場景文字識別技術研究綜述
2020-09-15 04:47:26王德青吾守爾斯拉木許苗苗
計算機工程與應用 2020年18期
王德青,吾守爾·斯拉木,許苗苗
1.新疆大學 信息科學與工程學院,烏魯木齊 830046
2.新疆大學 新疆多語種信息技術重點實驗室,烏魯木齊 830046
1 引言
文字作為人類文明的標志,是記錄思想、文化和歷史的載體,是信息交流的途徑,也是人類感知世界的重要手段。文字是不同于普通視覺元素的信息來源,可以和其他視覺元素信息形成互補。文字中包含的高層語義,使得場景信息可以被高效地利用,這對理解圖像具有非凡的學術意義。自然場景中的圖像通常包含豐富的文字信息,對分析和理解場景圖像的內容有著重要作用。當前,隨著互聯網的快速發展,越來越多的領域需要利用圖像中的文字信息[1]。
光學字符識別(Optical Character Recognition,OCR)[2]技術是指運用電子設備對圖像中的文字進行檢測,然后識別出圖像中的文字內容。場景文字識別(Scene Text Recognition,STR)[3]是在自然場景中圖像分辨率低、背景復雜、字體多樣等情況下,將圖像信息轉化為文字序列的過程。當前,很多人定義OCR 技術不僅包括傳統意義上對簡單二值圖像中的的文字識別,還包括復雜的自然場景圖像中的文字檢測和識別。近年來,OCR 技術的應用使得人們工作與生活的效率大幅提升,OCR技術也是當前計算機視覺領域的熱點研究方向。近年來,圖像里的文本檢測與識別技術發展迅速,但是由于受到識別文本的語種、數據集的大小及公開時間等限制,場景圖像文字檢測識別技術目前尚不能滿足實際應用中的需求,為此該技術的應用前景非常廣闊。
目前,隨著人工智能的飛速發展以及英文和中文的廣泛使用,研究圖像里的中英文文字識別在機器翻譯、圖像視頻文本識別、文檔識別等領域具有極其重要的意義。同樣,維吾爾文在一帶一路的沿線省份新疆,使用非常廣泛,研究圖像中的維吾爾語檢測及識別對于智慧城市建設、文化遺產保護、網絡輿情監控等意義重大。目前,OCR 技術主要應用于卡證識別、票據表單識別、圖像文字識別、遙感圖像識別、無人駕駛、圖像檢索等。
傳統的光學字符識別與場景文字識別不同,傳統光學字符識別主要用于文檔中的圖像識別,文檔的背景顏色比較單一[4]、分辨率高。然而在自然場景中,圖像里的文字會受到光照、復雜背景、對比度低、遮擋等因素的影響,因此會存在圖像中的文字大小、角度、位置變化、分辨率不同等問題。為了提高文字的識別效果需要對圖像進行預處理,預處理過程包括:彩色圖像灰度化、二值化處理、噪聲去除、圖像變化角度檢測、文字幾何矯正[5]等。
2 場景文字識別預處理技術及流程
場景文字識別預處理技術包括圖像分割、圖像二值化、圖像去噪、檢測技術、矯正技術等。
(1)檢測技術
由于自然場景中的圖像背景復雜使得圖像存在幾何變形,圖像的畸變對文字識別的效果影響較大,因此對圖像的檢測是十分重要的。直線檢測常用的方法[6]可分為兩類[7]:全局Hough 變換法和局部感知組合法。文本圖像的傾斜檢測方法有[8]:投影圖傾斜檢測方法、基于Hough 變換的傾斜檢測方法、交叉相關性傾斜檢測方法、基于Fourier變換的傾斜檢測方法和K-最近鄰簇傾斜檢測方法等。
(2)矯正技術
在圖像中的字體可能會變形,以維吾爾文為例,維吾爾文共有32 個字母,其中元音有8 個,輔音有24 個,每個字母有2至8種寫法,共有126種形式[9]。維吾爾語的結構屬粘連語類型[10],為了更好地矯正要先確定其基線,矯正是為了得到標準化的數據,常用的數據矯正方法包括[11]:(1)基線提取和彎曲矯正。由于一些字符存在彎曲且另一些字符在識別時是通過其相對于基線的位置來確定的,所以要確定基線的位置。基線提取的主要方法有:行間互相關[12]、最近鄰域聚類等。(2)傾斜矯正比較常用的算法有[13-14]:豎直筆畫、投影圖方法。(3)字號矯正。將字體大小處理為一致的大小,而且能夠將字號進行估計[15]。(4)圖像輪廓平滑處理。圖像的平滑(濾波)是為了抑制圖像的噪聲,減少文字表示的采樣點數量,提高有效性。
(3)傳統光學字符識別流程
傳統的光學字符識別過程為[16]:圖像預處理(彩色圖像灰度化、二值化處理、圖像變化角度檢測、矯正處理等)、版面劃分(直線檢測、傾斜檢測)、字符定位切分、字符識別、版面恢復、后處理、校對等。流程圖如圖1所示。

圖1 傳統字符識別流程圖
(4)深度學習場景文字檢測與識別流程
深度學習場景圖像文字檢測與識別流程包括:輸入圖像、深度學習文字區域檢測、預處理、特征提取、深度學習識別器、深度學習后處理等。流程圖如圖2所示。

圖2 基于深度學習的OCR流程圖
3 基于深度學習的自然場景文字檢測與識別技術
3.1 基于深度學習的通用檢測網絡
場景文字檢測與識別算法的特征提取模塊的網絡通常來源于通用檢測網絡,部分目標檢測算法可直接用于場景文字檢測。本節介紹幾種常用的通用檢測網絡。
(1)RCNN網絡
RCNN[17]網絡是首次將卷積神經網絡應用于目標檢測領域的算法。該網絡利用CNN[18]進行特征提取,通過候選區域方法實現目標檢測問題的轉化。但是RCNN網絡提取候選框是通過速度較慢的selective search[17]算法且重復卷積網絡計算,所以該算法存在內存占用量大、運行速度慢、訓練需要多階段、不能實時更新等缺點。其結構如圖3所示。

圖3 RCNN網絡圖
(2)Faster R-CNN網絡
Faster R-CNN[19]網絡將獲取特征圖、候選區域選取、回歸和分類等操作全部融合在一個深層網絡當中,實現了端到端檢測。該網絡引入RPN[19]網絡,利用CNN卷積操作后的特征圖生成候選區域,訓練時RPN 與檢測網絡Fast R-CNN[20]共享卷積層,大幅提高網絡的檢測速度和精度。但是該算法因為主干網絡較為復雜所以產生目標候選框時需要較多時間,運行速度慢不能滿足實時性要求。其結構如圖4所示。
(3)YOLO網絡
YOLO[21]網絡是一個端到端網絡,可以從原始圖像的輸入直接得到物體位置和類別。該網絡將物體檢測看為回歸問題,輸入圖像經過一次推理,就能得到圖像中所有物體的位置和其所屬類別及相應的置信概率。但是該網絡的局限性在于:(1)位置的準確性差,對小目標和密集物體的檢測效果不好。(2)輸入尺寸固定,輸出層為全連接層,在檢測時,只支持與訓練圖像相同的分辨率輸入。(3)沒有region proposal 階段,召回率較低。其結構如圖5所示。

圖4 Faster R-CNN網絡圖

圖5 YOLO網絡圖
(4)RetinaNet網絡
RetinaNet[22]網絡使用新的損失函數focal loss,有效解決了one stage目標檢測過程中正負樣本比例不平衡問題。該網絡實現目標檢測的過程為:首先用殘差網絡ResNet[23]進行特征提取,其次用特征金字塔網絡FPN[24]生成多尺度特征圖,然后用全卷積分類子網絡進行目標分類,最后用回歸網絡對目標進行定位。由于該網絡是基于anchor-based的檢測方法所以存在兩個問題:(1)啟發式引導特征選擇。(2)基于重疊的anchor 采樣。其結構如圖6所示。
(5)FSAF網絡
FSAF[25]網絡使用無anchor 特征選擇模塊,有效解決了啟發式引導特征選擇和基于重疊的anchor 采樣問題,提升了檢測的準確率和速度。實驗結果表明FSAF網絡可以更好地發現具有挑戰性的目標;具有較好的魯棒性和高效性。但是該網絡是基于anchor-point 的方法,所以存在注意力偏差(attention bias)和特征選擇(feature selection)等問題。其網絡結構圖如圖7所示。

圖6 RetinaNet網絡圖

圖7 FSAF網絡圖
由表1可以看出:RCNN網絡將CNN方法應用到目標檢測問題上,檢測精度較傳統方法大幅提升;Faster R-CNN 網絡用RPN 網絡提取候選區域,有效解決了利用SelectiveSearch算法選取候選框時運行速度慢的問題但是該網絡的速度不能滿足實時性要求;YOLOV1網絡采用單獨的CNN 模型實現端到端的目標檢測,相比于基于候選區域的Two-stage 類算法速度有較大提升,但沒有解決Two-stage 類算法的準確率不高的問題;RetinaNet 網絡提出了新的損失函數Focal Loss 解決了正負樣本的比例不平衡問題,但是網絡存在啟發式引導特征選擇和基于重疊的anchor 采樣問題;FSAF 網絡使用無anchor 特征選擇模塊,雖然解決了上述問題,但是引入了注意力偏差和特征選擇問題。
3.2 基于深度學習的場景文字檢測技術
文本檢測與目標檢測不同,文本是序列,目標檢測是一個目標。在目標檢測中,每個目標都有定義好的邊界框,檢測到的邊界框與目標的實際邊界框的重疊率大于某個值則說明檢測結果正確。文本行是由一些獨立的字符組成,檢測時需要更準確的定位。所以目標檢測算法不適用于場景文本檢測。
自然場景圖像背景復雜,文字的位置、顏色、大小等沒有規律地變化,有時是多語言的,這些因素使得自然場景圖片中的文字檢測非常麻煩,而機器學習算法在解決自然場景圖片的文字檢測常常有不錯的結果。本節主要介紹基于維吾爾文和中英文的圖像文字檢測技術。
傳統的方法如李凱等[27]提出的基于邊緣和基線的檢測方法、依再提古麗等[28]提出基于角點密集度的定位方法、姜志威等[29]提出共享維吾爾語之間的字符結構信息等方法對于維吾爾文的檢測效果并不理想,隨著人工智能的快速發展,基于深度學習的方法在自然場景下維吾爾文的檢測中應用較多,實驗證明其檢測效率高、檢測的準確率較好。常用的基于深度學習的維吾爾文場景文字檢測技術有:基于深度學習的自然場景中維吾爾文檢測[30]、基于改進YOLOV3的維吾爾文檢測[31]等。
(1)基于深度學習的自然場景中維吾爾文檢測
彭勇[30]提出基于深度學習的維吾爾文檢測網絡。該網絡利用改進的單深層神經網絡進行特征提取,然后將提取的特征輸入文本檢測組件,最后進行定位。該算法仍然存在一些問題有待解決:(1)由于文字多方向,使用矩形邊框檢測時準確率較差。(2)本網絡只對深度學習網絡進行了改進,未將傳統維語特征加入。(3)可將圖像分割技術應用于自然場景維文檢測。其網絡結構如圖8所示。
(2)自然場景中維吾爾文檢測系統的設計與實現
李路晶一[31]提出改進YOLOV3[32]網絡的維吾爾文檢測方法。該網絡對YOLO V3進行改進,將Darknet-53中的Res block替換為密集型的Dense block[33]。并且在該網絡中引進dilated卷積,利用Trident Net[34]結構替換FPN。同時將深度可分離卷積(Depthwise Separable Convolution[35])和 MobileNet V2[36]進行結合,構造了一個輕量級的網絡。BN 層與Depthwise Separable Convolution 進行融合,提高了運行速度。但是該網絡仍存在以下問題:(1)針對維吾爾語的默認框的生成較為粗糙。(2)缺乏語義分割使得檢測精度不高。其流程圖如圖9所示。

表1 通用檢測網絡對比

圖9 維吾爾文檢測流程圖
常用的基于深度學習的中英文的場景文字檢測方法有:CTPN[37]網絡、EAST[38]網絡、WordSup[39]網絡、基于自適應文本區域表示的任意形狀場景文本檢測[40]網絡、可微二值化實時場景文本檢測[41]等。
(3)CTPN網絡
CTPN[37]網絡本質是全卷積網絡FCN[42],可以輸入任意大小的圖像。該網絡提出了垂直錨點機制,聯合預測每個固定寬度proposal 的位置和文本、非文本的分數,引入RNN連接文本proposal;將CNN[18]與LSTM[43]結合,能夠應用于復雜場景中的文字檢測。但是該算法只能檢測水平方向的文本,對多方向的文本行處理有待改善;由于涉及到anchor 合并,合并與斷開的時間有待確定。其結構如圖10所示。
(4)EAST網絡
EAST[38]網絡是一個端到端的文本檢測網絡。該網絡利用全卷積網絡(FCN[42])和非極大值抑制(NMS[44])消除中間過程冗余,有效減少了檢測時間,可以檢測單詞級別或文本行級別的文本,檢測的形狀可以為任意形狀的四邊形。但是該網絡也有很大的局限性:(1)由于該網絡處理的文本實例的大小與網絡的感受野成正比所以導致該網絡預測長文本區域受到限制。(2)由于該算法的訓練集中只有少量的垂直文本的圖片,所以在對于垂直文本實例的預測會遺漏。(3)樣本的權重設置不合理。其結構如圖11所示。

圖10 CTPN網絡圖
(5)WordSup網絡
WordSup[39]網絡主要應用于不規則形變文本行識別、數學公式圖文識別等。該網絡通過弱監督的訓練框架,在文本行和單詞級標注的數據集上訓練出字符級的檢測模型。網絡可分為兩大部分,字符檢測(character detector)部分,得到的是字符對應的坐標;文本結構分析(Text structure analysis)部分,得到的是詞的坐標(如果為詞)。該算法的缺點在于它的字符級標注是矩形的anchor,當圖像存在透視畸變時,矩形框不能較好地描述該字符。同時用了合成數據集(有準確的字符級標注)以及從單詞級標注的數據集評估得到的字符級標注數據集(字符級標注不一定準確)。其結構如圖12所示。
(6)基于自適應文本區域表示的任意形狀場景文本檢測
為了解決檢測彎曲文本的問題,王小兵等人[40]提出了基于自適應文本區域表示的循環神經網絡。該網絡使用不同的點的數量的自適應文本區域來表示不同形狀的文本;同時用RNN[45]來學習每個文本區域的自適應表示,有效地避免了逐像素分割,大幅提升了運行速度。該網絡可以檢測水平場景文本、定向場景文本、任意形狀的場景文本。但是該算法仍然可以改善:(1)該算法的訓練樣本為單詞級別或句子級別標注,可以通過使用角點檢測來改善任意形狀場景文本檢測。(2)該網絡為非端到端網絡,可以優化網絡結構實現任意形狀場景文本的端到端識別。結構如圖13所示。
(7)可微二值化實時場景文本檢測

圖11 EAST網絡圖

圖12 WordSup網絡圖

圖13 自適應文本區域表示的任意形狀場景文本檢測網絡圖
廖明輝等人[41]提出可微分模塊DB。該網絡將分割算法與DB模塊結合形成了一個快速且魯棒的文本檢測器。該網絡中的DB模塊產生適應的閾值使得網絡運算速度加快,該模塊能夠生成更加魯棒的分割二值圖;在推理階段可將該模塊去除,有效減少了運行時間與資源消耗,該模塊在輕量級的主干網絡(ResNet-18[23])也具有很好的性能。但是該網絡不是端到端檢測框架。其結構如圖14所示。
介紹了部分常用的場景文本檢測網絡。由表2 可以看出:彭勇使用改進的單深層神經網絡算法進行維文檢測雖然檢測準確率有一定提升但是使用矩形邊框檢測時準確率較差;李路晶一提出改進YOLOV3 網絡的維吾爾文檢測方法檢測速度較快但缺乏語義分割使得檢測精度不高;可以看出維吾爾文檢測的算法問題較多,由于缺乏公開數據集所以目前尚沒有通用的維文檢測網絡。
CTPN網絡結合CNN與LSTM深度網絡,解決了復雜場景中橫向分布的文字檢測問題,但是該網絡只能檢測水平方向文本;EAST 網絡利用全卷積網絡(FCN)和非極大值抑制(NMS)實現端到端文本檢測,但是網絡的樣本的權重設置不合理、感受野較小;WordSup 網絡通過弱監督來訓練出字符級的檢測模型,解決了不規則文本識別、數學公式識別需要的字符級標注問題,但是對畸變圖像的檢測效果差;王小兵等提出了使用不同的點的數量的自適應文本區域來表示不同形狀的文本,解決了用固定點數量的多邊形來表示不同形狀的文本區域不合適的問題;廖明輝等提出可微分模塊DB解決了訓練帶來的梯度不可微問題。
3.3 基于深度學習的圖像文字識別技術
文字識別是將圖片中的文字序列識別的過程。文字識別時輸入的是含有文字的候選框,輸出是該檢測框中的文字序列[46]。由于目前尚無性能較好的維吾爾文識別網絡,本節主要介紹常用的基于中英文的場景文字序列識別算法:CRNN[47]網絡、RARE[48]網絡、FAN[49]網絡、二維視角的場景文本識別[50]網絡、FACLSTM[51]網絡等。
(1)CRNN網絡
CRNN[47]網絡(Convolutional Recurrent Neural Net-work)是一個端到端的識別網絡,包括特征提取、序列分析、序列解碼三個部分。該網絡使用雙向LSTM[43]和CNN 對圖像進行特征提取且將語音識別領域的CTC[52]引入圖像處理不定長序列對齊問題。但是該網絡仍然存在不足:(1)BLSTM和CTC使得網絡結構復雜且計算難度大。(2)因為使用的是序列特征故對于角度很大的值不能識別。該網絡結構如圖15所示。

圖14 可微二值化實時場景文本檢測網絡圖

表2 文本檢測網絡對比

圖15 CRNN網絡圖
(2)RARE網絡
RARE[48]網絡將 TPS[53]和 STN[54]結合使 STN 具有較強的矯正形變能力,可準確地識別透視變換過的文本以及彎曲的文本。該網絡由空間轉換網絡(Spatial Transformer Network,STN)和序列識別網絡(Sequence Recognition Network,SRN)兩個部分組成。STN 將輸入圖片中的文本矯正成水平形,然后SRN 進行文本識別使得該網絡在變形的圖像文本識別中效果較好,可端到端訓練。但是由于該網絡在最后一個全連接層中使用了非線性激活函數tanh,梯度在反向傳播過程中被保留,導致收斂速度較慢。結構如圖16所示。
(3)FAN網絡

圖16 RARE網絡圖
FAN[49]網絡解決了在復雜圖像中不能得到特征區域和目標字符偏離的問題。該網絡的AN(Attention Network)模塊主要計算對齊因子使注意力區域與對應的真值標簽對齊;FN(Focusing Network)模塊首先檢測注意力網絡的注意力區域與目標字符位置是否對齊,然后自動調整注意力網絡的注意力中心,所以該網絡可以更精確地識別自然場景圖像中的文本。但是該網絡中注意力機制的對齊操作依賴于上一步的解碼信息,如果上一步解碼出錯,則會導致注意力機制的對齊產生錯誤,且此錯誤會累積傳播,在較長的手寫文本上這個問題較為明顯。其結構如圖17所示。
(4)二維視角的場景文本識別
二維視角的場景文本識別(Scene Text Recognitionfrom Two-Dimensional Perspective[50])是一種基于FCN 的文本識別算法。該網絡將不規則文本識別看作圖像分割問題,將文本圖片編碼為二維特征實現不規則文本的識別。首先用Character Attention FCN(CA-FCN)模塊做像素級的分類,再通過字符形成模塊(word formation module)預測整合后輸出字符序列。但是該網絡對于字符的Attention[55]機制需要帶有字符位置的訓練樣本,對于沒有字符級注釋的訓練集該算法會受到限制。其主要結構如圖18所示。
(5)FACLSTM網絡
FACLSTM[51]網絡解決了二維特征圖轉換為一維特征向量時二維圖像的結構信息和像素空間相關性信息被破壞的問題。FACLSTM 網絡是一個典型的編碼-解碼結構,用嵌入Deformable Convolutional Networks[56]的VGG作為主干網絡,其中有兩個解碼分支,一個特征檢測分支,一個檢測字符中心掩碼分支。在序列解碼時,經過ConvLSTM[57]網絡提取特征圖,然后用全連接層將提取的特征圖映射為字符輸出。該算法大幅提高了文本識別的精度。該網絡的缺點是不能進行端到端識別。其結構如圖19所示。
由表3 可以看出:CRNN 網絡將用 BLSTM 和 CTC學習文本圖像中的上下文關系解決了基于圖像的序列識別問題但是由于使用序列特征,對于角度較大的值很難識別;RARE網絡將STN和TPS結合實現了對不規則文本的端到端的識別但是該網絡的收斂速度較慢;FAN網絡提出FN 網絡解決了attention drift 問題;二維視角的場景文本識別網絡提出將文本圖片編碼為二維特征,實現了任意形狀場景文本識別但是該算法的訓練數據需要像素級標注成本較高;FACLSTM網絡將基于CNN的特征提取(encoder)和基于ConvLSTM 的序列識別(decoder)相結合,解決了傳統全連接式LSTM無法充分利用二維文本圖像空間信息的問題。

圖17 FAN網絡圖

圖18 CA-FCN網絡圖

圖19 FACLSTM網絡圖

表3 文本識別網絡對比
3.4 端到端場景文字檢測與識別網絡
(1)STN-OCR網絡
STN-OCR[58]網絡將檢測和識別集成,可以進行端到端的文本識別。該網絡使用半監督的方式進行訓練,無需標注文本位置信息,整個系統可進行端到端訓練,在檢測階段利用空間變換器對輸入圖像進行特征映射,并對該特征映射應用空間變換(傾斜、旋轉等),產生輸出特征映射及采樣網格;在識別階段,將提取的文本圖像送入識別網絡中獲得識別結果。但是該網絡不能完全檢測出圖像中任意位置的文本且算法難以訓練。其結構如圖20所示。
(2)FOTS網絡
FOTS[59]網絡是端到端的快速文本定位網絡。FOTS網絡通過CNN 學習通用特征,并將特征在文本檢測和識別網絡之間共享;引入了RoIRotate 將文本檢測和識別統一為端到端網絡。該網絡的結構可分為四部分:卷積共享、文本檢測分支、RoIRotate 操作、文本識別分支。但是該網絡文本識別分支中使用RNN 關注模塊,導致在順序計算中效率較低,尤其是在預測長文本時,而且只能對常規文本實現檢測。結構如圖21所示。
(3)MORAN網絡
MORAN[60]網絡是為了解決任意形狀的文本識別而提出的。MORAN 分為兩部分:矯正網絡MORN、識別網絡ASRN。該網絡使用了像素級弱監督學習機制,降低了不規則文本的識別難度;訓練過程中無需字符位置或像素級分割的信息,顯著簡化了網絡訓練。但是該網絡仍存在局限性:(1)對于字體變形角度過大的圖片識別效果不好。(2)校正網絡僅能對垂直方向的畸變進行變換,無法處理水平方向畸變。(3)訓練難度大。其結構如圖22所示。
(4)TextDragon網絡
TextDragon[61]網絡可以高效地識別任意形狀的文本,訓練時不需要字符級標注,通過可微分運算符RoISlide 將檢測與識別網絡融合為端到端網絡。但是該網絡使用單詞(行級別)標注進行訓練是基于分段的方法,需要維護復雜的工作流程,不適用于實時應用程序。其結構如圖23所示。
(5)ABCNet網絡

圖20 STN-OCR網絡圖

圖21 FOTS網絡圖
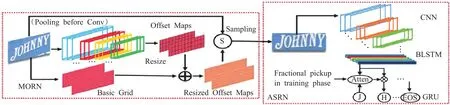
圖22 MORAN網絡圖

圖23 TextDragon網絡圖
ABCNet[62]網絡是一個端到端的場景文本檢測識別網絡。該網絡首次通過參數化的貝塞爾曲線自適應擬合任意形狀文本,其計算成本可忽略;其中的BezierAlign層可以準確地提取卷積特征使得識別精度顯著提高。該網絡由貝塞爾曲線檢測分支、貝塞爾曲線Align 和識別分支兩個部分組成。但是該網絡用合成數據進行訓練在實際較復雜場中的識別效果不好。其結構如圖24所示。
端到端場景文字檢測與識別網絡的目標是為了從圖片中定位和識別出所有文本內容。端到端網絡不僅減少了計算時間和模型大小[63],而且將檢測網絡和識別網絡融合共同訓練使得模型的收斂效果更好,有效地提升了準確率。
由表4可以看出:STN-OCR網絡通過集成空間變換器網絡來實現端到端場景文本識別,解決了文本識別中先檢測后識別的復雜步驟并且以半監督的方式訓練;FOTS 網絡引入了RoIRotate 將文本檢測和識別結合為端到端網絡,有效提高了網絡的識別速度;MORAN 網絡運用矯正子網絡MORN對不規則文本的形狀進行糾正,降低了不規則文本的識別難度但是并未徹底解決不規則文本的識別問題;TextDragon 網絡運用可微運算RoISlide將文本檢測和識別結合成為端到端模型,但是其在ICDAR2015[64]數據集上的效果不是最好,所以并未徹底解文本檢測與識別分開的問題;ABCNet 網絡通過參數化的貝塞爾曲線自適應地處理任意形狀的文本,解決了基于字符的方法和基于分割的方法代價高昂、維護復雜的問題。
4 數據集
隨著文本檢測識別技術的不斷發展,數據集的需求也越來越大。下面介紹幾種公開數據集。目前的數據集分為:規則數據集、不規則數據集、多語言數據集、合成數據集等。其中不規則數據集包括ICDAR2015、SVT-P[65]、CUTE80[66]、Total-Text[67]等;規則數據集包括IIIT5K[68]、SVT[69]、ICDAR2003(IC03)[70]、ICDAR2013(IC13)[71]、COCO-Text[72]、SVHN[73]等;多語言數據集包括RCTW-17[74]、MTWI[75]、CTW[76]、SCUT-CTW1500[77]、LSVT[78]、ArT[79]、ReCTS-25k[80]、MLT[81]等;合成數據集包括Synth90k[82]、SynthText[83]等。
5 場景文字識別技術研究趨勢
由于自然場景中的圖片存在圖像模糊、遮擋、復雜背景干擾,圖片中的文字有變形文字、不規則文本、曲線文本、多種形狀等問題使得場景文字識別技術面臨較多挑戰。近年來場景文字識別技術發展迅速,在ICDAR2015不規則數據集上識別準確率從59.2%提升到83.7%,在具有識別難度的規則數據集SVT 上識別率從80.7%提升到92.7%,但是仍然需要深入研究。

圖24 ABCNet網絡圖

表4 端到端文本識別網絡對比
(1)多語言結合的場景文本識別。我國是一個統一的多民族國家,文字種類豐富,目前的識別網絡主要是基于中文或英文,對于多語言混合的文本的通用識別網絡較少,雖然E2E-MLT[84]網絡實現了多語言的識別但是其F 指數只有48%,難以滿足實際需求,所以多語言混合的文本識別是一個較大的挑戰,也是未來的研究重點。
(2)多行文本、曲形文本端到端識別。由于多行文本和曲形文本的彎曲分布使得很難用普通的文本框去檢測,但目前出現的ABCNet網絡雖然可以對曲線文本進行檢測但是其F指數只有61.9%,所以多行文本、曲形文本的端到端識別仍是很有挑戰性的問題。
(3)實時文字識別。隨著互聯網的迅速發展,網絡安全問題日益突出,文字識別技術是信息過濾的基礎,但是目前識別精度高的算法網絡結構復雜、運行時間長、不能滿足實時過濾的要求,所以如何構建輕量級模型,實現實時文字識別仍有待解決。
(4)無約束場景文字識別網絡魯棒性研究。盡管目前的場景文字識別網絡已經有較好的識別效果,如Luo等[85]在SVT-Perspective數據集上的準確率達到95.5%,Qi等[86]在IIIT5K 數據集的準確率為99.6%。但是對于復雜的情況其魯棒性較差,如小尺寸區域文字識別、噪音嚴重和光照不均勻的圖片文字識別等。
(5)自然場景漢字識別。漢語作為中國通用語言、國際通用語言之一,研究漢字識別意義重大。目前的印刷體漢字識別率已達到98%,可以滿足實際應用需求,但是自然場景中的漢字識別由于存在相似字、背景復雜等問題使得識別效果不理想,故漢字識別將是未來研究的重點。
(6)數據集及字符級標注。目前的識別網絡主要是基于中英文的,主要原因在于其他語言文本公開數據集較少或沒有,如目前尚無公開的維吾爾語數據集,但是可以利用GAN[87]進行數據生成,但該網絡無法直接處理形變文字,所以仍可作為未來的研究重點。
另外目前的公開數據集缺乏字符級標注,但是可以運用弱監督或半監督的方式在單詞級或句子級的數據集上訓練出字符級模型,如WordSup[39]網絡、TextDragon[61]網絡、STN-OCR[58]網絡、MORAN[60]網絡、CharNet[88]網絡、CRAFT[89]網絡等。
WordSup網絡在文本行、單詞級標注數據集上訓練出字符級檢測模型;STN-OCR 網絡訓練時只需要提供文本標簽,而不要求文本位置信息;MORAN 網絡訓練過程中不需要字符位置或像素級分割的監督信息;CharNet網絡開發了迭代字符檢測方法使用合成數據生成真實數據上的字符級標注;TextDragon網絡訓練時使用單詞級別或行級別的標簽;CRAFT 網絡主要通過合成的數據集具有字符級別的標注,檢測合成產生標簽再進行訓練并借助文本行長度確定置信度實現單個字符的標注。
由以上各種網絡的弱監督訓練方式對比可知,未來解決數據集缺乏字符級標注問題的研究重點為:(1)在單詞級標注數據集上訓練出字符級檢測識別模型。(2)使用合成數據生成真實數據上的字符級標注。(3)利用數據集提供的文本內容標簽,無需文本位置信息,實現網絡訓練。
6 結束語
首先說明了場景文字檢測與識別算法的研究背景和識別難點,其次說明了場景文字識別的處理過程,然后介紹了常用的目標檢測方法和文本檢測方法;接著介紹了常見的場景文字識別算法和端到端檢測與識別算法,并對各類算法總結了其優缺點、適用場景、實現成本等;最后介紹了常用的公開數據集,并探討了未來發展趨勢和可能的研究重點。隨著人工智能的快速發展,自然場景圖像中的文字檢測和識別技術在自動駕駛、網絡安全、地理定位、智能交通等領域將會受到越來越多人的青睞,雖然文字識別技術目前仍存在較多問題,但是隨著對文字識別技術的深入研究,以及深度學習技術的進步,未來一定能解決這些問題。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
海峽科技與產業(2016年3期)2016-05-17 04:32:12
小學教學參考(2015年20期)2016-01-15 08:44:38
