一種融合社交關(guān)系的矩陣分解推薦模型
2020-08-19 07:25:52吳清春賈彩燕
計(jì)算機(jī)工程 2020年8期
吳清春,賈彩燕
(北京交通大學(xué) a.計(jì)算機(jī)與信息技術(shù)學(xué)院; b.交通數(shù)據(jù)分析與挖掘北京市重點(diǎn)實(shí)驗(yàn)室,北京 100044)
0 概述
隨著互聯(lián)網(wǎng)快速發(fā)展,人們獲取信息的方式越來(lái)越多,然而大量無(wú)關(guān)的信息會(huì)干擾用戶對(duì)所需信息的選擇。推薦系統(tǒng)作為用戶快速獲取信息的有效途徑,已被廣泛應(yīng)用于各個(gè)行業(yè),但用戶對(duì)項(xiàng)目評(píng)分?jǐn)?shù)據(jù)的稀疏性阻礙了推薦系統(tǒng)性能的提升,如在商業(yè)推薦系統(tǒng)中,可用商品評(píng)級(jí)的密度通常小于1%,這使得傳統(tǒng)推薦算法[1-3]無(wú)法達(dá)到理想的推薦水平。此外,傳統(tǒng)的推薦系統(tǒng)通常只考慮用戶對(duì)商品的評(píng)級(jí)信息,而忽略了用戶之間的社交關(guān)系或信任關(guān)系。
社交媒體的廣泛使用產(chǎn)生了大量的社交關(guān)系,并且在現(xiàn)實(shí)世界中人們總是易受他人的影響,傾向于與具有相似偏好的人相互交往,而這些相互交往的人由于彼此影響變得更加相似。因此,可以利用這些信息來(lái)提高商品評(píng)級(jí)預(yù)測(cè)的質(zhì)量。在此假設(shè)下,研究者提出多種基于社交網(wǎng)絡(luò)的推薦模型。實(shí)驗(yàn)表明,融合社交網(wǎng)絡(luò)信息的推薦模型能改善傳統(tǒng)模型的推薦性能,尤其當(dāng)用戶對(duì)項(xiàng)目的評(píng)級(jí)矩陣稀疏時(shí),推薦性能會(huì)有較為明顯的提升,但仍存在一些問(wèn)題,例如:現(xiàn)有數(shù)據(jù)集中社交網(wǎng)絡(luò)的數(shù)據(jù)形式大多為0-1數(shù)據(jù),并且僅包括用戶之間是否信任的信息,難以區(qū)分用戶之間的社交信任程度;部分模型對(duì)社交關(guān)系建模時(shí)僅考慮用戶之間的顯性社交關(guān)系,在商品評(píng)分?jǐn)?shù)目較少或社交關(guān)系信息較少的情況下,模型的推薦效果不佳;部分挖掘用戶隱性社交關(guān)系的方法如聚類、社區(qū)發(fā)現(xiàn)等方法,因類或社區(qū)大小的定義不同可能會(huì)引入額外的社交噪聲影響推薦效果。
本文對(duì)僅考慮直接交互關(guān)系的矩陣分解(Matrix Factorization,MF)推薦模型SoReg進(jìn)行改進(jìn),采用基于信號(hào)傳播的社區(qū)發(fā)現(xiàn)算法計(jì)算社交網(wǎng)絡(luò)中用戶之間的拓?fù)湎嗨贫?將其作為用戶的信任值并通過(guò)設(shè)置閾值構(gòu)建加權(quán)社交信任網(wǎng)絡(luò),進(jìn)而提出融合社交信任網(wǎng)絡(luò)的推薦模型SoRegIM。
1 相關(guān)工作
一些學(xué)者提出通過(guò)社會(huì)關(guān)系信息來(lái)改進(jìn)推薦方法,基于近鄰的社交推薦模型[4]、基于圖的推薦模型[5-6]、基于物質(zhì)擴(kuò)散的推薦模型[7]、基于矩陣分解的推薦模型[8-9]和其他的一些社交推薦模型[10-12]相繼被提出。
基于矩陣分解的推薦模型算法具有靈活性高、推薦性能好等特點(diǎn),是當(dāng)前推薦系統(tǒng)中的主流方法。本文以融合社交關(guān)系的矩陣分解型推薦模型為基礎(chǔ),研究基于社會(huì)關(guān)系的推薦方法,包括通過(guò)社交網(wǎng)絡(luò)中直接相連的用戶信息來(lái)優(yōu)化推薦性能的算法,以及通過(guò)社交網(wǎng)絡(luò)中的用戶關(guān)系進(jìn)行聚類并融合商品評(píng)分信息來(lái)提升推薦性能的方法。SoRec[13]對(duì)評(píng)級(jí)矩陣和社交關(guān)系矩陣執(zhí)行同因子分解,同時(shí)學(xué)習(xí)用戶特征、社交特征以及項(xiàng)目特征。文獻(xiàn)[14]提出的社會(huì)模型TrustMF,同時(shí)考慮了用戶對(duì)其他用戶的信任以及被其他用戶的信任信息,使用戶從信任和被信任兩個(gè)方面進(jìn)行建模,學(xué)習(xí)兩個(gè)不同的特征向量。文獻(xiàn)[15]通過(guò)使用捕捉當(dāng)?shù)睾腿蛏鐣?huì)關(guān)系的方法,提出一個(gè)新的框架LOCABAL,利用當(dāng)?shù)睾腿蛏鐣?huì)上下文進(jìn)行推薦,在當(dāng)?shù)厣缃恍畔⒅屑僭O(shè)具有朋友關(guān)系的用戶之間品味相似,而在全球社交信息中使擁有較高聲譽(yù)的用戶權(quán)值更大,從而發(fā)揮更大的作用。文獻(xiàn)[16]提出的推薦模型FangPMF,將社交信任信息分解成4個(gè)維度進(jìn)行衡量,從不同的角度充分考慮社會(huì)信息,并使用支持向量回歸對(duì)多個(gè)信任維度進(jìn)行整合,將其與原始概率分解的模型相結(jié)合。文獻(xiàn)[17]同時(shí)使用社交網(wǎng)絡(luò)信息和評(píng)分信息學(xué)習(xí)用戶信任和被信任矩陣,將其用于最終的評(píng)分預(yù)測(cè)模型中。
上述將社交信息融合到推薦模型中的方法已被證明能夠有效提升傳統(tǒng)推薦方法的推薦性能,然而這些方法僅關(guān)注顯性的社交關(guān)系,當(dāng)用戶評(píng)分信息和社交中直接相連用戶都比較少時(shí)推薦性能提升有限。也有學(xué)者采用社區(qū)發(fā)現(xiàn)或聚類算法挖掘隱性的社交關(guān)系。文獻(xiàn)[18]使用社區(qū)發(fā)現(xiàn)算法挖掘社交網(wǎng)絡(luò)中不同的社會(huì)關(guān)系,提出一種重疊社區(qū)正則化的模型MFC,假設(shè)同一社區(qū)中的用戶偏好相似。文獻(xiàn)[19]提出了基于社交維度的推薦模型SoDimRec,但同一社交維度中包含不具有社交關(guān)系但興趣可能相似的用戶。文獻(xiàn)[20]通過(guò)建立社區(qū)信任模型獲取用戶綜合信任度,并利用重疊社區(qū)發(fā)現(xiàn)算法為用戶劃分專屬虛擬社區(qū)進(jìn)行信任傳播,將其用于協(xié)同過(guò)濾算法得到推薦結(jié)果,但這種基于聚類的社交興趣推理方法可能會(huì)產(chǎn)生社交噪聲,并且難以區(qū)分同一社區(qū)內(nèi)不同用戶之間的信任強(qiáng)度,可能會(huì)給推薦系統(tǒng)帶來(lái)不良的影響。因此,有必要根據(jù)社交網(wǎng)絡(luò)的拓?fù)湫畔⒂?jì)算用戶之間的鏈接強(qiáng)度,建立社交信任網(wǎng)絡(luò)進(jìn)而獲得合適的社會(huì)推薦模型。
2 基于矩陣分解的推薦模型框架

(1)

3 基于社交網(wǎng)絡(luò)拓?fù)潢P(guān)系的推薦模型
3.1 社交信任關(guān)系網(wǎng)絡(luò)構(gòu)建
在現(xiàn)有的社交網(wǎng)絡(luò)數(shù)據(jù)集中,數(shù)據(jù)形式多為二值型數(shù)據(jù),常見(jiàn)的社交網(wǎng)絡(luò)二值型描述方法不能充分描述用戶之間的信任程度,這也導(dǎo)致大部分使用社交信息的推薦算法在推薦準(zhǔn)確性上提升有限。社交網(wǎng)絡(luò)中的節(jié)點(diǎn)表示用戶信息,網(wǎng)絡(luò)的拓?fù)浣Y(jié)構(gòu)能體現(xiàn)出節(jié)點(diǎn)之間的緊密程度,因此,社交網(wǎng)絡(luò)中節(jié)點(diǎn)間的拓?fù)潢P(guān)系能夠間接反映兩個(gè)用戶之間的相關(guān)程度,將通過(guò)拓?fù)潢P(guān)系計(jì)算的節(jié)點(diǎn)間的相關(guān)程度稱為用戶拓?fù)湎嗨贫取1疚耐ㄟ^(guò)挖掘社交網(wǎng)絡(luò)中用戶的拓?fù)潢P(guān)系,計(jì)算用戶之間的拓?fù)湎嗨贫?用于近似刻畫(huà)用戶之間的信任程度;另一方面,在社交網(wǎng)絡(luò)中許多用戶的直接鄰居較少,因此,有必要考慮間接鄰居的信任度對(duì)用戶評(píng)級(jí)產(chǎn)生的影響。在對(duì)社交網(wǎng)絡(luò)中直接相連的用戶計(jì)算相似度時(shí),將用戶拓?fù)湎嗨贫瘸^(guò)一定閾值的間接用戶連接起來(lái),形成新的社交信任網(wǎng)絡(luò)。
本文使用signal相似度[21]來(lái)計(jì)算社交網(wǎng)絡(luò)中用戶間的拓?fù)湎嗨贫取<僭O(shè)用戶之間的信息通過(guò)τ步傳播后,該用戶對(duì)網(wǎng)絡(luò)中的其他用戶擁有一個(gè)影響度,用戶信息傳遞方式如下:
S=(A+I)τ
(2)
其中,I是n維單位矩陣,A是網(wǎng)絡(luò)的鄰接矩陣,τ是信息傳遞的次數(shù)。在進(jìn)行標(biāo)準(zhǔn)化處理后,得到用戶間的拓?fù)湎嗨贫葹?
(3)
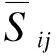

圖1 用戶間社交關(guān)系表示Fig.1 Representation of social relationship among users
3.2 SoReg模型
SoReg是文獻(xiàn)[22]提出的一種基于社會(huì)正則化的社交推薦模型,該文獻(xiàn)認(rèn)為用戶的偏好與其直接相連的鄰居一致。SoReg模型的目標(biāo)函數(shù)如下:

(4)

(5)
3.3 SoRegIM模型
經(jīng)典社交推薦模型SoReg[22]只對(duì)社交網(wǎng)絡(luò)中直接相連的用戶施加相似度約束來(lái)改進(jìn)評(píng)級(jí)預(yù)測(cè),社交信息利用率有限。而在現(xiàn)實(shí)世界中,用戶不僅僅受到與他直接相連的用戶的影響,社交網(wǎng)絡(luò)中拓?fù)湎嗨贫容^大的用戶之間的興趣應(yīng)該更接近。因此,本文利用社交網(wǎng)絡(luò)中用戶之間的拓?fù)潢P(guān)系,考慮直接鄰居、間接鄰居及其鏈接強(qiáng)度構(gòu)建信任網(wǎng)絡(luò)(如圖1(b)所示)。此外,在計(jì)算用戶之間相似度時(shí)不僅使用用戶評(píng)級(jí)信息,而且還使用用戶之間的社會(huì)信任強(qiáng)度,進(jìn)而構(gòu)建一個(gè)新的推薦模型SoRegIM,其最小化的目標(biāo)函數(shù)為:
(6)
上式最后一項(xiàng)中Z的定義如式(7)所示,用于保證用戶之間的特征盡可能接近,使得社會(huì)信任強(qiáng)度高且評(píng)分相似度大的用戶之間的用戶特征向量相似度盡可能高。
(7)
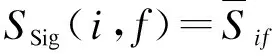
(8)

通過(guò)對(duì)Ui和Vj求偏導(dǎo),利用梯度下降法可以計(jì)算出目標(biāo)函數(shù)(式(6))的極小值,其中,Ui和Vj求解如下:
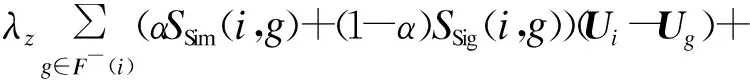
(9)
4 實(shí)驗(yàn)與分析
本節(jié)在3個(gè)公開(kāi)的數(shù)據(jù)集FilmTrust、Ciao和Epinions上通過(guò)實(shí)驗(yàn)驗(yàn)證SoRegIM模型的性能,并利用均方根誤差(Root Mean Square Error,RMSE)和平均絕對(duì)誤差(Mean Absolute Error,MAE)兩個(gè)評(píng)價(jià)指標(biāo)進(jìn)行評(píng)價(jià)。
4.1 數(shù)據(jù)集
本文實(shí)驗(yàn)使用的數(shù)據(jù)集信息如表1所示,這3個(gè)數(shù)據(jù)集中的數(shù)據(jù)都包含用戶評(píng)級(jí)和用戶社交關(guān)系信息。FilmTrust是一個(gè)電影推薦網(wǎng)站,用戶可以按照自己的喜好對(duì)電影進(jìn)行打分,也可以對(duì)其他用戶添加信任關(guān)系。Ciao是一個(gè)物品評(píng)論網(wǎng)站,用戶可以對(duì)不同物品進(jìn)行打分和和添加評(píng)價(jià),同時(shí)可以和其他用戶建立有向社交關(guān)系。Epinions是一個(gè)著名的消費(fèi)者評(píng)論網(wǎng)站,其提供了各種商品的比較信息,用戶可以對(duì)商品進(jìn)行打分和評(píng)論,同時(shí)每個(gè)用戶都有一個(gè)信任列表,可以添加對(duì)其他用戶的信任。

表1 實(shí)驗(yàn)數(shù)據(jù)集信息Table 1 Information of experimental data set
4.2 評(píng)價(jià)指標(biāo)
使用平均絕對(duì)誤差(MAE)和均方根誤差(RMSE)進(jìn)行評(píng)價(jià),計(jì)算公式如下:
(10)
(11)

4.3 對(duì)比模型與實(shí)驗(yàn)參數(shù)
為評(píng)估本文模型的有效性,選取推薦系統(tǒng)領(lǐng)域中7個(gè)經(jīng)典的矩陣分解相關(guān)模型進(jìn)行對(duì)比,具體如下:
1)PMF[2]:僅使用用戶評(píng)分信息,是一種概率矩陣分解的模型。
2)SoRec[13]:使用用戶評(píng)分信息和社交網(wǎng)絡(luò)中直接鄰居信息,是一種對(duì)評(píng)級(jí)矩陣和社交關(guān)系矩陣執(zhí)行同因子分解的模型。
3)SoReg[22]:使用用戶評(píng)分信息和社交網(wǎng)絡(luò)中直接鄰居信息,是一種通過(guò)定義社會(huì)正則化來(lái)捕捉用戶間強(qiáng)依賴連接的模型。
4)LOCABAL[15]:使用用戶評(píng)分信息和社交網(wǎng)絡(luò)中直接鄰居信息,是一種同時(shí)考慮用戶信任與專家信息的推薦模型。
5)SocialMF[23]:使用用戶評(píng)分信息和社交網(wǎng)絡(luò)中直接鄰居信息,是一種將信任傳播機(jī)制應(yīng)用到概率矩陣分解中的模型。
6)MFC[18]:使用用戶評(píng)分信息和社交信息,是一種將社交正則化應(yīng)用在不同重疊社區(qū)上,利用已有重疊社區(qū)發(fā)現(xiàn)算法從社交網(wǎng)絡(luò)中挖掘社團(tuán)的模型。
7)SoDimRec[15]:使用用戶評(píng)分信息和社交信息,是一種考慮不同社交維度中用戶弱依賴鏈接,采用傳統(tǒng)社區(qū)發(fā)現(xiàn)算法識(shí)別用戶社交維度的模型。
對(duì)各模型的參數(shù)進(jìn)行如下設(shè)置:將所有模型的隱空間特征個(gè)數(shù)設(shè)置為10,λu和λv設(shè)置為0.001;在SoRec模型中設(shè)置λc=1,λz=0.001;在SoReg模型中設(shè)置β=0.001;在LOCABAL模型中設(shè)置α=0.5;在SocialMF模型中設(shè)置λT=1;在MFC模型中設(shè)置λz=0.001;在SoDimRec模型中設(shè)置λ1=10,λ2=100;在本文SoRegIM模型中設(shè)置α=0.8,β=0.02,λz=0.001。
4.4 實(shí)驗(yàn)結(jié)果
本文選擇80%的數(shù)據(jù)作為訓(xùn)練數(shù)據(jù),以預(yù)測(cè)其余20%的評(píng)分,實(shí)驗(yàn)結(jié)果是五重交叉驗(yàn)證的平均值,如表2所示,其中加粗?jǐn)?shù)據(jù)為最優(yōu)數(shù)據(jù)。可以看出,PMF的準(zhǔn)確度不如其他模型,這進(jìn)一步表明利用社交信息可以提升推薦的準(zhǔn)確性。SoRec、SoReg、LOCABAL和SocialMF使用了社交網(wǎng)絡(luò)中直接鄰居信息,MFC和SoDimRec通過(guò)聚類的方法考慮到間接鄰居,雖然與只使用直接鄰居信息的模型相比性能有所提升,但由于聚類個(gè)數(shù)難以確定,容易出現(xiàn)興趣不太相似的用戶在同一類中的情況,從而產(chǎn)生社交噪聲。本文構(gòu)建了社交信任關(guān)系網(wǎng)絡(luò),并定義了信任強(qiáng)度,避免了多余的社交噪聲。由表2結(jié)果可知,與7種經(jīng)典模型相比,本文模型的性能有所提升,特別在稀疏數(shù)據(jù)集FilmTrust和Epinions上提升明顯。

表2 本文模型與7種經(jīng)典模型的MAE和RMSE指標(biāo)對(duì)比Table 2 Comparison of MAE and RMSE indexes of the proposed model and seven classical models
4.5 參數(shù)影響
在本文模型中,參數(shù)β、α和λz會(huì)對(duì)推薦效果產(chǎn)生不同程度的影響。其中:β是通過(guò)signal相似度計(jì)算出的用戶拓?fù)湎嗨贫榷x的閾值,用于控制重構(gòu)社交信任網(wǎng)絡(luò)的稀疏程度;α用于控制評(píng)分相似度和社交關(guān)系信任度在整體用戶相似度中所占的比例;λz用于控制社交信息對(duì)模型的貢獻(xiàn)程度。本文通過(guò)實(shí)驗(yàn)分析在Epinions數(shù)據(jù)集中這些參數(shù)對(duì)SoRegIM模型推薦性能的影響。圖2~圖4分別顯示了β、α和λz不同設(shè)置下本文模型的MAE和RMSE指標(biāo)。由圖2可以看出,β=0.02時(shí)推薦性能最好,當(dāng)閾值β設(shè)置過(guò)低時(shí),額外引入的用戶信息過(guò)多可能造成社交噪聲,當(dāng)閾值β設(shè)置過(guò)高時(shí),則會(huì)忽略掉部分重要的社交信息。在圖3中,α=0表示用戶相似度僅考慮社交信息,α=1表示僅考慮評(píng)級(jí)信息。由圖3可以看出,在計(jì)算用戶之間相似度時(shí)同時(shí)考慮評(píng)級(jí)信息與社交信息推薦性能最好。由圖4可以看出,λz的變化對(duì)推薦結(jié)果有一定的影響,λz=0.01時(shí)推薦性能最好,隨著λz的增大,信任的用戶可能產(chǎn)生過(guò)度影響,而當(dāng)λz較小時(shí),信任用戶產(chǎn)生的影響太小會(huì)導(dǎo)致推薦效果相對(duì)傳統(tǒng)方法提升有限。
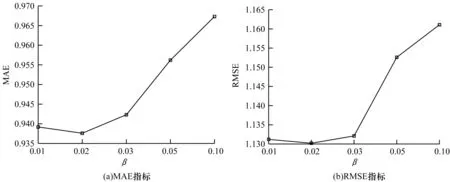
圖2 參數(shù)β對(duì)推薦性能的影響Fig.2 Impact of parameter β on recommendation performance
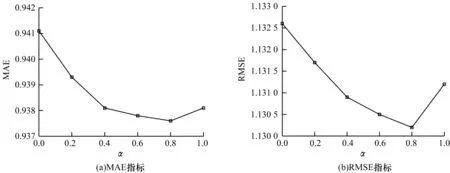
圖3 參數(shù)α對(duì)推薦性能的影響Fig.3 Impact of parameter α on recommendation performance

圖4 參數(shù)λz對(duì)推薦性能的影響Fig.4 Impact of parameter λz on recommendation performance
5 結(jié)束語(yǔ)
在網(wǎng)絡(luò)信息量爆炸式增長(zhǎng)的背景下,本文構(gòu)建一種融合社交網(wǎng)絡(luò)用戶拓?fù)潢P(guān)系的矩陣分解型推薦模型。該模型考慮用戶的直接和間接鄰居并挖掘其鏈接強(qiáng)度,在計(jì)算相似度時(shí)不僅利用用戶在項(xiàng)目上的歷史評(píng)分,同時(shí)還同時(shí)考慮用戶之間的社會(huì)關(guān)系。實(shí)驗(yàn)結(jié)果表明,通過(guò)融合社交信息可大幅提高模型的推薦性能。但本文模型僅考慮用戶之間的關(guān)系,下一步將考慮項(xiàng)目之間和偏好相異用戶之間的關(guān)系,探索其對(duì)用戶評(píng)級(jí)行為的影響。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
中外會(huì)展(2014年4期)2014-11-27 07:46:46
