基于輪廓重合度分析的道路標記魯棒識別
2020-08-26 07:07:14陳家成肖曉明黃余唐琎耿耀君
中南大學學報(自然科學版) 2020年7期
關鍵詞:檢測
陳家成,肖曉明,黃余,唐琎,耿耀君
(1.西北農林科技大學信息工程學院,陜西楊凌,712100;2.中南大學自動化學院,湖南長沙,410083)
隨著人工智能的興起,無人駕駛技術已經成為企業和學者的研究熱點。無人駕駛汽車依靠計算機視覺提供必要的交通信息[1-2],識別公路編碼道路標記是必要的組成部分[3]。道路識別對人類駕駛員來說是一項簡單的任務,但對計算機來說并非易事。道路交通的復雜性、不同的街道照明、能見度和不同的天氣狀況常常會降低道路標記的圖像質量。非目標干擾如積水、陰影、行人、車輛和路邊灌木叢等會使識別道路標記變得復雜。如果這些非目標干擾在預處理過程中不能有效去除,將會導致道路標記識別出現誤報,影響道路標記識別算法的整體性能。此外,由于道路標記種類繁多,僅使用單一的特征描述符方法很難準確區分,也很難區分陰性樣本(如積水、樹的陰影)[4-5],因此,在復雜的交通條件下,有必要結合多種特征對道路標記進行有效識別。目前,人們對路面車道標記檢測的研究較多[6-7],但對道路標記識別的研究較少。為了識別道路交通標記,許多方法依賴于車道位置[8]的檢測結果。因此,車道檢測的準確性會對其他道路標記的識別產生很大影響。WU 等[9]指出了該方法的不足,提出了一種獨立的道路標記檢測與識別算法。該方法提取多個ROIs作為最大穩定極值區域(MSER)[10],然后,使用快速特征[11]和方向梯度直方圖(HOG)[12]特征作為描述符,為每個類構建模板。這種方法嚴重依賴于快速檢測的準確性,并且數據量巨大的HOG 特征也需要大量的計算量。REBUT等[4]提出了一種識別4類箭頭和線性標記的方法。他們使用霍夫變換來檢測線性標記,并使用1 個k 近鄰(KNN)[13]分類器與傅里葉描述符來標記其他道路標記。WANG等[14]提出了一種基于先驗知識和圖像匹配的道路標記檢測與識別方法。GANG等[15]從重建圖像中得到4個改進的Hu矩陣和2個仿射不變矩陣,然后使用SVM 分類器進行最終識別。這些方法操作簡單,實時性好,在理想路況下取得了良好的效果。然而,在輕度和嚴重退化的道路條件下,該方法識別準確率低,假陽性率高。KHEYROLLAHI 等[16]提出了一種先進行反向透視變換,然后利用自適應閾值分割算法獲得二值圖像的算法。該算法利用連通域的方法提取道路標線對應的目標區域,并在尺度和方向上進行校正。最后,提取候選目標的Hu 矩陣、直方圖、縱橫比等118 維特征,并與單隱層人工神經網絡(ANN)分類器相結合進行特征識別。該方法對特定標記的識別率較高,但對某些道路標記(如分岔箭頭等)的識別率較低(75.5%)。此外,提取的特征維數高,采用人工神經網絡進行分類,計算量大。ZHANG 等[5]提出了一種利用霍夫變換檢測路面車道線并建立感興趣區域(ROI)的算法,然后進行一維熵分割和邊緣檢測,提取改進后的Hu矩陣不變特征進行識別。然而,該方法僅使用一種描述特征,因此,存在一定的局限性。此外,還有一些研究者使用深度學習來對道路標記進行分類。AHMAD等[17]使用不同數量的卷積/池化操作和全連通層以及不同分辨率的道路標記數據集來訓練5 種不同的CNN 架構。這2種方法只實現了對路標的識別而沒有檢測,不能直接應用到實際情況中。更重要的是,這些深度神經網絡需要大量的訓練樣本和價格昂貴的圖形處理硬件來支持其龐大的計算負載,因此,很難將其應用于嵌入式高級輔助駕駛系統和商業化。上述方法為道路標記識別提供了廣闊的應用前景。雖然個別算法分類樣本的準確率很高(>99%),但其綜合檢測和識別性能還沒有達到要求,這主要是實際道路環境中水、影、車、路邊草等復雜條件的干擾因素造成的。若這些非目標干擾在預處理階段不能有效去除,則分類器就很難正確區分負樣本,因此,在識別結果中存在許多誤報,導致分類器性能較低。在實際無人系統中,如果1個算法的結果含有大量誤報,將嚴重影響高層決策算法的運行,使無人系統失效。為了解決上述問題,本文作者提出一種基于輪廓重合分析的非目標干擾濾波算法,可有效濾除道路標記識別預處理階段的大部分干擾,降低道路標記識別錯誤的風險。同時,改進輪廓特征分析方法,并將其與基于橢圓傅里葉描述子的SVM 相結合。這種提取和融合多種特征的方法可以更準確地對道路標記進行分類[8]。
1 算法原理
本文提出的整個道路標線識別算法是基于IPM和非目標濾波器的道路標線魯棒識別算法。具體步驟如下:1)使用逆透視映射將原始圖像轉換為俯視圖像;2) 從頂視圖圖像中提取邊緣圖像和Canny 圖像;3) 對上述2 種圖像比較結果進行分析,濾除干擾,得到過濾后的圖像;4)對過濾后的圖像進行形狀處理和幾何濾波;5)對步驟4)所得結果使用2種方法進行處理,其中,一種是通過輪廓特征分析計算道路標線模板與圖像中目標的相似度,另一種是計算圖像中目標的橢圓傅里葉描述子并將其用于支持向量機的訓練;6)將輪廓分析和支持向量機的2個結果進行融合,得到最終的分類結果。該算法的總體框架圖如圖1所示。
1.1 逆透視映射
由于車輛攝像機以斜角(稱為原始圖像)捕獲道路圖像,因此,在所獲取的圖像中存在失真情況,在原始圖像上很難直接檢測和識別道路上的交通標記。為此,首先使用IPM算法[19]將原始圖像轉換為俯視圖像,然后限制轉換后圖像的長和寬,只留下有用的區域,如圖2所示。
1.2 結合Canny的閾值分割
為了獲得感興趣區域的邊緣,首先將彩色圖像轉換成灰度圖像,然后使用Canny邊緣檢測器提取圖像的邊緣。
由于獲取的道路圖像失真,在一定距離處道路圖像的清晰度略低于近點的清晰度,從而導致逆透視變換后頂視圖圖像的上半部分分辨率略低,因此,首先將俯視圖分成上、下2部分,然后使用鄰域塊參數為S1和S2的自適應閾值分割算法(OSTU)[20]進行分割,并將分割結果進行合并。
由于上一個分割仍然包含許多孤立面片,以及由于光照效果不佳而沒有很好分割的區域,故將此結果與Canny邊緣檢測相結合并進行第2個分割。首先,對第1個分割的每個連接域進行輪廓搜索,并找到相應的邊界矩形。其次,設置面積閾值Sth和外接矩形面積Srec,若Srec<Sth,則進行第2次分割;否則,將該區域劃分為等距塊,然后進行第2次分割。第2個分段計算式如下:
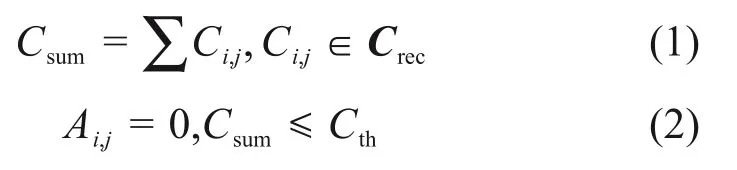
其中:Crec為對應于矩形灰度圖像區域的矩陣;Cth為設置的Canny 邊緣像素閥值;Ci,j為該區域中的像素。使用式(1)計算矩形區域內Canny 邊緣像素的總數Csum,若Csum≤Cth,則參考式(2)將連接區域內的所有像素Ai,j設置為0;否則,使用鄰域塊參數為S3的自適應閾值分割算法(OSTU)[20]對矩形區域中的灰度圖像區域Crec進行二值化,以生成俯視圖像的普通二值化圖像Ibin。
1.3 色彩過濾
由于道路標線以白色、黃色和紅色為主,利用顏色信息可以初步濾除道路上的路邊樹木、草地和色彩鮮艷的車輛等干擾。首先,將彩色頂視圖圖像從RGB空間轉換到HSV空間,得到其飽和度S、亮度V 和灰度圖像灰度G。然后,創建1 個新的灰度圖像Imask,其長和寬與俯視圖的相同,定義如下:
圖1 基于IPM和非目標濾波器的道路標線魯棒識別算法框圖Fig.1 Frame diagram of robust recognition algorithm of road markings with IPM and nontarget filter

圖2 逆透視映射算法得到的俯視圖示例圖Fig.2 An example of a top view image from inverse perspective mapping algorithm
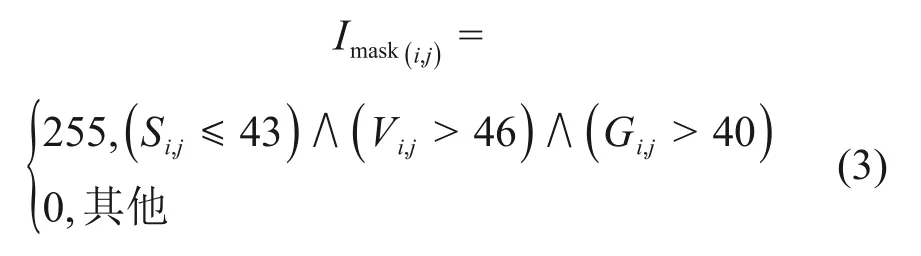
其中“∧”表示“并且”。式(3)用于基于顏色信息和灰度選擇滿足條件的遮罩區域,其中,閾值43,46和40是由實驗確定的。
使用第1.2節中描述的方法獲得二值圖像Ibin中連接區域的輪廓,并確定每個輪廓的邊界矩形。每個矩陣使用
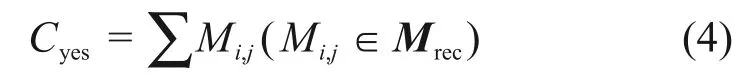
來計算掩模圖像Imask在相應矩形區域中的非零點數Cyes。其中,Mrec為圖像Imask中的相應矩陣;Mi,j為坐標(i,j)的像素。若Cyes大于圖像Ibin中矩形區域的總非零點的一半,則認為該區域包含過多的顏色像素,并且過濾掉圖像Ibin中的輪廓區域;否則,保留Ibin圖像中的輪廓區域。
1.4 輪廓與Canny邊緣的重合分析
現有的道路標線識別方法大多對道路分割結果進行簡單幾何濾波,提取圖像區域中的目標特征,然后進行特征匹配和分類[4-5]。當感興趣的范圍小或道路環境簡單時,采用該方法可取得較好的效果。但是,當感興趣的范圍較大(如車輛縱軸方向32 m,道路場景寬度18 m)或道路環境復雜時,僅通過目標大小、縱橫比、形狀特征等信息很難濾除非目標干擾,導致誤報率高,穩健性差。
經過IPM 變換后,原始路面上的非平行車道線在俯視圖中變得平行,俯視圖中的道路標線也變得更加規則。但是,在俯視圖中,原始圖像中具有一定高度的非目標(如前車、行人、路邊草、圍欄等)會被拉伸變形,這將使頂視圖像中非目標干擾的輪廓模糊,但路面上的交通標記不會受到影響,因為它們沒有高度。因此,Canny邊緣圖像與輪廓圖像在道路標線和非目標干擾的重合度上存在較大差異,即頂視圖中道路標線的邊緣和輪廓重合度較高。相反,非目標干擾符合度低,如圖3 所示。其中,圖3(a)中的非平行車道在圖3(b)中變為平行車道。與圖3(a)相比,圖3(b),圖3(c)和圖3(d)中的目標(道路標記)變得更加規則,非目標(車輛、草地和圍欄)在圖3(c)和圖3(d)之間表現出很大差異。圖3(c)和圖3(d)中的目標區域很匹配,而非目標區域則不匹配。
基于上述特點,提出以下非目標干擾濾波算法。
第1步,遍歷輪廓圖像中的每個輪廓,然后順時針掃描輪廓上的點,以確定輪廓與邊緣圖像重疊的最長長度Lmax。計算Rmax,即Lmax與輪廓總長度Lcontour之比:


圖3 Canny邊緣與俯視圖像中輪廓的比較Fig.3 Comparison between Canny edge and the contour in the top view image
第2 步,經實驗設置高閾值RH和低閾值RL;若Rmax<RL,則將輪廓點視為路面區域的像素點,并保留相應的輪廓區域;若RH<Rmax,則將輪廓點視為非路面的立體干擾物的區域的像素點,并過濾該輪廓點;若RL<R<RH,則繼續執行下一步。
第3步,確定包圍點鏈Lmax的最小矩陣Rin,并在Rin的基礎上向上、下、左、右4個方向擴展5個像素,得到更大的矩陣Rout。若在展開過程中遇到圖像的邊界,則停止沿該邊界方向展開。分別確定Rin和(Rout-Rin)區域灰度圖像的平均灰度Vin和Vout。若Vdelta=|Vin-Vout|>25,則表示內部和外部灰度之間的差異顯著,保留輪廓區域,否則丟棄。
使用收集到的20 000 多幅道路圖像進行非目標濾波實驗,發現非目標過濾后的非目標區域僅占原來二值化后的18.72%。這意味著在普通二值化基礎上,非目標濾波可以進一步去除81.28%的非目標干擾。
不同道路場景的非目標濾波結果如圖4 所示。其中,圖4中每個分圖從左到右依次為原始二值化結果、非目標濾波結果和最終測試結果。需注意的是,每個分圖中的中心圖像都顯示了與最左圖像相比的過濾結果,最左圖像中的大多數非目標都已被過濾掉。可見在不同的復雜環境下,非目標濾波算法有效地去除了大部分干擾,濾波結果與二值化結果相比有了較大改善。
1.5 形態處理與幾何濾波
如1.4節所述,去除二值圖像中的非目標干擾后,在檢測和識別道路標記時,處理時間和錯誤檢測率降低。然而,檢測到的道路標記有一些缺損,如破損或凹陷的標線,因此,在特征提取之前,有必要對一些形狀進行處理,即擴填后再減縮,以減少標記缺損,如圖5所示。
對邊界矩形進行面積濾波和縱橫比濾波。遍歷所有剩余的輪廓,并計算外接矩形的面積Arec和縱橫比Rrec,保留滿足以下規則的輪廓區域:
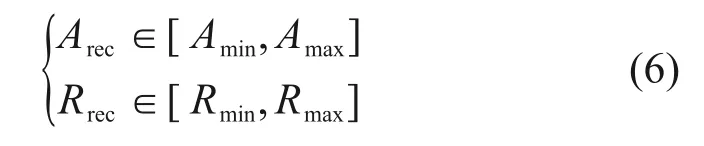
通過對采集到的所有圖像進行計數,并記錄俯視圖中道路標記的Arec最小值Amin和最大值Amax,以及俯視圖中道路標記的Rrec最小值Rmin和最大值Rmax,通過實驗確定面積和縱橫比的上下限。為了提高算法的適應性,將得到的最小值減少20%,最大值增加20%。
1.6 輪廓特征分析與分類
為了區分不同的道路標線,輪廓描述子需要在不同的道路標線類型之間具有很高的相似性,并且在相同的道路標線類型之間具有很高的相似性,同時還需要具有平移、旋轉和縮放不變性。
在文獻[21]中,利用輪廓形狀描述子來表示人體輪廓的形狀特征,并與視頻序列特征相匹配,實現步態識別。該描述子根據人體關節的高度在人體輪廓上分布28 個標記點,每個標記點到輪廓中心的距離構成28 維特征向量。地標點的分布假定不同人群的相對關節位置相同。
不同道路標線的形狀不同,因此,提出一種新的路標選擇方法,如圖6 所示(其中,Din為最內側交點距離中心點的距離,Dout為最外側交點距離中心點的距離)。

圖4 不同道路場景的非目標濾波結果Fig.4 Non-target filtering results of different road scenes
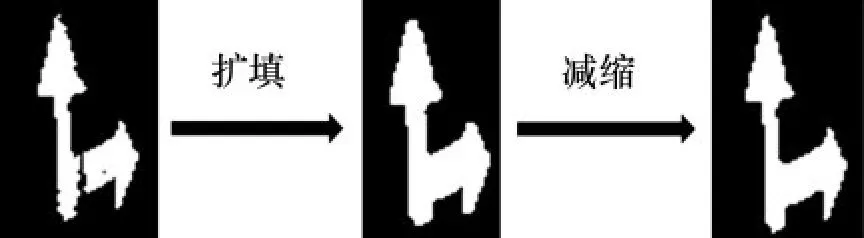
圖5 形態處理Fig.5 Morphology processing
該方法首先提取所有道路標記模板的輪廓,將其高度歸一化為最高高度,并保持縱橫比不變。從輪廓的幾何中心(O)開始,以規則間隔發出18條射線(如圖6(a)所示)。記錄每條射線與輪廓之間的內外交點(見圖6(b))。若每條射線有2 個以上的交點,則只保留最內側點和最外側交點。若射線沒有交點,則該射線對應的內、外距離均設置為0。若幾何中心于輪廓內,則該射線對應的內部相交距離設置為0,交叉點用作輪廓標記點。這里的距離是歐幾里德距離。因此,使用k×d維矩陣來表征道路標記的每個輪廓,其中,k=18表示每個輪廓使用的射線數為18,d=2表示交點的個數為2。要使矩陣對平移、旋轉和縮放保持不變,需要執行如下步驟。
1)將模板輪廓和實際道路標記輪廓(分別為MT和MR)的形狀矩陣中心化:
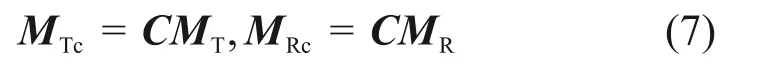
其中:中心矩陣C = Ik-(1/k)1k1Tk;Ik為1 個k×k的單位矩陣;1k是值均為1的k維向量。
2)將中心真實道路標記矩陣MRc進行變換、旋轉和縮放,得到中間矩陣MY:
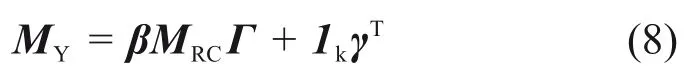
其中:β ∈?+,為比例因子;Γ 為d×d 維正交旋轉矩陣;γ 為1 個(d × 1)轉置的d 維向量;相似參數因子β,Γ和γ通過最小化矩陣MTc和MY之間的歐氏距離得到,即最小化
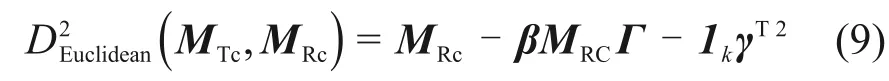
來得到MY。
3)使用以下公式計算模板輪廓與實際道路標線輪廓之間的相似度SCSA:
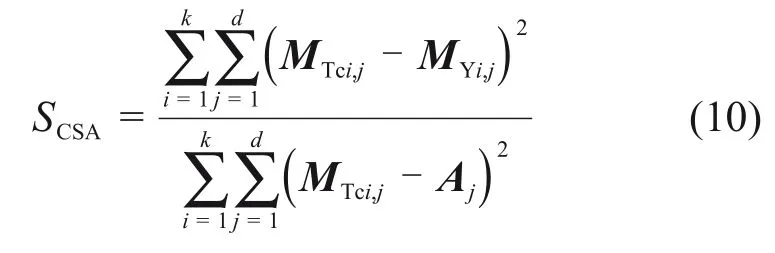
其中:A 為模板矩陣MTc的每個維度的平均值的行向量。SCSA的范圍為[0,1],表示2 個輪廓之間的相似性,其值越小,則表示2 個輪廓之間的相似度越小。
在實驗中,使用式(10)比較提取的輪廓與每種模板的輪廓的相似度,然后,根據相似度等級對它們進行排序,從而實現道路標線的分類。
1.7 橢圓傅里葉描述子的特征提取與分類
橢圓傅里葉描述子[22]比傳統的傅里葉描述子更適合描述復雜的單閉合輪廓,具有更高的描述精度和更少的系數,它對平移、旋轉和縮放具有不變性,對輪廓起點不敏感。
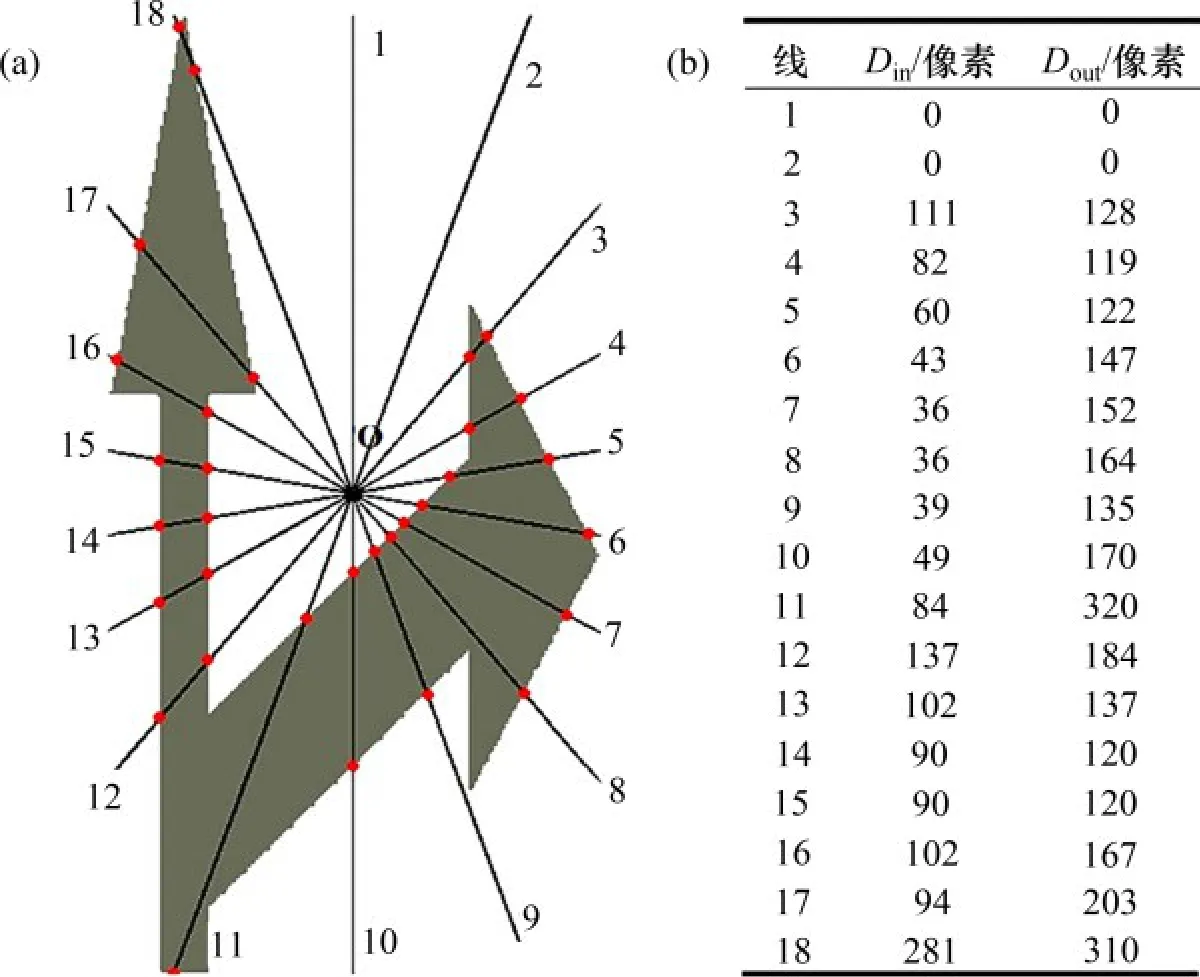
圖6 標記點采集方法示例圖Fig.6 An example diagram of the marking point acquisition
本文隨機選取輪廓上的1 個點(x0,y0)作為起點,沿輪廓逆時針方向遍歷,直至到達原點。在此期間遇到的點集記錄為(x1,y1),(x2,y2),…,(xN-1,yN-1)。把這些點集看作一個復雜的序列s(t),即
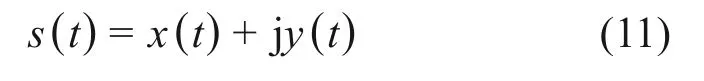
其中:t=0,1,2,…,N-1。Fourier 級數在輪廓的(x,y)方向展開如下:
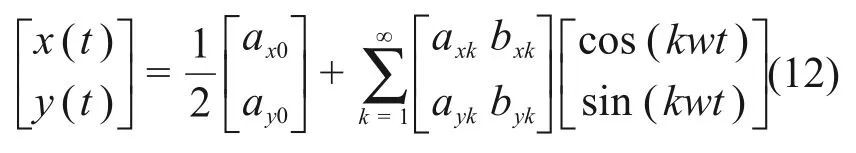
其中:
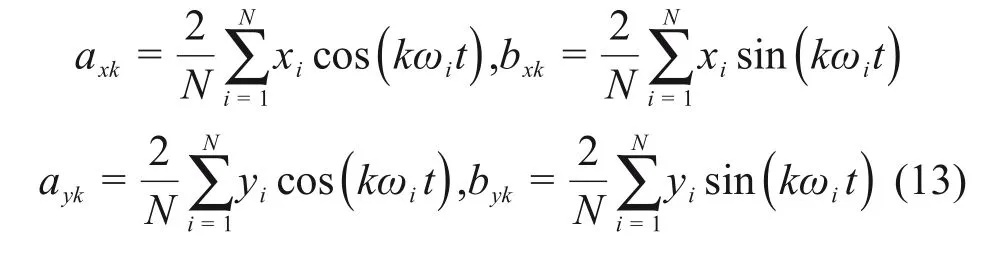
使用以下方法得到對平移、旋轉和縮放不變的橢圓傅里葉描述子:
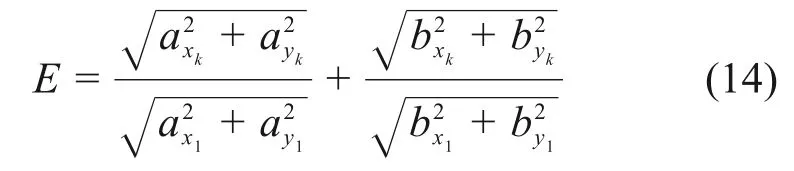
式中:E 表示提取到的橢圓傅里葉描述子(EFD)。由于低頻EFD 能表征輪廓的宏觀特征,而高頻EFD 能表征輪廓易受噪聲影響的細節,因此,僅選擇前36 個系數作為輪廓的橢圓傅里葉描述子。這些數據被傳遞給經過訓練的SVM[23]進行分類。
1.8 結果融合
由于道路交通環境的復雜性,不能保證提取的目標都是道路標線,并且可能存在少量的非目標干擾。因此,為了提高算法的魯棒性,使用以下簡單的規則來融合這2個分類結果:
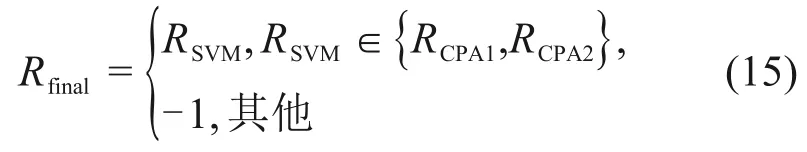
其中:RSVM為支持向量機分類的結果;RCPA1和RCPA2分別為輪廓特征分析的前2 個分類結果;Rfinal為最終結果。融合方法首先對輪廓特征分析的結果進行排序,然后確定支持向量機分類的結果是否在輪廓特征分析的前2個結果內。若是,則確認目標為道路標線,并將SVM 分類結果作為最終結果;否則,將提取的目標視為干擾。該融合方法提高了識別結果的可靠性,降低了誤報率。
1.9 目標定位及誤差補償
為了滿足無人駕駛汽車的要求,不僅需要確認正確的道路標記類型,而且需要知道它們的確切位置。根據第3節中的逆透視算法,將實際的感興趣的區域設置為車輛前方0~32 m,從左到右的距離為18 m;在俯視圖中,將水平和垂直方向上每個像素表示的實際物理距離分別設置為σx=8 cm和σy=5 cm。因此,逆透視變換后的俯視圖長×寬為w×h=360 像素×400 像素。然后,對于俯視圖中的每個像素(xm,ym),車輛坐標系中相應的實際位置(Xreal,Yreal)由以下公式給出:
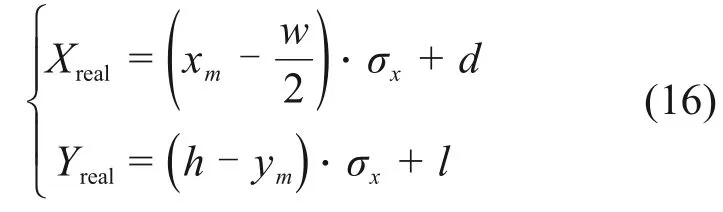
其中:d和l為補償值。獲取(Xreal,Yreal)后,從頂視圖圖像到原始圖像的映射由IPM[19]給出。類似地,當俯視圖中道路標記的坐標已知時,由式(16)給出車輛坐標系中的實際位置。
為了分析定位誤差,將實驗車輛開到道路標線的后部,使車輛前部垂直于標線的下邊緣。然后,讓算法自動識別道路標線,并在計算機顯示器上實時輸出標線的位置坐標(Xreal,Yreal)。然后選擇標記識別框的左下角作為參考點,并使用標尺測量其實際坐標。每次記錄后,倒車1~2 m,直到32 m左右。
由于攝像機標定參數的誤差,在識別距離內的道路標線時可能存在較大的定位誤差,因此,使用最小二乘法對算法的測量結果和誤差進行多項式擬合。最后,算法的位置輸出是原始測量值加上補償值d和l的結果。
2 結果與討論
使用車載相機拍攝了我國長沙、上海和蘇州的城市交通,總共獲得29 850 張圖像,其中包括1 032張帶有道路標記的圖像。對原始視頻(30幀/s)進行截圖采樣,生成圖像數據集。圖像采集是在晴天、多云和小雨天氣以及正常、磨損和其他道路條件下進行的。
實驗中使用8 種常見的道路標記,如圖7所示。
圖8 所示為所提出的算法所涉及的各種過程。該算法的輸出包含標記的類型及其在車輛坐標系中的位置,其中,圖8(f)所示為過濾掉圖8(b)中非目標區域的結果,可以發現干擾基本上被過濾了。
圖7 8種常見的道路標記Fig.7 8 types of common road markings
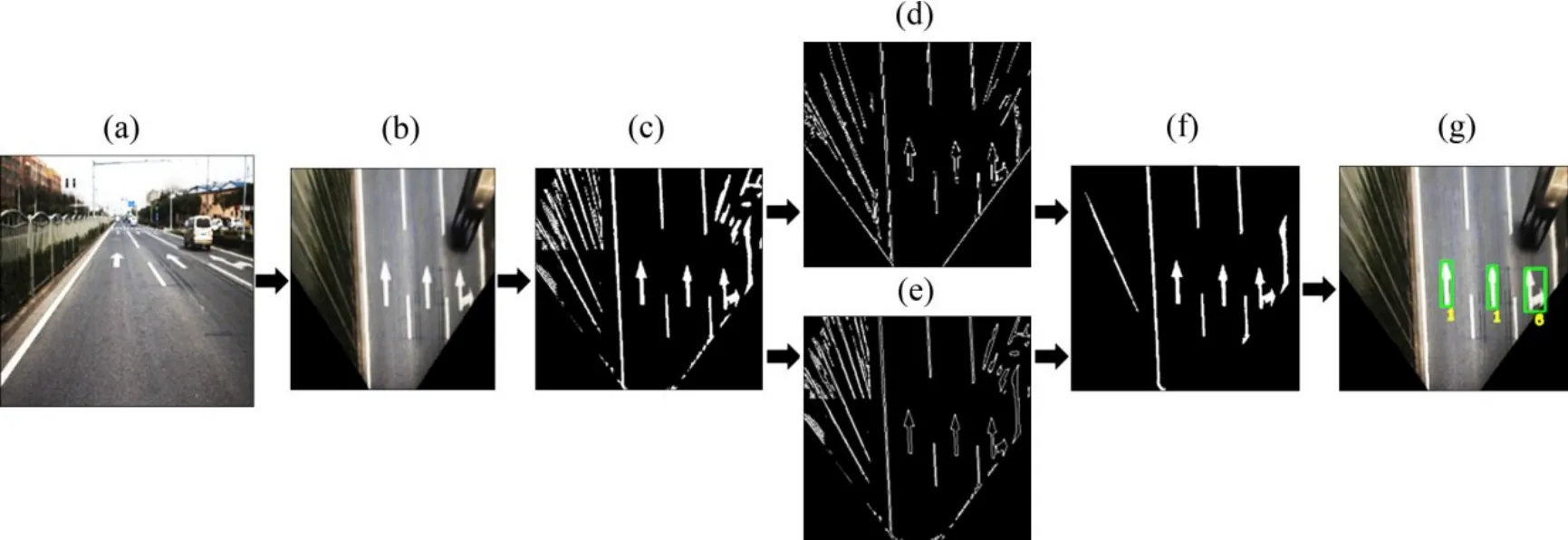
圖8 算法的檢測與識別過程Fig.8 Detection and recognition processes of algorithm
2.1 檢測和識別結果分析
為了比較非目標濾波算法對最終檢測和識別結果的影響,分別進行2組實驗來確定是否使用非目標濾波算法。這2個實驗的實驗條件除了1個有非目標濾波算法和1 個沒有非目標濾波算法之外,其他均相同。實驗結果如表1所示。表1中,一些重要參數說明如下:對于路況,若路面標記磨損率小于15%,且主要特征信息不受影響,則表示路況正常,否則為磨損(極其骯臟的路面也視為磨損)。在天氣變量中,“√”表示測試集中包含該天氣條件的對應類別的圖像,“×”表示測試集中不包含該天氣條件的對應類別的圖像。
從表1可見:當路面磨損或變臟時,算法的召回率降低,這會導致目標在二值化過程中被誤認為是背景,從而導致最終檢測和分類失敗。其中,FP為將正樣本誤識別為負樣本的數量,即未正確識別出來的標記數。
由實驗統計結果可以發現:非目標濾波算法的使用對誤報數量產生了很大影響,誤報總數由2 036 個減少到268 個,整體識別準確率由90.90%提高到98.69%。但非目標濾波算法對召回率的影響很小,總召回率僅從94.31%下降到94.02%,說明非目標濾波算法幾乎不會誤濾出真實道路標記。此外,非目標濾波的使用顯著提高了算法的整體性能,精確率和召回率的調和平均數F1從92.57%提高到96.30%。
不同天氣條件下的識別準確率、召回率和F1如圖9所示。從圖9可見:在多云情況下,道路上沒有強烈的陰影和反光效果,準確率、召回率和F1都接近98%;然而,在陽光充足的條件下,路邊的樹木會對道路產生大量的強烈陰影,干擾目標檢測,導致算法精度下降;在小雨條件下,環境的照度較低,潮濕的路面上有反射,可能導致目標檢測失敗,召回率低。雖然惡劣的天氣會對算法產生一定的影響,但算法整體性能良好,F1保持在92%以上,說明算法具有良好的魯棒性。
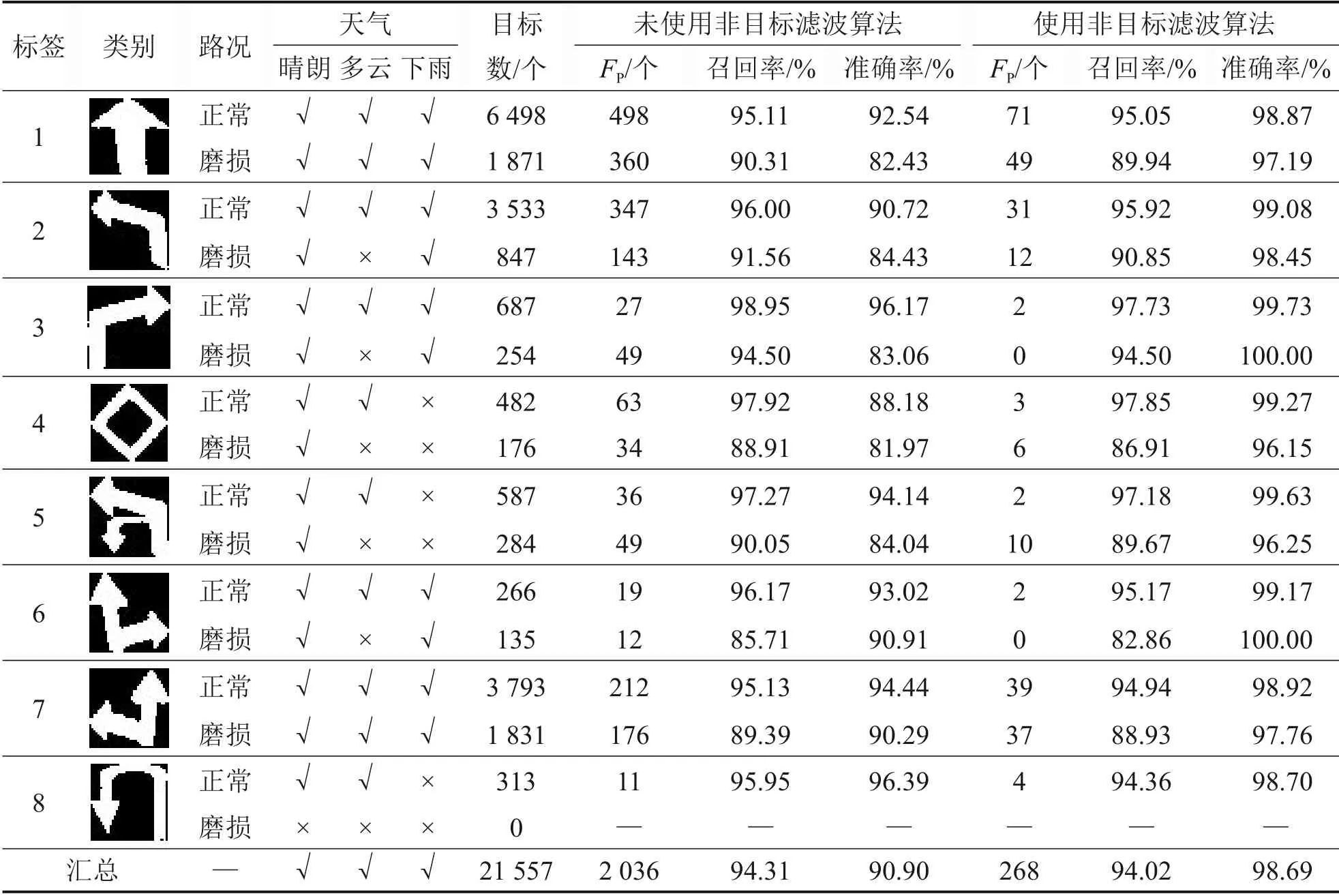
表1 道路標記檢測與識別統計結果Table 1 Statistical results of detection and recognition of road markings
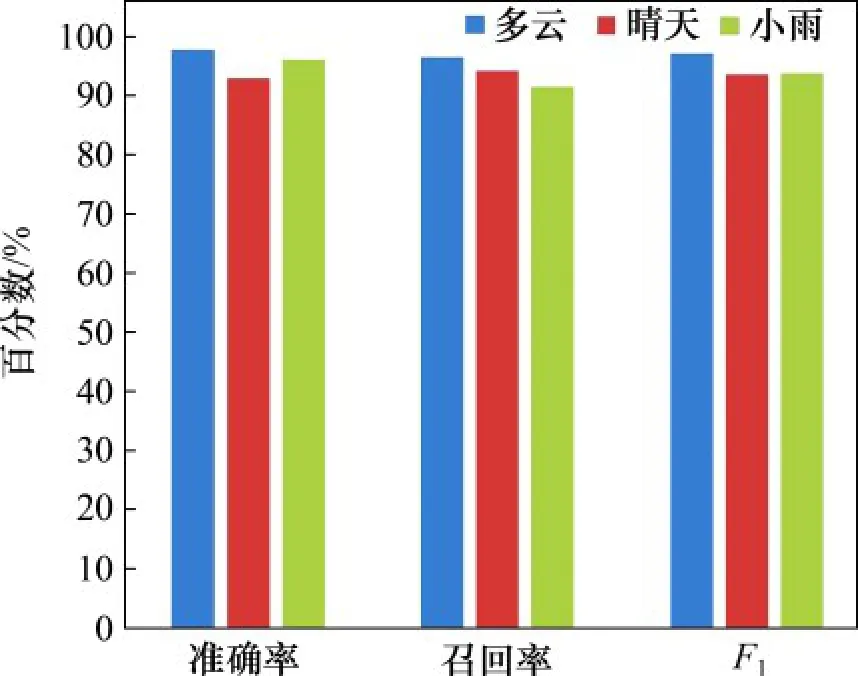
圖9 不同天氣條件下的識別準確率、召回率和F1Fig.9 Identification accuracy,recall rate and F1 under different weather conditions
2.2 與其他算法的比較
為了比較不同算法的性能,將文獻[5-6,14-18]中的算法和本文算法的實驗結果進行比較,如表2所示。
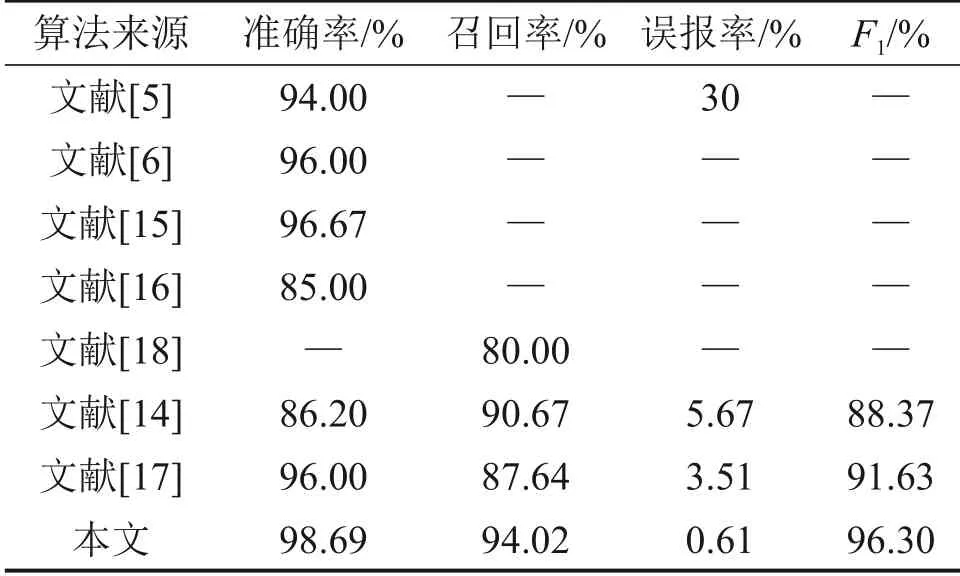
表2 不同算法的識別性能Table 2 Recognition results of different algorithms
從表2 可以看出,本文算法與其他算法相比,召回率高,精確率和召回率的調和平均數F1高,誤報率低。
另外,本文算法是基于俯視圖進行檢測和識別,確保目標矩形內不會有車道或其他干擾跡象。然而,文獻[14,16]中的方法直接從原始圖像中檢測和裁剪目標,這可能導致目標檢測框包含其他干擾,從而導致識別錯誤。
通過比較發現:文獻[5,14]中的方法在檢測前并沒有很好地濾除非目標干擾,在檢測和識別的后期也不能完全濾除干擾,導致誤報率較高。
在本文算法中,經過二值化后,首先使用非目標濾波算法濾除大部分干擾,然后在識別后期使用2種不同的特征描述道路標線輪廓,并融合它們的結果,保證了系統的識別精度高,誤報率低。
各種路況的道路標記檢測與識別的結果如圖10 所示。從圖10 可見:檢測和識別道路標記的視覺結果較好,它在絕大多數復雜的道路場景下都保持了良好的性能。但由于信息不足,很臟的道路可能會導致識別失敗。
2.3 目標定位及誤差補償結果
圖11 所示為補償前后算法測量距離輸出與誤差比較。其中,圖11(a)和圖11(b)中的橫坐標為使用標尺測量的實際距離,圖11(a)中縱坐標為算法的測量距離,圖11(b)中縱坐標為測量距離誤差。
由圖11 可見:近距離(<15 m)算法測量誤差小于30 cm,在一定距離內最大誤差可達1.11 m,但采用非線性補償算法后,無論實際距離多長,誤差均保持在30 cm以內,保證了無人駕駛系統對道路標線的精確定位。
2.4 實時性能分析

圖10 各種路況的道路標記檢測與識別的結果Fig.10 Examples of various road marking detections and recognition results colored with green box
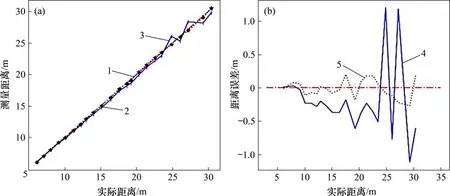
圖11 補償前后算法輸出與誤差比較Fig.11 Comparison of output and error before and after compensation
標準化組織3GPP定義了幾個低延遲場景,主要集中在自動駕駛上。自動駕駛制動反應時間是系統響應時間,包括網絡云計算和車間協商處理時間,以及車輛系統計算和制動處理時間。若速度為100 km/h 的制動距離不超過 30 m,則系統的整體響應時間不能超過10 ms,而最好的F1賽車手的響應時間大約為100 ms。
道路標記識別系統的硬件平臺為Advantech ARK-3500 IPC, Intel (R) Core i7-3610QE CPU @2.3GHz, 15.76G RAM,使用的編程語言為C++。共使用分辨率為1 920 像素×1 200 像素的29 850 幅彩色圖像,對道路標線進行檢測和識別。識別系統各階段的平均運行時間見表3。

表3 各階段算法運行時間Table 3 Time of algorithm running at each stage
3 結論
1)提出了一種基于輪廓重合度分析的道路標記識別算法,該算法在不同光照、天氣、道路等交通環境條件下保持了良好的檢測和識別性能。提出的非目標濾波算法有效地濾除了普通二值圖像中81%以上的干擾,并將輪廓分析結果與基于EFDs 的支持向量機識別結果相結合,對最終結果進行了改進。該算法的最終召回率以及精確率和召回率的調和平均數F1較高,誤報率較低。
2)本文提出的道路標線識別算法可以在未來應用于無人駕駛場景。道路標線可以為道路上行駛的車輛提供預告性的信息,對無人駕駛系統得出正確的反應策略具有重要作用。因此,及時、準確地識別出車輛前方的道路標線,可以為無人駕駛技術提供關鍵、可靠的道路信息。特別地,在地圖信息的通信信號質量不佳的情況下,道路標記提供的信息顯得尤為重要。
3)提出的定位補償算法有效地提高了道路標線檢測的精度,可以滿足無人駕駛技術對道路標線檢測精度的要求。
本文研究還存在一些不足,如:該算法只能用于白天的道路輪廓分析和道路標記識別,不能用于夜晚的道路輪廓分析和道路標記識別。其次,該算法只能識別幾種常見的國際道路標記,而不能全部識別。未來的工作核心將聚焦于擴展訓練數據集類別,增加算法能識別的道路標記種類,使算法功能更全面。其次,需要研究適合夜晚場景下的道路標記識別算法,并進行針對性分類訓練和實驗。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
