基于深度學習的三維目標檢測方法綜述*
2020-09-22 01:10:20彭育輝鄭瑋鴻張劍鋒
汽車技術 2020年9期
彭育輝 鄭瑋鴻 張劍鋒
(福州大學,福州 350116)
1 前言
有別于機器視覺傳感器,激光雷達傳感器具有受環境和天氣等因素影響小、測距精準等優點。隨著多線激光雷達傳感器價格的逐年下降,基于車載激光雷達進行汽車外界環境感知成為實現汽車無人駕駛的主流技術方案,同時也是汽車無人駕駛領域的關鍵技術和研究熱點。
基于激光雷達實現車外環境信息的感知就是在汽車行駛過程中,通過車載激光雷達準確地估計出車外不同三維目標的類別和位置,即分類和定位[1-6]。車載激光雷達獲取的物體三維點云具有稀疏、分布不均、無序的特點,從而衍生出不同的數據處理算法。其中,基于深度學習的點云處理方法因其優秀的分類準確性和實時性而受到國內外學者的普遍關注。
深度學習的一般表現形式為一種深層神經網絡,具有很強的特征提取能力,在監督式學習的目標分類上取得了很好的結果。圖像是最早、最常用的視覺信息載體,攝像頭等設備采集的圖像信息大量使用,因此,圖像信息的處理十分重要。2010 年,Felzenszwalb 團隊提出的可變形部件模型(Deformable Part Model,DPM)[7]使傳統的二維圖像目標檢測與識別達到一定的高度,但是算法的效果并不令人滿意,梯度方向直方圖(Histogram of Oriented Gradients,HOG)特征提取存在的遮擋物影響問題仍然比較突出。2013年,Girshick 等提出區域卷積神經網絡(Region-based Convolutional Neural Network,R-CNN)[8],揭開了基于深度學習的二維目標檢測與識別的帷幕。目前,基于深度學習的二維圖像目標檢測方法不斷完善[9-13],已廣泛應用在人臉識別、交通管理、文字識別等方面[14-17],技術成熟可靠。
在處理激光雷達獲取的三維點云方面,借鑒二維圖像的目標檢測成為一種重要的技術途徑。將三維點云數據降維后,利用圖像目標檢測的方法進行特征提取是初期的處理手段,算法耗時長且精度不足,局限性明顯。隨著車載激光雷達和計算機硬件的不斷進步,蘋果公司提出了VoxelNet[1]對三維點云進行編碼處理,美國斯坦福大學于2017 年提出了PointNet[18],首次將原始點云數據投入深度神經網絡訓練的模型,清華大學與百度公司聯合開發了MV3D(Multi-View 3D networks)[6],實現了點云多視圖融合圖像處理。上述方法都通過直接或融合處理點云的方式逐漸取代了間接的手段,成為三維目標檢測方法的發展趨勢。
本文將在回顧二維目標檢測方法的基礎上,對目前國內外基于深度學習的三維目標檢測方法進行綜述,為車載激光雷達目標檢測方法的選擇提供參考依據。
2 二維目標檢測
二維目標檢測主要解決圖像中的目標分類和定位問題。由于圖像的像素具有十分豐富的目標紋理信息,所以主流的方法是利用提取特征能力優異的深度卷積神經網絡對圖像進行目標檢測。近10 年來,隨著信息獲取技術的不斷進步,出現的ImageNet、PASCAL VOC和COCO(Common Objects in Context)等數據集為深度神經網絡模型的訓練提供了可靠的數據來源,可以使模型減少不必要的誤差,快速地靠近最優解,對模型的學習訓練起到重要的作用。
2010年,Felzenszwalb 團隊提出的DPM 是當時檢測效果最好的模型。這種由人工選取特征的目標檢測模型隨著信息量的增大呈現出很大的局限性,因此在目標檢測上逐漸引入了深度學習方法。2013年,Girshick 等提出了R-CNN[8],使用區域候選的方式替代了滑動窗口,再通過卷積神經網絡(Convolutional Neural Network,CNN)提取候選目標的特征。R-CNN 在每次特征提取時都要重新進行CNN 的訓練,增加了計算成本。2015年,Girshick 等對R-CNN 進行改進,提出快速區域卷積神經網絡(Fast Region-based CNN,Fast R-CNN)[9],采用將感興趣區域(Regions of Interest,RoI)與CNN結合的方式平行輸出分類和邊框回歸的結果。由于R-CNN 和Fast R-CNN 運算量大且無法很好地使用圖形處理器(Graphics Processing Unit,GPU)進行運算,因此檢測速度很難提高。同年,Ren等提出了端到端的更快速區域卷積神經網絡(Faster Region-based CNN,Faster RCNN)[10],目標區域候選由區域候選網絡(Region Proposal Networks,RPN)來完成,所有運算過程都可以在GPU 上運行,檢測速度得到提高。受R-CNN 的啟發,He 等提出了掩模區域卷積神經網絡(Mask Regionbased CNN,Mask R-CNN)模型[19],Zhang等提出了局部-區域卷積神經網絡(Part-based R-CNN)模型[20]等。
基于目標區域候選的檢測算法都要先提取目標候選區域,明顯增加了運算的負荷。Redmon 提出了基于回歸的YOLO(You Only Look Once)模型[11],從圖像的輸入到檢測結果的輸出,只使用了1 個深度神經網絡模型,把點云的處理當作回歸問題,精度低于Faster RCNN模型,但是檢測速度至少提高了5倍。繼YOLO模型之后,Liu 等提出了單發多框檢測器(Single Shot MultiBox Detector,SSD)模型[12],速度比YOLO 更快的同時,可獲得與R-CNN相媲美的精度。YOLO和SSD高效的處理速度再次證明了深度神經網絡在提取特征和分類任務上具有很強的性能,但是處理結果的精確度有待提高。YOLO 經過不斷改善,出現了YOLOv2[13]和用于研究三維目標檢測的YOLO3D[21]。對于目標檢測的研究,算法的處理速度和精確度是相互矛盾的,若以保證處理速度為主,算法就會精簡,對特征的提取可能會變得簡單。表1 所示為二維目標檢測方法在PASCAL VOC 2007 數據集上測試的結果,其中,Faster R-CNN(VGG)是指以視覺幾何組(Visual Geometry Group,VGG)網絡為特征提取器的Faster R-CNN,SSD(300)是指輸入圖像尺寸大小為300×300 的SSD。由表1 可知,平均精度最高的是SSD(300),處理速度也達到了59 幀/s,相比最高速度的Fast YOLO模型,平均精度高21.6百分點,檢測精確度和處理速度取得了一定的平衡。
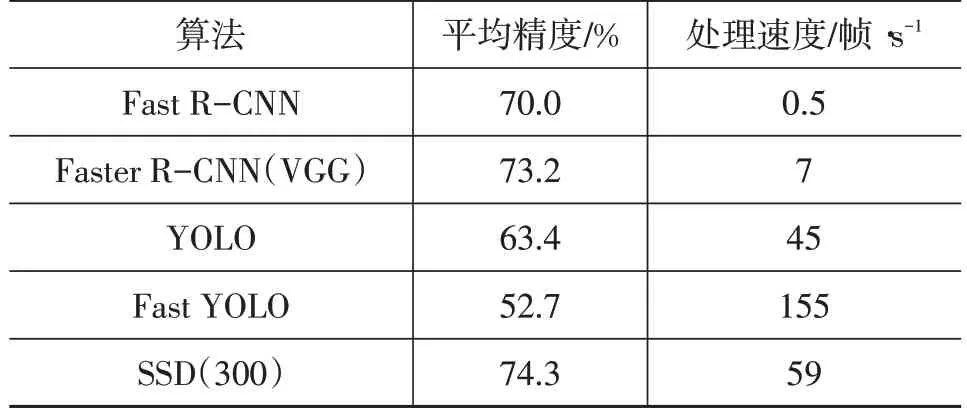
表1 二維目標檢測方法測試結果
本質上,對目標檢測方法的探索就是對深度神經網絡的研究,二維目標檢測的深度神經網絡對三維目標檢測方法研究具有啟發性的作用,如RPN 和基于回歸的YOLO設計等。
3 三維目標檢測
隨著近年車載激光雷達在汽車智能駕駛領域的廣泛應用,由車載激光雷達獲取的三維點云數據逐漸成為國內外研究的熱點。點云數據攜帶的信息主要是以激光雷達為原點的空間坐標和反射強度。相繼出現的機器人三維掃描庫(Robotic 3D Scan Repository)、悉尼城市目標數據集、KIITI 數據集[22]等多個開源數據集為網絡的訓練及驗證提供了有效的數據支撐,由KITTI數據集節選出并經過處理的點云和相對應的高清圖片如圖1 所示。基于深度學習的三維點云處理方法總體上可分為3 類,即間接處理、直接處理和融合處理。間接處理點云的方法主要是對點云進行體素化或降維后再投入已有的深度神經網絡進行處理;直接處理點云的方法主要是重新設計針對三維點云數據的深度神經網絡對點云進行處理;融合處理點云的方法則是融合圖像和點云的檢測結果再進一步處理。隨著圖像硬件的發展,融合處理點云的方法將是點云處理的主要技術。

圖1 KITTI數據集節選[22]
檢測的主要目標有車輛、行人和騎行者,其中行人和騎行者的點云數據比車輛的點云數據稀疏,可提取的特征信息少,檢測難度大。目前的檢測算法都以車輛的檢測為主,兼容行人和騎行者的檢測。
3.1 間接處理點云
間接處理點云的對象,最初主要有RealSense、Kinect 等三維智能傳感器采集的深度圖像(RGB-D)和經過人工處理的CAD模型。間接處理點云的方法大都源自前期二維目標檢測的深度神經網絡模型,先利用統計的方法或者卷積網絡模型將點云數據轉化為體素網格的形式或其他二維特征,再利用深度神經網絡模型進行學習訓練。
最初,人們并未對點云的性質進行深入研究,而是受圖像像素處理方法的啟迪,將點云和圖像一樣進行“像素”的處理,即對點云進行體素網格處理,再對體素網格進行研究分析,初期主要的間接處理方法[4,23-26]特點如表2所示。
蘋果公司針對無人駕駛場景下的三維目標檢測提出了一個端到端的深度神經網絡——VoxelNet,實現對點云的逐點處理。其設計的特征學習網絡層(Feature Learning Network)對輸入的點云進行體素分塊(Voxel Partition)、點云分組(Grouping)、隨機采樣(Random Sampling)、多層體素特征編碼(Stacked Voxel Feature Encoding)、稀疏張量表示(Sparse Tensor Representa?tion),經過卷積網絡的壓縮提取后接入RPN 層進行高效檢測。VoxelNet 模型僅利用車載激光雷達的點云數據輸入進行模型訓練,保證了點云的原始三維特征。重慶大學的Yan等受VoxelNet的啟發,提出了稀疏嵌入式卷積檢測網絡(Sparsely Embedded Convolutional Detec?tion,SECOND)模型[27],采用2 個串聯的體素特征編碼(Voxel Feature Encoding,VFE)架構,采用稀疏卷積神經網絡進行連接,利用RPN 完成目標的檢測工作,如圖2所示[27]。SECOND 充分利用了點云的稀疏性,改善了VoxelNet中的特征提取效果。
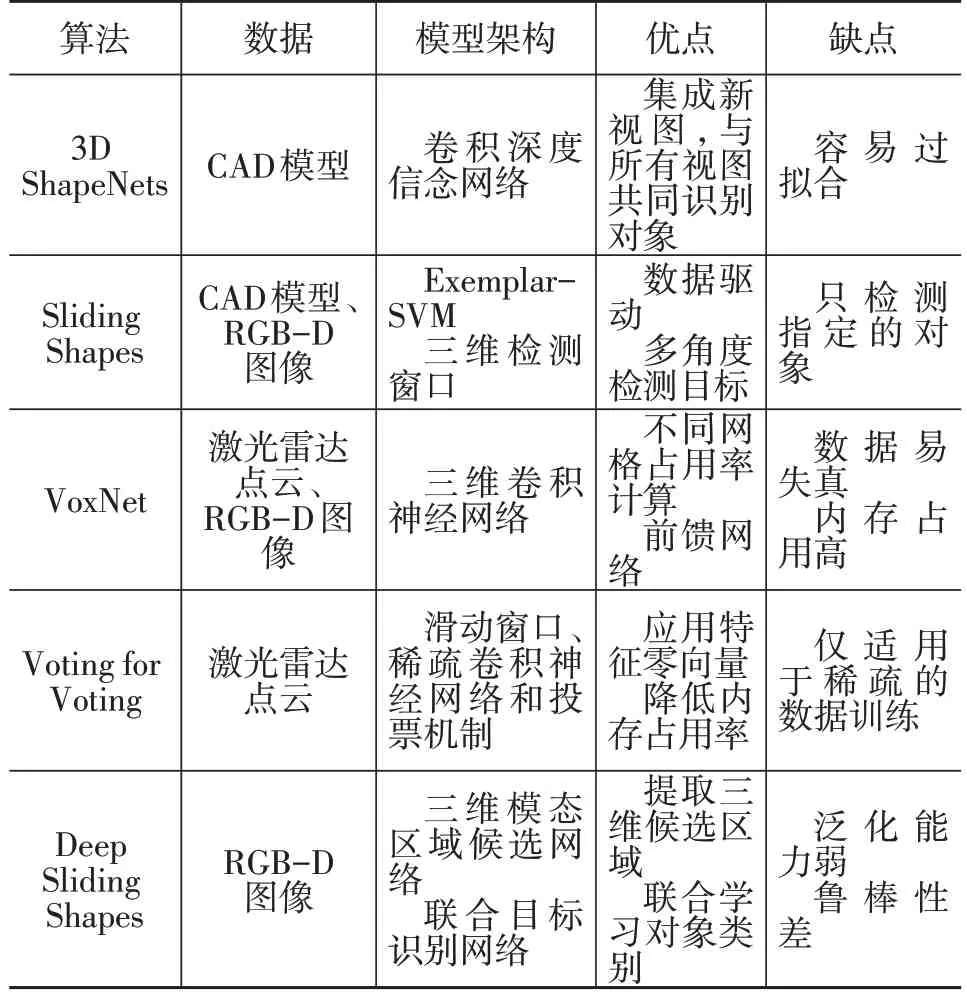
表2 初期主要的間接處理方法比較
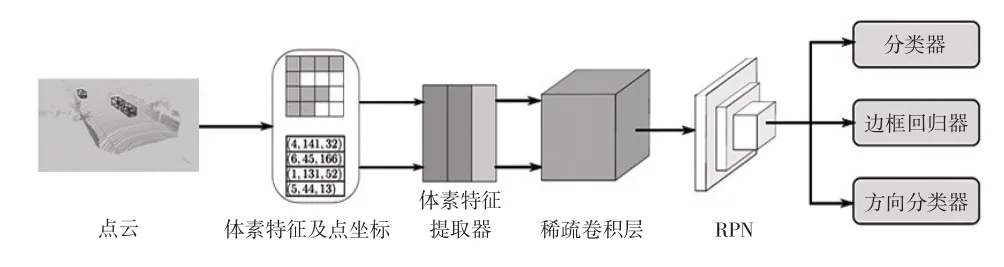
圖2 SECOND模型[27]
有別于體素網格處理方法,將點云的深度信息投至圖像而形成的融合深度圖像方法是另一種重要的點云間接處理途徑。受到Dolson[28]和Andreasson[29]等人的啟發,2014年,Cristiano[30]指出了點云所具有的深度信息在行人檢測中起到重要的作用。緊接著,Alejandro結合深度圖一并考慮行人的朝向,提出了多視圖隨機森林(Multiview Random Forest)算法[31],并指出算法中的一些簡易模塊可以使用卷積神經網絡進行特征表示,檢測效果會進一步提高。2016 年,斯坦福大學的Qi 等提出多視角卷積神經網絡(Multi-View CNN,MVCNN)[32],利用一個神經網絡輔助預測目標分類,設計了非均質的探測過濾器將三維數據投影至二維空間做目標分類。在訓練的過程中,做了數據擴增,并根據三維物體設計了多方向池(Multi-Orientation Pooling)。該方法對Model?Net40 模型庫的檢測精度已經達到了86.6%,超過了之前的所有檢測算法。百度公司的李波[5]將數據以二維點圖的形式表示,移植了圖像處理的端到端深度神經網絡,能夠同時預測目標置信度和邊界框。
間接處理點云的方法借鑒二維目標檢測的設計,如數據預處理中的“體素化”或者合成深度圖,網絡模塊中的RPN 或者稀疏卷積神經網絡等,都會導致網絡訓練過程中失去一部分三維特征信息,甚至引入誤差。在網絡模塊的設計中可以加入池化(Pooling),大量的卷積運算會使數據的提取產生偏移,池化不僅可以改善這種錯誤,還可以減小過擬合并且提高模型的魯棒性。
3.2 直接處理點云
隨著研究的不斷推進,學術界愈發重視點云數據本身的特性,如無序性、稀疏性和分布不均等。直接處理點云的方法是直接把原始的三維點云數據投入重新設計的深度神經網絡進行訓練,并不對點云數據做任何預處理,而且深度神經網絡的設計不受以往圖像檢測網絡設計的影響。
斯坦福大學的Qi 等提出了PointNet[18],直接從點云中學習點對點特征。PointNet 使用多層感知機(Multi-Layer Perceptron,MLP)提取單點特征,訓練最大池化層作為對稱函數,整合來自全局的點云信息并解決了點的無序性問題,最后得到全局特征。其中,設計的空間變換網絡可保證輸入點云的不變性。PointNet 在三維物體檢測、三維物體部分分割和逐點語義分割任務中取得了良好效果。PointNet 解決了無序和不變性問題,提取了全局特征,但是沒有考慮到全局信息的問題,經過改進,Qi等提出了PointNet++[33],該模型考慮了點與點之間的距離度量,通過層級結構利用局部區域信息學習特征,還解決了采樣不均等問題,使得網絡結構魯棒性更好。PointNet和PointNet++的提出對三維目標檢測技術具有深遠的意義。香港大學的Shi等利用PointNet++模型提出了PointRCNN[34]。PointRCNN 主要分為2 個階段處理點云,先利用具有強大實例分割能力的PointNet++進行點云的初步分割,提出目標候選框,再進行目標候選框的精細化處理以精準地檢測目標。新加坡國立大學的Uy等成功地將PointNet模型和NetVLAD[35]結合,提出了端到端的PointNetVLAD[36],并使用度量學習[37]的訓練方法,準確地得到點云的全局描述信息特征,解決了基于點云檢索的位置識別問題。香港大學的Yu等利用PointNet 的點特征聚合能力將點云的三維坐標映射到特征空間,再結合特征擴展組件[38]和全連接網絡完成點云的三維坐標重建任務。德國慕尼黑工業大學的Deng等人提出PPFNet[39],使用多個PointNet 提取多個對應面片區域的特征,再利用最大池化層聚合和融合,得到全局特征。PointNet 的提出起到了很大的啟發作用[40-48],其對點云特征提取的優異效能得到了學者們的肯定和廣泛應用。
德國的Valeo Schalter und Sensoren GmbH(簡稱法雷奧公司)和德國伊爾曼諾理工大學借鑒YOLOv2提出Complex-YOLO[49],其繼承了YOLOv2 的網絡架構,將方向向量轉換為實值和虛值,并設計了歐氏區域建議網絡(Euler-Region-Proposal Network,E-RPN),在英偉達的Titan X顯卡上識別速度達到了50.4 幀/s,但是精確度有所偏差,而且忽略了小目標物體,如行人和騎行者。因此,法雷奧公司又提出了YOLO3D[21],吸收了MV3D模型的數據處理方法,設計了雙輸入通道,修改YOLOv2 的架構,并優化損失函數,精度得到有效提高。
目前,主流的研究手段均基于PointNet 或者YOLOv2。基于PointNet 或之后的PointNet++的層級訓練特點是能很好地得到點云的局部或者全局區域特征,基于YOLOv2 的方法繼承了YOLOv2 的高效識別速度。直接處理方法最大的難點在于設計的針對三維數據的神經網絡架構能否符合點云無序性、局部性和不變性等特點,并且如何準確地表征出來。
3.3 融合處理點云
當硬件計算速度足夠支撐算法的多維度計算時,便產生了以圖像為輔助的融合處理點云方法。融合處理點云的方法主要著眼于融合圖像和點云檢測的結果,其中圖像的檢測利用已有的二維目標檢測算法,點云的檢測利用以上提到的直接或者間接的處理方式得到檢測結果,再進一步對兩者的結果進行融合處理,得到最終檢測結果。融合處理點云的方法由于增加了高清圖像的輔助,在平均準確度上有一定的優勢。
清華大學和百度公司聯合提出MV3D[6],設計的三維候選網絡將點云的數據分成了鳥瞰和前視2個視圖,都利用卷積神經網絡處理,以點云的前視圖處理作為輔助,主要處理鳥瞰視圖得到點云的坐標及強度特征信息編碼,結合圖像(RGB)的初步卷積處理后,三者都經過池化再進行融合處理,結果接入基于區域的融合網絡,得到分類和邊框回歸結果。針對PointNet,Qi等人提出了針對無人駕駛中障礙物檢測的Frustum PointNets[3],先對高清圖像進行目標的候選,給定目標在圖像中的區域,然后用平截頭體框出對應位置的點云,其中包含了其他非目標的點,最后利用PointNet精確地把目標點云分割出來,如圖3所示[3]。加拿大滑鐵盧大學的Jason Ku等人提出的AVOD[50]神經網絡結構使用改進的RPN 分別對三維點云和RGB圖像中的目標生成各自的三維候選區域并進行融合處理,通過全連接神經網絡層連接至第二階段檢測網絡,進行三維邊界框的精確回歸和分類,預測目標障礙物。融合處理點云的算法模型,結合圖像RPN,使得融合后的處理效果得到明顯提升,其還有許多值得研究的融合算法,如深度連續融合算法[51]、針對車輛檢測的一般融合算法[52]等。
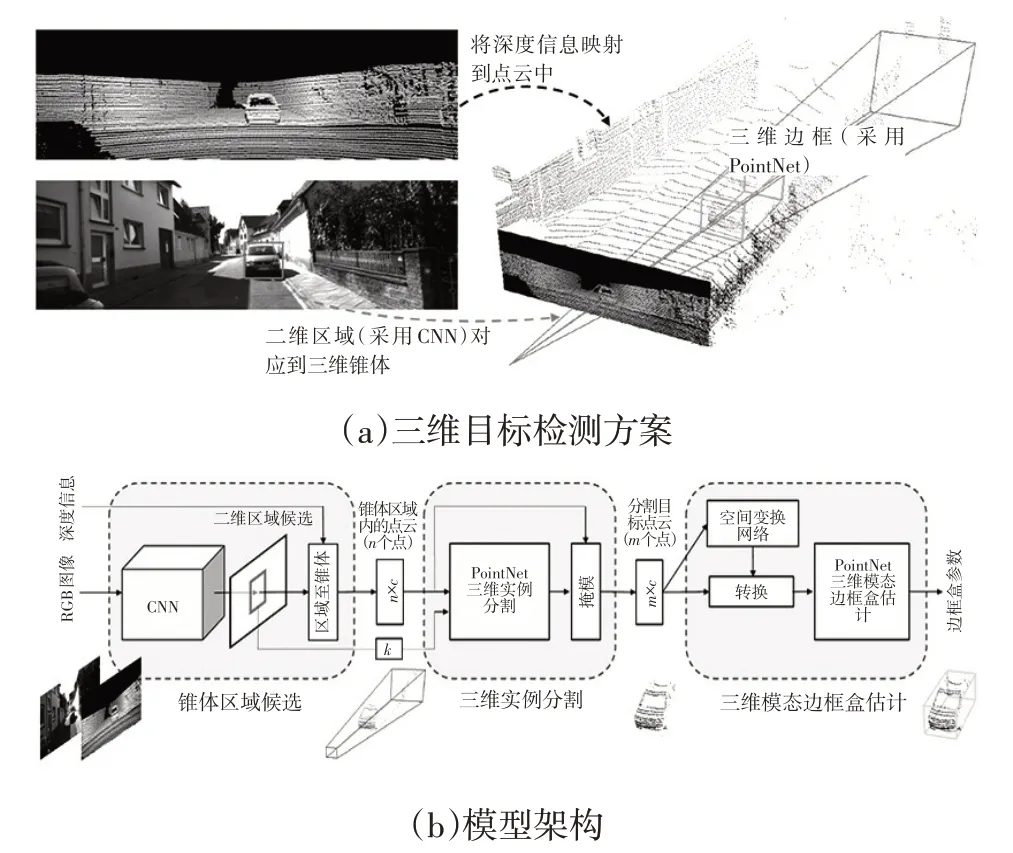
圖3 Frustum PointNets模型[3]
3種處理方法的優、缺點如表3所示,融合處理在對行人和騎行者這類稀疏的三維點云數據的檢測上具有很好的效果。間接處理和直接處理的方法在車輛檢測上平均精度可達82%,但是在行人和騎行者的檢測平均精度為30%~60%;融合處理的方法得益于結合了圖像檢測,不僅車輛的檢測精度超過85%,而且行人和騎行者的檢測平均精度已超過70%。

表3 不同處理方法的優、缺點對比
硬件的發展必然使點云處理手段的重心偏向融合處理,點云的間接或直接處理最大化地利用了三維信息,但是對小目標物體的識別能力很差,需要結合圖像的高精度識別才能使三維目標檢測的結果更加準確。Frustum PointNets 的融合方式過于依賴圖像的檢測結果,與MV3D或AVOD等將圖像和點云并行處理再融合的方式有明顯的差距,在同樣的KITTI 數據測試樣本中,Frustum PointNets、MV3D、AVOD 的 平均精度 為81.2%、89.05%、84.41%,圖像和點云并行處理再融合的方式優勢突出,將是融合處理點云的主流設計方法,其攻克的重點在于如何設計融合算法,引入神經網絡可增強融合處理算法的適應性和智能化。
4 結束語
針對車載激光雷達獲取的三維點云的目標檢測方法是實現汽車無人駕駛的關鍵技術。深度學習算法使得基于三維點云的目標檢測取得了突破性進展,但在訓練大量樣本數據或在實際應用場景下,仍會出現數據易失真、運行效率低、識別精度不高等問題。
綜合當前基于深度學習的三維目標檢測的研究現狀,本文對今后的研究提出以下建議:
a.必須有效地對原始點云進行數據預處理,減少數據采集過程中因設備或者環境產生的誤差,以有效提高檢測的效率和精度。
b.采用線性的卡爾曼濾波算法或者非線性的深度神經網絡改進融合算法,是提高融合算法的學習性能、增強融合效果的有效途徑。
c.高清圖像的輔助可以有效彌補激光雷達點云數據稀疏的缺點,所以圖像與三維點云的融合處理方法將成為三維目標檢測的主要技術發展趨勢。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
現代出版(2020年3期)2020-06-20 07:10:34
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
