影推薦問題,提出了一種融合電影類別、用戶評分和用戶標簽的電影推薦模型。該方法基于電影類別使用凝聚式層次聚類算法進行社區劃分,在社區中進行推薦。黃泳航等[23]提出了基于社區劃分的學術論文推薦方法。該方法在社區好友關系網絡圖中進行社區劃分,根據社區劃分結果在社區內部的用戶之間推薦學術論文。賀懷清等[24]提出基于網絡社區劃分的協同推薦算法。該方法首先利用社區劃分算法對用戶進行社區劃分,使得劃分在同一社區的用戶有共同話題和愛好,接著利用同一社區的用戶尋找目標用戶近鄰集,最后根據近鄰用戶對未知項目的評分來預測目標用戶的評分。
上述的各種基于復雜網絡社區挖掘技術的推薦方法在對用戶-項目網絡進行社區劃分以后,僅僅在社區內通過用戶或項目相似度對項目進行推薦,這就限制了推薦結果只能在同一社區內進行,使得推薦結果的質量與社區劃分密切相關。對于不同的粒度、不同的社區個數,其社區劃分結果是不一樣的。這樣就很難找到一個能取得最優推薦結果的社區劃分。為此,本文提出了基于社區挖掘的推薦算法,在考慮項目之間、用戶之間的相似性的同時,還考慮社區之間的相似性對項目進行推薦。這樣可以提高推薦結果的質量。
本文用帶權的二部圖來表達用戶-項目的評分矩陣,利用二部網絡的社區挖掘的技術,提出了在二部網絡上進行社區挖掘的標簽傳遞的算法,基于社區之間的相似性和用戶間的相似性對項目進行推薦。該方法基于二部網絡中的社區結構信息,充分利用了用戶所在的社區之間的相似性,以及項目之間、用戶之間的相似性來挖掘用戶可能感興趣的項目。由于二部網絡的社區信息在一定程度上反映了用戶和項目的相似程度,算法可以取準確率較高的推薦結果。
1 二部網絡及其社區挖掘
二部網絡可用一個無向簡單二部圖G=(U,V,E)來表示,其中,E為G的邊的集合,U和V分別是G的兩部分頂點的集合。U和V兩部分頂點內部不存在連接的邊,對于所有邊(u,v) ∈E必有u∈U、v∈V。二部網絡可以用來描述推薦問題,例如圖1 所示為一個二部網絡,其中上面部分的節點表示用戶,下面部分的節點表示商品,在兩個部分的一些節點之間的連線上具有權重,表示上面部分的節點所代表的用戶對相應的商品的評分值,其值的范圍為1~5。這樣就描述了7個用戶對8個商品進行評分的推薦問題。在圖1中,有些商品和用戶的節點之間沒有連線,說明該用戶尚未對該商品評分,也可能是該項評分丟失了。在這種情況下,帶權鄰接矩陣中的相應的元素aij的值為0。圖1 中的二部網絡的帶權鄰接矩陣如圖2 所示,其中每行代表用戶類型的一個頂點,每列代表項目類型的一個頂點。這實際上是推薦問題中的評分矩陣。因此每個推薦問題對應了這樣一個加權二部圖。

圖1 二部網絡示例Fig.1 Bipartite network example
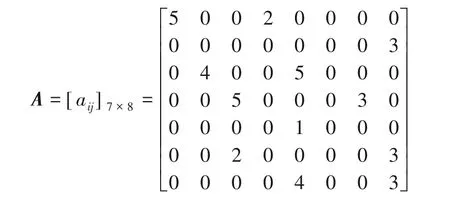
圖2 二部網絡鄰接矩陣示例Fig.2 Example of bipartite network adjacency matrix
復雜網絡往往具有社區特性,社區是由拓撲性質相似、聯系密切的頂點所組成的。設二部網絡的兩部分頂點分別稱為X部分和Y部分,二部網絡的社區挖掘的目的就是要分別把二部網絡的X部分頂點和Y部分頂點各自劃分為若干個社區,而且定義兩個部分的社區之間的對應關系,使得社區間頂點連接比較稀疏,而社區內頂點之間連接比較稠密。
自2001 年Newman[25]提出社區挖掘的概念至今,已有很多學者提出關于復雜網絡社區挖掘的方法。網絡社區挖掘的代表性方法有基于優化模塊度、基于頂點劃分、基于標簽傳播、基于仿生計算的方法以及利用Markov 隨機游走理論的方法等。
基于標簽傳播的社區挖掘方法的基本思想是任一頂點都必須和它的大部分鄰居被劃分在同一個社區里.該方法開始時將每一個頂點看作是一個社區,并給每個社區設定一個標簽,然后通過迭代將標簽傳遞,實現社區的合并。標簽傳遞的規則是:每個節點取其鄰居節點中出現最多的標簽為自己的新標簽。若鄰居節點中出現最多的標簽有多個,則根據一定的規則選取其中某一個作為自己的新標簽。經過若干次這樣的迭代后,緊密相連的節點的標簽會趨于相同,即表示它們被劃分在同一個社區。
2 興趣密度值和稠密用戶
本文首先用一個矩陣P=[pij]n*n來表示由n個用戶對M個項目的評分,將這個評分矩陣看成帶權的鄰接矩陣,可構建一個帶權二部圖G={(ui,vj)|ui∈U,vj∈V,pij>0}。這里,U為代表用戶的頂點集合,V為代表項目的頂點集合,E為邊的集合,邊(i,j)上有權重值pij>0,為用戶i對于項目j的評分。推薦問題的目標就是要對給定的用戶,計算那些沒有評分的項目的評分估計值,并將具有較高的評分估計值的一些項目向該用戶進行推薦。
在用戶和項目數增多時,社交網絡規模迅速擴大。此時,每個用戶所參與評價的項目數占總項目數的比例會迅速變小,使得評分矩陣變得稀疏,這就導致了網絡數據出現稀疏性。此外,由于用戶對某一類商品的偏好性,他的評分會集中在某一類商品上。還有由于一些商品的用戶的數量相對較少,如房屋、汽車等,用戶對商品評分也就較少,導致了在用戶-商品評分數據庫的稀疏性。此外,新增的用戶往往評分的商品較少,也會增加數據的稀疏性,從而降低推薦結果的質量。
為了解決評分矩陣的稀疏性問題,本文提出了興趣密度值來挑出用戶頂點中對項目評分較多的頂點構成稠密子集。然后在稠密子集中使用標號傳遞的算法進行社區挖掘,最終在得到的社區的基礎上進行推薦。由于將評分矩陣所提供的用戶偏好信息和網絡的拓撲特征有機地結合,使得推薦的準確度得到提高。這也是一種基于社區挖掘的推薦算法。
針對數據的稀疏性問題,為了提高推薦結果的質量,本文挑選出用戶頂點中對項目評分較多的頂點,從而從稀疏網絡中構造一個連接密集的子網絡,然后對該子網絡中的頂點進行社區挖掘。為此定義每個用戶ui的興趣密度值des(ui):

其中sign()是符號函數,定義為:

由于用戶ui的興趣密度值des(ui)反映了用戶ui評價的項目數,為此,本文設定一個閾值ε>0,定義稠密用戶集合為:

如此使得評價的項目數高于閾值的用戶定義為稠密用戶。興趣密度閾值ε的確定取決于網絡用戶側頂點連接的稠密程度。該稠密程度定義為,即為所有用戶的評論總數。在用戶側頂點連接的稠密程度較低時,用戶的評論較少,可取較低的值(如ε=0.5);在網絡連接較稠密時,可取較高的值(如ε=1.5),對于一般的網絡可取ε=1。
由于一些商品對于大部分用戶僅僅是一次性需求,如房屋、汽車等,對它們總的評價數量相對較少。此外,新增的商品往往很少被用戶所知,導致評分較少,使得這些商品在用戶-商品評分數據庫中的稀疏性。為了提高推薦結果的質量,本文挑選出項目頂點中被評分較多的頂點,從而從稀疏網絡中構造一個連接密集的子網絡。為了合理地挑選被評分較多的項目頂點,對項目頂點也定義其興趣密度值des(vj):

設定一個λ>0,定義稠密項目集合為:

類似于興趣密度閾值ε的確定,稠密項目的閾值λ的確定取決于網絡項目側頂點的稠密程度:在鏈接較稀疏時,可取較低的值(如λ=0.5);在網絡鏈接較稠密時,可取較高的值(如λ=1.5);對于一般的網絡可取λ=1。
用連接密集的子網絡中的用戶及其相關項目構建新的評分矩陣P',同時由P'構建原二部圖的子圖G'=(U′,V′,E′)。然后在新的二部圖G'中利用標簽傳遞進行社區挖掘,這樣可以把用戶和項目一起聚類為若干社區,從而利用社區信息來計算相似度,再進行推薦。本文根據興趣密度值選取稠密的用戶頂點和項目頂點構成新的二部網絡,其優點是使得對項目的推薦的信息集中在用戶最感興趣的項目上,其參考信息也來源于參與評分最活躍的用戶中,這就使得推薦結果的準確率得到提高。此外,由于減少了二部網絡中的頂點的個數,可以提高算法的執行速度。
3 標簽傳遞算法
在對二部網絡劃分社區時,本文用模塊度作為度量社區劃分結果質量的標準。設U、V兩部分各有p、q個頂點,社區劃分結果的模塊度定義如下:
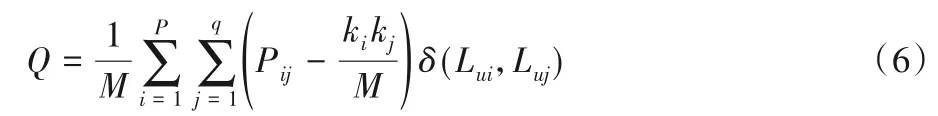
這里,用i=1,2,…,p表示集合U中的頂點u1,u2,…,up;用j=1,2,…,q表示集合V中的頂點v1,v2,…,vq;ki、kj分別表示頂點ui、vj的度。用Lui代表頂點ui所歸屬的社區的標簽,用Lvi代表頂點vi所歸屬的社區的標簽,指示函數δ(Lui,Luj)的定義為:

若ui與vj歸屬于同一個社區,則δ(Lui,Luj)的值為1;否則值為0。式(6)中的M為二部網絡中所有邊上的評分值之和:。為了找出具有最大模塊度的社區劃分,文中對網絡中每一對頂點定義了一個模塊度增量,頂點ui、vj之間的模塊度增量定義為:

所有頂點對的模塊度增量構成了p*q的矩陣B=[bij],稱為模塊度增量矩陣。
對照式(6)和(7)可以發現,頂點ui、vj之間的模塊度增量bij的值的大小表示整體模塊度增加的程度。如果模塊度增量bij較大,頂點ui與vj就歸屬于同一個社區。所以本文的算法目的就是逐次挑選模塊度增量值較大的頂點對,將其劃歸同一個社區之中。根據這樣的想法,本文提出標簽傳遞算法來劃分社區。
首先,在原有網絡的頂點集上構造一個帶權完全圖,該圖每條邊上的權重為它所連接的節點對的模塊度增量。一開始,把一個頂點看成一個社區,并給它定一個標簽,然后將各個頂點的標簽根據邊上的模塊度增量在完全圖中進行傳遞:節點之間傳遞標簽的概率會隨著模塊度增量的增大而增大。如此,它們就越有可能被劃歸到同一個社區。在傳遞標簽時,通過迭代把每個節點的標簽根據其鄰居節點的標簽來逐次更新,將每個頂點的標簽更新為其鄰居頂點中邊的權重值之和最大的標簽。因為邊上的權重值就是模塊度增量,而邊上模塊度增量又與該頂點連接,其值越大,取相連接的節點的標簽的可能性就越大,它們也就越可能被劃分到同一個社區。這樣可以將模塊度增量較大節點對劃歸到同一個社區中。重復上述標簽傳遞過程,直到網絡中的頂點的標簽不再變化時為止。此時得到的社區劃分會具有最大的整體模塊度。
基于模塊度增量和標簽傳遞的社區挖掘算法的框架如下:


經過算法1 的處理,將稠密的用戶和項目分別劃分為若干社區,其中用戶的每個社區與一個項目社區對應。對于非稠密用戶,將其劃歸到其感興趣的項目最多的社區之中。設I(uj)為非稠密用戶uj的感興趣的項目集合,記I(Ci)為第i個社區Ci中的項目集合,將用戶uj劃歸到其感興趣的項目最多的社區Ck(j):
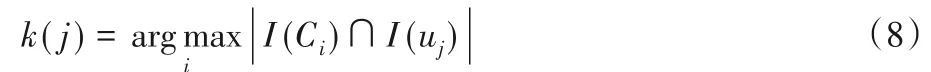
社區的再劃分實際上是將用戶和項目的集合各自劃分成許多不重疊的社區,在用戶社區和項目社區之間存在一一對應關系,相對應的用戶社區和項目社區一起構成了一個網絡的子圖。在該子圖中,用戶之間和項目之間的相似度如果較高,用戶和項目之間的相關性也會較高。
算法1 的標簽傳播規則讓模塊度增量較大的節點對之間的標簽傳播概率越大,這本質上是在使模塊度最大化,這樣使得算法的社區劃分的準確率較高。由于算法1 的標簽傳播過程簡單易行,每輪迭代所需的時間為O(max{p,q}),因此算法時間復雜度較低。算法1 的另一個優點是,社區的個數無需作為參數預先指定,而是由算法取得使模塊度最大化的社區的個數。
4 基于社區劃分的推薦算法
利用算法1 將用戶和項目劃分成社區,使得最相似的用戶以及他們最感興趣的項目劃歸于同一個社區,就可以基于社區的信息進行推薦。本文在社區挖掘的基礎上,提出對指定用戶的項目評分的推薦算法。記用戶v所在的社區為U(v),項目j所在的社區為I(j),用戶u和v所在的社區U(u)和U(v)的相似度為SU(u,v),項目i和j所在的社區I(i)和I(j)的相似度為SI(i,j)。算法主要有4步:
步驟1 計算項目社區之間、用戶社區之間的相似度。
項目社區I(i)和I(j)之間的相似度定義為:
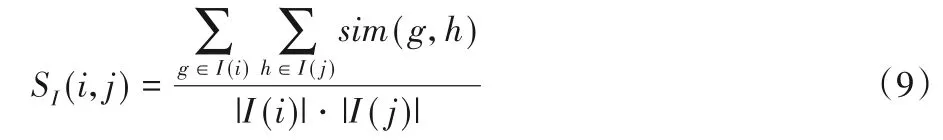
這里,sim(g,h)為項目g和h的相似度,可以通過計算評分矩陣相應列向量的余弦相似度或者相關系數得到。
用戶社區U(i)、U(j)之間的相似度定義為:
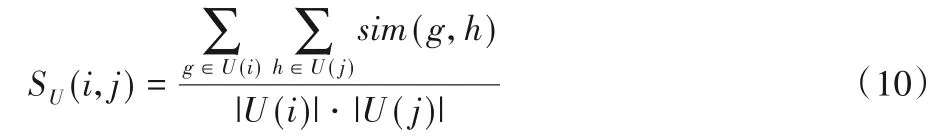
其中,sim(g,h)為用戶g和h的相似度,可以通過計算評分矩陣相應行向量的余弦相似度或者相關系數得到。
步驟2 計算每一個用戶u的相對于項目j的評分均值

其中:I(u)為用戶所評價的項目的集合,SI(j,k)為項目j和k所在的社區I(j)和I(k)的相似度。
步驟3 根據用戶間的評分偏差和用戶的歷史評分,預測用戶對未評分物品的評分。還要計算用戶u對項目j的評分puj。在對用戶和項目進行社區劃分后,首先判斷用戶u和項目j的社區U(u)和I(j)是否為相對應社區。若是,用戶u對項目j的評分puj可以在U(u)和I(j)構成的子圖中進行,計算公式為:
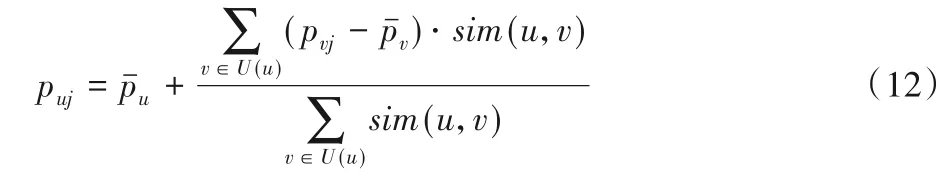
若用戶u和項目j的社區U(u)和I(j)不是相對應社區,則要參考其他社區的信息以及社區間的相似度來計算用戶u對項目j的評分puj,計算公式為:
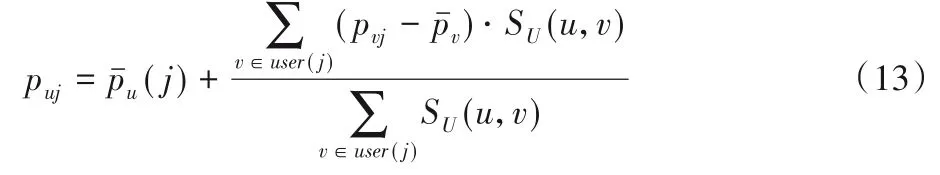
其中,user(j)是給項目j評分過的用戶的集合,SU(u,v)為用戶u和v所在的社區之間的相似度。在式(13)中,(j)為用戶u對項目j的所在的社區的所有項目評分的均值,后面的一項為對用戶u對項目j的偏好值的估計。這個估計值為所有給項目j評分過的用戶v對項目j的偏好值的加權平均。權重為用戶u與v所在社區的歸一化相似度。計算過程如圖3所示。
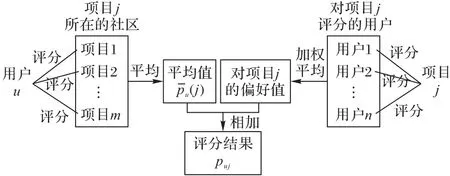
圖3 評分puj的計算過程Fig.3 Computation of the score puj
從式(13)可見,對于某個用戶來說,與他所在的社區相似度較高的社區里的用戶的評分對他的推薦結果會產生較大的影響。
步驟4 對所得到的對項目的預測評分進行排序,將其中得分最高的N個項目向用戶進行推薦。
下面給出基于社區挖掘的社交網絡推薦算法的框架:

算法2 通過對二部圖進行社區挖掘,對用戶進行分類,然后根據用戶對項目的偏好以及用戶所在的社區間的相似度,再參考相關內容進行推薦。具有簡單易行、效率高、推薦準確性較高的優點,還能有助于挖掘用戶對一些項目潛在的偏好。
5 實驗結果與分析
本文用電影網站數據集MovieLens 和Recsys 提供的Yelp消費評論的數據集,對上述基于社區挖掘的推薦算法CMBR進行實驗,并將實驗結果與類似的推薦算法進行了對比分析。文中采用Matlab 編碼,在中央處理器為3.2 GHz,內存為8 GB,Windows 7,64位操作系統的計算機上運行。
5.1 實驗數據集
5.1.1 MovieLens數據集
電影網站MovieLens數據集由GroupLens Research 實驗室搜集整理。該數據集包含一些用戶信息、電影信息以及電影評分,是一個最常用的實驗數據集。本文選擇數據集中100K大小的數據,包括1 682 部電影、943 個用戶、100 000 個評分,評分值為1~5。
5.1.2 Yelp消費評論數據集
此數據集記錄了Yelp 網站在美國亞利桑那州的每個顧客、每個商家的信息和他們的評分。該數據集被劃分為訓練集和測試集兩部分:訓練集中有商家12 742 個、顧客51 296個、評分252 863 條;測試集中有商家8 341 個、顧客15 001 個、評分36 404條。顧客的評分值為1~5。
上述兩個數據集都是比較稀疏的。數據的稀疏度為未評分的數目占總體的百分比,稀疏度越大,數據集就越稀疏。
MovieLens 數據集共有943 個用戶、1682 部電影以及100 000 條電影評價,訓練集的稀疏度約為93.695%;Yelp 消費評論數據集中有20 萬個顧客評分數據,其中有22 829 個用戶僅有一個評分,Yelp訓練集的稀疏度大約為99.961%。
5.2 推薦結果的評價指標
對于推薦結果的質量評估的最常用的指標是平均絕對差(Mean Absolute Error,MAE)和準確率(precision)。
5.2.1 平均絕對差
在統計學中,平均絕對誤差(MAE)是兩個連續變量之間的差值。在推薦問題中,平均絕對差定義為用戶對項目的實際評分與推薦算法計算的評分之間的差。設用戶對k個項目的實際評分值為{r1,r2,…,rk},推薦算法計算得到的相應的評分值為{p1,p2,…,pk},平均絕對偏差的計算公式如下:

由式(14)可以看出,較小的MAE 值表示推薦結果的精度較高。
5.2.2 準確率
在推薦問題中,設用戶對k個項目的實際評分值為R={r1,r2,…,rk},而推薦算法計算得到的相應的評分值為I={p1,p2,…,pk},那么準確率的計算公式如下:
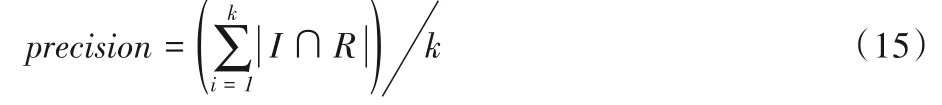
即為所推薦的正確項目的個數所占的百分比,其值在0~1,推薦結果越精確,準確率的值就越高。
5.3 實驗結果及分析
本文把基于二部網絡劃分的標簽傳遞社區挖掘推薦算法(CMBR)與其他4 種算法的預測結果準確度和平均絕對差進行比較。這4 個算法分別是基于雙向關聯規則項目評分預測的推薦算法(Collaborative Filtering recommendation algorithm based on item rating prediction using Bidirectional Association Rules,BAR-CF)[27]、基于項目評分預測的推薦算法(Collaborative Filtering recommendation algorithm based on Item Rating prediction,IR-CF)[28]、基于網絡鏈接預測的用戶偏好預測方法(user Preferences prediction method based on network Link Prediction,PLP)[29]和改進的基于用戶的協同過濾的方法(Modified User-based Collaborative Filtering,MU-CF)[30]。從數據集中,觀察到用戶評論的條數的分布大部分集中在4~20,也就是說用戶側頂點的近鄰個數集中在4~20。為了測試在各種近鄰個數下不同算法的結果的平均絕對差,本文在實驗中對4~20、間隔為4 的不同近鄰數進行測試。實驗結果如表1所示。
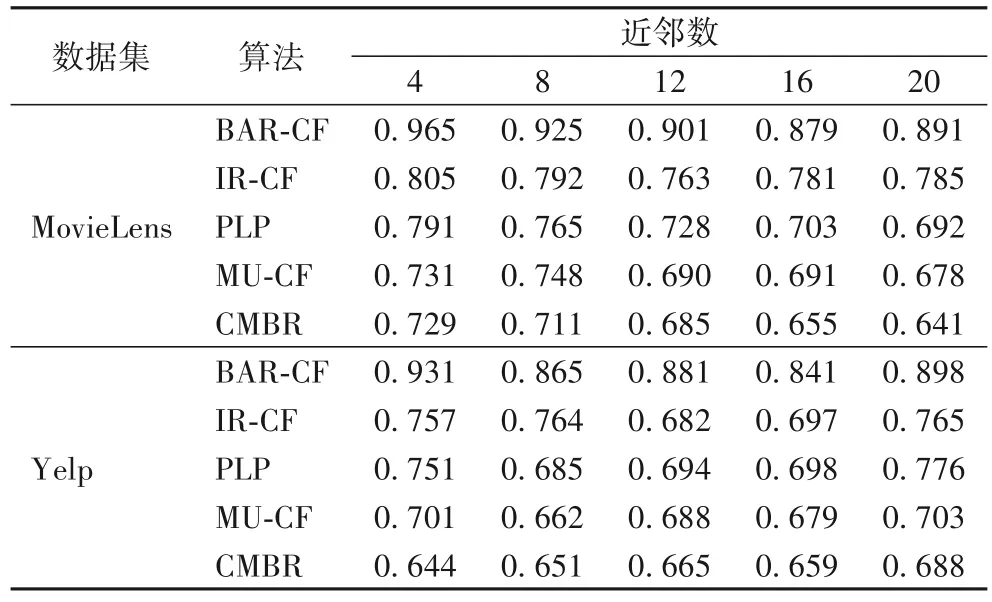
表1 兩個數據集上各種算法在不同近鄰個數下的平均絕對差Tab.1 Average absolute errors of various algorithms on two datasets under different neighbor numbers
由表1 可以看出,算法CMBR 在兩個數據集上對于各種近鄰數都可以取得最低的MAE 值。這說明算法CMBR 能夠比其他算法取得更好的推薦效果。同時也可以看出,較大的近鄰數可以取得準確率較高的推薦結果。
為了進行更全面的性能比較,本文采用5 折交叉驗證進行實驗,需要進行5次重復實驗。文中將數據集隨機地分成5個部分。在每次實驗中用其中的4 個部分作為訓練集、剩下的一個部分作為測試集。如果5次實驗得到的MAE值的標準差小于閾值0.024,則取5 次測試結果的MAE 值的平均值作為MAE估計值。各種算法對于MovieLens和Yelp數據集上的平均MAE值如圖4所示。
由圖4可見,隨著近鄰數的增加,各種算法的MAE值都有所降低。但在相同的數量的最近鄰居時,本文的推薦算法CMBR 的平均絕對偏差(MAE)比其他的推薦算法更小,推薦結果的精度更高,這表明文中所提出的基于二部網絡劃分的標簽傳遞社區挖掘推薦算法CMBR優于其他的推薦算法。
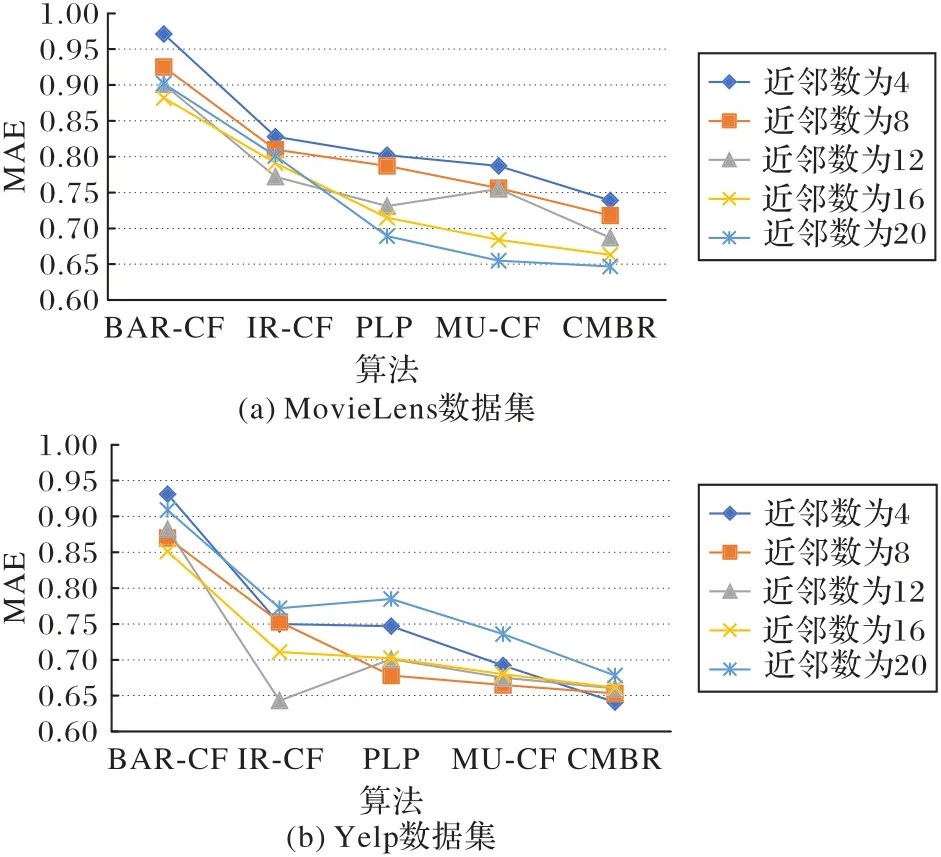
圖4 兩個數據集上各種算法在不同近鄰數下的平均MAE值對比Fig.4 Average MAE value comparison of various algorithms on two datasets under different neighbor numbers
本文還測試了所提出的CMBR 算法的推薦結果與真實結果進行比較得出的準確率,并與其他四個算法在兩個數據集上進行了比較,用得分最高的10 個項目作為推薦結果,其準確率的比較如圖5所示。
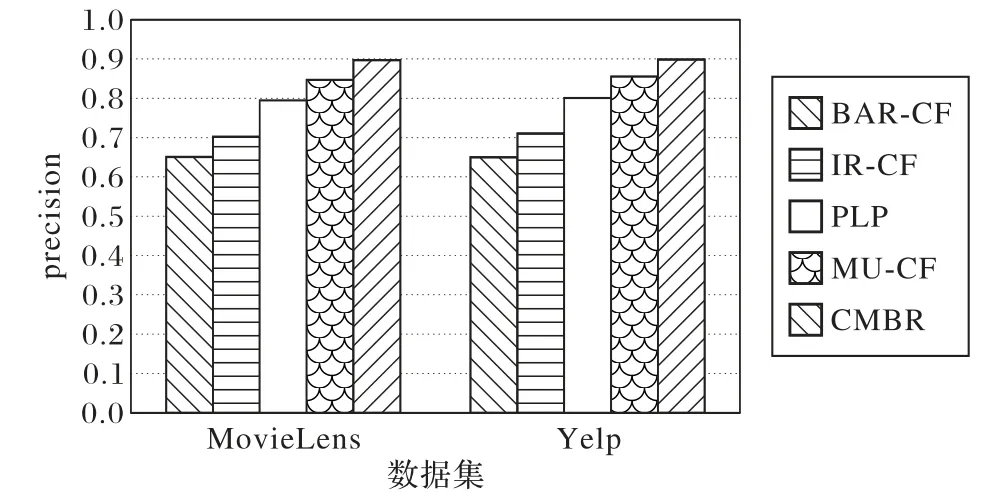
圖5 各種算法推薦結果的準確率比較Fig.5 Precision comparison of recommendation results of various algorithms
由圖5 可以看出,相較于其他的推薦算法,算法CMBR 在兩個數據集上皆具有較高的準確率,取得較精確的推薦結果,說明本文提出的基于二部網絡劃分的標簽傳遞社區挖掘推薦算法CMBR 明顯優于其他的推薦算法。本文算法之所以能有效地提高推薦結果的準確率,是因為它充分利用了二部圖的社區信息和用戶-項目的評分信息,有機結合了用戶和項目之間的評分信息和二部網絡的拓撲結構[31]。
6 結語
本文提出了基于模塊度和標簽傳遞的推薦算法,該方法基于二部網絡中的社區結構信息,充分利用了用戶所在的社區之間的相似性,以及項目之間、用戶之間的相似性來挖掘用戶可能感興趣的項目。實驗結果也證明,該算法可以取得比其他類似方法更高準確率的推薦結果。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
