TensorFlow Lite:端側(cè)機(jī)器學(xué)習(xí)框架
2020-09-24 08:40:50李雙峰
計(jì)算機(jī)研究與發(fā)展 2020年9期
李雙峰
(Google TensorFlow團(tuán)隊(duì) 北京 100190)shuangfeng@google.com)
TensorFlow Lite[1](TFLite)是一個(gè)輕量、快速、跨平臺(tái)的專門針對(duì)移動(dòng)和IoT應(yīng)用場(chǎng)景的機(jī)器學(xué)習(xí)框架,是開源機(jī)器學(xué)習(xí)平臺(tái)TensorFlow[2-4](TF)的重要組成部分.它致力于“一次轉(zhuǎn)換,隨處部署”,支持安卓、iOS、嵌入式Linux以及MCU等多種平臺(tái),降低開發(fā)者使用門檻,加速端側(cè)機(jī)器學(xué)習(xí)(on-device machine learning, ODML)的發(fā)展,推動(dòng)機(jī)器學(xué)習(xí)無(wú)處不在.本文介紹了工業(yè)界端側(cè)機(jī)器學(xué)習(xí)的最新趨勢(shì)以及TFLite如何加速其發(fā)展,包括:
1) 端側(cè)機(jī)器學(xué)習(xí)的趨勢(shì)、挑戰(zhàn)和典型應(yīng)用,以及TFLite的起源;
2) TFLite的系統(tǒng)架構(gòu);
3) TFLite的最佳實(shí)踐以及適合初學(xué)者的工具鏈;
4) 未來(lái)的發(fā)展方向.
1 TensorFlow Lite推動(dòng)端側(cè)機(jī)器學(xué)習(xí)的發(fā)展
1.1 機(jī)器學(xué)習(xí)的普及以及TensorFlow的發(fā)展
機(jī)器學(xué)習(xí)的發(fā)展改變著語(yǔ)音交流、機(jī)器翻譯、健康醫(yī)療和城市交通等我們生活中的諸多領(lǐng)域,越來(lái)越多的企業(yè)、組織和個(gè)人嘗試用機(jī)器學(xué)習(xí)解決業(yè)務(wù)或者生活中遇到的難題.開發(fā)者數(shù)量的大量增加也意味著需要降低技術(shù)門檻,讓更多人參與進(jìn)來(lái).
在2015年底,Google開源了端到端的機(jī)器學(xué)習(xí)開源框架TensorFlow[2-4]:它既用于研究,也用于大規(guī)模生產(chǎn)領(lǐng)域;既支持大規(guī)模的模型訓(xùn)練,也支持各種環(huán)境的部署,包括服務(wù)器和移動(dòng)端的部署;支持多種語(yǔ)言比如Python,C++,Java,Swift甚至JavaScript.TensorFlow提供了全面靈活的工具生態(tài),幫助解決各種挑戰(zhàn)性的問題.而近年來(lái)移動(dòng)化浪潮和交互方式的改變,使得機(jī)器學(xué)習(xí)技術(shù)開發(fā)也在朝著輕量化的端側(cè)發(fā)展,于是TensorFlow團(tuán)隊(duì)在2017年底開源了TFLite[5],一個(gè)輕量、快速、兼容度高的專門針對(duì)移動(dòng)應(yīng)用場(chǎng)景的深度學(xué)習(xí)工具,降低了端側(cè)深度學(xué)習(xí)技術(shù)的門檻.
1.2 端側(cè)機(jī)器學(xué)習(xí)的機(jī)遇和挑戰(zhàn)
伴隨移動(dòng)和IoT設(shè)備的普及,世界以超乎想象的方式連接在一起.如今已有超過30億的智能手機(jī)用戶[6],以及超過70億的聯(lián)網(wǎng)IoT設(shè)備[7](不包括手機(jī)、電腦等).手機(jī)成本不斷降低,并且隨著微控制器(mircrocontrollers, MCU)和微機(jī)電系統(tǒng)(micro-electro-mechanical systems, MEMS)的發(fā)展,高性能低功耗的芯片使得“萬(wàn)物”智能具有了可能性.從智能穿戴、智能家居到共享單車,從工業(yè)控制到車載設(shè)備,這些設(shè)備都有了智能化的基礎(chǔ).我們有時(shí)把這些設(shè)備統(tǒng)稱為邊緣設(shè)備(edge device).
將邊緣設(shè)備的數(shù)據(jù)傳輸?shù)皆贫颂幚砗芏鄷r(shí)候不是最經(jīng)濟(jì)有效的方式,它帶來(lái)了延遲,降低了復(fù)雜網(wǎng)絡(luò)條件下的可靠性,也引起了更多的隱私顧慮,從而影響用戶體驗(yàn).用戶對(duì)交互的需求越來(lái)越高,快速、及時(shí)的智能反應(yīng)是消費(fèi)者的普遍期待,以智能音箱為例,喚醒的響應(yīng)速度是良好體驗(yàn)的基礎(chǔ).
我們把在邊緣設(shè)備上的運(yùn)行機(jī)器學(xué)習(xí)統(tǒng)稱為端側(cè)機(jī)器學(xué)習(xí)(ODML),它為萬(wàn)物智能互聯(lián)帶來(lái)了新的機(jī)遇:
1) 更快、更緊密的交互方式,因?yàn)槟P驮诒镜貓?zhí)行的延遲小.比如及時(shí)的語(yǔ)音喚醒、直播視頻的實(shí)時(shí)圖像分割或者輔助駕駛的目標(biāo)檢測(cè),都需要在本地執(zhí)行.
2) 在復(fù)雜網(wǎng)絡(luò)環(huán)境下仍可提供可靠服務(wù),比如在網(wǎng)絡(luò)基礎(chǔ)設(shè)施相對(duì)落后的國(guó)家或偏遠(yuǎn)地區(qū),在復(fù)雜環(huán)境下(比如隧道中),帶寬可能有限或無(wú)法聯(lián)網(wǎng).
3) 更好的保護(hù)隱私,因?yàn)樵诒镜剡M(jìn)行數(shù)據(jù)收集和處理,減少了數(shù)據(jù)上傳.
然而實(shí)現(xiàn)端側(cè)機(jī)器學(xué)習(xí)有很多挑戰(zhàn),因?yàn)檫吘壴O(shè)備:
1) 算力有限,限制了模型的復(fù)雜度.
2) 內(nèi)存有限,限制了模型的大小.
3) 電池有限,需要模型運(yùn)算效率更好.比如對(duì)智能手表而言,省電非常關(guān)鍵.
通常,移動(dòng)設(shè)備上耗電最多的是無(wú)線電,如果在本地執(zhí)行,尤其是有DSP或NPU等硬件加速器的情況下,電池續(xù)航時(shí)間就更長(zhǎng).
4) 計(jì)算硬件生態(tài)碎片化嚴(yán)重,比如CPU,GPU,DSP,NPU等,如何將這些異構(gòu)硬件真正利用起來(lái)是一大難題.這與云端不同,在云端,硬件加速器供應(yīng)商通常非常集中,如NVIDIA GPU或TPU.
1.3 TensorFlow Lite的起源和相關(guān)工作
TFLite是在邊緣設(shè)備上運(yùn)行TensorFlow模型推理的官方框架,它跨平臺(tái)運(yùn)行,包括Android,iOS以及基于Linux的IoT設(shè)備和微控制器.
TensorFlow適用于云端的大型、大功率設(shè)備,以及本地的工作站設(shè)備.當(dāng)邊緣設(shè)備的需求增加時(shí),我們嘗試簡(jiǎn)化TensorFlow并在移動(dòng)設(shè)備上運(yùn)行,這就是TF Mobile項(xiàng)目:它是一個(gè)縮減版的TensorFlow變體,簡(jiǎn)化了算子集,也縮小了運(yùn)行庫(kù)(runtime).然而,我們始終難以大大縮小運(yùn)行庫(kù);同時(shí)運(yùn)行庫(kù)的擴(kuò)展性方面也存在問題,如何將其映射到移動(dòng)環(huán)境中所用的各種異構(gòu)加速器上困難重重.
TFMini是Google內(nèi)部用于計(jì)算機(jī)視覺場(chǎng)景的解決方案,它提供了一些工具(比如TOCO轉(zhuǎn)換工具),壓縮模型(比如刪掉訓(xùn)練相關(guān)的不必要節(jié)點(diǎn)),進(jìn)行算子融合并生成代碼.它將模型嵌入到二進(jìn)制文件中,這樣我們就可以在設(shè)備上運(yùn)行和部署模型.TFMini針對(duì)移動(dòng)設(shè)備做了很多優(yōu)化,性能優(yōu)秀,但在把模型嵌入到實(shí)際的二進(jìn)制文件中時(shí)兼容性存在較大挑戰(zhàn),因此TFMini并沒有成為通用的解決方案.
基于TF Mobile的經(jīng)驗(yàn),也繼承了TFMini和內(nèi)部其他類似項(xiàng)目的很多優(yōu)秀工作,我們?cè)O(shè)計(jì)了TFLite:
1) 更輕量.在32 b安卓平臺(tái)下,核心運(yùn)行時(shí)的庫(kù)大小只有100 KB左右,加上支持基本的視覺模型(比如InceptionV3和MobileNet)所需算子時(shí),總共300 KB左右,而使用全套算子庫(kù)時(shí),只有1 MB左右.
2) 特別為各種端側(cè)設(shè)備優(yōu)化的算子庫(kù).
3) 能夠利用各種硬件加速,比如GPU,DSP等.
TFLite兼具性能和通用性,已經(jīng)完全取代了TF Mobile和TFMini,成為TensorFlow針對(duì)移動(dòng)和IoT設(shè)備的官方框架,被廣泛使用.
其他相關(guān)工作包括:CoreML[8]是iOS平臺(tái)的解決方案,而TFLite強(qiáng)調(diào)其優(yōu)秀的跨平臺(tái)能力.中國(guó)的開源端側(cè)機(jī)器學(xué)習(xí)框架代表包括騰訊NCNN[9]、小米MACE[10]和阿里巴巴MNN[11]等,它們專注于移動(dòng)推理平臺(tái),而TFLite是TensorFlow生態(tài)的一部分,支持從訓(xùn)練到多種平臺(tái)部署[3](比如TFX,TF.js,TFLite),并提供完整的工具鏈(比如TensorBoard).
1.4 端側(cè)機(jī)器學(xué)習(xí)應(yīng)用的蓬勃發(fā)展
端側(cè)機(jī)器學(xué)習(xí)在圖像、文本和語(yǔ)音等方面都有非常廣泛的想象空間.全球有超過40億[12]的設(shè)備上部署著TFLite,這個(gè)數(shù)字還在不斷增加當(dāng)中.Google的大量產(chǎn)品部署著TFLite,比如Google Assistant,Google Photos等;國(guó)際巨頭比如Uber,Airbnb等[12],以及國(guó)內(nèi)的許多大公司,比如網(wǎng)易、愛奇藝和WPS等,都在使用TFLite.
一方面,端側(cè)機(jī)器學(xué)習(xí)能解決的問題越來(lái)越多元化,這帶來(lái)了應(yīng)用的大量繁榮.前期在圖像和視頻方面廣泛應(yīng)用,比如Google Lens[13],Google Photos,Google Arts & Culture[14].最近,離線語(yǔ)音識(shí)別方面有很多突破,比如Google Assistant宣布了完全基于神經(jīng)網(wǎng)絡(luò)的移動(dòng)端語(yǔ)音識(shí)別[15],效果和服務(wù)器端十分接近,服務(wù)器模型需要2 GB大小,而手機(jī)端只需要80 MB.端側(cè)語(yǔ)音識(shí)別非常有挑戰(zhàn),它的進(jìn)展代表著端側(cè)機(jī)器學(xué)習(xí)時(shí)代的逐步到來(lái).一方面依賴于算法的提高,另外一方面TFLite框架的高性能和模型優(yōu)化工具也起到了很重要的作用.離線語(yǔ)音可以帶來(lái)很好的用戶體驗(yàn),比如無(wú)需網(wǎng)絡(luò)環(huán)境即可使用,無(wú)隱私顧慮.Google Pixel 4手機(jī)上發(fā)布了Live Caption[16],自動(dòng)把視頻和對(duì)話中的語(yǔ)言轉(zhuǎn)化為文字,大大提高了有聽力障礙人群的體驗(yàn)(accessibility).更進(jìn)一步,端側(cè)自然語(yǔ)言處理將會(huì)有巨大的前景.我們發(fā)布了基于MobileBERT模型的問題回答系統(tǒng)[17-18],速度非常快,在普通CPU上可實(shí)時(shí)響應(yīng),創(chuàng)造了無(wú)縫的用戶體驗(yàn).
另外一方面,模型越來(lái)越小,無(wú)處不再.Google Assistant的語(yǔ)音功能部署在非常多元的設(shè)備上,比如手機(jī)端、手表、車載和智能音箱上,全球超過10億設(shè)備.更激動(dòng)人心的前景發(fā)生在IoT領(lǐng)域,TFLite可以支持微控制器(microcontrollers, MCU)[19],而MCU是單一芯片的小型計(jì)算機(jī),沒有操作系統(tǒng),只有內(nèi)存,也許內(nèi)存只有幾十KB.很多設(shè)備上都有MCU,全球有超過一千五百億的MCU.MCU低功耗、便宜、無(wú)處不在.TFLite發(fā)布了若干MCU上可運(yùn)行的模型,比如識(shí)別若干關(guān)鍵詞的語(yǔ)音識(shí)別模型和簡(jiǎn)單的姿態(tài)檢測(cè)模型,模型大小都只有20 KB左右,我們基于此可構(gòu)建很有意思的應(yīng)用,比如更智能的小玩具:它在MCU上運(yùn)行上述模型,呼叫設(shè)定的特定呢稱時(shí)就會(huì)發(fā)出某個(gè)聲音,而當(dāng)拿起玩具做一些設(shè)定的動(dòng)作時(shí)就會(huì)響應(yīng).當(dāng)隨處可見的物品都在MCU上部署機(jī)器學(xué)習(xí)的模型時(shí),智能開始無(wú)處不在.
在中國(guó),在移動(dòng)應(yīng)用方面,網(wǎng)易使用TFLite做OCR處理[20];愛奇藝使用TFLite來(lái)進(jìn)行視頻中的AR效果[21],而WPS用它來(lái)做一系列文字處理[22].在IoT方面,出門問問智能音箱使用TFLite來(lái)做熱詞喚醒[23](對(duì)于智能音箱而言,準(zhǔn)確、實(shí)時(shí)、輕量化低功耗的喚醒非常關(guān)鍵),科沃斯掃地機(jī)器人使用TFLite在室內(nèi)避開障礙物[24].另外,TFLite也非常適合工業(yè)物聯(lián)智能設(shè)備的開發(fā),因?yàn)樗芎玫刂С秩鐦漭杉捌渌贚inux SoC的工業(yè)自動(dòng)化系統(tǒng).創(chuàng)新奇智應(yīng)用TFLite開發(fā)智能質(zhì)檢一體機(jī)、智能讀碼機(jī)等產(chǎn)品,應(yīng)用到服裝廠質(zhì)檢等場(chǎng)景[25].
2 TensorFlow Lite系統(tǒng)架構(gòu)
我們?cè)O(shè)計(jì)TFLite,目標(biāo)是:
1) 輕量.縮小運(yùn)行庫(kù)和模型大小,減少內(nèi)存消耗,適用于更多設(shè)備.
2) 高性能.針對(duì)移動(dòng)和IoT設(shè)備深度優(yōu)化,利用多種硬件加速機(jī)器學(xué)習(xí),比如利用ARM CPU最新指令、GPU、DSP和NPU.
3) 跨平臺(tái)、兼容度高.支持安卓、iOS、嵌入式Linux以及MCU等多種平臺(tái),支持多種“一次轉(zhuǎn)換,隨處部署”.
4) 易用.與TensorFlow緊密集成,實(shí)現(xiàn)從訓(xùn)練到部署過程流暢,提供豐富的平臺(tái)相關(guān)API,提供豐富的模型庫(kù)、完整的實(shí)例和文檔,以及豐富的工具鏈,降低開發(fā)者使用門檻.
5) 可擴(kuò)展性.模塊化,易定制,容易擴(kuò)展到更多硬件支持,定制更多算子.

Fig.1 Main components of TFLite圖1 TFLite的主要組成部分
圖1展示了TFLite的主要組成部分:
1) TFLite模型轉(zhuǎn)換器[26](converter).TFLite自帶一個(gè)轉(zhuǎn)換器,它可以把TensorFlow計(jì)算圖,比如SavedModel或GraphDef格式的TensorFlow模型,轉(zhuǎn)換成TFLite專用的模型文件格式,在此過程中會(huì)進(jìn)行算子融合和模型優(yōu)化,以壓縮模型,提高性能.
2) TFLite解釋執(zhí)行器(interpreter).進(jìn)行模型推理的解釋執(zhí)行器,它可以在多種硬件平臺(tái)上運(yùn)行優(yōu)化后的TFLite模型,同時(shí)提供了多語(yǔ)言的API,方便使用.
3) 算子庫(kù)(op kernels).TFLite算子庫(kù)目前有130個(gè)左右,它與TensorFlow的核心算子庫(kù)略有不同,并做了移動(dòng)設(shè)備相關(guān)的優(yōu)化.
4) 硬件加速代理(hardware accelerator delegate).我們將TFLite硬件加速接口稱delegate(代理),它可以把模型的部分或全部委托給另一個(gè)硬件后臺(tái)執(zhí)行,比如GPU和NPU.
圖2展示了在TensorFlow 2.0中TFLite模型轉(zhuǎn)換過程,用戶在自己的工作臺(tái)中使用TensorFlow API構(gòu)造TensorFlow模型,然后使用TFLite模型轉(zhuǎn)換器轉(zhuǎn)換成TFLite文件格式(FlatBuffers格式).在設(shè)備端,TFLite解釋器接受TFLite模型,調(diào)用不同的硬件加速器比如GPU進(jìn)行執(zhí)行.
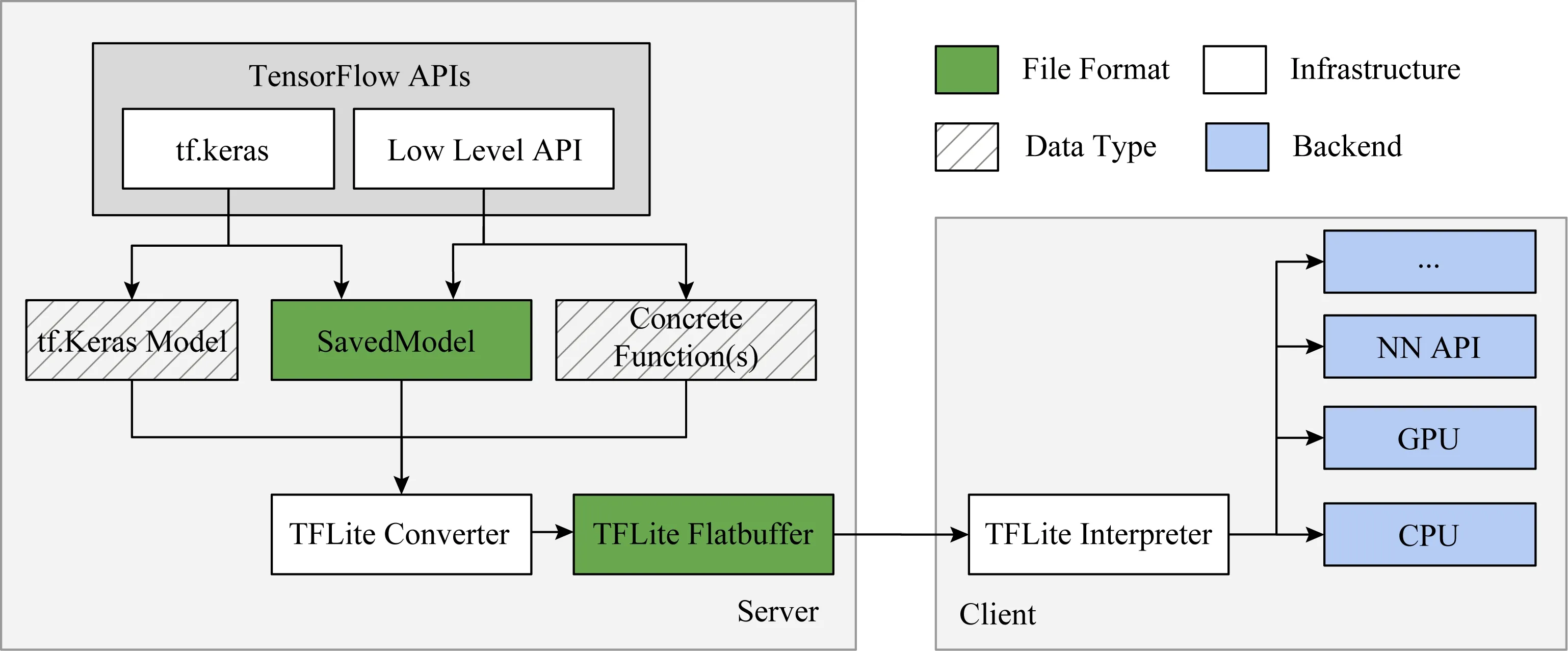
Fig. 2 TFLite model conversion圖2 TFLite模型轉(zhuǎn)換過程
2.1 TensorFlow Lite模型轉(zhuǎn)換器
圖2中描述了模型轉(zhuǎn)換過程,轉(zhuǎn)換器可以接受不同形式的模型,包括Keras Model和SavedModel(TF 2.0中推薦的格式),開發(fā)者可以用tf.Keras或者低層級(jí)的TensorFlow API來(lái)構(gòu)造TensorFlow模型,然后使用Python API或者命令行的方式調(diào)用轉(zhuǎn)換器(推薦使用Python API,更靈活).比如:
1) Python API.調(diào)用tf.lite.TFLiteConverter,可用TFLiteConverter.from_saved_model(),或TFLiteConverter.from_keras_model();
2) 命令行:tflite_convert--saved_model_dir=tmpmobilenet_saved_model--output_file=tmpmobilenet.tflite
在TF 1.x版本中,還支持GraphDef格式,如果需要,請(qǐng)使用:tf.compat.v1.lite.TFLiteConverter.
轉(zhuǎn)換器做了2類優(yōu)化工作:
1) 算子優(yōu)化和常見的編譯優(yōu)化,比如算子融合、常數(shù)折疊(constant folding)或無(wú)用代碼刪除等.TFLite實(shí)現(xiàn)了一組優(yōu)化的算子內(nèi)核,轉(zhuǎn)化成這些算子能在移動(dòng)設(shè)備上實(shí)現(xiàn)性能大幅度提升.比如讓我們將Relu融合到卷積等高級(jí)算子中,或優(yōu)化LSTM算子.
2) 量化的原生支持.在模型轉(zhuǎn)換過程中使用訓(xùn)練后量化(post-training quantization)非常簡(jiǎn)單,不需要改變模型,最少情況只需多加一行代碼,設(shè)置converter.optimizations=[tf.lite.Optimize.DEFAULT].
2.2 TensorFlow Lite FlatBuffers格式
TFLite模型文件格式采用FlatBuffers[27].與Protocol Buffers[28]類似,F(xiàn)latBuffers是Google的一個(gè)開源的跨平臺(tái)序列化格式,最初為視頻游戲而設(shè)計(jì).它在開發(fā)過程中更注重考慮實(shí)時(shí)性,內(nèi)存高效,這在內(nèi)存有限的移動(dòng)環(huán)境中是極為關(guān)鍵的.它支持將文件映射到內(nèi)存中(mmap),然后直接進(jìn)行讀取和解釋,不需要額外解析.我們將其映射到干凈的內(nèi)存頁(yè)上,減少了內(nèi)存碎片化.另外,相對(duì)于Protocol Buffers,它有更小的依賴,因此也會(huì)減小二進(jìn)制文件大小.
TFLite代碼中schema.fbs[29]文件使用FlatBuffers定義了TFLite模型文件格式,我們摘取了其中一些關(guān)鍵樣例代碼,以幫助理解模型所包含的信息,如圖3所示.TFLite模型文件是一個(gè)層次的結(jié)構(gòu):
1) TFLite模型(model)由子圖(subgraph)構(gòu)成,同時(shí)包括用到的算子庫(kù)和共享的內(nèi)存緩沖區(qū).
2) 張量(Tensor,多維數(shù)組)用于存儲(chǔ)模型權(quán)重,或者計(jì)算節(jié)點(diǎn)的輸入和輸出,它引用Model的內(nèi)存緩沖區(qū)的一片區(qū)域,提高內(nèi)存效率.
3) 每個(gè)算子實(shí)現(xiàn)有一個(gè)OperatorCode,它可以是內(nèi)置的算子,也可以是自定制算子,有一個(gè)名字.
4) 每個(gè)模型的計(jì)算節(jié)點(diǎn)(operator)包含用到的算子索引,以及輸入輸出用到的Tensor索引.
5) 每個(gè)子圖包含一系列的計(jì)算節(jié)點(diǎn)、多個(gè)張量,以及子圖本身的輸入和輸出.

Fig. 3 TFLite schema.fbs samples[29]圖3 TFLite schema.fbs樣例代碼[29]
模型轉(zhuǎn)換器最早來(lái)源于TFMini項(xiàng)目,稱為TOCO轉(zhuǎn)換器.最近我們基于Google最新的機(jī)器學(xué)習(xí)編譯技術(shù)MLIR[30]重寫了轉(zhuǎn)換器,將算子的TensorFlow dialect映射到算子的TFLite dialect.它提供了更好的轉(zhuǎn)換錯(cuò)誤追蹤和調(diào)試功能,也支持了更多的新模型(比如Mask R-CNN,Mobile BERT),特別是對(duì)控制流(control flow)有更好的支持.另外,也讓TFLite轉(zhuǎn)換器具有更好的可擴(kuò)展性,同時(shí)可以利用機(jī)器學(xué)習(xí)編譯技術(shù)的最新成果.
2.3 TensorFlow Lite解釋執(zhí)行器
TFLite解釋執(zhí)行器[31]針對(duì)移動(dòng)設(shè)備從頭開始構(gòu)建,具有3個(gè)特點(diǎn):
1) 輕量級(jí).在32 b安卓平臺(tái)下,編譯核心運(yùn)行時(shí)得到的庫(kù)大小只有100 KB左右,如果加上所有TFLite的標(biāo)準(zhǔn)算子,編譯后得到的庫(kù)大小是1 MB左右.它依賴的組件較少,力求實(shí)現(xiàn)不依賴任何其他組件.
2) 快速啟動(dòng).既能夠?qū)⒛P椭苯佑成涞絻?nèi)存中,同時(shí)又有一個(gè)靜態(tài)執(zhí)行計(jì)劃,在轉(zhuǎn)換過程中,我們基本上可以提前直接映射出將要執(zhí)行的節(jié)點(diǎn)序列.采取了簡(jiǎn)單的調(diào)度方式,算子之間沒有并行執(zhí)行,而算子內(nèi)部可以多線程執(zhí)行以提高效率.
3) 內(nèi)存高效.在內(nèi)存規(guī)劃方面,采取了靜態(tài)內(nèi)存分配.當(dāng)運(yùn)行模型時(shí),每個(gè)算子會(huì)執(zhí)行prepare函數(shù),它們做必要的內(nèi)存分配.我們會(huì)分配一個(gè)單一的內(nèi)存塊,而這些張量會(huì)被整合到這個(gè)大的連續(xù)內(nèi)存塊中.不同張量之間甚至可以復(fù)用內(nèi)存以減少內(nèi)存分配.
參照?qǐng)D3中TFLite模型格式,我們會(huì)執(zhí)行模型的子圖,而根據(jù)數(shù)據(jù)依賴關(guān)系,子圖中的計(jì)算節(jié)點(diǎn)已經(jīng)被提前靜態(tài)規(guī)劃好,保證每個(gè)計(jì)算節(jié)點(diǎn)在執(zhí)行前它所需要的張量已經(jīng)被之前的計(jì)算準(zhǔn)備好.所以,總體上依次執(zhí)行即可.
使用解釋執(zhí)行器通常需要包含4步:
1) 加載模型.將TFLite模型加載到內(nèi)存中,該內(nèi)存包含模型的執(zhí)行圖.
2) 轉(zhuǎn)換數(shù)據(jù).模型的原始輸入數(shù)據(jù)通常與所期望的輸入數(shù)據(jù)格式不匹配.例如,可能需要調(diào)整圖像大小,或更改圖像格式,以兼容模型.
3) 運(yùn)行模型推理.使用TFLite API執(zhí)行模型推理.
4) 解釋輸出.解釋輸出模型推理結(jié)果.比如,模型可能只返回概率列表,而我們需要將概率映射到相關(guān)類別,并將其呈現(xiàn)給最終用戶.
TFLite提供了多種語(yǔ)言的API,正式支持的有Java,C++和Python,實(shí)驗(yàn)性的包括C,Object C,C#和Swift.大家可以從頭自己編譯TFLite,也可以利用已編譯好的庫(kù),Android開發(fā)者可以使用JCenter Bintray的TFLite AAR,而iOS開發(fā)者可通過CocoaPods在iOS系統(tǒng)上獲取.

Fig. 4 TFLite Java API code samples圖4 TFLite Java API代碼樣例
圖4是使用Java API的一個(gè)示例:創(chuàng)建輸入緩沖區(qū)和輸出緩沖區(qū),填充輸入,并定制推理選項(xiàng)(比如是否使用GPU).之后創(chuàng)建TFLite執(zhí)行器,輸入TFLite模型并執(zhí)行.
2.4 高性能算子庫(kù)和可擴(kuò)展性
目前TFLite約有130個(gè)算子(op kernels),大多同時(shí)支持浮點(diǎn)和量化類型,可以在這里找到所有支持的算子[32].很多算子專門針對(duì)ARM CPU進(jìn)行了優(yōu)化,包括基于匯編和intrinsics級(jí)別的NEON指令集的多種優(yōu)化.針對(duì)矩陣相乘,算子之前浮點(diǎn)運(yùn)算使用Eigen,量化運(yùn)算使用gemmlowp[33],最近我們重新設(shè)計(jì)了一個(gè)叫Ruy[34]的高性能矩陣相乘庫(kù),統(tǒng)一了浮點(diǎn)運(yùn)算和量化運(yùn)算,并且性能有較大提升.特別針對(duì)一些重度使用的算子做了深度優(yōu)化,比如涉及到卷積或者LSTM的算子.另外,不少算子支持多線程執(zhí)行.
算子的定義基于C語(yǔ)言接口TfLiteRegistration,包括4個(gè)函數(shù)(init,free,prepare,invoke),開發(fā)者可方便自定義算子.
在創(chuàng)建解釋器時(shí),用戶可以提供自定義的算子解析器(OpResolver),從而控制模型執(zhí)行所用到的算子實(shí)現(xiàn),如圖5所示.使用內(nèi)置算子解析器(BuiltinOpResolver)時(shí)使用默認(rèn)的算子.每個(gè)算子都有自己的版本控制.我們還提供機(jī)制,把不用的算子自動(dòng)刪掉.

Fig. 5 TFLite customized op圖5 TFLite自定義算子
當(dāng)遇到不能支持的算子時(shí),可以自定義算子,另外一種選擇是,復(fù)用TensorFlow算子,稱為Select TF Ops,只需要多加一行轉(zhuǎn)換器參數(shù)就可以開啟:
converter.target_spec.supported_ops=[tf.lite.OpsSet.TFLITE_BUILTINS,tf.lite.OpsSet.SELECT_TF_OPS]
它可能帶來(lái)的問題是所依賴的運(yùn)行庫(kù)更大,同時(shí)TensorFlow算子在移動(dòng)設(shè)備中未必足夠優(yōu)化.
2.5 CPU性能
CPU最具普適性,其性能最為關(guān)鍵,因此我們持續(xù)不斷提升CPU性能.矩陣運(yùn)算(GEMM[35])效率對(duì)于深度學(xué)習(xí)非常關(guān)鍵,過去我們使用gemmlowp[33]庫(kù)進(jìn)行量化矩陣乘法,使用Eigen庫(kù)進(jìn)行浮點(diǎn)乘法.最近,我們從頭開發(fā)了一個(gè)針對(duì)移動(dòng)環(huán)境CPU特別優(yōu)化的矩陣乘法庫(kù)Ruy[34],統(tǒng)一了浮點(diǎn)運(yùn)算和量化運(yùn)算.之前面向桌面和云端的矩陣乘法庫(kù)則更加專注于大矩陣乘法的峰值性能,而Ruy對(duì)各種矩陣大小的乘法都表現(xiàn)優(yōu)異:不僅適合大矩陣,也適合當(dāng)前TFLite應(yīng)用中最常見的矩陣運(yùn)算(往往是小矩陣或者多種多樣的矩陣形狀).Ruy目前支持浮點(diǎn)數(shù)和8 b整型,主要針對(duì)ARM CPU(64 b和32 b),而我們也在針對(duì)英特爾x86架構(gòu)進(jìn)行優(yōu)化.
自TensorFlow 1.15版本開始,Ruy在所有ARM設(shè)備上默認(rèn)啟用,大范圍地加速了模型,特別是那些卷積比較多的視覺模型,將延遲降低了1.2~5倍,尤其在具有NEON點(diǎn)積內(nèi)置函數(shù)的硬件上.圖6以最常見的MobileNet V1為例,浮點(diǎn)模型和量化模型都有明顯提高.

Fig. 6 Single thread CPU on Pixel4 圖6 Pixel 4上單線程CPU性能
性能提升工作需要持續(xù)不斷的努力,另一個(gè)即將到來(lái)的新突破,是全新的高度優(yōu)化后的浮點(diǎn)卷積核庫(kù)XNNPACK[36].在TFLite支持的所有關(guān)鍵浮點(diǎn)卷積模型上的測(cè)試結(jié)果表明,XNNPACK可以進(jìn)一步提高執(zhí)行速度.
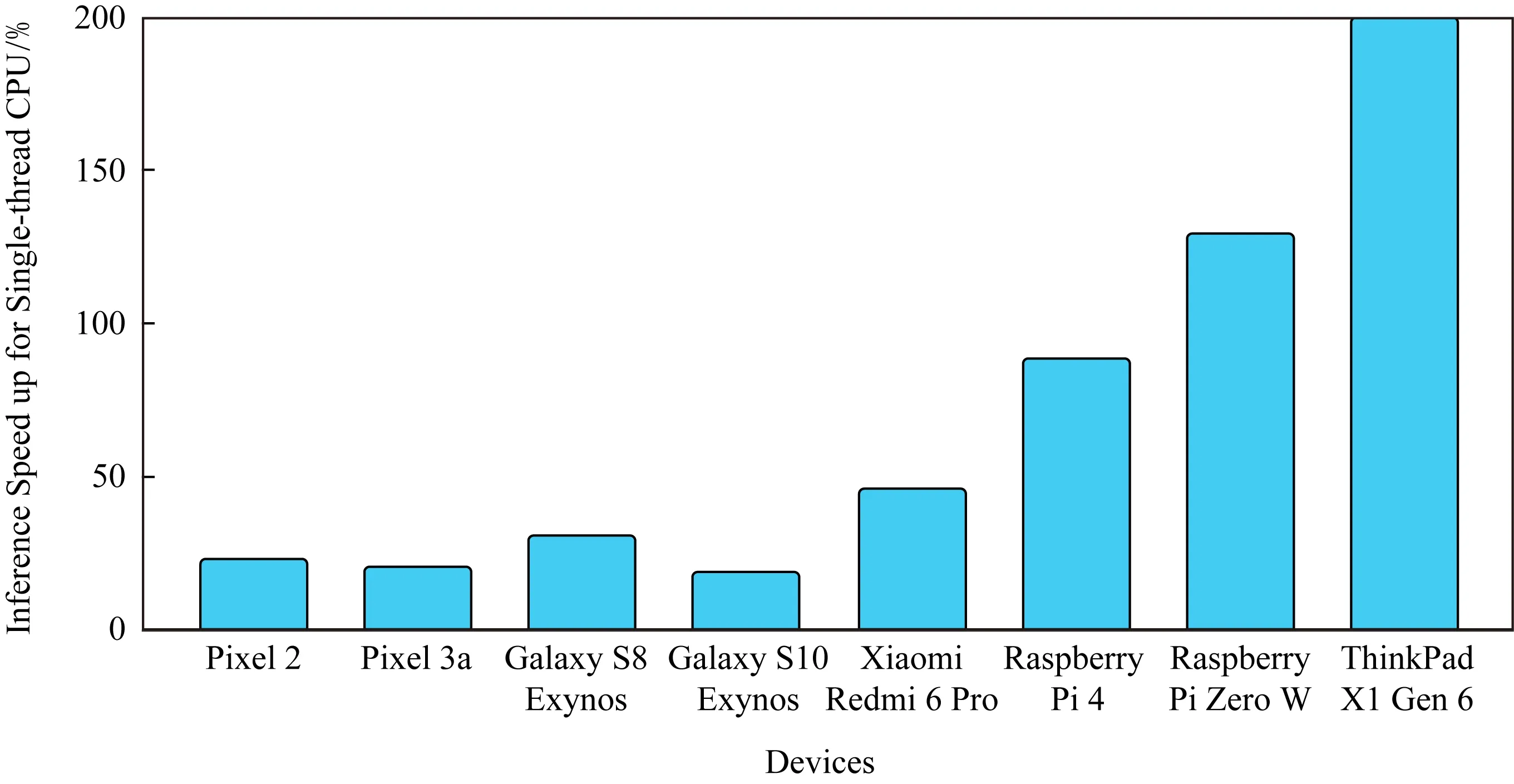
Fig. 7 Single thread CPU performance improvement with XNNPACK (Jun 2020)圖7 使用XNNPACK后單線程CPU性能提升比例(2020年6月)
以MobileNet V1浮點(diǎn)模型為例,如圖7所示,在多種硬件平臺(tái)上,使用XNNPACK后,單線程CPU性能提升達(dá)20%~200%.比如在X86 Windows平臺(tái)上,有了2倍的提升.我們將在TensorFlow 2.3版本中集成XNNPACK,并計(jì)劃在2.4版本中對(duì)于浮點(diǎn)模型,在所有平臺(tái)中默認(rèn)使用XNNPACK.
2.6 硬件加速器代理
我們將TFLite硬件加速接口稱delegate[37](代理),它可以把模型計(jì)算圖的部分或全部代理給另一個(gè)執(zhí)行器,讓它們?cè)谟布铀倨髦袌?zhí)行.在圖8示例中,整個(gè)計(jì)算圖一部分在CPU中執(zhí)行,另一部分子圖被代理給硬件加速器執(zhí)行.

Fig. 8 TFLite hardware delegate example圖8 TFLite硬件加速器代理示意
我們不是把算子逐一放到加速器上執(zhí)行,而是將計(jì)算圖的整個(gè)子圖在加速器上運(yùn)行,這對(duì)于GPU或NPU(神經(jīng)網(wǎng)絡(luò)加速器)等需要在設(shè)備上盡可能多地進(jìn)行計(jì)算,且中間沒有CPU互操作的設(shè)備而言,是一個(gè)巨大的優(yōu)勢(shì).
TFLite有著非常豐富的硬件加速器支持:在Android系統(tǒng)中,支持NNAPI,GPU,EdgeTPU和Hexagon DSP delegates;在iOS系統(tǒng)中,有Metal和CoreML delegates.
1) GPU delegate[38].適用于跨平臺(tái).GPU delegate可在Android和iOS上使用,支持32 b和16 b浮點(diǎn)的模型,對(duì)許多浮點(diǎn)卷積模型實(shí)現(xiàn)了大幅度速度提升,尤其是較大的模型.不過,運(yùn)行庫(kù)大小會(huì)有小幅度的增加.GPU的驅(qū)動(dòng)可以有不同的后端,Android系統(tǒng)有OpenGL,OpenCL和VulKan后端,以及iOS上基于Metal的后端.我們最近增加了對(duì)OpenCL的支持,在多個(gè)視覺模型上進(jìn)行的測(cè)試表明,基于OpenCL的GPU delegate的性能提升為CPU上的4~6倍和OpenGL的2倍.圖9是三者在Pixel 4上測(cè)試后端性能的對(duì)照結(jié)果.
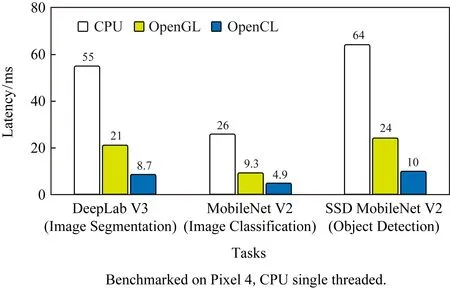
Fig. 9 TFLite GPU performance圖9 TFLite GPU性能
2) Android NNAPI delegate[39].適用于較新的Android設(shè)備.NNAPI delegate可用于在具有GPU,DSP和NPU的Android設(shè)備上加速模型.它在Android 8.1(API 27+)或更高版本中可用.NNAPI[40]是Android系統(tǒng)中用于加速機(jī)器學(xué)習(xí)的抽象層.在NNAPI和TFLite中,我們會(huì)發(fā)現(xiàn)高級(jí)算子的定義有很多相似之處,因?yàn)槎呤蔷o密聯(lián)系在一起進(jìn)行開發(fā)的.NNAPI是Android平臺(tái)級(jí)的硬件加速器抽象層,我們可以通過TFLite調(diào)用它,而供應(yīng)商比如高通則為NNAPI提供DSP或GPU的驅(qū)動(dòng)程序.在Android Q上,NNAPI真正進(jìn)入了一個(gè)良好的穩(wěn)定狀態(tài),功能和算子方面都正在接近TFLite的同等水平.有越來(lái)越多的用戶和硬件供應(yīng)商予以采用,這促進(jìn)了這些驅(qū)動(dòng)程序的發(fā)展.
3) Hexagon delegate[41](DSP).適用于較舊的Android設(shè)備.Hexagon DSP是一種微處理器,常見于大量使用高通驍龍SoC的安卓手機(jī).與CPU相比,新的TFLite Hexagon delegate利用DSP實(shí)現(xiàn)了MobileNet和InceptionV3等模型,性能大幅提升,提升幅度可達(dá)3~25倍,同時(shí)CPU和GPU的能效也得到了提升[42].它可以在不完全支持NNAPI的舊版Android設(shè)備上使用.
4) Core ML delegate[43].適用于較新的iPhone和iPad.CoreML是在蘋果設(shè)備上使用的機(jī)器學(xué)習(xí)框架,它還提供了在Neural Engine上運(yùn)行機(jī)器學(xué)習(xí)模型的API.CoreML delegate允許在CoreML和Neural Engine(如果設(shè)備有相關(guān)芯片)上運(yùn)行TFLite模型,以更低的功耗實(shí)現(xiàn)更快的推理速度.在含有Neural Engine的iPhone XS以及后續(xù)發(fā)布的設(shè)備上,測(cè)試表明各種計(jì)算機(jī)視覺模型的性能提高了1.3~11倍[44].
圖10給出了使用TFLite GPU delegate的Java示例,只需要多加幾行代碼,非常簡(jiǎn)單,而其他delegate也類似.值得注意的是,圖中的delegate.bindGlBufferToTensor可以使用OpenGL紋理作為計(jì)算圖輸入,這樣數(shù)據(jù)就不用復(fù)制,減少在CPU和GPU之間來(lái)回傳送數(shù)據(jù).

Fig. 10 Use TFLite GPU delegate in Java圖10 使用TFLite GPU delegate的Java示例
可擴(kuò)展性是TFLite很重要的設(shè)計(jì)目標(biāo),如果一些硬件后端默認(rèn)還不支持,完全可以自己定制delegate,只需要:
1) 定義一個(gè)新的delegate算子,它負(fù)責(zé)計(jì)算被代理的子圖.
2) 創(chuàng)建一個(gè)TfLiteDelegate實(shí)例,它負(fù)責(zé)注冊(cè)新定義的delegate算子,并可以把計(jì)算圖中的一些子圖替換為新的delegate算子.
這樣,應(yīng)用開發(fā)者可以利用新的加速器,同時(shí)硬件廠商也可以擴(kuò)展對(duì)TFLite的支持,從而觸及更多的用戶.
我們正在持續(xù)改進(jìn)如何更方便地實(shí)現(xiàn)一個(gè)新TFLite delegate,以及提供可擴(kuò)展的工具鏈來(lái)驗(yàn)證測(cè)試這一新delegate.目前推薦擴(kuò)展SimpleDelegate相關(guān)APIs[45]來(lái)實(shí)現(xiàn),具體可以參考我們提供的簡(jiǎn)單案例[46]來(lái)進(jìn)一步了解,包括如何集成到我們的測(cè)試和驗(yàn)證工具鏈當(dāng)中.更多請(qǐng)參考delegate使用開發(fā)指南[37].
2.7 TensorFlow Lite微控制器版
1.4節(jié)提到,MCU沒有操作系統(tǒng),只有極小內(nèi)存,低功耗、便宜、無(wú)處不在.真正在MCU上部署機(jī)器學(xué)習(xí)模型變得很普及時(shí),智能開始無(wú)處不在.TFLite可以支持微控制器MCU,為IoT領(lǐng)域的智能化帶來(lái)很多想象空間.
TFLite微控制器版(TFLite for Microcontrollers)[47]接受和TFLite同樣的FlatBuffers模型格式,讓同樣的模型可運(yùn)行在手機(jī)和MCU上,減輕了開發(fā)者負(fù)擔(dān).它的核心運(yùn)行庫(kù)在Arm Cortex M3上小于16 KB,加上一些關(guān)鍵詞檢測(cè)的算子,總共只需要22 KB.
它支持ARM Cortex-M系列芯片以及其他架構(gòu)比如ESP32.也可以作為Arduino庫(kù),對(duì)MBed開發(fā)環(huán)境也有很好的支持.最近,Cadence宣布旗下的Tensilica HiFi DSP系列也支持TFLite微控制器版[48].
MCU上的模型都非常小,低功耗,只能完成簡(jiǎn)單的功能,不過可以常駐內(nèi)存,一直處于等待觸發(fā)狀態(tài).一般常見的用法是級(jí)聯(lián)觸發(fā):比如先用MCU的一個(gè)模型檢測(cè)是否有聲音,如果是,另一個(gè)MCU模型判斷這是不是人的聲音(排除外界噪音),更進(jìn)一步才開啟設(shè)備CPU上更強(qiáng)大的語(yǔ)音識(shí)別功能.如果設(shè)備需要開啟CPU持續(xù)監(jiān)聽外界的聲音,功耗會(huì)很大.
我們開源了很多有意思的樣例,比如:
1) 識(shí)別若干關(guān)鍵詞的語(yǔ)音識(shí)別模型,只有20 KB左右.
2) 魔法棒.只需要20 KB左右的模型就可以做姿態(tài)檢測(cè),這很適合一些使用加速計(jì)數(shù)據(jù)的應(yīng)用.
3) 人物識(shí)別.250 KB的視覺模型識(shí)別攝像頭是否有人出現(xiàn).
3 使用TensorFlow Lite的最佳實(shí)踐
3.1 解決模型轉(zhuǎn)換挑戰(zhàn)
目前TFLite約有130個(gè)算子,大多同時(shí)支持浮點(diǎn)和量化類型,可以在這里找到所有支持的算子[32].TensorFlow有一些語(yǔ)義在TFLite中尚未得到很好的原生支持,同時(shí)在模型轉(zhuǎn)換過程中算子進(jìn)行了優(yōu)化和融合.總結(jié)一下TensorFlow算子和TFLite算子的兼容性:
1) 大多TFLite算子支持float32和量化(int8,uint8),不過很多算子尚不支持bfloat16或string.
2) TFLite目前只支持TensorFlow的某些固定格式,而廣播只支持有限的一些ops(比如tf.add,tf.mul,tf.sub,andtf.div,tf.min,tf.max).
3) 一些TensorFlow算子有嚴(yán)格對(duì)應(yīng)的TFLite算子,比如tf.nn.avg_pool,tf.nn.conv2d,tf.nn.depthwise_conv2d,tf.nn.l2_normalize,tf.nn.max_pool,tf.nn.softmax,tf.nn.top_k等,以及tf.matmul,tf.one_hot,tf.reduce_mean,tf.reshape,tf.sigmoid,tf.squeeze,tf.strided_slice,tf.transpose等.詳細(xì)清單請(qǐng)參考文獻(xiàn)[32].
4) 另外很多TensorFlow算子,沒有一一對(duì)應(yīng)的TFLite算子,不過TFLite仍可以支持,在模型轉(zhuǎn)換過程得到優(yōu)化.這些TensorFlow算子可能被刪除(比如tf.identity),替換(比如tf.placeholder被換成張量),或者融合為更復(fù)雜的操作(比如tf.nn.bias_add).詳細(xì)清單請(qǐng)參考文獻(xiàn)[32].
如遇到模型轉(zhuǎn)換問題,請(qǐng)嘗試如下解決方法:
1) 自定義算子.可以自定義新的算子,或者提供定制的更優(yōu)化的算子.這種方式對(duì)于開發(fā)者而言最靈活,可控性高.
2) 使用其他等價(jià)算子.可以替換為其他TFLite能支持的算子,假設(shè)模型更改后精度和速度等方面沒有明顯損失.
3) Select TF Ops.可以重用TensorFlow算子,缺點(diǎn)是二進(jìn)制文件大小會(huì)有所增加,速度也可能會(huì)慢些.
5) 控制流(control flow)支持.最新的基于MLIR的模型轉(zhuǎn)換器已經(jīng)對(duì)此有不錯(cuò)的支持.
6) 動(dòng)態(tài)張量形狀(dynamic tensor shape)的支持.目前對(duì)動(dòng)態(tài)張量形狀支持有限,需要在轉(zhuǎn)化時(shí)將輸入設(shè)置成固定大小,隨后在運(yùn)行時(shí)調(diào)用ResizeInput.設(shè)置輸入為固定大小的技巧包括調(diào)整圖片大小,或者為文字加填充.
一方面,算子在不斷增加中,我們也在為TFLite增加動(dòng)態(tài)張量形狀等更多新功能的支持.持續(xù)關(guān)注社區(qū)和github更新,可嘗試每日更新的代碼是否已支持;還可以向社區(qū)發(fā)issue或者直接貢獻(xiàn)代碼.
3.2 進(jìn)行模型優(yōu)化
壓縮模型可以加速模型執(zhí)行,更好地利用硬件加速器,特別是當(dāng)一些加速器只能接受全整型的模型時(shí).模型壓縮領(lǐng)域是很熱的研究話題,而我們則更關(guān)注足夠簡(jiǎn)單的開發(fā)體驗(yàn),希望用戶只需要幾行代碼就可以實(shí)現(xiàn).TensorFlow提供了一個(gè)模型優(yōu)化工具包(TensorFlow model optimization toolkit, MOT)[52],簡(jiǎn)化模型優(yōu)化過程.MOT被很好地集成到了TFLite工具鏈中,可在TFLite模型轉(zhuǎn)換時(shí)輕松啟用.
MOT目前主要支持2類優(yōu)化:
1) 量化(quantization).降低模型參數(shù)精度,比如將浮點(diǎn)轉(zhuǎn)換成整型.
2) 剪枝(pruning).減少模型參數(shù),比如去掉那些不重要的權(quán)重(比如為0的權(quán)重).
從開發(fā)者使用體驗(yàn)來(lái)看,又可以分為:
1) 訓(xùn)練后(post-training).比如訓(xùn)練后量化(post-training quantization),不需要改變模型,非常簡(jiǎn)單.
2) 訓(xùn)練中(training-aware).需要改動(dòng)模型,在訓(xùn)練的時(shí)候優(yōu)化.
推薦訓(xùn)練后量化(post-training quantization)[53],足夠簡(jiǎn)單,只要能滿足需求.

Table 1 TFLite Post-Training Quantization

Fig. 11 Quantization: map 32 b float to 8 b integer圖11 量化:將32 b浮點(diǎn)數(shù)映射到8 b整數(shù)
最初引入的是動(dòng)態(tài)范圍量化(dynamic range quantization),它可以動(dòng)態(tài)地對(duì)輸入和激活函數(shù)做量化和去量化,是一種混合量化:當(dāng)有量化算子支持時(shí),調(diào)用量化算子核,否則使用浮點(diǎn)算子核,整個(gè)執(zhí)行過程混合了2類算子.精度上會(huì)有所損失,損失多大取決于具體模型.圖11展示了如何將32 b浮點(diǎn)數(shù)映射到8 b整數(shù).它貴在簡(jiǎn)單,只需在轉(zhuǎn)化時(shí)多加一行代碼:converter.optimizations=[tf.lite.Optimize.DEFAULT].
而全整型量化[54]可以同時(shí)量化權(quán)重和激活函數(shù),這樣所有的權(quán)重和計(jì)算都是整形的,可以進(jìn)一步改善延遲,減少峰值內(nèi)存使用量,以及利用僅支持整數(shù)的硬件加速器.
為進(jìn)一步提高精度,我們支持了按軸量化或按通道量化:不會(huì)對(duì)整個(gè)張量使用同一組量化參數(shù),而是對(duì)張量中每個(gè)通道使用不同的量化參數(shù).為此,需要使用代表性數(shù)據(jù)集來(lái)評(píng)估激活函數(shù)和輸入的動(dòng)態(tài)范圍,幫助確定量化參數(shù),這樣可以實(shí)現(xiàn)與訓(xùn)練時(shí)量化大體相當(dāng)?shù)木_度.對(duì)于一個(gè)基于圖片的模型而言,或許只需要輸入30張圖片,就能夠探索出量化和輸出值的空間.
開發(fā)者只需創(chuàng)建一個(gè)輸入數(shù)據(jù)生成器,并將代表性數(shù)據(jù)提供給TFLite轉(zhuǎn)換器即可:
converter.representative_dataset=representative_dataset_gen
如有GPU,則考慮使用16 b浮點(diǎn)數(shù),進(jìn)一步減少精度損失:
converter.target_spec.supported_types=[tf.lite.constants.FLOAT16]
訓(xùn)練時(shí)優(yōu)化,需要對(duì)于模型訓(xùn)練過程做一些改變,相對(duì)更復(fù)雜.為盡量簡(jiǎn)化用戶體驗(yàn),MOT針對(duì)Keras提供了非常便捷的API.目前可以支持:
1) 訓(xùn)練時(shí)量化(training-aware quantization).可以量化整個(gè)Keras模型和部分Keras模型節(jié)點(diǎn).
2) 剪枝(pruning).去掉一些權(quán)重,讓模型更稀疏.
比如量化整個(gè)Keras模型只需要增加一行:
quantized_model=mot.quantization.keras.quantize_model(keras_model)
MOT在壓縮Google的一些關(guān)鍵模型發(fā)揮著重要作用,比如1.4節(jié)提到的離線語(yǔ)音模型.我們一直致力于開發(fā)一些更易用的工具,既簡(jiǎn)化操作,又能夠在模型壓縮比和加速性能方面同樣優(yōu)異.比如,之前的訓(xùn)練時(shí)量化工具需要在模型中插入偽量化(fake quantization)節(jié)點(diǎn),相對(duì)復(fù)雜,因此我們發(fā)布了新的更易使用的基于Keras訓(xùn)練時(shí)量化[55].
我們也在探索更多壓縮方法的支持,比如張量壓縮算法或者模型蒸餾.
3.3 減少運(yùn)行庫(kù)大小
除了壓縮模型本身,我們也希望減少運(yùn)行庫(kù)大小.一個(gè)技巧就是只鏈接所需要的算子,因?yàn)橥ǔR粋€(gè)模型只用到部分算子,我們稱之為選擇性注冊(cè)(selective registration).
TFLite有很好的可擴(kuò)展性,可以自己定義算子和算子解析器.我們?cè)趖ensorflowlitetools下提供了工具,給定一個(gè)模型,可以掃描用到的算子,自動(dòng)生成一個(gè)注冊(cè)實(shí)際算子的代碼文件,這樣利用自定義的算子解析器,就可以刪除不用的算子內(nèi)核.
3.4 選擇正確的模型
選擇合適的模型非常關(guān)鍵,這很大程度上取決于應(yīng)用的需求,比如:
1) 模型大小的限制;
2) 模型延遲的需求;
3) 精度要求;
4) 硬件運(yùn)行環(huán)境.
可以嘗試不同的模型,對(duì)各個(gè)方面做取舍.比如,如果精度要求高而硬件許可,可以選擇較復(fù)雜的模型;而速度最關(guān)鍵時(shí),選擇簡(jiǎn)單而精度低的模型.
研究領(lǐng)域發(fā)布的模型日新月異,開發(fā)人員很難時(shí)刻跟進(jìn),另外,論文上的精度更多是理想情況,是否在真實(shí)場(chǎng)景下有穩(wěn)定表現(xiàn)還需要根據(jù)實(shí)際場(chǎng)景評(píng)估.通常情況下,我們可以從一些經(jīng)典的針對(duì)移動(dòng)特別優(yōu)化的在工業(yè)界久經(jīng)考驗(yàn)的模型開始,比如MobileNet.
可以嘗試在目標(biāo)手機(jī)上運(yùn)行一些TFLite的參考應(yīng)用[56],感受模型實(shí)際取得的效果,比如對(duì)象追蹤應(yīng)用的流暢程度.
TFHub上提供了一系列的經(jīng)典模型[57],既有預(yù)訓(xùn)練的TF模塊,可做遷移學(xué)習(xí)后轉(zhuǎn)換到TFLite模型,也可以直接下載TFLite模型.機(jī)器學(xué)習(xí)是一個(gè)飛速發(fā)展的領(lǐng)域,也許每隔幾個(gè)月就有新的模型刷新記錄.我們?cè)谂Υ_保最前沿(SOTA)的模型可以在TFLite上運(yùn)行.
最近,我們?cè)黾恿藢?duì)EfficientNet-Lite(圖像分類模型系列)[58],MobileBERT[59]和ALBERT-Lite[60](支持多種NLP任務(wù)的輕量級(jí)版本BERT)的支持.
EfficientNet-Lite是一種新穎的圖像分類模型,可通過減少計(jì)算和參數(shù)的數(shù)量級(jí)來(lái)實(shí)現(xiàn)SOTA的準(zhǔn)確性.它針對(duì)TFLite量化方式進(jìn)行了優(yōu)化,在損失較低精度(幾乎可忽略)的同時(shí)大大提升了推理速度,并可以運(yùn)行在CPU,GPU和EdgeTPU上[61].
圖12中,在相似的高精度下,EifficientNet-Lite4比Inception V4有顯著的速度提升.
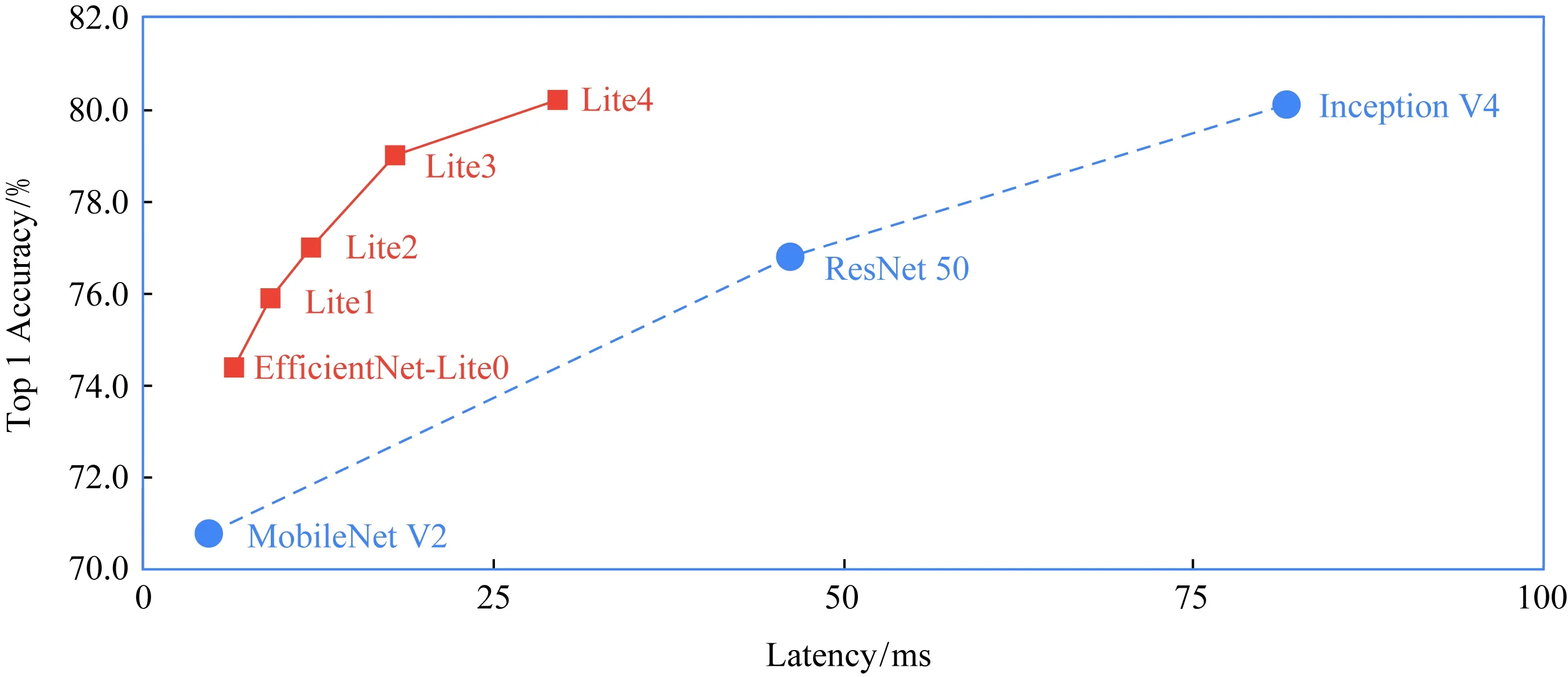
Fig. 12 Benchmarked on Pixel 4 CPU with 4 threads (March 2020)圖12 在四線程Pixel 4 CPU上做基準(zhǔn)測(cè)試(2020年3月)
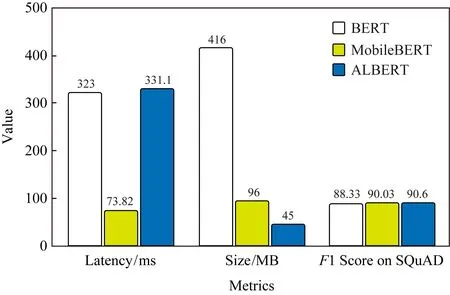
Fig. 13 Benchmarked on Pixel4,Float32 QA model, 4 threads CPU圖13 在Pixel 4,F(xiàn)loat32問答模型,4線程CPU上評(píng)測(cè)
MobileBERT[62]和ALBERT-Lite[63]是流行的BERT模型的優(yōu)化版本,該模型在一系列NLP任務(wù)(包括問答、自然語(yǔ)言推斷等)上均達(dá)到了SOTA的準(zhǔn)確度.圖13中,MobileBERT的體積是BERT的14,速度是BERT的4倍,同時(shí)保持了相近的準(zhǔn)確度.ALBERT-Lite的體積甚至更小,僅有BERT的16,也就是MobileBERT體積的23,在速度上ALBERT-Lite稍遜于MobileBERT.我們還在探索量化版本的MobileBERT,它是BERT的116,速度是BERT的8倍,同時(shí)也保持了相近的準(zhǔn)確度,MLPerf社區(qū)正嘗試基于此建立移動(dòng)硬件加速的NLP測(cè)試基準(zhǔn).
3.5 性能的最佳實(shí)踐
TFLite性能測(cè)試工具[64]可以找出在特定設(shè)備上運(yùn)行時(shí)的性能瓶頸,輸出耗時(shí)長(zhǎng)的算子,還可以插入不同的計(jì)算后端,并探索它究竟是如何影響推理性能的.它支持對(duì)內(nèi)部事件(如算子調(diào)用)的檢測(cè)日志記錄,可以通過Android的系統(tǒng)跟蹤(system tracing)[65]進(jìn)行追蹤.
以下是性能分析工具給出的分析示例,及性能提升的備選解決方案:
1) 如果可用的CPU內(nèi)核數(shù)量少于推理線程的數(shù)量,則CPU調(diào)度開銷可能會(huì)導(dǎo)致性能下降.可以在應(yīng)用程序中重新調(diào)度其他大量占用CPU的任務(wù),以避免與模型推斷重疊,或嘗試調(diào)整解釋器線程的數(shù)量.
2) 如果算子沒有完全被代理到GPU上執(zhí)行,那么模型計(jì)算圖中的某些部分將在CPU上執(zhí)行,而不是按預(yù)想的在硬件加速器上執(zhí)行.可以將不支持的算子替換為相似的已支持算子.
盡可能優(yōu)化模型,比如量化.盡可能地使用硬件加速器,也注意一些性能負(fù)擔(dān),比如內(nèi)存零拷貝.
當(dāng)然,移動(dòng)平臺(tái)可能具有多種硬件加速器,而模型的選擇也很多(比如模型類型、量化或浮點(diǎn)),組合起來(lái)比較復(fù)雜.同時(shí)這些加速器也可能需要被用作其他用途,比如GPU可能需要預(yù)留給視頻處理,這帶來(lái)了優(yōu)化的復(fù)雜度.通常情況下,需要在不同平臺(tái)上嘗試運(yùn)行應(yīng)用,統(tǒng)計(jì)數(shù)據(jù),根據(jù)數(shù)據(jù)進(jìn)行優(yōu)化.我們也在探索提供更好的開發(fā)者工具支持.
3.6 TensorFlow Lite的使用限制
由于TensorFlow算子豐富,而新模型也不斷出現(xiàn),雖然TFLite覆蓋了很多常見的模型,對(duì)于普通開發(fā)者,模型轉(zhuǎn)換仍是較大的痛點(diǎn).請(qǐng)參考3.1節(jié)部分解決,比如自定義算子,利用Select TF Ops.
TFLite目前對(duì)動(dòng)態(tài)張量形狀支持有限,需要在轉(zhuǎn)化時(shí)將輸入設(shè)置成固定大小,隨后在運(yùn)行時(shí)調(diào)用ResizeInput.很多TFLite ops可能還不支持bfloat和string.另外,TFLite目前只支持TensorFlow的某些固定格式,而廣播只支持有限的一些ops(比如tf.add,tf.mul,tf.sub,andtf.div,tf.min,tf.max)[32].
硬件加速部分,delegate的算子不支持仍是主要挑戰(zhàn).總體而言,CPU算子有較好的覆蓋率,而GPU和DSP等覆蓋率相對(duì)小一些;而NNAPI的算子則更新速度較慢,且其硬件驅(qū)動(dòng)的性能不一,建議進(jìn)行實(shí)際模型性能測(cè)試.如碰到問題,歡迎到社區(qū)里反饋.
社區(qū)對(duì)于個(gè)性化的應(yīng)用和聯(lián)邦學(xué)習(xí)(federated learning[66])的興趣逐步增強(qiáng),因此對(duì)于端側(cè)訓(xùn)練的需求越來(lái)越多.目前TFLite對(duì)于端側(cè)訓(xùn)練還不支持.我們提供了一個(gè)TFLite案例,允許有限的端側(cè)模型遷移,從而讓端側(cè)模型個(gè)性化,不過使用相對(duì)復(fù)雜[67].
4 適合初學(xué)者的工具
4.1 預(yù)訓(xùn)練模型和完整參考示例
我們提供了預(yù)訓(xùn)練模型的代碼庫(kù)和實(shí)現(xiàn)這些模型的示例應(yīng)用[56,68],開發(fā)者無(wú)需編寫任何代碼即可在實(shí)際設(shè)備上試用TFLite模型,并可以在github找到完整應(yīng)用代碼,包括模型的前處理和后處理.包括多種案例,比如對(duì)象追蹤、風(fēng)格遷移和問題回答,也包括不同平臺(tái)的例子,比如Android、WiOS、樹莓派及MCU.
比如,在手機(jī)上實(shí)現(xiàn)問題問答[17]是一個(gè)很有挑戰(zhàn)的問題,我們發(fā)布了基于MobileBERT的參考應(yīng)用,學(xué)術(shù)界的多個(gè)BERT模型可以在這個(gè)應(yīng)用上運(yùn)行.風(fēng)格遷移模型[69]啟發(fā)了Google Arts & Culture的產(chǎn)品新特性[14].
對(duì)于視頻處理應(yīng)用,MediaPipe[70]提供了很好的框架,可以和TFLite配合使用.MediaPipe也有豐富應(yīng)用例子,比如手勢(shì)追蹤.
另外,社區(qū)github項(xiàng)目“Awesome TFLite”[71],收集了很多有意思的示例.
4.2 TensorFlow Lite Model Maker
TFLite Model Maker[72]使用遷移學(xué)習(xí),可讓開發(fā)者在自己的數(shù)據(jù)集上應(yīng)用最前沿的機(jī)器學(xué)習(xí)模型.它將復(fù)雜的機(jī)器學(xué)習(xí)概念封裝在直觀的API中,無(wú)需機(jī)器學(xué)習(xí)專業(yè)知識(shí),只需幾行代碼即可訓(xùn)練最新的圖像分類模型:

Fig. 14 TFLite Model Maker example圖14 TFLite Model Maker示例
ModelMaker支持TensorFlowHub上的許多最新模型,如3.5節(jié)EfficientNet-Lite.如果想獲得更高的準(zhǔn)確率,僅需修改一行代碼,即可切換到不同的模型架構(gòu).目前支持圖片分類和文本分類任務(wù),我們還在不斷擴(kuò)展其功能.
4.3 TensorFlow Lite Support庫(kù)
執(zhí)行模型推理前,通常需要對(duì)輸入數(shù)據(jù)做轉(zhuǎn)換,稱為前處理,比如圖片裁剪和大小挑戰(zhàn).而推理之后,如何解讀數(shù)據(jù),又需要做后處理.
為簡(jiǎn)化開發(fā)流程,我們提供了TFLite Support[73]庫(kù),它提供了一系列工具庫(kù).目前支持圖片處理庫(kù),更多數(shù)據(jù)類型(比如NLP)和更多平臺(tái)(比如iOS)的支持正在進(jìn)展當(dāng)中.
4.4 模型元數(shù)據(jù)、自動(dòng)代碼生成和Android Studio工具
直接使用TFLite解釋器,它的輸入輸出都是張量.這帶來(lái)了2個(gè)問題:
1)TFLite模型的使用者將需要確切地知道一個(gè)1×224×224×3張量的含義.比如它是位圖嗎?特別是模型創(chuàng)建團(tuán)隊(duì)和使用團(tuán)隊(duì)不是同一個(gè)時(shí),更容易出問題.
2)對(duì)高維數(shù)據(jù)進(jìn)行轉(zhuǎn)換時(shí)容易出錯(cuò),例如把Bitmap轉(zhuǎn)換為RGB浮點(diǎn)數(shù)組或者ByteArray.
我們希望把模型調(diào)用并做前后處理的整個(gè)復(fù)雜過程都封裝到一個(gè)簡(jiǎn)單的API中,開發(fā)者只需要調(diào)用簡(jiǎn)單4~5行代碼,而且可以直接使用他們熟悉的原生數(shù)據(jù),比如Android開發(fā)時(shí)直接用Bitmap,而不是轉(zhuǎn)化為ByteArray.
為此,TFLite增加了對(duì)模型元數(shù)據(jù)的支持[74],這讓模型創(chuàng)建者可以使用類型化的對(duì)象來(lái)描述模型的輸入和輸出,方便模型共享和自動(dòng)化處理.更進(jìn)一步,提供了一個(gè)Android代碼生成器[75],給定模型,它可以讀取元數(shù)據(jù),自動(dòng)生成封裝好的Java類,它可以自動(dòng)調(diào)整圖片大小,對(duì)其進(jìn)行歸一化且從ByteArray進(jìn)行轉(zhuǎn)換.
更進(jìn)一步,我們正將此功能集成到Android Studio的ML model binding工具中[76],只需要把模型導(dǎo)入到Android Studio中就可以生成代碼,目前已提供試用版,請(qǐng)參考文獻(xiàn)[77].
5 未來(lái)的方向
TFLite作為開源項(xiàng)目,為了更好地與社區(qū)互動(dòng),我們提前公開了開發(fā)計(jì)劃[78],以確保所從事的工作和優(yōu)先級(jí)清晰明了.
性能是我們持續(xù)關(guān)注的重點(diǎn).我們正在集成XNNPACK以便于進(jìn)一步優(yōu)化浮點(diǎn)模型,還在提升訓(xùn)練后量化的性能,以便加快CPU推理速度.增加更多優(yōu)化的算子,并讓現(xiàn)有的硬件加速器delegate支持更多算子,以便加速更多模型,支持更多的硬件加速器.在有多個(gè)異構(gòu)加速器的情況下,探索如何提供更簡(jiǎn)易的工具,幫助發(fā)揮出其最佳性能.
簡(jiǎn)化開發(fā)者體驗(yàn)很關(guān)鍵.我們會(huì)持續(xù)不斷更新最前沿的端側(cè)模型以及相關(guān)的示例,展示更多的可能性.增強(qiáng)TFLite Model Maker,支持更多任務(wù),例如目標(biāo)檢測(cè),支持BERT系列的NLP任務(wù).更豐富的TFLite Support庫(kù).擴(kuò)展模型元數(shù)據(jù)和代碼生成工具,以支持更多用例,以及與Android Studio的無(wú)縫集成,進(jìn)一步簡(jiǎn)化體驗(yàn).提供更便捷工具,幫助用戶根據(jù)模型來(lái)減少算子庫(kù),壓縮運(yùn)行時(shí)間.
進(jìn)一步讓TensorFlow模型到TFLite模型轉(zhuǎn)化更流暢,比如更好地支持RNNLSTM和動(dòng)態(tài)形狀、模型轉(zhuǎn)換過程更好的語(yǔ)義匹配(比如只轉(zhuǎn)換部分計(jì)算圖).長(zhǎng)期看來(lái),如何更好地融合TensorFlow和TFLite,共享算子和核心庫(kù),同時(shí),也兼具移動(dòng)平臺(tái)的優(yōu)化.
提供更豐富的模型優(yōu)化工具,比如剪枝、張量壓縮和蒸餾技術(shù).
在TFLite微控制器版中,和社區(qū)合作支持更多芯片平臺(tái)、更多算子,同時(shí)提供更多適合MCU的樣例模型和應(yīng)用.
更好地支持聯(lián)邦學(xué)習(xí),保護(hù)用戶隱私.更好地支持端側(cè)訓(xùn)練,支持個(gè)性化應(yīng)用.
致謝感謝TensorFlow團(tuán)隊(duì),特別是Tensor-Flow Lite團(tuán)隊(duì)的杰出工作,設(shè)計(jì)并開源TensorFlow Lite,加速端側(cè)機(jī)器學(xué)習(xí)的發(fā)展.感謝Google相關(guān)團(tuán)隊(duì)持續(xù)對(duì)TensorFlow Lite的貢獻(xiàn)和反饋.感謝廣大硬件平臺(tái)的支持.感謝最廣大開發(fā)者對(duì)TensorFlow社區(qū)的貢獻(xiàn),持續(xù)推動(dòng)其發(fā)展.
