基于多模態融合的自動駕駛感知及計算
2020-09-24 08:40:32張燕詠吉建民段逸凡黃奕桐張宇翔
計算機研究與發展 2020年9期
張燕詠 張 莎 張 昱 吉建民 段逸凡 黃奕桐 彭 杰 張宇翔
(中國科學技術大學計算機科學與技術學院 合肥 230027)yanyongz@ustc.edu.cn)
自動駕駛意味著智能系統逐步取代人類操縱汽車行駛,該理念早在20世紀20年代就被提及,并于20世紀80年代開始逐步發展[1].近年來,汽車數量迅速增加,據國家統計局統計(1)http://data.stats.gov.cn/easyquery.htm?cn=C01&zb=A0G0I&sj=2018,2018年底我國民用汽車保有量就已突破2.3億,汽車交通事故發生次數達到166 906起.城市道路日漸擁堵,人們“被困”在道路上的時間越來越多.而自動駕駛是最有可能解決以上問題的技術.學術界和工業界對于自動駕駛技術的研究也正是如火如荼.麻省理工大學的TOYOTA-CSAIL、斯坦福大學的SISL等研究機構紛紛入場;為自動駕駛服務的各類數據集[2-4]開始涌現;自動駕駛物體3D檢測、目標跟蹤等各子任務的挑戰榜單(2)https://motchallenge.net/results/CVPR_2019_Tracking_Challenge/;https://www.nuscenes.org/;http://www.cvlibs.net/datasets/kitti/不斷刷新;Uber、Tesla、百度等國內外公司都成立特定部門進行自動駕駛技術研發.這一系列表現足見自動駕駛領域的重要性.
用于自動駕駛的智能車與傳統車輛最大的不同之處在于,智能車搭載了眾多用于感知環境、計算決策的設備,用來代替人類在駕駛汽車時做出感知和決策.其中,激光雷達、攝像頭、GPS、毫米波雷達是常見的感知設備.在汽車行駛的過程中,通過處理以上傳感器的數據進行對環境的感知、對物體的識別與跟蹤、對自身的實時定位等工作,以確保汽車行駛的安全性.
在過去的幾年中,L2級別自動駕駛已經成為比較成熟的技術,高級駕駛輔助系統(advanced driving assistance system, ADAS)被集成到越來越多的新款車輛中.ADAS提供包括車道線偏移預警系統、自適應巡航、自主泊車等在內的可以優化人類駕駛體驗的眾多功能.但是,ADAS仍然只能提供簡單的輔助功能,在處理突發情況或遇到罕見環境時不能保證安全,所以駕駛員仍然是交通中不可缺少的,與真正意義上的自動駕駛相去甚遠.隨著人工智能領域的蓬勃發展,越來越多的研究者不止滿足于L2級別,而是著眼于L3甚至L4級別的自動駕駛.在這種級別的自動駕駛中,對環境的感知成為重中之重,例如對道路情況的感知、行人與車輛的識別、交通標志的識別等.如果沒有對環境的正確認識,那控制車輛將無從談起.如何才能讓智能車精確認識環境、理解環境成為自動駕駛的一大挑戰.
沒有一種單一傳感器的數據能提供足夠的感知精度.真實的駕駛環境變換多樣,霧、雨、雪、晴會影響激光雷達的感知,白天、黑夜等光照條件不同的情況將影響攝像頭的感知.因此,一個有效的自動駕駛系統必然是架構復雜、任務繁多,不同任務依賴的感知數據不盡相同:檢測、追蹤主要依賴圖像和點云數據,即時定位則需要GPS和IMU等.為了確保不同條件準確感知、系統正常運行,自動駕駛汽車不得不搭載多種感知硬件,從不同的感知器中接收海量的、異構的感知數據.自動駕駛要求對車道線、交通標識、可能的障礙物等駕駛環境有全面的認識,就不得不接收大量感知數據并執行多種感知任務.但這同時造成了感知任務種類多、任務量大的問題.此外,為了提升感知精度,用于感知任務的各種深度學習模型不斷加深、網絡結構愈發復雜,導致計算量也逐漸龐大.
然而,在感知數據海量、感知任務多樣、計算量巨大的情況下,車載計算資源卻極為受限.首先,自動駕駛汽車分配給計算硬件的能源是有限的,這便極大地限制了車端計算硬件的選擇.再者,相較于系統所需的計算量,車載計算設備存在發展緩慢、算力不足等問題,在不做計算優化的情況下,根本無法滿足自動駕駛實時性的要求.如何進行計算優化才能滿足系統實時性是自動駕駛的另一大挑戰.
接下來,本文將針對自動駕駛的環境感知和實時計算兩大挑戰,從自動駕駛系統的整體架構、智能感知、計算優化3個方面對自動駕駛進行介紹和分析.之后將詳細介紹中國科學技術大學LINKE實驗室的智能小車系統Sonic及其感知融合算法ImageFusion和計算優化框架MPInfer.
本文主要貢獻包括3個方面:
1) 重點回顧了自動駕駛系統的歷史和現狀,分析自動駕駛系統在感知和計算這2部分的重難點(第1節),之后詳細介紹了中國科學技術大學的Sonic智能小車自動駕駛系統(4.1節);
2) 詳細剖析了自動駕駛系統中的感知模塊,并對其中的代表性算法進行了系統性的分析和比較(第2節),之后對Sonic系統的融合感知算法ImageFusion進行詳細介紹(4.2節);
3) 針對自動駕駛系統的實時性問題,對感知相關的深度學習模型的計算優化的研究進展進行了詳細的闡述和討論(第3節),并詳細介紹了Sonic系統中的計算優化框架MPInfer(4.3節).
1 自動駕駛系統現狀
1.1 自動駕駛歷史背景
自動駕駛本身的歷史可以追溯到1920年代及1930年代間,但真正具有自動駕駛能力的汽車出現于1980年代.1984年,卡內基美隆大學推動Navlab計劃與ALV計劃;1987年,梅賽德斯-奔馳與德國慕尼黑聯邦國防大學共同推行尤里卡普羅米修斯計劃.自此許多大型公司、機構開始將目光轉向這個領域.在2005年的DARPA挑戰賽中,從Stanford,CMU,UC-Berkeley等高校為代表的15個團隊中誕生了5輛完成142英里自動駕駛挑戰的無人車[5].由此開始,世界各地的學術界和工業界對于自動駕駛技術的研究都在不斷加速.其中學術界有諸如斯坦福大學、卡內基梅隆大學、麻省理工學院等研究機構.工業界著名的參與者有Uber、Aurora、Momenta、Waymo、百度、Tesla、Nvidia、Mobileye、Pony.ai等公司.根據美國DMV公布的《2019年自動駕駛接管報告》,目前在美國道路上具有運行自動駕駛車輛資格且已經在實際環境中進行測試的公司已經有36家以上.
1.2 自動駕駛系統分類
從系統結構上看,自動駕駛系統分為端到端的系統以及模塊化的系統,其中端到端的自動駕駛系統缺少可靠的安全措施和可解釋性,因此還沒有實現開放環境中的城市自動駕駛[6].模塊化的系統在各個子系統中有相應的領域知識[7],可以在子系統中利用相應的領域知識,從而使整個自動駕駛系統變得可解釋[5],此外也可以通過各個子領域的發展來提高整體系統的性能.
下面將具體介紹模塊化的自動駕駛系統.
1.3 自動駕駛硬件結構
一個自動駕駛系統的硬件主要由各類傳感器以及計算設備組成.圖1展示了典型的自動駕駛系統的硬件組成,主要由激光雷達、攝像頭、毫米波雷達、IMU(慣性測量單元)、高精度GPS、高性能PC等組成.其中激光雷達、攝像頭、毫米波雷達屬于感知子系統,用于車輛感知周圍環境,為無人駕駛車輛建立一個準確、穩定的周圍環境的模型.攝像頭能獲取包括物體顏色、外形、材質等豐富的環境信息,并且2D計算機視覺已取得很多進展,該領域有許多先進的算法用于信號燈檢測[8]、物體分類[9]等.但由于獲取的是二維信息,因此難以得到可靠精準的距離信息,并且由于攝像頭獲取的數據對環境光照、天氣較為敏感,在環境變換時(如穿過昏暗的隧道)難以得到可靠的數據.而雷達對距離感知精度較高,可獲得高精度的距離信息;但由于激光雷達的物理特性,獲取到的環境信息較為稀疏.此外,激光雷達對天氣的變化十分敏感,在霧霾、雨雪天氣性能下降十分明顯.無論是激光雷達、攝像頭,都會產生大量的觀測數據,這往往是整個系統實時運行的瓶頸[9-10].毫米波雷達能夠獲取精準的距離信息,穿透能力強,能夠抵抗天氣和環境變化的影響,可實現遠距離感知探測[11];但毫米波雷達易受金屬物品干擾.IMU、高精度GPS則用于定位子系統,用來在環境中獲得車輛的準確位置信息.高精度GPS能夠獲得車輛的全球定位信息,通常定位精度為厘米級.而在諸如隧道、地底等場景下不能獲得GPS信號時使用IMU能夠獲得車輛運動時在x,y,z三個方向的加速度信息,再加上感知子系統對周圍環境的感知,能夠在無法獲取GPS信號也能得到準確的定位.

Fig. 1 A self-driving autonomous car with sensors圖1 裝載各種傳感器的半程自動駕駛小車
1.4 自動駕駛軟件組成
一個模塊化的自動駕駛系統的軟件部分主要由感知、決策規劃、控制等子模塊組成.
圖2是典型的模塊化自動駕駛系統的軟件結構.單獨的車輛可以通過高精度GPS的定位數據進行定位,在GPS受到干擾時通過IMU以及激光和視覺的輔助進行定位.但是,在室內環境中,隨著時間的增長,IMU的慣性導航精度會下降[12],此時需要基于激光、視覺的定位,并需要離線地圖獲取當前環境特征來進行定位[13].由于獲得了車輛的定位信息,并且事先也有環境的靜態信息,當進行導航規劃時,根據車輛當前定位信息,便可以在靜態地圖上獲得全局的路徑規劃.之后,在全局路徑的基礎上,隨著車輛運動,不斷獲得周圍環境的信息,再進一步地進行局部路徑規劃,即可獲得一個能夠避開環境動態物體的路徑.以上從建立全局路徑到產生局部路徑的過程通常由導航子模塊負責.根據全局路徑以及局部路徑加上定位子系統,可以獲得車輛的位置以及位姿.獲知車輛的下一步運動,并且隨著車輛的運動、周圍環境的變化更新局部路徑,再產生再下一步的運動.如此不斷地循環,車輛就具有了從初始位置到達目標位置的自動駕駛能力.而根據路徑進行下一步運動由車輛的運動控制子系統負責.
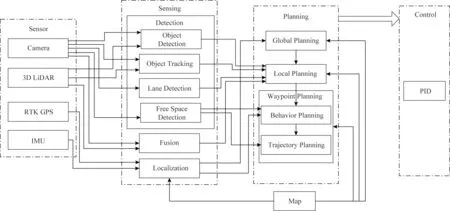
Fig. 2 Overview of the autonomous driving software system圖2 自動駕駛軟件系統總覽
由于自動駕駛系統由各個復雜的模塊組成,其中感知模塊需要對大量數據進行實時處理,因此如何處理自動駕駛任務中的感知數據是目前自動駕駛遇到的諸多挑戰之一.
1.5 自動駕駛中的感知與計算挑戰
一個成功的自動駕駛系統不僅需要準確可靠的算法,更需要有對系統中產生的大量數據進行實時處理的能力.比如,一個64線的激光雷達產生的點云數據量高達3 000 KBs.作為基于激光點云的3D目標檢測網絡中實時性最好的PointPillars,其在算力較充足的1080tiGPU上能達到60 Hz的執行頻率[10].同時,視覺感知也是自動駕駛系統中不可或缺的一部分.基于視覺數據的目標識別需要YOLOv3[14],Fast R-CNN[15]等基于視覺的神經網絡.該類神經網絡的計算量更大,現在能達到的處理頻率在10~60 Hz.上面的點云和視覺感知都是自動駕駛感知子系統的主要任務,即通過處理感知數據來對車自身和周圍環境進行感知.相比于自動駕駛中的其他子系統比如說物體追蹤和路徑規劃,感知子系統對計算資源的需求要遠大于其他.
然而,實際車輛能夠提供給計算設備的能源是非常有限的,這要求自動駕駛系統不能依靠強大的計算設備來達到滿足運行要求的感知頻率,而需要在面對大量計算任務下對任務進行合理的分配,對單個任務在不影響精度的情況下進行計算優化.
一個自動駕駛系統的計算瓶頸集中在感知層面,無論是僅僅使用3D激光雷達還是攝像頭,又或者兩者同時使用,都引入了大量的數據.對于RGB攝像頭的物體識別網絡,如果識別的圖片分辨率為320×320,攝像頭產生數據的頻率在50 Hz,這個情況下的數據量為14 MBs.對于一個64線的激光雷達每秒產生的點云數據量高達3 000 KB.目標檢測神經網絡的實時性要求為處理頻率大于50 Hz,但目前還沒有計算設備能夠在無優化、無調度的情況下滿足此計算需求.而且,無論是1080ti還是Titan X的INT8性能都超過了專門用于車輛計算的Jetson AGX Xavier,如表1所示.由此看來,為滿足實時性要求,車載計算的優化是不可或缺的.
因此,目前自動駕駛實時性的挑戰主要集中在:在計算資源有限的情況下,如何在不影響各類算法精度的前提下,提升自動駕駛系統感知模塊的運行頻率.為了解決這個問題,我們的思路是一個以深度融合(deepfusion)為主的框架:在高層進行感知數據、模型和計算方法、調度方法的融合,以提高感知的計算時效;在感知層對不同感知模態的數據進行融合(本文中以融合攝像頭和激光雷達數據為主),以提高感知的精度.
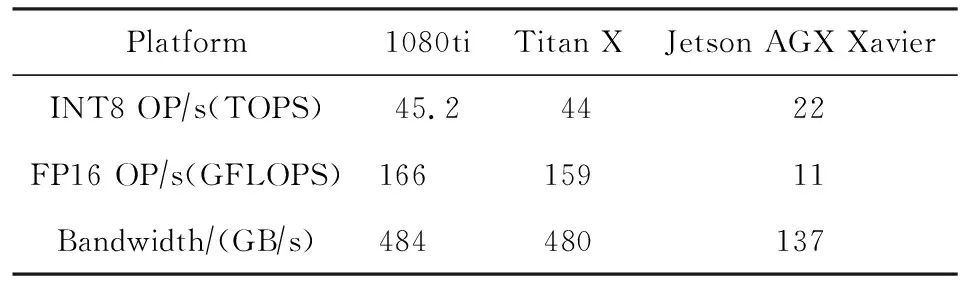
Table 1 Performance of Devices表1 計算設備性能
2 自動駕駛中的感知現狀
在自動駕駛領域,對環境的感知將用于后續的路線規劃、障礙物規避等關鍵性操作,是確保行駛安全的前提.基于圖像的2D感知輸出2維結果,缺少深度信息,無法直接用于構建立體環境,不滿足自動駕駛的要求.因此能夠獲取三維信息的3D感知成為自動駕駛感知任務中的焦點,近幾年對3D感知的研究可謂是百花齊放、百家爭鳴.其中3D目標檢測是感知的基礎和重點,由于篇幅限制,本節僅對近年來基于激光雷達、攝像頭及二者融合的3D目標檢測算法進行介紹.
ResNet[16]和PointNet[17]作為圖像處理和點云處理中最經典的網絡,本身及其變種經常作為網絡的一部分出現在感知處理模塊中.由于二者在感知處理中的重要性和奠基性,本節將率先介紹PointNet和ResNet.
ResNet一面世就在當年(2015年)的ILSVRC & COCO中斬獲包括檢測在內的多項挑戰的桂冠,之后在改進的同時,不斷被其他感知處理網絡借鑒使用,影響深遠.ResNet針對網絡“退化”問題,即隨著模型層次加深,學習效果反而變差,提出了殘差結構:增加如圖3所示的恒等映射(identity mapping),將直接學習變為更容易的殘差加恒等映射學習.該結構由shortcut connection實現,即用一條近路將一個塊的輸入和輸出聯結,該方法降低了優化難度,提高了訓練速度,解決了退化問題,在圖像處理中被廣泛使用.
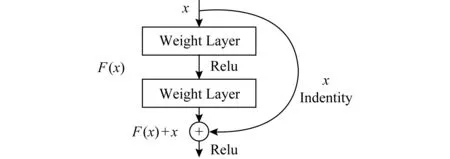
Fig. 3 Identity mapping[16]圖3 恒等映射示意圖[16]
PointNet是直接對點云數據進行處理的深度學習模型,可以運用在點云分割、分類等任務.為了克服點云數據的無序性問題,該網絡利用max-pooling作為對稱函數,達到數據排列不同、結果仍保持一致的效果;此外,數據處理過程中不受空間變化的影響,為了確保這一點,PointNet在點云處理前使用空間變換網絡(spatial transformer network)進行對齊.最終,雖然網絡的基礎結構簡單,但運行速度快、效果好,成為處理點云數據的基礎網絡.
2.1 基于激光雷達的3D感知
激光雷達數據包含目標物體的距離信息以及豐富的結構信息,相較于圖像數據能構建出更加接近真實環境的感知結果,在目標檢測方面有得天獨厚的優勢.近年來,利用激光雷達數據進行3D檢測的精度相較單純利用圖像數據的方式提高不少,逐漸成為自動駕駛中的新趨勢.本節從眾多優秀的算法中挑選PointPillars[10],PointRCNN[18],TANet[19]進行介紹.PointPillars是用體素化方法解決點云數據稀疏、無序問題的代表,同時也是典型的一階段實現方法,這種方式使得PointPillars檢測時間短、實時性能好;PointRCNN是兩階段操作的代表,檢測時間較長,但實現了更高的精度;而TANet提出多層次的特征提取,克服了點云數據應用在行人檢測上的檢測難、誤檢多的問題.
1) PointPillars
PointPillars在檢測精度和時間上都表現得不錯,在時間上尤為突出.其網絡結構如圖4所示,其創新點在于3D點云體素化編碼.作為一階段檢測方法的代表,其具體的處理流程大致如下:按照3D點云的x,y,z軸劃分成小塊,再將點云中的點按照其坐標進行特征編碼,經過PointNet特征提取之后形成偽圖像,該偽圖像被輸入到RPN中進行進一步的特征提取;最后將其放入2D檢測網絡,該網絡輸出關于3D標注框的相關參數,由此得到感知結果.其新穎的編碼方式,是其快速性、準確性的重要保障,可以以62 Hz的頻率進行識別工作,在KITTI 3D檢測數據集上運行時間僅16 ms,是目前KITTI 3D檢測排行榜上最快的算法.
2) PointRCNN
PointRCNN網絡結構如圖5所示,在檢測精度上比PointPillars更勝一籌.其主要創新在于:在如何選擇候選區域這一問題上拋棄以往使用的待選框多、計算量大的anchor方法,創造了一種基于前景點的方法.該算法是典型的兩階段檢測方法,其具體處理流程大致如下:在第1階段,將所有原始點云分割成前景點和背景點,利用從下到上的網絡生成高質量的3D候選區域;接著在第2階段,對候選區域的點進行池化并加上部分特征,通過全連接層學習空間信息,然后與全局特征相結合來進行邊框精度優化以及置信度的預測.其在候選區域選取方法的創新,使得第一階段具有高召回率.該算法當時在所有以點云輸入的KITTI 3D檢測排行榜(3)KITTI 3D檢測排行榜用檢測指標:3D Bbox AP中的moderate進行排名,具體計算依照PASCAL criteria.中名列第1.
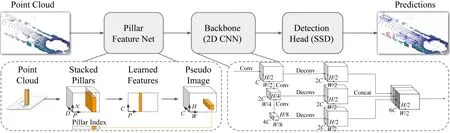
Fig. 4 The structure of PointPillars[10]圖4 PointPillars網絡結構圖[10]
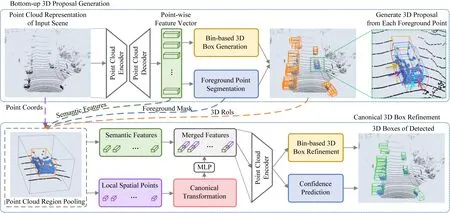
Fig. 5 The structure of PointRCNN[18]圖5 PointRCNN網絡結構圖[18]
3) TANet
TANet在行人檢測中表現十分突出,目前在KITTI行人3D檢測排行榜上排名第4,同時在KITTI測試中算法的運行時間僅為0.035 s.該算法網絡結構如圖6所示,主要的創新點在于,關注多個層次的特征提取.從淺層次的語義信息到深層次的融合信息,該算法都給予充分關注.從稀疏的點云數據中挖掘出足夠多的信息,使其在行人檢測更具分辨力,實現高精度檢測.具體的處理流程如下:原始點云數據經過體素化,之后通過2個相同的逐點、逐通道和逐體素的3點關注網絡模塊學習得到關鍵特征,并經過全連接層和池化層調整,輸出至從簡到精的回歸模塊,多次使用上采樣和降采樣以及整合的方式得到信息豐富的特征地圖;再進行分類和位置估計,最終得到檢測結果.多層次多關注點的特征提取方法是其在行人檢測取得成功的重要保障,是實現強魯棒性的重要原因,同時由簡到精的回歸模塊確保了算法的快速性.
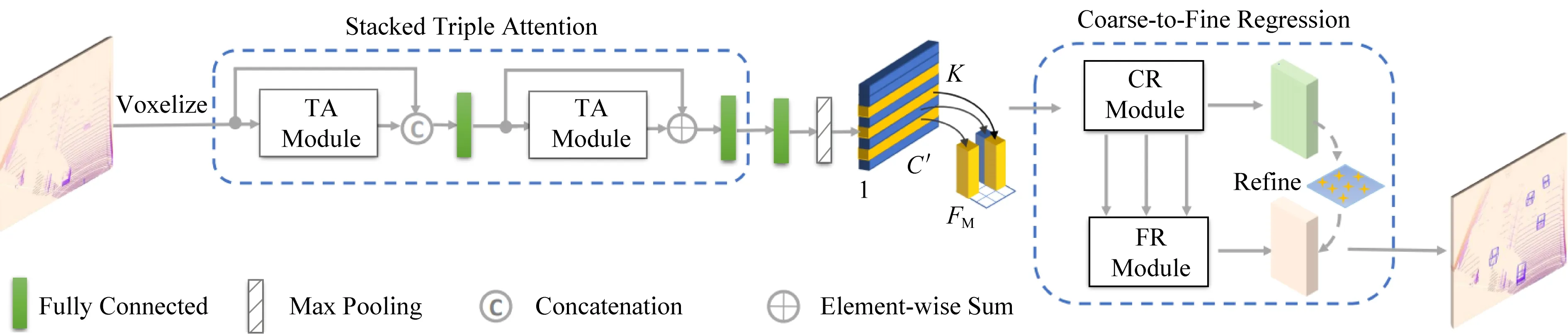
Fig. 6 The structure of TANet[19]圖6 TANet網絡結構圖[19]

Fig. 7 The structure of Pseudo-LiDAR++[20]圖7 Pseudo-LiDAR++網絡結構圖[20]
2.2 基于視覺的3D感知
相機在可以獲取稠密豐富的信息的同時,仍然可以保持著低廉的價格.憑借著同時實現低成本與高性能的特點,計算機視覺在無人駕駛中扮演著舉足輕重的角色.從目標檢測到目標跟蹤,從路面識別到視覺里程計,相機幾乎可以完成所有在無人駕駛中所需要的感知任務.但是,相機并非是完美無缺的選擇,相較于雷達而言,由于其缺少所獲取畫面的深度信息,所以在3D目標檢測等任務上有著天生的缺陷,如何彌補這一缺陷成為該領域的重點與熱點.這里我們在近期取得的研究進展中選擇了3項思路不同的工作進行簡單介紹.Pseudo-LiDAR++[20]為雙目視覺的代表工作;D4LCN[21]從深度圖學習知識,以改進基礎的2D全卷積;SMOKE[22]通過結合單一特征點的估計值與回歸3D變量的思路來預測目標物體的3D邊框.
1) Pseudo-LiDAR++
基于雙目圖像的偽激光雷達(Pseudo-LiDAR)是一種有前途的替代雷達進行檢測的方案,但是在性能方面仍然存在著很大差距.傳統的方法首先估計像素在左右兩攝像頭中的視差,從而間接估計像素的深度,這種方法在近距離表現良好,但在遠距離效果不佳.而Pseudo-LiDAR++的創新點在于:其首先使用立體深度網絡(stereo depth network, SDN)從左右圖像中構建costvolumn,該操作使3D卷積在正確的比例上進行深度估計,對相鄰的深度產生相同的影響.此外本文還提出一種使用廉價的4線激光雷達來彌補偽激光雷達中不足的方法,稱為基于圖的深度矯正算法(graph-based depth correction, GDC).將雷達產生的點云少量與圖片中的像素進行匹配,以獲取圖像中幾個節點的精確深度,最后使用標簽擴散機制將準確的深度信息傳播到整張圖片,其網絡結構如圖7所示.這種方法以極其低廉的價格而取得與64線激光雷達類似的效果.
2) D4LCN
一種比較流行的3D目標檢測方法是估計2D圖像的深度圖,將2D圖像轉化為點云進行表示,以模仿雷達的信號,但是這種方法的性能取決于2D圖像深度圖估計的準確度.D4LCN提出一種稱之為Depth-guided Dynamic-Depthwise-Dilated Local Convolutional Network的卷積神經網絡.其創新點在于:不僅解決了2D卷積尺度敏感的問題,還充分利用了RGB的語義信息.如圖8所示,卷積核由深度圖生成,局部地運用于各個圖像的像素和通道(而不是使用全局卷積核應用于整個圖像)來區分物體與背景.整體的網絡結構由3個關鍵組件組成:網絡主干、深度引導的濾波模塊、2D-3D的檢測頭,依次完成RGB特征提取與卷積核生成,橋接2D卷積與3D點云,輸出3D標注框的工作.D4LCN不僅解決了2D卷積尺度不敏感和局部結構無意義的問題,還利用了RGB圖像中的語義信息,最終經過KITTI數據集的比對也取得了良好的效果.
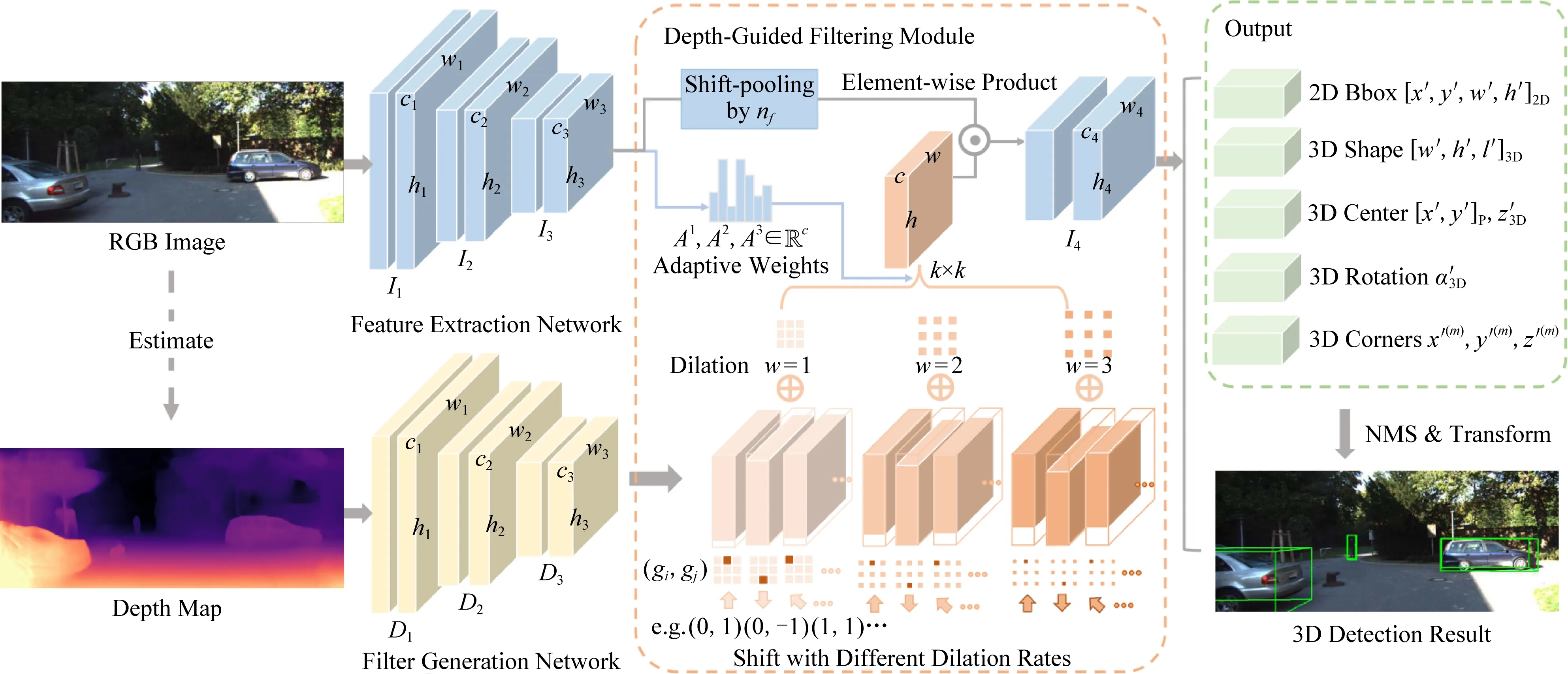
Fig. 8 The structure of D4LCN[21]圖8 D4LCN網絡結構圖[21]
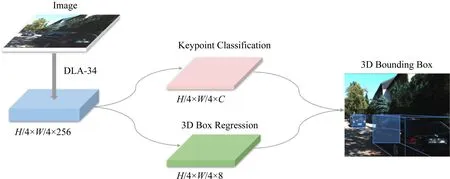
Fig. 9 The structure of SMOKE[22]圖9 SMOKE網絡結構圖[22]
3) SMOKE
SMOKE從另一個角度實現了新的創意.其創新點在于:提出一種單步的3D對象檢測方法;將每個對象與關鍵點配對,預測圖像上的3D投影點,并且并行地進行3D邊框參數的回歸,以此消除2D檢測帶來的噪聲,實現端到端3D邊框的預測.在網絡結構上,如圖9所示,SMOKE采用DLA-34作為backbone,從下采樣過后的圖像中提取特征.再由2個單獨的分支進行關鍵點分類和3D邊框的回歸,綜合2個分支的信息,獲取3D邊框值.其中提取關鍵點的分支將每個對象由一個特定的關鍵點表示,這個關鍵點代表著對象在圖像平面上的投影3D中心.回歸分支將3D邊框表示為8個參數,依次推出3D邊框的位姿.SMOKE舍棄了常規方法的各種步驟,采用簡單的網絡結構,提高了3D對象檢測的準確度與速度,并在相應的KITTI排行榜中名列前茅.
上述3種方法的測試結果在表2中得到展示,可以看到其效果距基于雷達數據的方法仍有較大差距,說明基于視覺的3D檢測仍然有著很大的進步空間.
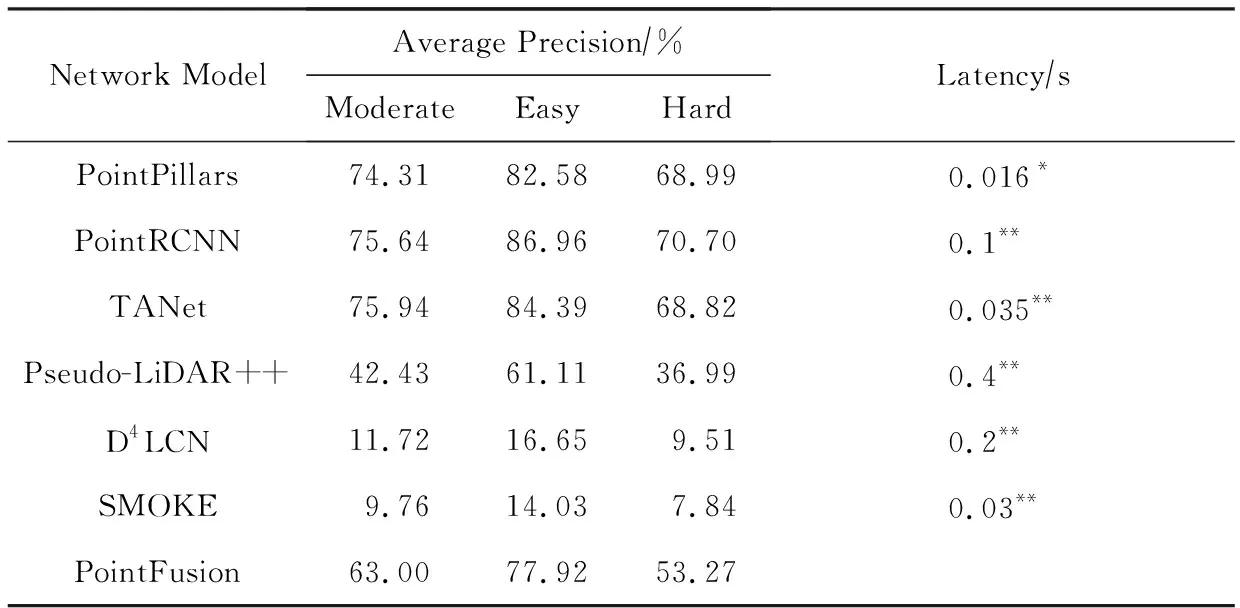
Table 2 Comparison of Performance for 3D Car Category on KITTI Dataset
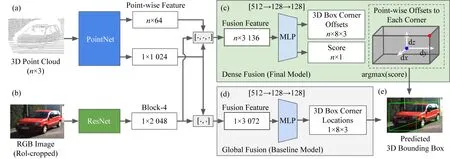
Fig. 10 The structure of PointFusion[23]圖10 PointFusion網絡結構圖[23]
2.3 基于融合的3D感知
圖像數據擁有豐富稠密的物體信息,但是缺少畫面的深度信息;而雷達數據恰好可以彌補此缺陷,給出精確的深度信息和物體的結構信息.在3D目標檢測的過程中,將2類數據中的信息相融合在理論上應該可以達到更高的精度.但是在哪些或者哪個階段,以何種方式將2種不同的數據進行融合才能獲得更好的效果,這是以融合的方式解決3D檢測問題的重點和難點.依據在什么階段執行融合步驟被分為前融合和后融合2種,前者先將數據進行融合之后再執行感知任務,后者則是先進行感知,之后對結果進行融合.本文我們選取其中最具代表性的工作Pointfusion[23]進行簡單的介紹.
Pointfusion是典型的前融合模型,執行特征級別的數據融合.它使用簡單的網絡結構(如圖10所示)實現通用的融合模型,不需要進行特定數據集的模型調優,在KITTI和SUN-RGBD相應的排行榜上都取得不錯的成績用不同的網絡分別從圖像和點云數據中學習特征,再將特征進行融合用來預測3D邊框.鑒于3D點云數據轉換成圖像格式或者體素化都會導致信息的丟失,Pointfusion將利用PointNet的變種直接從原始激光雷達點云數據中學習特征,同時利用ResNet學習圖像的特征;之后密集融合子網絡會結合2類不同特征進行融合,再將融合特征傳入MLP,估計3D邊框的偏移和置信度,最終實現3D邊框的預測.
第2節提到的7種網絡模型在KITTI 3D檢測數據集的測試結果如表2,3所示:
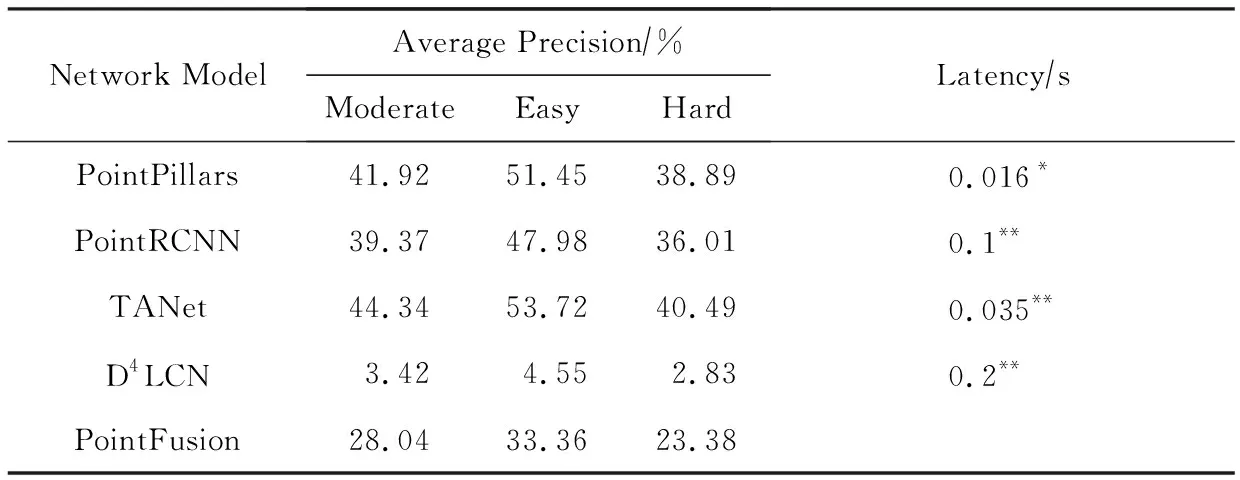
Table 3 Comparison of Performance for 3D Pedestian Category on KITTI Dataset
3 自動駕駛中的計算優化現狀
自動駕駛依賴各種傳感器感知環境信息.為了提升感知精度,感知模型的深度不斷增加、模塊間依賴關系也愈發復雜,模塊內計算量不斷攀升.同時,感知任務的響應時延能否達到自動駕駛系統的實時性要求關乎道路安全,必須嚴格限制.但與此矛盾的是車端計算設備的算力發展相對緩慢,主要關注感知精度的實驗室研究成果直接部署很難滿足系統的實時性要求.自動駕駛普遍要求從數據采集傳輸、數據感知到控制決策的端到端時延在100 ms以內[2,24-26],其中留給感知任務的時間在幾十毫秒量級,相應的基于圖像的感知任務要達到30FPS的速度[27].表4分別展示了視覺模型和點云模型常用的骨干網絡ResNet50和PointNet的參數量和計算量.因此,需要通過各種計算優化手段,削減模型中潛在的無效計算,仔細調度計算資源占用,實現感知任務的實時響應.
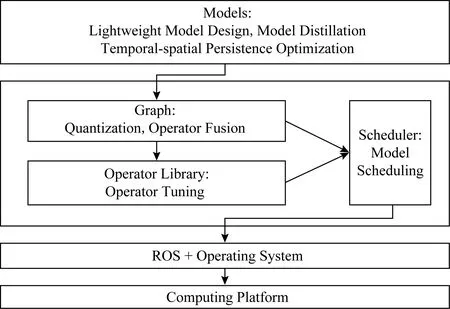
Fig. 11 Computational optimization method diagram圖11 計算優化方法的脈絡圖
本節剩余部分按照圖11所示的脈絡詳細介紹近年來涌現的計算優化方法.模型層次上,輕量網絡設計(lightweight model design)、模型蒸餾(model distillation)和時空連續性優化(temporal-spatial persistence optimization)等方法利用應用領域知識將計算復雜度降低.在深度學習框架層次上,模型調度(model scheduling)、模型量化(model quantiza-tion)和算子融合(operator fusion)與調優(operator tuning)等方法僅從系統層次上降低無效計算,提升計算硬件利用率,降低運行時開銷.由于不改變應用的高層邏輯,這些方法擁有廣泛的適用性.
3.1 模型調度
模型調度是指對智能車系統上的各類感知任務進行調度,從而使得有限的計算資源得到充分利用,達到系統要求的吞吐率和延遲,可分為多任務、多實時幀流的感知計算、同一幀流的計算復用等.
多任務是指多個模型在CPU和GPU上并行執行.NVIDIA的CUDA編程模型[28]提供了多種GPU并行模式:1)同一CUDA context下多CUDA stream并行模式,不同的CUDA stream上的GPU操作可以并行執行,這種方式對于GPU的利用率較高,但模型的推理延遲波動較大.2)多CUDA context并行模式,這種模式以時間片的方式共享GPU資源,不同CUDA context的資源相互獨立,但GPU的利用率較低.在Multi-Process Service(MPS)服務的支持下,多CUDA context模式以類似于多CUDA stream的方式運行.
多實時幀流的感知計算往往采用相同的模型處理多個實時輸入幀流,例如同時對多個攝像頭的視頻流進行模型推理.動態批量化方式[29]將在一段時間內到達的或者達到一定閾值數量的輸入數據進行批量(batch)化,產生一個多維向量,交由模型統一處理,這種方式有利于提高吞吐率,但對于每一幀圖片有額外的等待延遲開銷,而且在較小的批量化數目下處理延遲會隨著批量化數目的增加近似線性增長.流水線方式[30]將包含數據前處理在內的模型推理切分為一個個階段,對輸入的數據進行流水處理,這種方式使得CPU和GPU并發執行,在CPU的計算延遲低于GPU延遲的情況下,可以掩蓋CPU端的計算延遲,提高系統整體的吞吐率.由于單個模型對于GPU的利用率不能達到100%,在每個流水階段使用多線程的話,還會有一定的GPU并行收益.
3.2 模型量化
模型量化是將模型中的32位單精度浮點數(FP32)替換為低精度整型數(如INT8),來改變存儲與計算的一種模型壓縮技術.目前主流量化方案是INT8[29],此外,根據使用位寬的不同還有二值量化[31-32]與三值量化[33]等.量化后的模型對存儲和帶寬的需求降低,在大多數處理器上整型計算速度更快,從而實現網絡模型的加速計算.使用整型數替換浮點數意味著計算精度丟失,不過網絡模型對精度丟失引入的噪聲足夠魯棒,合理控制量化位寬并調整量化參數,可以在帶來計算加速的同時避免嚴重的精度損失.以ResNet50網絡為例,采用8 b量化可以帶來3倍左右的性能提升[34],而ImageNet目標分類任務Top1精度降低小于2%.
考慮INT8量化,FP32浮點數x和INT8整型數y滿足關系y=S(x-Z),其中參數S為量化縮放系數(FP32表示),參數Z為量化后零值(INT8表示).這2個參數需要根據x的取值分布仔細設置以保證網絡模型精度.
根據參數設置時機的不同,量化可以分為訓練后量化和訓練時量化.訓練后量化指網絡模型使用FP32表示完成訓練后再量化到INT8表示.TensorRT[29]在calibration數據集上應用訓練好的FP32模型統計各層激活值的直方圖,通過嘗試不同x的值域邊界來評估量化前后的KL散度.HAQ[35]則直接將這個問題抽象為強化學習問題,反復在實際設備上運行量化模型得到精度與時延作為反饋來調整參數.訓練時量化指在訓練網絡模型的同時調整量化參數.典型工作[34]在網絡模型的計算圖中插入量化模擬結點來模擬量化的影響,但是所有計算仍舊使用FP32完成.
根據量化粒度大小的不同,量化分為逐層量化(layer-wise)和逐通道量化(channel-wise)兩種.逐層量化把參數張量作為一個整體來選擇量化參數,而逐通道量化把參數張量視為多個通道參數的集合,為每個通道選擇獨立的量化參數.文獻[36]表明量化粒度越小,量化對精度的影響越小.考慮到逐通道量化的實現復雜化,各主流框架優先支持逐層量化.
3.3 模型蒸餾
知識蒸餾(knowledge distillation)將復雜的教師網絡(teacher network)的知識遷移到一個較小的學生網絡(student network)來實現網絡的壓縮,能夠幾乎不損失精度地減少模型計算量.具體來說,學生網絡在訓練時學習2個目標:1)硬目標(hard target)為數據標簽;2)軟目標(soft target)為教師網絡預測的概率分布.因為軟目標蘊含了數據上更多的相似性結構的信息,使學生網絡學到教師網絡在更大數據集上習得的潛在內部結構,避免學生網絡過擬合,使其有更好的泛化能力.但是如何選擇一個簡單又不至于欠擬合的學生網絡仍是一個問題.
Hinton等人[37]在2015年提出知識蒸餾時,教師網絡使用的是學生網絡的集成模型,即多個模型的平均,并指出可以通過分布式地訓練集成模型,然后蒸餾到單個模型的方式加速模型訓練.后來的研究者又基于知識蒸餾的思想提出了一些衍生工作,比如設計其他的訓練函數以提取教師網絡的更多信息,將教師網絡中間層的結果也用于對學生網絡的監督訓練[38-40]或者使用更小的學生網絡以提高模型壓縮的效果,如量化蒸餾中用量化模型作為蒸餾學習的學生網絡[36].
3.4 算子融合與調優
深度學習框架提供各種算子來組合表達模型的計算邏輯,這些算子每個都對應獨立的GPU核函數實現,通常由第三方的GPU計算庫提供,如人們熟知的cuDNN[41]計算庫.模型訓練或推理過程中,這些算子對應的核函數被分別地發射到GPU端運行.因此一個算子完整的執行開銷包括發射核函數的CPU端的運行時開銷(算子調度開銷與GPU驅動開銷)和GPU端的實際計算開銷.
算子融合是指將多個算子的核函數融合為一個核函數一并發射到GPU端運行.算子融合可以減少算子發射的運行時開銷,同時如果融合的算子間存在數據依賴關系,通過在GPU的高層存儲(如GPU上的共享內存或寄存器)上精心排布不同核函數的輸入輸出可以大幅提升算子間的數據傳輸效率,進一步提升計算性能.以LSTM單元為例,文獻[42]聲稱算子融合操作可以將LSTM單元的運行時間從27 ms降至8.3 ms左右,性能提升3.25倍.
各種深度學習框架編譯器對自動算子融合支持已經逐步完善,如XLA[43],Torch Script[44],Relay[45]和TensorRT[29]等.模型會檢測計算圖中是否存在子圖符合預置的算子融合模式,如連續多個逐點操作、復雜操作緊接逐點操作和矩陣乘法批量化等,根據模型預估性能收益決策是否執行融合[46].融合后算子的計算邏輯可能沒有第三方計算庫函數能夠直接支持,需要編譯器后端自動生成對應的GPU核函數代碼.
面向深度學習領域,支持自動生成高效的GPU核函數的后端編譯器典型代表是TVM[47].它將張量計算中硬件無關的計算邏輯與硬件相關的調度邏輯解耦,并將常用的調度手段抽象為一組原語.開發人員使用原語為融合后的算子描述參數化的調度模板,搭配基于深度學習的自動調優器AutoTVM[48]對模板參數進行調優得到最優調度策略,最終由代碼生成器綜合計算邏輯與調度策略生成最終高效的GPU核函數代碼.Tensor Comprehensions[49]和Tiramisu[50]則采用多面體模型來進行自動調度,進一步減少調度策略搜索中人工的介入.
3.5 輕量網絡設計
不同于模型壓縮方法在訓練好的網絡中進行壓縮,輕量網絡設計的思路是直接構建一個輕量、高效的網絡結構.這些設計可大致分為2種:1)直接人工構建一個輕量網絡;2)使用NAS(neural architecture search)自動搜索輕量網絡結構.
由于深度學習網絡之中卷積層占據著大多數的計算量,人工設計輕量網絡主要關注于降低卷積操作的計算復雜度.一種方法是修改常規卷積的基本參數,如將一些卷積核大小為3×3的卷積替換為1×1的卷積[51],3×3的卷積是1×1的卷積參數量的19.另一種是對常規卷積的分解,以達到降低計算量的目的.深度可分離卷積將卷積操作分解為Depthwise卷積和Pointwise卷積.常規卷積將卷積核應用到輸入特征圖的每個通道,而Depthwise卷積只將卷積核應用到輸入特征圖的單個通道.Pointwise卷積則是卷積核大小為1×1的常規卷積.MobileNets[52]使用的3×3深度可分離卷積是常規卷積的19~18的計算量.還有一種方法是從卷積的原理和產生的作用上研究如何減低計算復雜度.GhostNets[53]發現了卷積所生成的不同特征圖之間的冗余信息(部分特征圖比較相似),在保留部分常規卷積生成的特征圖之后,使用計算復雜度較低的線性操作(如Depthwise卷積)來生成冗余信息,這樣在降低計算復雜度的同時,保持了模型的精度.卷積計算可以看做是計算卷積核與輸入的相似度操作,常規卷積用點積計算互相關,AdderNet[54]將其換成L1距離,可以實現只使用加法進行CNN網絡的構建.
由于人工設計網絡難以很好地平衡在受限資源下網絡的性能和精度,NAS的方法自動搜索輕量網絡結構,使得網絡的性能和精度能夠更好地取得平衡.NAS的基本流程是:1)定義一個搜索空間;2)使用一個包含搜索參數的模型生成器從搜索空間中取樣一個或幾個模型;3)評估這些模型的性能,取其中最好的一個模型;4)使用評估結果調整搜索參數;5)重復2)~4)直到取得結果.其中比較關鍵的問題就是搜索空間的定義、搜索算法的設計以及模型的評估方法.MnasNet[55]定義了一個較為全面的模型搜索空間(對整個網絡結構進行搜索),使用強化學習的方法搜索整個網絡結構,并在搜索過程中使用實際設備進行模型推理延遲的測試.DARTS[56]定義了一個連續的可微分的搜索空間(搜索的是cell,網絡由cell堆砌而成),使得可以使用梯度下降的方法進行參數更新.不同于強化學習或可微分的方法,AmoebaNet-A[57]使用了演化(evolution)算法進行模型搜索.
3.6 時空連續性優化
自動駕駛場景下,車輛周圍環境是連續變化的,傳感器感知周圍環境的相鄰兩幀數據在時間和空間2個維度上也會呈現出連續且規律的變化.以檢測任務為例,目標的空間位置、運動特征和外觀特征在間隔足夠短的兩幀感知數據中可能會有微小變化,但不會出現突變的情況.對于需要高頻連續感知的任務,這種時空連續性使得模型利用歷史感知數據提升感知精度、優化計算性能成為可能.
當前,感知數據的時空連續性更多地被編碼為上下文信息輸入感知網絡來提升感知任務的精度,而從計算優化角度出發,討論利用時空連續性來減少無效計算的工作比較少,主要集中在離線視頻流的目標檢測任務上,方法特征可以分為2類:1)基于關鍵幀的信息傳播.文獻[58]對視頻流采樣關鍵幀并對其應用較為復雜目標檢測模型得到目標位置,將相鄰2個關鍵幀圖像的相關特征和檢測結果輸入較為簡單的模型預測中間幀目標位置.PaD[59]同樣采樣關鍵幀并應用復雜的目標檢測網絡,對于中間幀,直接基于關鍵幀目標位置劃定ROI大致范圍,從而跳過兩階段目標檢測模型中的Region Proposal階段.2)直接學習相鄰幀數據相關性,如光流或者殘差.文獻[60]將關鍵幀特征圖與光流信息卷曲(warp)降低非關鍵幀特征圖計算開銷.除了圖像光流,Flownet3D[61]針對點云數據提出flow embedding層學習連續兩幀數據的相關性、編碼點云的運動規律,并提出upconv層傳播特征來預測下一幀點云數據.文獻[62]將相鄰幀相減得到稀疏輸入并交由稀疏感知硬件實現計算加速.
上述工作應用局限在離線處理場景,要求全局數據已知,而自動駕駛的感知任務都需要在線處理.在線處理場景下,時空連續性只能對歷史感知數據已經捕捉到的目標應用,而對新出現的目標無能為力,需要特殊處理.
4 Sonic智能小車融合感知及計算優化
4.1 Sonic智能小車系統介紹
Sonic智能小車系統使用16線3D激光、四路高清攝像頭作為環境感知傳感器,厘米級精度的RTK GPS以及IMU用于輔助車輛定位.在車輛控制方面,通過高速CAN總線與車輛進行通信,包括接受車輛當前運動狀態、車輛當前運行狀態、控制車輛速遞和轉向等功能.
整個Sonic系統由底層硬件向上觀察,首先激光雷達不斷對周圍的環境進行掃描獲得3D激光點云數據,攝像頭獲取周圍環境的RGB數據,并且由四路攝像頭組成環視.RTK GPS在環境良好的情況下能夠獲取高精度定位信息,車輛通過CAN總線發送當前車輛的速度、轉向角、異常信息等數據.得到硬件感知、控制數據之后,感知部分持續接收激光雷達、攝像頭的感知數據、GPS的定位信息,再結合預先對環境建立的離線地圖通過cartography等定位算法得到在該地圖中精確的定位數據.之后將定位數據、車輛運動數據、激光點云、攝像頭RGB數據通過感知神經網絡以車輛作為中心進行物體的識別、定位、對周圍物體建立運動模型.之后導航模塊接收感知結果,結合靜態地圖建立局部實時的動態地圖,并根據該動態地圖使用Hybird A*,teb local planner等導航算法進行路徑規劃,生成一個車輛可執行動態避障的路徑.根據該路徑計算車輛的加速度、轉角等控制數據,并將控制數據發送CAN總線控制車輛.整個系統的每個部分都需要巨大算力的支持,這里我們利用模塊MPinfer來實現計算優化以滿足系統運行實時性要求.
4.1.1 感知模塊
本系統在感知部分使用感知融合技術,而感知融合根據結構可以分為2類:前融合、后融合.前融合直接以3D激光、攝像頭、IMU作為數據來源并結合車輛當前運動狀態通過神經網絡直接給出對環境周圍物體的識別、追蹤.而后融合則在得到識別、追蹤等感知結果后再進行融合.本系統包含這2種融合方式.
通常感知模塊這部分的結果表現為一個對周圍環境物體的列表,表中不僅包含物體的坐標還有物體的運動速度、方向等運動信息.為了滿足車輛行駛的需求通常該模塊工作頻率在50 Hz左右,根據車輛自身的運動性能可以對該頻率進行下調,目前本系統部署的車輛最高速度為1.5 ms左右,該模塊工作頻率可略微下調.
感知模塊除了對周圍環境進行物體識別并建立模型之外,還負責車輛在當前環境中的定位工作.定位則不僅僅需要3D激光、攝像頭的感知數據,還有RTK GPS的高精度定位信息以及預先建立的離線地圖,通過3D激光和攝像頭的感知數據在離線地圖內進行識別,匹配得到車輛在地圖中的坐標,再結合RTK GPS的定位數據得到更加準確的定位坐標.
此外在真實的交通環境中,該模塊還負責對交通燈的識別,以及道路車道線、可行駛區域的識別,并將這類感知結果輸出給規劃導航模塊.
4.1.2 規劃、導航、控制模塊
Sonic自動駕駛系統的規劃模塊接收感知模塊輸出,獲取對周圍環境感知的結果以及定位信息.首先進行全局路徑規劃:根據輸入到當前系統中的目標位置、車輛當前位置,結合靜態地圖,通過Dijkstra,A*等算法得出粗糙的路徑,這部分的規劃涉及到了當前車輛未觀察到的地圖,并且使用的算法沒有考慮到車輛的運動學限制,因此得到的路徑不能直接用于車輛的行駛,而為了使得這一部分的執行速度加快,通常全局路徑規劃使用進行網格化后的地圖.
得到了導航路徑后,在局部路徑的基礎上利用pure pursuit等算法保證車輛能夠成功地沿著路徑平滑行駛,同時確保駕駛的舒適度.之后根據路徑特點對車輛的行駛線速度、加速度進行規劃,使車輛行駛過程速度變化平緩,保證駕駛的舒適度,防止突然變化的速度造成交通事故.
控制模塊的重點在于車輛如何精準迅速地執行指定指令.給車輛發送一個控制信息(線速度、轉角)到車輛接受該控制信息、執行相應的控制信息最后車輛輸出每個步進電機、舵機的控制信號,達到給定的狀態,這個過程由于模塊間的延遲、以及控制信號達到給定數值直接的延遲,導致從當前狀態到給定狀態直接有較大的延遲.為了使車輛能夠盡量以理想狀態運行,控制模塊需要PID、模糊控制等自動控制方面的算法,以實現給車輛相應的線速度、角速度等控制信息后,車輛迅速且穩定地達到給定的控制狀態.
在Sonic系統中控制模塊集成在車輛底盤中,直接將目標狀態通過CAN總線發送給底盤即可.
4.2 ImageFusion:Sonic融合感知
在本系統的感知模塊,我們通過挖掘3D點云和2D圖像之間的隱式相似性,提出了一種新穎的深度融合模型——ImageFusion.圖像和點云都包含不同的局部結構,并能在旋轉和平移中表現出不變性.即使點云是無序的數據結構,我們也可以通過在體素中對點云進行組織,并將每個垂直列中的點云編碼為固定長度的特征作為偽圖像.這些偽圖像包含具有特定結構的空間信息.因此,當我們將偽圖像與相機圖像結合在一起,并用2DCNN與多層感知機等目標檢測器進行處理,即可得到3D檢測的結果.由于我們的方法將相機圖像與LiDAR偽圖像融合在一起,所以起名為ImageFusion.
ImageFusion將3D點云與相機圖像作為輸入,預測對象的3D邊框,充分利用圖像與激光雷達的共同優勢.在KITTI數據集的測試結果表明,Image-Fusion明顯地優于只基于激光雷達和只基于攝像頭數據的檢測模型.ImageFusion主要由4個部分組成:偽圖像轉換(將點云數據轉換為2D偽圖像)、相機圖像預處理、圖像拼接融合、目標檢測.圖12是ImageFusion的網絡圖.下面逐一介紹這4個步驟.
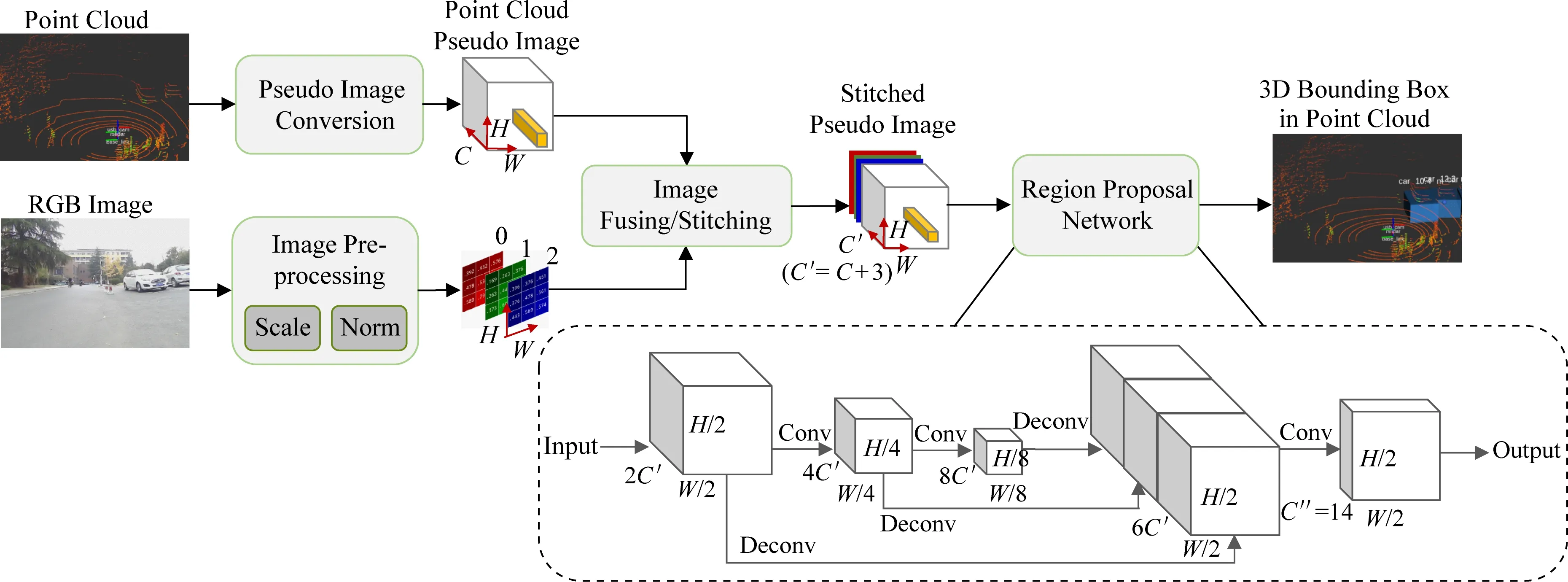
Fig. 12 The structure of ImageFusion圖12 ImageFusion網絡結構圖
第1步,在應用深度融合之前,我們需要先將不同感器的數據轉換為通用格式.我們使用PointPillar的特征網絡將3D點云轉換為2D偽圖像,其將點云分割為若干柱體,對柱體中的點進行編碼,創建大小為(C,H,W)的偽圖像.在具體的試驗中,C=64,H=432,W=496.PointPillars的整個網絡在Intel i7 CPU和1080ti GPU的臺式機上可以在20 ms內進行完整的運行,可以滿足自動駕駛對于推理速度的要求,達到實時運行的目的.
第2步,為了正確地將相機圖像與LiDAR偽圖像結合在一起,我們對相機圖像進行了適當的預處理,將其縮放到(3,H,W)的尺寸,以在H與W兩個維度匹配2個圖像.其次我們對圖像執行標準化操作.這里我們通過減去圖像中所有像素的平均值并除以標準差來進行標準化的步驟.這一步驟可以將圖像中像素的分布調整為正態分布,極大地平滑每個單獨圖像中的分布偏移,并更好地幫助深度神經網絡更好的學習特征.
第3步,為了利用各個傳感器的優勢,傳感器的融合非常重要.點云包含準確的空間信息,但是很稀疏.圖像有足夠的密度,但會受到許多環境因素的干擾,如天氣照明等.因此,我們認為將二者結合起來,可以盡可能地實現準確可靠的3D對象檢測.在第3步中,我們將LiDAR偽圖像與預處理后的相機圖像進行串聯拼接,獲得大小為(C′,H,W)的偽圖像,其中C′=C+3.
第4步,我們使用了RPN(region proposal net-work)進行目標物體3D邊框的生成.在Image-Fusion中,RPN輸入第3步中融合產生的偽圖像.RPN由3個卷積塊、3個反卷積塊和1個最后的卷積層組成.每個卷積塊執行卷積運算以縮小圖像尺寸,同時使通道數增加1倍.之后加上BatchNorm層和Relu層,隨后反卷積塊對相應卷積塊的輸出進行反卷積操作.最后將3個反卷積塊的輸出按順序串聯成形狀為[6C′,H2,W2]的向量,由卷積層進行最終的邊框預測.
在實驗部分,我們首先比較ImageFusion和其他幾個融合網絡的3D目標識別效果.我們關注汽車對象的檢測,將KITTI數據集分為3 712個訓練樣本和3 769個測試樣本.ImageFusion的準確率較僅使用雷達的方法(PointPillars)提高了7.64%,較之前的深度融合方法(MV3D,PointFusion)提高了8.77%.具體結果如表5所示.
最后對測試結果進行定性分析,如圖13所示,圖13(a)~(f)展示了ImageFusion的預測結果.其中圖13(a),(c),(e)為人類居住場景,圖13(b),(d),(f)為高速公路場景.不同場景的難度由若干因素決定:待檢測對象的大小(較小的對象較難檢測)、待檢測對象的數量(對象較多的場景較難檢測)等.我們可以觀察到,在這6個代表性的場景中,代表檢測結果的紅色框與代表真實情況的綠色框有著很高的重疊率,這代表著我們的模型可以在復雜的場景中準確地預測對象的3D邊框.

Fig. 13 Qualitative results on the KITTI dataset across 6 different scenarios圖13 在KITTI數據集中對6個不同場景的定性分析
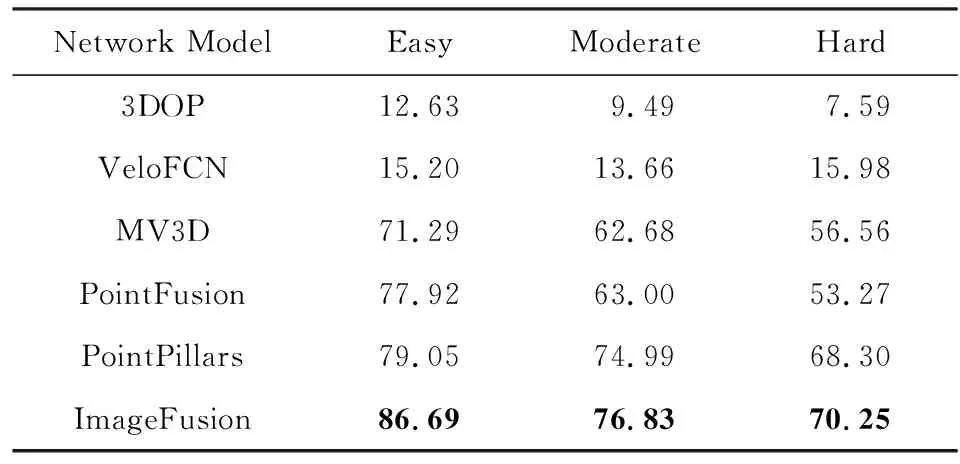
Table 5 Comparison of Average Precision for the Car Category on KITTI Dataset
4.3 MPInfer:Sonic計算優化
在Sonic系統中,需要使用卷積神經網絡CNN處理來自多個攝像頭的圖像,進行一系列的感知任務.雖然CNN網絡有著較高的準確率,但是它在車載設備上面的推理延遲較高,導致吞吐率較低,難以支持多路攝像頭均達到每秒30幀的實時性要求.為此,我們設計了MPInfer(multi-tenant parallel CNN inference framework)這一框架來進行多路攝像頭數據下多個CNN網絡實例的調度優化.
圖14是MPInfer設計的結構圖.在離線時,MPInfer的輸入是高層次的CNN模型表示(包括模型定義文件和權重文件)和可調參數(如批量大小和數據類型).CNN EngineBuilder利用輸入生成一組優化的CNN模型.我們將CNN EngineBuilder設計為用于處理大量的CNN推理模型(如YOLOv3[14])的模塊,從而適應硬件資源限制和模型精度要求.在運行時,MPInfer使用來自多個攝像頭的視頻流,并將輸入的圖像插入優先級隊列.優先級隊列根據啟發式方法對圖像進行排序,并在輸入圖像數目大于隊列大小時進行丟棄,然后將它們分派到后續的CNNApplication.CNNApplication使用線程池來執行用戶指定的CNN模型推理以及預處理和后處理,并可以根據配置啟用不同的并行策略.最后,MPInfer輸出結果(如圖像的標注框)給自動駕駛中下一個模塊(如導航模塊).
可配置性和高效是MPInfer設計的兩大目標.由于存在多種網絡模型和結構以及各種優化策略,可配置性成為MPInfer的一個設計目標.CNNEngine-Builder的接收模型可以是任意CNN模型.此外,我們的框架還配置了攝像頭數量或者視頻流數目的超參數Ncam、線程數Nt以及GPU并行策略S.MPInfer旨在實現高吞吐量、低延遲.吞吐量測量固定周期內處理的圖像數.30 FPS被確定為最小的實時性要求.延遲(從圖像捕獲到識別完成)是另一個相關的關鍵指標,并與自動駕駛的安全性直接相關.每幀圖像從相機到識別的延遲,用于實時自主駕駛時間不得超過輸入圖像的間隔(例如,對于30 FPS相機為33 ms).
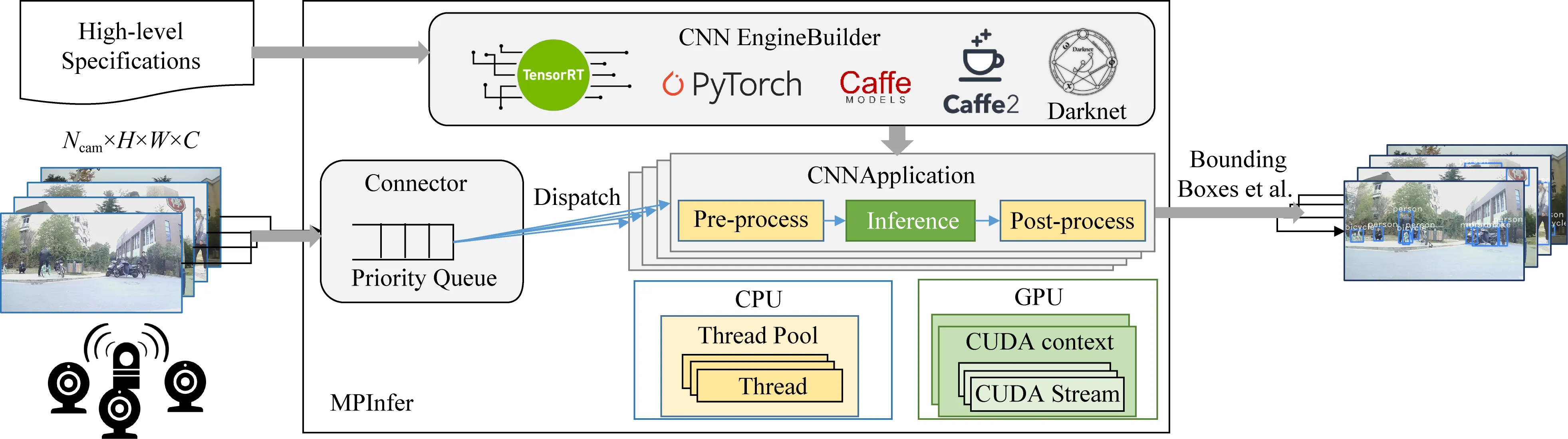
Fig. 14 Overview architecture of MPInfer圖14 MPInfer結構圖
MPInfer在網絡構建和模型運行時進行優化.在網絡構建時,CNNEngineBuilder獲取的輸入使用高效的深度學習框架TensorRT[29]進行模型構建和優化.通過使用TensorRT,可以利用TensorRT支持的計算圖優化、算子自動調優和INT8量化.模型運行時,MPInfer使用了3.1節提到的3種GPU并行模式,分別是同一CUDA context下多CUDA stream并行模式、多CUDA context并行模式、multi-process service(MPS)支持下的多CUDA context并行模式.
MPInfer作為一個支持自動駕駛多視頻流CNN模型推理的框架,達到了低延遲和高吞吐率的設計目標.在實驗中,我們使用的模型是YOLOv3[14],測試平臺是GTX 1660和Jetson AGX Xavier.我們使用一個簡易程序模擬攝像頭的圖片流,每個攝像頭30FPS,則多個攝像頭的圖片流吞吐率為30FPS的倍數.
表6給出了輸入為4個攝像頭120FPS情況下MPInfer和其他框架在GTX 1660上的性能對比.MPInfer在使用MPS支持下的多CUDA context并行模式(線程數為3)時性能最好,吞吐率為117.62 FPS,延遲為21.31 ms.相比串行的LibTorch吞吐率提高3.97x,相比串行的TensorRT吞吐率提高1.41x.
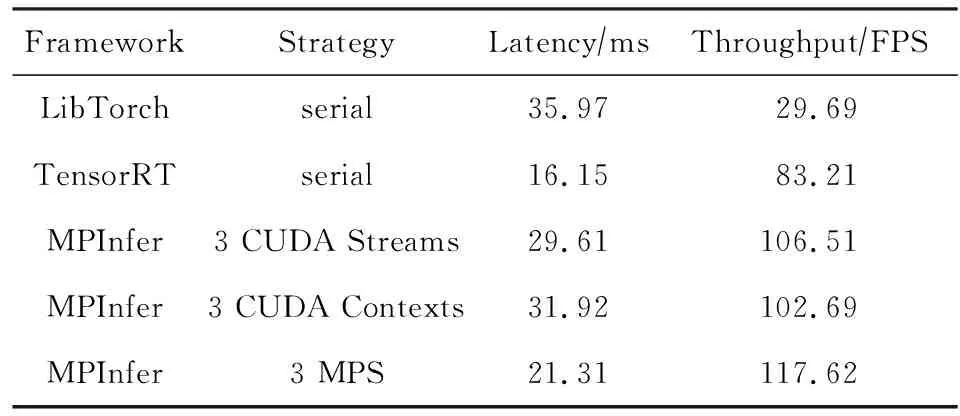
Table 6 Comparison of MPInfer with Other Frameworks on GTX 1660
表7給出了輸入為2個攝像頭60FPS情況下MPInfer和其他框架在Jetson AGX Xavier上的性能對比.MPInfer在使用同一CUDA context下多CUDA stream并行模式(線程數為2)時性能最好,吞吐率為45.84FPS,延遲為56.55 ms.相比串行的Darknet吞吐率提高4.48x,相比串行的TensorRT吞吐率提高1.14x.

Table 7 Comparison of MPInfer with Other Frameworks on Jetson AGX Xavier
從表6和表7的結果看,GPU并行相比串行能更好地發揮出GPU的性能,提升系統的吞吐率.在GTX 1660上,我們推薦在多線程環境下使用MPS支持的多CUDA context并行模式.在MPS不支持的Jetson AGX Xavier設備上,我們推薦在多線程環境下使用多CUDA stream并行模式.
5 總 結
自動駕駛能如何為駕駛員提供更加舒適的駕駛環境,如何為交通參與者帶來比人為駕駛更高的安全性,如何更高地提高未來城市的運行效率,涉及的技術仍然值得更多的關注.本文著眼于自動駕駛技術鏈中感知與計算部分,首先回顧了自動駕駛的歷史背景,綜合評述了關于自動駕駛的系統分類、硬件結構、軟件組成等方面,并指出了其中仍然存在的感知與計算挑戰;其次,基于激光雷達、攝像頭及二者融合3個方面調研了近年來感知領域關于3D檢測的國內外最新成果;隨后針對自動駕駛的實時計算的問題,分析了計算優化中有關模型調度、模型量化、模型蒸餾等關鍵技術手段;最后詳細介紹中國科學技術大學LINKE實驗室在自動駕駛領域的最新進展——智能小車系統Sonic,感知融合算法Image-Fusion,以及計算優化框架MPInfer.智能小車系統Sonic仍然在持續設計和開發中.在未來的工作中,我們計劃在現有成果的基礎上進一步擴展和優化,實現包括目標檢測、目標跟蹤、建圖與定位、規劃與導航以及對應模塊計算優化的全棧自動駕駛技術,完成一套麻雀雖小五臟俱全的,真正可靠、可用的無人小車系統.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
現代出版(2020年3期)2020-06-20 07:10:34
數學物理學報(2020年2期)2020-06-02 11:29:24
