ON-LSTM和自注意力機制的方面情感分析
2020-09-02 06:52:20張忠林李林川朱向其馬海云
小型微型計算機系統 2020年9期
張忠林,李林川,朱向其,馬海云
1(蘭州交通大學 電子與信息工程學院,蘭州730070)2(天水師范學院 電子信息與電氣工程學院,甘肅 天水 741001)
E-mail:llc_1995@163.com
1 引 言
文本情感分析,又稱意見挖掘(Opinion Mining)、傾向性分析,是對具有主觀情緒色彩的文本信息進行分析、處理、歸納和研究的過程[1].隨著大數據技術的快速發展,利用計算機技術對各大社交媒體或網絡平臺上的評論、留言等文本信息中蘊含的觀點和輿論進行情感分析,越來越受到各大企業和研究人員的重視和關注.
文本情感分析最早是由Nasukawa[2]提出,用于判斷句子所表達的情感極性.早期的文本情感分析更多的是關注句子整體的情感傾向,而隨著研究的深入,研究者們將文本情感分析細分為文檔粒度(document level)、句子粒度(sentence level)、方面粒度(aspect level)三種粒度.其中,與文檔級和句子級的情感分析不同,方面情感分析(Aspect Based Sentiment Analysis,ABSA)同時考慮了目標詞與情感信息的關系,通過給定句子和主題詞,方面情感分析可以判斷出主題詞在句子中的情感傾向.同一個句子中針對不同的方面可能會有不同的情感傾向,例如,在句子“食物很好,但服務很差”中,“食物”方面的情感極性是積極的,而“服務”方面的情感極性則是消極的.因此,基于方面的情感分析能提供比一般情感分析更細粒度的信息,更具有研究價值和商業價值,是目前自然語言處理(Natural Language Processing,NLP)領域里最熱門的研究方向之一.
Hochreiter和Schmidhuber[3]在1997年提出了長短時記憶(Long Short Term Memory,LSTM)神經網絡模型,有效解決了循環神經網絡(Recurrent Neural Network,RNN)在處理文本中上下文由于情感詞的長期依賴而導致的梯度爆炸和梯度消失問題.隨著神經網絡在NLP領域的廣泛應用,許多學者開始使用LSTM進行情感傾向分析.吳鵬等人[4]使用雙向LSTM(Bidirectional Long Short Term Memory,Bi-LSTM)與CRF結合提出了一種網民負面情感識別模型EBiLSTM,用來判斷網民負面情感和非負面情感的類別.孟仕林等人[5]詞嵌入基礎上增加情感向量,并采用BiLSTM獲取文本的特征信息進行情感分類.Al-Smadi等人[6]使用兩種LSTM神經網絡實現阿拉伯酒店評論的方面情感分析.王文凱等人[7]通過在輸出端融入Tree-LSTM提高了非連續詞之間的關聯性,在微博情感分析上表現良好.同時,也有許多學者通過改變LSTM內部門結構提高情感分類的準確率.Greff[8]在論文中探討了基于Vanila LSTM[9]的8個變體,并比較了他們之間的性能差異.Cho等人[10]在2014年提出門循環單元(Gated Recurrent Unit,GRU),通過將LSTM中的遺忘門和輸入門合成單一的更新門(update gate),并混合了細胞狀態和隱藏狀態,旨在解決LSTM計算開銷較大的缺點,在小樣本數據集中表現優異.
隨后,Bahdanau等人[11]首次將Attention機制由計算視覺領域引入到NLP領域中,利用Attention機制在輸入的文本信息中有選擇性地學習重要信息并在模型輸出時將其與輸出序列相關聯.Zhou等人[12]基于Attention機制和Bi-LSTM提出了基于特征方面的關系分類模型.Tang等人[13]針對目標依賴的細粒度文本情感分析任務提出了TC-LSTM、TD-LSTM兩個模型,通過兩個LSTM從左右兩個方向獲取情感詞與上下文的關聯,從而提升方面情感分析效果.Wang等人[14]提出了一種結合注意力機制的ATAE-LSTM模型,通過attention機制給予方面情感項不同的權重,使得模型能更好地分析情感極性.曾鋒等人[15]提出一種基于雙層注意力循環神經網絡模型,通過雙層注意力分別捕獲不同單詞的重要性.彭祝亮等人[16]提出一種結合雙向長短記憶網絡和方面注意力模塊(BLSTM-AAM)的網絡模型,利用方面注意力對不同的方面同時獨立訓練,充分提取特定方面的隱藏信息.
以上的模型都只考慮了方面情感項在模型輸入層或隱藏層處理過程中的結合,并沒有體現出文本的層級結構信息.為解決以上問題,本文提出了一種方面情感分析模型,在隱藏層加入了有序神經元(Ordered Neurons),使得模型能無監督地學習句子的句法結構,并在連接層采用自注意力(Self-Attention)機制,讓模型更容易獲取到方面情感詞在句子中的情感極性.本文提出的模型不僅提高了方面情感分析的準確率,而且在神經網絡中融合了層級結構,使得模型更容易判斷句子中的方面情感傾向.
2 相關工作
2.1 ELMo預訓練模型
ELMo(Embeddings from Language Models)是由Peters等人[17]提出的一種動態預訓練模型.常用的Word2Vec方法[18]本質上是一種靜態模型,使用Word2Vec訓練完的詞匯不會跟隨上下文的場景變化而發生變化.例如,針對“蘋果”這一詞匯,文本序列“我買了三斤蘋果”中的“蘋果”表示一種水果;“我買了一個蘋果8”中的“蘋果”表示一種手機品牌,但在Word2Vec中使用的是同一個詞向量進行表示.這導致在多義詞情況下使用Word2Vec預訓練時會得到一個混合多語義的固定向量表示,降低了預訓練效果.相比較Word2Vec,ELMo模型很好地解決了這一問題.
ELMo基于雙層LSTM(Bidirectional Long Short Term Me-mory,Bi-LSTM),主要做法是經過先訓練一個完整的語言模型(Language Model,LM),再利用語言模型處理需要訓練的文本,依據上下文生成能改變語義的詞嵌入向量.它是由前向語言模型和后向語言模型兩部分組成,其計算過程如式(1)、式(2)所示:
(1)
(2)
其中,(t1,t2,…,tN)表示N個單詞的序列.
雙層語言模型(Bidirectional Language Models,BiLM)整合了上面的兩種語言模型,目標函數為前后向語言模型的聯合對數似然函數,如式(3)所示:
(3)
其中,Θx表示輸入的標記嵌入(token embedding),Θs表示輸出的softmax層參數.
ELMo的模型結構如圖1所示.
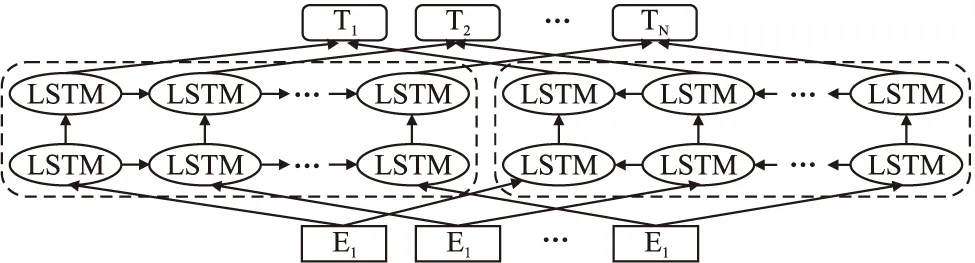
圖1 ELMo模型結構圖Fig.1 Model structure of ELMo
ELMo模型在解決很多NLP下游任務中表現得十分優秀,通常采用與初始詞向量或隱藏層輸出向量拼接,在SNLI、SQuAD等多個數據集上的性能都有所提升.
2.2 ON-LSTM模型
有序神經元長短時記憶網絡(Ordered Neurons Long Short-Term Memory,ON-LSTM)通過對神經元進行特定排序將層級結構(樹結構)整合到傳統的LSTM中,使得LSTM神經元自動學習到層級結構信息[19].
傳統的LSTM模型主要解決長距離依賴所產生的梯度消失和梯度爆炸問題,其更新過程如式(4)-式(9):
ft=σ(Wfxt+Ufht-1+bf)
(4)
it=σ(Wixt+Uiht-1+bi)
(5)
ot=σ(Woxt+Uoht-1+bo)
(6)
(7)
(8)
ht=ot°tanh(ct)
(9)
其中,ft,it,ot分別代表LSTM模型中的遺忘門、輸入門和輸出門,xt和ht-1表示當前信息和歷史信息,σ表示sigmoid函數,tanh是雙曲正切函數.

ft=σ(Wfxt+Ufht-1+bf)
(10)
it=σ(Wixt+Uiht-1+bi)
(11)
ot=σ(Woxt+Uoht-1+bo)
(12)
(13)
(14)
(15)
(16)
(17)
ht=ot°tanh(ct)
(18)
ON-LSTM的模型結構如圖2所示.

圖2 ON-LSTM模型結構圖Fig.2 Model structure of ON-LSTM
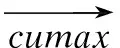
(19)
(20)
2.3 自注意力機制
自注意力機制在文獻[20]中首次提出,是一種注意力機制的特殊情況,主要用于關注句子本身從而抽取出相關信息.
注意力機制最早在計算機視覺圖像領域被提出,通過模仿人眼快速掃描事物,并將聚焦點設置到關注的目標區域.隨后Bahdanau等人[11]將其應用到NLP領域并取得不錯的效果.其本質為一個查詢(Query)到一系列鍵值對(Key-Value)的映射,具體做法為采用Encoder-Decoder框架,將Query和每個Key進行相似度計算得到權重,然后使用softmax函數進行歸一化,最后將權重和相應的鍵值Value進行加權求和得到最終的Attention.其基本模型如圖3所示.

圖3 注意力基本模型Fig.3 Attention model
其公式如式(21)所示:
(21)
其中,Q∈n×dk,K∈m×dk,V∈m×dv,當Q(Query)、K(Key)、V(Value)三個矩陣均來自于同一輸入,即Q=K=V時,則模型變為自注意力機制.
3 ON-LSTM-SA模型
本文在以上理論基礎上提出了基于ON-LSTM和自注意力模型的方面情感分析模型(Ordered Neurons Long Short-Term Memory-based and Self-Attention Mechanism-based Aspect Sentiment Analysis Model,ON-LSTM-SA),模型主要按照以下三個方面進行構建:
1)對于預訓練的詞向量部分,通過引入ELMo模型獲得語義信息,提高訓練效果;
2)針對target-dependent情感任務,模型加入target vector與context vector進行拼接,并作為輸入端信息;
3)將數據集送入ON-LSTM-SA模型中,通過分層結構獲取神經元的有序信息,獲得方面情感.
4)在輸出端通過Self-Attention機制學習句子內部的詞依賴關系,捕獲句子的內部結構.
ON-LSTM-SA模型結構如圖4所示.

圖4 ON-LSTM-SA模型結構圖Fig.4 Model structure of ON-LSTM-SA
3.1 預訓練
本文在原始語料庫上通過GloVe分詞得到初始詞向量,然后將詞向量送入ELMo模型中進行預訓練.與其他預訓練模型不同,ELMo模型使用所有層輸出值的線性組合作為word embedding值.對于某一個單詞序列,一個L層的BiLM需要由2L+1個向量表示,其計算公式如式(22):
(22)

ELMo模型將多層LSTM的輸出Rk整合為一個向量,低層的Bi-LSTM負責捕捉語料中的句法信息,高層Bi-LSTM負責捕捉語料中的語義信息,并將向量正則化后輸入到softmax層,作為學到的一組權重.其計算過程如式(23)所示:
(23)
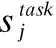
在此基礎上,將ELMo詞向量與初始詞向量通過殘差連接(residual connection)架構銜接起來,形成具有上下文語義的詞向量,其計算過程如式(24)所示:
(24)
3.2 輸入層
針對方面情感分析任務,模型在輸入層的預訓練詞向量基礎上添加了target vector,具體做法是將預訓練好的詞向量wk和target words拼接起來做word embedding,然后將向量求平均值,得到vtarget,最后將vtarget和vcontext拼接起來作為輸入層.其計算過程如式(25)-式(26)所示:
vtarget=avg(embedding([wk,wtarget]))
(25)
input=[vtarget,vcontext]
(26)
3.3 隱藏層
一個自然句子通常可以通過樹狀結構表示成一些層級結構,這些抽象出來的結構就是語法信息,而LSTM以及普通的神經網絡中的神經元通常是無序的,無法獲取有序信息.ON-LSTM則試圖通過建立層級關系來獲取這種信息,層級越低代表語言中顆粒度較小的結構,對應的編碼區間則越小,傳輸距離也越短,更容易被遺忘門過濾掉;層級越高代表語言中顆粒度較大的結構,對應的編碼區間越大,意味著層級信息在對應的編碼區間內保留時間更久.其原理示意圖如圖5所示.

圖5 ON-LSTM原理示意圖Fig.5 Schematic diagram of ON-LSTM
其中,圖5(a)展示了ON-LSTM的一系列tokenS=(x1,x2,x3)對應的解析樹形式.圖5(b)將圖5(a)的解析樹轉換為層級結構,可以發現S和VP節點都跨越了一個以上的時間長度.圖5(c)將圖5(b)的層級結構進行矩陣化,最終形成ON-LSTM隱藏層神經元的細胞狀態.其中,在每個時間步驟中,給定一系列輸入字符,神經元首先將其完全更新,而由于三組神經元更新頻率不同,最上層的組更新頻率較低,最下層的組則頻繁更新.圖5中(c)以顏色深淺表示更新頻率,顏色程度越深代表更新頻率更快,而顏色越淺代表信息更新越慢,以此劃分出層級結構.
在隱藏層中,本文根據target words的前后上下文建模,給定輸入序列{xt},在每次更新ct之前,首先預測歷史信息ht-1的層級df:
df=F1(xt,ht-1)
(27)

pf=softmax(Wfxt+Ufht-1+bf)
(28)
得到歷史信息的層級計算公式:
(29)
其中,pf(k)表示指向向量pf的第k個元素.這樣,我們就能使用序列
(30)
來表示輸入序列的層級變化.有了這個層級序列后,按照貪心算法輸出對應的層級序列{df,t},找出層級序列中最大值所在的下標,然后將輸入序列分區為[xt
輸入:蘋果的顏色是什么
輸出:
{
{
{
蘋果
的
},
{
顏色
是
}
},
{
什么
}
}
模型使用兩個ON-LSTM模型從左往右和從右往左分別訓練模型,期間前一個神經元的有序信息傳遞給下一個神經元進行分層處理,直至目標詞,最后輸出隱藏層詞向量.
在Self-Attention層中,分別將左右兩個hidden vector利用公式做Self-Attention計算來學習文本內部的詞依賴關系.最后,將左Self-Attention和右Self-Attention拼接傳入softmax層轉換為概率輸出,具體見式(31)-式(34):
hi=ON-LSTML([vi,vtarget]),i=1,2,…,r-1
(31)
hj=ON- LSTMR([vj,vtarget]),j=l+1,…,n
(32)
(33)
(34)
其中,l表示方面情感的類別數.
4 實驗與分析
4.1 實驗環境
本文采用流行的深度學習框架Keras完成實驗,采用GPU加速,分詞工具采用GloVe,實驗環境配置具體如表1所示.

表1 實驗環境配置Table 1 Experimental environment configuration
4.2 實驗數據集和評價指標
本文采用SemEval2014 Task 4、SemEval2017 Task4數據集進行實驗,該數據集主要用于細粒度情感分析,分為訓練集和測試集,其中包含laptop、restaurant和twitter三個不同領域的用戶評論數據,每一條評論包括評論內容、方面項和對應的方面情感極性,數據樣本的情感極性分為Positive、Negative和Neural.本文利用NLTK工具庫將數據集中的訓練集按照9:1比例切分成訓練集和驗證集,該數據集的主要數據統計信息如表2所示.
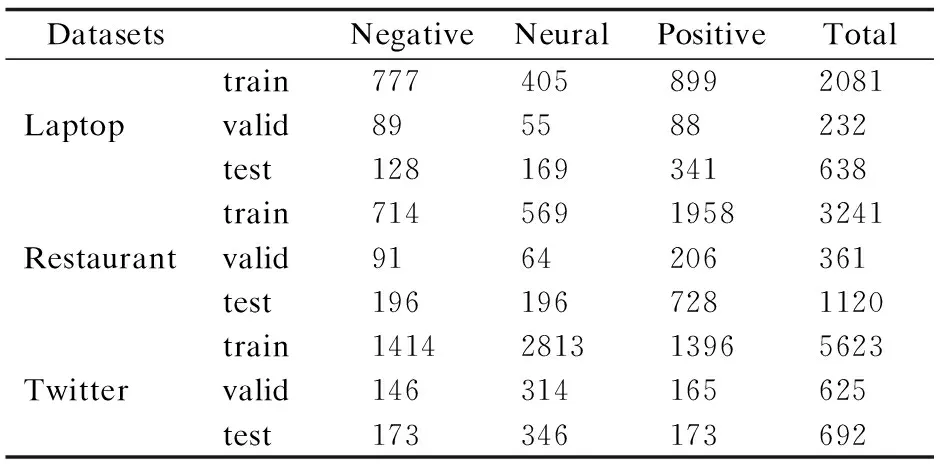
表2 實驗使用數據統計Table 2 Experimental data statistics
本文采用準確率(Accuracy)和F1值作為方面情感分析的評價標準,具體計算公式分別見式(35)和式(36).
(35)
(36)
其中,T表示預測正確的樣本數,N為樣本總數,準確率通常使用百分比表示;F1值計算公式中recall代表召回率,precision代表正確率.
4.3 參數設置與訓練
本文首先使用Glove分詞工具對數據集中的文本進行分詞,然后使用Word2Vec工具將分詞后的文本轉換為詞向量,從而進行無監督的詞向量學習.實驗結合Keras和TensorFlow框架,參數設置方面,將詞向量維度大小設置為300維,全連接層大小為128維,ON-LSTM輸入維度300維,樹結構層級為5層.
模型訓練方面,實驗采用隨機梯度下降方法,通過設置批量樣本大小為64進行模型訓練,并采用Adam優化算法,初始化學習率為0.001,為防止過擬合加入了Dropout機制,Dropout參數設置為0.2.詳細參數設置如表3所示.
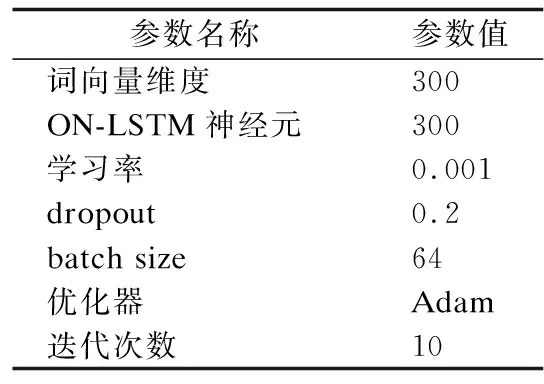
表3 模型參數設置Table 3 Model parameter settings
4.4 對比實驗與結果分析
將本文提出的ON-LSTM-SA模型與以下模型進行對比實驗:
1)LSTM:采用標準LSTM神經網絡進行方面情感分析.
2)TD-LSTM:采用兩個LSTM,圍繞target word進行上下文建模,使得左右兩個方向的上下文都可以用作情感分類的特征表示.
3)TC-LSTM:在TD-LSTM模型的基礎上增加了target vector,并跟輸入詞向量拼接以后作為輸入向量,整合了target word與context word的相互關聯信息.
4)AE-LSTM:主要是將LSTM隱藏層與aspect embedding層結合起來,區分出對特定aspect更重要的上下文信息.
5)ATAE-LSTM:在AE-LSTM的基礎上,將情感嵌入(aspect embedding)和詞嵌入(word embedding)進行拼接,共同組成模型的輸入端,更充分利用了方面信息.
所有模型都采用相同數據集進行實驗,并盡量參考原論文中的超參數,以達到模型理論準確率.實驗結果如表4所示.

表4 模型準確率(Acc)對比Table 4 Comparison of model accuracy

表5 模型F1值(Macro-F1)對比Table 5 Comparison of the Marcro-F1 score ofmodel
從表4、表5中可以看出,相較于標準LSTM神經網絡模型,其他5種模型都在一定程度上提高了方面情感分析的準確率和F1值.TD-LSTM和TC-LSTM都考慮了target word在上下文中的影響,對比LSTM效果提高了2%~3%,說明target word對方面情感分析輸入方面具有提升作用.AE-LSTM、ATAE-LSTM在LSTM的隱藏層拼接了aspect embedding和word embedding,并通過增加Attention機制提高模型效果,同樣也取得不錯了效果.
在本文提出的模型中,ON-LSTM-SA模型在restaurant和twitter兩個數據集上的實驗效果明顯比其他模型更好,準確率相較于標準LSTM分別提高了5.9%和6.5%,相較于TD-LSTM分別提高了2.9%和3.4%,F1值方面相較于標準LSMT分別提高了7.1%和6.8%,相較于TD-LSTM分別提高了4.7%和3.1%.
綜上所述,本文提出的模型通過實驗證明,對輸入動態生成、添加層級結構、使用Self-Attention機制對方面情感分析具有提升作用.
5 結束語
傳統的LSTM神經網絡能夠有效處理序列問題,而層級結構使得神經元能夠獲取有序信息.同時,Attention機制能使得模型獲得對aspect word的權重大小,從而更好判斷方面情感極性.在此基礎上,本文提出了一種基于ON-LSTM和自注意力機制的ON-LSTM-SA模型,該模型在輸入端融入了對詞向量動態預訓練的ELMo模型,同時在輸入層整合了target word和context word,使得輸入具有一定語義信息,然后在隱藏層中利用ON-LSTM的層級結構,使得神經元攜帶有序信息,根據詞語粒度在區間上跨度的大小從兩個方向獲得情感關鍵詞,再將信息傳遞給Self-Attention做進一步方面情感極性判斷,最終生成對句子的方面情感分析.通過實驗證實,本文提出的模型在多個數據集中效果優秀,具有一定的應用價值.
雖然ON-LSTM-SA模型在方面情感數據集上實驗取得了較好的效果,但由于模型內部分層結構,以及前期需要通過ELMo動態預訓練,因此訓練時長比一般模型較長.下一步的工作將通過與更先進的預訓練模型例如BERT、XLNet等進行結合,降低預訓練時長,并進一步提升語義信息切分.
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
山東工業技術(2016年15期)2016-12-01 05:31:22
小學教學參考(2015年20期)2016-01-15 08:44:38
