基于模型驅動的終端在線教育數據挖掘技術研究
2020-08-14 09:59:10劉維軍李曉會
現代電子技術 2020年16期
關鍵詞:數據挖掘
劉維軍 李曉會

摘? 要: 傳統終端在線教育數據挖掘技術的挖掘速度慢,為了解決這一問題,提出基于模型驅動的終端在線教育數據挖掘技術研究。運用關聯分析數據轉換法轉換數據,再利用模型驅動的人群行為建模方法,設計終端在線教育數據挖掘任務流程。完成上述工作后,通過篩選、選擇數據子集、編碼、設定閾值、進化步驟,優化模型驅動數據挖掘關鍵技術,實現終端在線教育高效數據挖掘。實驗結果表明,所提技術使用數據集規模小的挖掘速度相近,在使用數據集規模大時,挖掘速度逐漸增加;而傳統技術使用數據集規模小的挖掘速度與使用數據集規模大的挖掘速度基本相近。證明所提技術挖掘速度更快。
關鍵詞: 在線教育; 數據挖掘; 模型驅動; 數據轉換; 挖掘流程設計; 技術優化
Abstract: The terminal on?line education data mining technology based on model driving is proposed to overcome the defect that the mining speed of the traditional terminal online education data mining technology is slow. The correlation analysis method of data conversion is utilized to convert the data, and then the model?driven crowd behavior modeling method is used to design the flow of the terminal online education data mining. After above work is completed, the model?driven data mining key technology is optimized by the steps of screening, selecting data subset, encoding, setting threshold and evolving, so as to realize the high?efficiency data mining of the online education on the terminal. The experimental results show that the mining speeds of the proposed technology are similar as the traditional technology when using small?scale datasets, and the mining speeds of the proposed technology are gradually increased when using large?scale datasets; however, the mining speed of the traditional technology when using small?scale dataset and using large?scale dataset are almost same. It proves the mining speed of the proposed technology is faster.
Keywords: online education; data mining; model driven; data conversion; mining flow design; technology optimization
0? 引? 言
終端在線教育可視化需要完成數據挖掘這項任務,相關學者曾提出對LDA主題概率模型改進的研究,通過單一時間跨度的論壇主題挖掘數據,但這無法滿足數據噴薄而出的趨勢。還有學者引入時間要素的傳統方式,將終端在線教育數據按照時間劃分成獨立的主題集,但區間內部是無序的,無法留存多個獨立主題。為解決上述問題,國外學者提出使用模型驅動對結構內部之間的關系建模。模型驅動是專門用于解決模型建立和模型擴展等方面的問題[1]。模型驅動可以描述其他未來可能出現的XML的建模語言。這種方式可以描述兩種數據模型之間的映射規則,使通用的數據模型自由變換[2]。為了解決傳統終端在線教育數據挖掘技術存在的漏洞,提出基于模型驅動的終端在線教育數據挖掘技術研究。
終端在線教育數據龐大,其具有數據結構復雜、規模大、數據量大的特點。為優化數據挖掘關鍵技術,使用模型驅動更改線程結構,可挖掘出用戶的潛在信息。基于模型驅動的終端在線教育數據挖掘技術通過處理在線教育數據,梳理系統開發的任務目標,完成終端在線教育數據挖掘任務流程的設計,通過優化終端在線教育數據挖掘關鍵技術,提高挖掘目標精確度。實驗結果表明,本文所提技術具有一定的可行性。
1? 終端在線教育數據轉換
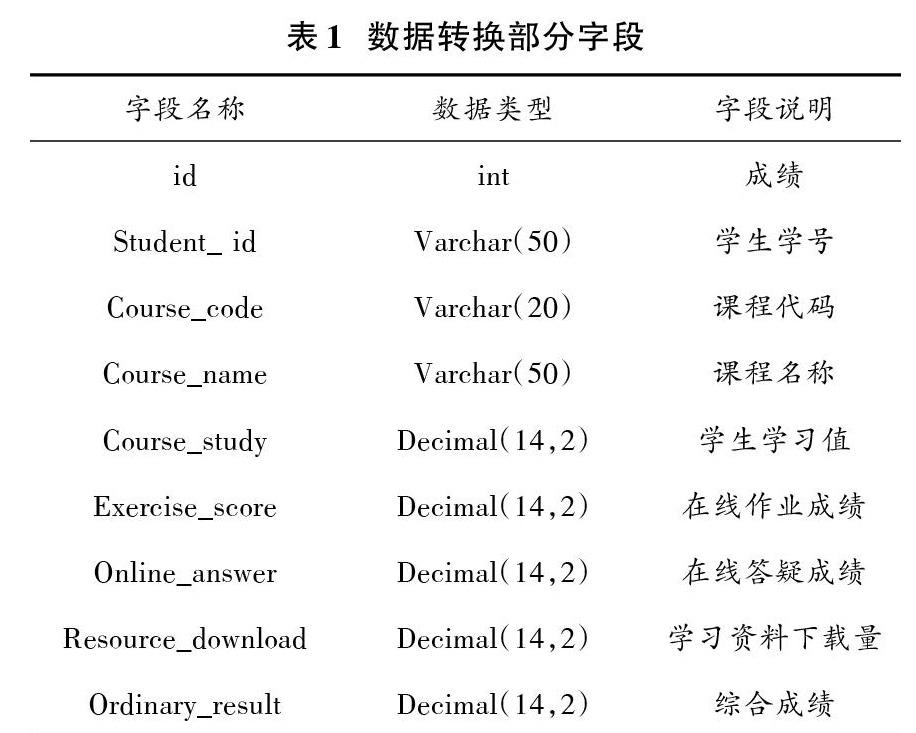
使用關聯分析數據轉換法,將區間內的數據映射為相應的離散值[3],再根據相關算法對數據的要求,將數據轉換成易于存儲的形式,轉換好的選定數據可存入相應的數據表,如表1所示。
當數據轉換成功后,即可從表1中的字段查看出學生在不同階段的學習情況。
2? 終端在線教育數據挖掘任務流程設計
當數據轉換成功后,利用模型驅動的人群行為建模方法,設計在線教育數據挖掘任務流程[4]。
先構建模型驅動人群行為模塊,包括數據驅動模塊和模型驅動模塊,模型驅動建模方法整體思路如圖1所示。
數據驅動模塊包含視頻采集和人群行為特征信息。模型驅動模塊由屬性模塊、行為模塊和路徑算法模塊組成[5]。為了過濾無效數據,運用爬蟲技術獲取文本流,再進行數據處理[6]。將轉換后的文本作為計算機處理對象。處理過程步驟為:分詞文本、取出停用詞、統計詞頻、文本向量化。完成文本處理后,從數據中提取用戶行為數據,即提取主題相關數據。不同的應用場景主體挖掘算法不同,要結合主題挖掘算法獲取相似主題特征的數據集合[7]。若仍無法自動生成主題,模型驅動會保存底層關系,采用簡潔的主題描述文檔語料庫。
3? 模型驅動數據挖掘關鍵技術優化
在主題挖掘的過程中,為完成不同主題集合的任務,采用聚類算法處理[8]。先求出特征空間內的特征加權向量,表達式為;
式中:[P]表示特征向量;[Tn]表示關鍵詞屬性;[Wn]表示主題向量;[n]表示聚類目標。設[Tn]與[Wn]有[x]個相同關鍵詞屬性,則[Tn]與[Wn]的相似度為:
式中:[J]表示相似度;[V]表示增量聚類個數。應用式(2)求出[Tn]與[Wn]的相似度。將[Tn]與[Wn]結果代入式(3)得到最終的聚類結果為:
式中:[k]表示聚類個數;[C]表示增量聚類時發生的變化;[r]表示特征向量屬性。得到最終的聚類結果,即為任務目標。
在此基礎上,優化模型驅動數據挖掘關鍵技術,得到最優特征子集,實現終端在線教育高效數據挖掘。優化數據挖掘關鍵技術的目的是從原始特征空間中剔除無效數據,提高挖掘目標精確度。優化過程為:
1) 篩選。經過篩選后得到最優特征子集,篩選流程如圖2所示。
2) 選擇數據子集。完成篩選任務后,要選擇較好的數據子集,選擇方式包括過濾式,先考察特征間的關系,再去除預測結果的一部分特征,采用優勝劣汰的機制刪除無效的數據。每次遞歸都要按照主題特征的參數求解大小排序,排序靠前的為無噪聲數據,排序靠后的為無效數據;也可以將數據看作一個最優搜索問題,通過搜索和遺傳算法選擇帶有主題特征的數據集合。
3) 編碼。為有效地從數據挖掘空間中選擇最優子集,選用種群個體編碼的方式,模擬原始數據的種群個體,種群空間為數據挖掘的搜索空間[9]。為簡化計算過程,在初始化種群時,將種群初始化大小設為20~100之間,其中種群個體代表每一種可能的數據集合,采用二進制編碼,選擇帶有主題特征的數據集合。
4) 設定閾值。引入方差閾值,將每個主題特征方差值與閾值相對比,若方差值大于設定閾值,需要過濾原始的數據挖掘空間;若小于設定閾值,可以直接提出變化幅度小的主題特征。經過篩選后,可以有效消減數據挖掘的范圍,提高算法的迭代速度[10]。
5) 進化。算子代表數據子集,在算子進化的過程中,根據種群內的個體適應值進行判斷。適應值高的可以進入下一輪進化,適應值低的個體可以保留。
由此,完成基于模型驅動的終端在線教育數據挖掘技術研究。
4? 實驗分析
為驗證基于模型驅動的終端在線教育數據挖掘技術的有效性,進行實驗研究。本次實驗選用的數據集是通過使用ERP系統獲取,主要包含用戶行為信息。將原始數據集隨機抽樣,擴充后的實驗數據集為D0,D1,D2,D3,D4。每個數據集中都包含68個主題特征,目標變量會隨著時間變化。本次實驗利用以上數據集,在模型驅動的框架下,分別測試傳統在線教育數據挖掘技術與所提技術的挖掘速度。表2為主題特征明細。
實驗數據的目標值域是無法確定的,實驗中要使用對數均方根誤差表示實驗結果的錯誤率。
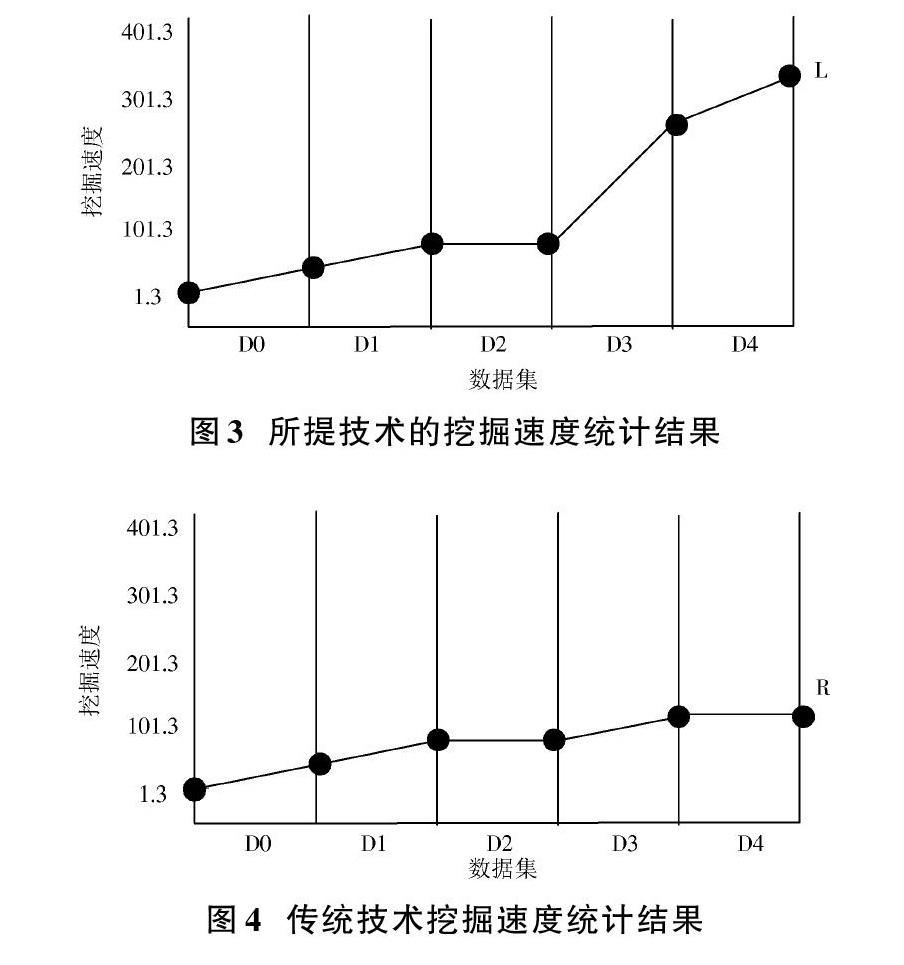
實驗結果利用模型驅動的線性回歸進行預測,實驗迭代次數為10次,為方便統計,將本次提出的基于模型驅動的終端在線教育數據挖掘技術標記為L,傳統的終端在線教育數據挖掘技術標記為R。兩種技術的挖掘速度對比結果如圖3和圖4所示。
從圖3可以看出,所提技術使用數據集規模小的時候,挖掘速度相近,在使用數據集規模大的時候,挖掘速度逐漸增加,在速度上相比傳統技術的更快。從圖4可以看出,傳統的技術使用數據集規模小的時候,挖掘速度相近,但耗時較長,在使用數據集規模大的時候,上漲幅度并不是很大,未超越所提技術的挖掘速度。由此可知,本次提出的基于模型驅動的終端在線教育數據挖掘技術更好。
5? 結? 語
針對傳統終端在線教育數據挖掘技術存在的問題,提出基于模型驅動的終端在線教育數據挖掘技術研究。將數據轉換部分字段轉換成易于存儲的形式,再利用模型驅動的人群行為建模方法設計終端在線教育數據挖掘流程,利用聚類算法求出特征空間內的特征加權向量,優化模型驅動數據挖掘關鍵技術。實驗結果表明,本文所提技術的挖掘速度大于傳統技術的挖掘速度,證明本文所提技術的效率更高。
參考文獻
[1] 陸鑫赟,王興芬.基于領域關聯冗余的教務數據關聯規則挖掘[J].計算機科學,2019,46(z1):427?430.
[2] 錢玲,徐輝富,郭偉.美國在線教育:實踐、影響與趨勢:CHLOE3報告的要點與思考[J].開放教育研究,2019,25(3):10?21.
[3] 陳敬德,盛戈皞,吳繼健,等.大數據技術在智能電網中的應用現狀及展望[J].高壓電器,2018,54(1):35?43.
[4] 王坤,唐純志,田小婷,等.基于數據挖掘技術探討針灸治療蕁麻疹的選穴規律及理論依據[J].針刺研究,2018,43(6):388?393.
[5] 甘璐.基于數據挖掘技術的檔案館信息快速分析算法研究[J].現代電子技術,2019,42(7):32?34.
[6] 張利利,馬艷琴.基于數據挖掘技術的航空客戶流失與細分研究及R語言程序實現[J].數學的實踐與認識,2019,49(6):134?142.
[7] 張康,黃亦翔,趙帥,等.基于t?SNE數據驅動模型的盾構裝備刀盤健康評估[J].機械工程學報,2019,55(7):19?26.
[8] 王學男.不同教師群體對教育大數據的認知及影響因素:基于全國5434名教師的調查[J].開放教育研究,2019,25(3):81?91.
[9] 李爽,李榮芹,喻忱.基于LMS數據的遠程學習者學習投入評測模型[J].開放教育研究,2018,24(1):91?102.
[10] 張愛平,馬敏.基于質量監測的初中學生數據分析發展狀況的調查研究[J].數學教育學報,2017,26(1):28?31.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
