基于隨機森林的居民健康評估模型
2020-09-28 07:05:41魏小弟
電腦知識與技術 2020年16期
魏小弟


摘要:隨著我國經濟水平的快速發展和人民生活水平的不斷提高,特別是新時期健康衛生工作方針由“以治病為中心”向“以健康為中心”轉變的背景下,人們對生活質量、衛生服務和身心健康提出了更高的要求。本文基于大健康學科前沿成果,分析了“失配性”現象的形成機理并將飲食、生活、工作、醫療、環境作為輸入層,社會公共衛生和居民個體作為輸出層,構造基于隨機森林(Random Forest, RF)算法的社會公共衛生與環境和居民個體評估模型;然后采用模糊等級劃分法設定五種評估等級,并使用指派法建立隸屬度函數來確定五個因素對五種評估等級的影響;最后通過比較模型輸出值和隸屬度函數空間值的大小,及時發現存在的問題,并提出解決類似“失配性”慢性非傳染疾病以及環境污染等問題的可行方案。
關鍵詞:居民健康; 隨機森林; 模糊等級劃分法; 隸屬度函數
中圖分類號: TP391? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2020)16-0033-03
隨著經濟的快速發展,人們對衣、食、住、行等方面提出了更高的要求,如醫療模式從傳統的單一救治模式逐漸向“防、治、養”的大健康模式轉變[1-5]。但健康問題受到飲食習慣、生活方式、工作壓力和醫療保障等多方面的影響,且患慢性病、老年病、肥胖病以及亞健康等問題的人數逐年遞增,給國民健康帶來了非常大的困擾[6-8]。為此建立一種能夠支持健康水平動態測控的居民健康評估模型迫在眉睫。
1 算法設計與分析
1.1 隨機森林模型
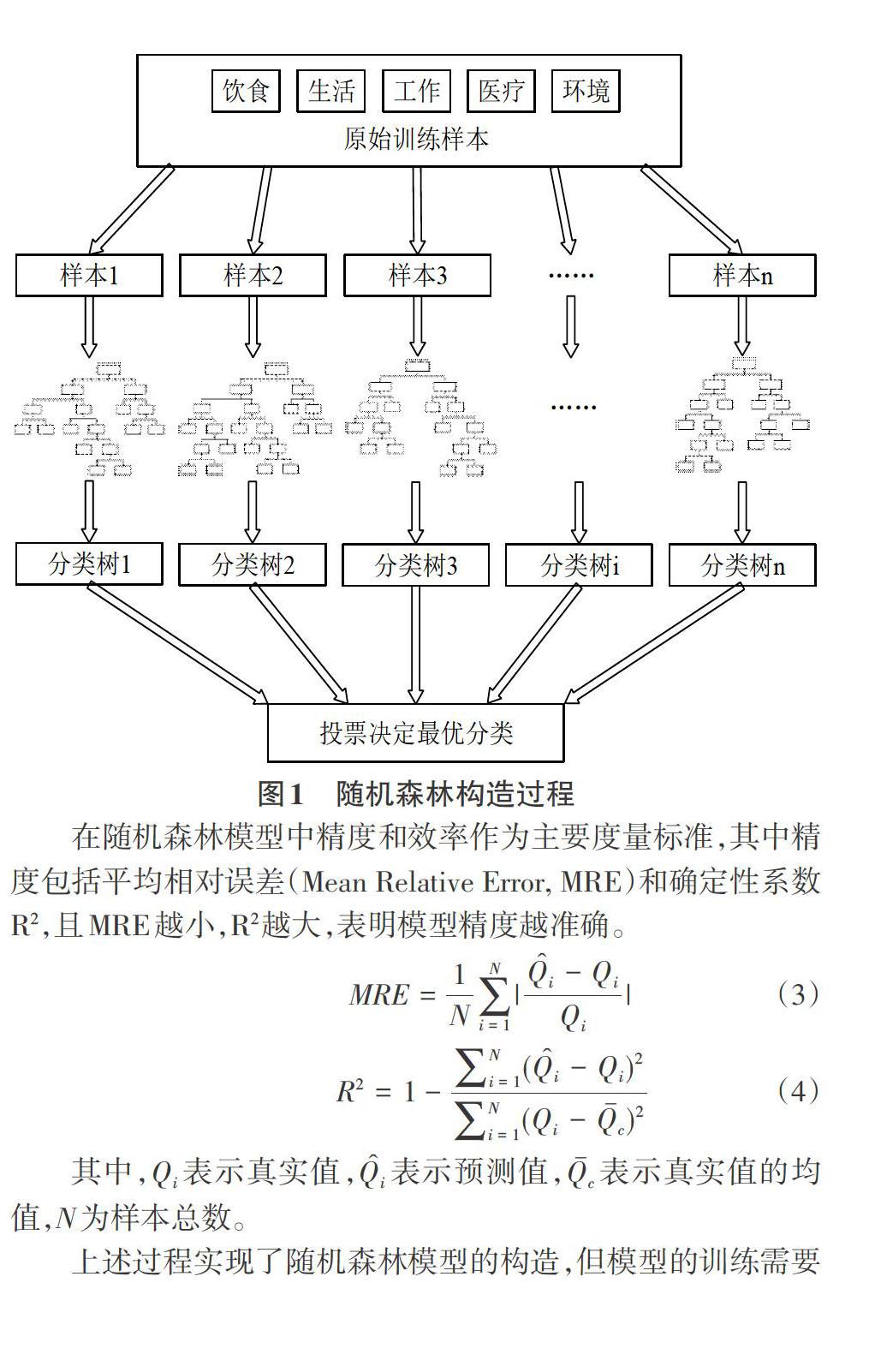
根據大健康學科前沿研究成果,通過分析“失配性”現象的形成機理[9],將飲食、生活、工作、醫療、環境作為輸入層,社會公共衛生和居民個體作為輸出層,構造基于隨機森林算法的居民健康評估模型。隨機森林構造過程如圖1所示。
隨機森林是由一組決策分類器[{h(x,?t),t=1,2,...,T}]組成的集成分類器,其中[?t]是服從獨立分布的隨機變量,T表示隨機森林中決策樹的個數,每個決策樹分類器通過投票的方式來決定最優的分類結果[10]。具體計算如公式(1)所示。
上述過程實現了隨機森林模型的構造,但模型的訓練需要多個城市不同狀況下居民的健康數據,本文選擇北京、上海、西藏、蘭州和成都等地的居民健康數據進行模型的訓練。
考慮到模型輸入時各因素數據不統一的問題,采用以下五種計算方式實現數據的歸一化處理。
(1)飲食方面采用攝入能量與體重之間的關系進行計算,體質指數(Body Mass Index, BMI)如公式(5)所示。
[BMI=BWST2]? ? ? ? ? ? ? ? ? ? ?(5)
(2)生活方面采用國民幸福指數(National Happiness Index, NHI)進行計算,如公式(6)所示。
[NHI=IIGE×UR×IN]? ? ? ? ? ? ? ? (6)
(3)工作方面采用失業率表示,如公式(7)所示。
[UR=UYNB+UY]? ? ? ? ? ? ? ? ? (7)
(4)醫療方面采用醫保普及率表示。
(5)環境方面主要考慮到空氣質量,等標排放量Pi(m3/h)計算如公式(8)所示。
[Pi=Qi/Coi×109]? ? ? ? ? ? ? ? (8)
其中,BW表示身高,ST表示體重;II表示居民收入的遞增,GE表示基尼系數,UR表示失業率,IN表示通貨膨脹;UY表示失業人數,NB表示在業人數;[Qi]表示第i類污染物在單位時間內的排放量,[Coi]表示第i類污染物空氣排放質量標準。
1.2 隨機森林算法描述
隨機森林算法作為基于機器學習的一種集成分類算法,結合了多個決策樹的分類效果,最終通過“投票”方式選擇出票數最多的類別作為最終的分類[11]。每一棵樹構造流程如算法1所示。
[算法1:隨機森林算法 Step1 用N表示訓練樣本個數,M表示特征數目; Step2 輸入特征數目[m(m 3 實驗與分析 3.1 實驗環境 實驗環境如表1所示。 3.2 實驗結果與分析 為驗證本文算法的性能,從國家衛生部和國家統計局等網站收集與整理120000條數據作為隨機森林模型的訓練與測試數據,設置模型的最大訓練次數epochs=120,learning rate=0.01,具體訓練過程如圖2(a)和(b)所示。 通過圖2(a)可知,在訓練與測試初期,模型的準確率隨著訓練步數的增加而快速上升,且訓練準確率高于測試準確率;由圖2(b)可知,在訓練初期模型的loss值隨著訓練步數的增加快速下降,且訓練loss值低于測試loss值,表明該模型具有較好的訓練與測試效果。 圖3給出了隨機森林模型的回歸檢驗,其中紅色表示訓練值,黃色表示驗證值,藍色表示測試值,當R=0.9943、0.9952和0.9935時符合回歸檢驗,如圖3(a)、(b)和(c)所示。通過觀察圖3(d),當R=0.9958時,模型在訓練、測試和驗證集上取得最好的吻合效果,表明本文模型具有可行性。 用于模型輸入的五個指標存在動態變化的特點,本題針對這一問題采用指派法,通過建立梯形函數和三角函數相結合的隸屬度函數,求解出劃定評價社會公共衛生與環境和居民個體的五個等級。隸屬度函數關系如圖4所示。 3.3 依據評估模型提出可行性方案 為評估本文提出模型的有效性,現以西安市為例。將五個指標作為模型的輸入,社會公共衛生和居民個體作為模型的輸出,分別計算得到社會公共衛生和居民個體的評價為0.58和0.76。 根據表2評價等級與區間范圍對應關系,可得公共衛生為中等,說明西安市需要在環境和醫療等方面進行調控。在環境方面可以通過控制水質因子,利用工業污染物排序指標ISE控制廢物排放量,有效降低患有癌癥、糖尿病和高血壓、高血脂等疾病的人數。 根據表2評價等級與區間范圍對應關系,可得居民自身評價良好,說明西安市居民對當地飲食、工作和生活等方面的把控能力較好。若想提升評價等級指數,在飲食方面可以通過計算標準體重與身高對應能量攝入量,在工作方面可以通過運動等方式解壓,全面提升居民幸福指數。 通過計算隨機森林模型輸出值與隸屬度對應的區間范圍,及時發現問題,并就當前問題提出合理的解決方案,為“健康行動計劃”提供有力支持,此外,根據建立的模型和經驗有效提出解決類似“失配性”慢性非傳染疾病以及環境污染等問題的可行方案。 4 結語 近年來,利用機器學習算法預測居民健康指數成為研究熱點,本文在先驗知識的基礎上,提出了一種基于隨機森林的居民健康評估模型,為解決類似“失配性”慢性非傳染疾病以及環境污染等問題提供一種新的研究思路。 參考文獻: [1] 桑祎瑩,黃仕鑫,易靜,等.基于隨機森林和誤差反向傳播神經網絡的糖尿病性周圍神經病變患病風險研究[J].解放軍醫學雜志,2018,43(10):877-881. [2] 俞竣瀚. 基于極限學習機馬爾科夫模型的結果健康狀態預測研究[D]. 西安: 長安大學, 2016. [3] 彭炎亮, 李旺根, 劉嬌. 基于動態權重和模糊綜合評價法的健康評估模型[J]. 計算機系統應用, 2017, 12(1):37-43. [4] 朱鳳梅. 基于模糊綜合評價方法的醫療衛生體制改革評價研究[J]. 中國衛生統計, 2016, 33(2):267-270. [5] 雷順群. 論大健康理念形成的立論基礎和根據[J]. 中醫雜志, 2016, 57(15):1261-1265. [6] 李欣海. 隨機森林模型在分類與回歸分析中的應用[J]. 應用昆蟲學報(昆蟲知識), 2016, 50(04):1190-1197. [7] 明勇, 王華軍. 模糊隸屬度融合多層前饋神經網絡的CBIR方法[J]. 計算機測量與控制, 2015, 23(3):903-906. [8] 任鵬飛, 秦貴和. 具有交通規則約束的改進Dijkstra算法[J]. 計算機應用, 2015, 35(9):2503-2507. [9] 常振波, 盧文喜, 辛欣. 基于靈敏度分析和替代模型的地下水污染風險評價方法[J]. 中國環境科學, 2017, 37(1):167-173. [10] 李莉瓊, 劉漳輝, 郭昆. 基于灰關聯分析的模糊C均值算法[J]. 福州大學學報:自然科學版, 2016, 44(2):170-175. [11] 王小強. 基于隨機森林的亞健康狀態預測與特征選擇方法研究[J]. 計算機應用與軟件, 2014, 31(1):296-298, 307. 【通聯編輯:唐一東】
