不同精度的土壤數據對水質和水量模擬的影響
2020-09-11 05:37:04李影雷秋良秦麗歡朱阿興李曉虹翟麗梅王洪媛武淑霞閆鐵柱李文超胡萬里任天志劉宏斌
中國農業科學 2020年16期
李影,雷秋良,秦麗歡,朱阿興,李曉虹,翟麗梅,王洪媛,武淑霞,閆鐵柱,李文超,胡萬里,任天志,劉宏斌
(1中國農業科學院農業資源與農業區劃研究所/農業農村部面源污染控制重點實驗室,中國北京100081;2中國科學院地理科學與資源研究所,中國北京100101;3南京師范大學/江蘇省地理信息資源開發與利用協同創新中心,中國南京 210023;4Department of Geography, University of Wisconsin-Madison,Madison, WI 53706, USA;5云南省農業科學院農業環境資源研究所,中國昆明 50205;6中國農業科學院,中國北京100081)
0 引言
【研究意義】當前我國水質污染情勢嚴峻,成為制約我國可持續發展的主要因素之一[1-2]。人類的耕作、養殖和生產生活等活動引起的面源污染是造成水質惡化的主要原因[3-5]。由于面源污染的廣泛性、復雜性和空間異質性等特征,基于污染物遷移轉化過程的分布式水文模型逐漸被用于面源污染的研究中,如SWAT(soil & water assessment tool)模型、AnnAGNPS(annualized agricultural non-point source pollution model)模型和 HSPF(hydrological simulation programfortran)模型等[6-8]。此類模型可用于定量化描述人類活動對流域污染物產生和遷移過程的影響[9],為流域的規劃和管理提供決策依據。雖然分布式模型在污染物的空間識別上具有絕對的優勢,但它的復雜性和對數據的強依賴性,使得其在應用過程中具有很大的不確定性。依據來源的不同,可將不確定性劃分為:模型的結構、輸入數據和參數不確定性[10-11]。在眾多的模型中,SWAT模型是采用日尺度作為最低模擬時間尺度的半分布式模型。該模型在我國得到了廣泛的應用且模擬結果都可達到決定系數R2≥0.6,納什系數NS≥0.5的可接受模擬效果[6,12-13]。然而,當前對于SWAT模型在使用過程中的不確定性問題的關注卻遠遠不夠。【前人研究進展】土壤數據作為流域模擬中的重要輸入數據之一,其來源和分辨率的不同會影響地表的產流過程[14],這要歸因于其屬性的空間分布特征對模型坡面產流空間分布的影響[15]。國內外學者研究了土壤數據對環境模型模擬的影響,發現土壤特征差異會放大氣象條件的差異,并顯著影響流域的水文響應,因此強調開發精細土壤數據庫的必要性[16];但也有研究表明,模型的模擬效果與污染物類型有關,對土壤數據的精度不敏感[17];甚至有研究顯示在低分辨率的土壤數據下徑流模擬效果反而略好于高精度數據[18]。此外,土壤數據對模型的影響存在尺度效應,在匯流面積大于10 km2時,基于不同來源土壤數據的模擬結果吻合度較高[19-20]。由于土壤數據的可獲取性,當前對于美國SSURGO和STATSGO兩種土壤圖的研究較多。盡管當前研究表明了不同的土壤圖會對水文響應單元(hydrologic response unit, HRU)劃分、水質水量模擬及相關參數的提取產生影響,但影響程度卻存在差異[21-22],也未明確哪個土壤圖更有優勢[23]。全國第二次土壤普查形成了不同精度的土壤圖,1﹕5萬土壤圖(縣級土壤圖)、1﹕50萬土壤圖(省級土壤圖)和1﹕100萬土壤圖(國家級土壤圖),是目前我國可以獲得的3種類型土壤圖,但鮮有研究分析這3種土壤圖數據對流域模擬的影響。【本研究切入點】綜上所述,應用精細分辨率土壤數據,需要花費更多的精力來收集或生產土壤數據、準備和校準模型,但當前的研究結果對于模型模擬所需土壤圖的最佳分辨率仍然存在爭議。此外,已有研究大多只關注于土壤數據對水量和水文過程模擬的影響,而對于水質的研究仍然較為缺乏。【擬解決的關鍵問題】鑒于此,本文采用當前應用廣泛的SWAT模型,研究不同精度(1﹕5萬、1﹕50萬和1﹕100萬)的土壤數據對HRU劃分、模型參數和水質水量模擬的影響,以期豐富這一領域的建模先驗知識,為流域水質和水量模擬時選取土壤基礎數據提供依據。
1 材料與方法
1.1 研究區概況
鳳羽河流域(99.86°—100.03°E,25.88°—26.10°N)地處云南省大理白族自治州,被稱為“洱海之源”,是洱海的源頭。該流域位于我國西南山區,坡度較大,流域的平均坡度約19°。流域總面積為217 km2,主干河流全長 12.8 km。流域內干濕季明顯,年均氣溫在13.9℃,近5年平均降雨量為1 328 mm(下龍門監測站數據),7、8、9月的降水量占全年降水量的70.72%。該流域包含茈碧湖鎮和鳳羽鎮的9個行政村,總人口約35 400人。流域內經濟主要依靠種植業和養殖業,二者貢獻了總產值的60%以上。其中,種植以水旱輪作和旱旱輪作為主;養殖以散養為主。流域內土地利用現狀為草地(45.93%)、林地(29.59%)、果園(2.26%)、農村居民點(1.41%)和水域(0.03%)。此外,農用地占20.78%,包括旱地(8.89%)和水田(11.89%)(圖 1)。流域內的主要面源污染源為農村生活源、農田種植源和畜禽養殖源[24-25]。
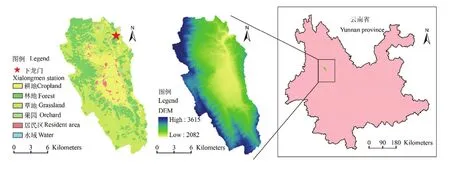
圖1 鳳羽河流域位置圖、數字高程圖、土地利用圖和流域出口監測點Fig.1 Location of Fengyu river watershed in Yunnan province, digital elevation model (DEM), land use and monitoring site
1.2 數據資料
SWAT模型需要的輸入數據主要為空間數據和屬性數據。
1.2.1 空間數據 本文用于構建SWAT模型的空間數據包括:DEM圖、土壤類型圖、土地利用圖和水系圖,柵格大小均為25 m×25 m。數據的詳細信息如表1所示。其中,3種不同比例尺土壤圖的土壤分類情況和實測采樣點位置如圖2所示。對比不同土壤圖可知,隨著比例尺的減小,較小的土壤斑塊被合并,空間數據精細度降低。其中,1﹕5萬的土壤圖土壤分類為 20種、1﹕50萬的土壤圖土壤分類為11種、1﹕100萬的土壤圖土壤分類為8種,3種土壤數據不僅在土壤分類的詳細程度上有差異,同時各類土壤的邊界也有明顯的差別。
1.2.2 屬性數據 模型所需的其他數據主要包括:氣象數據、土壤屬性數據、農田管理措施、農村生活污染及畜禽養殖。這些數據通過實際的站點監測和現場調查獲得,數據的詳細信息如表2所示。
其中,土壤屬性數據的物理屬性數據包括土壤分層、土層結構、含水量、導水率、容重等;化學屬性數據包括土壤中硝態氮、有機氮和無機磷等的含量。這些數據通過挖土壤剖面(每個土壤類型一個剖面),取土壤樣品測試得到(土壤采樣點分布見圖 2),具體測試結果可參考文獻[26],未采集到的土壤類型數據通過土種志獲得。

表1 空間數據的精度和來源Table 1 The resolution and source of spatial data
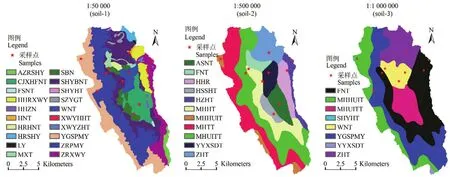
圖2 3種比例尺的土壤圖和采樣點Fig.2 Soil maps of three scales and samples
流域輪作方式主要為玉米-蠶豆和水稻-蠶豆,因此土地利用的屬性數據主要輸入了水稻、玉米和蠶豆的土地覆蓋/植物生長數據庫中的變量,對于其他類型的土地利用采用模型默認值。具體管理措施來自參考文獻[26-27],其中灌溉用水量取自子流域所在的河道。
將流域內農村生活的排放作為點源輸入模型中,通過流域的實地調查和查閱文獻,確定各子流域的人口數量和排污系數。其中流域內人均年總氮(TN)排放量為1.87 kg、總磷(TP)排放量為0.22 kg,流域的入河系數為0.15[25]。
1.2.3 實測數據
(1)水質數據。2011年1月至2013年12月,在鳳羽河小流域出口(下龍門監測站)(圖 1),每天進行一次人工水樣采集,并進行實驗室分析。測試指標包括可溶性總氮、TN、TP和含沙量。水樣采集后在4℃低溫下冷藏保存,之后分別利用過濾烘干法測定含沙量;利用紫外分光光度計比色法測定總氮、溶解性總氮和含量;利用靛酚藍比色法測定含量;利用鉬藍比色法測定溶解性總磷和總磷含量[26-27]。(2)水量數據。2010年6月至2012年6月,在下龍門監測站,使用Stalker II SVR測量流量數據。2012年6月,在下龍門監測站安裝了Waterlog H-3553氣泡水位計并可通過無線傳輸實現水位的遠程自動實時監測。根據在流域出口的實測流量和水位數據建立水位-流量關系曲線Q=(4.09×H-81.54)2.20,H為水位計高度(m),Q為與H匹配的流量(m3·s-1),得到高頻率的實時流量數據。
1.3 研究設計
SWAT模型[28]是一個日時間尺度上的連續模型,可以對流域等大尺度范圍的多種污染物和水文過程進行模擬,具有計算效率高、模擬周期長等特點,已經成為流域水循環、污染源評價和流域管理措施分析的重要工具之一。
本研究利用空間數據、屬性數據及水文、氣象監測數據,結合1﹕5萬、1﹕50萬和1﹕100萬3種不同精度的土壤數據,分析不同的土壤圖精度是否會對SWAT模型的模擬結果產生影響:
(1)水文響應單元(HRU)是SWAT模型進行流域模擬的基本單元,HRU的劃分對于準確的模擬有著至關重要的作用。考慮流域中不同土壤所占比例及土壤類型的面積,設定 0—16%的劃分閾值范圍,子流域中每種土地利用下小于該面積閾值的土壤類型將被忽略。通過不同的閾值設置生成HRU,分析不同閾值下模型劃分HRU數量的差異。通過比較不同精度土壤數據對HRU劃分的影響,可以在一定程度上反映其對SWAT模型模擬的影響。
(2)在流域土地利用類型劃分閾值設置為10%、土壤類型劃分閾值設置為10%和坡度面積的劃分閾值設置為5%的前提下[26],運用3種不同精度的土壤數據進行鳳羽河流域的水文和水質模擬,利用SWAT-CUP軟件進行參數的調整和模擬效果的分析。為避免4個指標率定過程的相互影響,將流量、泥沙、總氮及總磷數據同時進行率定,分別得到1﹕5萬(soil-1)、1﹕50萬(soil-2)和1﹕100萬(soil-3)3種不同精度土壤圖所建SWAT工程對4個模擬指標的最佳綜合模擬效果。
1.4 模型的率定
在模型率定之前進行了參數的敏感性分析。對SWAT輸入輸出文件手冊中列出的水文循環、營養物、泥沙和河道過程相關的103個參數(剔除了已有的土壤參數和 SWAT-CUP中沒有的參數)進行了敏感性分析,利用SWAT-CUP軟件設置運行次數為1 000次。同時參考了文獻[29]中用于徑流和硝態氮率定所選取的 38個參數,以及文獻[26-27]中的參數敏感性分析結果和選定的率定參數,對本文中率定的參數進行了補充,最終選取了與流量、泥沙、總氮和總磷模擬過程關系密切的43個參數,見表3—6。對于模型的率定,采用SWAT-CUP軟件中的 SUFI-2算法進行自動率定,在調整參數過程中不對土壤參數和實測參數進行率定。參照(公式4)將4個因子的整體表現效果設置為目標函數,并對模擬效果進行綜合分析。因此,率定的目的是達到流量、泥沙、總氮和總磷4個項目的綜合效果最優,這樣才能說明模型在流域的應用是最佳狀態。
選取SWAT-CUP中的通用評價指標相關系數R2和納什系數NS進行模擬效果的評價。當相關系數R2≥0.6,且納什系數NS≥0.5時,模型模擬結果是滿意的[30]。R2和NS的計算方法如下所示:
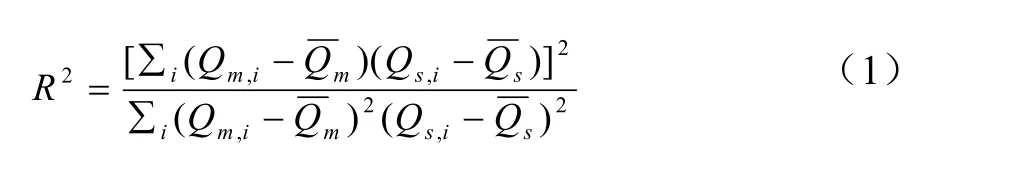
式中,Qm,i為第i天的監測數據,Qs,i為第i天的模擬值,為監測數據平均值,為模擬值平均值。
如果有多個變量,則目標函數為:

w為權重(在本研究將泥沙的權重設為1.5,徑流、總氮和總磷的權重設為1),j為模擬變量。
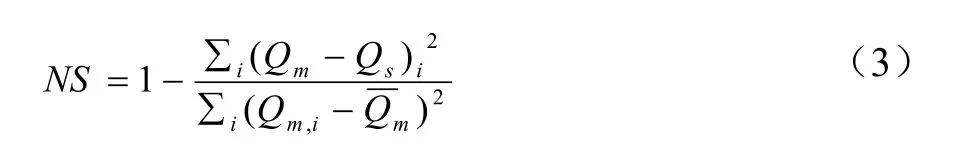
NS為納什系數。如果有多個變量,則目標函數為:

率定過程中選取的率定參數及初始閾值如表 3—6所示,其中R表示在參數調整中作相對初始值變化調整,V表示在參數調整過程中做絕對值變化調整(直接賦新值),率定的實測數據范圍為2011年1月至2013年12月。
2 結果
2.1 不同精度土壤數據對 HRU分配和模型參數的影響
圖3為3種不同精度的土壤圖在不同的土壤閾值設定下生成 HRU的數量。從圖中可以看出,隨著土壤劃分閾值從0—16%逐漸增加,1﹕5萬(soil-1)土壤數據的HRU劃分數量從741減少到382個,1﹕50萬(soil-2)土壤數據HRU的劃分數量從611減少到347個,1﹕100萬(soil-3)土壤數據HRU的劃分數量從487減少到320個。由此可知,不同土壤圖劃分的 HRU數量在閾值較小時存在較大的差別,隨著土壤閾值逐漸增加,3種土壤數據所生成的HRU個數均逐漸減少,且不同土壤數據之間的差別也逐漸減小。此外,隨著精度的降低,HRU隨閾值增加而減少的趨勢逐漸變緩,這說明 HRU的劃分對高分辨率的土壤數據影響更大。土壤數據引起 HRU劃分的差異,會進一步影響 SWAT模型對流域水文過程及污染物遷移過程的模擬。
表7統計了3種土壤數據下所提取的幾個重要模型參數。不同精度的土壤數據下所得到的 CN2、SOL_ZMX和SOL_Z、SOL_BD、SOL_AWC、SOL_K、USLE_K都有所差異。3種土壤圖所得到的CN2分別為77.93、77.43和66.23;得到的SOL_ZMX分別為722.73、879.93和526.07 mm;以第一層土壤為例得到的SOL_Z分別為211.24、160.66和201.79 mm;得到的SOL_BD分別為1.19、1.15和1.27 g·cm-3;得到的SOL_AWC分別為0.16、0.36和0.18 mm·mm-1;得到的SOL_K分別為21.61、42.56和21.18 mm·h-1;得到的USLE_K分別為0.27、0.29和0.24。由此可以看出,對于參數CN2、SOL_ZMX、SOL_BD和USLE_K,soil-2與 soil-1的差異更小;而對于參數 SOL_Z、SOL_AWC和SOL_K,soil-3與soil-1的差異更小。

表3 選取的水文循環參數及其初始閾值Table 3 Hydrologic cycle parameters and their initial ranges

表4 選取的營養物參數及其初始閾值Table 4 Nutrients parameters and their initial ranges
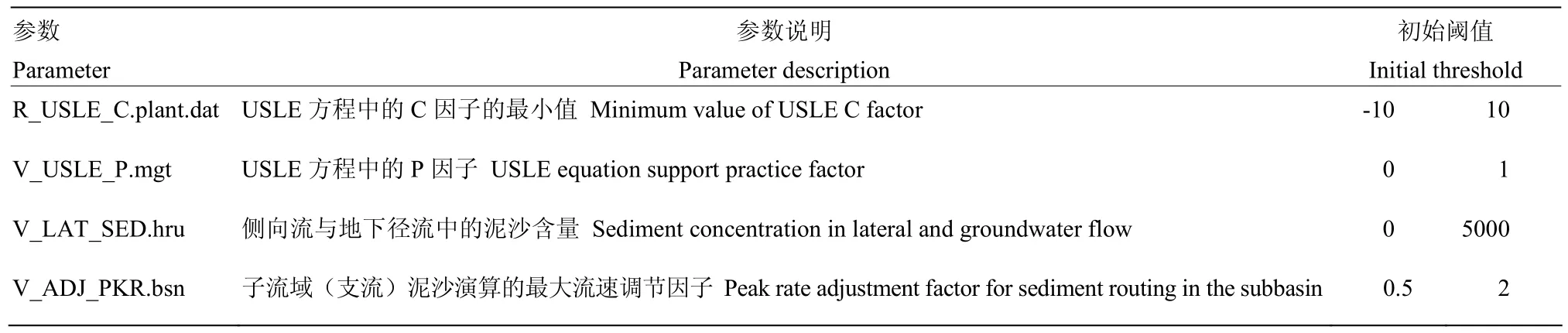
表5 選取的泥沙參數及其初始閾值Table 5 Sediment parameters and their initial ranges

表6 選取的河道過程參數及其初始閾值Table 6 Channel processes parameters and their initial ranges
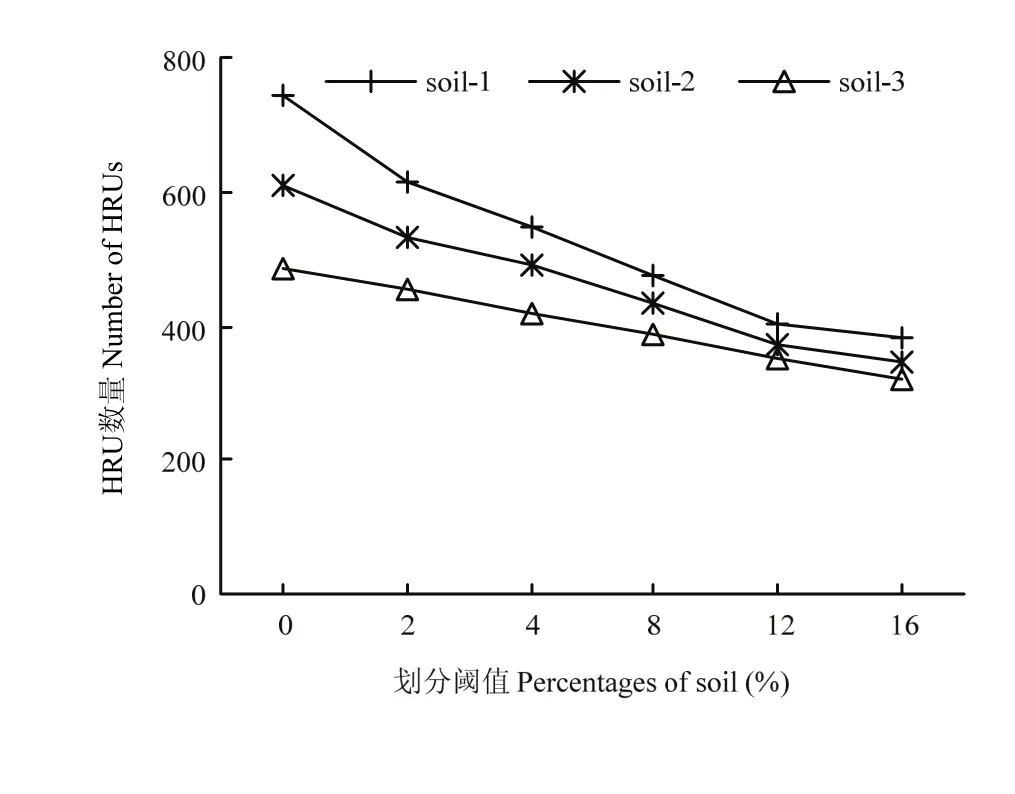
圖3 不同土壤數據的閾值設置對HRU劃分的影響Fig.3 Effects of threshold settings on HRU numbers based on the difference soil datasets
2.2 不同精度土壤數據對模型模擬效果的影響
利用SWAT-CUP軟件分別進行參數的調整和模擬效果的分析,表8為基于3種不同土壤圖的模型在率定前后模型表現效果的評價結果。從表中可以看出,在校準之前,泥沙的模擬效果最好(泥沙的NS值較流量、總氮和總磷高),流量次之,而總氮和總磷的模擬效果最差,并且與實測值相差很大,不可以進行使用。因此在默認參數下,3種土壤數據所建立的模型對于總氮、總磷的模擬是完全不可信的(NS遠遠小于0);經過校準之后模型的表現效果(各評價指標)有顯著的提高,這說明對于模型參數的校準十分必要,模型參數的校準可以大幅度提高模型在流域的模擬效果。通過對模型校準后各評價指標的分析,發現經過校準后徑流的模擬效果最好,而對于泥沙的模擬效果均不太理想(NS<0.5)。

表7 不同土壤數據下的模型參數Table 7 Model parameters from different soil data

表8 校準前后模型的表現效果Table 8 Performance of the models before and after calibration
基于 3種土壤圖進行模型的建立和參數的率定后,模型的表現效果見圖 4。從中可以看出對于流量的模擬存在普遍的高估,R2分別為0.81、0.86和0.75,模擬效果較為接近;模擬的泥沙產量在總量較低時存在高估,在總量較高時出現低估;對于總氮的模擬,基于1﹕50萬和1﹕100萬的土壤圖存在低估現象,而基于1﹕5萬的土壤圖在總量較低時會出現高估現象;對于總磷的模擬,3種土壤數據所建立的SWAT工程在模擬過程中存在普遍的低估現象。因此,不同精度的土壤數據對于不同指標的模擬效果存在差異,并非精度越高模擬效果必然越好。為了評價3種土壤圖對4個指標的綜合表現效果,將3個SWAT工程模擬的4個指標(流量、泥沙、總氮和總磷)的R2和NS進行平均,得到基于1﹕5萬、1﹕50萬和1﹕100萬土壤圖模擬結果的平均R2分別為0.59、0.70和0.67,平均NS分別為0.55、0.64和0.58。因此,從模擬的整體效果來說,基于 1﹕50萬土壤圖的模擬整體效果最好,其次是基于1﹕100萬土壤圖的模擬,而基于1﹕5萬土壤圖的模擬效果反而最差。因此,對于流域出口流量、泥沙、總氮和總磷模擬來說,如果考慮成本和模擬效果,在建立模型的時候并不需要追求過高精度的土壤數據。
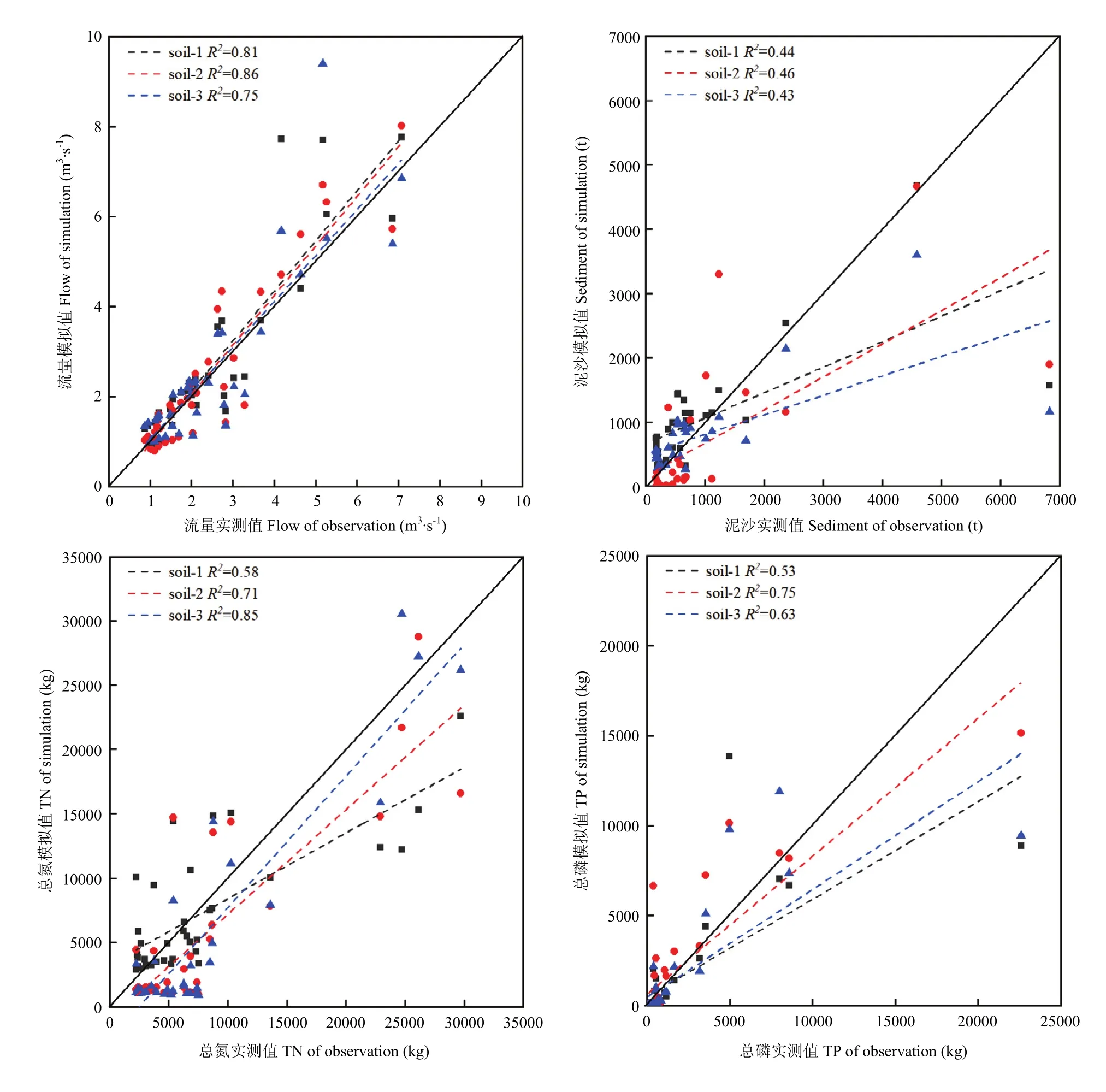
圖4 3種精度土壤數據在進行模型校準后的模擬效果Fig.4 Simulation performance for the three types of soil data after model calibration
2.3 不同精度土壤數據的空間尺度效應
圖5顯示了鳳羽河子流域的劃分結果和水系匯流情況,流域出口位于4號子流域。基于子流域面積和流域的匯流情況進行了不同精度土壤數據的空間尺度效應分析。
以1﹕5萬的土壤數據為標準,以第一層土壤層為例分析了基于不同土壤圖獲得的模型參數隨子流域面積的變化情況,如圖6所示。從圖中可以看出,當子流域面積較小的時候,不同土壤數據計算得到的模型參數之間的差異較大,子流域間參數差異存在較大的變幅;隨著子流域面積的增大,基于不同土壤數據的子流域參數的差別逐漸趨于穩定。說明隨著面積的增大,不同土壤數據得到的土壤平均屬性趨于一致,大的子流域面積可以在一定程度上綜合掉土壤參數的空間異質性。
以 1﹕5萬(soil-1)的土壤數據為標準,對基于不同土壤圖的模擬結果的差異隨匯流面積的變化進行分析,如圖7所示。圖7顯示了在進行模型校準前后soil-2和soil-3與soil-1結果的差異。從圖中可以看出,在校準之前,當子流域面積較小的時候,不同精度的土壤數據模擬結果的差異在不同子流域之間差別較大,隨著子流域面積的增大,基于不同土壤數據模擬結果的差別逐漸變小,并且逐漸趨于穩定;校準后,soil-2和soil-3的模擬結果與soil-1相比,在匯流面積較小時差異很大,在流域出口差異收斂于 0,也就是說對于不同精度的土壤數據來說,模型的校準增加了較小匯流面積時的模擬差異,但隨著匯流面積的增加,差異迅速減小并趨于穩定,收斂于 0。這說明校準過程會在較小的匯流面積上產生較大的影響。
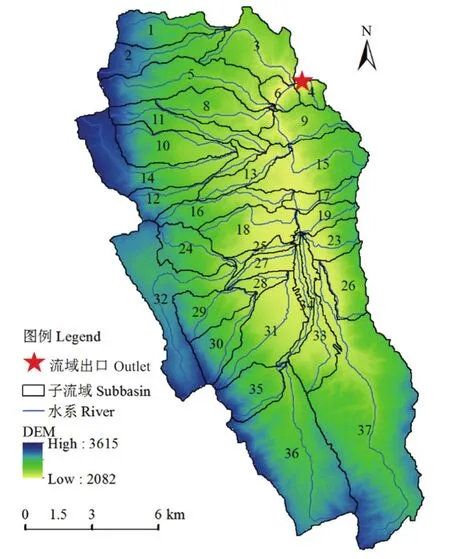
圖5 子流域劃分圖Fig.5 Subbasin map
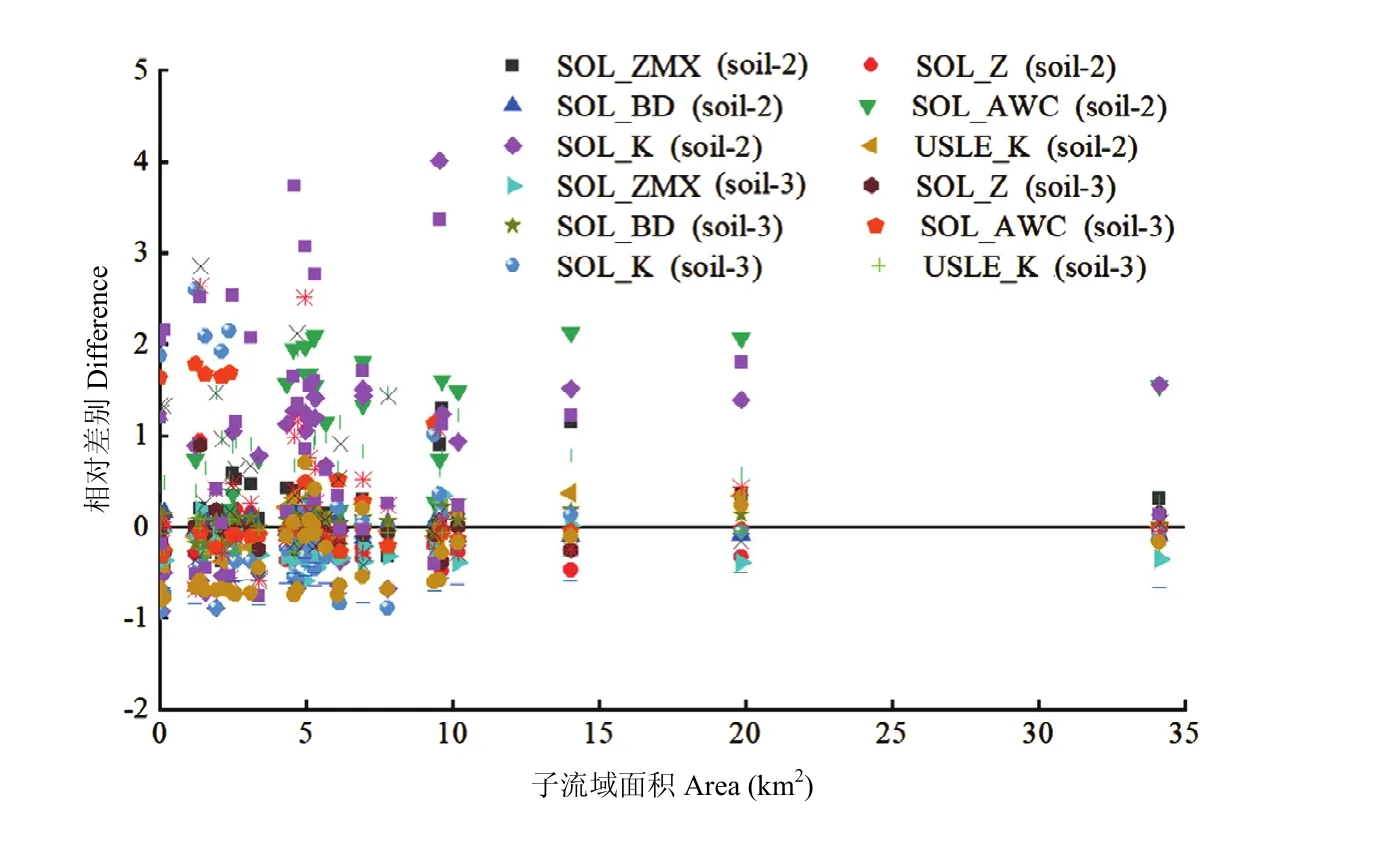
圖6 基于不同土壤圖獲得的土壤參數隨子流域面積的變化Fig.6 Differences between soil parameters from different soil data across varying subbasin areas
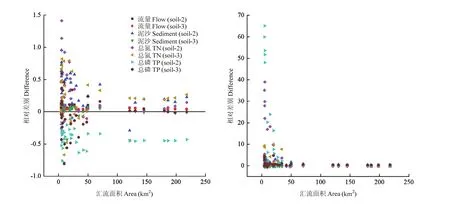
圖7 在進行模型校驗前(左)后(右)基于不同土壤數據模擬結果的差異與匯流面積的關系Fig.7 Differences in simulation results based on different soil data across varying subbasin areas
3 討論
3.1 土壤數據精度對模擬的影響與模擬指標有關
本研究利用1﹕5萬、1﹕50萬和1﹕100萬的土壤數據在面積為217 km2的小流域進行建模,發現3種土壤數據對流量模擬的差異小于對水質的模擬。土壤數據作為SWAT模型中重要的輸入信息之一,具有很強的空間變異性,通過影響流域的水文過程而影響模型的模擬[16]。不同分辨率的土壤數據會對SWAT模型模擬的土壤參數產生影響,其中含水量差異顯著,進而顯著影響水文響應單元的劃分,但對于土壤蒸發的計算沒有顯著影響[18]。而已有研究也表明不同比例尺的土壤數據對 SWAT模型模擬的影響與模擬項目有關。例如許多學者探討了美國比例尺為1﹕12000—63360的縣級SSURGO土壤數據和1﹕25萬—50萬比例尺的州級STATSGO土壤數據對流域水文模型的流量與水質的影響。在流量預測的影響方面,模型校準前后存在差異,校準前應用STATSGO數據進行流量預測效果相對高于 SSURGO數據;在校準后,SSURGO土壤數據整體上提供了更好的流量預測結果[23],使用SSURGO導致傳輸損失較少,較高的地表徑流歸因于較高的土壤數據分辨率[22-23]。然而,在更大尺度流域應用不同比例尺土壤數據時,不同比例尺土壤圖之間對于流量的預測差異不大[17],甚至低分辨率的數據效果反而略好于高分辨率[18]。與之相反,對SSURGO和STATSGO數據的研究表明,土壤數據分辨率的不同對營養物負荷影響比較顯著[31]。與SSURGO數據相比,1﹕25萬和1﹕50萬STATSGO土壤圖顯著降低了月平均氮負荷[32]。
3.2 不同土壤數據的模擬效果存在尺度效應
不同土壤數據對SWAT模型的模擬效果與流域尺度關系密切,不同土壤數據對模型模擬效果的影響存在時空尺度效應[33]。在本研究中,隨著匯流面積的增大,基于3種土壤數據提取的模型參數和模擬結果的差異逐漸減小,說明不同土壤數據參數在較小的空間尺度差異更大,進而對模型產生影響。主要原因在于模型在地表徑流計算過程中,進行了土壤水文組的劃分,概括了土壤信息,降低了土壤信息的精度;同時,在小的尺度上土壤的異質性影響較為嚴重,而在大的空間尺度上土壤屬性的均值較為一致[20]。已有研究表明對于大于 10 km2的子流域,采用10 m的SoLIM模型生成的土壤數據和1﹕24 000 SSURGO土壤數據對于流量的模擬沒有顯著差異,在較大的尺度上,使用精度低的土壤數據同樣可以達到理想的模擬效果[20]。此外,空間尺度對流域演算過程的影響呈線性相關關系,最小模擬單元級別下的徑流模擬差異非常大,但差異隨著模擬單元的空間尺度的增加而逐漸降低[19,34]。雖然不同模型對土壤數據的敏感性不同,但模擬的差別也會隨流域面積的增大而降低[35]。這說明不同土壤數據對于模型提取的土壤參數存在空間尺度效應,進而對模型的模擬產生影響。
3.3 流域模型模擬效果受其他因素影響
通過本文的研究發現,SWAT模型的模擬效果在較大尺度上受土壤數據影響不明顯,可能是由于流域模擬效果受 CN2[14]、地貌和氣候的綜合影響更為明顯,這些因素會在一定程度上掩蓋土壤數據所帶來的不確定性。另外,模型率定調整參數的過程以同一套實測數據為率定目標不可避免的掩蓋了土壤數據的不確定性對模型模擬過程的影響。本文研究結果也顯示出3個模型表現效果的差異在率定后出現了明顯的變化。也有研究表明,相較于土壤圖分辨率,土壤數據的來源對于模型輸出的影響更大[17]。因此,土壤圖的質量和適用性不僅取決于比例尺,還取決于制圖方式[36]。不同制圖方法會造成地表產流和產沙模式存在高度的空間變異性[37],WAHREN等將傳統的土壤圖和SoLIM生成的數字土壤圖應用到SWAT模型中,在模擬出口日流量時,盡管均取得滿意的模擬效果,但 SoLIM 派生的土壤數據對旱季的第一次峰值流量模擬擬合程度更好。從傳統土壤數據與數字土壤制圖數據在水文模型中的應用對比來看,更詳細的反映土壤屬性空間變異性的制圖方法(SoLIM)對峰值徑流事件的模擬效果更好[38-39]。此外,土壤制圖采用的插值方法也會影響土壤圖精度[36]。ZIADAT等[40]的研究對比了傳統插值方法和SLEEP(soil-landscape estimation and evaluation program)方法,結果表明相比于傳統的反距離加權和克里金插值方法,雖然模型對 SLEEP方法使用的土壤樣點數量并不敏感,但SLEEP方法制作的土壤數據在環境模型應用中的效果更好。因此,提高土壤制圖方法的精確性也是減少 SWAT模型模擬不確定性的重要途徑。
從已有研究及本文的研究結果來看,在應用SWAT模型進行流域模擬時,土壤數據分辨率與模型的模擬結果并無明顯的因果關系,提高土壤數據分辨率不一定會得到更好的模擬效果。同時,土壤數據對SWAT模型的影響存在著空間尺度效應,因此,在實際模型模擬中應根據流域大小和模擬指標選擇土壤數據的精度。此外,土壤圖的制作方法也是提高模型模擬精度的關鍵。
4 結論
(1)不同精度的土壤數據對 HRU的劃分結果有明顯影響,并且 HRU劃分數量的敏感性與劃分閾值及土壤詳細程度有關。此外,不同精度的土壤數據會明顯影響模型參數,但各參數的大小與土壤圖的詳細程度沒有對應關系。(2)模型參數的校準可以大幅度改善模型的模擬效果,不同的土壤數據對于不同模擬指標的模擬效果存在差異,但并非土壤數據越精細模擬效果越好。因此,在建立模型的時候,需要根據模擬目標具體而定,并不必要追求高精度的土壤數據。(3)隨著子流域面積的增大,土壤的平均屬性趨于一致,大的子流域面積在一定程度上綜合了土壤參數的空間異質性;隨著匯流面積的增大,土壤差異所帶來的模擬結果的差異逐漸趨于穩定,校準過程會在較小的匯流面積上產生較大的影響。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
音樂探索(2022年2期)2022-05-30 21:01:37
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小天使·一年級語數英綜合(2019年8期)2019-08-27 02:23:00
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
小學科學(學生版)(2018年7期)2018-08-13 09:33:04
中華詩詞(2018年11期)2018-03-26 06:41:34
光學精密工程(2016年6期)2016-11-07 09:07:19
