基于殘差梯度法的神經網絡Q學習算法
2020-09-15 04:47:52司彥娜普杰信臧紹飛
計算機工程與應用 2020年18期
關鍵詞:實驗
司彥娜,普杰信,臧紹飛
河南科技大學 信息工程學院,河南 洛陽 471023
1 引言
強化學習是一類介于監(jiān)督學習與非監(jiān)督學習之間的機器學習算法,其學習機制靈感來源于人類的學習行為[1]。它通過不斷試錯累積經驗達到學習目的,特別適用于缺少先驗知識或高度動態(tài)化的優(yōu)化決策問題,因此被廣泛應用在機器人控制[2]、資源優(yōu)化調度[3]、工業(yè)過程控制[4]等領域,并取得了令人矚目的成果。
經典的強化學習過程中,狀態(tài)和動作空間都是離散且有限的,通常用表格來存儲,值函數(shù)也需要通過“l(fā)ook-up table”來獲得。然而,實際應用中,多數(shù)問題都具有大規(guī)模離散或連續(xù)狀態(tài)(動作)空間。若使用查表法,算法的時間和空間復雜度隨維數(shù)增加而成指數(shù)增長,易造成維數(shù)災難(curse of dimensionality)問題。為了解決這個問題,一個比較好的方法就是先對值函數(shù)進行參數(shù)化表示,然后利用逼近器擬合,稱為值函數(shù)近似(Value Function Approximation,VFA)方法[5-7]。常見的函數(shù)逼近器包括:線性多項式、決策樹、最小二乘法和人工神經網絡等。
近年來,對于各種神經網絡與強化學習相結合的理論和應用研究層出不窮,例如:文獻[8]針對連續(xù)狀態(tài)空間強化學習問題,提出了一種基于自適應歸一化RBF網絡的協(xié)同逼近算法——QV(λ),該算法對由RBFs 提取得到的特征向量進行歸一化處理,并在線自適應地調整網絡隱藏層節(jié)點的個數(shù)、中心及寬度,可以有效地提高逼近模型的抗干擾性和靈活性。文獻[9]考慮連續(xù)狀態(tài)馬爾科夫決策過程,提出了一種基于極限學習機(Extreme Learning Machine,ELM)的最小二乘時序差分算法,在旅行商問題和倒立擺實驗中均能用較少的資源獲得較高的精度。文獻[10]和文獻[11]討論了基于神經網絡的強化學習算法在移動機器人導航中的應用,分別實現(xiàn)了移動機器人的避障和跟蹤控制。
然而,對于上述多層前饋神經網絡等非線性逼近器,在權值更新過程中若使用直接梯度法,已經被證明在某些條件下無法收斂[12]。若使用殘差梯度法,雖然能夠保證較好的收斂特性,但部分情況下的收斂速度較慢[13]。基于此,本文提出一種基于殘差梯度法的神經網絡Q學習算法。利用殘差梯度法和經驗回放機制,對神經網絡的參數(shù)進行小批量梯度更新,有效減少迭代次數(shù),加快學習速度,同時引入動量優(yōu)化,進一步提高學習過程的穩(wěn)定性。此外,本文選擇Softplus 激活函數(shù)代替常用的ReLU 激活函數(shù),避免了ReLU 函數(shù)在負數(shù)區(qū)域值恒為零所導致的某些神經元可能永遠無法被激活,相應的權重參數(shù)可能永遠無法被更新的問題。最后,利用CartPole 控制任務,對所提算法的正確性和有效性進行仿真驗證,并與其他算法進行對比,結果表明本文所提算法具有良好的學習效果。
2 Q學習
強化學習中,智能體(Agent)觀察當前狀態(tài)(State),采取某種行為(Action)作用于環(huán)境(Environment),然后獲得獎賞(Reward),并迫使環(huán)境狀態(tài)發(fā)生改變,如此循環(huán)。通過與環(huán)境的不斷交互,Agent 根據(jù)獎賞值隨時調整自己的行為,以獲得最大回報為目標,其基本原理如圖1所示。
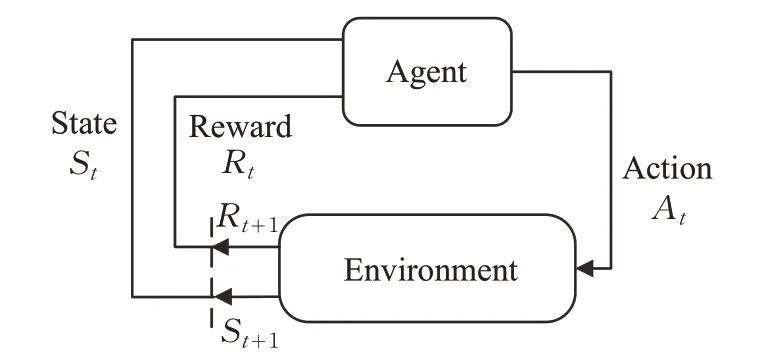
圖1 強化學習基本原理
通常,回報值定義為獎賞值的加權累積:
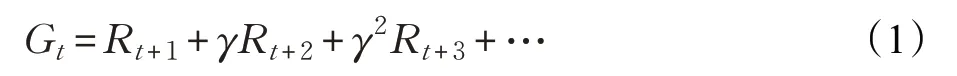
其中,γ∈ ( 0,1) 為折扣因子,用來平衡短期獎勵和長期獎勵。
為了更好地描述累積回報這一變量,定義其在狀態(tài)s處的期望為狀態(tài)值函數(shù)(value function):
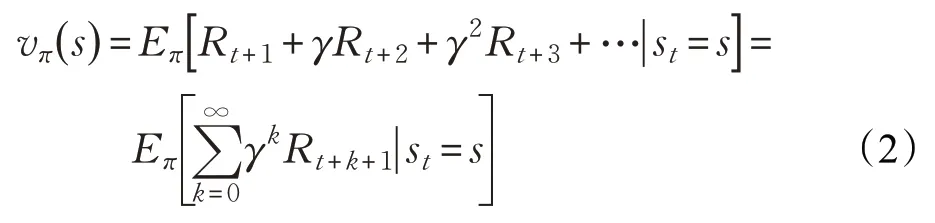
相應地,狀態(tài)-動作值函數(shù)為:
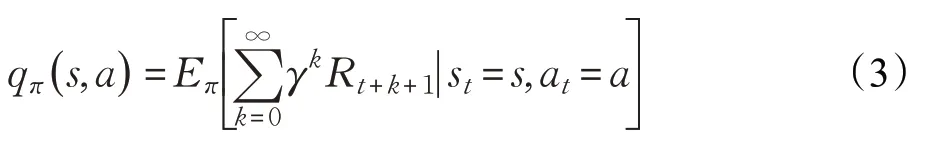
Agent 在每次動作完成以后,都要更新值函數(shù)。針對不同的更新規(guī)則,產生了多種強化學習算法。其中,Q-learning 是時序差分(Temporal Difference,TD)強化學習算法的一種,通過不斷改善特定狀態(tài)下特定動作的價值評估實現(xiàn),相當于動態(tài)規(guī)劃的一種增量方法。其更新公式定義為:
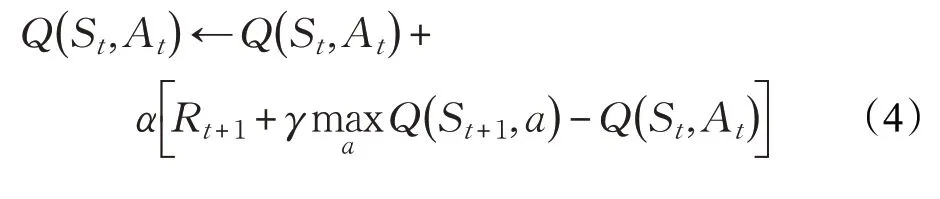
3 基于殘差梯度法的神經網絡Q學習算法
3.1 前饋神經網絡
前饋神經網絡(Feedforward Neural Network,F(xiàn)NN)是最常見的神經網絡結構之一,較為常用的前饋神經網絡有兩種,一種是反向傳播神經網絡(Back Propagation Neural Networks,BPNN);一種是徑向基函數(shù)神經網絡(Radial Basis Function Neural Network,RBFNN)。前饋神經網絡的結構并不固定,以圖2為例,包括輸入層、一個隱藏層和輸出層。層與層之間單向連接,層間沒有連接;每層節(jié)點數(shù)不固定,可根據(jù)需要設置。
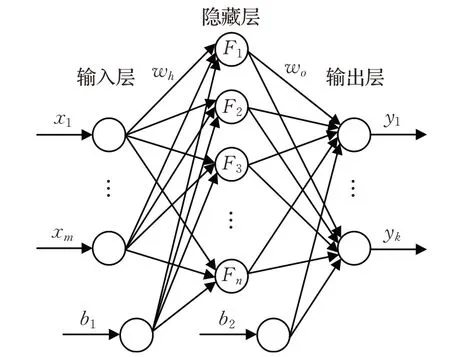
圖2 前饋神經網絡結構
雖然神經網絡強化學習的理論研究和實際應用均取得了不錯的發(fā)展,但神經網絡的選擇和訓練依然值得關注。尤其是隨著神經網絡深度的增加,模型的訓練也更加困難。其中激活函數(shù)是人工神經網絡實現(xiàn)非線性逼近的關鍵,直接影響到網絡最終的訓練效果。Sigmoid函數(shù)及Tanh 函數(shù)曾經是廣泛使用的一類激活函數(shù),但這類函數(shù)包含指數(shù)運算,計算量比較大,影響學習速度,并且其飽和性導致的梯度消失現(xiàn)象,非常不利于深度網絡的訓練,已很少使用。為了解決Sigmoid 類函數(shù)帶來的問題,有學者提出了線性整流單元(Rectified Linear Unit,ReLU)。ReLU 具有線性、非飽和形式,既能提高運算速度,又能緩解梯度消失現(xiàn)象。但是,ReLU在負數(shù)區(qū)域梯度為零,可能導致某些神經元完全不被激活,相應的參數(shù)可能永遠不被更新。因此,本文采用Softplus激活函數(shù)代替ReLU。Softplus 函數(shù)可以看作是ReLU的改進版本,更加接近生物學激活特性,可以有效克服“Dead ReLU Problem”,并使整個系統(tǒng)的平均性能更好[14]。四種激活函數(shù)的圖像如圖3所示。
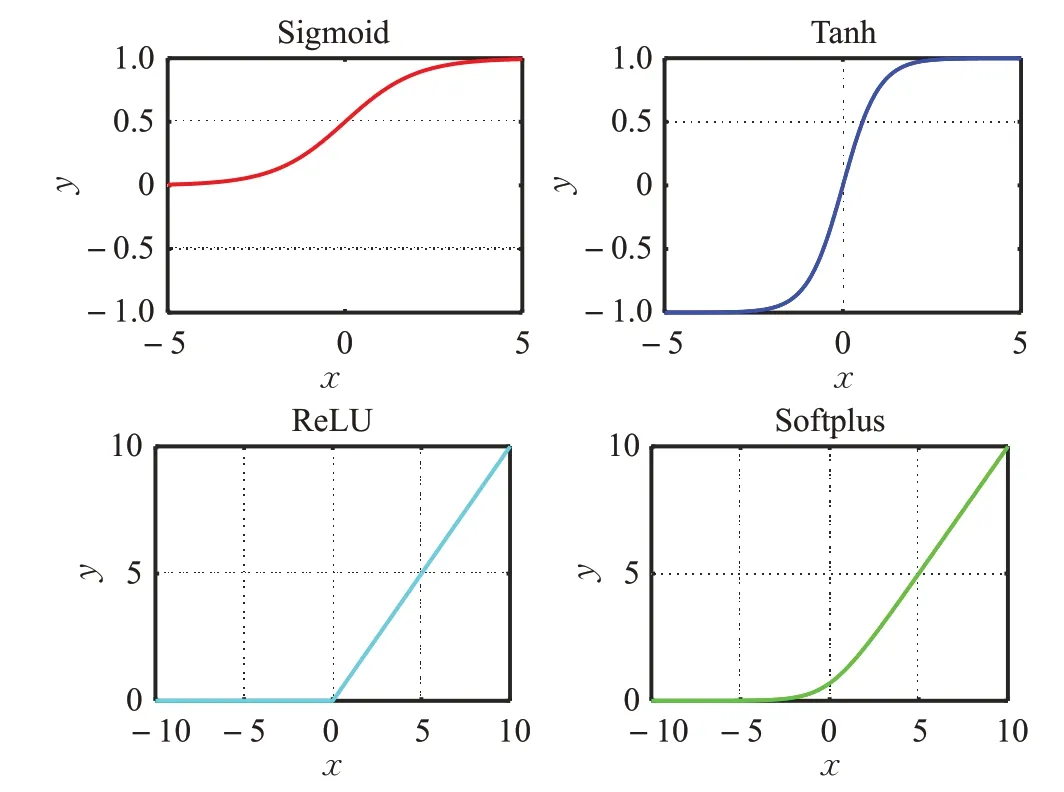
圖3 激活函數(shù)圖像
3.2 值函數(shù)近似
在離散狀態(tài)或小規(guī)模強化學習問題中,值函數(shù)一般采用表格形式存儲。面對大規(guī)模離散或連續(xù)狀態(tài)(動作)空間問題,若使用查表法,存在維數(shù)災難問題。因此需要采用值函數(shù)近似方法。利用神經網絡對值函數(shù)進行逼近時,可表示為:

此時,w為網絡更新參數(shù)。當網絡結構確定時,w就代表值函數(shù)。
采用圖2 所示的多層前饋神經網絡逼近狀態(tài)——動作值函數(shù)Q(s,a),輸入為系統(tǒng)狀態(tài)變量,輸出為每一個可能動作所對應的Q值。隱藏層有n個神經元,激活函數(shù)為Softplus 函數(shù),記為φ(x)=ln(1+ex),則神經網絡的輸出可表示為:
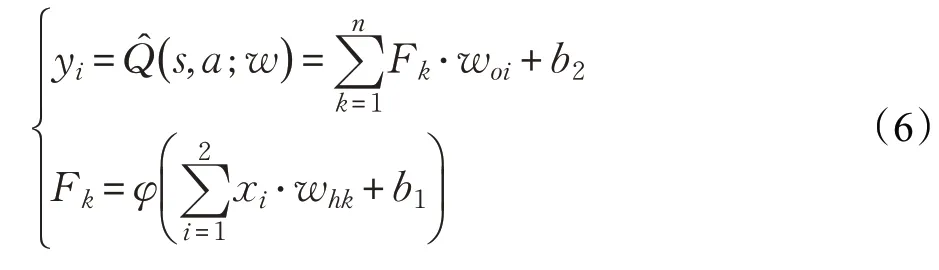
若按照直接梯度法,則神經網絡的權值更新為:
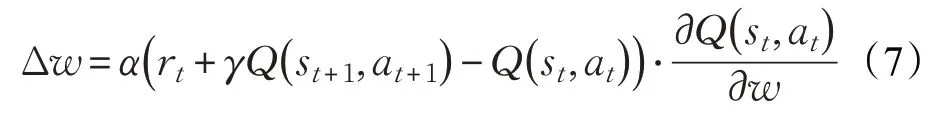
其中,α為學習速率。
雖然直接梯度法更新過程中所需信息較少,學習速度相對較快,但其收斂性無法保證。為了保證學習過程收斂,故選擇殘差梯度法更新神經網絡的權值。記誤差函數(shù)為:
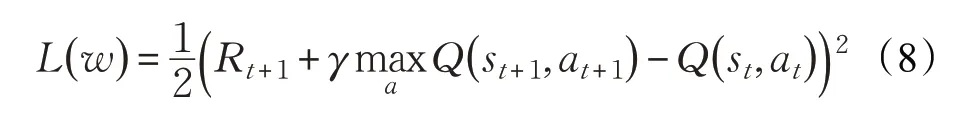
則神經網絡的權值按照殘差梯度法更新為:
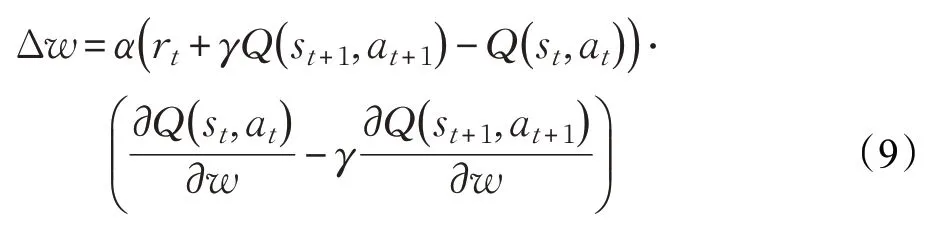
根據(jù)目標函數(shù)更新時采用的數(shù)據(jù)量,梯度下降法大致可以分為兩種:批量梯度下降算法(Batch Gradient Descent,BGD)和隨機梯度下降算法(Stochastic Gradient Descent,SGD)。BGD每次更新需要對全部的訓練集樣本計算梯度,可以保證更新朝著正確的方向進行,最后能夠收斂于極值點(凸函數(shù)收斂于全局極值點,非凸函數(shù)可能會收斂于局部極值點),但是運算量大,尤其是樣本數(shù)量較多時,會導致收斂速度非常慢,且不能實時更新。SGD 每次僅隨機選擇訓練集中的一個樣本來進行梯度更新,學習速度較快,但每次更新不能保證按照正確的方向進行,并且很不穩(wěn)定,容易造成優(yōu)化波動,使得整體收斂速度變慢。
因此本文采用經驗回放機制,儲存在線學習過程中產生的樣本,進而實現(xiàn)對神經網絡參數(shù)的小批量梯度更新。該方法相較于BGD,有效減少計算量,加快學習速度;相較于SGD,大大減少迭代次數(shù),同時訓練過程更穩(wěn)定。然而其收斂性受學習率的影響,如果學習率太小,收斂速度會很慢;如果太大,誤差函數(shù)就會在極小值處不停地振蕩甚至偏離。故而引入動量修正項,以緩解隨機梯度帶來的優(yōu)化波動問題并加快收斂過程。動量項的加入,可以使得更新速度在梯度方向不變的維度上變快,而在梯度方向有所改變的維度上變慢,這樣就可以加快收斂并減小振蕩[15]。
引入動量的梯度下降法更新公式為:

4 仿真實驗
4.1 問題描述
CartPole控制是測試強化學習算法性能的常用任務之一。如圖4 所示,在游戲里,一根桿子由一個非驅動性關節(jié)連接到一個小車上,小車可以沿著無摩擦的軌道移動。游戲開始,桿子是直立的,通過對小車施加+1或-1 的力來控制小車前后移動。每次動作,若桿子保持直立,獎勵值為+1,若桿子離開垂直方向超過12°,或者小車距離中心移動超過2.4個單位,游戲結束。
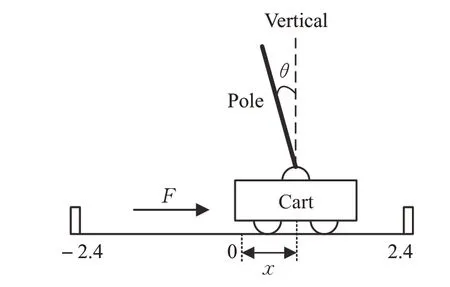
圖4 CartPole模型示意圖
該系統(tǒng)中,狀態(tài)為水平方向的位置及導數(shù)和垂直方向的偏角及導數(shù)屬于連續(xù)變量;動作為離散變量A=[-1,1],分別表示向左或向右移動。實驗使用圖2所示神經網絡結構,隱含層神經元個數(shù)設為200。
4.2 實驗結果與分析
為了充分驗證所提算法的正確性和有效性,進行兩組對比實驗。實驗中,動作選擇使用ε-greedy 策略,并且為了平衡探索和利用的關系,每一輪游戲中,ε逐漸減小,探索值ε=(0.9 →0.01) 。其他參數(shù)設置為:折扣因子γ=0.9,學習率η=0.001,動量衰減值μ=0.5,批量大小batch_size=32。
實驗1 分別對比隨機梯度下降(SGD),小批量梯度下降(MBGD)和本文所提算法在ReLU 和Softplus 兩種激活函數(shù)下的單輪學習得分情況,結果如圖5所示。
圖中,橫坐標Episode表示游戲進行的輪數(shù),縱坐標Reward 表示每輪游戲結束獲得的獎勵。每幅圖中,左側為ReLU 激活函數(shù)訓練下的結果,右側為Softplus 激活函數(shù)訓練下的結果。
其中,圖5(a)的SGD 算法在ReLU 激活函數(shù)下,雖然200 輪以后,可以達到最高分,但在1 000 輪結束后,每輪游戲的得分波動依然很大;而使用Softplus 激活函數(shù),在大約200輪以后,得到最高分的次數(shù)逐漸增多,并且分數(shù)基本保持在75 分以上。圖5(b)的MBGD 使用ReLU在100輪左右得到最高分,但大概在600輪以后分數(shù)才基本穩(wěn)定在175 分以上;而使用Softplus 激活函數(shù)在100 輪左右得到最高分,500 輪以后分數(shù)的波動次數(shù)就明顯減少,基本能夠得到最高分。圖5(c)本文所提算法在兩種激活函數(shù)訓練下,均在100輪左右開始取得最高分,但使用ReLU 在后續(xù)訓練過程中分數(shù)不太穩(wěn)定,仍然存在相對較多的波動;使用Softplus 激活函數(shù)大約200輪之后基本維持在最高分,只有幾次小幅度的分數(shù)波動。
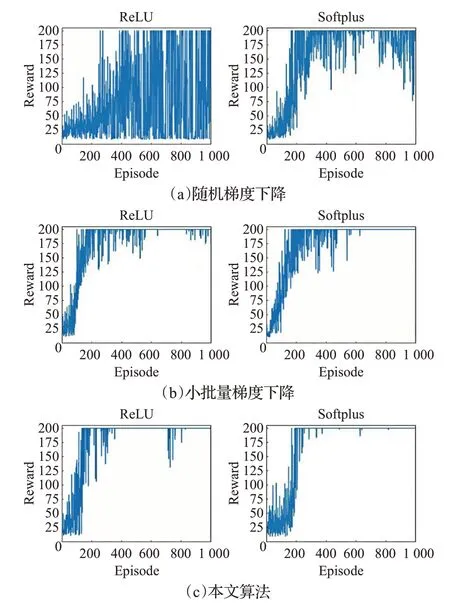
圖5 CartPole任務單輪得分
橫向對比,三種算法在使用Softplu函數(shù)代替ReLU函數(shù)以后,分數(shù)波動大幅減小,而得到最高分的次數(shù)明顯增多,訓練效果得到顯著提高。縱向對比,在兩種激活函數(shù)訓練下,本文所提出的基于動量修正的MBGD算法比常規(guī)的SGD算法和MBGD算法能更多地得到最高分,且分數(shù)波動次數(shù)與波動幅度均得到有效抑制。
實驗2 在Gym 中,CartPole 任務設定每個episode最大步數(shù)為200,并規(guī)定每100 個episode 的平均獎勵若超過195,則視為訓練成功。所以,本組實驗將對比本文所提算法與另外兩種算法的訓練成功率。
對比算法選擇常規(guī)的隨機梯度下降法(SGD with ReLU)和小批量梯度下降法(MBGD with ReLU)。為了盡可能獲得有效數(shù)據(jù),每種算法實驗4 次,并且實驗過程中保持其他參數(shù)不變。設置episode 為3 000,每100個episode記為一次訓練,取其平均獎勵值作為訓練結果,則三種算法的最終任務完成效果如圖6 所示,統(tǒng)計結果見表1。其中,圖6為三種算法在4次實驗中的訓練平均得分分布,表1為訓練成功次數(shù)統(tǒng)計。
實驗結果表明,ReLU 激活函數(shù)情況下:SGD 算法4 次實驗均未成功;MBGD 算法最少成功19 次,最多成功26次,成功率在63%以上。而本文提出的算法,最少成功26次,最多成功28次,成功率在86%以上。對比圖6(b)和6(c),可以看出本文所提算法表現(xiàn)更加穩(wěn)定,失敗情況相對較少,且集中在訓練初始階段,5次之后,基本能夠保持成功,且穩(wěn)定在最高分。

表1 CartPole任務成功次數(shù)統(tǒng)計表
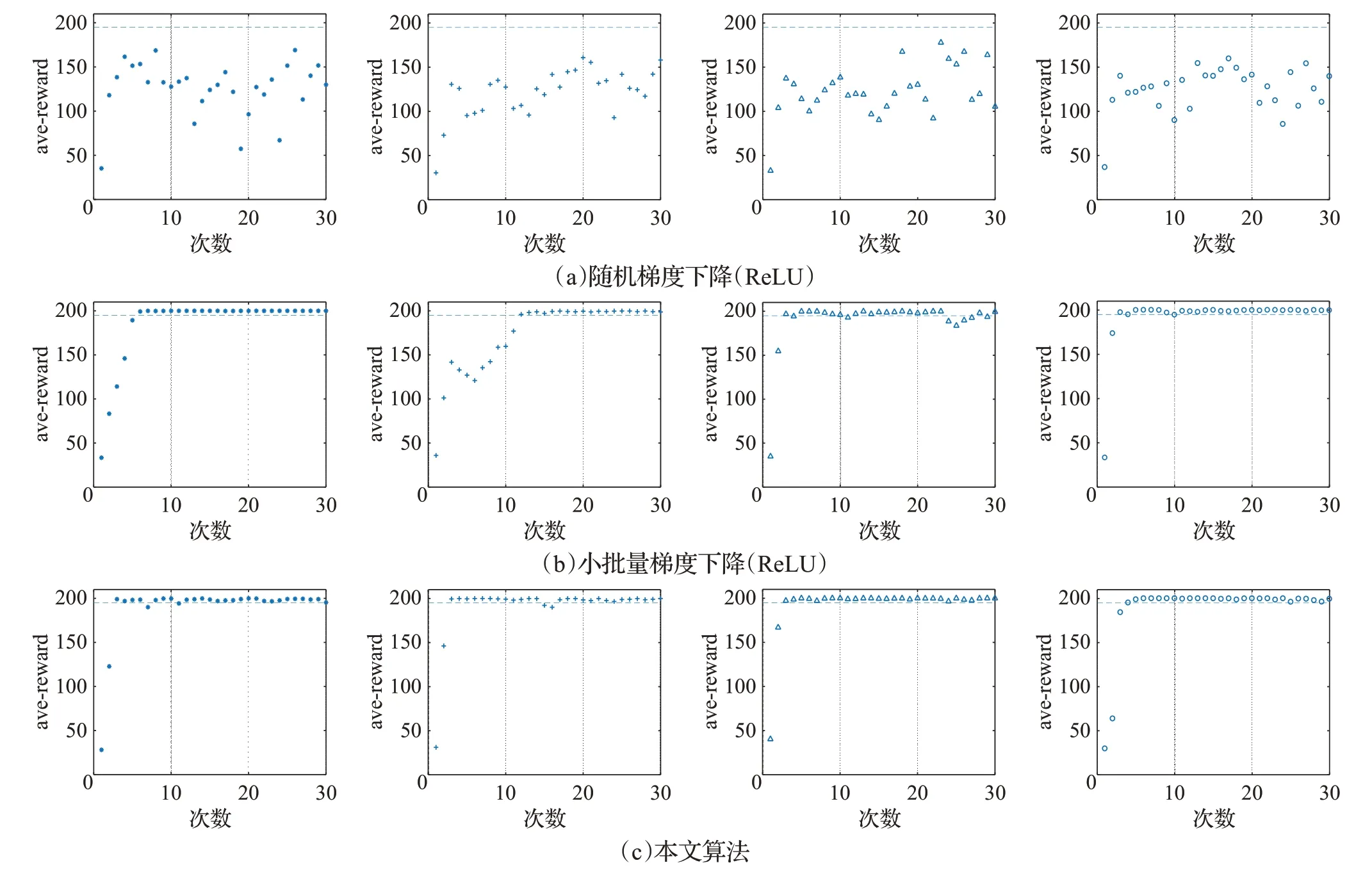
圖6 CartPole任務平均得分
5 結論與展望
本文針對具有連續(xù)狀態(tài)空間的強化學習問題,提出了一種基于殘差梯度法的神經網絡Q 學習算法。首先利用多層前饋神經網絡實現(xiàn)了Q值函數(shù)的近似表達,然后采用殘差梯度法和經驗回放機制,對神經網絡的權重參數(shù)進行小批量梯度更新,加快了學習速度;動量優(yōu)化的引入,提高了訓練過程的穩(wěn)定性。此外,Softplus函數(shù)代替一般的ReLU 激活函數(shù),避免了ReLU 函數(shù)在負數(shù)區(qū)域值恒為零所導致的某些神經元可能永遠無法被激活,相應的權重參數(shù)可能永遠無法被更新的問題。最后,CartPole 任務的實驗證明,在同等條件下,本文所提算法能夠在更少的訓練次數(shù)下完成任務,并且得分更高,表現(xiàn)更加穩(wěn)定。
然而,神經網絡等非線性函數(shù)逼近缺乏可靠的收斂性保證,且泛化性能較差。接下來需要考慮本文算法在其他控制任務中的表現(xiàn),并進一步提高時效性。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
