基于壓縮激活機制的輕量級人臉識別網絡設計
2020-08-31 07:03:10黃倫文
數字通信世界 2020年8期
黃倫文
(安徽四創電子股份有限公司,安徽 合肥 230031)
0 引言
人體生物特征識別技術包括人臉、指紋、手掌紋、虹膜、聲音、體型等,其中,人臉識別是最容易被用戶接受的身份認證方式之一。目前,高精度的人臉驗證模型多是以對計算資源要求高的深度卷積神經網絡為基礎建立的,這些模型使用大量的數據進行訓練,模型復雜且具有非常多的參數,需要消耗大量計算資源,難以在移動設備和嵌入式設備中運行。因此,低內存占用、低計算資源消耗的輕量級神經網絡成為當前的研究熱點。
非輕量級人臉識別網絡具有較高的識別精度,但是參數量較大,如DeepFace、DeepFR等。本文提出了一種基于壓縮激活機制的輕量級人臉識別網絡,減少了MobileFaceNet網絡頭部卷積核的數量,降低模型的復雜度;并且引入squeeze-and-excitation結構[1],增加網絡的感受野和學習特征的能力,使得網絡具備從整個圖像更多地關注人臉關鍵部位的能力,進而提高網絡的識別精度。
1 基于壓縮激活機制的輕量級人臉識別網絡
1.1 網絡結構設計
基于壓縮激活機制的輕量級人臉識別網絡(Squeeze and Excitation Mobile Face Net,SEMFN)結構見表1。每一行代表網絡的一層,每一列的含義依次為:輸入流,具體操作,輸出通道數量,瓶頸層中擴展的通道數,卷積核的大小,卷積計算的步長,重復次數,NL表示使用的非線性變換函數,本文使用PReLU[2]作為非線性激活函數。
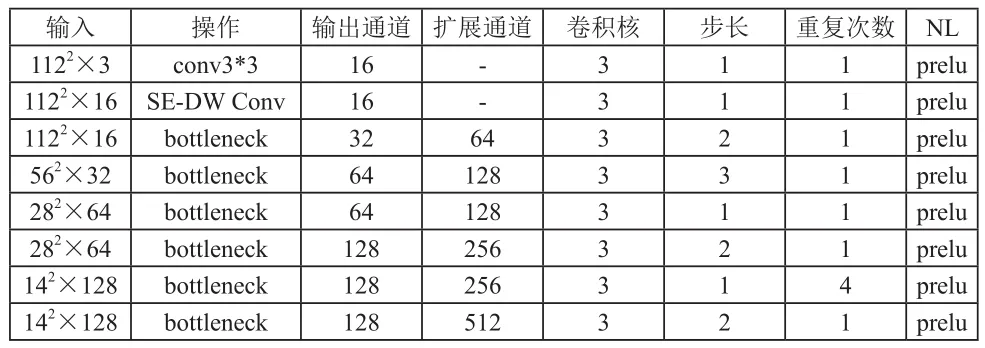
表1 基于壓縮激活機制的輕量級人臉識別網絡

72×128 bottleneck 128 256 3 1 2 prelu 72×128 linear GDConv 128 - 7 1 1 -12×128 linear conv 128 - 1 1 1 -
為了降低網絡參數數量,SEMFN頭部卷積核通道數降低為16,保證網絡精度的前提下,減少了網絡頭部的參數,節省網絡的計算成本;SE-DW conv層具有Depthwise Convolution[3]和SEBlock[9]兩種計算,在網絡的最開始階段引入了輕量級注意力機制,使得網絡能夠更準確地抓取輸入信息最值得注意的區域,精準地學習輸入人臉特征。GDConv是指DepthwiseConvolution計算。此外,我們在瓶頸層使用了一個快速的下采樣策略,在最后幾個卷積層使用了提前降維策略,并在linear GDConv層之后使用線性1×1的卷積層作為特征輸出層。最終形成的模型參數量為80萬,相對于MobileFaceNet的99萬參數量,降低了近20%。
1.2 引入壓縮激活機制
Sequeeze and Excitationblock是一種網絡子結構[1],能夠方便地嵌入到其他網絡結構中,其核心思想是:引入了輕量級注意力機制,通過網絡學習特征通道的權重,使得部分有效的特征通道具有較高的權重,其他通道具有低權重,促使模型自適應抓取高權重通道特征,提高識別精度。
本文在網絡開始階段SE-DW Conv層引入了輕量級注意力機制,使得網絡能夠更準確地抓取輸入信息最值得注意的區域,精準地學習輸入人臉特征,具體結構如圖1所示。

圖1 SE-DW conv層結構圖
第一步,對輸入的通道進行Squeeze壓縮操作,對輸入層進行特征壓縮,將每個二維的特征通道變成一個實數,這個實數具有全局的感受野,并且輸出的維度和輸入的特征通道數相匹配。Squeeze操作為全局平均池化,如公式(1):

式中,uk為輸入層數據;k為輸入通道數;W和H為輸入通道數據的寬和高;Fs為Squeeze操作結果,是大小為k的向量。
第二步,對Squeeze的結果進行激活操作Excitation,如公式(2),通過參數為每個特征通道生成權重,用來顯示地建模特征通道間的相關性。

式中,W1和W2為全連接層操作;δ和σ為非線性激活函數;W1的維度是k/r*k,r是縮放參數,本文算法r=4。即,先對Squeeze的結果Fs進行全連接層操作,并根據r降低維度,經過ReLU非線性激活函數層處理;為了保持輸出維度k不變,再經過W2全連接層操作,這里W2的維度是k*k/r;最后在經過sigmoid函數,得到激活后的結果Fe。
第三步,根據Excitation操作獲取的通道權重系數Fe,對輸入數據進行加權處理Fw,如公式(3):

式中,uk為輸入層數據;Fe為步驟二中求解的Excitation權重。通過乘法逐通道加權到輸入特征上,完成通道維度上的原始特征的重標定。自適應學習輸入通道的權重,尤其是引入了輕量級注意力機制,通過網絡學習特征通道的權重,促使模型自適應抓取高權重通道特征,提高識別精度。
第四步,對輸入通道數據進行depthwise卷積處理,其優勢在于大幅降低卷積參數的數量,例如本文網絡的第二層,輸入層和輸出層大小均為112*112*16,卷積核大小為3*3時,普通卷積核參數為3*3*16*16=2304;對于depthwise卷積,則參數為3*3*16=144,大幅降低參數量。
BN是Batch Normalization層,將卷積層計算之后的數據歸一化,忽略整體數據的大小變化而保留卷積后數據之間的相對關系。Act.是激活函數,此處采用了PReLU非線性變換。
第五步,對步第四步中獲得的depthwise卷積結果和第三步中獲得的加權結果進行重組,具體方法為計算二者的內積。
1.3 Bottleneck瓶頸層結構設計

圖2 Bottleneck層結構圖
Bottleneck是一種瓶頸層結構,可以幫助網絡綜合性地理解輸入信息,學習輸入特征。
第一塊和第三塊類似,由Conv1x1、BN、Act構成。其中,Conv1x1是指卷積核大小為1的卷積層;如前文所述,BN是Batch Normalization層,將卷積層計算之后的數據歸一化;Act是激活函數,這里采用了PReLU激活函數,使該神經元具備分層的非線性映射學習能力。
第 二 塊 由 DWConv3x3、BN、Act組 成, 其 中,DWConv3×3是指卷積核大小kernel_size=3的Depthwise ConvolutioBN。
SEMFN使用大量的Bottleneck瓶頸層作為網絡的主體結構,輸入信息可以在網絡內部充分流動,使網絡有足夠的參數理解輸入信息并記錄信息特征。
2 實驗結果分析
2.1 數據集
CASIA-WebFace[10]數據集包含了10,575個人的494,414張圖像。本文使用CASIA-WebFace作為訓練數據,并使用人臉驗證數據庫LFW[11]來檢查不同條件下算法的改進情況,訓練數據與測試數據沒有重疊。
2.2 實驗設置
(1)數據準備:對每張圖片進行雙線性插值縮放,將所有圖片統一為112×112的分辨率;將所有圖像顏色信息歸一化處理,即每個像素的顏色信息減去127.5,然后除以128。
(2)訓練設置:由于GPU內存有限,我們采用隨機梯度下降(SGD)作為優化器,批量大小為恒定為128。與大模型相比,輕量級模型可以使用相同的GPU服務進行相對大批量的訓練,這也是DCNNs訓練階段的一個常見但關鍵的實際問題。動量參數設置為0∶9,初始學習速率設置為0.1,并在28、38、48、58個時點周期性降低為前一步的0.1倍,以適應訓練計劃。
2.3 實驗對比和分析
表2為引入Squeeze and Excitation結構的實驗對比分析,可見:模型參數量僅增加了128,識別率由98.91%提升至99.13%,證明了SE結構能夠提升模型的識別精度。

表2 引入Squeeze and Excitation結構實驗對比
為了驗證本文算法的性能,與當前人臉識別領域主流的算法進行了實驗對比,包括:MobileNetV1/V2[3][4]、Light CNN-29[5]、ShuffleNet[6]、MobileID[7]、MobileFaceNet[8]、LMobileNetE[12]等, 結 果 詳 見 表3。Light CNN-29和LMobileNetE的識別精度較高,但是其訓練數據集分別是4M和3.8M,模型參數數量分別是12.8M和26.7M,均明顯高于本文算法,難以應用于移動平臺;MobileNetV1/V2的模型參數數量降低至3.2M和2.1M,但是其識別率均未達到99%,識別精度不高;MobileID參數量降低至1.0M,但是識別精度大幅降低;ShuffleNet使用逐點群卷積等方式進一步降低了參數量,識別性能優于MobileID。

表3 主流算法結果對比
MobileFaceNet的整體性能較好,包括三個不同的網絡類型,其中,MobileFaceNet的識別率得到99.28%,但是其網絡參數數量為0.99M,相對本文算法,識別率提升0.15%,參數量多了約20%;MobileFaceNet-M參數量0.92M,仍然較高;MobileFaceNet-S參數量降低至0.84M,識別率為99%。本文算法在模型復雜度和識別率上均優于MobileFaceNet-S,是因為本文引入了基于壓縮激活機制的輕量級注意力機制,能夠有效地增加網絡的感受野和學習特征的能力,使得網絡具備從整個圖像更多地關注人臉關鍵部位的能力,進而提高網絡的識別精度。
3 結束語
為了保持識別精度的同時進一步降低輕量級人臉識別網絡的參數量,提高網絡的運行速度,本文提出了一種基于壓縮激活機制的輕量級人臉識別網絡,通過降低頭部卷積核通道數量降低了模型的復雜度;進一步引入了squeeze-and-excitation結構,自適應計算特征通道的權重,使得網絡在降低參數的同時,保持較高的識別精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
學生天地(2020年31期)2020-06-01 02:32:06
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
計算機工程(2015年8期)2015-07-03 12:19:07
