HPEC中子程序級推測并行性分析
2020-08-19 07:01:02王欣夷王耀彬卜得慶劉志勤
計算機工程 2020年8期
關鍵詞:程序
王欣夷,王耀彬,李 凌,楊 洋,卜得慶,劉志勤
(1.西南科技大學 a.計算機科學與技術學院; b.四川省軍民融合研究院,四川 綿陽 621010;2.四川省計算機研究院,成都 610041)
0 概述
隨著半導體工藝的發(fā)展,單個芯片上的核心數(shù)量不斷增加,其為芯片帶來了更多的可用計算資源[1],但如何充分利用這些片上計算資源成為目前亟待解決的問題。程序并行化是有效利用現(xiàn)有片上計算資源的一種手段,但手動并行化方法較為繁瑣且容易出錯,因此,線程級推測(Thread-Level Speculation,TLS)技術受到廣泛關注[2]。
TLS技術作為一種支持多核處理器的自動并行化技術,可有效提高并行化效率,并在不違反串行執(zhí)行語義的情況下,將串行代碼劃分到多個線程中并行執(zhí)行,自動挖掘程序潛在并行性,進而提高片上硬件計算資源利用率[3-5]。在TLS技術中,由于子程序和循環(huán)迭代在程序中運行時間較長,常將其作為推測線程的候選區(qū)域[6]。目前,TLS技術的研究主要以循環(huán)迭代為主,并未在子程序方面進行深入分析。由于子程序中局部變量的作用范圍通常在其內部,局部變量的訪問極少與作用域外的程序產生數(shù)據依賴,具有較好的獨立性[7],因此對TLS技術的子程序級進行深入分析是很有必要的。
早期研究主要通過比較單位時間內運行指令數(shù)的多少來評測處理器性能,其衡量標準過于單一,并不能系統(tǒng)地評測處理器多方面因素所造成的影響。相較而言,20世紀80年代提出的benchmark更為業(yè)界所認可。HPEC基準套件由麻省理工學院研發(fā),旨在為信號處理、通信等領域提供一套明確定義的基準,以對其庫和系統(tǒng)的性能進行評測[8]。目前,該基準套件已在GPU、DSP以及基于VSIPL++的并行應用程序接口(Application Programming Interface,API)等方面得到應用,但并未使用TLS技術,特別是在子程序級方面未對其進行深入研究。
本文對HPEC應用在子程序級推測并行化中的并行性提升潛力和運行時的影響因子進行分析。通過選取HPEC中7個具有代表性的程序,設計一種子程序結構的動態(tài)剖析機制,結合用于保存子程序調用的核心數(shù)據結構,分析線程粒度、可推測并行區(qū)域覆蓋率、線程間數(shù)據依賴、子程序調用次數(shù)以及程序源代碼對程序并行化性能提升潛力的影響,并結合推測執(zhí)行結果分析程序加速比的主要影響因素。
1 相關工作
在對TLS技術的軟硬件支持[9]進行綜合研究后,各種線程推測方案相繼出現(xiàn),較為典型的方案包括Hydra多處理器[10]、POSH線程級推測系統(tǒng)[11]、SMA系統(tǒng)[12]等。文獻[13-14]使用基于模糊聚類的推測多線程劃分算法對Olden程序進行測試,其加速比平均可達1.85。文獻[15]在硬件事務內存上進行線程級推測,其循環(huán)結構獲得3.8倍的加速。文獻[16]對反向傳播神經網絡等應用的線程級推測并行性進行了分析。綜上所述,線程級推測技術已能有效地運用在多種類型的串行應用自動并行化工作中。
目前,關于HPEC的研究集中在循環(huán)結構方面。文獻[17]在GPU上開發(fā)了HPEC基準測試的高效實現(xiàn)方案,并在GPU和DSP上比較其性能和功效,結果顯示,HPEC在DSP上的實現(xiàn)效果更好。文獻[8]使用VSIPL++的并行API分析HPEC中存在的數(shù)據并行性,其在大多數(shù)情況下產生的加速比是線性或超線性的。文獻[18]使用HPEC評估OpenSPARC處理器在Virtex-5FPGA上的性能,發(fā)現(xiàn)復制浮點單元消耗小,可對浮點應用程序的性能產生顯著影響。然而目前,研究人員仍未對HPEC的子程序級線程推測方面進行深入分析。
2 推測執(zhí)行模型與剖析機制
2.1 推測執(zhí)行模型
圖1(a)和圖1(b)分別為傳統(tǒng)程序的串行執(zhí)行過程和基于線程級推測技術的子程序并行執(zhí)行過程。線程級推測技術在程序執(zhí)行到需要被推測執(zhí)行的子程序時,其推測處理器會創(chuàng)建新的線程執(zhí)行子程序代碼,主處理器對子程序返回值進行預測,并使用該預測值執(zhí)行后續(xù)代碼。當推測處理器中的子程序執(zhí)行完成后,會通知主處理器。主處理器將子程序預測值與推測線程中子程序的返回值進行比較,若結果相同,程序繼續(xù)運行,否則程序跳轉至子程序調用的返回點并重新運行。可以看出,在推測執(zhí)行期間只有一個非推測線程,并且僅允許非推測線程將結果提交到內存[19]。

圖1 子程序結構的推測執(zhí)行模型Fig.1 Speculative execution model of subroutine structure
2.2 剖析機制
程序剖析是一種根據程序運行時的信息,動態(tài)分析程序運行特征的方法,其主要目的是得到函數(shù)執(zhí)行次數(shù)、執(zhí)行時間以及代碼覆蓋率等性能數(shù)據[20]。本文設計了一種針對子程序的剖析工具Profun,該分析工具能夠提供程序在推測執(zhí)行時的可推測并行區(qū)域覆蓋率、線程粒度、線程間數(shù)據依賴等關鍵信息,從而指導程序員或編譯器對串行程序進行并行劃分。
子程序結構的剖析流程如圖2所示,其具體過程如下:

圖2 子程序結構剖析流程Fig.2 Analysis procedure of subroutine structure
1)使用GNU Prof工具對程序進行初步分析,得到該程序的函數(shù)間調用關系、每個函數(shù)運行時間的比例以及函數(shù)調用的層次關系等。
2)結合上述信息,選出占程序運行時間5%以上的熱點片段作為熱點剖析區(qū)域。
3)交叉編譯器對程序源代碼進行編譯,生成可執(zhí)行的二進制代碼文件。
4)剖析工具通過識別匯編文件中的jr、jal和jarl指令,結合候選熱點區(qū)域文件對熱點區(qū)域進行剖析,并根據關鍵因素(可推測并行區(qū)域覆蓋率、線程粒度、線程間數(shù)據依賴)的量化分析,得到剖析結果。
為獲取更多程序調用的行為信息,本文使用針對PISA指令集的反匯編工具objdump4pisa,將二進制代碼反匯編成匯編文件。程序源碼及其部分匯編代碼如圖3所示,可以看出,子程序返回地址被保存在31號寄存器中,全局變量sum被保存在28號寄存器中,在對sum進行運算前,將其加載到2號寄存器,運算結束后將結果保存到3號寄存器中。

圖3 子程序反匯編代碼示例Fig.3 Example of disassembly code of subroutine
圖4給出子程序剖析的核心數(shù)據結構。其中,call_list結構記錄待剖析子程序結構的每一次調用與返回時間,其每一項對應一個call_list_entry_t結構,且每個call_list_entry_t對應n個call_t結構,call_t用于記錄函數(shù)被調用的相關信息。Hash_list結構用于記錄對存儲器的寫操作,當程序存在大量子程序調用時,通過Hash_list中的call_list_head與call_list_tail遍歷查找,即可快速找到該子程序結構的某次特定調用。

圖4 子程序剖析的核心數(shù)據結構Fig.4 Core data structure of subroutine analysis
程序對所有全局數(shù)據段的數(shù)據讀寫操作保存在如圖5所示的last_write_hash_list結構中。在執(zhí)行到待剖析子程序時,該子程序在執(zhí)行讀操作時會被剖析工具攔截,通過對last_write_hash_list結構進行檢索,獲得其最后一次寫操作的時間。如果最后一次寫操作的時間大于當前時間,則將其替換為當前時間,并保存串行版本的運行時間,上述2個時間的比值即為最終加速比。
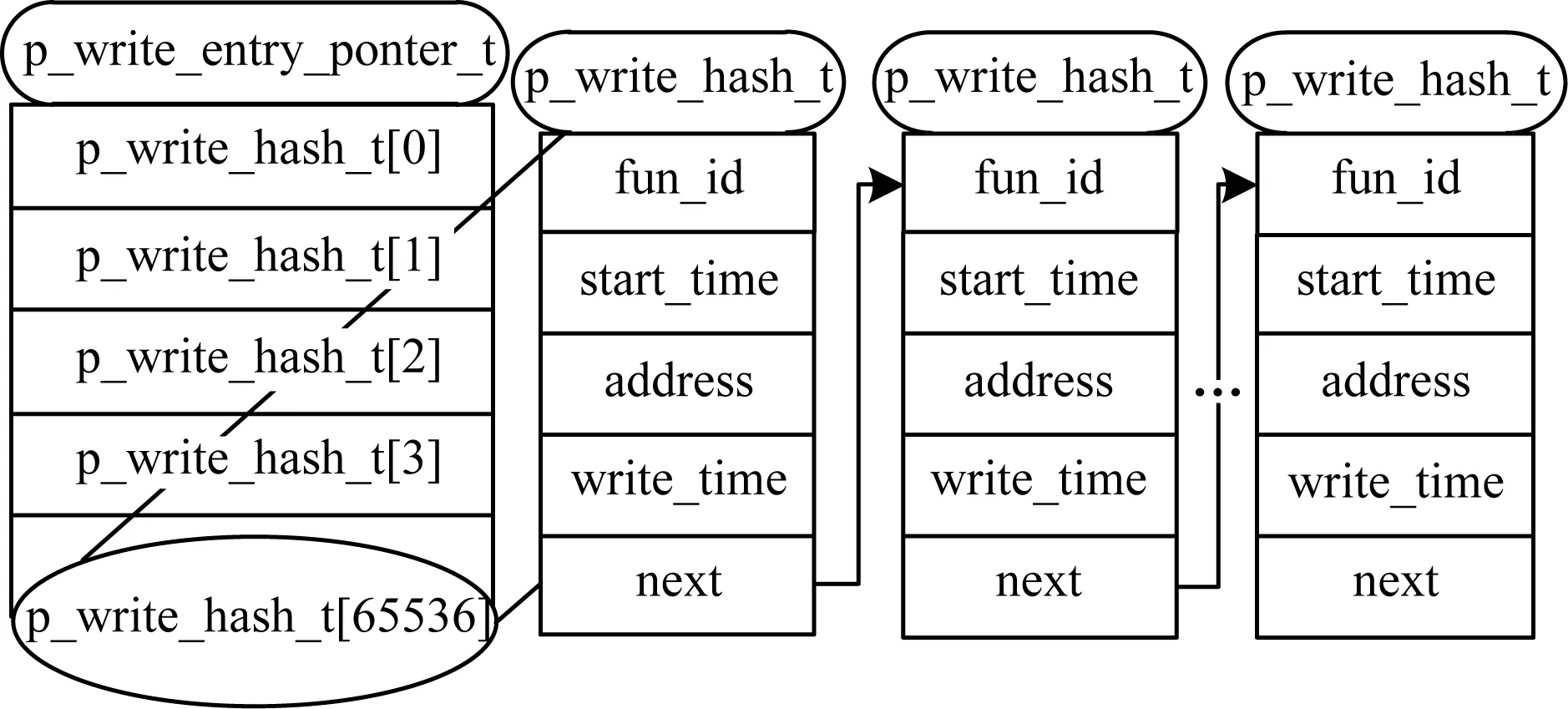
圖5 last_write_hash_list數(shù)據結構Fig.5 Data structure of last_write_hash_list
3 性能影響因素
影響子程序線程級推測的因素包括線程粒度、可推測并行區(qū)域覆蓋率、子程序調用次數(shù)以及線程間數(shù)據依賴。
線程粒度過小會導致推測執(zhí)行過程中產生的開銷增多,影響并行效果;線程粒度過大可能會出現(xiàn)錯誤沖突,從而導致不必要的推測線程壓縮。此外,線程粒度不一致可能會導致負載不平衡。在推測執(zhí)行過程中,子程序調用次數(shù)過少會影響程序性能提升潛力,進而影響程序加速效果。
數(shù)據依賴是影響程序推測并行化性能提升潛力的一個重要因素。本文將線程間的數(shù)據依賴關系簡化為數(shù)據生產者與數(shù)據消費者之間的關系,生產數(shù)據即對存儲器的寫操作,消費數(shù)據即對存儲器的讀操作。在剖析工作中,使用生產距離與消費距離的比值分析線程間的數(shù)據依賴關系。
將生產距離定義為最后一次寫操作到線程開始執(zhí)行之間的指令數(shù),消費距離定義為第一次讀操作到線程開始執(zhí)行之間的指令數(shù),如圖6所示。當消費距離小于生產距離時,數(shù)據依賴沖突發(fā)生的可能性極大。定義α=消費距離/生產距離,α值越小,數(shù)據依賴程度越嚴重。當0<α<0.4時,數(shù)據依賴程度為重度數(shù)據依賴;當0.4<α<1時,為輕度數(shù)據依賴;當α>1時,為安全數(shù)據依賴,不會發(fā)生數(shù)據依賴沖突;當α趨近于0時,推測線程間的執(zhí)行方式類似于程序的串行執(zhí)行方式。

圖6 生產距離與消費距離的定義Fig.6 Definition of production distance and consumption distance
綜上所述,線程粒度大小適中、可推測并行區(qū)域覆蓋率高、子程序調用次數(shù)多、線程間數(shù)據依賴程度較輕的程序能獲得較大的性能提升。
4 實驗結果與分析
4.1 實驗環(huán)境
本文實驗平臺為基于Linux的Ubuntu 14.04開發(fā)版本,指令集采用Simplescalar工具集的PISA指令集,編譯器采用Simplescalar工具集中提供的經過后端改造的gcc-2.7.2.3。為了使剖析時間能更好地適應編譯器整體開銷,剖析器采用基于Simplescalar工具集中功能模擬器sim-fast修改擴充的版本,該模擬器每個周期可執(zhí)行一條指令。本文選取HPEC中7個具有代表性的程序,所選程序及其介紹如表1所示。

表1 測試程序相關信息Table 1 Relevant information of testing program
4.2 結果分析
4.2.1 加速比
在最大程度地挖掘程序性能潛力后,程序加速比的結果如表2所示。可以看出,大部分程序的性能提升效果較好,程序加速比都在2以上。其中,tdfir程序的加速比達到221.78,而文獻[17]通過循環(huán)結構對tdfir程序進行加速,所得加速比為28.80,因此,tdfir程序非常適合采用子程序級線程推測技術開發(fā)并行性。此外,ct程序和pm程序的程序性能提升效果較差,加速比僅為1.00。

表2 程序最大加速比Table 2 Maximum acceleration ratio of programs
4.2.2 子程序調用次數(shù)
7個測試程序的子程序調用次數(shù)的對比結果如表3所示。由表3可知,子程序調用次數(shù)較少的程序為ct、pm以及svd程序中的mat_mult_cx_by_real程序,并且在所有測試程序中,以上3個程序的加速比相對較小。此外,ct程序和pm程序中只存在一個子程序,其調用次數(shù)為1,因此,子程序調用可能是造成ct和pm程序并行性差的主要原因。對于svd程序,其僅有一個子程序的調用次數(shù)較少,其他子程序的調用次數(shù)較多,因此,需綜合考慮性能影響因素對程序加速效果的影響。

表3 子程序調用次數(shù)對比Table 3 Comparison of number of subroutine calls
4.2.3 可推測并行區(qū)域覆蓋率
根據Amdahl定律,程序推測并行區(qū)域覆蓋率越高,可并行性越好。圖7給出7個程序的可推測并行區(qū)域覆蓋率對比。可以看出,所有的測試程序可并行化區(qū)域都在90%以上,其中,fdfir、tdfir、ct、pm程序的并行區(qū)域達到100%,因此,應著重考慮其他因素對程序并行性的影響。
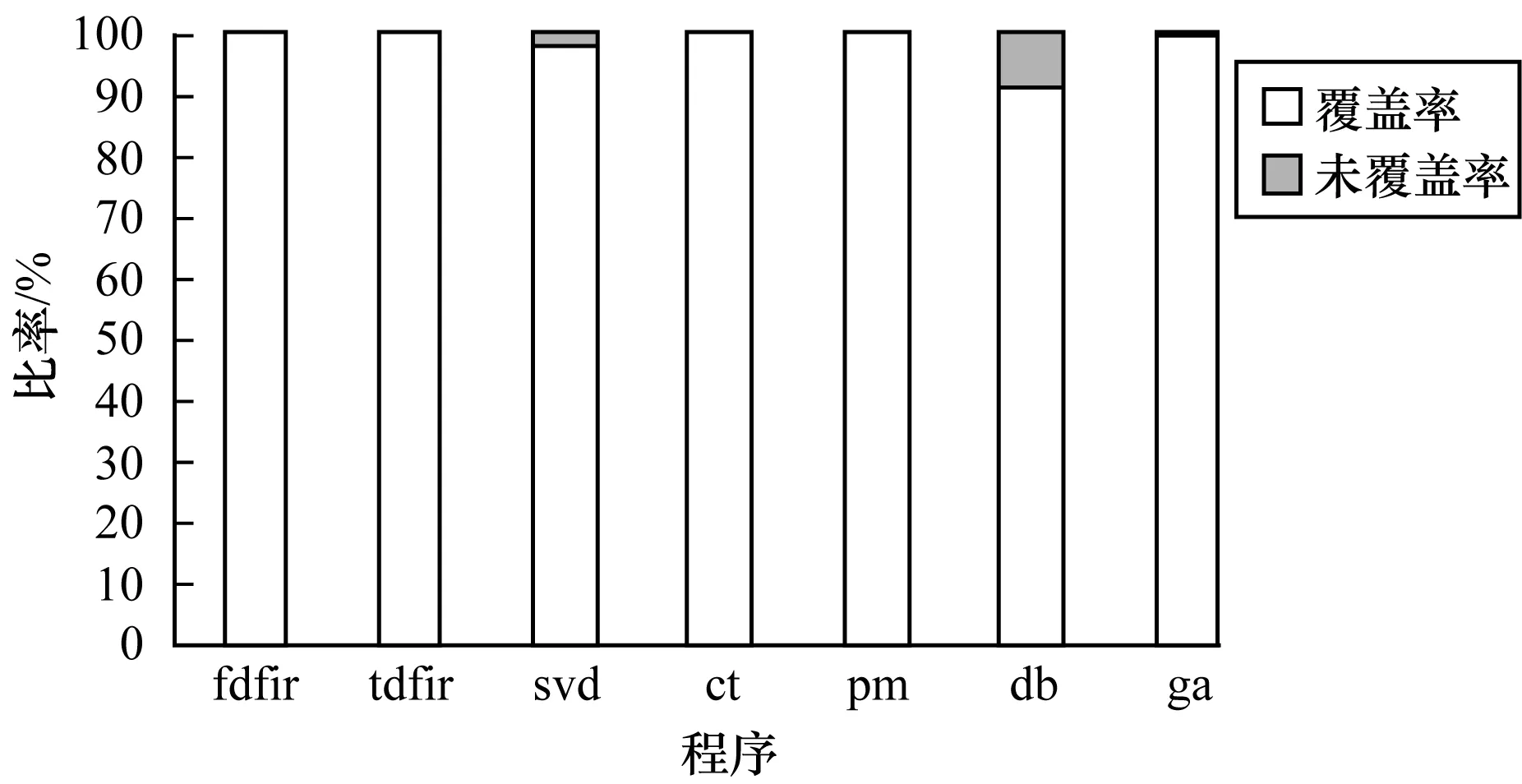
圖7 并行區(qū)域覆蓋率對比Fig.7 Comparison of coverage rate of parallel regions
4.2.4 線程粒度
所選測試程序的線程粒度如圖8所示。可以看出,多數(shù)子程序的線程粒度都在105~108,但Hydra項目組提出線程最適宜的粒度應為102~104,因此,可能會出現(xiàn)線程粒度太大而造成處理器緩存溢出的情況。ct、tdfir、pm程序中的線程粒度均勻,但其線程粒度過大仍是造成加速比不高的主要原因。svd、db和ga程序中存在線程粒度過大和不均勻的情況。綜合以上情況,線程粒度可能對大部分測試程序的加速效果產生影響。
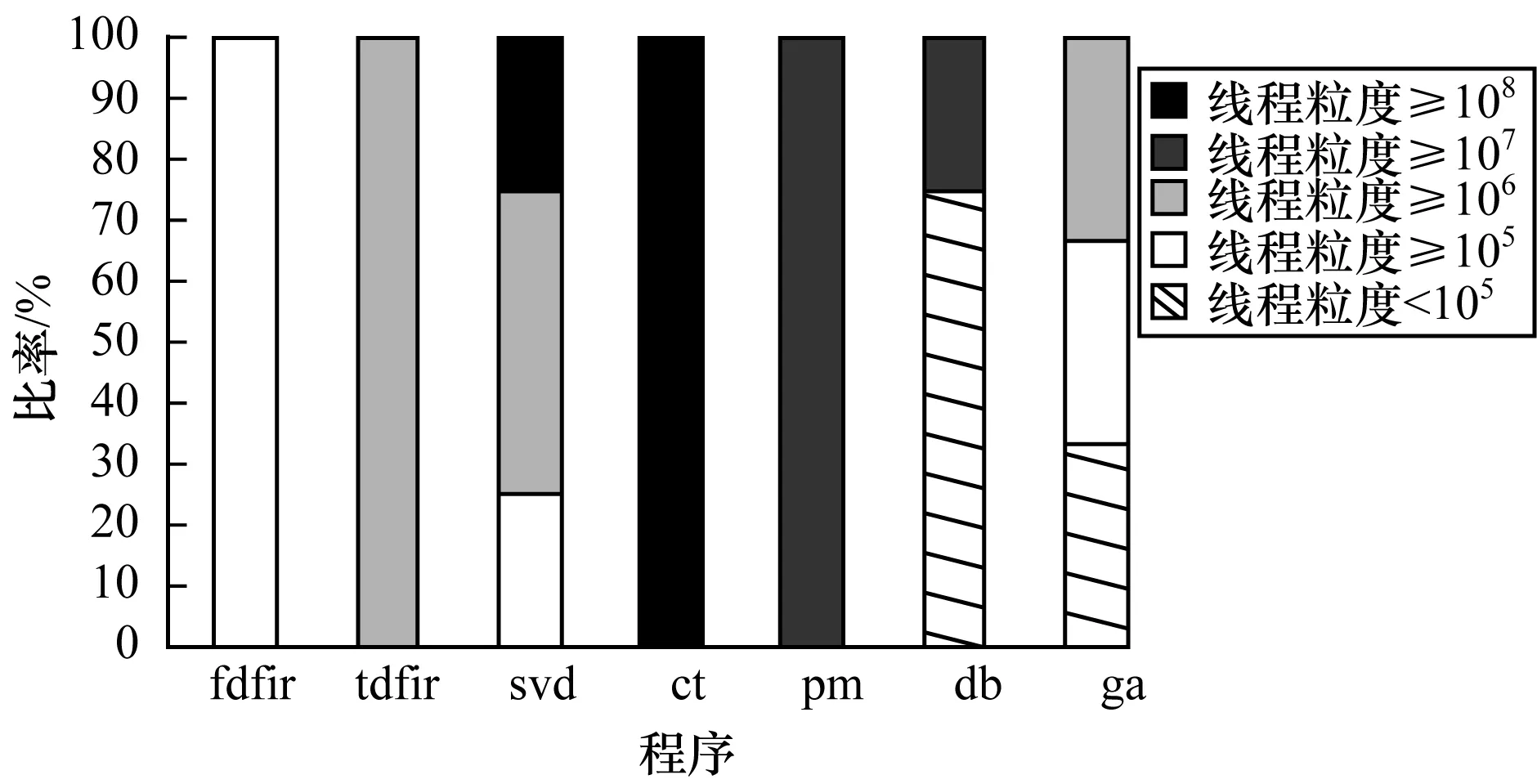
圖8 程序的線程粒度對比Fig.8 Comparison of program granularity
4.2.5 線程間數(shù)據依賴關系
本文第2節(jié)給出生產距離、消費距離和α的定義,并將數(shù)據的依賴程度分為重度依賴、輕度依賴和安全依賴。7個程序的線程間數(shù)據依賴對比如圖9所示。可以看出,ga、db、svd以及tdfir程序的線程間數(shù)據存在輕度和重度依賴,其中svd、db、ga程序中存在重度數(shù)據依賴,雖在程序中所占比例較小,但也可能會對程序加速效果造成影響。此外,大部分程序中的依賴關系屬于安全依賴,fdfir、ct和pm程序中安全依賴的比例達到100%,因此,可考慮其他因素對fdfir、ct和pm程序性能提升的影響。
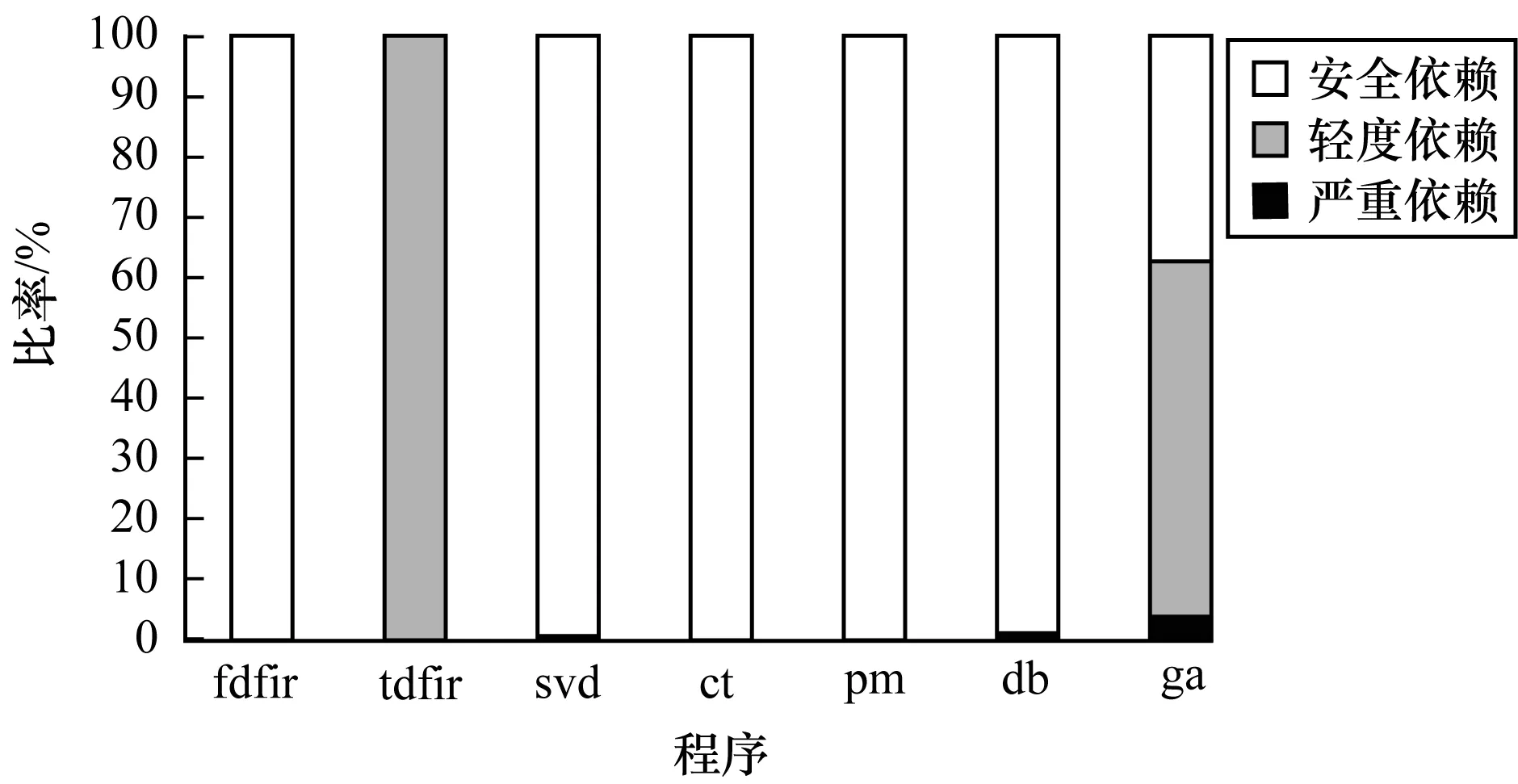
圖9 線程間數(shù)據依賴關系對比Fig.9 Comparison of data dependency results of threads
4.2.6 加速比綜合分析
本文結合上述性能影響因素以及源碼,分析7個測試程序加速比的原因,具體如下:
1)tdfir、fdfir程序同屬有限脈沖響應濾波器。tdfir程序的加速比最高,達到221.78,其主要原因是子程序在雙層嵌套循環(huán)中,使得該函數(shù)的調用次數(shù)較大,因此,即使tdfir存在輕度數(shù)據依賴,程序也能獲得較高加速比。fdfir程序的加速比為10.49,綜合各種性能影響因素后發(fā)現(xiàn),程序中僅存在安全數(shù)據依賴,子程序的線程粒度大小較為合適,并在程序運行時對子程序進行多次調用,因此,fdfir程序的加速效果較好。但tdfir子程序的調用次數(shù)遠高于fdfir,導致fdfir程序加速比低于tdfir程序。
2)db程序的加速比為11.31。綜合推測結果發(fā)現(xiàn),db程序存在重度數(shù)據依賴和線程粒度大小不均勻的問題,但重度數(shù)據依賴的比例小于1%。對源代碼進行分析發(fā)現(xiàn),存在重度數(shù)據依賴的子程序調用了存在安全數(shù)據依賴的子程序,被調用子程序的并行化區(qū)域比調用子程序大65%左右,并且被調用子程序的調用次數(shù)也遠高于調用子程序,因此,即使調用子程序存在重度數(shù)據依賴,其最終加速比依然較高。
3)ga程序的加速比為3.17,該程序中存在不同程度的數(shù)據依賴,并且線程粒度大小不均勻。分析程序源代碼后發(fā)現(xiàn),可推測并行區(qū)域覆蓋率最高的子程序中調用了其他2個子程序。第1個被調用子程序為一個返回值類型為float的隨機函數(shù),在程序推測執(zhí)行過程中,將返回值與預測值進行多次對比。第2個被調子程序中存在對指針變量的操作,因此,程序存在不同程度的數(shù)據依賴,但ga程序中子程序的調用次數(shù)較多,其性能提升潛力較大。
4)svd程序的加速比為2.23。綜合影響因素以及加速比可知,svd程序的線程粒度不均勻,且線程粒度較大,程序中還存在不同程度的數(shù)據依賴。由于安全依賴的占比遠遠大于重度依賴和輕度依賴的占比,因此線程粒度較大是影響svd程序加速效果的主要原因。但是,svd程序中其他子程序的調用次數(shù)較多,因此,程序最終獲得較好的加速效果。
5)ct、pm程序的加速比為1.00。綜合分析性能影響因素發(fā)現(xiàn),ct、pm程序中僅存在一個子程序且其調用次數(shù)都為1次。因此,即使ct和pm程序中僅存在安全數(shù)據依賴,程序的加速效果也不理想。
綜上所述,子程序中存在的重度或者輕度數(shù)據依賴會對程序性能提升產生影響,但子程序調用次數(shù)與線程間數(shù)據依賴情況成反比。因此,即使子程序存在少量重度或者輕度數(shù)據依賴,程序仍可在子程序調用次數(shù)較多的情況下獲得較高的加速比。
5 結束語
本文基于線程級推測技術對HPEC基準測試集中的7個程序進行分析。通過Profun分析工具獲取程序在執(zhí)行推測時的可推測并行區(qū)域覆蓋率、線程粒度、線程間數(shù)據依賴關系等關鍵信息,從而對串行程序進行熱點區(qū)域劃分。利用交叉編譯器編譯程序源代碼,并結合熱點區(qū)域文件實現(xiàn)量化分析。分析結果表明,7個程序中有5個程序能獲得較好的加速效果,其中,tdfir程序的加速比達到221.78,遠高于通過循環(huán)結構所得的加速比,其更適合采用子程序級的TLS技術挖掘潛在并行性。對于存在較多輕度和安全數(shù)據依賴的子程序調用,采用子程序級線程推測技術可獲得較好的加速效果。雖然HPEC中部分測試程序不宜采用子程序級TLS進行推測加速,但其代碼中存在大量可推測的循環(huán)迭代,下一步可通過循環(huán)級TLS技術挖掘其推測并行性,并與本文工作進行對比,以找到更適合此類程序的線程級推測方式。
猜你喜歡
電腦愛好者(2020年6期)2020-05-26 09:27:33
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環(huán)球時報(2017-03-30)2017-03-30 06:44:45
信息安全與通信保密(2016年3期)2016-08-23 01:23:56
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:34
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:25
中國衛(wèi)生(2015年3期)2015-11-19 02:53:32
政治與法律(2014年11期)2014-03-01 02:20:40
