面向區塊鏈交易可視分析的地址增量聚類方法
2020-08-19 07:00:54王勁松呂志梅趙澤寧張洪瑋
計算機工程 2020年8期
王勁松,呂志梅,趙澤寧,張洪瑋
(天津理工大學 a.計算機科學與工程學院; b.天津市智能計算及軟件新技術重點實驗室;c.計算機病毒防治技術國家工程實驗室,天津 300457)
0 概述
比特幣自2009年問世以來,就因具有分布式、匿名性、可溯源等與傳統貨幣不同的特征而發展迅速,此后各種類似的加密貨幣也隨之出現。根據CoinMarketCap的統計數據,到2019年4月加密貨幣種類已經超過2 100種。比特幣本質是一種基于區塊鏈的分布式賬本,系統中所有用戶通過基于公鑰的錢包地址進行點對點的直接交易,無需通過任何中心化金融機構,所有交易記錄都不可篡改地永久記錄在區塊鏈上[1-2],交易只與雙方的錢包地址有關,與錢包所有人的真實身份沒有直接聯系,以此來保護用戶隱私。比特幣在保護用戶隱私的同時也常被用于異常交易活動,并且給追蹤這些交易團體增大了難度。通過分析交易數據,可以發現交易特征并識別實體[3-4],同時推測實體類型并發現實體之間的聯系,進而對交易數據進行可視分析,幫助研究人員更好地感知區塊鏈交易信息,分析交易中的安全事件。
文獻[5-9]針對比特幣地址聚類和實體識別進行研究。文獻[5]利用Petri網對比特幣網絡進行建模,把所有交易地址和交易映射為矩陣的行和列,通過分析矩陣來解決比特幣實體識別的問題,但是如果交易數量過多,會造成矩陣維數過大,這是此方法的不足。文獻[6]提出一個模塊化的框架BitIodine,通過解析區塊鏈和可能屬于同一個實體的地址,對這些實體分類并貼上標簽。文獻[7]對用戶的交易規律進行抽象,提出一種基于參數的身份識別方法,能夠有效識別匿名區塊鏈地址對應的真實用戶身份。文獻[8]通過分析比特幣交易數據,基于實體識別對勒索軟件CryptoLocker的攻擊行為進行分析。文獻[9]通過設計模擬實驗,采用基于行為的聚類技術對比特幣交易數據進行分析,能夠匹配40%的用戶身份和地址。
上述研究都認為如果比特幣一條交易中包括多個輸入地址,那么這些地址都屬于同一實體,把這一條件作為啟發式聚類條件,在實體識別和進一步數據分析方面能夠取得很好的效果。文獻[10]分析得到這種啟發式聚類方法有效的主要原因,即地址重用、可避免的合并、具有高中心性的超級集群以及地址集群的增量增長。文獻[11]提出將多輸入地址和找零地址結合作為啟發式條件進行聚類的方法,并通過大量實驗驗證方法的準確性和全面性,同時分析實驗迭代次數對聚類效率的影響。文獻[12]對20個月中生成的交易進行分析,將35 770 360個地址聚類為13 062 822個集合,但未對聚類后的實體及其之間的聯系進一步分析。文獻[13]提出一個基于圖的數據挖掘工具對比特幣交易數據進行可視分析,實現了對任意給定的一個或一組地址的局部聚類,適用于對已知事件中的地址進行詳細行為和關聯分析,但聚類結果沒有與實體類型聯系。
上述方法都是基于某一時段的比特幣交易數據進行聚類,沒有對實體的演變情況進行分析。為此,本文提出一種基于比特幣交易數據特征的地址增量聚類方法。采集比特幣的區塊流數據對原始流數據進行解析和結構化處理,提取符合聚類條件的交易和地址形成聚類地址組,并通過散列函數生成聚類地址組的數據索引,獲得聚類地址組之間的聚合關系。在此基礎上,利用并查集算法實現對此關系的增量聚類以發現交易實體,進而對交易數據進行重標記和再分析,得到比特幣實體間的的交易特征。此外,本文通過對聚類過程中各階段實體的特點及實體間交易聯系進行可視分析,得到地址增量聚類過程中實體的變化特征。
1 增量聚類方法
基于比特幣交易數據的地址增量聚類方法主要包括數據采集及數據預處理、聚合關系集合獲取、數據增量聚類和存儲聚類4個部分。
1.1 數據采集及預處理
本文通過配置區塊鏈環境和搭建比特幣客戶端Bitcoin Core,將區塊流數據同步到本地,Dt表示截止至t時刻的所有區塊數據。
當生成新區塊后,將新的區塊數據同步到本地,Dt′-t表示t到t′時刻之間產生的區塊數據。同步到本地的區塊數據Dt是二進制流數據,圖1所示為創世區塊的十六進制格式的數據。為進一步實驗,通過分析區塊的數據結構[14-15],對原始流數據Dt解析和結構化處理[16],得到比特幣交易數據集St,St=Json(Dt),該數據集為t時刻之前的區塊數據經過處理后得到的結構化數據。圖2所示為創世區塊經過處理后的交易數據。

圖1 創世區塊原始數據Fig.1 Original data of genesis block

圖2 創世區塊結構化數據Fig.2 Structured data of genesis block
基于比特幣交易數據集提取用于增量聚類的可聚類交易T。T必須滿足以下條件:交易T不是挖礦交易;交易T包含兩個以上不同的輸入地址。可聚類交易中的地址即為聚類地址組,用ci標識,i為一個自增的整數,Ct為t時刻之前生成的ci。
圖3所示為兩例可聚類交易模型(地址的顏色不同表示地址所屬實體不同),其中,聚類地址組表示為c0={a1,a2},c1={a1,a6,a8}。

圖3 可聚類交易模型Fig.3 Clustered transaction models
1.2 聚合關系集合獲取
基于聚類地址組Ct通過散列函數生成哈希表Ht,其中,k為地址,v為地址所屬組。當讀取到已存在于Ht的地址但地址所屬組與Ht中對應的值不一致時,說明這兩個地址組間存在聚合關系,其中地址屬于同一實體,聚合關系用(rc0,rc1)表示,將t時刻之前的所有聚合關系放入集合Rt中:
Ht,c={vt,c|c∈Ct,c=kt}
Rt={(rc0,rc1)|c0,c1∈Ct,Ht,c0≠Ht,c1}
其中,(rc0,rc1)表示關系對中的聚類地址組。關系集合生成算法描述如下:
算法1聚合關系集合生成算法
輸入t時刻之前所有聚類地址組Ct
輸出哈希表Ht,聚合關系集合Rt
for ciin Ctdo
for a in cido
if a as in Ht.k and Ht[a].v≠cithen
(rc0,rc1)←(Ht[a].v,ci)
將聚合關系(rc0,rc1)添加到Rt中
else
Ht[a].v=ci
end
end
例如圖3交易中的聚類地址組有c0、c1,地址a1在c0中也在c1中,經過算法1處理后,Ht中{a1:c0}更新為{a1:c1},同時生成一個聚合關系r:(c0,c1),存儲最終生成的聚合關系集合,同時輸入并查集算法進行聚類。
1.3 增量聚類
由于區塊鏈數據是增量的,傳統聚類方法需要獲取創世區塊到當前區塊的所有關系集合進行聚類,會導致效率下降,因此本文基于聚類地址組間聚合關系通過并查集算法實現實體增量聚類。并查集是一種樹型的數據結構,常用于判斷兩個子集是否屬于同一集合以及按照一定順序將屬于同一集合的子集合并,時間復雜度是線性的,適用于解決數據量大的應用問題,基本操作包括初始化、查找、合并。
初始化集合G,集合中的元素為聚類地址組的標識名稱ci。由于比特幣交易數據量較大,因此采用路徑壓縮方法優化查詢操作,查詢函數Find(x)如下:
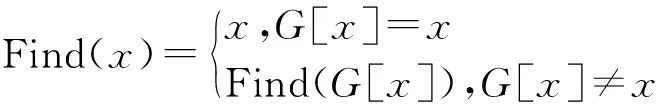
其中,x為G中的元素。執行查找函數后的兩個元素若屬于不同集合則將其合并,合并函數Union(x,y)如下:
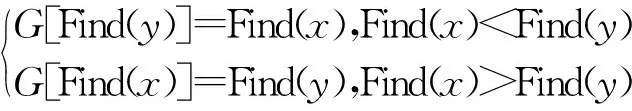
初始集合和結果集合同一位置的元素屬于同一集合,元素相同的個數代表聚類后實體的數量,因此,通過并查集算法可以對比特幣交易數據中的所有聚類地址組進行聚類。基于聚合關系的并查集算法描述如下:
算法2基于聚合關系的并查集算法
輸入關系集合Rt
輸出并查集G
初始化數組G
if Rt≠? then
for (rc0,rc1) in Rtdo
Find(ci),Find(cj)
if Find(ci)≠Find(cj) then
Union(ci,cj)
end
//合并整理
for k←0 to G.length do
if G[k]≠k then
Find(k)
end
如圖4所示,一個節點代表一個聚類地址組,同一聚合關系中的兩個組用實線連接,用虛線連接關系之間存在關聯的節點。圖4(a)中虛線圈出的為存在聚合關系的所有節點,合并之后節點分布如圖4(b)所示。
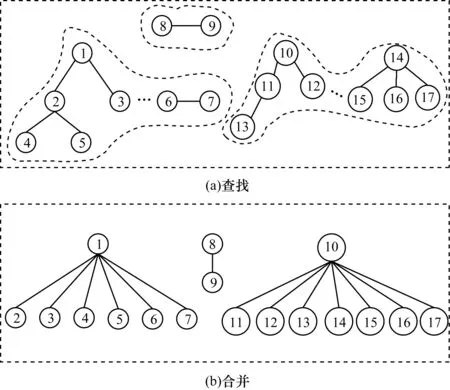
圖4 基于聚合關系的并查集算法模型Fig.4 Model of union-find set algorithm based on aggregation relationship
聚合聚類算法完成后,存儲中間結果G,并檢查是否有新的區塊數據生成,若有生成新區塊,則對新區塊數據進行結構化處理,提取區塊中的所有聚類地址組Ct′-t,執行算法1生成新的關系集合Rt′-t。基于中間結果G集合對Rt′-t進行算法2中操作即可生成新的聚類結果Ft′,Ft′為基于t′時刻前數據生成的聚類結果。
重復使用上述方法對新數據進行處理以實現增量聚類的效果。基于并查集方法實現增量聚類的時間復雜度低,并且在更新G集合的過程不需要額外的空間,適用于比特幣這種數據量大的問題。數據采集及數據預處理、聚合關系集合獲取、數據增量聚類和存儲聚類4個模塊之間的數據交互過程如圖5所示。

圖5 基于比特幣交易信息的地址增量聚類方法時序圖Fig.5 Sequence diagram of address increment clustering method based on Bitcoin transaction information
2 實驗與結果分析
2.1 數據集
本文采集比特幣網絡前278 878個區塊數據作為實驗的數據源,數據覆蓋時間為2009年至2013年,數據的具體參數如表1所示。

表1 實驗參數Table 1 Experimental parameters
2.2 聚類結果分析
2009年2月3日前交易的輸入地址都是單個或重復,實驗處理了2 817個區塊后首次出現符合條件的可聚類交易。圖6所示為交易實體、地址、關系對數量隨時間的變化。可以看出,2009年至2012年地址增長速率相對緩慢,2012年后地址增長率顯著提高,并且2013年關系對增長量較之前明顯降低。出現此現象原因可能為:在線交易服務的出現,使用比特幣的用戶迅速增長,用戶逐漸意識到可聚類交易對隱私的影響。
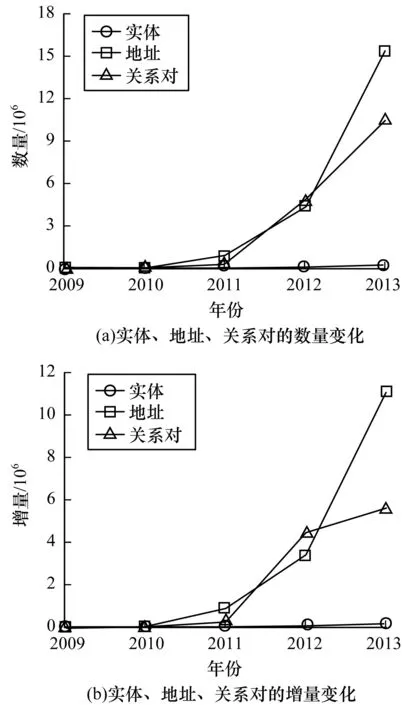
圖6 實體、地址、關系對數量及增量隨時間的變化Fig.6 Change of number and increment of entity,address and relationship pair over time
表2和表3中的數據為實體標識,通過對實體中錢包地址進行哈希運算后取哈希值前十位得到該標識。如果實體中包含多個地址,則使用最小的哈希,其中10位哈希值和CoinJoinMess標識的實體均為普通錢包實體,提供在線服務的實體用服務的名稱標識。

表2 基于可聚類交易數量的實體排名Table 2 Entity ranking based on number of clustering transactions
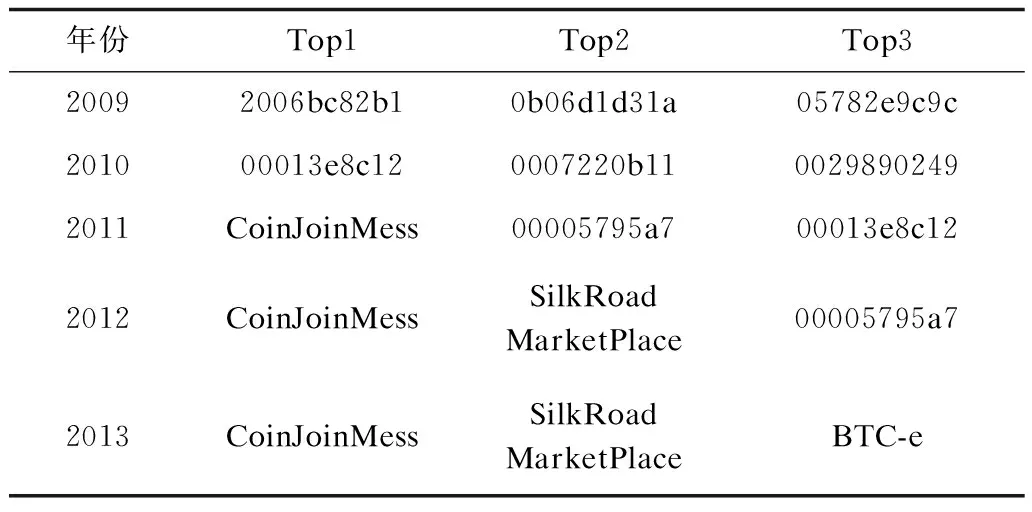
表3 基于地址數量的實體排名Table 3 Entity ranking based on number of addresses
由表2數據可以發現:2009年至2011年可聚類交易最多的Top3實體皆為普通錢包;在2012年前三名的實體中首次出現了錢包外的新類型,即比特幣在線服務SatoshiDice,其為一款從2012年開始運營的“基于區塊鏈的在線服務”;2013年出現了同類型新實體BitZillions,其為2013年起開始提供的加密貨幣下注的市場[17]。
表3按包含的可聚類地址數量對實體排名,從中可以發現:在2012年前三名的實體中首次出現了比特幣在線服務SilkRoad MarketPlace,該服務成立于2011年,提供各類商品在線匿名交易服務,這一特點使其發展迅速[18],2012年后成為地址數量Top3的實體;2013年出現的新實體BTC-e,是一個比特幣交易網站。同時從表3數據也可以看出,2010年后實體包含的地址明顯增多,這是因為2010年上半年是比特幣初始階段[19],主要用于挖礦,而2010年下半年是比特幣交易階段,逐漸出現了各種各樣的用戶和在線服務提供商[20]。
2.3 交易行為可視分析
對3個地址數量最多的實體進行交易行為可視分析。圖7(a)所示為截止至2012年Top3實體的交易行為,圖7(b)所示為截止至2013年Top3實體的交易行為,其中不同樣式的節點與圖例中相應樣式的實體類型相對應,交易的數量用節點的大小編碼,實體間的交易次數越多,節點間的距離越小。

圖7 Top3實體交易行為Fig.7 Top3 entity transaction behaviors
可以看出,圖7(a)中形成了2個明確的交易集群,其中一個集群的交易中心為SilkRoad實體,將鼠標懸浮在節點上可以看到中心節點SilkRoad MarketPlace實體與圖中其他類型的實體都有交易行為;另一交易團體中心為錢包實體,與其交易密切的實體類型也是錢包,推測其為錢包服務。
為防止節點過密而造成節點相互遮擋,在圖7(b)中顯示交易數量超過500次的實體。圖中形成3個交易集群,中心節點分別是錢包服務、交易平臺以及匿名交易網站SilkRoad MarketPlace。可以看出,與圖7(a)相比,圖7(b)中交易平臺類型的實體數量明顯增多,并且出現了新的匿名交易網站Sheep Marketplace,與其交易密切是實體分別為SilkRoad MarketPlace、BTC-e以及錢包實體。此外,BTC-e在2013年是地址數Top3的實體,出現此現象的原因為:在2013年在線匿名交易網站Sheep Marketplace通過BTC-e來進行洗錢[21],產生了大量地址和交易。
2.4 性能分析
與Walletexplorer.com 網站聚類的結果相比,本文方法進行實體聚類能夠達到100%正確率。表4為截止至2012年隨機選取的3個實體的地址數量對比。

表4 本文方法與Walletexplorer.com網站的聚類結果對比Table 4 Comparison of clustering results by the proposed method and WalletExplorer.com
圖8所示為傳統聚類方法與本文方法的執行并查集算法時間對比。可以看出,第1次實驗即處理2009年的數據時兩種方法用時相同,而之后由于本文增量聚類方法無需初始化集合和處理重復數據,因此用時較少,時間復雜度較低,因此效率更高。
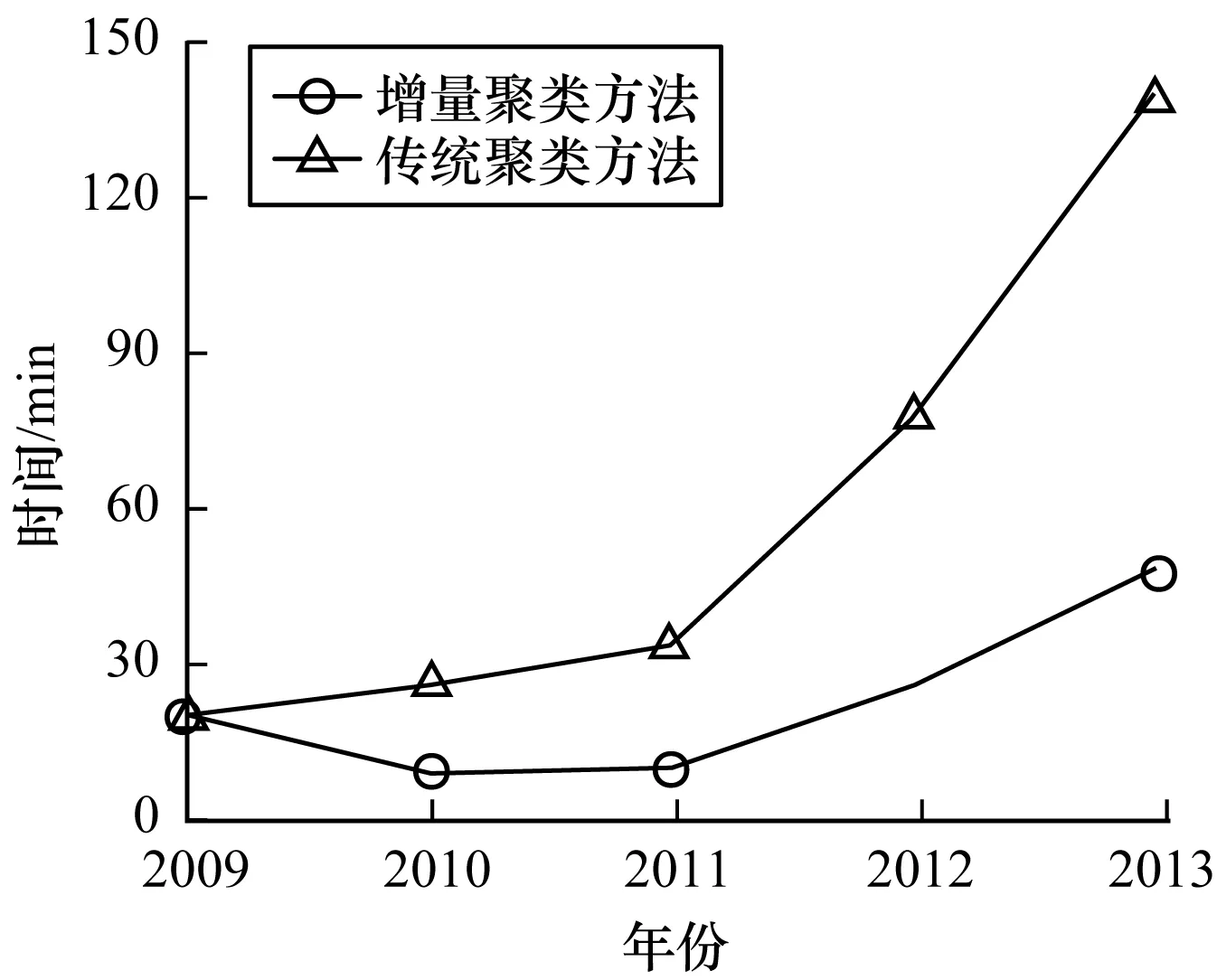
圖8 并查集算法時間對比Fig.8 Comparison of time of union-find algorithm
圖9所示為傳統聚類方法與本文方法的聚類時間對比。可以看出,在比特幣初始階段,兩種方法的聚類用時相同,但隨著時間推移,每年生成的區塊數量和聚合關系集合越來越多,本文增量聚類方法性能優勢越明顯。

圖9 聚類時間對比Fig.9 Comparison of clustering time
3 結束語
本文在啟發式聚類方法的基礎上,提出一種比特幣交易數據的增量聚類方法。通過對區塊流數據的分析及結構化處理,提取可聚類交易和聚類地址組并獲取聚類地址組間聚合關系,在此基礎上進行增量聚類,實現對比特幣實體類型和數量的演變分析,同時對地址數量最多的前三名實體的交易做進一步可視分析,發現不同時期實體間的交易特征。實驗結果表明,本文方法對多輸入交易的地址具有較好的效果,但不能將全部的交易地址覆蓋到聚類分析中。下一步將對此進行改進,提高該方法的交易地址覆蓋率。
