分布式存儲系統中的日志分析與負載特征提取
2020-09-29 06:56:24茍子安吳東南王艷秋
計算機應用 2020年9期
茍子安,張 曉,2*,吳東南,王艷秋
(1.西北工業大學計算機學院,西安 710129;2.工信部大數據存儲與管理重點實驗室(西北工業大學),西安 710129)
0 引言
隨著企業數據量的快速增長,大規模的數據處理成為一個具有挑戰性的問題,尤其是大數據的高性能存取,直接影響著對上層的服務質量。Hadoop 分布式文件系統(Hadoop Distributed File System,HDFS)[1]是Hadoop 項目的核心子項目,是分布式計算中數據存儲管理的基礎。它具有高容錯性、高可靠性、高可擴展性、高吞吐率等特點,為超大數據集的應用處理和存儲帶來了許多優勢。分析Hadoop 集群上工作負載的特性是提高分布式文件系統性能的關鍵。針對不同類型應用的訪問特征,分布式存儲系統可選擇不同的緩存策略或數據布局方式來進行性能優化[2]。
然而,Hadoop 集群上的工作負載分析,特別是在大型的生產環境中,主要局限于集群的負載特征采集[3]。本文提出了一種離線的負載特征采集和分析方法,通過對HDFS 中各個節點日志的關鍵信息進行提取和處理,來描述運行在其上的多客戶端和多個應用的負載特征。由于MapReduce將任務分布在不同節點運行,任務和數據的分布,以及規模和調度的變化都會影響工作負載的特征[4],因此基于靜態分析獲取工作負載特征的方法是不準確的,并且在混合多種應用的集群中靜態分析的方法存在更多的問題[5]。從節點日志收集到的動態數據足以準確描述工作負載,并提供應用程序輸入/輸出(Input/Output,I/O)工作負載的估計和預測。通過日志分析獲取負載特征具有3 個優勢:1)低開銷,采用離線分析方式,不會占用HDFS 的I/O 帶寬等資源,因此不會影響到上層應用的性能,數據采集和分析的成本較低;2)高時效,HDFS 的I/O等信息會同步的反映到日志上,因此對日志的實時分析具有一定的時效性;3)易于分析,基于日志的方法對負載分析提供了一定的便捷,例如對于匯聚起來的HDFS 集群訪問信息,在日志中可以很容易地根據網際互連協議(Internet Protocol,IP)地址來對客戶端進行區分等。
本文的主要貢獻如下:
1)建立了一個分布式日志數據提取框架,通過在元數據節點和數據節點實時的日志處理,來提取I/O操作相關的關鍵信息。
2)建立了一個通用的模型對提取出的I/O 信息進行分析,以描述負載統計和時序特征,并通過與現有的benchmark對比驗證了模型方法的可行性與準確性。
3)說明了利用負載統計和時序特征進行負載均衡、智能預取等HDFS優化的可行性。
此外,本文提出的日志分析與負載特征提取方法還可用于任務調度、緩存管理、數據分布的優化,也可以用于HDFS集群性能實時監控、定位熱點數據與節點等[6]。
1 背景
1.1 HDFS架構
HDFS 是一種主/從架構,如圖1 所示,一個HDFS 集群由一個元數據服務器(NameNode,NN)和多個數據服務器(DataNode,DN)組成。其中,NameNode 執行例如打開、關閉、重命名等文件系統命名空間的相關操作、控制客戶端對文件的訪問和維護數據塊到DataNode 的映射關系等。此外,集群中的每一個數據服務器通常是一個DataNode,負責為文件系統客戶端的讀取和寫入請求提供服務,同時處理NameNode發來的數據塊創建、刪除和復制等指令。
HDFS 為了保證可靠性,需要對數據進行冗余備份,通常是三副本策略,即存儲一個文件塊的同時還存儲兩個冗余塊。客戶端在讀取文件時,首先會聯系NameNode 獲取文件的元數據,包括文件塊信息以及每個塊的存儲信息等,隨后客戶端會在三副本所在DataNode 中選擇一個物理拓撲上最近的節點,與其建立傳輸控制協議(Transmission Control Protocol,TCP)連接并進行讀取。而對于文件的寫入,客戶端首先需要聯系NameNode,為待寫入的文件塊在命名空間中創建元數據信息,隨后,NameNode 向客戶端返回的元數據中包含應持久化存儲這個文件塊的三個DataNode 的相關信息,客戶端與之建立相應的pipeline,并將文件塊寫到管道流中的第一個DataNode 上,具體在寫入時傳輸的單位是packet,第一個DataNode 收到packet 后會傳給管道流中后續DataNode,并等待確認字符(ACKnowledge character,ACK),以此類推,當客戶端接收到最后一個packet 的ACK 后,標志著這個塊的寫入完成,并開始下一個塊的傳輸。
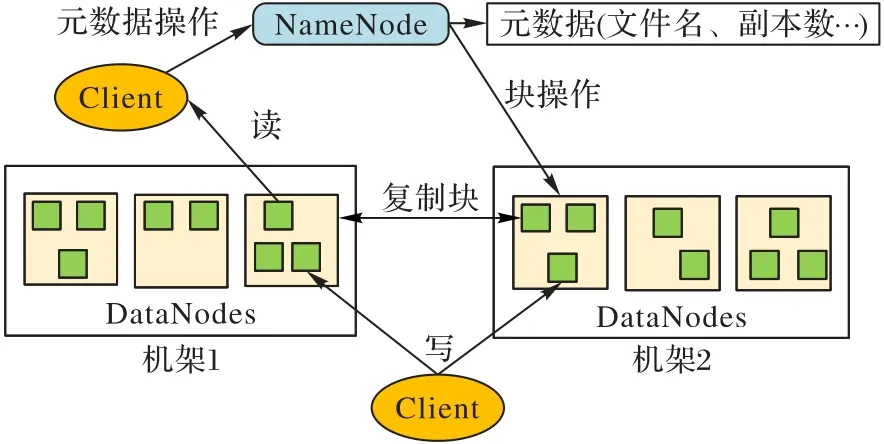
圖1 HDFS架構Fig.1 HDFS architecture
1.2 Hadoop log
Hadoop的日志有很多種,主要分為Hadoop系統服務輸出日志和MapReduce 程序輸出日志兩大類,Hadoop 系統服務輸出日志是指諸如NameNode、DataNode、ResourceManager 等系統自帶的服務輸出的日志,MapReduce 程序輸出日志則包括作業運行日志和任務運行日志[7]。
在Hadoop 系統服務輸出日志中,文件系統元數據日志位于NameNode 節點,客戶端對分布式文件系統命名空間的所有修改均可以在該日志中查看到,例如,在寫入一個文件時需要在命名空間中創建對應的元數據信息,因此日志中可以查看到寫入該文件的客戶端IP,文件所有塊的標識(Identity Document,ID)、大小以及分布等。此外,客戶端對文件的讀寫操作也可以在元數據日志中查看到,例如,客戶端讀取文件時通過open 操作來獲取元數據,日志中則可以看到open 操作對應的客戶端IP。文件系統數據日志位于各個DataNode 節點上,該DataNode 上所有數據塊的I/O 信息均可以從日志中查看到,例如數據塊的詳細讀寫信息,包括塊操作的源和目的IP 地址、被操作的塊ID 和大小以及操作的持續時間等。分布式文件系統客戶端將日志輸出在其被調度到的Hadoop 節點上,日志中主要包含客戶端的相關配置等基礎運行信息,以及一些讀寫時的詳細信息等,例如讀取時聯系NameNode 獲取的文件塊分布等元數據信息。由此可見,分布式文件系統客戶端對整個Hadoop 集群的操作基本可以反映在Hadoop 系統服務輸出日志中,因此從分布式節點日志中收集的數據足以表征客戶端和集群的工作負載特征,并提供應用程序I/O工作負載的估計和預測。
此外,Hadoop 日志庫將日志分為5 個級別,分別為DEBUG、INFO、WARN、ERROR 和FATAL。這5 個級別對應的日志信息重要程度依次從低到高,Hadoop 只輸出級別不低于設定級別的日志信息。即級別設定為DEBUG 時,這5 個級別的日志信息都會被輸出。
2 相關工作
已有研究證明,深入了解I/O工作負載特征對于分布式系統的資源調度與性能調優至關重要[8-10],文獻[11-13]從后端磁盤陣列(Redundant Arrays of Independent Disks,RAID)控制器或文件系統I/O 控制器采集數據,得到應用程序的I/O 負載特征。這種采集方式無法很好地應用到Hadoop 等分布式環境中,因為實際生產環境的集群規模往往很大,基于硬件存儲設備的負載特征采集開銷較大、成本較高。基于訪問trace 的分析方法成本較低,并且證明是有效的,文獻[14]分析了清華大學校園云存儲系統Corsair 的文件系統快照和5 個月的訪問trace,以研究學生團體對該云存儲系統使用的負載特征,包括文件大小、類型和讀寫比等。但是目前在諸如Hadoop 等分布式環境中,對其底層文件系統的工作負載研究還不夠深入,盡管最近的一些研究[15-18]對Hadoop 生產環境的trace 進行采集,并對I/O工作負載和數據分布進行了表征,但僅僅與現有一些服務的工作負載進行了比較,得出了啟發式的規律,或是用于合成基準測試進行性能評估,沒有考慮對系統進行性能優化。文獻[19-22]使用基于trace的分析方法獲取負載特征并指導集群的優化,但是其特征的采集要么通過對Hadoop JobTracker的trace進行處理,以獲取job的遞交時間、完成時間以及job結構等信息,要么通過對Hadoop YARN 日志進行處理,提取有關job 和task 的統計信息。對特征的采集僅僅專注于應用層上,負載的描述也是關于job的信息,沒有關注上層應用對底層分布式文件系統的影響,在負載的描述上可能不十分地準確與全面。此外,這些研究的trace 采集時間也長至幾周到幾個月不等,對系統的優化沒有即時的幫助,無法適應工作負載的變化,并且研究也是先有了trace 才分析得到負載特征,這樣得出的結論和該trace的相關性較大,系統的優化十分局限。
本文旨在以低開銷的trace 分析方法,先建立負載分析模型,再對分布式系統日志進行處理。首先,系統的調優不局限于某一具體的trace,也無需長時間的采集;其次,模型可以根據集群的負載以固定的時間間隔運行,也可以按需運行,其輸出結果可以對HDFS 做到及時的反饋,以適應工作負載的變化;最后,負載特征的描述采用文件系統層級的信息,與應用層相比在負載的描述上更加全面,對分布式存儲系統的優化更具有意義。這些在先前的研究工作中是沒有的。
3 設計與實現
3.1 模型架構簡述
模型架構如圖2 所示,共分為兩個模塊:數據收集器和數據分析器。數據收集器從NameNode 與DataNode 的日志中根據關鍵字抽取出與讀寫相關的日志記錄,并根據這些日志記錄的數據結構提取讀寫原始數據。數據分析器對這些讀寫原始數據進行分析與計算得到負載特征,并據此進行負載描述與HDFS 優化。具體的,數據分析器的主要功能又分為兩部分:用于指導負載均衡的負載統計分析與用于指導智能預取的負載時序分析。本文提出的模型利用數據庫進行中間數據交互,對HDFS 日志提供的信息進行分析,將分析結果再反饋給HDFS進行優化,形成了一個閉環正反饋系統。
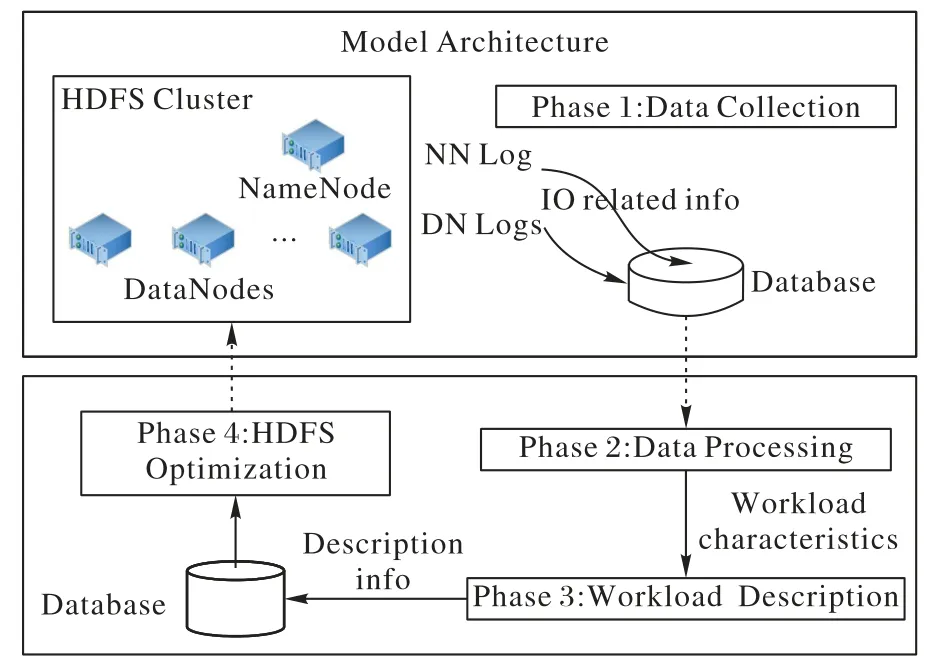
圖2 模型架構Fig.2 Model architecture
3.2 日志數據結構
本文用于描述負載特征的原始數據均采集自Hadoop 分布式節點日志,通過設置關鍵字來對日志文本進行處理,找出包含有關讀寫信息的日志記錄,并對這些結構化日志記錄中的數據進行提取以作后續分析,下面說明數據收集器選取的每一個關鍵字并簡單描述其對應的內容。
cmd=open NameNode日志關鍵字、DEBUG 級別、文件打開操作時生成,記錄了有關客戶端讀取的詳細信息,包括時間戳、執行讀操作的客戶端IP、打開文件的絕對路徑等。
NameNode.create NameNode 日志關鍵字、DEBUG 級別、文件寫入前在命名空間創建元數據時生成,記錄了有關客戶端寫入的詳細信息,包括時間戳、寫入文件的絕對路徑、執行寫操作的客戶端IP等。
HDFS_READ DataNode 日志關鍵字、DEBUG 級別、塊讀取時生成,記錄客戶端讀取該塊的詳細信息,包括時間戳、讀取塊的客戶端IP、讀取字節數(通常略大于塊的數據大小)、操作持續時間等。
HDFS_WRITE DataNode 日志關鍵字、INFO 級別、塊寫入時生成,記錄pipeline中該塊寫入的詳細信息,包括時間戳、pipeline 上游節點IP、寫入字節數(通常是塊的數據大小)、操作持續時間等。
此外,還有一些關鍵字,例如Block* allocate 日志中包含文件名與塊ID 列表,op:AddBlockOp 日志中包含客戶端IP 與其寫入塊的ID 列表,這些對負載特征的提取也有一定的用處,可以幫助從日志數據中構建一些必要的映射關系,因此本文在數據收集器中也加入了對它們的采集。
本研究基于DEBUG 日志級別,而Hadoop 默認的日志級別為INFO,因此數據收集器的工作需要將Hadoop 日志級別修改為DEBUG,這可能會造成集群性能的下降,本文將在4.2節詳細討論其影響。需要注意的是,可以通過將DEBUG 級別的日志在源碼上改為INFO 級,來避免對性能可能造成的影響,但是本文沒有采用這種設計,原因是這樣的設計在將模型移植到其他的集群上工作時,需要對集群源碼修改并進行編譯,操作較為復雜,使模型的可移植性變差,而修改集群日志級別僅僅需要更改配置文件中的參數即可,操作方便。此外,對源碼中日志級別的修改,一定程度上會影響調試過程,違背代碼編寫的初衷,因此本文采用了修改集群日志級別這種源碼無關的設計。
3.3 原始數據采集
模型設計為離線的工作方式,可以在一天內以固定的時間間隔運行,其間隔可以根據系統負載情況進行適當的調整,也可以按需運行,分析特定應用執行時間范圍內的日志信息。利用3.2節描述的NameNode和DataNode日志關鍵字,并行地對集群各個節點日志目錄下的系統服務輸出日志進行文本分析,可以跟蹤并獲取到具體的I/O 相關信息,將這些原始數據保存于數據庫中以做后續使用,至此便完成了模型的數據收集階段。此外,Hadoop 系統服務日志會不斷生成,并且舊的歷史日志會以特定格式重命名并備份,因此日志量可能會較大,本文模型會記錄各個節點上次的日志處理位置,以實現數據的增量收集,提高處理效率。模型運行時有兩個輸入參數,分別是負載分析的開始和結束時間戳,后續的數據處理階段會根據這個時間戳從數據庫提取原始數據,這樣可以根據需要分析某個特定時段的負載特征。
數據收集器根據3.2 節描述的日志記錄結構,從NameNode 日志中提取出客戶端的讀寫信息并存儲到數據庫中。這些讀寫日志記錄是客戶端混合的,后續需要按IP 來進行區分,但考慮客戶端數目較多可能需要大量的表去存儲,因此本文將不同客戶端的讀寫原始數據按時序存入數據庫的同一張表中。該表包含五個字段:操作時間戳、客戶端IP、操作名、操作文件名稱和該文件的大小。需要注意的是,NameNode日志中無法提取出有關文件大小的信息,但是為了便于后續的負載特征計算,這里設計了這個保留字段。
在DataNode端,按時序提取出該節點的塊讀寫信息并存入數據庫中,每個DataNode維護一張表來保存該信息。該表包含四個字段:操作時間戳、操作名、操作塊ID和操作數據大小。對于HDFS寫操作,操作數據大小即為該數據塊的大小,利用這一點,通過日志數據建立塊ID到塊大小的映射以及文件名到塊ID的映射來獲取文件大小,以填充上述保留字段。當然,使用HDFS的du子命令也可以獲取文件大小,但是本研究的目的是設計一個離線分析工具,在線對HDFS進行du操作,當文件數目較多時會對集群的性能造成影響。對于HDFS讀操作,操作數據大小偏大于該數據塊的實際大小,因為在塊讀取時,HDFS會為數據塊生成校驗和信息,因此這個操作數據大小僅可用來計算和讀取量有關的負載特征。最后,整個系統模型統一維護一張表,該表僅有兩個字段:Hadoop設備IP和該節點提取的最后一條日志記錄的時間戳,下次該節點直接提取該時間戳之后的日志記錄中的數據,以加速數據收集過程。
3.4 負載統計分析
負載統計分析的目的是對HDFS 集群進行負載均衡,因此,需要了解客戶端與集群的負載統計情況,利用這些統計數據去充分描述負載。在負載統計特征選取時,對于客戶端來說,選取的特征應盡可能反映客戶端的基本讀寫類型及其對集群讀寫負載的影響等。而對于集群,應盡可能反映整個集群的讀寫承載情況以及各個節點的負載變化等。在客戶端與集群兩方面進行負載統計特征選取,有助于較為準確、全面地了解集群的承載情況及其可能發生的變化。此外,在進行特征選取時,要盡可能從不同的角度去進行描述,以免冗余。具體負載統計特征的選取及其描述見表1。

表1 負載統計特征Tab.1 Workload statistical characteristics
為了獲取上述負載統計特征,數據分析器首先需要處理NameNode日志中提取出的客戶端文件讀寫信息,區分客戶端并獲取不同客戶端的讀寫時序流。其次,處理從DataNode 日志中提取出的塊讀寫信息,獲取文件塊在集群中的讀寫分布。最后也是最重要的,需要根據日志中提取出的原始數據建立一些必要的映射關系,例如文件名到塊ID 的映射、文件到文件大小的映射等,這些映射關系就像橋梁,連接NameNode 與DataNode 日志中分析出的信息,從而得到負載統計特征。通過建立映射來進行分析的優勢是可以準確得出負載統計特征的數值,例如HDFS 的寫入中pipeline 上游節點接收數據后會寫往下游節點,因此下游節點的DataNode 日志中該數據塊寫入的源IP 即為上游節點的IP 地址,但是這次寫入操作并不能計算在上游節點客戶端的寫入中,而通過NameNode 日志可以分析出具體某一個客戶端寫入的所有文件名稱,通過文件名到塊ID 的映射以及每個DataNode 上的塊寫入信息,可以準確得到這個客戶端在集群上的寫入分布以及寫入總量。
數據分析器可以通過分析日志直接得到不同客戶端的文件讀寫流、文件讀寫分布、文件讀寫量以及不同DataNode 上的讀寫承載,以這些負載特征數據為基礎,數據分析器可以計算輸出表1 所描述的所有負載統計特征,例如通過客戶端的文件讀寫流可以計算出該客戶端的每秒讀寫次數(Input/Output Operations Per Second,IOPS)等。此外,數據分析器可以通過分析集群的讀寫承載來進行負載均衡,例如某個節點讀取承載過多時,說明該節點存儲的文件塊較多,可以通過HDFS 的balancer 子命令使集群數據自動遷移達到均衡,一定程度上降低該節點的讀取負擔[23],另一方面,可以結合客戶端的負載統計特征,當某個客戶端在該節點讀取較多時,上層MapReduce 應用程序可以將該讀取任務適當調度到文件塊所在的其他節點上,以此來達到負載均衡。
3.5 負載時序分析
負載時序分析的目的是進行智能預取,鑒于HDFS的讀取等操作大多是在文件層級上的,因此本文選擇客戶端的文件讀取流作為負載時序特征的一部分,同時數據分析器也會更加細粒度地給出客戶端按時序、跨節點的塊讀取流,以適應更多的智能預取算法。為了得到客戶端的負載時序特征,數據分析器同樣需要用到NameNode 日志中提取出的客戶端文件讀寫信息,以從不同客戶端的讀寫時序流中獲取其文件讀取流。而按時序、跨節點的塊讀取流則可以從DataNode 的塊讀取日志中分析得到,如3.2 節中所述,“HDFS_READ”日志中詳細包含了某個客戶端從某個節點上讀取的塊ID及時間戳。
數據分析器可以通過對客戶端負載時序特征進行文件訪問模式分析得出文件預取信息,并顯式調用HDFS集中式緩存管理指令對文件塊進行緩存[24],這是HDFS自身提供的一種顯式緩存機制,允許用戶根據存儲路徑指定HDFS中的文件或目錄并將其緩存在內存中,NameNode通知存儲該文件數據塊的DataNode 將數據塊緩存在進程Java 虛擬機(Java Virtual Machine,JVM)的堆外內存中,MapReduce 應用程序可以根據從NameNode查詢到的元數據獲取緩存塊的分布,隨后再次發生緩存文件的讀取時,可以將客戶端調度到緩存塊所在的節點上,通過調用HDFS 源碼中提供的零拷貝函數,直接從內存中獲取所需數據塊,一定程度上提升客戶端的讀取效率。
此外,數據分析器也可以結合所獲取的負載統計與時序特征來進行智能預取,例如可以通過負載統計特征來對客戶端進行分類,為不同訪問模式的客戶端選取不同的緩存策略,對HDFS 分布式日志的后續跟蹤分析中,如果發現了客戶端訪問模式的匹配,則可以用相應的預取模型對其負載時序特征中的文件訪問流進行分析,從而得出需要主動緩存的預取文件。在本文提出的模型中,數據分析器除了文件級別的負載時序特征,還給出了更加細粒度的按時序、跨節點的塊級別負載時序特征,因此使得智能預取的策略選擇更加靈活和普適,并且緩存預取不會僅僅局限于文件層級。
4 實驗評估
4.1 實驗基礎環境
實驗搭建的Hadoop 集群共由6 臺服務器組成,包括1 個NameNode、4 個DataNode 和1 個沒有存儲數據的DFSClient 節點,Hadoop 版本為2.9.0。NameNode 所在的服務器的型號為Sugon S650,CPU 為AMD Opteron 6212,CPU 頻率為2.6 GHz,核心數為16 核,內存大小為64 GB,硬盤大小為1.7 TB。DataNode 與DFSClient 的節點配置與NameNode 相比,除了內存大小不同以外其他均相同,每個DataNode 的內存為40 GB,DFSClient 則為48 GB。除此之外,機器的操作系統為Ubuntu16.04,linux內核版本為4.4.0-124-generic。
實驗使用了兩個benchmark,分別為TestDFSIO 和HiBench。其中:TestDFSIO 是Hadoop 自帶的基準測試組件,其jar 包版本同Hadoop,也為2.9.0;HiBench 為Intel 開發的大數據基準測試套件,實驗使用的HiBench 版本為7.0。此外,本章所有的實驗,benchmark 均在DFSClient 節點上執行,以模擬更加真實的場景。
4.2 模型可行性分析
本文模型要求Hadoop 集群日志設置為DEBUG 級別,而集群在不同日志級別下性能可能會有所不同,因為日志級別設置得越低,集群在進行讀寫時就會輸出越多的日志,因此需要在兩種不同的日志級別下對集群進行性能分析。使用TestDFSIO 進行文件的讀寫測試,因為多個小文件的讀寫會進行多次的元數據查詢、命名空間創建等,會輸出更多的日志,因此本實驗主要進行多個小文件的讀寫性能測試。控制文件大小為128 MB,讀寫文件數從4 增大到64,測試結果見圖3,從中可以看出,更改Hadoop 集群的日志級別,對MapReduce多個小文件的讀寫任務執行時間影響不大,因此提出的模型具有一定的可行性。
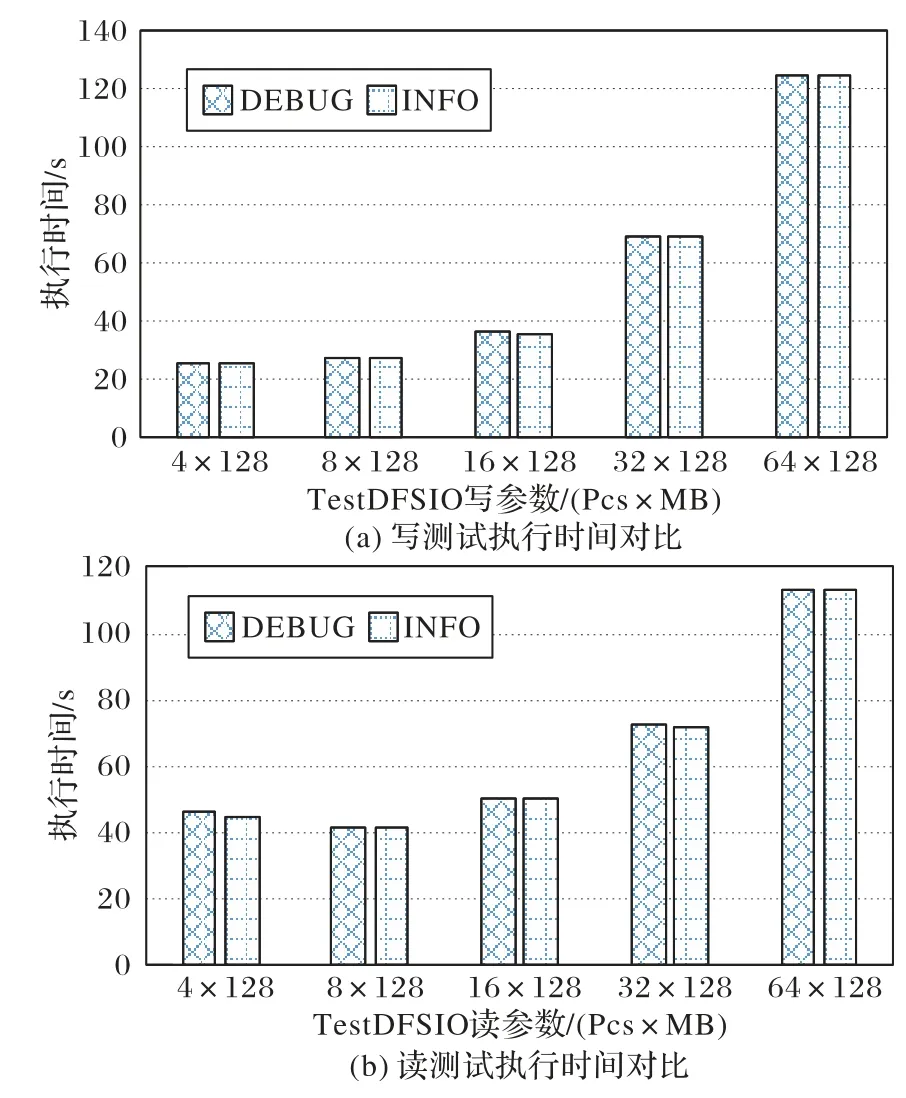
圖3 不同日志級別讀寫性能對比Fig.3 Comparison of read and write performance at different log levels
4.3 模型準確性驗證
現使用TestDFSIO 進行準確性驗證,為了充分驗證本文模型的準確性,分別從以下兩種情況來進行文件的讀寫測試:1)控制文件大小不變,改變讀寫文件數;2)控制讀寫文件數不變,改變文件大小。先執行寫入任務再執行讀取任務,將這視為一組測試,每組測試結束后運行模型進行日志分析,模型分析讀寫量與benchmark 理論讀寫量的對比結果如圖4所示,其中:圖4(a)控制文件大小為128 MB,分別改變讀寫文件數為8、16、32和64;圖4(b)控制讀寫文件數為10,分別改變文件大小為128 MB、256 MB、512 MB和1 024 MB。
從結果可以看出,模型準確地分析出了執行MapReduce任務后的集群讀寫量,均略大于理論值是因為TestDFSIO 在進行實際數據的寫入前,會由一個客戶端向集群io_control 目錄下寫入控制文件,在這之后其他客戶端會先從這個目錄下讀取控制文件,然后再向io_data 目錄下寫入實際的數據。對于讀取操作,也是先需要讀取控制文件,然后再進行數據文件的讀取。此外,HDFS 在讀取文件塊時,每512 B 會生成一個4 B 的校驗和,這意味著每讀一個128 MB 的塊會額外讀取1 MB 的校驗和,模型可以分析出這些額外的讀寫,充分說明了利用日志分析來進行負載特征提取的準確性。模型的執行過程幾乎沒有時延,可以很好地適應大數據分析的實時性。因此,從實驗結果來看,具有一定的準確性與時效性。
4.4 負載特征的獲取
下面使用模型來分析HiBench微基準Sort的執行過程,說明模型在具體應用下獲取到的負載統計與時序特征。微基準數據量參數設置為“huge”,實際進行排序的數據量大小約為3 132.73 MB。需要注意的是,benchmark 雖然是在DFSClient節點執行的,但是TestDFSIO 和HiBench 均為MapReduce 應用,也就是說,集群存在多個客戶端進行并發讀寫,這些客戶端分布在集群的不同DataNode上。
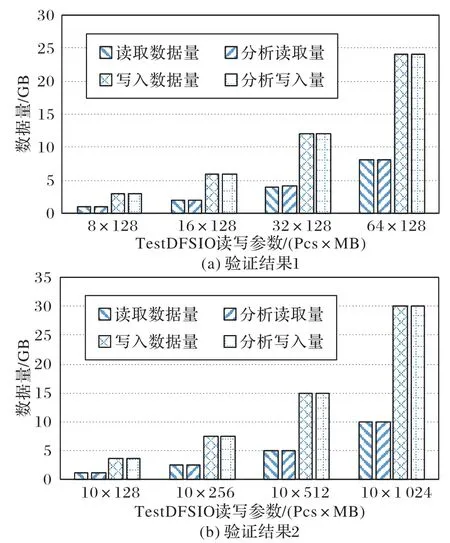
圖4 不同讀寫參數下的準確性驗證結果Fig.4 Accuracy verification results at different read and write parameters
首先,對于各個客戶端的負載統計特征,模型分析結果如表2、3 所示,其中日志跟蹤時間為93.39 s。其次,對于HDFS集群的負載統計特征,跟蹤時間內模型的分析結果如下:平均讀文件大小136.65 MB;平均寫文件大小1 174.78 MB;集群吞吐率236.39 MB/s。此外,各個DataNode 節點的讀寫承載見圖5。
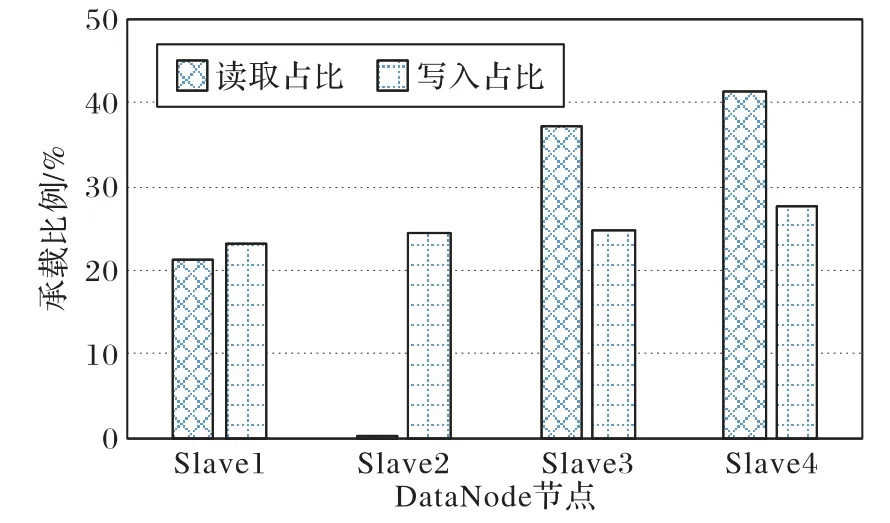
圖5 集群各節點讀寫承載情況Fig.5 Read and write load status of different nodes in the cluster
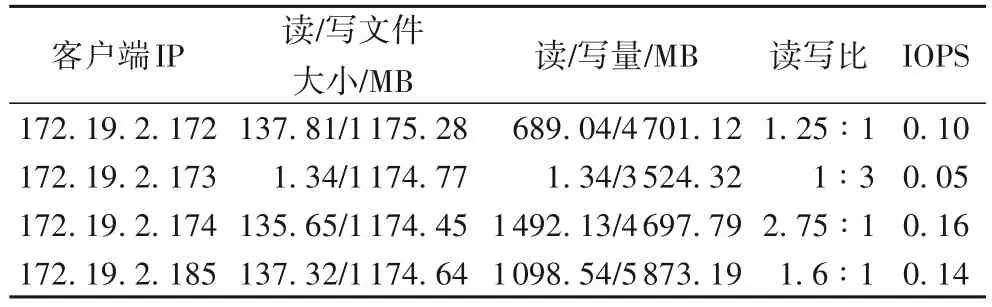
表2 客戶端負載統計特征分析結果Tab.2 Client workload statistical characteristics analysis results

表3 客戶端讀寫分布 單位:MBTab.3 Client read and write distribution unit:MB
至于負載時序特征,分為文件層級的客戶端文件讀取流和塊層級的按時序、跨節點的客戶端塊讀取流兩部分,模型的部分分析結果如表4、5所示。

表4 客戶端(172.19.2.172)文件讀取流Tab.4 Client(172.19.2.172)file reading stream
4.5 模型的應用
在緩存算法、調度策略的研究中,或是機器學習、深度學習等模型的訓練中,往往需要trace 集來輔助研究,以作為實驗的一個手段。在缺乏理想、可用的開源trace 的情況下,需要使用嚴謹的實驗方法來制作trace集。本節描述在HDFS緩存預取研究中模型在trace 集制作上發揮的作用,以說明模型在實際工作中的應用價值,及其能為后續分析提供什么樣的數據。
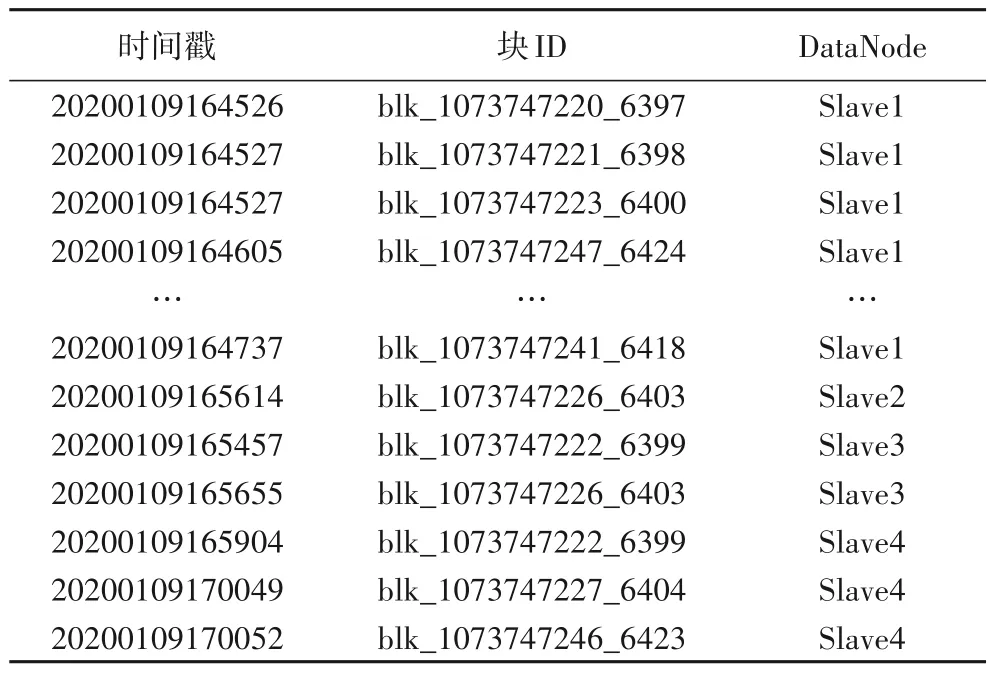
表5 客戶端(172.19.2.172)塊讀取流Tab.5 Client(172.19.2.172)block reading stream
本文使用SWIM(Statistical Workload Injector for MapReduce)[25]在實驗集群上復現來自Facebook 生產系統的真實工作負載。該工具包含5 個trace 集,本文使用的trace 集為Facebook 上包括600 個節點的Hadoop 跟蹤歷史記錄的公開部分,完整trace 從2009 年5 月到2009 年10 月共6 個月,大約包含100萬個job。該trace集主要包含job的遞交時間、map和reduce 階段的數據量等,而HDFS 緩存預取研究需要不同節點的文件讀取時序流,因此需要將該trace 從應用層轉化為文件系統層,以提供研究所需要的數據。
本文首先使用SWIM工具以較低的開銷在實驗Hadoop環境上重現上述Facebook trace,該工具依照原trace 中的時間和數據大小不斷向Hadoop 遞交job。根據需要,本實驗將job 執行所需的數據平均文件大小設置為32 MB,總文件數為1 501。在腳本執行完畢后,即獲取到了job 執行完畢后GB 級別的Hadoop 日志,接著使用模型對這些日志進行負載時序分析,以獲取不同節點的讀取時序流,部分分析結果如表6 所示。根據統計結果顯示,僅前1 000 個job 運行時間約為9 h 38 min,訪問文件次數約為21 000個,足以證明文本提出的模型在復雜應用中的工作價值。

表6 執行Facebook trace時172.19.2.172部分文件讀取流Tab.6 Some 172.19.2.172 file reading stream when executing Facebook trace
5 結語
本文面向HDFS,提出了一個基于分布式文件系統日志的負載特征提取模型,模型分為兩個模塊:數據收集器和數據分析器。數據收集器從NameNode 與DataNode 的日志中根據關鍵字抽取出與讀寫相關的日志記錄,并根據這些日志記錄的數據結構提取讀寫原始數據。數據分析器對這些讀寫原始數據進行分析與計算得到負載特征,并據此進行負載描述與HDFS優化。實驗結果表明,本文提出的模型具有一定的可行性與準確性,且可以較為詳細地給出負載統計與時序特征,具有低開銷、高時效、易于分析等優點,可以用來指導合成具有相同特征的工作負載、熱點數據監測、系統的緩存預取優化等。
本文的研究重點在于探究以什么樣的關鍵字可以從分布式存儲系統日志中準確地跟蹤到I/O信息,并且提出一個通用的模型來對集群在不同工作負載下的特征進行描述,最后開發出實際的系統原型來為下一步的工作打下基礎。因此本文在3.4 與3.5 節提出描述負載特征的模型后只是簡單給出了利用分析結果進行HDFS 性能優化的思路,具體優化策略的研究將作為未來的工作。此外,在后續的研究中發現有利用Web 日志構建預測模型進行Web 文檔預取的應用[26]。利用日志的更新進行模型自適應調參,也顯現出了在不斷變化的工作負載下保持較好的預測準確率的優勢[27]。但是,缺乏基于分布式文件系統日志進行預取模型構建的研究。本文的工作是后續拓展工作的基礎,基于本文提出的日志分析與負載特征提取方法,下一步研究將利用分布式文件系統的歷史日志來構建基于機器學習的預取模型,并且使用后續日志的增量更新來自適應地對模型進行調參,達到對HDFS 熱點文件的預取,提升Hadoop上層應用性能的目的。
最后關于模型分析結果的可視化展示,目前原型的設計是在獲取負載特征后,對于負載統計特征使用Python 的可視化庫將其展示出來,包括客戶端的統計特征,集群的讀寫文件大小、吞吐率以及各個DataNode 的讀寫承載分布等。而關于負載時序特征,鑒于客戶端文件和塊的讀取流內容較多,并且這部分結果將作為智能預取模型的輸入,因此本文目前將其以文本的形式進行保存。此外,現有的可視化原型系統還可通過AJAX(Asynchronous Javascript And XML)等技術實現基于Web的監控系統,在此不再贅述。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
