基于改進深度注意神經網絡的語義角色標注
2020-09-04 04:58:52梁志劍
計算機工程與設計 2020年8期
梁志劍,郝 淼
(中北大學 大數據學院,山西 太原 030051)
0 引 言
傳統語義角色標注方法(semantic role labeling,SRL)[1-3]主要依賴句法分析結果,增加了語義角色標注系統的復雜性。基于端到端[4]和基于長短期記憶神經網絡[5](long-term and short-term memory,LSTM)的語義角色標注模型,雖然在一定程度上降低了標注系統的復雜性,但在任意長度序列的預測任務中對句子長短和語句結構的依賴性強。王明軒等提出的深層雙向長短期記憶神經網絡(deep bidirectional long short term memory,DBLSTM)[6],易于實現且能進行并行處理,在任意長度序列的預測任務中效果良好,但隨著網絡模型深度的增加,標注效果質量下降。Zhixing Tan等[7]提出了基于注意力機制的深度注意神經網絡模型DEEPATT(deep attention neural network),自我注意機制可實現任意兩個實體之間的直接連接,即使句子中距離很遠的論元也可以通過較短的路徑建立聯系,使得信息更加通暢,但標簽之間具有很強的依賴關系,且模型深度過大也會加重梯度消失,影響了標注準確率。本文提出了一種基于自注意力機制的DEEPATT模型的優化方法,通過在模型的層與層之間使用Layer Normalization進行歸一化處理,并引入Highway Networks優化的DBLSTM替代DEEPATT模型中的RNN,增強了模型的穩定性,提高了標注準確率。
1 相關工作
1.1 語義角色標注
當給定某一個語句,語義角色標注的任務就是用來識別每個目標動詞并對其進行分類。例如:“小紅昨天從小明那兒借了一輛自行車”,SRL會產生如下輸出:[ARG0 小紅][J借來][ARG1一輛自行車][ARG2向小明][AM-TMP昨天]。其中ARG0代表借方,ARG1代表被借方,ARG2代表借方實體,AM-TMP表示動作發生的時間,J是動詞。語義角色標注任務的第一步是標識,為給定的謂語動詞標注屬性類別,第二步需要為它們分配語義角色。
本文提出的模型則是將語義角色標注作為一個序列標注問題,以上文語句為例,構建一個詳細詞匯表,用向量V表示,V={小紅,昨天,向小明,借來,一輛自行車},向量V的長度等于5。除了詞匯表中相應單詞索引處的元素外,其余元素使用0表示,詞匯表編碼為:小紅=[1,0,0,0,0]T,昨天=[0,1,0,0,0]T,向小明=[0,0,1,0,0]T,借來=[0,0,0,1,0]T,一輛自行車=[0,0,0,0,1]T,這些編碼代表五維空間,其中每個詞都占據一個維度,且相互獨立,與其它維度無關。這意味著上面語句中的每一個詞都是相互獨立的,詞語和詞語之間沒有任何關系。而語義角色標注的目的是為了讓具有相似背景的詞語占據緊密的空間位置,即在數學上,這些矢量之間角度的余弦值應接近1,即角度接近0。為此引入詞嵌入向量(Word Embedding),直觀地說是引入了一個詞對另一個詞的依賴性。用詞嵌入向量可以用更低維度的特征向量代替高維度的特征向量,這些嵌入向量作為新的輸入被送到下一層。本文用改進的DEEPATT作為基本模型,以捕捉句子之間復雜的嵌套結構和詞語標簽之間存在的潛在依賴關系。
1.2 優化后的深度注意神經網絡模型
DEEPATT模型是基于注意力機制[8]的神經網絡模型,本文采用DEEPATT模型作為整體架構,每一層神經網絡都包含一個注意力機制子層和一個非線性變換子層,第N層神經網絡的數據通過SoftMax輸出層輸出,完成最后的分類。DEEPATT模型中探討了3種非線性子層,即遞歸子層、卷積子層、前饋子層。本文首先在層與層之間使用了Layer Normalization來進行全局優化,其次還針對非線性子層的RNN進行了優化,優化后的模型如圖1所示。

圖1 優化模型
1.2.1 注意力機制子層
近兩年,注意力機制的提出為語義角色標注領域帶來了新的活力。目前很多研究者開始將注意力機制運用于自己的研究領域,也用注意力機制來搭建整個模型框架。Zhixing Tan等同樣將注意力機制應用到了語義角色標注任務中,在CoNLL-2005和CoNLL-2012兩個數據集中取得了很好的訓練效果。本文運用DEEPATT模型作為整體架構,它的注意力機制層計算步驟主要分為3步,第一步是計算query和key的相似度,得到權重。第二步是用SoftMax函數來做歸一化處理。第三步是將得到的權重和相應的value計算求和。計算公式如式(1)所示
(1)
其中,Q表示query vectors,K表示keys,V表示values,d表示網絡隱藏單元。
1.2.2 非線性變換子層
DEEPATT模型中的深度注意神經網絡模型的非線性變換子層可由遞歸子層、卷積子層以及前饋子層組成,本文也針對3種非線性子層做了討論。
對于遞歸子層,RNN用遞歸關系來傳播網絡的信息。神經元節點連接形成一個有向圖,對于信息有部分記憶能力。循環神經網絡可以使用其內部狀態來處理輸入序列。
對于卷積子層,本文使用Dauphin等在2016提出的門控線性單元 (gated linear units,GLU)。與標準卷積神經網絡相比,GLU更容易學習,在語言建模和機器翻譯任務上都取得了令人印象深刻的成績。給定兩個過濾器W∈RK×d和V∈RK×d, GLU的輸出激活計算過程如式(2)所示
GLU(X)=(X*W)⊙(X*V)
(2)
濾波器寬度K被設置為3。
對于前饋子層,它由兩個中間隱藏ReLU非線性的線性層組成,計算過程如式(3)所示
FFN(X)=ReLU(XW1)W2
(3)
1.2.3 SoftMax輸出層
模型通過一層層非線性子層和注意子層的訓練,最后通過SoftMax的輸出層輸出。SoftMax回歸是邏輯回歸的一種形式,它將輸入值歸一化為值向量,該值向量遵循總和為1的概率分布,且輸出值在[0,1]范圍之間。在數學中,SoftMax函數,也稱為歸一化指數函數。它將K個實數的向量作為輸入,并將其歸一化為由K個概率組成的概率分布。也就是說,在應用SoftMax之前,一些矢量分量可能是負的,或者大于1,并且可能不等于1,SoftMax函數通常作為神經網絡分類器的最后一層,即輸出層,經過自注意力機制子層和非線性子層的訓練,最后通過輸出層輸出,完成最后的分類。
1.3 加入Layer Normalization全局優化后的模型
在DEEPATT模型的層與層間加入Layer Normalization[9]進行全局優化,對同一層網絡的輸出作標準的歸一化處理,使模型訓練時更趨于穩定。其計算如式(4)至式(5)所示
(4)
(5)
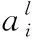
1.4 優化的LSTM單元
1.4.1 LSTM單元
如上文所說,深度注意神經網絡模型的靈活變換性主要由于它的非線性變換子層,而非線性變換子層的靈活性主要因為循環神經網絡的存在。在語義角色標注任務中,循環神經網絡的應用無處不在。谷歌在科研過程中廣泛使用循環神經網絡來進行語義角色標注,并將其應用于機器翻譯,語音識別以及其它一些NLP任務。實際上,通過利用循環神經網絡實現了幾乎所有與NLP相關的任務,然而傳統的循環神經網絡對于上下文信息的存取是有限的。隨著深度學習框架TensorFlow的興起,Hochreiter等發明了LSTM[10],將一個稱為細胞的存儲單元引入網絡來解決這個問題,LSTM結構如圖2所示。
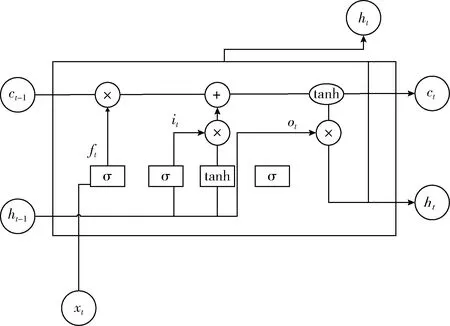
圖2 長短期記憶神經網絡單元結構
圖2中xt表示LSTM單元在t時刻的輸入向量,ft表示LSTM單元在t時刻忘記門的激活矢量,it表示LSTM單元在t時刻輸入門的激活矢量,ot表示LSTM單元在t時刻輸出門的激活矢量,ht表示LSTM單元在t時刻隱藏狀態向量也稱為LSTM單元的輸出向量,ct表示LSTM單元在t時刻的細胞狀態向量。W、U、b表示訓練時間需要學習的權重矩陣和偏差以及矢量參數,其計算公式如式(6)至式(10)所示
ft=σg(Wfxt+Ufht-1+bf)
(6)
it=σg(Wixt+Uiht-1+bi)
(7)
ot=σg(Woxt+Uoht-1+bo)
(8)
ct=ft*ct-1+it*σc(Wcxt+Ucht-1+bc)
(9)
ct=ot*σh(ct)
(10)
其中,σg表示sigmoid函數,σc,σh表示雙曲正切函數。從圖2的LSTM結構圖可以看出,LSTM單元最后的輸出不僅僅與上一層網絡的輸入有關,還與隱藏狀態向量有關。于是本文用Highway Networks優化的DBLSTM代替DEEPATT模型中的RNN來解決SRL序列標注問題,以此來獲得標簽之間更復雜的依賴關系。
1.4.2 深層雙向長短期記憶神經網絡
首先對于DBLSTM來說,第一層LSTM正向處理輸入的句子序列,得到的輸出結果作為第二層的輸入,同時反向處理得到輸出結果,以此循環。這樣就可以從向前和向后兩個方向來處理LSTM單元的原始輸入。實際上在標注過程當中,對于一個句子的信息是同時提取的,DBLSTM相比于LSTM的優點在于將兩個經過不同方向處理的輸入得到的輸出相互連接,不僅可以利用過去的信息,還可以充分利用未來的信息,在一定的參數下,該方法能在空間上訓練出更深層次的神經網絡模型。
其計算公式如式(11)至式(14)所示:
圖2中從左向右循環神經網絡層的公式為
(11)
圖2中從右向左循環神經網絡層的更新公式為
(12)
雙向LSTM的計算公式為
(13)
在這種拓撲結構中,第l層的輸入恰好就是第l-1層的輸出,第l層的輸出公式如式(14)所示
(14)
根據式(14)可以得出,訓練更深層次的神經網絡會增加網絡模型的表達能力,但更深層次的神經網絡模型會為訓練帶來更大的復雜性,訓練起來也會更加困難。因此,為了解決神經網絡訓練達到更深層數時帶來的梯度消失、梯度爆炸問題,本文引入Highway Networks來優化DBLSTM替換DEEPATT模型中的RNN來構建非線性子層,相對于DEEPATT(RNN)的結果取得了明顯的進步,有效減緩了由于神經網絡層數加深導致梯度回流受阻而造成的深層神經網絡訓練困難問題。
1.4.3 基于Highway Networks優化的DBLSTM
神經網絡的深度在一定程度上決定著訓練結果的準確性,Highway Networks就是受到長短期記憶網絡LSTM的啟發,使用自適應門控單元來調節信息流。即使有數百層,也可以通過簡單的梯度下降直接訓練高速公路網。加入Highway Networks優化的DBLSTM就在一定程度上緩解了訓練模型的復雜性。
Highway Networks的基本公式如式(15)至式(22)所示
y=H(x,WH)⊙T(x,WT)+x⊙C(x,Wc)
(15)
其中,y向量由兩項組成。T表示轉換門transform gate,C表示攜帶門carry gate。C和T的激活函數都是sigmoid函數
T=(a1,a2,…,an)
(16)
C=(b1,b2,…,bn)
(17)
C=1-T
(18)
y=H(x,WH)⊙T(x,WT)+x⊙C(1-T(x,WT))
(19)
最后得
(20)
雅可比變換
(21)
最后的輸出公式為
yi=Hi(x)*T(x)+xi*(1-T(x,WT))
(22)
其中,x,y,H(x,WH),T(x,WT)是同維度向量,不夠的話用0補全。或者我們想更改x的維度從A變成B的話,只需要引入一個維度為A×B的矩陣做乘法。由式(21)可以看出,最終通過sigmoid變化,當T(x,WT)=0時,原始輸入直接輸出,不做任何改變;當T(x,WT)=1時,原始信息在轉換之后輸出。即使訓練層數加深時,也可以用這種方法來收斂層數,從而減少由于網絡層數的增加而帶來的復雜性,并且可以降低訓練模型的難度。
2 實驗分析和結果
本文所用實驗環境:MacBook Pro;處理器是2.5 GHz Intel Core i7;圖形加速卡:Intel Iris Plus Graphics 640 1536 MB;內存:16 GB 2133 MHz LPDDR3;操作系統:IOS;使用Google 開源深度學習框架 TensorFlow 以及anaconda構建神經網絡,并在PyCharm軟件平臺上運行python進行實驗。
2.1 實驗數據
CoNLL-2005共享任務數據集和CoNLL-2012共享任務數據集。
2.2 實驗方法
本文的模型的設置如下。字嵌入和謂詞掩碼嵌入的維度設置為100,隱藏層的數量設置為10。我們將隱藏神經元數量d設置為200。且采用了Dropout機制來防止神經網絡過擬合。
2.3 實驗結果與分析
實驗結果見表1、表2。

表1 優化模型測試結果(CoNLL-2005)
由實驗結果表1、表2可知,在加入Layer normalization[11]改進后的模型在CoNLL-2005共享任務數據集的表現中比之前最好模型DEEPATT的結果優化了0.12個百分比,在CoNLL-2012共享任務數據集的表現中比之前的最好模型DEEPATT的結果優化了0.03個百分比。本文同時也針對DEEPATT模型中的RNN進行了優化,引入基于Highway Networks優化后的DBLSTM替代原模型的RNN層,在CoNLL-2005共享任務數據集中優化后的結果比DEEPATT(RNN)模型的結果提高了0.34個百分比,在CoNLL-2012共享任務數據集中優化后的結果比DEEPATT(RNN)模型的結果提高了0.22個百分比。這說明本文優化后的模型提高了標注準確率。同時也間接說明了Layer normalization和Highway Networks對深度注意神經網絡模型訓練的重要性。
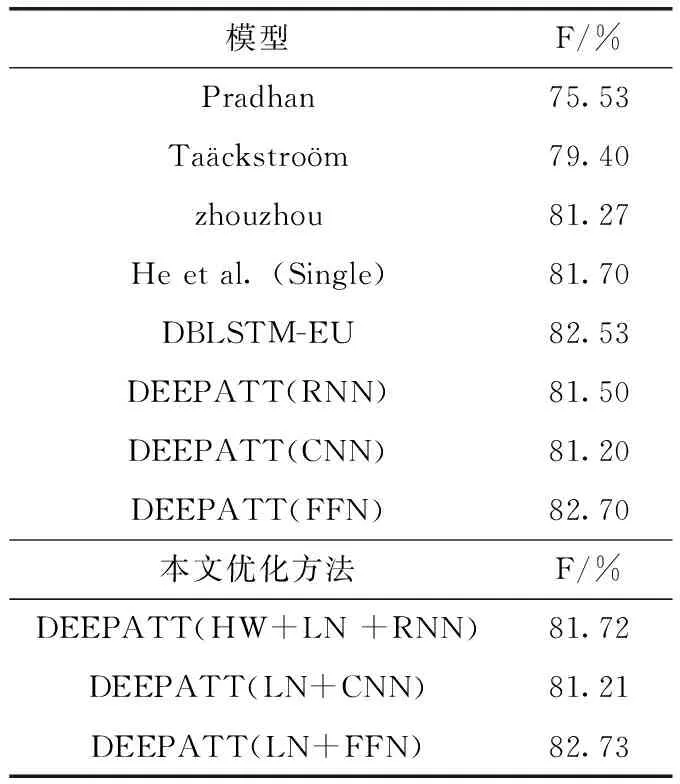
表2 優化模型測試結果(CoNLL-2012)
3 結束語
本文提出了一種基于注意力機制的DEEPATT模型的改進方法,首先對DEEPATT模型的層與層之間使用Layer Normalization進行歸一化處理,其次引入Highway networks優化的DBLSTM對DEEPATT中的RNN進行了優化,用來解決語義角色標注過程中存在的問題。本文的實驗結果驗證了Highway Networks對于解決深度注意神經網絡模型訓練困難的能力,以及Layer Normalization對于提高深度注意神經網絡模型穩定性的能力。雖然本文優化后的方法較之前最好的模型DEEPATT取得的結果有所進步,但本文優化后的模型仍然有可以改進的地方。本文并沒有在標注速度上取得很明顯的成果,所以筆者接下來將對這一方面進行深入探索。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
