基于深度學習的無人駕駛視覺識別
2020-09-02 06:46:29李嘉寧劉楊胡馨月劉建恬陳宗文
工業技術創新 2020年4期
關鍵詞:深度學習
李嘉寧 劉楊 胡馨月 劉建恬 陳宗文
摘 ? 要: 大數據技術的發展,以及基于圖像處理單元(GPU)并行計算能力的提升,共同促進了深度學習算法在無人駕駛視覺識別等領域的應用。在Ubuntu 16.04操作系統上,搭建Python實驗環境,開展基于卷積神經網絡——Mask R-CNN的無人駕駛視覺識別實驗。使用VIA 3.0工具,實現圖像與視頻的標注與分類;采用GTX 1080Ti GPU、cuDNN顯卡加速包等軟硬件,實現模型訓練和測試;引入混淆矩陣和平均精度等指標對卷積神經網絡模型進行性能評估。結果表明:視覺識別效果較好、可靠性較強,展現了深度學習技術在該領域具有很高的應用價值。
關鍵詞: 深度學習;無人駕駛;卷積神經網絡;視覺識別;性能評估
中圖分類號:TP2 ? ?文獻標識碼:A ? ?文章編號:2095-8412 (2020) 04-054-04
工業技術創新 URL: http://gyjs.cbpt.cnki.net ? ?DOI: 10.14103/j.issn.2095-8412.2020.04.010
引言
近年來,深度學習技術促進了人工智能在學術界和工業界的推廣應用。深度學習算法起源于人工神經網絡,為多層神經網絡在各個大規模計算領域中的應用提供了一種有效的途徑。大數據技術的發展,以及基于圖像處理單元(GPU)的并行計算能力的提升[1],正在同步促進深度學習算法的深度應用,如無人駕駛智能系統的研究。
道路環境智能感知是無人駕駛技術的重要組成部份,主要依賴于高分辨率攝像頭、超聲波雷達、激光雷達、GPS定位儀等設備及時、準確獲取的路標、坑洼、路障、行人等行車環境信息。傳統視覺識別算法魯棒性差,泛化能力弱,一般而言檢測精度最多達到93%(人類約能達到95%),無法達到無人駕駛所的預期標準[2]。理論與實踐表明,深度學習算法具備對復雜環境進行感知的強大能力,且檢測精度可達到95%以上。
本文首先介紹基于深度學習的圖像處理理論;其次借助一種得以改進的卷積神經網絡——Mask R-CNN,進行無人駕駛視覺識別實驗;最后對實驗結果進行分析和評價。
1 ?基于深度學習的圖像處理理論
1.1 ?卷積神經網絡
卷積神經網絡(CNN)的基本結構包括輸入層、卷積層 、池化層 、全連接層及輸出層。
卷積層和池化層一般有若干個,二者通常交替設置,即一個卷積層連接一個池化層,這個池化層后再連接一個卷積層,依此類推。卷積層由多個特征圖(Feather Map)組成,每個特征圖由多個神經元組成。卷積層的作用是借助卷積操作提取圖像特征。卷積層數越多,其提取的特征層次越高。由于卷積層中輸出特征面的每個神經元的輸入值是通過與其輸入進行局部連接,對應的連接權值與局部輸入進行加權求和,再與偏置值相加而得到的,而該過程等同于卷積過程,因此這一算法稱作卷積神經網絡。
池化層同樣由特征圖組成,旨在通過降低特征面的分辨率來獲得具有空間不變性的特征,有二次提取圖像特征的作用。
全連接層可以整合卷積層或者池化層中具有類別區分性的局部信息,其后連接的輸出層用于邏輯分類[3]。
1.2 ?Mask R-CNN
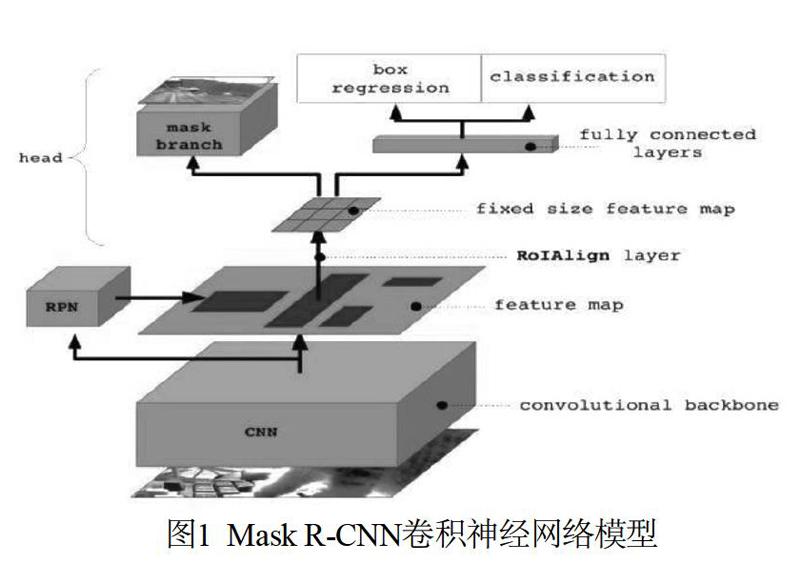
Mask R-CNN是一種卷積神經網絡,其模型示意如圖1所示。Mask R-CNN脫身于Fast R-CNN,并進行了諸多改進。
1.2.1 ?特征提取
Mask R-CNN通過ResNeXt提取特征,并通過特征金字塔網絡(FPN)構成骨干網絡。經過第一階段的特征提取,給出固定大小的感興趣區域(RoI)[4]。
1.2.2 ?檢測與實例分割
在感興趣區域上,Mask R-CNN一方面進行二值分類給出候選框,另一方面結合后續介紹的RoI Aligh操作,將隨后的一個網絡分支用于分類和回歸,另一個網絡分支用于分割生成掩膜(mask)。
1.2.3 ?RoI Aligh
RoI Aligh是一種用于增加檢測精度的技術手段,用于RoI的給出階段。在之前的檢測算法中,RoI的提取會因為特征圖大小和檢測圖像大小不匹配的原因,進行像素點取整操作,進而出現細微的位置偏差。而RoI Aligh利用雙向線性差值的原理,將像素點定位規范到浮點小數級別,將位置偏差降到最低。
1.2.4 ?損失函數
Mask R-CNN采用多任務的損失函數,在一定程度上加快了卷積神經網絡的訓練效率。
綜上,Mask R-CNN是一種可以同時進行目標識別和物體實例分割的卷積神經網絡[5],可以有效地作為無人駕駛的視覺感知模型。
2 ?基于Mask R-CNN的無人駕駛視覺識別實驗
2.1 ?數據集處理
2.1.1 ?圖像與視頻的標注與分類
VGG Image Annotator(VIA)可用于圖像與視頻目標的人工標注與分類[6]。本文采用VIA 3.0。標注完成后,可為數據集生成相應格式的標注信息文件(.csv/.json),以解決深度學習任務的數據集標注問題。
2.1.2 ?數據集制作過程
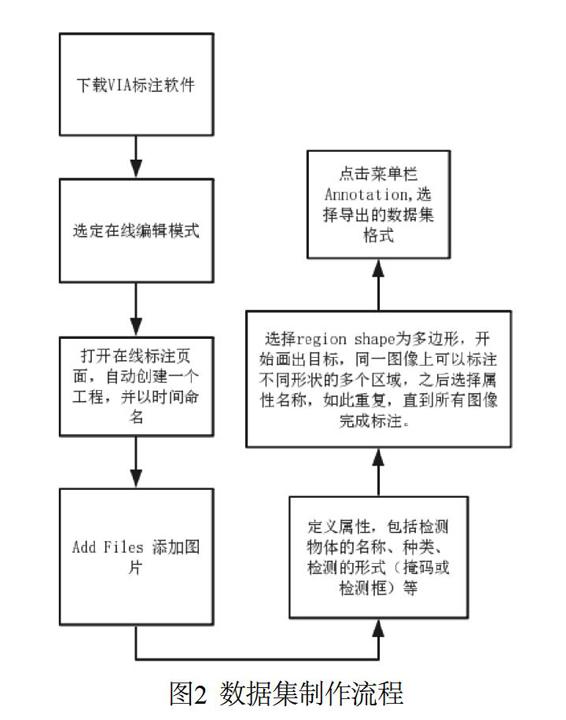
使用長春市中心360行車記錄儀記載的視頻,作為數據集的數據來源,并用VIA工具進行標注。數據集制作流程如圖2所示。
實際操作的數據集標注界面如圖3所示。
2.2 ?實驗調試
2.2.1 ?實驗配置
本實驗在Ubuntu 16.04操作系統進行,實驗環境為Python 3.5.2,實驗工具為GTX 1080Ti GPU。
2.2.2 ?實驗調試
(1)環境的搭建
首先,在Python官方網站下載Python 3.5.2版本,并在系統環境變量的路徑中增加Python路徑;安裝成功之后,使用自帶工具包pip,進行所需科學計算工具包的下載。
然后,下載Nvidia CUDA-linux顯卡驅動,以及cuDNN顯卡加速包,為下一步的GPU訓練做準備。
(2)模型的訓練和測試
首先,將制作好的數據集放置在系統的具體目錄下;其次,下載COCO2012數據集,并對Mask R-CNN網絡進行預訓練,得到網絡初始權重;之后,在系統終端輸入訓練指令,使用自制數據集對網絡進行訓練,訓練后的網絡權重;最后,使用訓練后的Mask R-CNN模型對未標注的360行車記錄儀視頻進行測試。
3 ?結果與討論
3.1 ?評價標準
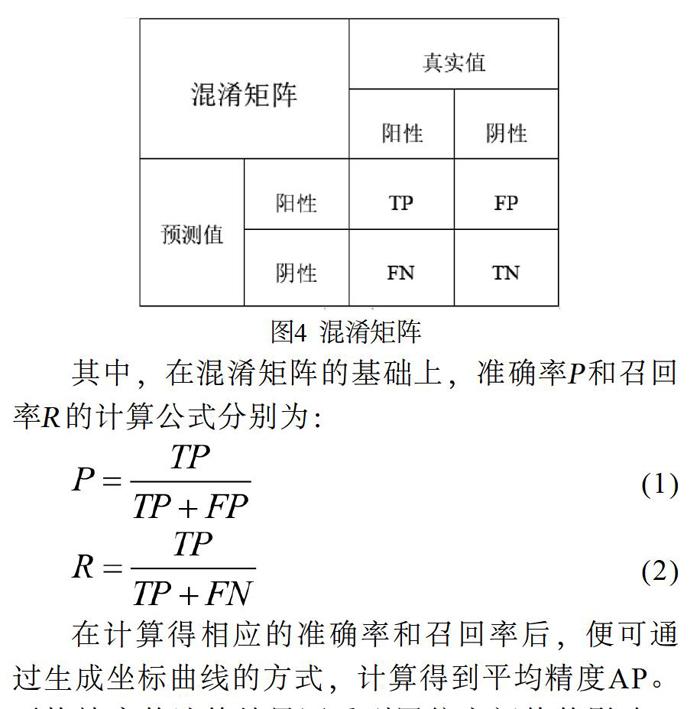
針對實驗結果,引入混淆矩陣[7]和平均精度[8](Average Precision,AP)進行駕駛道路感知模型的性能評估。混淆矩陣在圖像目標識別與分割任務中是最常用的評價指標之一,它以矩陣的形式,對數據真實的類別和判定生成的類別之間的對應關系作出歸納,并以此為基礎,計算模型對輸入數據處理的準確率、召回率、特異度以及精確度等性能指標。混淆矩陣如圖4所示。
其中,在混淆矩陣的基礎上,準確率P和召回率R的計算公式分別為:
(1)
(2)
在計算得相應的準確率和召回率后,便可通過生成坐標曲線的方式,計算得到平均精度AP。平均精度的計算結果還受到置信率閾值的影響。例如,若置信率閾值設定過高,置信率評分較低,則得到正確判斷的陽性數據容易被過濾;若置信率閾值設定過低,則難以保證所有歸納結果的準確性[9]。因此,本實驗分別取置信率閾值[10]為0、0.5和0.75進行評估,并且將相應得平均精度記為AP0、AP1和AP2。
3.2 ?評價實施
對自制數據的測試集進行駕駛道路環境自動感知模擬實驗,效果示例如圖5所示。
由混淆矩陣理論計算得到該部分實驗相應的平均精度如表2所示。
3.3 ?討論
視覺識別過程由訓練后的Mask R-CNN實現。整體來看,實驗結果具有較好的識別效果,對道路上的車輛、交通標志、行人的識別率較高,對可行駛區域、當前行駛區域的分割結果較好。
另一方面,模型對路邊停靠車輛的識別效果相對較低,從而影響了整體的識別率;從原理角度分析,路邊停靠車輛角度多為車頭與道路垂直,而數據集中車輛標注多為車輛與道路平行,因此識別率較低是由數據集樣本不夠導致的,如果再此基礎上增加車輛標注的角度與數量,識別效果可以更好。
綜合而言,本項目依托卷積神經網絡對圖像特征提取的優勢,在自行制作的數據集基礎上較好地模擬實現了無人駕駛的視覺識別,展現了深度學習技術在各個領域的實用性、適用性。
4 ?結束語
使用深度學習技術,在無人駕駛領域實施視覺識別,具有較高的識別率。本文采用卷積神經網絡Mask R-CNN作為視覺識別的模型,對道路行人、交通標志、道路車輛識別情況較好,對可行駛區域分割效果清晰。深度學習技術在無人駕駛領域有很高的應用價值。
基金項目
城市環境下無人駕駛中目標識別和可行駛區域分割
致謝
感謝吉林大學通信工程學院玄玉波老師的指導,同時感謝編輯、審稿專家的意見與指正!
參考文獻
[1] 周開利. 神經網絡模型及其MATLAB仿真程序設計[M]. 北京: 清華大學出版社, 2005.
[2] 汪榆程. 無人駕駛技術綜述[J]. 科技傳播, 2019, 11(6): 147-148.
[3] 周飛燕, 金林鵬, 董軍. 卷積神經網絡研究綜述[J]. 計算機學報, 2017, 40(6): 1229-1251.
[4] 陳先昌. 基于卷積神經網絡的深度學習算法與應用研究[D]. 杭州: 浙江工商大學, 2014.
[5] 張沁怡. 基于深度卷積網絡的人車檢測及跟蹤算法研究[D]. 北京: 北京郵電大學, 2019.
[6] VGG Image Annotator[OL]. http://www.robots.ox.ac.uk/~vgg/software/via/.
[7] Townsend J T. Theoretical analysis of an alphabetic confusion matrix[J]. Perception & Psychophysics, 1971, 9(1): 40-50.
[8] 趙琛, 王昱潭, 朱超偉. 基于幾何特征的靈武長棗圖像分割算法[J]. 計算機工程與應用, 2019, 55(15): 204-212.
[9] Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative Adversarial Networks[J]. Advances in Neural Information Processing Systems, 2014, 3: 2672-2680.
[10] Li Z, Dekel T, Cole F, et al. Learning the Depths of Moving People by Watching Frozen People[C]// IEEE International Conference on Computer Vision and Pattern Recognition, California, USA, 2019.
作者簡介:
李嘉寧(1999—),男,山東泰安人,在讀本科生。研究方向:圖像處理。
E-mail: jnli2021@163.com
(收稿日期:2020-06-12)
Vision Recognition of Unmanned Driving Based on Deep Learning
LI Jia-ning, LIU Yang, HU Xin-yue, LIU Jian-tian, CHEN Zong-wen
(College of Communication Engineering, Jilin University, Changchun 130012, China)
Abstract: The development of big data technology and the improvement of parallel computing capability based on Graphical Processing Unit (GPU) jointly promote the application of deep learning algorithm in the field of visual recognition of unmanned driving. On the Ubuntu 16.04 operating system, the Python experimental environment is built, and the visual recognition experiment of unmanned driving based on convolutional neural network, i.e. Mask R-CNN is carried out. The software and hardware of training and testing are realized by using the GTX 1080Ti GPU and cuDNN video acceleration card. The confusion matrix and average accuracy are introduced to evaluate the performance of the convolution neural network model. The results show that the visual recognition effect is good and the reliability is preferable, which shows that the deep learning technology has high application value in such fields.
Key words: Deep Learning; Unmanned Driving; Convolutional Neural Network; Visual Recognition; Performance Evaluation
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
