融合信任度值與半監督密度峰值聚類的改進協同過濾推薦算法
2020-09-07 01:48:10李昆侖王萌萌于志波翟利娜
小型微型計算機系統 2020年8期
關鍵詞:用戶
李昆侖,王萌萌,于志波,翟利娜
(河北大學 電子信息工程學院,河北 保定 071000)E-mail:likunlun@hbu.edu.cn
1 引 言
隨著互聯網時代的到來,面對過載的信息與資源,用戶難以快速找到有用的信息,個性化推薦系統應運而生,繼而出現了多種推薦算法,常用的有基于內容、基于用戶的協同過濾的推薦算法[1]等.協同過濾推薦算法是當前各類算法研究中應用最多且推薦效果最好的算法之一.因此,協同過濾推薦算法廣泛應用于各大電子商務平臺與網站中,例如淘寶、京東、亞馬遜等.但是隨著用戶和項目數量的劇增,導致用戶評分數據稀疏性問題嚴重影響到推薦系統的推薦質量[2].
用戶之間的關注度作為社交信息中的一個重要特征信息,為系統推薦提供了新的依據[3].文獻[4]提出采用概率矩陣分解來對評分進行預測,在構建用戶特征模型時加入社交信任,并對用戶特征向量本身進行擴展,該方法能夠在數據稀疏情況下提高推薦精度;文獻[5]提出一種帶偏置的專家信任推薦算法,在形成評分時融合專家的評價可信度、活躍度、評價偏差度,因此在數據稀疏時可以提高推薦精度;文獻[6]提出一種新的雙層鄰居選擇,通過選擇最具影響力和最值得信賴的鄰居來提高鄰居選擇的質量,故在數據稀疏的情況下能夠提高推薦精度;文獻[7]提出利用社交網絡特征,在傳統矩陣分解模型的基礎上加入信任特征矩陣,能夠達到提高系統推薦精度的目的.然而多數社交信息并沒有給出用戶之間的信任度值,如何度量用戶之間信任度值是當前有待解決的問題.
針對推薦系統中存在的數據稀疏性問題,本文提出了一種融合信任度值與半監督密度峰值聚類的改進協同過濾推薦算法,該算法將約束對的半監督信息[10-12]融入到密度峰值聚類算法[8,9]中,提高算法的在線推薦效率;同時將用戶的信任信息融入到評分預測中為目標用戶產生推薦,改善由數據稀疏性導致的推薦精度不準確等問題.本文算法進行了相關的理論分析,并在不同數據集上與其他算法進行了相關的實驗對比,本文算法在平均絕對誤差方面和均方根誤差方面均表現優異.
2 傳統的基于用戶的協同過濾推薦算法
傳統的基于用戶的協同過濾推薦算法的關鍵是快速準確的定位目標用戶的鄰居集,這將直接影響到推薦算法的推薦效率和推薦精度.一般推薦過程分為三個步驟,具體如下:
Sept1.獲取用戶-項目評分信息,建立用戶-項目評分矩陣n*m,如表1所示.
Sept2.根據表1,計算全體用戶之間的相似度,得到用戶相似度矩陣,依據相似度大小確定目標用戶的最近鄰居集.
Sept3.根據最近鄰居集中的用戶對目標項目i進行評分預測.
傳統的協同過濾推薦算法在尋找最近鄰居集時對所有用戶進行相似度計算,相似度的計算量大,導致算法的推薦效率下降;在處理稀疏數據時,其推薦精度也急劇下降.因此本文引入相似度聚類以提高算法的在線推薦效率,并結合社交信息改善由數據稀疏性導致的推薦質量差等問題.下面本文將針對改進部分進行詳細介紹.
3 改進的協同過濾推薦算法
3.1 半監督密度峰值聚類算法的改進
本文引入半監督密度峰值聚類算法,根據相似度進行聚類,將興趣相同的用戶分為一類,并建立用戶興趣度集合Iu.在線推薦時,僅需對Iu中的用戶進行相似度計算,繼而減少相似度的計算量,提高算法的推薦效率.
3.1.1 密度峰值聚類
用戶對項目的具體評分Rnm,表示用戶對該項目的興趣程度,因此本文采用密度峰值聚類算法對用戶的評分矩陣進行相似度聚類,構建用戶的興趣集合.將每個用戶評分作為一個樣本點,算法如下:
1)計算兩兩樣本點之間的距離dij,修正余弦相似度在計算中減去用戶所有評分項目的平均值消除評分的差異問題,因此本文采用修正余弦相似度的度量方式.如式(1)所示:

(1)
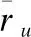
2)計算每個樣本點的密度,ρi為該樣本截斷距離dc內的樣本總數,為防止不同樣本點的ρi相同,采用dc內樣本點高斯核函數之和的倒數代替,式(2)所示:
(2)
3)計算每個樣本點的距離δi,δi分兩種:一種情況,該點到高密度點之間的距離;另一種情況,該點為局部密度最大點,則該點的距離表示與其它點之間的最大距離.如式(3)所示:
(3)
4)選取聚類中心,根據ρi和δi繪制決策圖,在決策圖中選取簇的聚類中心,通常選取ρi和δi均為較大的點作為簇的聚類中心,即在決策圖中處于右上角與其它點分離明顯的部分點,如圖1所示.
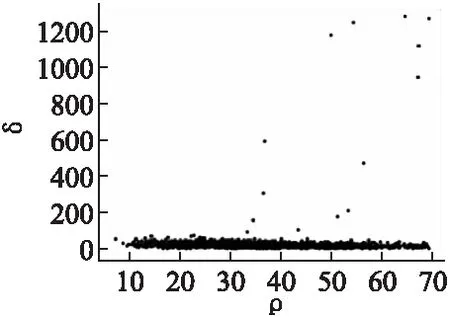
圖1 ρ-δ決策圖
5)分配剩余各點,確定聚類中心后將剩余點分配到距離最近的密度比其大的點所屬的類.
3.1.2 約束對信息嵌入
由于密度峰值聚類算法對dc過于依賴,且聚類后的數據無法服從真實數據的分布,因此本文在原算法的基礎上提出約束對限制的半監督聚類算法.約束對限制包括正關聯約束(must-link)和負關聯約束(cannot-link),即對必須在同一簇中而沒有被分到同一個簇中的數據實行must-link約束,對不該在同一個簇中卻被錯誤的分到同一個簇中的數據實行cannot-link約束.這兩種約束具有兩種性質.
對稱性:
(xi,xj)∈must-link?(xj,xi)∈must-link(xi,xj)∈cannot-link?(xj,xi)∈cannot-link
(4)
傳遞性:
(xi,xj)∈must-link&(xj,xm)∈must-link?(xi,xm)∈must-link(xi,xj)∈cannot-link&(xj,xm)∈cannot-link?(xi,xm)∈cannot-link
(5)
根據各點之間的相似度值,構造n個用戶之間的相似度矩陣S,用n*n的矩陣表示:

相似值s(i,j)越大,則表示兩個樣本之間越相似,若s(i,j)=1,則表示i和j完全相同,在計算數據集相似度矩陣時,保存所有樣本對之間的最大相似度Smax.
在獲得數據集相似度矩陣的基礎上,將已知的某些樣本對之間的兩種類型的must-link和cannot-link信息嵌入矩陣中.實驗中采用Random函數隨機產生成對約束對進行約束,若屬于同一簇加入must-link約束集;反之,加入cannot-link約束集.基于must-link和cannot-link具有對稱性和傳遞性,可以對矩陣中的其它樣本間的相似度進行調整擴展,進而充分地挖掘樣本對之間隱藏的約束對的約束關系.
將約束對監督信息嵌入數據集的相似度矩陣中,會生成已知的某些樣本對之間的兩種類型的成對點限制中滿足must-link和cannot-link約束的樣本對,以及由初始的must-link和cannot-link約束集的性質進行擴展得到新的must-link和cannot-link約束.由于采用修正余弦相似度計算樣本間的相似度,如果兩個樣本屬于同一簇則為must-link約束,將其相似度值設置為數據集所有樣本對之間的最大相似度Smax;如果兩個樣本不屬于同一類,則為cannot-link,則令其相似度值為0.步驟如下:
1)根據最初加入的成對約束建立數據集成對約束標記矩陣M,矩陣大小為樣本的總數,定義如下:
(6)
2)在成對約束標記矩陣的基礎上利用改造的Floyd算法求解成對約束擴展情況,算法如下:
輸入:成對約束標記矩陣M,樣本總數n
輸出:經過擴展的成對約束標記矩陣Mextend
Sept1.對矩陣M進行三次嵌套遍歷循環i,j,k
Sept2.任意點之間的相似度為s(i,j)=1,且s(j,k)=1,則點s(i,k)=1
Sept3.任意點之間的相似度為s(i,j)=-1,且s(j,k)=-1,則點s(i,k)=-1
3)根據擴展后的成對約束標記矩陣Mextend修正數據集相似度矩陣S中樣本對之間的相似度值,計算如下:
(7)
3.2 信任度值計算的改進
為緩解推薦算法數據稀疏性問題,利用社交網絡信任信息給目標用戶匹配精準鄰居用戶以提高推薦精度.在社交網絡中,用戶之間的關注度反映了用戶之間的信任程度,如圖2所示,本文通過用戶之間的關注度計算用戶之間信任度值并構造信任度集合Tu.

圖2 社交網絡有向圖
其中箭頭指向表示該用戶為目標信任用戶,如0→1,表示用戶0信任用戶1.
定義1.令Ttrust表示信任度,例如用戶u0對用戶u1的信任程度,記為Ttrust(u0,u1).
定義2.令Lij表示傳遞路徑,例如用戶u0到用戶u1的傳遞路徑,記為L01(u0,u1).
3.2.1 直接信任度值計算的改進
傳統觀念認為,用戶之間的信任是等價的,即用戶u0信任用戶u1,則用戶u1也信任用戶u0,兩者信任程度等價.然而現實生活中,用戶u0和用戶u1之間的信任程度通常并不等價,如果用戶u0信任用戶u1,不能代表用戶u1也一定信任用戶u0.因此本文引入信任權值,如式(8)、式(9)所示:
(8)
(9)
其中I(u0),I(u1)分別表示用戶u0,u1關注的用戶的集合,|I(u0)∪I(u1)|表示用戶I(u0)或者用戶I(u1)關注的用戶的集合的數量.式(8)、式(9)分別計算了用戶u0對用戶u1的信任權值和用戶u1對用戶u0的信任權值.
定義3.令Dtrust表示直接信任,根據用戶關系矩陣T,對于任意u0,u1,如果用戶u0關注了用戶u1,則存在Dtrust(u0,u1),記作u0→u1.
直接信任計算公式如式(10)、式(11)所示:
(10)
(11)
其中|I(u0)∩I(u1)|表示用戶I(u0)和用戶I(u1)共同關注的用戶的集合的數量.
3.2.2 間接信任度值計算的改進
為給目標用戶匹配更多的鄰居用戶,需要利用社會網絡信任傳遞性質,將更多沒有直接關聯的用戶聯系起來.
定義4.令Itrust(u,v)表示間接信任,若u信任w,w信任v,則存在Itrust(u,v),反之,不存在間接信任關系.
隨著間接信任用戶的增加信任度減小,所以本文采用兩級路徑傳播,如圖2所示,用戶u0到用戶u5的信任度傳遞為L025,L015,每條路徑的間接信任度計算如式(12)、式(13):
L025=Dtrust(u0,u2)*Dtrust(u2,u5)
(12)
L015=Dtrust(u0,u1)*Dtrust(u1,u5)
(13)
u0到u5存在兩條路徑傳遞,每條路徑信任值不同,對應的權重值也不同,因此引入等效電阻理論的距離度量方式[13],計算間接路徑的信任度.如圖3所示.
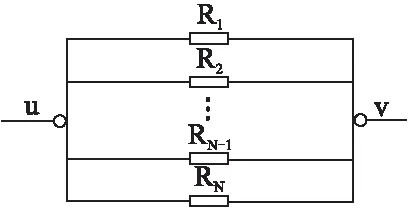
圖3 兩個用戶間的電路圖
令:
R1=L025
(14)
R2=L015
(15)
間接信任方式計算公式如式(16)所示:
(16)
綜合用戶直接信任Dtrust(u,v)和間接信任Itrust(u,v)得到用戶總的信任Trust(u,v),將Trust(u,v)作為用戶信任的相似度值,記作sim_t(u,v),如公式(17)所示:
sim_t(u,v)=

(17)
其中Dtrust(u,v)和Itrust(u,v)均不為零時,sim_t(u,v)表示綜合用戶的直接信任度值和間接信任度值;Itrust(u,v)=0時,sim_t(u,v)表示用戶之間只存在直接信任度值;Dtrust(u,v)=0時,sim_t(u,v)表示用戶之間只存在間接信任度值.
3.3 綜合用戶興趣度與信任度關系的評分預測
根據用戶興趣度和信任度的關系,通過設置推薦權重δ,平衡用戶興趣度和信任度的權重,可以提高識別鄰居的能力,不同應用情況,對兩種信息依賴程度不同,通過調整δ的取值調節兩種信息對預測評分的影響,避免出現興趣度或信任度權重較大的問題.如公式(18)所示:
wu,v=
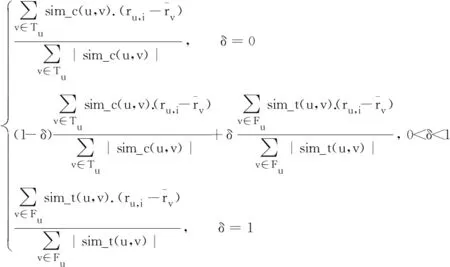
(18)
其中δ=0時,wu,v僅表示用戶的興趣相似度值;δ=1時,wu,v僅表示用戶的信任相似度值;0<δ<1時,表示綜合用戶興趣相似度值和信任相似度值.
計算目標用戶u對未評分項目i的預測值,其評分Pu,i預測如公式(19)所示:
(19)
3.4 本文算法步驟
本文的主要思路是根據用戶-項目評分矩陣M,使用基于約束對的密度峰值聚類將用戶進行分類,并采用TOP-N方法構建興趣度集合Iu,提高對目標用戶的在線推薦效率;再依據用戶關系矩陣T度量用戶之間的信任度值,采用TOP-N方法構建信任度集合Tu;最后將兩個集合的預測值進行線性加權.具體步驟如下:
輸入:用戶-項目評分矩陣M,用戶關系矩陣T.
輸出:前N個推薦項目.
Sept1.根據矩陣M,使用半監督密度峰值聚類將用戶按興趣度分類,計算ρi和δi,并根據公式(1)將用戶進行相似度分類.
Sept2.根據公式(1)計算目標用戶u和聚類中心的相似度,并將用戶u0加入到相似度高度的簇.
Sept3.根據公式(1)計算目標用戶u與簇內所有用戶的相似度,得到用戶興趣相似度的sim_i(u,v)值,并采用TOP-N方法建立興趣度集合Iu.
Sept4.根據用戶關系矩陣T,利用公式(10)、(11)、(16)、(17)計算目標用戶u與T中的信任度值sim_t(u,v),并采用TOP-N方法建立信任度集合Tu.
Sept5.刪除Iu和Tu集合中目標用戶已評分的項目,構建評分預測候選集Cu.
Sept6.對集合Cu中的項目,通過式(19)計算預測評分值,將預測評分值降序排序,給目標用戶u提供前N個推薦項目.
4 實驗分析
4.1 實驗環境及數據集介紹
本文實驗均在CPU為i7-7700HQ,2.80GHz,內存為8.00GB的計算機上運行,實驗軟件為python 3.7.本文實驗采用三個經典的包含信任關系數據集:Epinions數據集、Filmtrust數據集和Ciao數據集,數據集的具體評分信息和信任信息如表2所示.
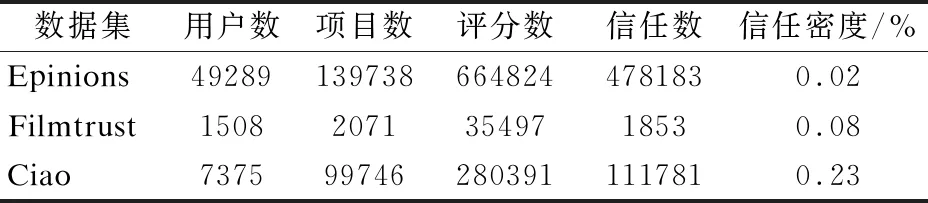
表2 三個不同數據集的統計信息
4.2 評價標準
本實驗將數據集按照80%和20%的比例分為兩部分,前者作為訓練集使用,用來構造推薦模型,后者作為測試集使用,這樣可以保證訓練集和測試集數據都是隨機的且都來自同一數據集.本實驗采用平均絕對誤差(Mean Absolute Error,MAE)和均方根誤差(Root Mean Squared Error,RMSE),這兩種評價指標通過計算真實評分與預測評分之間的誤差來衡量推薦結果的準確性,差值越小,表示偏差越小,推薦效果越好,如公式(20)、公式(21)所示:
(20)
(21)
4.3 δ參數的選擇
本文相似度計算由用戶興趣度和信任度兩部分組成,δ作為調節因子.δ的取值為[0,1],間隔0.1.δ取值分為三種情況,δ=0時,算法僅依據用戶興趣度產生推薦;δ=1時,算法僅依據用戶信任度產生推薦;0<δ<1時,算法綜合興趣度和信任度產生推薦,且δ越大則信任度占比越大.
圖4給出δ在不同數據集上的變化趨勢,隨著δ的增加,MAE和RMSE均呈現先減小后增大,表明興趣度和信任度的占比不同會直接影響該算法的推薦結果,從圖4(a)中可以得到,在Epinions數據集上,MAE值在δ=0.5時取得最小值,RMSE值在δ=0.6時取得最小值,綜合用戶興趣度和信任度在MAE值和RMSE值的考慮,取δ=0.55時,該算法有最佳推薦結果.從圖4(b)可以得到,在Filmtrust數據集上,MAE值和RMSE值均在δ=0.6取得最小值,綜合興趣度和信任度的MAE值和RMSE值的考慮,當δ=0.6時,該算法有最佳推薦結果.從圖4(c)可以得到,在Ciao數據集上,MAE值和RMSE值均在δ=0.7時取得最小值,綜合興趣度和信任度的MAE值和RMSE值的考慮,當δ=0.7時,該算法有最佳推薦結果.Epinions數據集的信任密度為0.02%,δ取值0.55;Filmtrust數據集的信任密度為0.08%,δ取值0.6;Ciao數據集的信任密度為0.23%,δ取值0.7,說明信任密度越大,信任度占比越重.
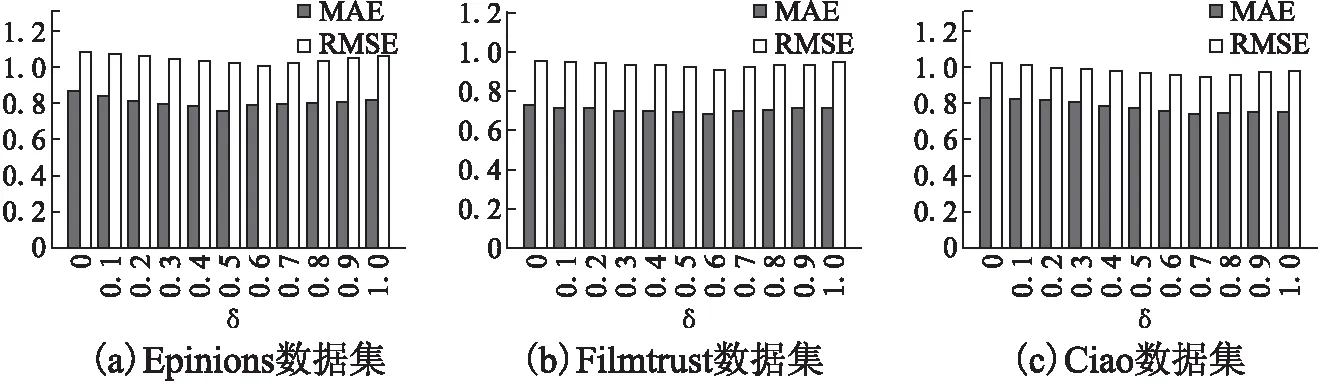
圖4 不同數據集對δ值的影響
4.4 信任度值的推薦效果比較
為能更清晰地分析信任度在推薦系統中的作用,將本文算法進行信任效果對比,即不加信任、加直接信任以及加入間接信任時的三種方法進行對比分析.
如圖5所示,圖5(a)、(d)為本文算法在Epinions數據集上的運行結果,圖5(b)、(e)為本文算法在Filmtrust數據集上的運行結果,圖5(c)、(f)為本文算法在Ciao數據集上的運行結果.根據實驗結果圖縱向對比分析,當加入直接信任度值時的MAE值和RMSE值始終小于不加入信任度值計算的MAE值和RMSE值;加入間接信任度值計算的MAE值和RMSE值始終小于僅加入直接信任度值計算的MAE值和RMSE值.根據實驗結果圖的橫向對比分析,通過圖5(a)、(d)可以分析,在Epinions數據集上,當推薦數量N=35時,本文算法的MAE值和RMSE值均為最小,即當推薦數量為35時,該算法有最佳推薦結果,能夠充分挖掘用戶之間的信任信息;通過圖5(b)、(e)可以分析,在Filmtrust數據集上,當推薦數量N=25時,本文算法的MAE和RMSE值均為最小值,即當推薦數量為25時,該算法的推薦結果最佳,能夠充分挖掘用戶之間的隱式信息;通過圖5(c)、(f)可以分析,Ciao數據集上,當推薦數量N=30時,本文算法的MAE和RMSE值均為最小值,即當推薦數量為30時,該算法的推薦結果最好,可以充分挖掘用戶之間的信任信息.因此當該算法同時考慮直接信任度值和間接信任度值時能夠有效降低MAE值和RMSE值,提高對目標用戶的推薦質量,同時也說明該算法在不同的數據集上有不同的最佳推薦數量.
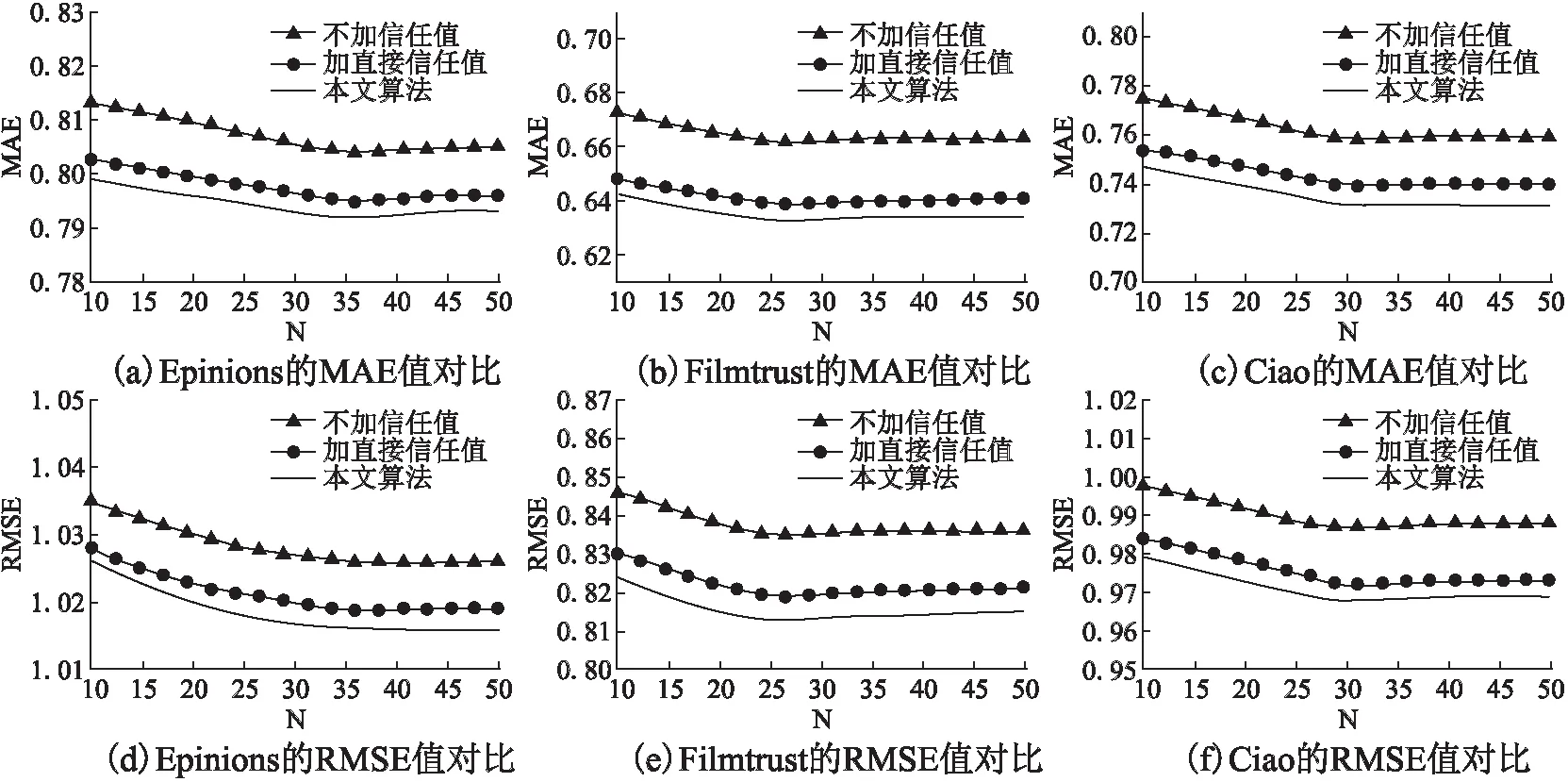
圖5 三種信任度值在不同數據集上的對比結果
4.5 幾種算法的推薦效果比較
為更直觀地分析本文算法的推薦質量,本文選用一個傳統的算法模型和三個改進的且帶有信任度值計算的算法模型,分別是基于用戶的協同過濾算法模型(UBCF)[14]、基于社交網絡矩陣分解的推薦算法模型(SRM-MF)[15]、基于用戶信任和商品評級的推薦算法模型(TrustSVD)[16]以及融合用戶信任的協同過濾推薦算法模型(SUPTserCF)[17],與本文提出的算法模型進行對比分析.
如圖6所示,圖6(a)、(d)為各個算法在Epinions數據集上的對比結果,圖6(b)、(e)為各個算法在Filmtrust數據集上的對比結果,圖6(c)、(f)為本文算法在Ciao數據集上的運行結果.從實驗結果圖中可以分析,在Epinions數據集、Filmtrust數據集上和Ciao數據集上,UBCF算法的MAE值和RMSE值均遠大于其他四種算法模型,說明其他算法模型在不同的數據集上均可以有效地提高推薦算法的推薦精度.如圖6(a)、(d)所示,在Epinions數據集上,根據實驗結果的橫向對比分析,SRM-MF算法、TrustSVD算法、SUPTserCF算法以及本文算法均在推薦數量N=35時平均絕對誤差最小,且隨著推薦數量的增加MAE值趨于平穩不再有大的波動,說明隨著推薦數量的增加各個算法的平均絕對誤差不會再減小,該數據集的最佳推薦數量為35.如圖6(b)、(e)所示,在Filmtrust數據集上,通過實驗結果的橫向對比分析,SRM-MF算法、TrustSVD算法、SUPTserCF以及本文算法均在推薦數量N=25時MAE值和RMSE值均為最小值,此后隨著推薦數量的增加,MAE值和RMSE值不會再降低,且略有上升,說明隨著推薦數量的增加各個算法的MAE值和RMSE值不會再下降,該數據集的最佳推薦數量為25.如圖6(c)、(f)所示,在Ciao數據集上,通過實驗結果的橫向對比分析,SRM-MF算法、TrustSVD算法、SUPTserCF以及本文算法均在推薦數量N=30時MAE值和RMSE值均為最小值,此后隨著推薦數量的增加,MAE值和RMSE值不會再降低,該數據集的最佳推薦數量為30.在不同的數據集上對實驗結果進行縱向對比分析,當推薦數量N值相同時,在Epinions數據集、Filmtrust數據集和Ciao數據集上本文算法的MAE和RMSE值均小于其它對比算法,證明本文算法在提高推薦精度上有良好的效果.
5 總 結
本文針對傳統協同過濾推薦算法在數據稀疏情況下的不足,提出了一種融合信任度值與半監督密度峰值聚類的改進協同過濾推薦算法.該方法通過半監督密度峰值聚類將用戶按興趣分類建立用戶興趣度集合;并結合社交網絡的信任關系,通過計算直接信任度值和間接信任度值建立用戶信任集合.在基于用戶的興趣度集合和信任度集合分別選擇鄰居用戶,根據鄰居集合為用戶產生推薦.該算法降低了在尋找目標用戶集合的時間損耗并為用戶匹配精準鄰居集合,提高了系統的推薦效率和推薦精度.
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
