基于一維卷積神經(jīng)網(wǎng)絡和降噪自編碼器的駕駛行為識別
2020-09-02 01:22:38楊云開范文兵彭東旭
計算機應用與軟件 2020年8期
關鍵詞:模型
楊云開 范文兵 彭東旭
(鄭州大學信息工程學院 河南 鄭州 450000)
0 引 言
駕駛行為分類在過去幾年里受到了不同行業(yè)的關注。在汽車行業(yè)中,對駕駛行為進行分類,例如在注意力不集中情形下的駕駛,對保證駕駛員的安全至關重要,尤其是在半自動和高度自動化的車輛中。同樣,在汽車保險行業(yè),對駕駛行為進行分類和監(jiān)控對于風險評估和保險費都至關重要[1]。
現(xiàn)已出現(xiàn)了許多方法來解決駕駛行為分類問題。根據(jù)所使用的傳感器數(shù)據(jù),這些方法可以分為兩種主要方法,即基于車輛檢測的方法和基于駕駛員檢測的方法。基于車輛檢測的方法利用不同的車輛傳感器數(shù)據(jù)對一組駕駛行為或駕駛風格進行分類。車輛傳感器的數(shù)據(jù)包括慣性測量數(shù)據(jù),車輛的方位、速度、加速度和制動。基于駕駛員檢測的方法是利用車內(nèi)的活動傳感器(通常是攝像頭)來觀察駕駛員的直接表現(xiàn),例如注視方向、腦電圖波動、頭部和身體的姿勢。
文獻[2]提出一種使用動態(tài)時間規(guī)整(DTW)和基于智能手機的傳感器融合(加速度計、陀螺儀、磁強計、GPS、視頻)來檢測、識別駕駛行為的系統(tǒng),雖然識別率很高,但是需要一個龐大的數(shù)據(jù)庫。文獻[3]使用貝葉斯非參數(shù)模型與LDA模型相結(jié)合,以此將抽象的線性分段與具體的駕駛行為相聯(lián)系,雖然識別效果很好,但是在計算上有很大的復雜性。文獻[4-5]通過智能手機內(nèi)置的傳感器采集數(shù)據(jù),然后用深度學習模型對駕駛行為識別,但是只能識別縱向運動,無法識別橫向運動(轉(zhuǎn)向)。文獻[6]通過貝葉斯模型來處理駕駛數(shù)據(jù),可以無監(jiān)管地推斷出具體駕駛行為,該算法效率和識別精度都比較高。
上述研究雖然都有很高的識別率,但都沒有考慮過時間復雜度的影響,也都沒有采用降維算法。本文方法結(jié)合了降維和神經(jīng)網(wǎng)絡設計,不僅降低了時間復雜度還具有高識別率。常見降維算法有PCA、LDA和LPP等,這些傳統(tǒng)的降維方法只能保留數(shù)據(jù)的單一特征,會造成數(shù)據(jù)特征信息的丟失。降噪自編碼器(DAE)能更好地挖掘數(shù)據(jù)的非線性特性,并能給壓縮數(shù)據(jù)的方式提供很大的靈活性[7],故本文采用DAE進行降維處理。實驗獲得的駕駛行為數(shù)據(jù)集為時間序列數(shù)據(jù),具有連續(xù)且局部相關性高等特點,而一維卷積神經(jīng)網(wǎng)絡(1D-CNN)能夠有效地捕獲時間和空間結(jié)構(gòu)的相關性,因此本文采用一維卷積神經(jīng)網(wǎng)絡進行駕駛行為識別。
1 模型介紹
1.1 一維卷積神經(jīng)網(wǎng)絡(1D-CNN)
CNN被廣泛應用在圖像和計算機視覺領域。在CNN的輸入層中,數(shù)據(jù)輸入的格式與全連接神經(jīng)網(wǎng)絡的輸入格式(一維向量)不同。CNN的輸入層的輸入格式保留了圖片本身的結(jié)構(gòu)(二維矩陣),而且CNN中的過濾器、特征圖等內(nèi)部結(jié)構(gòu)也都是二維的,其結(jié)構(gòu)如圖1所示。但傳感器數(shù)據(jù)都為一維信號,無法輸入到CNN中,所以本文采用保留了CNN的局部連接和權(quán)值共享等特性的1D-CNN[8]。1D-CNN中的輸入是一維向量,過濾器、池化層等內(nèi)部結(jié)構(gòu)也都是一維的,其結(jié)構(gòu)如圖2所示。
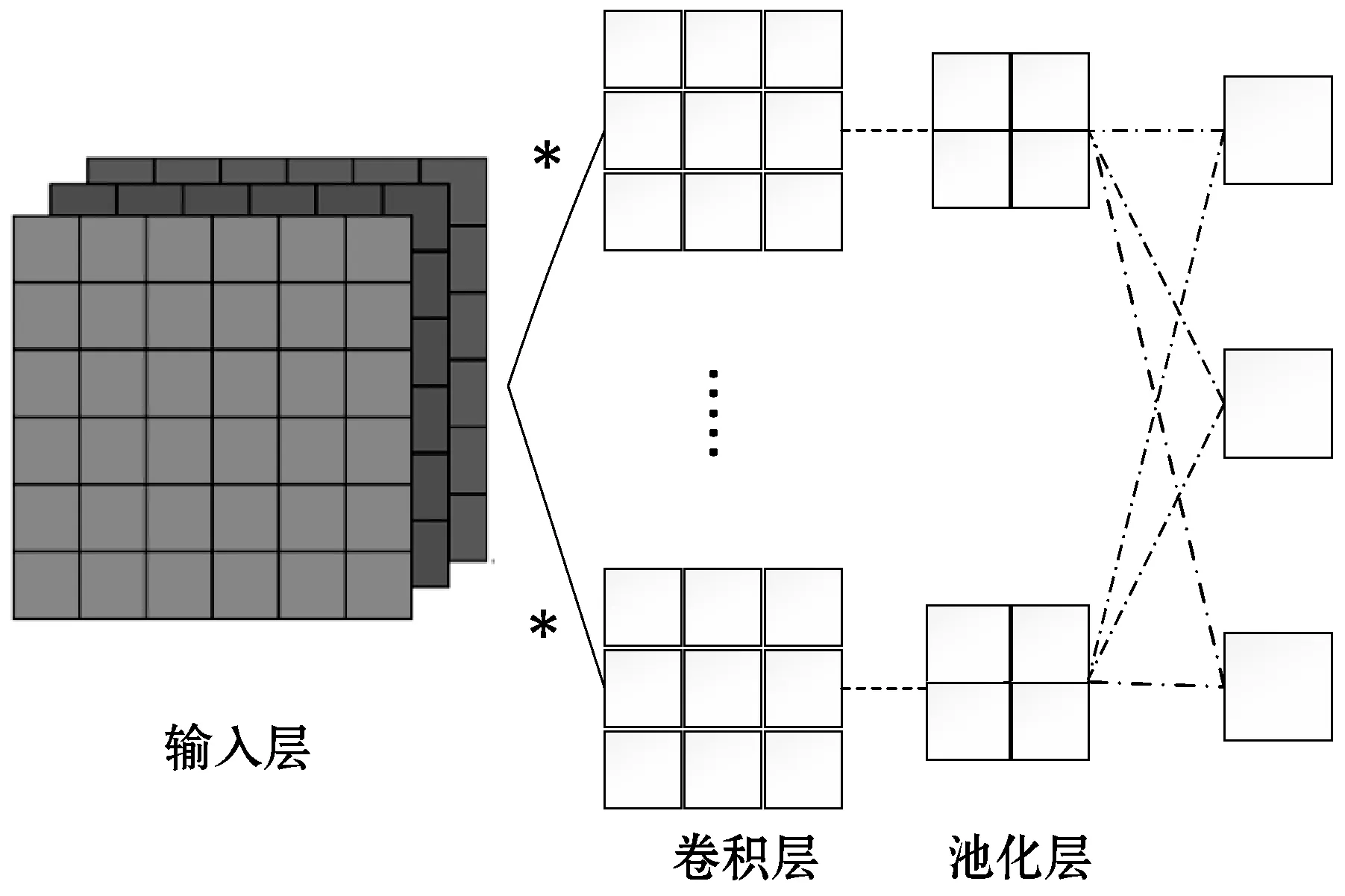
圖1 二維卷積神經(jīng)網(wǎng)絡結(jié)構(gòu)
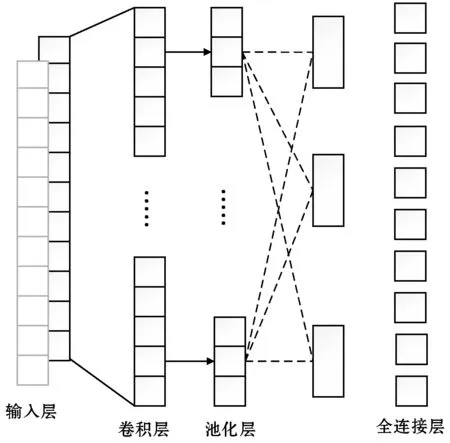
圖2 一維卷積神經(jīng)網(wǎng)絡結(jié)構(gòu)
1.2 降噪自編碼器(DAE)
自動編碼器(Auto-encoder)是一種降維方法,通過訓練具有小中心層的多層神經(jīng)網(wǎng)絡,將高維數(shù)據(jù)轉(zhuǎn)換為低維數(shù)據(jù)。AE是一種典型的三層神經(jīng)網(wǎng)絡。在隱藏層和輸入層之間有一個編碼過程,在輸出層和隱藏層之間有一個解碼過程。自動編碼器通過對輸入數(shù)據(jù)的編碼操作得到編碼表示(編碼器),通過對隱含層的輸出解碼操作得到重構(gòu)的輸入數(shù)據(jù)(解碼器),隱含層的數(shù)據(jù)就是降維數(shù)據(jù)。然后定義重構(gòu)誤差函數(shù)來測量自動編碼器的學習效果。基于誤差函數(shù),可以添加約束條件,生成各種類型的自動編碼器。典型的AE網(wǎng)絡結(jié)構(gòu)如圖3所示[9]。

圖3 自動編碼器的網(wǎng)絡結(jié)構(gòu)
編碼器和解碼器以及損失函數(shù)如下所示:
編碼器:h=δ(Wx+b)
(1)

(2)
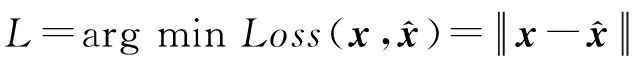
(3)
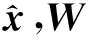
DAE就是AE改進版,通過加入噪聲來破壞原始數(shù)據(jù),然后將損壞的數(shù)據(jù)作為輸入層輸入到神經(jīng)網(wǎng)絡中。神經(jīng)網(wǎng)絡的重構(gòu)結(jié)果應與原始數(shù)據(jù)近似,通過這種方法,可以消除擾動,并獲得穩(wěn)定的結(jié)構(gòu)[10]。原始輸入數(shù)據(jù)x通過加入噪聲得到干擾輸入x′,然后輸入到編碼器中得到特征表達h,再通過解碼器將h映射到輸出層,算法流程與AE一樣。加噪聲主要有兩種方法,一種方法是加入高斯噪聲,即x′=x+ε,ε∈(0,δ2);另一種方法是加入二元掩蔽噪聲,即以一定概率把輸入層節(jié)點的值設置為0。
2 基于DAE+1D-CNN的識別模型
實驗獲得的駕駛行為數(shù)據(jù)集為時間序列數(shù)據(jù),具有連續(xù)且局部相關性高等特點,而一維卷積神經(jīng)網(wǎng)絡能夠有效地捕獲數(shù)據(jù)時間和空間結(jié)構(gòu)的相關性,因此一維卷積神經(jīng)網(wǎng)絡很適合用在駕駛行為識別中。為了能夠同時輸入三個特征向量(分別對應加速度、陀螺儀數(shù)據(jù)和磁感性強度),使用3通道的1D-CNN。同時為了解決卷積神經(jīng)網(wǎng)絡時間復雜度高的問題,使用DAE對初始數(shù)據(jù)進行降維處理。本文提出了一種應用于駕駛行為分類的神經(jīng)網(wǎng)絡結(jié)構(gòu)DAE+1D-CNN,如圖4所示。

圖4 基于降噪自編碼器和一維卷積神經(jīng)網(wǎng)絡的識別模型
可以看出,該模型自左向右由四個模塊組成。
(1) 數(shù)據(jù)預處理:使用滑動窗口來提取數(shù)據(jù)片段,數(shù)據(jù)片段為一個250×3的矩陣,再將此矩陣歸一化并使用中位值平均濾波器去除噪聲干擾,最后得到輸入樣本V{ax,gy,mz}。
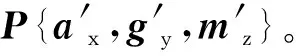
DAE模型結(jié)構(gòu)設置一層隱藏層網(wǎng)絡結(jié)構(gòu),隱藏節(jié)點設為200。隱含層激活函數(shù)采用tanh函數(shù),輸出層的激活函數(shù)采用Sigmoid函數(shù),訓練方法采用變學習率動量算法,梯度下降算法采用Mini-batch梯度下降法,采用L2正則化來防止過擬合,采用的損失函數(shù)為:
(4)

1D-CNN模型結(jié)構(gòu)設置為2個卷積層和2個池化層。池化層使用最大池化(Max pooling)。激勵函數(shù)并沒有使用ReLu函數(shù),ReLu函數(shù)一般用于CNN處理圖片等二維數(shù)據(jù)時,而本文的數(shù)據(jù)是一維數(shù)據(jù),且使用ReLu函數(shù)測試后識別效果很差,因此本文采用Sigmoid函數(shù)。輸出層采用Softmax分類器。采用的訓練方法和梯度下降算法與DAE一樣,損失函數(shù)并沒有使用L2正則化,而是使用了dropout來防止過擬合[12]。損失函數(shù)為交叉熵損失函數(shù)(Cross-entropy):
(5)
(4) 分類識別:Logistics回歸只能實現(xiàn)二分類,而Softmax分類可以實現(xiàn)多分類,因此本文使用Softmax分類器進行分類識別。其中y(i)∈{1,2,…,k},k是類別總數(shù)[13]。將輸入x判別為l類的概率為:
(6)
算法流程進一步解釋了該模型的實現(xiàn)細節(jié):
輸入:三種傳感器數(shù)據(jù)。
輸出:九種駕駛行為的概率值。
步驟1數(shù)據(jù)預處理得到樣本V{ax,gy,mz}。

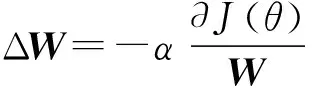
步驟4卷積層:將P代入C=δ(conv2(wc,P)+b)得到特征圖C。
步驟7y(i)為步驟6的識別結(jié)果,將y(i)代入式(5)得到交叉熵損失函數(shù),使用步驟3的方法使損失函數(shù)降至最小。不斷地循環(huán)步驟4至步驟7直到交叉熵損失函數(shù)降至最低并且收斂。
3 數(shù)據(jù)預處理
3.1 樣本數(shù)據(jù)選擇
過去大多數(shù)駕駛模式識別系統(tǒng)只使用加速度計的數(shù)據(jù)。本文使用加速度計、陀螺儀和磁力傳感器的傳感器融合輸出來檢測和識別駕駛運動。陀螺儀數(shù)據(jù)可以使車輛轉(zhuǎn)彎運動更清晰地顯示,因為陀螺儀測量的是車輛的轉(zhuǎn)向加速度,而磁力傳感器可以檢測到車輛行駛方向的磁感性強度,每個方向的磁感性強度都是固定的,當車輛行駛方向變化時磁感性強度也隨之改變(相當于一個羅盤)。因此三者配合使用,可以更準確地讀出車輛的姿態(tài)(方向)。假設陀螺儀值為G={gx,gy,gz}(rad/s),加速度計值A={ax,ay,az}(m/s2),設備磁力傳感器M={mx,my,mz}(μT)。
本文中使用ax、gy和mz作為樣本數(shù)據(jù)進行分類,因為在A、G、M中只有這三個單軸數(shù)據(jù)能反映車輛方向的變化。本文認為集合T={ax,gy,mz}是區(qū)分駕駛行為的最佳信號選擇,將在下文仿真實驗中證明。同時也將檢驗使用純G、純A和純M數(shù)據(jù)的準確性。
3.2 提取數(shù)據(jù)片段
獲取到集合T的數(shù)據(jù)后,提取n個樣本數(shù)據(jù)段。數(shù)據(jù)段的數(shù)量取決于所涉及的應用類型。增加段的長度可以提高識別精度,但是會使不同活動之間的邊界變得不那么清晰。綜合考慮本文采用10 s的非重疊窗口大小對原始慣性時間序列數(shù)據(jù)進行分割。使用分段而不是單個數(shù)據(jù)點的原因是由于原始慣性測量的高度波動使得單個數(shù)據(jù)點的分類不切實際。因此,使用分別應用于ax、gy、mz軸上的滑動窗口來獲得片段[14]。在25 Hz的數(shù)據(jù)采集頻率下,250次數(shù)據(jù)是一個數(shù)據(jù)段,將這個250×3的矩陣V{ax,gy,mz}作為識別模型的輸入樣本。
3.3 去噪聲干擾
在實際采集數(shù)據(jù)過程中會偶然出現(xiàn)脈沖性干擾,所采集的數(shù)據(jù)會存在噪聲,因此需要對原始數(shù)據(jù)進行濾波處理。本文選擇使用中位值平均濾波法[15],又稱防脈沖干擾平均濾波法,顧名思義就是專門用于消除脈沖性干擾方法,能濾除由偶然因素所引起脈沖性干擾所致的數(shù)據(jù)突變。
4 實驗仿真
4.1 實驗數(shù)據(jù)集
本文以內(nèi)置ARM處理器的智能手機作為駕駛行為數(shù)據(jù)采集硬件平臺。智能手機使用配置了線性加速度傳感器和陀螺儀以及磁力傳感器的榮耀V10和蘋果6S。智能手機被水平地放置在汽車儀表盤中間位置,x軸與儀表盤平齊,y軸垂直地面向上,z軸面向前進方向。汽車平臺為起亞賽拉圖和雪佛蘭賽歐3。數(shù)據(jù)收集軟件為phyphox(一個國外的傳感器數(shù)據(jù)測試軟件),圖5所示為使用該軟件進行傳感數(shù)據(jù)收集的結(jié)果。實驗采集了4名用戶的駕駛行為數(shù)據(jù),分別為直線行駛(SR)、起步(ST)、停車(P)、左轉(zhuǎn)(L)、右轉(zhuǎn)(R)、左變道(LL)、右變道(RL)、掉頭(U)和靜止(S)等九種駕駛行為。采樣頻率為25 Hz,共收集了超過3 600份樣本數(shù)據(jù),如表1所示。

圖5 數(shù)據(jù)采集工具

表1 實驗數(shù)據(jù)集
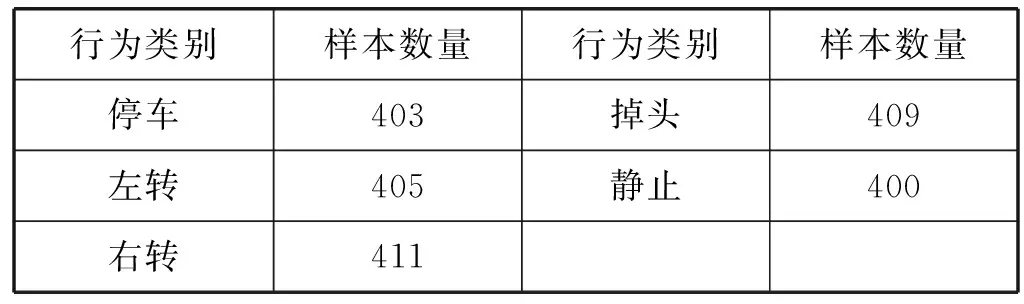
續(xù)表1
4.2 參數(shù)設置
整個實驗過程在MATLAB仿真環(huán)境中進行。把實驗數(shù)據(jù)分成三份:60%的訓練集,20%的交叉驗證集,20%的測試集。
DAE模型的參數(shù)設置:輸入層、隱藏層和輸出層的節(jié)點數(shù)分別為250、200、250,訓練批次大小(batch size)為10,學習率為0.01,L2正則化參數(shù)為0.02,最大迭代次數(shù)(epoch)為100,權(quán)值動量因子(Momentum)為0.9,學習率變化因子為0.9。
1D-CNN模型的參數(shù)設置:輸入:200×3的特征圖,3通道。第一層卷積:5×1大小的卷積核4個。第一層max-pooling:2×1的核。第二層卷積:3×1卷積核8個。第二層max-pooling:2×1的核。Softmax層:輸出為7。訓練批次大小(batch size)為10,最大迭代次數(shù)(epoch)為60,學習率為0.02,學習率變化因子為0.8,丟包率(Dropout level)為0.5,加入噪聲的比例(InputZeroMaskedFraction)為0.3。
4.3 實驗對比與結(jié)果分析
實驗1在探討DAE+1D-CNN模型對駕駛行為識別的具體效果之前,先驗證為什么集合T={ax,gy,mz}是區(qū)分駕駛行為的最佳信號選擇。將集合A、G、M和T的數(shù)據(jù)分別輸入到1D-CNN模型中,求得對應的識別率后進行對比分析。這四個集合中數(shù)據(jù)的樣本個數(shù)和維度都一樣,識別結(jié)果如表2所示。從表2可以看出集合T的識別率是最高的。
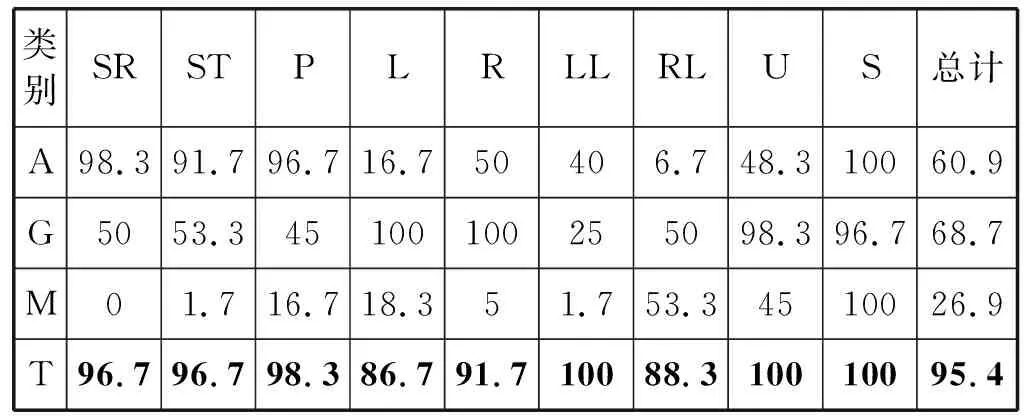
表2 A、G、M、T數(shù)據(jù)的識別率比較 %
實驗2探討使用DAE進行降維的原因,將輸入數(shù)據(jù)T分別利用DAE、主成分分析(PCA)、線性判別分析(LDA)、核主成分分析(KPCA)和局部保持投影(LPP)進行降維,將T中的三個單軸數(shù)據(jù)都從250維降到200維,然后輸入到同樣的1D-CNN結(jié)構(gòu)中,得到結(jié)果后與沒有經(jīng)過降維處理的1D-CNN進行比較,識別效果如圖6所示。
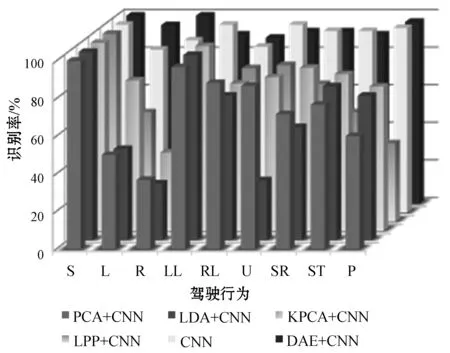
圖6 不同降維模型識別效果對比
可以明顯地看出,識別效果最好的是沒有經(jīng)過降維處理的1D-CNN模型和DAE+1D-CNN模型(后面兩排),它們兩個的平均識別率為95.4%和93.7%,1D-CNN模型比DAE+1D-CNN模型的識別率高了1.7%,這也是正常現(xiàn)象,因為即使是再好的降維算法也會造成數(shù)據(jù)信息的丟失。和其他降維算法相比,DAE的效果是最好的,其他幾種降維算法中效果最好的是KPCA,識別率為80.7%,DAE的效果比它強很多。DAE+1D-CNN模型的測試結(jié)果如表3所示。
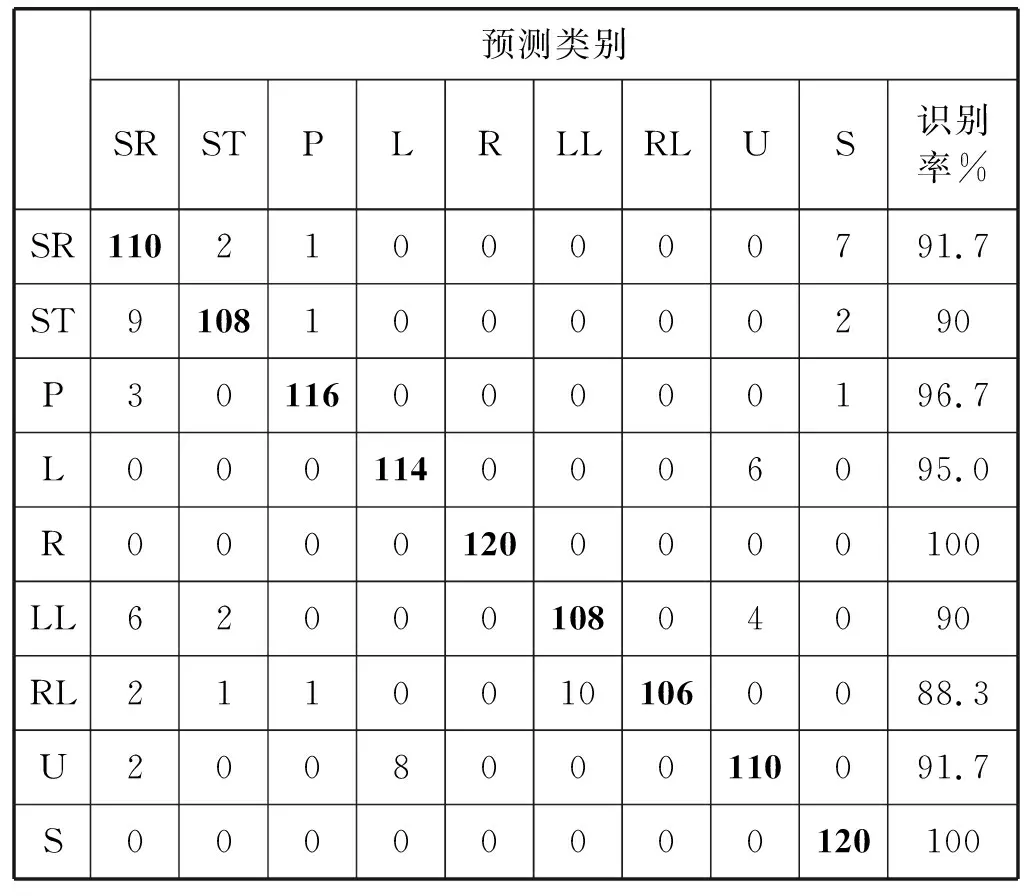
表3 具體識別結(jié)果
DAE不僅沒有造成識別率的大量降低而且改善了1D-CNN模型的收斂效果,從圖7可以很明顯地看出DAE+1D-CNN模型的損失函數(shù)要比1D-CNN模型收斂得更迅速,而且從最終的收斂結(jié)果來看,DAE+1D-CNN模型的誤差也明顯小于1D-CNN模型。

圖7 誤差收斂效果比較
實驗3將三個傳統(tǒng)的機器學習識別模型與DAE+1D-CNN模型進行對比,比較結(jié)果如圖8所示,可以明顯地看出本文模型識別效果最好,其他三個平均識別率最高的是BP神經(jīng)網(wǎng)絡的84.2%。同時將本文模型與兩個新型的分類模型:Deep Forest(深度森林,2017年提出)和XDBoost(2014年提出)進行對比,可以看出本文模型識別效果更好,Deep Forest和XDBoost的平均識別率分別為87.9%和72.1%。

圖8 常見分類模型識別效果對比
5 結(jié) 語
本文提出一種1D-CNN結(jié)合DAE的方法去識別常見的駕駛行為,這些駕駛行為包含縱向和橫向運動。1D-CNN算法不僅比其他分類算法有更好的分類效果,而且可以有效地處理和識別真實的時間序列數(shù)據(jù)。DAE不僅達到降維的效果,而且可以改善損失函數(shù)的收斂效果。實驗結(jié)果也驗證了該方法的有效性與可行性,該方法對汽車安全駕駛具有實際的應用參考價值。本文的不足之處在于采集的數(shù)據(jù)比較理想,本實驗采集的數(shù)據(jù)都是在無車的道路上采集到的,沒有考慮道路環(huán)境等問題。下一步將研究在道路狀況復雜區(qū)域的駕駛行為識別。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
