改進(jìn)的基于冗余點過濾的3D目標(biāo)檢測方法
2020-09-29 06:56:18宋一凡宗立波劉立波
計算機(jī)應(yīng)用 2020年9期
宋一凡,張 鵬,宗立波,馬 波,劉立波
(寧夏大學(xué)信息工程學(xué)院,銀川 750021)
0 引言
近年來,自動駕駛獲得了學(xué)術(shù)界內(nèi)外的廣泛關(guān)注,眾多學(xué)者投入到這一具有挑戰(zhàn)性的任務(wù)當(dāng)中。在自動駕駛中,3D 目標(biāo)檢測在其中發(fā)揮至關(guān)重要的作用,3D 目標(biāo)檢測的性能表現(xiàn)直接影響自動駕駛的可靠性。3D 目標(biāo)檢測需要在三維空間中標(biāo)注出待檢測目標(biāo)的3D 邊界框,這比2D 目標(biāo)檢測更具有挑戰(zhàn)性,因為要考慮到目標(biāo)的方向、空間位置、遮擋等空間因素[1]。深度學(xué)習(xí)在2D 目標(biāo)檢測中已經(jīng)取得了令人矚目的進(jìn)展[2-6],如何將深度學(xué)習(xí)應(yīng)用到3D 目標(biāo)檢測中成為了研究人員關(guān)注的中心。
很多學(xué)者將2D 目標(biāo)檢測框架擴(kuò)展為3D 目標(biāo)檢測框架,由此出現(xiàn)了一大批基于圖像的3D 目標(biāo)檢測算法。Gupta 等[7]將區(qū)域卷積網(wǎng)(Region with CNN feature,R-CNN)擴(kuò)展后在RGB-D 圖像中進(jìn)行目標(biāo)檢測;Chen 等[8]提出的Mono3D 在單目圖像中估計3D 邊界框;3D 目標(biāo)建議(3D Object Proposal,3DOP)[9]在立體圖形中重構(gòu)深度信息,并提出能量函數(shù),通過最小化能量函數(shù)生成3D 候選區(qū),組后通過R-CNN 對目標(biāo)進(jìn)行分類。目前,激光雷達(dá)已經(jīng)成為了自動駕駛車輛的必備組件,因此越來越多的方法開始對激光雷達(dá)獲取的點云進(jìn)行處理。激光雷達(dá)獲取的點云是一種3D數(shù)據(jù),提供比圖像更精確的深度信息,利用點云能夠獲取更精確的目標(biāo)位置和物體邊界,但是點云是一種不規(guī)則數(shù)據(jù),并且具有高度稀疏性,因此不能直接用于傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行特征提取。一些處理點云的方法是將點云轉(zhuǎn)換為標(biāo)準(zhǔn)格式,全卷積車輛檢測器(Vehicle detection from 3D lidar using Fully Convolutional Network,VeloFCN)[10]將點云投影到前視圖,形成2D 圖,再使用傳統(tǒng)卷積網(wǎng)絡(luò)進(jìn)行處理;Vote3Deep[11]、3D 全卷積網(wǎng)絡(luò)(3D Fully Convolutional Network,3DFCN)[12]、投票決策在線點云檢測器[13]將點云轉(zhuǎn)換為體素格,并對體素格進(jìn)行手工編碼。對點云數(shù)據(jù)進(jìn)行轉(zhuǎn)換,不能充分利用點云的3D 特性,最近,Qi等[14]提出了PointNet,直接利用點云進(jìn)行目標(biāo)識別和分割,改進(jìn)后的PontNet++[15]增強(qiáng)了局部特征識別,在對點云進(jìn)行直接處理的工作中,這兩種方法非常具有啟發(fā)性,為3D 數(shù)據(jù)的處理提供了一種全新的思路。基于圖像的目標(biāo)檢測能夠抽取非常豐富細(xì)致的紋理細(xì)節(jié)和高級語義信息,基于點云的目標(biāo)檢測能夠精確地定位,基于兩種方式結(jié)合的方法,會獲得更準(zhǔn)確的檢測效果。多視角3D 檢測網(wǎng)絡(luò)(Multi-View 3D object detection network,MV3D)[16]同時使用RGB和點云進(jìn)行目標(biāo)檢測,并且使用3D 區(qū)域生成網(wǎng)絡(luò)(Region Proposal Network,RPN)生成3D 目標(biāo)候選區(qū)域,并被認(rèn)為是最早將RPN 方法用于自動駕駛方面的方法。
以上提到的算法,大部分都聚焦于點云的手工特征表達(dá),人為地將點云轉(zhuǎn)換為2D 結(jié)構(gòu),比如投影到鳥瞰圖(Bird’s Eye View,BEV)平面或者前視圖平面。如此做法雖然能夠使用成熟的2D CNN 對點云數(shù)據(jù)進(jìn)行特征提取,但是會損失部分點云數(shù)據(jù)的三維精度。針對這一問題,VoxelNet 模型[17]移除了人工特征工程,將點云的特征抽取和目標(biāo)邊界框預(yù)測同意在一個單獨網(wǎng)絡(luò)完成,是第一個端對端訓(xùn)練的通用3D目標(biāo)檢測深度網(wǎng)絡(luò)。但是VoxelNet 使用完整的點云數(shù)據(jù)作為輸入,增加了計算負(fù)擔(dān)、耗費更多的計算資源在背景點云數(shù)據(jù)上,而且只包含幾何信息的點云對目標(biāo)的識別粒度較低,在較復(fù)雜的場景中容易出現(xiàn)誤檢測和漏檢測。
本文在VoxelNet 的基礎(chǔ)上進(jìn)行改進(jìn),加入了視錐體候選區(qū),首先使用2D 目標(biāo)檢測器在RGB 圖像中得到的感興趣目標(biāo)的2D 邊界框;之后根據(jù)點云雷達(dá)坐標(biāo)與RGB 前視圖像像素坐標(biāo)的一一對應(yīng)關(guān)系,將點云坐標(biāo)映射至RGB 前視圖中,提取出2D邊界框內(nèi)部區(qū)域的點云數(shù)據(jù),過濾目標(biāo)之外的冗余點;之后通過對精煉過的點云區(qū)域進(jìn)行端對端的特征學(xué)習(xí),對目標(biāo)進(jìn)行空間定位。改進(jìn)算法大幅降低了點云數(shù)據(jù)處理數(shù)量,減少了對背景點的計算量。改進(jìn)算法在KITTI 數(shù)據(jù)集[18]上訓(xùn)練并測試,結(jié)果和VoxelNet 相比,在簡單、中等和困難模式下,鳥瞰圖檢測精度分別提高了3、10、11個百分點,3D檢測精度分別提高了7、11、10個百分點。
1 相關(guān)工作
卷積神經(jīng)網(wǎng)絡(luò)一般要求輸入數(shù)據(jù)符合某種標(biāo)準(zhǔn)模式,而點云數(shù)據(jù)是一種不規(guī)則格式數(shù)據(jù)。為了將點云數(shù)據(jù)作為深度網(wǎng)絡(luò)的輸入,大部分研究者都是將點云數(shù)據(jù)轉(zhuǎn)換為標(biāo)準(zhǔn)的數(shù)據(jù)格式,但是這種方法會造成精度缺失。Qi 等[14]提出了PointNet,無需對點云進(jìn)行規(guī)則化處理,使用深度網(wǎng)絡(luò)直接處理不規(guī)則的三維點云數(shù)據(jù),在點云的分類和實例分割任務(wù)中取得了良好的效果。后來,Qi 等[15]在PointNet 的基礎(chǔ)上提出了PointNet++,利用分層結(jié)構(gòu)處理局部特征,彌補(bǔ)了PointNet只考慮全局特征而忽略局部特征的缺陷,在對復(fù)雜場景中和表面紋理豐富的目標(biāo)進(jìn)行分類時能取得更好的效果。
PointNet/PointNet++在點云分類和目標(biāo)實例分割中表現(xiàn)出色,但是在3D 目標(biāo)檢測中并不適用。為了提高PointNet/PointNet++的工作效率并能夠解決目標(biāo)空間定位問題,Qi等[19]提出了Frustum PointNets,引入了基于RGB 圖像的2D 檢測,通過2D 檢測結(jié)果在空間中提取視錐體,之后使用PointNet/PointNet++分割目標(biāo)實例,最后使用一個非模態(tài)邊界框預(yù)測模型預(yù)測3D 邊界框,使PointNet/PointNet++能夠進(jìn)行3D目標(biāo)檢測任務(wù)。
為了在高度稀疏的點云數(shù)據(jù)中使用CNN、RPN 這類在2D檢測中取得不錯成績的網(wǎng)絡(luò)結(jié)構(gòu),大部分研究者都是先將點云數(shù)據(jù)進(jìn)行手工特征表示,將3D 數(shù)據(jù)轉(zhuǎn)換成2D 表示,比如投射為鳥瞰圖視角或前視圖,這樣雖然可以更好地兼容2D 方法,但是損失了3D 信息。Zhou 等[17]提出了VoxelNet,一種端對端訓(xùn)練的深度網(wǎng)絡(luò),無需對點云數(shù)據(jù)進(jìn)行手工特征表示和轉(zhuǎn)換,直接對點云進(jìn)行體素化并編碼,使用3D CNN 進(jìn)行特征提取,和邊界框預(yù)測都在一個階段中進(jìn)行。
Chen 等[16]提出的MV3D 網(wǎng)絡(luò),以激光雷達(dá)點云和相機(jī)RGB圖像作為輸入,將點云投影至鳥瞰圖和前視圖,使用卷積網(wǎng)絡(luò)在RGB 圖像、點云鳥瞰圖和點云前視圖中提取特征圖,使用RPN 在鳥瞰圖中得到候選區(qū);之后將候選區(qū)映射至點云正視圖和RGB 圖像中,與3 個位面上的特征圖形成各自位面的感興趣區(qū)域;最后,通過基于區(qū)域的融合網(wǎng)絡(luò)將3 個感興趣區(qū)域融合,得到最終的檢測結(jié)果。
Song 等[20]提了一種3D 卷積網(wǎng)絡(luò)Deep Sliding Shapes,以RGB-D中的物體場景為輸入,輸出目標(biāo)的3D邊界框。此方法中,作者使用3D 區(qū)域生成網(wǎng)絡(luò)(3D RPN)和聯(lián)合目標(biāo)識別網(wǎng)絡(luò)(joint Object Recogniton Network,ORN)共同進(jìn)行目標(biāo)檢測。3D RPN 以深度圖為輸入,生成所有目標(biāo)的3D 候選區(qū)。對于每個3D 候選區(qū),將深度圖輸入ORN 中的3D CNN,提取目標(biāo)的幾何特征;將RGB圖輸入ORN 中的2D CNN,提取圖像特征。最后將幾何特征和圖像特征結(jié)合,用Softmax 分類器對候選區(qū)目標(biāo)進(jìn)行分類,以回歸的方式預(yù)測3D邊界框。
駱健等[21]基于稀疏自編碼(Sparse AutoEncoder,SAE)和循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)提出了多模態(tài)稀疏自編碼循環(huán)神經(jīng)網(wǎng)絡(luò)(Multi-modal Sparse Auto-Encoder and Recursive Neural Network,MSAE-RNN)模型,從RGB-D圖像中的RGB圖像、深度圖以及由RGB圖像和深度圖生成的灰度圖和3D 曲面法線圖分別抽取初級特征,并使用RNN 從初級特征提煉更加抽象的高級特征,最后將4 種特征融合為RGB-D 圖像的最終特征,使用SVM 分類器進(jìn)行目標(biāo)識別。MSAE-RNN在RGB-D圖像中的識別率達(dá)到了90.7%。
王旭嬌等[22]在PointNet 模型中插入了一個K最近鄰圖層,在點云空間中構(gòu)建K近鄰圖,利用圖結(jié)構(gòu)獲取點云中點的局部信息,彌補(bǔ)了PointNet 忽略每個點局部信息的缺陷,有效地提高了整體點云分類的準(zhǔn)確率,在ModelNet40 上準(zhǔn)確率達(dá)到93.2%,比PointNet高4.0%。
2 本文算法
VoxelNet是一個通用的3D目標(biāo)檢測網(wǎng)絡(luò),在一個單一階段的端對端學(xué)習(xí)網(wǎng)絡(luò)中同時完成特征提取和目標(biāo)邊界框預(yù)測,并且不需要對三維點云進(jìn)行特征工程方面的處理,在基于點云的3D目標(biāo)檢測中取得了突破性的進(jìn)展。然而,點云也存在一定的局限性:首先,點云數(shù)據(jù)量很大,通常一幀點云數(shù)據(jù)包含大約100 000個點,而目標(biāo)點只占其中的一小部分;其次,點云數(shù)據(jù)只包含幾何信息,目標(biāo)與背景的識別粒度低。這導(dǎo)致VoxelNet會進(jìn)行大量冗余計算,而且受到背景點的干擾,會出現(xiàn)誤檢測和漏檢測。受到Frustum PointNets的啟發(fā),本文在VoxelNet網(wǎng)絡(luò)模型的基礎(chǔ)上,加入了視錐體提取網(wǎng)絡(luò),同時利用RGB圖像豐富的語義信息和點云精確的深度信息,提升VoxelNet網(wǎng)絡(luò)模型的計算效率,并減少誤檢測率和樓檢測率,提高目標(biāo)檢測精度。
平面圖像的信息空間要遠(yuǎn)遠(yuǎn)小于立體空間,而且和激光雷達(dá)獲取的點云數(shù)據(jù)相比,相機(jī)拍攝的RGB圖形具有更加豐富的紋理細(xì)節(jié)和高級語義信息,因此基于RGB圖像的2D目標(biāo)檢測在目標(biāo)識別上的表現(xiàn)仍優(yōu)于3D目標(biāo)檢測,在目標(biāo)的分類上更為精準(zhǔn)。本文提出的算法首先通過2D檢測器在RGB圖像中檢測出目標(biāo)的2D邊界框,并將此2D邊界框升維至空間視錐體,將視錐體之外的冗余點云移除,只保留視錐體內(nèi)的點云,形成目標(biāo)的3D搜索空間——視錐體候選區(qū),如圖1所示。在獲取視錐體候選區(qū)后,使用VoxelNet僅對視錐體候選區(qū)內(nèi)的點云進(jìn)行處理,在精煉過的空間中進(jìn)行3D目標(biāo)檢測,生成3D邊界框。本文算法有效地減少了VoxelNet的搜索空間,提升了效率,有效地消除了在背景空間中生成3D邊界框的誤檢測事件。
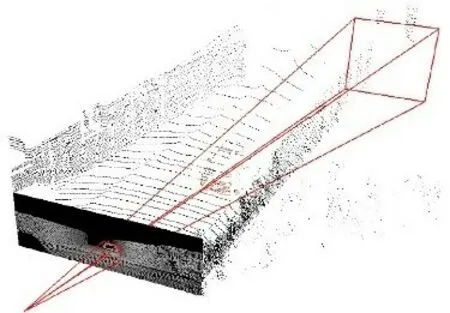
圖1 視錐體候選區(qū)Fig.1 View frustum candidate region
2.1 視錐體候選區(qū)提取
首先利用2D 檢測器在RGB 圖像中獲取目標(biāo)的2D 邊界框,并提取2D 邊界框坐上角點的坐標(biāo)(Xmin,Ymin)和右下角點的坐標(biāo)(Xmax,Ymax)。之后根據(jù)已知的激光雷達(dá)坐標(biāo)與相機(jī)坐標(biāo)的對應(yīng)關(guān)系,計算點云映射至相機(jī)平面的投影矩陣。激光雷達(dá)獲取的點云使用激光雷達(dá)坐標(biāo)系描述,每個點的空間位置使用空間坐標(biāo)系(x,y,z)表示,與之相應(yīng)的相機(jī)獲取的RGB圖像坐標(biāo)為平面坐標(biāo)(x,y),根據(jù)圖2(a)所示KITTI 數(shù)據(jù)集規(guī)定的雷達(dá)坐標(biāo)系和相機(jī)坐標(biāo)系的方向規(guī)定,RGB 圖像坐標(biāo)和點云雷達(dá)坐標(biāo)關(guān)系如圖2(b)所示。
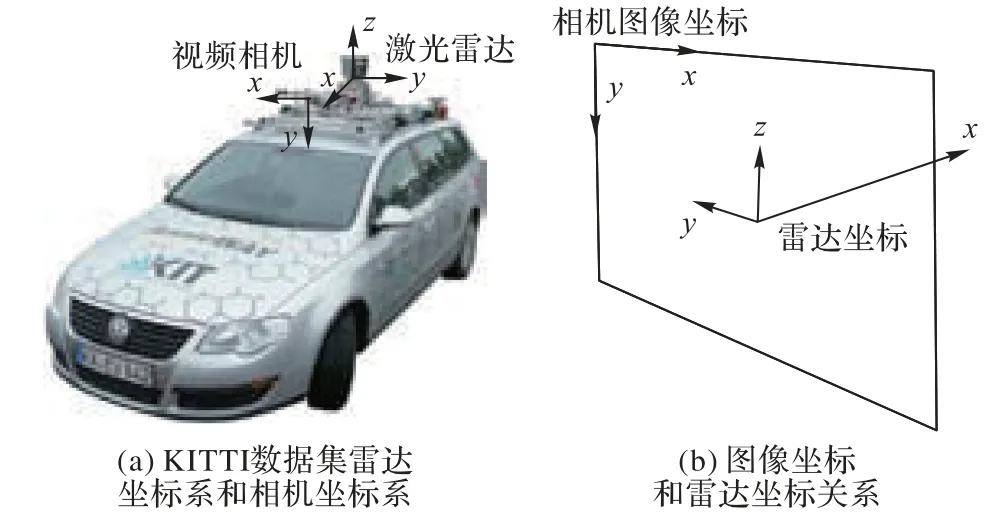
圖2 圖像坐標(biāo)和雷達(dá)坐標(biāo)關(guān)系Fig.2 Relationship between image coordinates and radar coordinates
激光雷達(dá)坐標(biāo)系定義:相機(jī)平面幾何中心為坐標(biāo)原點,水平向左為y軸,豎直向上為z軸,平面向前法線為x軸。圖像坐標(biāo)系定義:圖像左上為坐標(biāo)原點,水平向右為x軸,數(shù)值向下為y軸。
點云中的每一個點,在相機(jī)前視圖的RGB 圖像中都有唯一的對應(yīng)位置,因此RGB 圖像和相應(yīng)的點云之間有一個已知的映射關(guān)系,根據(jù)這個映射關(guān)系可以得知每一個點投影在RGB 圖像中的位置,如圖3。點云坐標(biāo)投影至RGB 圖像坐標(biāo)的計算公式如下:
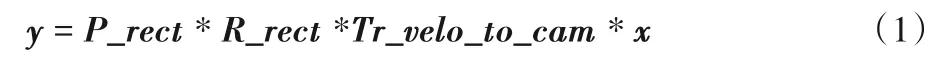
其中:x為雷達(dá)坐標(biāo)系下的點云坐標(biāo);y為點云投影至RGB 圖像中的平面位置坐標(biāo);P_rect是攝像機(jī)的投影矩陣,將矯正后的相機(jī)坐標(biāo)投影至相機(jī)圖像平面;R_rect是相機(jī)的矯正旋轉(zhuǎn)矩陣,用于矯正相機(jī);Tr_velo_to_cam是雷達(dá)坐標(biāo)到相機(jī)的外參矩陣,用于將點云的雷達(dá)坐標(biāo)投影至相機(jī)坐標(biāo)系。
通過式(1)計算得到點云在RGB圖像中的投影坐標(biāo)P(u,v)后,與之前得到的目標(biāo)2D 邊界框角點坐標(biāo)比較,計算出一個目標(biāo)點矩陣T:
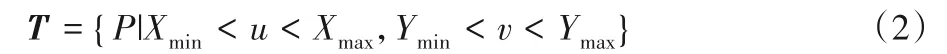
在得到目標(biāo)點矩陣T后,計算視錐體候選區(qū)點云矩陣F:

其中:x是點云雷達(dá)坐標(biāo);yx是x所投影到RGB 圖像上的坐標(biāo)。最后,保留視錐體候選區(qū)點云矩陣F,得到只含有目標(biāo)物體點云的視錐體空間,移除其他所有點云,完成冗余點的過濾。經(jīng)過視錐體候選區(qū)提取后的點云空間大幅縮小,背景點和其余無關(guān)點被充分過濾,目標(biāo)點云所占比重充分增加,原本每個場景的點云數(shù)據(jù)包含大約100 000個點,在經(jīng)過視錐體候選區(qū)提取后,每個場景的點縮減到了至多1 000個左右,在目標(biāo)數(shù)量較少的情況下,甚至達(dá)到100 個點以內(nèi),而且所包含的點基本都屬于目標(biāo)點,這樣可以減少背景點云的干擾,提高檢測精度,并且減少了對大量無效點的編碼計算,提高了有效計算率。

圖3 點云投影至RGB圖像Fig.3 Point cloud projecting to RGB image
2.2 視錐體合并
在一個場景中,有時會有多個目標(biāo),甚至?xí)霈F(xiàn)目標(biāo)重疊的現(xiàn)象。在Frustum PointNets 中,視錐體的提取以目標(biāo)為單位,在多目標(biāo)場景中,會生成和目標(biāo)數(shù)量相同的多個視錐體,而且在由目標(biāo)重疊時,不同的視錐體會包含相同的點云區(qū)域,這樣不僅會使數(shù)據(jù)量增加,還會對相同的點進(jìn)行重復(fù)計算。其次,F(xiàn)rustum PointNets 提取的視錐體點云是映射至矯正坐標(biāo)系下的點,沒有保留點云原始的空間結(jié)構(gòu),不能使用VoxelNet進(jìn)行端對端處理。因此本文改進(jìn)了視錐體提取方法,根據(jù)點云和前視圖的坐標(biāo)映射關(guān)系,直接提取視錐體中雷達(dá)坐標(biāo)系下的點,之后把不同目標(biāo)的點以矩陣的形式堆疊在一起,將相同的點合并,形成同一場景下的視錐體集合點云數(shù)據(jù)。
本文改進(jìn)后的視錐體提取方法與Frustum PointNets 相比:1)保留了點云的原始空間特征,視錐體點云是原始點云的子集,無需改變點云的操作方式;2)將多個目標(biāo)的視錐體點云融合在一個點云空間中,不會增加數(shù)據(jù)量;3)視錐體合并后,去除重復(fù)的點,避免了對相同點的重復(fù)計算。
2.3 體素劃分編碼
視錐體候選區(qū)生成完畢之后,將視錐體點云進(jìn)行體素劃分。體素格大小按照y、z、x軸方向設(shè)置為0.2 m、0.4 m、0.2 m,完整點云場景設(shè)置為寬80 m,高4 m,縱深70.4 m,此范圍之外不考慮,因此整個點云場景按照y、z、x軸被劃分為400、10、352 個體素格,每個體素格都包含一定數(shù)量的點,或者為空。由于使用了視錐體候選區(qū)生成網(wǎng)絡(luò),本文方法很大程度減少了點云搜索空間,體素劃分之后,大部分的體素格為空,而且非空體素中的點大部分都是目標(biāo)點,因此大大減少了對無用點的處理。只選取非空體素格進(jìn)行編碼處理,把非空體素格抽取出來,在其中隨機(jī)抽取固定數(shù)量的點向量化,再將同一個體素中的點的特征向量用全連接層聚合成為表達(dá)體素特征的向量。此時,整個點云空間被編碼成為一個體素特征向量空間,使用3D 卷積網(wǎng)絡(luò)對體素特征向量進(jìn)行卷積操作,聚合體素特征信息,增強(qiáng)體素特征的表達(dá),形成體素特征圖。之后,使用區(qū)域生成網(wǎng)絡(luò)(RPN)以體素特征圖為輸入,生成目標(biāo)3D 邊界框。RPN 由3 個全卷積層和3 個反卷積層構(gòu)成,在反卷積操作之后,得到一個高分辨率的特征圖,之后使用兩個卷積網(wǎng)絡(luò)得到最終的檢測結(jié)果,生成3D邊界框。本文算法網(wǎng)絡(luò)結(jié)構(gòu)如圖4所示。
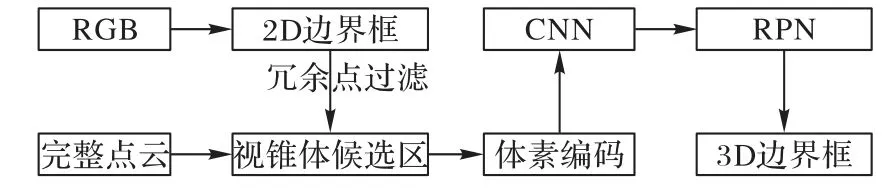
圖4 本文算法網(wǎng)絡(luò)結(jié)構(gòu)Fig.4 Network structure of the proposed algorithm
3 實驗結(jié)果與分析
本文方法在KITTI 目標(biāo)檢測基準(zhǔn)上進(jìn)行訓(xùn)練和測試。KITTI 數(shù)據(jù)集是一套面向自動駕駛的公開數(shù)據(jù)集,提供了7 481 個訓(xùn)練場景和7 518 個測試場景。每個場景都包含一個RGB 前視圖、配準(zhǔn)的點云數(shù)據(jù)和標(biāo)簽。由于測試集沒有提供標(biāo)簽,所以本實驗將訓(xùn)練數(shù)據(jù)重新劃分為訓(xùn)練集和測試集。按照KITTI 的評價設(shè)置,本實驗將在簡單、中等和困難3 個難度場景下進(jìn)行,分別測試3D 平均精度(3D Average Precision,3D AP)、鳥瞰圖平均精度(Bird’s Eye View,BEV)和平均方向相似度(Average Orientation Similarity,AOS),并且和Mono3D、3DOP、VeloFCN、MV3D還有基準(zhǔn)VoxelNet進(jìn)行對比。
3.1 實驗設(shè)置
訓(xùn)練數(shù)據(jù)5 000,測試數(shù)據(jù)2 481,訓(xùn)練epoch 設(shè)置為160,batch 設(shè) 置 為2。CPU 規(guī) 格Intel xeon E5-2620,顯 卡Nvidia Quadro P5000,內(nèi)存64 GB。依據(jù)KITTI 的官方標(biāo)準(zhǔn),BEV、3D AP的交并比(Intersection over Union,IoU)閾值設(shè)置為0.7。
3.2 算法性能和檢測結(jié)果對比
同樣訓(xùn)練160回合,VoxelNet與本文方法的訓(xùn)練曲線如圖5 所示。本文方法在訓(xùn)練時收斂性更好,且在所有困難度場景中3D AP和BEV AP性能更好。
VoxelNet 和本文算法在測試集上分別測試BEV AP、3D AP和AOS,測試結(jié)果如圖6所示。
將本文方法的BEV AP、3D AP 與選取的基準(zhǔn)算法進(jìn)行對比。
BEV 檢測結(jié)果對比見表1。本文方法在3 個難度等級都優(yōu)于所選基準(zhǔn)算法,和VoxelNet 相比,使用相同的RPN,也獲得了不小的精度提升,簡單、中等、困難3 個等級的檢測精度分別提升了3.12、10.29、11 個百分點,表明本文提出算法所引入的視錐體候選區(qū)生成對檢測結(jié)果有很大的提升作用,尤其在困難模式中效果提升顯著。
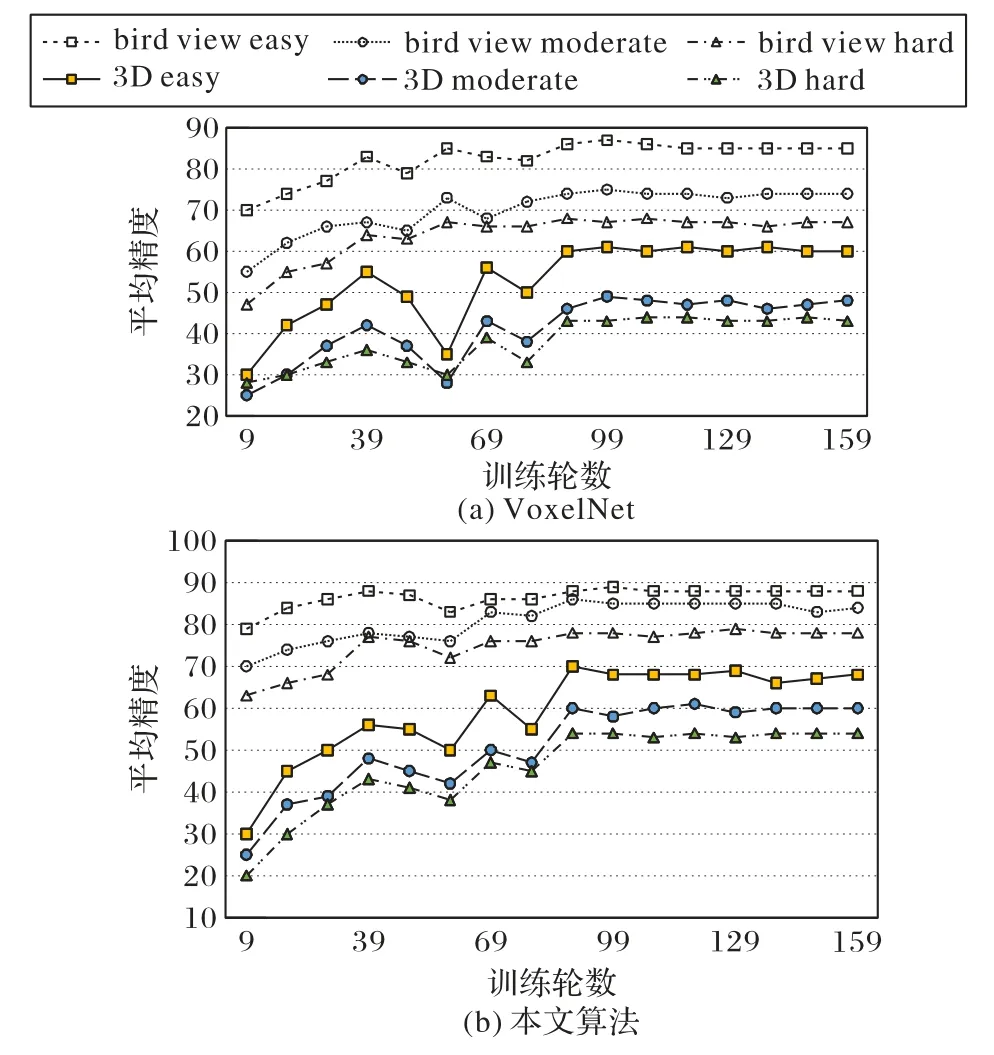
圖5 VoxelNet與本文算法的性能對比Fig.5 Performance comparison of VoxelNet and the proposed algorithm
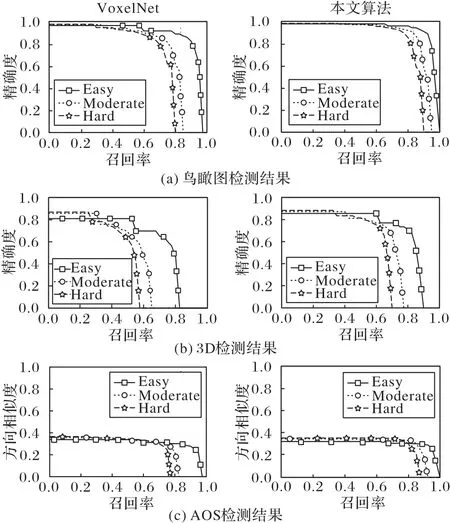
圖6 VoxelNet和本文算法檢測結(jié)果Fig.6 Testing results of VoxelNet and the proposed algorithm
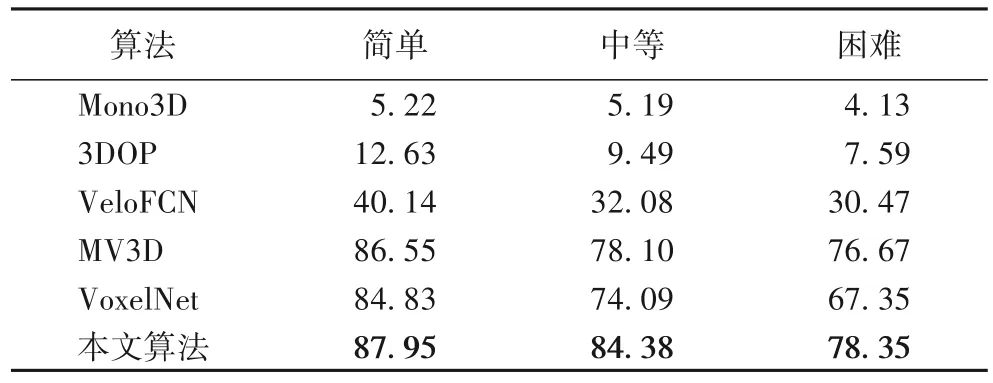
表1 BEV檢測結(jié)果Tab.1 BEV detection results
3D AP 檢測結(jié)果對比見表2。BEV 只檢測平面上的位置準(zhǔn)確率,3D AP 需要在3D 空間中檢測到準(zhǔn)確的3D 位置,因此更具有挑戰(zhàn)性。本文方法在三個難度等級的3D AP 均超越MV3D 以外的基準(zhǔn)算法,在簡單和困難下略低于MV3D。和VoxelNet相比,每個難度下都有大幅提升。
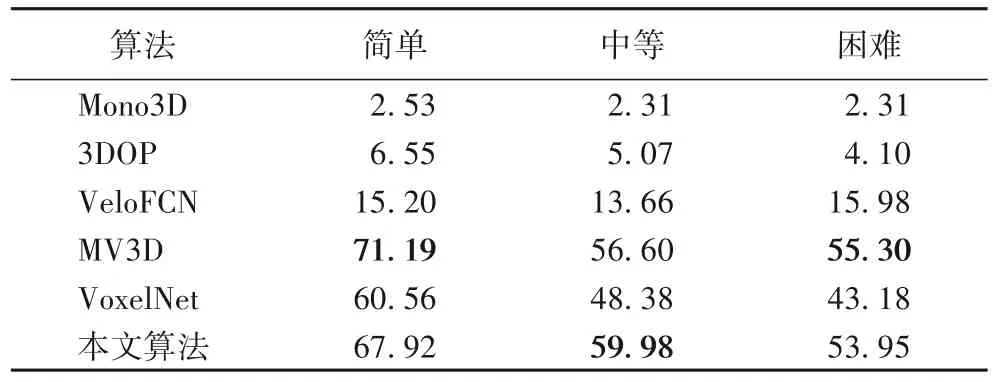
表2 3D AP檢測結(jié)果Tab.2 3D AP detection results
3.3 檢測結(jié)果分析
視錐體候選區(qū)生成網(wǎng)絡(luò)通過RGB 圖像上的目標(biāo)平面位置在點云空間中抽取高價值區(qū)域,縮小了3D 目標(biāo)搜索空間,和完整點云空間相比,點數(shù)量縮小到了原有點數(shù)量的1/10 到1/100。完整點云空間和視錐體生成網(wǎng)絡(luò)提取的視錐體候選區(qū)點云如圖7所示,部分場景的點云數(shù)據(jù)完整點數(shù)量和過濾后的數(shù)量對比見表3。由表3可知,視錐體候選區(qū)過濾掉了大量的多余點,不僅有助于提高檢測精度,降低誤檢率,還能明顯減少計算量,提高計算效率。在訓(xùn)練過程中,本文方法處理一幀數(shù)據(jù)平均時間為0.78 s,VoxelNet則需要1.12 s。

圖7 完整點云和視錐體候選區(qū)點云圖對比Fig.7 Comparison between full point cloud and frustum candidate region point cloud
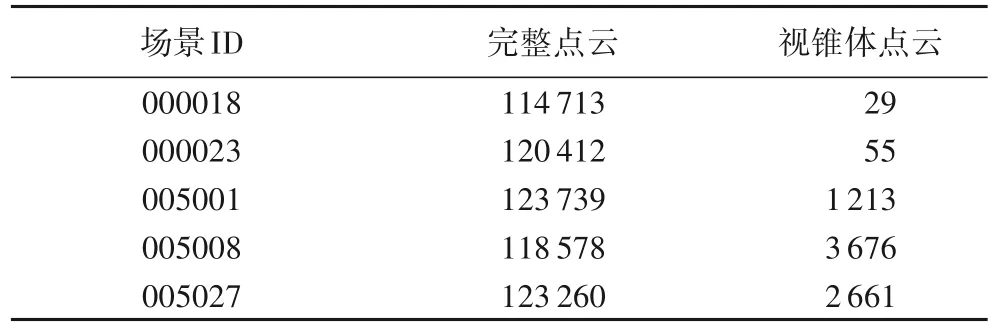
表3 點云數(shù)量對比Tab.3 Number comparison of point cloud
在測試集上測試后,將測試結(jié)果可視化,Ground Truth和檢測結(jié)果見圖8 中實例。鳥瞰圖檢測結(jié)果如圖8所示,使用VoxelNet 的檢測結(jié)果在部分場景中產(chǎn)生了大量的誤檢和漏檢(圖8(a)),本文方法有效地解決了這些問題(圖8(b))。這是因為點云數(shù)據(jù)只有深度信息,不包含語義信息和紋理信息,基于點云的檢測算法無法通過高級語義信息和紋理信息對正負(fù)樣本進(jìn)行區(qū)分,當(dāng)負(fù)樣本點的空間分布類似正樣本點的分布時,非常容易產(chǎn)生誤檢測。此外,VoxelNet 對整個點云進(jìn)行處理,而點云中大部分的點是非目標(biāo)區(qū)域,這就造成了正負(fù)樣本不平衡的問題,在訓(xùn)練調(diào)整權(quán)重時,被大量的負(fù)樣本影響,又產(chǎn)生了漏檢現(xiàn)象。本文提出的方法,引入RGB圖像檢測,通過語義信息在RGB前視圖中檢測出感興趣目標(biāo),再根據(jù)2D檢測結(jié)果在點云空間中抽取視錐體候選區(qū),不僅縮小了搜索空間,還有效地過濾了負(fù)樣本區(qū)域的點,只保留目標(biāo)所在區(qū)域點云,解決了誤檢測的問題;同時,還解決了正負(fù)樣本不平衡的問題,減少了目標(biāo)漏檢。在3D檢測中結(jié)果中,本文方法所預(yù)測的3D邊界框與Ground Truth也獲得了更高的重合度,如圖9所示。

圖8 VoxelNet與本文算法的鳥瞰圖檢測結(jié)果Fig.8 BEV detection results of VoxelNet and the proposed algorithms

圖9 VoxelNet和本文方法的3D檢測結(jié)果Fig.9 3D testing results of VoxelNet and the proposed algorithm
4 結(jié)語
本文提出了一種基于冗余點過濾的3D目標(biāo)檢測算法,考慮到點云數(shù)據(jù)只包含幾何信息,在目標(biāo)識別準(zhǔn)確率上仍低于基于RGB圖像的2D檢測,在VoxelNet模型的基礎(chǔ)上加入了視錐體候選區(qū),通過2D 檢測器在RGB 前視圖中鎖定目標(biāo)平面位置,并將2D位置升維至點云空間中的視錐體,得到包含目標(biāo)點云區(qū)域的視錐體候選區(qū),過濾冗余背景點云,縮小點云搜索空間。該算法模型減少了對多余背景點云的計算,提高了點云處理效率,并且通過高價值區(qū)域的選定,減小了誤檢率和漏檢率。本文在KITTI數(shù)據(jù)集上的實驗證明,通過縮小點云空間可以有效提升檢測精度和工作效率,在簡單、中等、困難3種模式下的評價精確率分別為67.92%、59.98%、53.95%,優(yōu)于VoxelNet模型。另外,本文提出的視錐體候選區(qū)提取網(wǎng)絡(luò)具有通用性,不會改變點云的原有屬性和結(jié)構(gòu),理論上可以應(yīng)用于任何以點云作為輸入的檢測框架。然而,使用視錐體候選區(qū)的檢測方法有一點不足,如果2D 檢測器在RGB 圖像中發(fā)生漏檢,該區(qū)域點云會直接被忽略,直接影響最終的3D 檢測結(jié)果。另外,3D檢測的平均精度和檢測速度和成熟的2D檢測器仍有不小的差距。提高視錐體候選區(qū)的生成質(zhì)量和進(jìn)一步提高3D目標(biāo)檢測的平均精度和檢測速度,將是下一步研究的重點。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
