消除隨機一致性的支持向量機分類方法
2020-08-25 07:34:00王婕婷錢宇華李飛江劉郭慶
計算機研究與發展 2020年8期
王婕婷 錢宇華 李飛江 劉郭慶
(山西大學大數據科學與產業研究院 太原 030006)(計算智能與中文信息處理教育部重點實驗室(山西大學) 太原 030006)(山西大學計算機與信息技術學院 太原 030006)(jietingwang@email.sxu.edu.cn)
在決策過程中,當人類缺乏足夠的證據或詳細的知識時,可能會進行邏輯欠缺的隨機猜測[1-6].例如學生在面對困難的多項選擇題時喜歡選擇自己幸運的選項.有時,這些隨機猜測可能與實際情況形成一致性,我們稱這種一致性為隨機一致性.隨機一致性的存在會誤導邏輯形成方向,導致決策結果無意義、信息含量少、擴展能力差.在隨機猜測與真實情況的分布相同時,這些缺點尤為明顯.
基于智能算法的機器學習系統本質上是一種由數學表達與邏輯運算構成的決策函數,被認為具有較強的客觀性與確定性,不像人類容易受外部因素的影響,出現主觀臆斷的現象.然而,1)智能學習算法是數據驅動的.機器學習算法面對的歷史數據通常具有數量有限、類別分布不平衡、含噪音等特質[7-9],這使得學習機所面對的學習證據缺乏完備性、充分性與準確性.那么,基于歷史數據所得的決策知識與數據蘊涵的潛在模式可能會出現偏差;2)智能學習算法是目標導向的[10-11].智能算法的設計目的、數據運用、結果表征等都是開發者、設計者的主觀價值選擇,算法設計者在把算法邏輯輸入機器的同時,也將具有隨機性的判斷方式帶到了學習機中.基于上述分析,智能算法也會呈現隨機一致性,并且在自我提升的反饋循環中又可能會把隨機一致性帶來的后果進一步放大或者固化,嚴重影響到自身泛化性能的提升.
目前,大多數機器學習算法以準確度為目標導向.例如,決策樹所采用的信息熵,k近鄰算法中所采用的投票準則,以及支持向量機,Adaboost等經典學習算法所使用的損失函數都與準確度有著密切的關系[12-13].然而,簡單的準確度指標作為反饋或啟發準則包含了由于偏差所導致的隨機一致性,這對于學習機泛化性能的評價是不合理的.
因此,研究如何消除學習過程中的隨機一致性,從而建立基于純一致性度量(消除隨機一致性的一致性度量)的機器學習算法與理論體系已成為人工智能研究領域的一個重要科學問題[14-17].
支持向量機(support vector machine, SVM)是傳統機器學習中泛化能力較強、理論保障較為完善的方法之一,被廣泛應用在故障診斷、文本分類等各個領域.本文首先給出純準確度的定義,然后提出基于純準確度的支持向量機分類方法PASVM,并通過KEEL數據集驗證PASVM的泛化性能.
1 純準確度指標
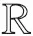

Table 1 Confusion Matrix表1 混淆矩陣
TP(true positive)表示正類樣本被分為正類的比例;
FN(false negative)表示正類樣本被分為負類的比例;
FP(false positive)表示負類樣本被分為正類的比例;
TN(true negative)表示負類樣本被分為負類的比例;
p表示真實類別中正類的比例;
q(h)表示分類器輸出正類的比例.
基于混淆矩陣,準確度A和錯誤率L的定義分別為
A(h)=TP(h)+TN(h),
(1)
L(h)=FN(h)+FP(h).
(2)
1.1 隨機準確度指標和純準確度指標的定義
如引言所述,分類器構建過程中存在著不可避免的隨機因素.本文引入置換劃分集來刻畫隨機因素對分類結果的影響.
定義1.置換劃分集Hq(h)為類別分布與待評估分類器h(X)相同的所有可能的二值劃分組成的集合:
Hq(h)={h′:P(h′(X)=+1)=
q(h),h′(X)=±1}.
(3)
例1.對于只包含3個樣本的數據集,假設待評估分類器的類別分布為q(h)=2/3,那么置換劃分集為包含3種二值劃分的集合:
Hq(h)={h1=(-1,+1,+1),h2=(+1,-1,+1),
h3=(+1,+1,-1)}.
當分類器視被視為一個隨機變量時,其分類結果的隨機性可以通過類別分布來體現.置換劃分集包含了與當前分類器輸出分布相同的所有可能的劃分結果.基于此,置換劃分集的某些數字特征可用來刻畫隨機性導致的一致性.本文使用置換劃分集中所有劃分的平均準確度來衡量隨機一致性,并且因缺乏劃分對數據偏好信息的先驗(傾向劃分哪些樣本為正類),我們假設所有的劃分以相同的概率出現.
引理1.當置換劃分集中的所有劃分是均勻分布的,其平均準確度為
Eh′:h′∈Hq(h)(A(h′))=pq(h)+
(1-p)(1-q(h)).
(4)

當置換劃分集中的劃分服從均勻分布時,TP(h)服從參數為(N,Np,Nq(h))的超幾何分布,即從N個樣本中(其中包含Np個正類樣本)中不放回地抽出Nq(h)個樣本,TP(h)表示其中包含正類樣本的個數.于是,我們有:

其中j=0,1,…,Nq(h).進一步基于超幾何分布的2個重要公式:

(6)
我們有:

(7)
證畢.

定義2.分類器h(X)的隨機準確度定義為
RA(h)=pq(h)+(1-p)(1-q(h)).
(8)
定義3.分類器h(X)的純準確度定義為

需要指出的是,純準確度與統計學中的κ指標形式相同,不同的是κ指標從評估者獨立時的一致性來刻畫隨機一致程度[16].隨機準確度的定義更具有啟發意義,可指導其他指標中隨機一致程度的定義,也可以擴展置換劃分集的定義形式和概率分布來定義新的形式.
純準確度從準確度中減去隨機一致的部分,再除以上界使得最大值歸一化,其定義框架與聚類中的調整蘭德指數[4-5,7-8]相同.圖1展示了純準確度指標以隨機準確度值為基準線(零值線);準確度指標以絕對零值為基準線.純準確度指標是相對指標,衡量算法優于隨機劃分的程度,而準確度指標是絕對指標,衡量算法取得的分數.在機器學習中,不同任務的數據集,不同類型的運行環境,不同的算法,導致分類器產生程度不同的隨機一致性.因此純準確度指標作為評價指標更為合理客觀,具有更多的信息量.

Fig. 1 The diagram of the baseline圖1 基準線示意圖
定義4.分類器h(X)的純錯誤率定義為

進一步,純錯誤率還可以表示為


純準確度指標和純錯誤率指標屬于線性分式指標.線性分式指標是指形式如(13)的指標:

其中,ai,bi(i=0,1,2)是不為零的常數.類似指標還包括F1-measure和精確率Precision等.
1.2 隨機準確度的進一步分析
本節進一步分析隨機準確度在評價過程中的作用及意義.圖2展示了隨機準確度值RA與真實標簽的類別分布p及輸出標簽的類別分布q之間的曲線圖.可以看到,(0.5,0.5)是純準確度曲面的鞍點:在p=q方向,0.5是曲面的最小值點;在p+q=1方向,0.5是曲面的最大值點.

Fig. 2 The relationship between the random accuracy and the class distribution圖2 隨機準確度與類別分布的關系
準確度指導的分類器往往過度擬合大類樣本.純準確度值隨著準確度的增加而增加,隨著隨機準確度的減少而增加.在純準確度指導下,為了保證較高的準確度,分類器與真實標簽類別分布趨勢應該相同(同時小于或大于0.5);為了保證達到較低的隨機準確度,分類器應該趨近于無偏的(輸出分布接近于0.5),進而有望更加接近于真實分布.基于上述分析,可以看到隨機準確度使得純準確度追求完全的輸出隨機性(輸出概率為0.5),而不是依賴于經驗數據的有偏差的隨機性.
在實際任務場景中,機器學習算法面對的數據越復雜,所得到的分類模型與真實模式之間的偏差越大,相對于真實模式的隨機性越強,從而產生更高的隨機一致性.表2展示了10種不同任務的數據集.我們通過改變數據的不平衡度和噪音水平來驗證隨機準確度是否能捕捉到偏差造成的隨機一致性.具體地,通過對每個數據集的小類樣本欠抽樣,得到不同IR(imbalance ratio)的數據集.IR表示大類與小類樣本的數量比例.通過數據的標簽加入單邊噪音,得到不同噪音水平的數據集.這里,單邊噪音是指小類樣本的標簽隨機均勻地被污染為大類.在人工標注中,這種單邊噪音相較于另一側的單邊噪音(大類標注為小類)更為常見.
然后,每個數據集按照7∶3的比例劃分為訓練集和測試集,使用訓練集建立SVM分類器.實驗進行30次,圖3和圖4的記錄了測試隨機準確度值(箱線)及其平均值(紫色圈),從圖3和圖4可以看到,隨著IR和噪音水平的升高,隨機準確度的值升高,這說明隨機準確度的定義是有意義的.

Fig. 3 The random accuracy increases with the increase of imbalance degree圖3 隨機準確度隨著不平衡程度的增加而增加

Fig. 4 The random accuracy increases with the increase of the one-size noise level圖4 隨機準確度隨著單邊標簽噪音水平的增加而增加
2 基于純準確度的支持向量機模型
為了消除SVM模型的隨機一致性,本文提出優化純準確度的SVM模型.首先,簡要回顧SVM模型,可用來優化純準確度指標的SVMperf(support vector machine for multivariate performance measures)模型及梯度下降法.然后,給出基于純準確度指標的SVM模型PASVM及其求解過程.
2.1 SVM、SVMperf及梯度下降法回顧
SVM模型是傳統機器學習中泛化能力較強的分類方法之一,該方法的基本思想是樣本點不僅能夠正確分類并且所有樣本點到分類器界面的距離要盡可能大.

SVM模型為
s.t. ?i:ξi≥0,yi(wTxi)≥1-ξi,
(15)
其中,ξi是錯誤率的上界.參數C為錯誤率和權重項的折中參數.SVM模型也可以等價表示為
為了構建優化F1-measure,Precision等多元復雜指標的SVM模型,文獻[18]提出SVMperf模型.SVMperf模型可以用來優化純準確度.其基本思想是將所有訓練數據看作一個整體,然后要求真實標簽向量與其他所有可能標簽向量之間的間隔要超過它們之間的評價指標值.


其中ξ可證明是目標度量Ψ的上界.參數C為錯誤率和權重項的折中參數.
與傳統的SVM模型相比,SVMperf的待解變量減少,然而約束條件的個數為2N-1個,與樣本數量呈現指數增長關系.

其中ε為折中參數.在二類分類問題中,線性分式指標Ψ的梯度定義為

據此,模型參數w的更新公式為
其中λ為更新步長.
2.2 PASVM模型
構建基于純準確度指標的支持向量機模型最直觀的方法之一是使用純錯誤率指標替代傳統SVM模型中的錯誤率指標:

其中,L=EX,YI[Yh(X)<0],q=EYI[Y>0],I[·]為示性函數.
這個目標函數的難點在于純錯誤率指標呈分式形式,并且L和q中存在不連續的非凸的示性函數.L中的示性函數表征樣本是否被錯誤分類,q中的示性函數表征樣本是否屬于正類.在本文所采用的優化方法中L出現在目標函數中,q出現在約束條件中.因此,本文使用連續的凸的hinge函數和有界的sigmoid函數分別近似L和q中的示性函數:

(19)
那么,基于純準確度指標的SVM模型為
(20)
稱之為PASVM模型.
定理1.表示定理[20].設Ω是一個嚴格單調遞增函數,c是任意損失函數.則每一個正則化風險

(21)
的最優解滿足:
(22)

易知,PASVM模型滿足表示定理.對于PASVM所使用的線性分類器,模型參數w的最優值滿足:
(23)
即最優值由訓練數據X張成.此時,模型的決策函數為
(24)
由表示定理可得,PASVM的核函數形式為

(25)
PASVM的求解問題屬于帶有正則項的分式規劃問題:

其中,g2(z)≥0,g3(z)>0.令

此類問題的解可以等價轉換求解z(r*),其中,

(28)
可以看到,上述過程將分式規劃問題式(26)轉換為一個帶有約束的規劃問題式(27)和一個一維優化問題式(28)[21].
然而,對于PASVM模型而言,在訓練集上,分母的最優值為p+(1-2p)p.因此,可以省去r*的尋找.基于此,PASVM模型的最優解可以通過以下帶有約束的規劃問題求得:

(1-2p)p.
與傳統SVM模型相比,PASVM模型多了一個約束條件.與SVMperf模型相比,借助分式規劃問題,PASVM只需要一個約束條件實現求解,這得益于純準確度的分母形式可以表示為真實標簽和預測標簽類別分布的函數.對于F1-measure,Precision而言,使用上述分式規劃式(26)求解可能需要尋求最優的r*.
為了進一步提高PASVM模型的泛化能力,我們將半監督學習的思想融入到模型求解過程中.半監督學習使用大量的未標記數據,以及同時使用標記數據進行機器學習.從式(19)中可以看到,q的計算未使用樣本的標簽.因此,規劃問題式(29)約束條件的可以使用未標記數據.具體地,規劃問題式(29)可以擴展為


其中,樣本xi,xj屬于同一集合并且都是標記數據:xi,xj∈D1;xk屬于另外一個集合,是標記數據或者未標記數據:xk∈D2.Nt為數據集Dt的樣本數量,t=1,2.算法1給出PASVM的分類方法.
算法1.基于純準確度的支持向量機PASVM.
輸入:標記數據集D1、數據集D2、參數C、待分類樣本x;
輸出:預測結果.
1) 初始化αj為[0,1]區間的任意值;
2) 計算核相似度矩陣K(xi,xj),xi,xj∈D1,K(xk,xj),xj∈D1,xk∈D2,計算
3) 使用內點法求解問題式(30),得到模型參數αj,j=1,2,…,N1;
4) 預測結果
3 實驗分析
為了驗證基于純準確度的SVM方法具有更加優異的性能,本文將PASVM方法與傳統的SVM方法、SVMperf[18]、梯度下降法[19]及優化純準確度的Plug-in[22]和Bisection[22]方法進行比較.
Plug-in方法的決策函數形式為
其中,η(x)=P(Y=1|X=x)為后驗類屬概率,δ為決策閾值.Plug-in方法是二步法,首先根據已有成熟的概率估計的方法得到后驗類屬概率,再按照某種搜索方法得到使得目標度量最大的決策閾值.Bisection方法歸屬于Plug-in這一類方法,不同的是Bisection方法按照二分法搜索δ.
3.1 數據集及設置
本文在KEEL[23]的10種基準數據集上測試PASVM的有效性.10種數據集詳細信息描述如表2所示:

Table 2 Description of the Data Set表2 實驗數據集描述

因對比算法未使用測試集進行學習,為了保證比較的公平性,在實現算法1的過程中,我們不使用測試數據集計算約束條件,而是將訓練集的樣本按照7∶3的比例劃分為D1和D2,p的計算按照D2中屬于正類的比例計算.
在每個數據集上,進行50次實驗對比,以此考察算法的平均性能.每一次對比在相同的劃分下進行.另外,為了創造更加復雜的數據環境,本文對數據集依次加入3%,5%的隨機均勻分布的標簽噪音.
3.2 實驗結果及分析
表3~5分別列出了標簽噪音為0%,3%,5%這3種情況時,6種算法在10個數據集上的準確度的平均值和標準差.表6~8分別列出了標簽噪音為0%,3%,5%這3種情況時,6種算法在10個數據集上的純準確度的平均值和標準差.黑體表示算法在該行數據集上取得了最高的性能值.每個數據集上,性能值最高的算法排序為1,性能值第二高的算法排序為2,以此順推.算法的性能值越高,序值越小.表格最后一行的Average Rank表示每列方法在所有數據集上序值的平均值,越小說明算法取得的性能值越好.表格中的黑色圓點表示PASVM顯著好于該方法.顯著性檢驗方法為配對t檢驗,顯著性水平為0.01.

Table 3 Comparison of Accuracy on Data Sets with 0% Noise (Mean±Standard Deviation)表3 無噪音時不同算法的準確度比較(均值±標準差)

Table 4 Comparison of Accuracy on Data Sets with 3% Noise (Mean±Standard Deviation)表4 噪音水平為3%時不同算法的準確度比較(均值±標準差)

Table 5 Comparison of Accuracy on Data Sets with 5% Noise (Mean±Standard Deviation)表5 噪音水平為5%時不同算法的準確度比較(均值±標準差)

Table 6 Comparison of Pure Accuracy on Data Sets with 0% Noise (Mean±Standard Deviation)表6 無噪音時不同算法的純準確度比較 (均值±標準差)

Table 7 Comparison of Pure Accuracy on Data Sets with 3% Noise (Mean±Standard Deviation)表7 噪音水平為3%時不同算法的純準確度比較(均值±標準差)

Table 8 Comparison of Pure Accuracy on Data Sets with 5% Noise (Mean±Standard Deviation)表8 噪音水平為5%時不同算法的純準確度比較(均值±標準差)
表3~8的數據表明,整體而言,PASVM取得了較高的準確度和純準確度值.相較于其他優化準確度的方法,PASVM能夠更好地優化純準確度.
為進一步分析表3~8的實驗結果,在95%置信水平下統計每種方法比其他方法統計性好的次數與統計性差的次數之間的差值.具體地,對于數據集的集合S,算法a比算法a′統計性好的次數為
(31)
算法a比算法a′統計性差的次數為
(32)

圖5與圖6展示了在準確度和純準確度意義下,每種算法的Ba-Wa值.圖5與圖6顯示,在不同噪音水平下,PASVM取得了較高的差值,這說明PASVM算法顯著性好于其他算法.

Fig. 5 Significant difference comparison of accuracy圖5 準確度顯著性差異比較

Fig. 6 Significant difference comparison of pure accuracy圖6 純準確度顯著性差異比較
接下來,對PASVM的參數進行分析.圖7~9展示了不同噪音水平下,PASVM在驗證集上的純準確度值.可以看到,核函數參數對PASVM的影響比較大,不同數據集上不同核窗寬參數的最優值差異較大.同一核參數下,不同的折中參數得到的驗證值基本保持在同一水平.

Fig. 7 The impact of parameters on validation sets with 0% noise圖7 無噪音時參數的影響

Fig. 8 The impact of parameters on validation sets with 3% noise圖8 噪音含量為3%時參數的影響

Fig. 9 The impact of parameters on validation sets with 5% noise圖9 噪音含量為5%時參數的影響
4 總 結
為了消除傳統支持向量機中的隨機一致性,本文給出了純準確度的定義框架,提出了基于純準確度的支持向量機模型PASVM.該方法不僅提升了傳統SVM的性能,相比于其他優化純準確度的方法,明顯提升了純準確度值.在未來的工作中,進一步考慮更具與普遍意義的置換劃分集的分布來定義其他形式的隨機準確度,這將有助于提高分類器對于其他類型的隨機性的區分程度.另外,構建消除隨機一致性的深度學習模型,以此進一步提高深度學習的性能,也是未來值得關注的研究方向.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
燕山大學學報(2015年4期)2015-12-25 02:19:49
Coco薇(2015年1期)2015-08-13 02:47:34
