用于特定目標情感分析的交互注意力網絡模型
2020-09-15 04:47:46劉國利
計算機工程與應用 2020年18期
韓 虎,劉國利
1.蘭州交通大學 電子與信息工程學院,蘭州 730070
2.甘肅省人工智能與圖形圖像工程研究中心,蘭州 730070
1 引言
特定目標情感分析是情感分析領域中的一項子任務[1]。給定一條評論和評論中出現的目標,特定目標情感分析的目的是確定每個目標的情感極性(如積極、中性或消極)。例如,在評論“The voice quality of this phone is amazing,but the price is ridiculous”中,有兩個目標“voice quality”和“price”,其中目標“voice quality”由兩個詞組成,其所表達的情感極性是積極的,而目標“price”表達的情感則是消極的。Jiang等人對一個Twitter情緒分類器進行了手工評估,結果表明40%情感分析的錯誤是源于沒有考慮句子中的目標信息[2]。因此,特定目標情感分析的任務也可以描述為預測一個“評論-目標”對的情感極性。
近年來,神經網絡在各個研究鄰域取得了顯著的進展。Zhang 等人將海溫預測問題轉化為時間序列回歸問題,首次利用長短時記憶網絡(LSTM)來預測海面溫度[3]。高雅等人通過神經網絡挖掘移動對象軌跡數據中的隱含規律,在原始模型上加入LSTM 進行位置預測[4]。華冰濤等人基于深度學習的優勢構建了用于意圖識別和槽填充的神經網絡模型,較傳統模型獲得較高的性能[5]。王凱等人提出了一種基于長短時記憶網絡的動態圖模型用于異常檢測,提高了網絡入侵事件檢測的準確率[6]。同時,在情感分析鄰域,神經網絡也取得了比傳統方法更好的結果。例如Dong 等人在2014 年提出基于遞歸神經網絡來評估特定目標在上下文詞中的情感傾向[7]。Vo 和Zhang 將整個句子分為三個部分,即,上文、目標和下文,并使用神經池化函數和情感詞典來提取特定目標的特征向量[8]。Tang 等人將句子分為帶目標的上文和帶目標的下文,然后使用兩個長短時記憶(LSTM)網絡分別對這兩部分進行建模,學習針對特定目標的句子表示[9]。為了進一步關注句子中特定目標情感的重要部分,Wang 等人將目標詞嵌入計算平均值后與句子中的每個詞向量表示進行拼接,使用LSTM網絡和注意力機制(attention mechanism)生成最終的情感表示[10]。
雖然這些方法已經意識到特定目標在情感分析中的重要性,但是這些方法存在兩個問題:(1)當目標由多個詞組成時,目標中不同的詞對情感分析的重要性也是不一樣的,以上對目標中所有詞的詞向量求平均的方法會丟失評論中重要的情感信息;(2)以上方法只關注目標對上下文建模的影響。如何利用目標與上下文之間的交互作用,來分別對目標與上下文進行建模,已成為一個新的研究課題。針對以上問題,Ma 等人提出了一個IAN模型,該模型使用兩個LSTM網絡分別對句子和目標短語進行建模,然后利用句子的隱層表示生成目標短語的注意力向量,反之亦然[11]。在文獻[11]的基礎上,本文提出一種交互注意力網絡模型(LT-T-TR)進一步提高目標和上下文的表示。首先,將評論分為三個部分:上文(包含目標)、目標短語、下文(包含目標),其中目標由一個或多個詞組成,然后利用三個Bi-LSTMs 分別對上述三部分進行建模。其次,通過目標與上下文的交互學習,來計算目標與上下文的注意力權重,注意力權重的計算主要包括兩部分:第一部分是目標-上文注意力權重和目標-下文注意權重的計算;第二部分是上文-目標注意力權重和下文-目標注意力權重的計算。計算這兩部分注意力權重之后,得到了目標和左右上下文的最終表示。最后,將三部分最終表示進行拼接,形成最后的分類向量。本文模型較其他模型主要有以下幾點優勢:(1)本文對目標短語和上下文采用相同的方法(Bi-LSTM)進行建模,考慮了目標由多個詞組成的情況。以往模型中只使用目標中所有詞的詞向量平均值來表示目標的方法不能準確區分目標中每個詞的重要性。(2)本文利用交互注意力機制計算目標和上下文的表示。因為目標和上下文的表示是互相影響的,在計算上下文的注意力權重時引入目標短語的表示,可以更好地獲取當前目標所對應的上下文中重要的部分,從而得到更好的上下文表示,提高模型性能,反之亦然。
2 相關工作
2.1 特定目標情感分析
一些早期的工作研究基于規則的目標情感分析模型。比如Nasukawa 等人[12]首先對句子進行依賴分析,然后使用預定義的規則來確定關于特定目標的情感傾向。近年來,許多特定目標情感分析任務中引入了基于神經網絡的方法,并取得了比傳統方法更好的結果。梁斌等人[13]將卷積神經網絡和注意力機制結合用于特定目標情感分析中。Wang 等人[10]在LSTM 的基礎上加入注意力機制,來計算一個注意力向量,提取句子中的不同重要部分,有效識別了句子中不同目標的情感傾向。在此基礎上,Ma 等人[11]使用兩個LSTM 網絡分別對句子和目標進行建模,然后利用句子的隱層表示生成目標短語的注意力向量,反之亦然。因此,模型既能提取句子中的重要部分,又能提取目標中的重要信息。
研究表明,和評論一樣,當目標由多個詞組成時,目標中不同的詞對情感分析的重要性是不一樣的,但是很多研究都忽略了這一情況,只使用目標中所有詞的詞向量平均值來表示目標。此外,目標和上下文的表示是受對方影響的。例如在評論句“I am pleased with the life of battery,but the windows 8 operating system is so bad.”中,對于目標“the life of battery”,上文中的“pleased”比其他詞對目標情感影響較大(比如“bad”),占權重比也大。同樣地,目標中詞“life”和“battery”比詞“the”和“of”的權重大。因此,在文獻[11]的基礎上,本文提出一種交互注意力網絡模型(LT-T-TR)用于特定目標情感分析,進一步提高目標和上下文的表示,解決不同目標在特定上下文時的情感傾向問題。
2.2 長短時記憶網絡
在處理文本這種變長的序列信息時,長短時記憶網絡(Long Short Term Memory,LSTM)可以避免梯度消失或爆炸問題[14],并且能夠解決原始循環神經網絡(RNN)中存在的長期依賴問題[15],從而可以提取文本中重要的情感特征信息。在LSTM的結構中,有三個門單元:輸入門、遺忘門和輸出門,以及一個記憶細胞用來對歷史信息進行存儲和更新。LSTM 中的每個單元可以計算如下:
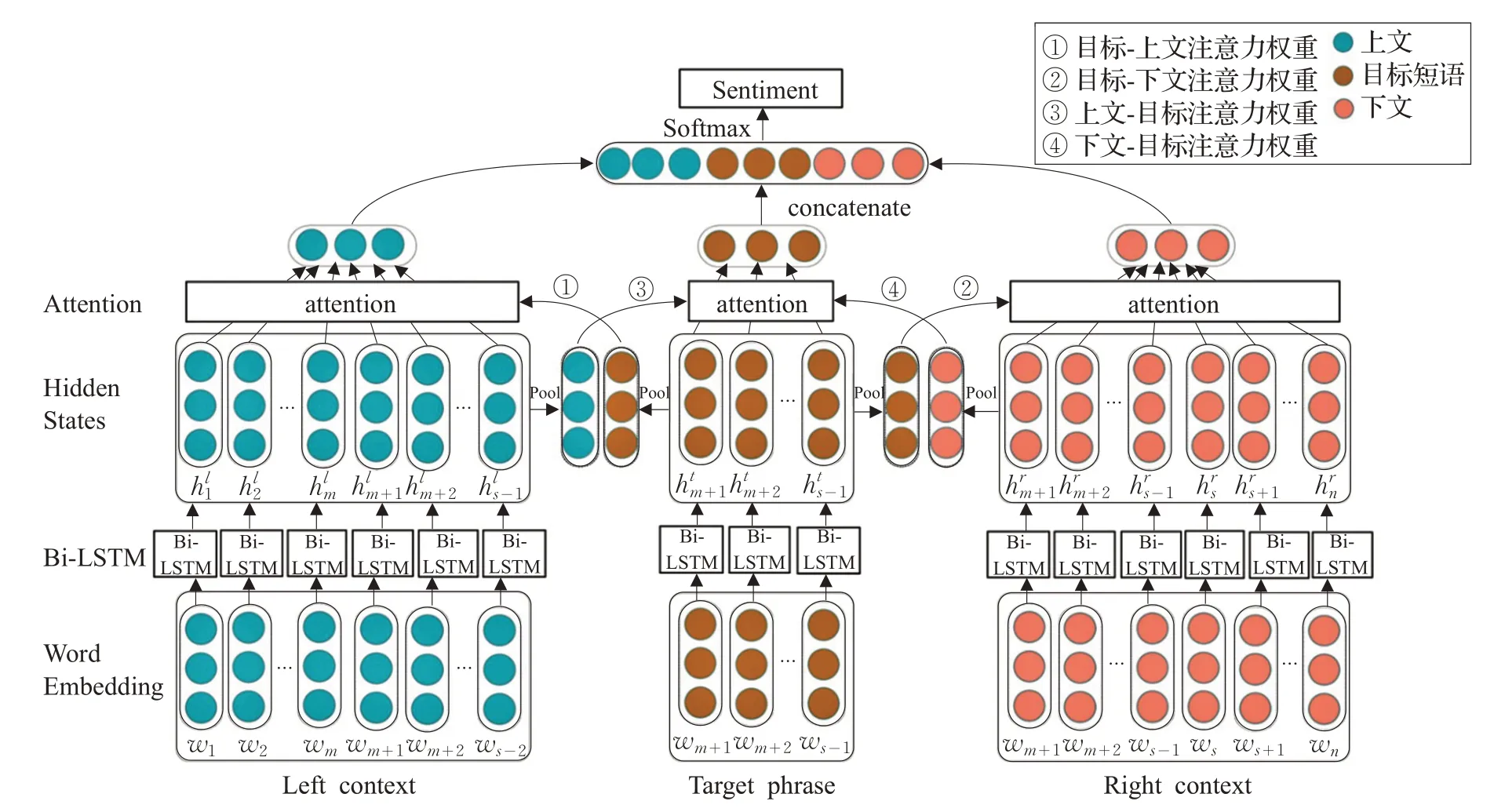
圖1 交互注意力網絡模型
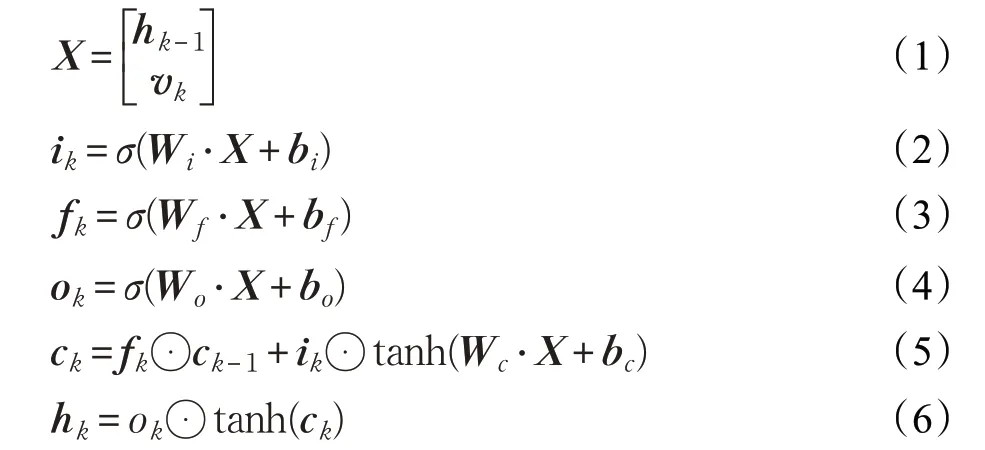
其中σ是sigmoid函數,tanh是雙曲正切函數,W和b分別是權重矩陣和偏置項。vk是LSTM的當前輸入,hk-1是上一時刻的隱層狀態。ik、fk、ok是輸入門、遺忘門和輸出門。
本文在標準LSTM 的基礎上增加反向的LSTM,通過將正向LSTM 和反向LSTM 進行連接,形成雙向的LSTM[16(]Bi-LSTM),來提取上下文中更多的情感特征信息。
3 基于交互注意力網絡的特定目標情感分析模型
本文在文獻[11]的基礎上,提出一種基于Bi-LSTM和注意力機制的交互注意力網絡模型,用于特定目標情感分析,模型結構如圖1所示,主要包括三部分:
(1)詞向量輸入矩陣。輸入矩陣中存儲上文、目標短語和下文中所有詞的詞向量表示。
(2)Bi-LSTM 網絡。對(1)中的三部分輸入進行訓練,提取情感特征信息,輸出上文、目標短語和下文的隱層表示。
(3)交互注意力模型。對于Bi-LSTM 層得到的三部分隱層語義表示,利用注意力機制交互地提取目標短語和上下文中的重要情感信息。
3.1 任務定義
對于長度為n的評論R=[w1,…,wm,wm+1,…,ws-1,ws,…,wn],其中wm+1,wm+2,…,ws-1是評論中的某一個目標,由一個或多個詞組成,w1,w2,…,wm是上文,ws,ws+1,…,wn是下文。如圖2所示,將評論R根據目標在句中的位置進行重新劃分,其中上文組成,目標組成。

圖2 評論劃分方法
特定目標情感分析的目標是確定評論R對于目標T的情感極性。比如在評論“The voice quality of this phone is amazing,but the price is ridiculous”towards target“voice quality”中,目標“voice quality”的情感極性是積極的,而目標“price”所對應的情感則是消極的。
3.2 詞向量表示
給定一條評論R,首先將評論中的每個詞映射到一個低維的實數向量,稱為詞嵌入[17],作為模型的輸入向量。即對每個詞wi∈R,可以得到向量vi∈?d。其中i是單詞索引,d是詞向量的維度。通過詞嵌入操作,分別得到LT、T和RT這三部分的詞向量表示:。
3.3 Bi-LSTM網絡
在得到三部分詞向量表示后,將其同時輸入到三個Bi-LSTM網絡中,學習上下文和目標短語中詞的語義表示。其中每個Bi-LSTM 都是通過連接兩個LSTM 網絡得到的。
對于上文LT,Bi-LSTM 的輸入是詞向量序列[v1l,,可以得到如下的隱層表示:
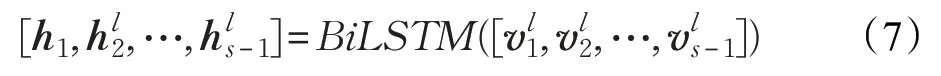
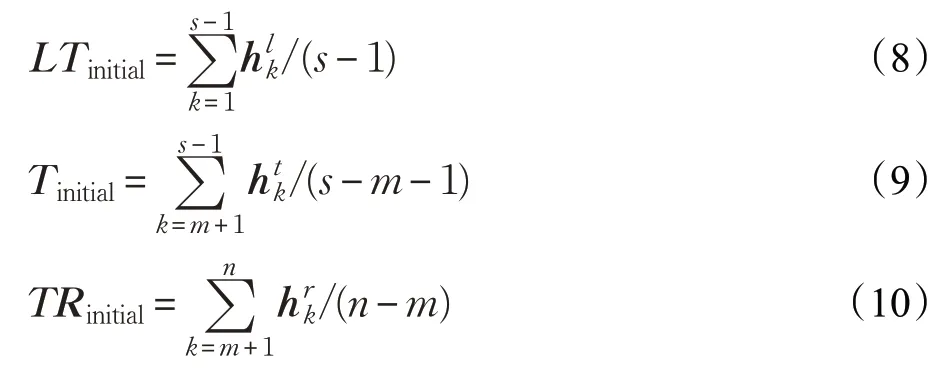
3.4 交互注意力模型
注意力機制(Attention mechanism)可以使模型在訓練時關注到文本中哪些信息是比較重要的,本文使用注意力機制來計算與目標相關的上下文的表示以及與受上下文影響的目標的表示。在得到三個Bi-LSTMs生成的上下文和目標的隱層語義表示之后,將上下文和目標的初始表示LTinitial、Tinitial以及TRinitial作為注意力層的輸入,來交互計算上下文和目標中不同詞的權重大小。
(1)目標-上下文注意力計算


其中,fatt是一個評分函數,用來計算上文中的每個詞受目標的影響程度:
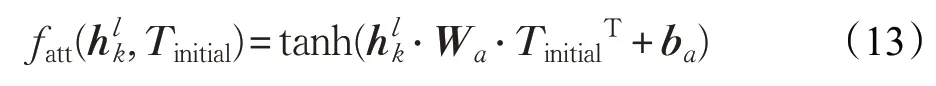
其中,Wa和ba分別是權重矩陣和偏置,tanh 是非線性激活函數,TinitialT是Tinitial的轉置。
(2)上下文-目標注意力計算
首先,通過上文的最初表示LTinitial,得到注意力權重:
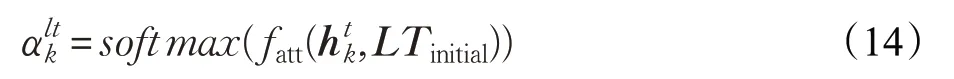
其中,fatt是計算受上文影響的目標中每個詞的重要性的評分函數:
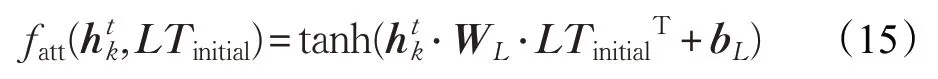
其中,WL是權重矩陣,bL是偏置項。
然后,通過加權求和,可以得到受上文影響的目標表示:

同樣地,按照公式(14)~(16),可以根據下文的初始表示TRinitial和目標的隱層表示得到受下文影響的目標的表示。

3.5 模型訓練
將上文、目標、下文三部分的最終表示LTfinal,Tfinal和TRfinal拼接為一個向量v做為文本最后的分類特征表示:

然后,用一個線性層將文本特征表示轉換為與情感類別向量維度相同的向量,再通過softmax 函數將其轉換為概率表示,取其中概率最大的值作為評論R中目標T的情感極性判斷:

其中,W和b是softmax層的參數。在模型訓練中使用交叉熵損失函數作為模型的優化目標:
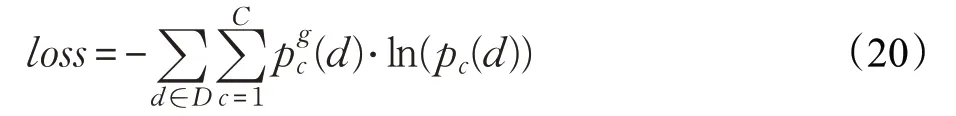
其中,D是所有的訓練數據。pc是模型輸出的預測d的情感極性為c類的概率,是實際的情感類別。
4 實驗
4.1 實驗數據與實驗平臺
本文使用SemEval-2014[18]數據集進行實驗驗證,SemEval-2014 數據集包含 la ptop 和 r estaurant 兩 個 領域的用戶評論,數據樣本的情感極性分為積極、消極和中性三種,數據集具體信息如表1所示。
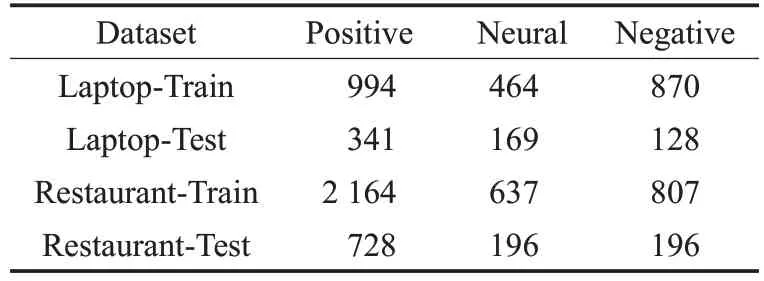
表1 SemEval 2014數據集統計
本文實驗平臺信息如表2所示,實驗基于Google的Tensorflow 深度學習框架,Tensorflow 集成了多種神經網絡模型(卷積神經網絡和LSTM等),并提供CPU/GPU并行計算能力,降低了模型構建代碼的難度,提高了實驗效率。因此,本文雖然利用三個Bi-LSTMs對上文、目標短語和下文進行建模,但運算效率并不低于其他的對比模型。
表2 實驗平臺設置
4.2 實驗參數與評價指標
在實驗中,使用GloVe[19]對上下文和目標短語中所有的詞進行初始化。對于未登錄詞和權重矩陣,使用均勻分布U(-0.1,0.1)對其進行隨機初始化,將所有的偏置初始化為0,將詞向量的維度和LSTM 的隱層數設為300。其他的超參數設置如表3所示。
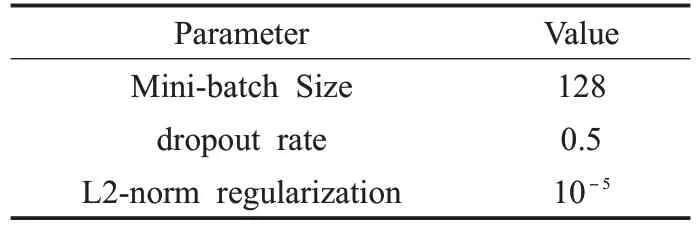
表3 實驗參數設置
采用準確率作為評估本文模型的指標,計算公式如下:

其中,T表示LT-T-TR 模型正確預測評論類別的數量,N是樣本總數。
4.3 對比實驗
將本文提出的方法LT-T-TR 與以下幾種目標情感分析方法進行比較。
(1)Majority:統計訓練集中出現概率最大的標簽值作為所以測試集樣本最終的情感標簽。
(2)LSTM:文獻[6]提出的模型,使用一個單獨的LSTM網絡對評論進行建模,將LSTM的最后一個隱層狀態輸出作為最終分類的評論表示。
(3)TD-LSTM:將一條評論劃分為包含目標的左半部分和包含目標的右半部分,然后使用兩LSTM網絡分別對這兩部分進行建模,學習針對特定目標的句子表示[6]。
(4)AE-LSTM:文獻[7]提出的基于LSTM和注意力機制的分類模型。首先通過LSTM對評論進行建模,然后將目標中所有詞的平均向量和LSTM 的隱層表示進行拼接來計算每個詞的注意力權重,最后以加權求和的方法得到評論的最終表示。
(5)ATAE-LSTM:在AE-LSTM 的基礎上將目標中所有詞的平均向量在輸入層與每個詞向量進行拼接形成新的輸入向量。
(6)IAN:文獻[11]提出的交互注意力模型,使用兩個LSTM對句子和目標短語進行獨立建模,然后利用句子和目標短語的隱層表示生成兩個注意力向量用于最后的分類。
4.4 實驗結果與分析
本文在SemEval-2014 數據集上進行7 組模型的實驗對比,情感分類準確率如表4所示。
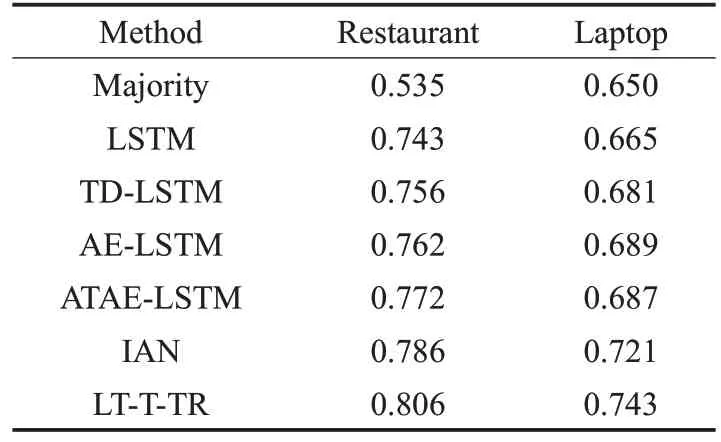
表4 不同模型的實驗準確率
從表4的實驗結果可以看出Majority方法的準確率是最差的,這是因為Majority沒有提取到任何的文本信息,這證明好的文本表示對目標情感分析非常重要。其次在所有基于LSTM的方法中,基礎的LSTM的準確率最差,這是因為LSTM模型將一條評論作為一個整體進行建模,而忽略了句子中不同目標的重要性,從而無法準確判斷句子中不同目標的情感極性。因此在模型中加入了目標信息的情況下,TD-LSTM 在Restaurant 和Laptop 數據集上的準確率較基礎的LSTM 提升了1.3%和1.6%。AE-LSTM和ATAE-LSTM在模型中引入了注意力機制,使得模型在訓練過程中能夠更好地提取句子中與情感分析結果相關的重要信息,準確率有了明顯的提升。然后,與所有基于LSTM 的方法相比,交互模型IAN 在 Restaurant 和 Laptop 數據集上較 ATAE-LSTM 提升了1.4%和3.4%,這是因為IAN 在對整條評論進行建模的同時也考慮了目標中每個詞的重要性,并且加強了目標短語和評論之間的交互學習。最后,LT-T-TR模型的性能明顯優于IAN 和其他所有模型。這更加強了之前的假設,即能夠交互式地捕獲目標和上下文之間依賴關系的模型可以更好地預測文本信息的情感傾向,取得更好的分類效果。
為了進一步驗證本文模型的有效性,選擇不同的序列模型,包括RNN、LSTM 和GRU,分析其對實驗結果的影響。表5為不同序列模型在Restaurant和Laptop評論數據集上的準確率對比結果。可以看出,GRU 的性能優于LSTM,而LSTM在精度指標上又優于RNN。這是因為GRU 和LSTM 具有更復雜的隱層單元,比RNN具有更好的組合能力。而與LSTM相比,GRU需要訓練的參數更少,因此可以比LSTM更好地進行泛化。然后與GRU和LSTM相比,Bi-LSTM的性能稍好一些,因為Bi-LSTM較LSTM和GRU能夠捕獲更多的上下文情感信息。
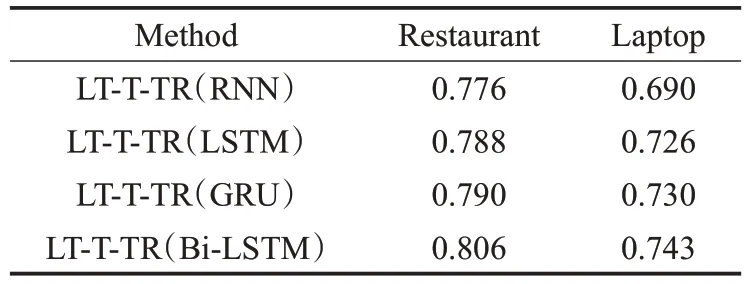
表5 不同序列模型的分類準確率
為了驗證目標短語和左右上下文之間的劃分方法以及交互注意力建模對實驗結果的影響,設計下面的對比模型來驗證LT-T-TR模型的有效性。首先,將評論作為一個整體而不是分為三個部分輸入到Bi-LSTM中進行建模,然后使用注意機制計算每個詞對最終情感類別的貢獻度。這個模型稱為No Separation 模型。其次,簡化LT-T-TR模型,即使用目標短語的詞向量的平均值作為目標短語的整體表示,而不是輸入到Bi-LSTM 中進行獨立學習(No Target-Learned模型)。進一步,比較目標和左右上下文之間的交互注意力建模對實驗結果的影響。首先,通過去除目標與左右上下文之間的注意力交互,建立了一個沒有注意力交互的模型(No Interaction模型),只學習目標和上下文他們自身的Bi-LSTM隱層輸出下的注意力權重表示。然后,考慮了Target2Context 模型,它基于文獻[11]中Ma 等人的設計思想。最后,通過將評論內容劃分為不包含目標的上文、目標和不包含目標的下文三部分,建立L-T-R 模型,使用與LT-T-TR模型相同的方法建模。
各個模型的實驗對比結果如表6 所示。可以看到No Separation模型的實驗結果最差,No Target-Learned模型的實驗準確率也低于No Interaction 模型和Target2Context模型,這驗證了目標短語獨立建模對情感極性判斷的重要性。同時LT-T-TR模型和L-T-R模型優于Target2Context 模型,這表明目標短語和左右上下文之間的交互對于判斷特定目標的情感極性是至關重要的。而L-T-R 模型的結果略差于LT-T-TR 模型,是因為目標短語不包含在上下文中,所以提取的情感信息比LT-T-TR模型要少。
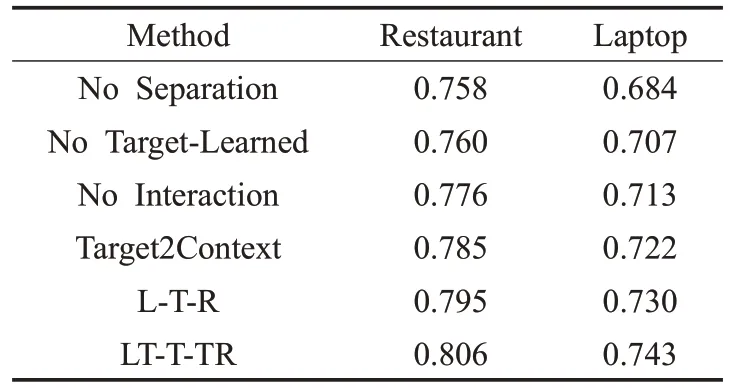
表6 LT-T-TR模型分析結果
為了進一步分析注意力層的權重計算對目標和上下文表示的作用,設計下面的對比模型來驗證LT-T-TR模型中注意力層的有效性。首先刪除LT-T-TR模型中上文對應的Attention計算層,建立No-Left-Attention模型。然后以同樣的方式刪除下文和目標短語的Attention計算層,建立No-Right-Attention 模型和No-Target-Attention模型,最后將上下文中的Attention 計算層同時去除,建立No-Attention模型。三種模型中對于刪掉Attention計算層的上/下文,直接以BI-LSTM 的隱層輸出的平均值來表示。實驗結果如表7所示。
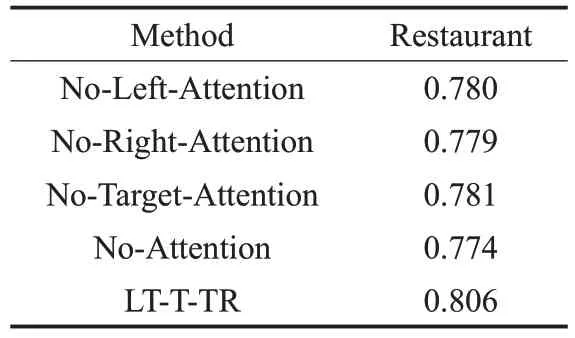
表7 實驗結果
從表7 可以看到,No-Attention 模型的實驗準確度最低,這是因為上下文和目標短語中不同的詞對分類結果的重要性不一樣,而注意力機制可以通過給上下文和目標短語中不同的詞分配不同大小的權重,對重要的詞進行突出表示,所以刪除了所有注意力層的No-Attention模型結果最差,其次是No-Left-Attention、No-Right-Attention和No-Target-Attention。
5 結束語
針對傳統基于LSTM 的方法沒有充分考慮到目標短語的獨立建模問題以及目標短語與上下文之間存在相互影響的關系,提出了一個交互注意力網絡模型用于特定目標情感分析。LT-T-TR 模型利用Bi-LSTM 和注意機制交互學習目標短語和上下文中的重要部分,生成最終的評論表示。在SemEval 2014數據集上的對比實驗也表明,LT-T-TR 模型較傳統的LSTM 方法有明顯的提高,具有更好的性能。通過不同的序列模型和池化方法進行分析,實驗結果表明不同的序列模型可以在上下文和目標短語中有區別地學習重要的部分,此外,結合平均池化和最大池化方法可以取得最佳準確率。最后從句子劃分和注意力交互兩方面出發,設計了不同的對比模型,也驗證了LT-T-TR 模型的有效性。同樣,由于實驗訓練樣本較少,實驗過程也會出現過擬合、分類錯誤等問題,之后會針對該問題繼續改進。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中國生殖健康(2018年5期)2018-11-06 07:15:40
光學精密工程(2016年6期)2016-11-07 09:07:19
