多維布隆算法在Redis指紋自動過期中的應用
2020-09-02 01:22:04賈小云杜曉旭
計算機應用與軟件 2020年8期
關鍵詞:設置
賈小云 杜曉旭
(陜西科技大學電子信息與人工智能學院 陜西 西安 710021)
0 引 言
如果利用Scrapy-Redis框架進行億級規模以上的數據爬取,且要滿足重復出現的指紋在一段時間內二次遇到不采集、一段時間外二次遇到再采集的話,該框架本身是無法完成的。這不僅是因為框架本身占用空間嚴重,還因為Redis只能對去重集合設置過期時間,而不能對具體的某一指紋設置。如果對去重集合設置了過期時間,等過期后整個去重隊列都會被刪除,這顯然無法滿足我們的需求。因此,解決這些問題成為解決Scrapy-Redis指紋自動過期難題的重點,也是本文研究內容的關鍵。
1 Scrapy-Redis框架
單機模式的Scrapy框架是目前十分流行的爬蟲框架,其融合Redis組件后的Scrapy-Redis框架擺脫了單機的限制,能夠快速實現簡單分布式爬蟲的部署與運行。Scrapy-Redis中有共用的數據庫用來存儲去重集合與請求隊列,并通過對它們的分享幫助分別部署在不同主機上的爬蟲程序協調工作。
Scrapy-Redis指紋是指把請求體、請求方式和請求URL通過MD5加密結合在一起,然后再利用32進制轉義字符進行轉義后生成的字符串。指紋放入Redis數據庫中作為請求的唯一標識。
當一個請求在Scrapy中被請求時,它會先在去重器中進行校驗,校驗過程可以簡單概括如下:
Step1針對發起的請求,生成一個請求指紋。
Step2對該指紋是否已在指紋集合中進行判斷。
Step3如果已經存在,則舍棄它;如果不存在,則在指紋集合中添加該指紋并在請求隊列中添加該請求。
Scrapy-Redis為了實現爬蟲的分布式部署,通過連接Redis數據庫重寫了Scrapy的去重器。該數據庫可以存儲每個爬蟲的每個指紋并將其寫入同一個鍵中,以此實現共享功能。
利用Scrapy-Redis的這種去重機制,只要設置爬蟲不主動清空去重集合,就可以實現采集過的信息不再二次采集。而且,通過對Redis設置過期時間也可以在過期時間后重新爬取先前采集過的所有信息。但在解決某采集過的特定信息隔上固定時間后再次進行采集的問題上,Scrapy-Redis的去重機制卻無法滿足。
這是因為Redis中設置過期時間只是針對去重集合的,而不能針對里面某一具體的指紋。Redis將所有指紋寫在同一個鍵中,當為Redis的鍵設置過期時間后,一旦鍵過期,整個庫中的去重集合都會被刪除,這時所有過期時間前的去重隊列都會消失。
除此之外,因為指紋在Redis去重集合中的長度為40位的16進制,而每個16進制占用4 B空間,所以一億規模的指紋就要占用2 GB的空間。而這并不包括存儲請求種子到隊列中所占用的空間,也不包括多個爬蟲協調工作的情況,所以事實上爬蟲中Redis的空間占比會更加嚴重。
2 算法原理
為了讓Scrapy-Redis適應億級規模爬取,本文使用Bloom算法。目前針對Bloom算法在爬蟲上的應用研究很少,但也有一些對簡單Bloom算法在Scarapy-Redis的去重效率優化方面的嘗試,這對本文研究起到了一定的啟發作用。在如何讓請求指紋自動過期的問題上,可以通過使用Redis散列表保存指紋到其過期時間的映射,以及多維Bloom算法與Scrapy-Redis的對接兩種方法進行實現。
2.1 Bloom算法
在判斷元素是否在一個集合內時,鏈表、樹等數據結構都采用將所有元素保存起來之后進行對比的方式,但這種方式會隨著集合的擴增占用更多的存儲空間和檢索速度。哈希函數可以將位數組上的某一位作為某一元素的映射,以便利用位數組上該位置的值來判斷該元素是否在判斷集合中存在,很大程度上彌補了鏈表、樹等結構的缺陷。Bloom算法便是利用哈希表來判斷集合中是否存在某元素的,其過程如下:
聲明一個初始條件下每一位都為0且長度大小為m的位數組,其結構如圖1所示。

圖1 Bloom過濾器位數組的初始設定
現假設有一個集合S,S={x1,x2,…,xn},使用k個相互獨立且隨機的哈希函數將S集合中每一個元素映射在{1,2,…,m}這一數組范圍內。在映射時,位數組中哈希函數的映射值相同的位置會被置1,且在多次映射的情況下只有第一次的置1為有效設定。
舉個例子,當k取3的時候,假設元素x1經過3個哈希函數映射的結果分別為1、4、8,而元素x2經過3個哈希函數映射的結果為4、6、10。那么位數組上將被置為1的位置是1、4、8、6、10這五位,位數組相應位置置1后的結構如圖2所示。

圖2 x1與x2映射后位數組的置1結果
圖2中x1和x2成功加入了去重集合S中,此時如果要判斷其他元素是否存在于S集合內,同樣需要用k個哈希函數求映射結果并判斷結果對應的位數組位置是否都已為1,若已都為1,則該元素屬于集合S,否則,不屬于集合S。現假設兩個新元素y1、y2的映射結果如圖3所示。

圖3 y1和y2的映射結果
由圖3可知y1對應位置有0,因此y1不屬于S集合,y2對應位置全部為1,應該屬于S集合。但這只是原則上的判斷結果,事實上,Bloom算法雖然在不屬于去重集合的元素的判斷上能夠保證百分之百的正確率,但對屬于該集合的元素的判斷卻存在一定的誤判率。
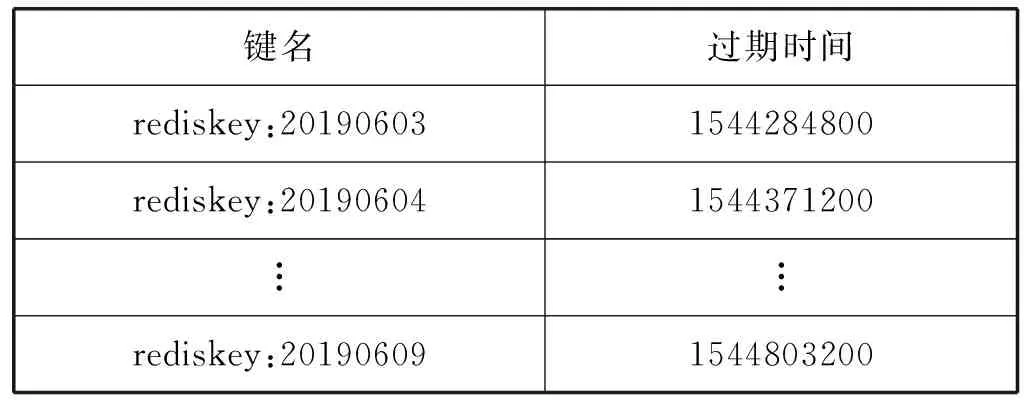
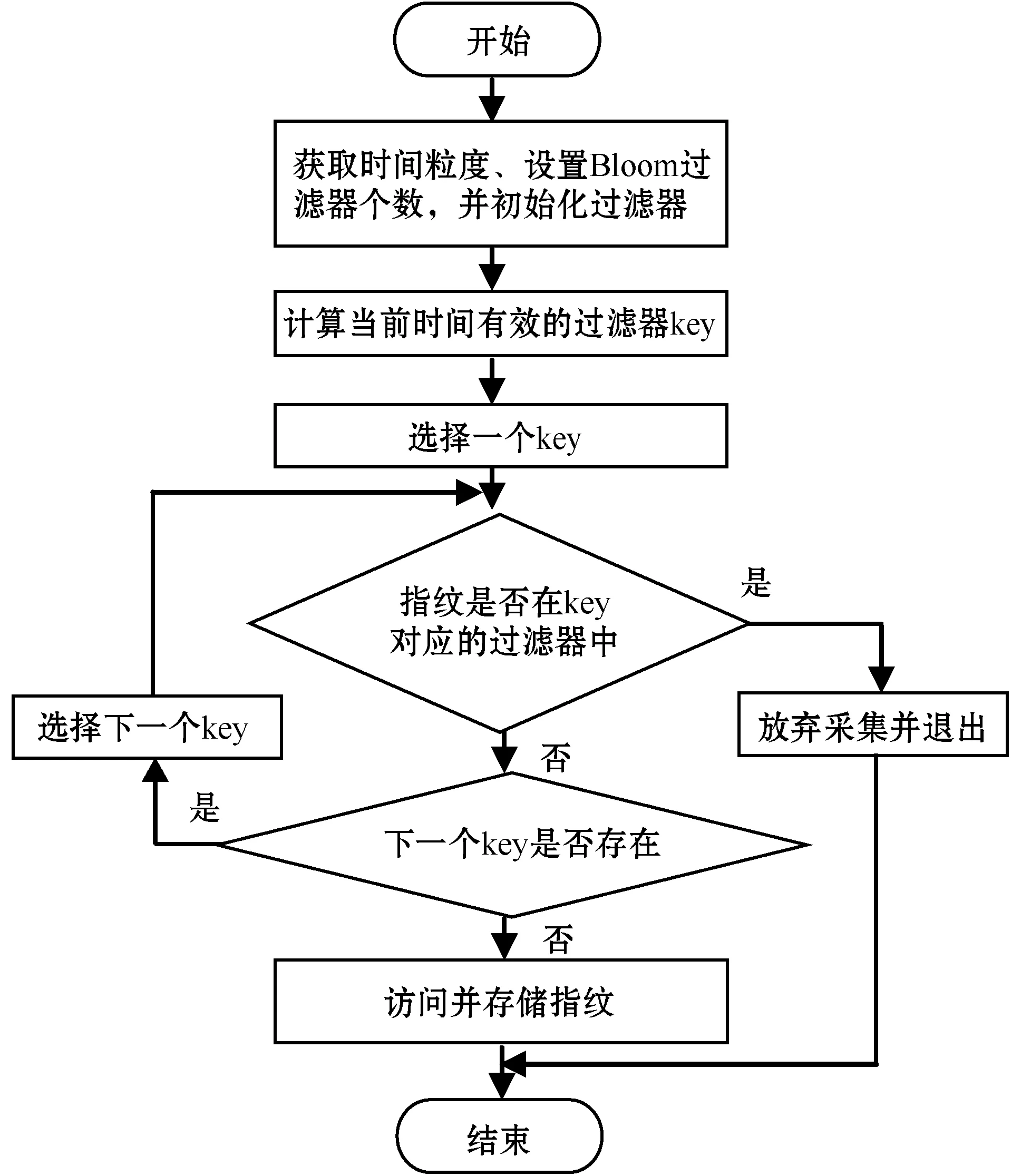
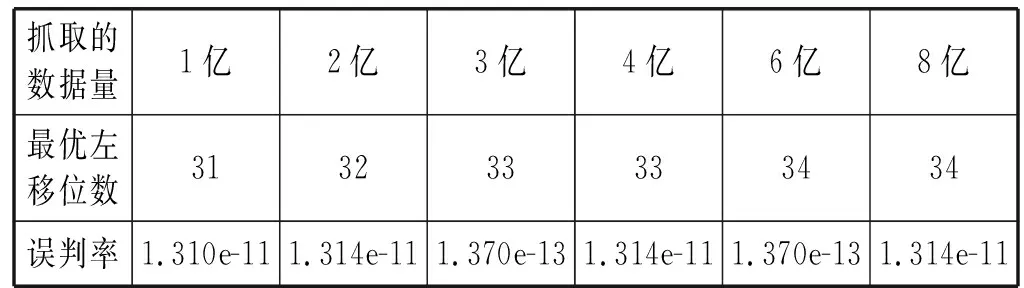
對于Bloom算法的誤判率,仍然假設存在k個相互獨立且隨機的哈希函數,存在已有n個元素的待對比集合以及長度為m的位數組,且k、m和n之間滿足kn (1) 式中:1/m為k個哈希函數中有任意一個選中位數組上該位置的概率,顯然1-1/m就代表k個哈希函數都未選中這一位置的概率。 該位置在經過k次哈希映射后仍然沒有被置為1的概率為: (2) 對于集合S={x1,x2,…,xn},需要做kn次散列運算才能將其所含元素全部映射到位數組中,此時位數組的該位置仍然沒有被置為1的概率為: (3) 經過kn次散列運算后,位數組中某一位置成功被置為1的概率則為: (4) 當某元素經k次哈希映射后所得結果對應的位數組內位置全部為1時,會將該元素判定為屬于集合S。因此,不在集合中的元素被檢測為已存在于該集合的誤判概率為: (5) 由式(5)可以看出,在n和m確定的情況下,最小誤判率可以通過最優的k獲得。而最優哈希函數個數的獲取公式如下: (6) 顯然,誤判率與m/n的值以及k的值有關。當m/n保持不變時,k值越靠近Ki越能保證判斷的準確性;而當k值保持不變的時候,m/n的值越大越能保證判斷的正確性。雖然整體而言存在誤判率,但由于誤判率可以調節且很小,所以相較于其在空間占比和時間效率方面的優勢,Bloom算法在能夠容許誤判的情況下是不錯的選擇。 多維Bloom算法由多個基本Bloom過濾器組成,且多個基本過濾器具有相同元素維數的位數組空間。每個基本過濾器負載待對比元素在某一維上的屬性,進行對比判斷時,需要對元素在每一維上的映射是否都存在于各自對應的過濾器位向量上進行判斷,并最終給出元素是否已存在于集合中的判定結果。 將多維Bloom算法的維數設為L,則其誤判概率為: (7) 由式(1)可知,多維Bloom算法的誤判概率與其維數大小成負相關,當k、m和n一致的時候,誤判率隨維數的增加而減小。且多維過濾器的誤判率始終低于基本過濾器的誤判率,是其每一維過濾器誤判率的乘積。 在解決實際問題時需要使用按時間排列的多個Bloom過濾器。首先,根據需求決定時間序列的粒度,然后在該粒度下選擇相應的要使用的Bloom過濾器的數量。例如,當去重周期為7天時,比較合適的時間粒度為“天”,過濾器數量為7;當去重周期為7個月,比較合適的時間粒度為“月”,過濾器數量同樣為7;當去重周期為一個月時,可以選擇時間粒度為“天”也可以選擇時間粒度為“月”,相應的過濾器數量為30和1。 在創建Bloom過濾器列表時,不會對數據庫中原有的數據產生影響。若Redis中已存在該鍵,會創建過濾器列表的Python對象并連接到Redis對應的鍵上;如果不存在,創建該鍵后再創建對象并連接到對應鍵上。當然,創建Python對象時也會聲明每個鍵的過期時間。比如,當粒度為“天”、過濾器數量為7、今天是2019年6月3日時,列表的結構如表1所示。 表1 創建Bloom過濾器列表的舉例 采用這種方法,當去重周期到后,對應Bloom過濾器里的內容會被自動清空,不再需要手動刪除以釋放內存,也不會影響其他時間的過濾器。 每當有新請求需要發出時,首先要生成當前時間有效的過濾器列表,然后對過濾器列表中的每一個過濾器進行對比判斷,只有全部過濾器都不包含此請求時,才能說明該請求沒有在有效期內進行請求過,才能夠將其放入請求隊列等待請求,并將該指紋存入當前時間對應的過濾器中。 Redis中存在散列表數據結構,它保存了鍵到值的映射,因此可以利用它進行請求指紋的自動過期設置。步驟如下: Step1因為Redis的去重集合中只保存了指紋,所以為了保存從該指紋到其過期時間的映射,需要先將去重數據的集合結構轉換為哈希表結構。 Step2判斷每一個需要發起的請求是否在哈希表中存在。 Step3當該請求存在于哈希表中時,對比當前時間和已存在指紋的過期時間。如果當前時間大于過期時間,需要更新指紋的過期時間并將請求種子放入請求隊列;反之,則說明該請求在有效期內已經被處理過,可以放棄訪問。 Step4當該請求不存在于哈希表中時,將請求種子加入請求隊列,將指紋和過期時間寫入哈希表中。 需要注意的是,該算法在實現時需要在Scrapy-Redis的settings中設置過期時間,同時通過from_crawler方法進行獲取。 使用這種方法來實現請求指紋的自動過期雖然簡單靈活,也可以指定任意的過期時間,且保證相同的請求兩次進行采集的時間間隔必定不小于指定的時間,但該方法存在很大的缺陷:其一,使用該方法后無法使用Bloom算法壓縮內存;其二,如果有URL在第一次被請求后再也沒有被請求或很長時間內再沒有被請求,那么始終緩存在Redis中的這些請求指紋會逐漸堆積造成巨大的空間消耗。要處理這些占用空間的指紋需要額外編寫腳本,這就代表不能直接依賴框架的去重機制來設置指紋,自然會消耗更多的計算和存儲資源。 所有針對Scrapy-Redis框架的重構過程,不會影響到框架的其他功能,更不會對其進行破壞。同時,多維Bloom過濾器中位數組的實現和維護需要依賴Redis數據庫,所以改造Redis數據庫是對框架進行改造的基礎。 (1) 算法流程圖。該算法實現過程如圖4所示。 圖4 實現Redis指紋自動識別的算法流程圖 (2) 獲取時間粒度、設置Bloom過濾器個數,并初始化過濾器。選擇時間粒度及設置過濾器個數的方法在2.2節中已有介紹。對每個過濾器key(鍵)的過期時間的設定,可以在settings中設置然后通過from_crawler方法獲得,也可以在下一步“初始化過濾器”中進行設置。 初始化過濾器時,因為各個過濾器之間是獨立的,所以主要設置的參數如下:需要的總bit位數、需要最少的哈希次數、需要多少MB內存、需要多少個512 MB的內存塊(指紋的第一個字符必須為ASCII碼,最多有256個內存塊),以及seed值的選擇、key的獲取、最大指紋量和位數組長度的設置等。 關于總的bit位數和需要的最少哈希次數,因為要處理億級之上的數據去重,所以指紋量n的值為1億以上,此時哈希函數個數k的取值可以為10左右,這樣位數組長度m至少要在10億以上,因為數值較大,所以采用左移的位操作來實現,左移的位數設為bit。假設bit=30,就有m為1<<30,因為1<<30=1 073 741 824=230=128 MB,此時再設k取6,則能夠處理的最大指紋量為230/k=178 956 970個。 在seed值的選擇上為每個過濾器內置了100個隨機種子;在能夠處理的最大指紋量上,本文在初次編碼中將其設為1億,而位數組長度設為了231-1。 (3) 生成周期內有效的過濾器key列表。在生成針對當前時間的有效周期內過濾器key列表時,定義了get_bloomfilter_keys()方法,該方法能夠根據當前時間、時間粒度和過濾器個數來返回有效的過濾器key列表。例如,假設當前時間為20190508,filter_granularity=′d′,filter_num=7,則返回的列表為[′xxx:20190502′,′xxx:20190503′,...,′xxx:20190508′],其中,′xxx′代表RFPDupeFilter的key。另外,在實現過濾器“判斷指紋是否存在于當前key對應的過濾器中”時,定義了一個exists()方法。在該方法中,為了應對日期的變化,像從20190508到20190509的過渡之類的,需要每次都重新計算當前有效的過濾器的鍵名列表,然后再進行判斷和處理。 (4) 判斷指紋是否在key對應的過濾器中。需要實現一個關鍵方法:判定指紋是否重復的exists()方法。部分代碼如下: if not value: return False exist=1 for map in self.maps: offset=map.hash(value) exist=exist & self.server.getbit(self.key,offset) return exist value為待判斷的元素即一個新到來的指紋,定義變量exist為1后,將其與每一個哈希函數對value進行哈希運算后得到的映射結果進行循環與運算,利用Redis中getbit()方法取每一次映射結果對應位置的值。若每一次取到的值都為1,則結果為True,表示value在集合內已存在;相反,只要getbit()的結果有一次為0,則結果為False,表示value不在集合內。 另外,由于在實現多維Bloom過濾器時使用到的key和server是可變的,所以不同于單個的基本過濾器的實現,這里的exists()方法在傳參時需要將key和server也一并傳入。 (5) 將指紋寫入當前時間的過濾器。同樣需要實現另一個關鍵方法:添加指紋到集合中去的insert()方法。部分代碼如下: for f in self.maps: offset=f.hash(value) self.server.setbit(self.key,offset,1) insert()方法同樣遍歷調用哈希函數以對元素進行運算并得到映射位置,然后利用Redis的setbit()方法將其位置置為1。同時,該方法的傳參相較于簡單的Bloom過濾器同樣多了server和key。 要完成已經實現的多維Bloom算法與Scrapy-Redis的對接,還需要繼續修改框架內源碼,同時將它的組件Dupefilter去重類替換為多維Bloom過濾器的邏輯。替換過程主要通過更改RFPDupeFilter類中的request_seen()來實現: def request_seen(self,request): fp=self.request_fingerprint(request) if self.bf.exists(fp): return True else: self.bf.insert(fp) return False 獲取請求指紋的方法是request_fingerprint()方法,判斷該指紋是否已在任意過濾器的key中存在的方法是exists()方法。如果任何一個過濾器顯示存在,則說明該Request是重復的,返回True,不再訪問該請求。相反,如果全部過濾器顯示不存在,則返回False并調用insert()方法添加指紋到當前過濾器,添加請求到請求隊列。 重構后框架和Scrapy-Redis具有相似的使用方法,但還有幾個關鍵的參數需要配置。 使用時需要替換掉DUPEFILTER_CLASS后使用,可以將其設置為:DUPEFILTER_CLASS="scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter"。 在初次代碼編寫中設置了最大指紋處理量為1億,位數組選擇了231-1,但在實際運用中,可以根據自己的需要在初始化過濾器時配置預處理的指紋量(capacity)、左移位數(bit)等參數。 同時為了控制誤判率,在設置bit參數時,可以引入error_rate變量來表示誤判率,然后使用math.ceil(capacity*math.log2(math.e)*math.log2(1/error_rate))來計算需要的總bit位數。這樣,根據不同誤判率的要求設置不同的誤判率參數就可以獲得不同的左移位數,但會影響到指紋自動過期的空間占用問題。 首先測試多維Bloom過濾器能否正確使用,因為在處理億級規模指紋存儲時難以尋找誤判的URL,因此,此部分利用每小時爬取100個URL的方法對過濾器的功能進行了測試。將時間粒度設為小時,并以兩個小時為過期時間創建兩個Bloom過濾器,編寫爬蟲程序分別在相應的時間訪問“https://www.baidu.com/s?wd=”并抓取100篇新聞的URL。結果顯示,第一小時與第二小時內所存儲的指紋中無重合,第三小時與第一小時的指紋有重合而與第二小時的指紋無重合,第四小時的指紋與前兩小時的指紋都有重合而與第三小時的指紋無重合,由此可知重構后的框架可以實現指紋的自動過期功能。 在此基礎上可以分析重構后框架在實現指紋自動過期時的誤判率。編寫爬蟲程序,分三天爬取某博客網站的博文,三天內再次遇到某博文不進行訪問和指紋的存儲,三天后再遇到該博文進行訪問并存儲指紋。根據需求顯然可知過期周期為3,因此將時間粒度選為天,需要創建3維Bloom過濾器,每個過濾器設置各自對應的key為20190603-20190605、過期時間分別為20190606-20190608。此外為了適應抓取規模、便于實驗測試,每個過濾器的哈希函數個數k統一設置為6。此時根據抓取的數據量的不同,可以計算出最優的位數組長度,即最優的左移位數。表2為不同數據量需求下最佳左移位數及其最低誤判率的展示。 表2 k固定時最佳左移位數及誤判率 由表2可以看出,即使是在k固定的情況下,重構后框架的誤判率也可以滿足低于萬分之一的條件,更不用說在最優k和最優m/n值之下了。 除了誤判率外,另一項需要關注的點是重構后框架所占用空間。實驗部署在內存總大小為175 GB的服務器上,虛擬機選用Centos7,分別以每天1億爬取量和每天2億爬取量的需求設置爬蟲,所以三天內最高指紋存儲需求可以達到6億。通過對比使用Redis和使用重構后框架存儲不同量指紋時所占用的空間,得到結果如圖5所示。 圖5 兩種方式下的空間占用情況 Redis的占用空間既包括指紋所占空間也包括請求種子所占用的空間,重構后框架的占用空間為依據表2在k值固定情況下選擇最優左移數之后,多維過濾器所開辟的位數組的總空間。綜上可以看出,重構后的框架可以在極低的誤判率下實現指紋的自動過期,且大大節省所需空間。 本文采用了多維Bloom算法對分布式爬蟲所用的Scrapy-Redis框架進行了重構,將實現后的攜帶當前時間及過期時間信息的多維Bloom過濾器替換掉原框架內的去重類,從而達到了Redis鍵內所存指紋自動過期的要求。該方法可以用于類似“過期時間內再次遇到某URL不訪問不存儲,過期時間后再次遇到該URL訪問并存儲”的場景,且能夠在誤判率低于萬分之一的情況下,大大縮減指紋存儲所占用的空間。2.2 多維Bloom算法
2.3 Redis散列表設置指紋過期
3 重構Scripy-Redis框架
3.1 多維Bloom算法的實現
3.2 多維Bloom與Scrapy-Redis的對接
4 測 試

5 結 語
猜你喜歡
少先隊活動(2021年4期)2021-07-23 01:46:22
水上消防(2020年5期)2020-12-14 07:16:18
中國畢業后醫學教育(2020年5期)2020-12-06 06:52:46
鐵道通信信號(2019年7期)2019-10-08 08:38:02
攝影之友(影像視覺)(2019年3期)2019-03-30 01:36:50
鐵道通信信號(2018年1期)2018-06-06 02:27:38
玩具世界(2017年9期)2017-11-24 05:17:29
作文評點報·低幼版(2017年42期)2017-11-16 22:12:34
沈陽醫學院學報(2015年1期)2015-12-27 13:44:40
醫學教育管理(2015年3期)2015-12-01 06:43:16
