RBAC中角色挖掘算法研究*
2020-08-14 06:32:24袁學斌李文萍劉生成李宗容張文倩
通信技術 2020年8期
袁學斌,李文萍,劉生成,李宗容,張文倩
(1.國網青海省電力公司電力科學研究院,青海 西寧 810008;2.中國移動通信集團青海有限公司,青海 西寧 810007;3.國網青海省電力公司信息通信公司,青海 西寧 810000)
0 引言
基于角色的訪問控制(Role based Access Control,RBAC)相比于傳統訪問控制有諸多優勢,因其安全性、靈活性、可擴展性已成為目前應用最廣泛的訪問控制技術之一。構建RBAC的核心是角色的發現,發現角色的方法稱為角色工程,其中將自底向上的角色工程方法簡稱為角色挖掘[1]。角色挖掘通過智能化方法在系統中將已存在用戶-權限關系得到合適的角色[2],是如今訪問控制中研究的重點。盡管角色挖掘研究已取得很多成果,但目前仍存在一些問題,如算法生成角色數較多,給系統實施和維護帶來負擔,角色挖掘算法精度低、運行效率低下等一系列問題,因此如何使算法高效且有效是一個具有研究價值的課題。
1 基于角色的訪問控制
1.1 RBAC模型
RBAC模型有別于傳統訪問控制模型自主訪問控制模型(Discretionary Access Control,DAC)和強制訪問控制模型(Mandatory Access Control,MAC),通過角色將用戶和權限進行邏輯隔離。RBAC模型中基本包含:角色集、用戶集、權限集、角色-權限指派關系和用戶-角色指派關系等基本元素,RBAC核心模型如圖1所示。
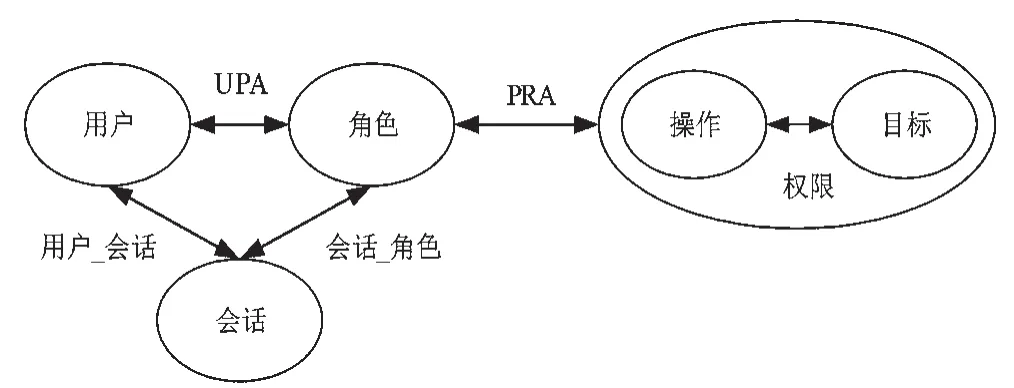
圖1 核心RBAC模型
RBAC模型中用戶得到角色,然后為角色分配權限,用戶由此得到相應的權限[3],在RBAC模型中,角色是整個模型的關鍵,角色的本質就是權限集[4]。因此RBAC相比于傳統的訪問控制模型,更加符合各類組織的安全要求,應用更加廣泛。考慮到角色間的分層關系對于提升RBAC安全性、實用性十分重要,RBAC中又可以分為層次RBAC模型,在層次RBAC模型中,考慮了角色分層(Role Hierarchy,RH)的概念,層次RBAC模型如圖2所示。
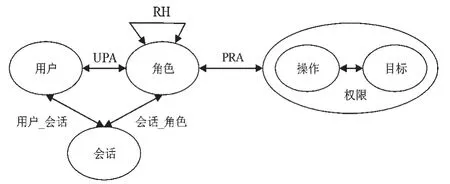
圖2 層次RBAC模型
RH中定義了角色之間的繼承關系,如果角色R2的所有權限都包含在角色R1權限集內,則角色R2繼承角色R1。層次RBAC可以避免同一權限在信息系統中的重復存儲,降低了存儲代價,提高了管理效率,同時也更加符合現實應用,得到了廣泛應用。
1.2 角色挖掘
角色挖掘的研究工作始于2003年,在文獻[5]中首次提出了角色挖掘技術,如今對于角色挖掘的研究正日益深入,現在已提出了眾多算法并且很多已經應用于實際。角色挖掘中最主要的目的就是構建RBAC系統,隨著該研究領域需求的日益重要,對于角色挖掘中很多重要問題有必要進行深入分析,其中最重要的就是角色挖掘算法的優化目標。
1.2.1 預備知識
首先給出角色挖掘算法中經常出現的概念:
USERS,用戶集;數量為m;
PERMS,權限集;數量為n;
ROLES,角色集,數量為k;
UA?USERS×ROLES,指用戶-角色分配關系m×k;
PA?ROLES×PERMS,指角色-權限分配關系k×n;
RH?ROLES×ROLES,指角色繼承關系k×k;
UPA?USERS×PERMS,指用戶-權限分配關系m×n;
RoleUsers(r)={u∈U|(u,r)∈UA},指賦予角色R的用戶集合;
RolePerms(r)={p∈P|(r,p)∈PA},指角色R分配的權限集合。
1.2.2 角色挖掘數據來源
角色挖掘是將系統中已存在的用戶-權限分配關系,通過智能化的方法轉化為RBAC系統。圖3中所示為將UPA數據通過角色挖掘技術得到候選的角色集,其中角色挖掘技術一般是指數據挖掘技術,所以在角色挖掘算法中,輸入為UPA數據,輸出為生成的角色集。
隨著對角色挖掘研究的不斷深入,在分析如今日益復雜的信息系統訪問控制策略并生成角色時,現有的角色挖掘算法仍然存在很多問題和不足,如產生冗余角色多、角色精度低、算法效率低下等,給系統的部署、使用和維護帶來諸多問題,具體問題如圖4中所示,本文的研究也是為了解決其中一些關鍵的問題。

圖3 角色挖掘

圖4 角色挖掘關鍵問題
2 YMiner算法設計
2.1 GO算法
Graph Optimisation(GO)算法由Zhang等提出[6],該算法將角色挖掘問題視為圖優化問題,利用圖優化技術來得到合適的角色集。GO算法首先將每個用戶的權限集視為一個角色,以最小化角色數和邊的數量為優化指標,對兩個角色迭代進行處理運算,來得到新的角色。該算法輸出結果為完整RBAC狀態,包含角色之間的繼承關系,圖5所示為GO算法在某數據集生成的角色繼承關系,是經典角色挖掘算法之一。

圖5 GO算法生成的角色繼承關系
2.2 GO算法缺陷
GO算法基于圖優化理論,通過優化指標對初始角色集迭代進行交集運算,來得到新的角色,但是在算法設計方面仍有可以改進的地方,其最主要的問題主要有[7]:第一,GO算法以最小化邊數和角色數為優化指標。將每個用戶的權限集視為一個角色,得到初始角色集,之后根據優化指標對其進行角色間的處理,得到新的角色,這意味著其目標是最小化角色數、角色-角色繼承關系指派成本、角色-權限的指派成本,并不考慮直接用戶授權等成本,在角色挖掘領域中用加權結構復雜度來代表角色指派成本;第二,在對角色進行處理時不考慮角色間相似度。角色相似度是指兩角色間的相似程度,相似度越大說明兩角色含有的相同權限就越多,相似度為1則說明兩角色含有相同的權限集。如果在角色生成時忽略了這一要素可能導致:(1)算法產生的角色不能準確反映實際需求,即角色集精確度低;(2)產生冗余角色,給系統實施和維護帶來負擔。因此有必要在角色合并時考慮這些因素。
2.3 角色相似度計算
在上文中討論了角色相似度在角色合并時的重要性,本文中將角色相似度定義如下:
定義 2.1 權限相似度
權限相似度是指兩個角色擁有的共同權限集與所有權限集之比[8]。即:
其中RolePerms(r1)是角色r1擁有的權限集,RolePerms(r2)是角色r2擁有的權限集。
定義2.2 用戶相似度
用戶相似度是指兩個角色擁有的共同用戶集與所有用戶集之比[9]。即:

其中RoleUsers(r1)是角色r1擁有的用戶集,RoleUsers(r2)是角色r2擁有的用戶集。
定義2.3 角色相似度
角色的本質是權限的集合,因此角色間的相似度定義為:

其中RolePerms(r1)是角色r1擁有的權限集,RolePerms(r2)是角色r1擁有的權限集。
2.4 加權結構復雜度計算
Ian Molloy[10]等人基于前人提出的角色挖掘算法,提出使用加權結構復雜度(Weighted Structure Complexity,WSC)來綜合衡量角色指派成本和角色挖掘算法性能。在該評價指標中給出權重因子
W=<WR,WUA,WPA,WRH,WD>,WR,WUA,WPA,WRH,WD
是所有非負有理數集合;給定系統狀態五元組<ROLES,UA,PA,RH,DUPA>,ROLES為角色集,UA為用戶-角色指派關系,PA為角色-權限指派關系,RH為角色層次關系,DUPA為進行角色指派后對用戶進行權限指派,||表示集合的基數,RBAC加權結構復雜度函數定義如下:

WSC中通過對五元組設置不同的權重,可得到不同的RBAC狀態,充分考慮了RBAC的所有關系。當W=<1,1,1,1,1>時,表示希望得到一個完整RBAC系統成本。在公式(4)中如不考慮DUPA因素,此時WSC只考慮前四個因素,當WSC作為角色挖掘算法評價標準時,一般不考慮DUPA。
2.5 算法全局優化函數計算
GO算法將最小化角色數和邊數作為最優化函數,本文提出的最優化函數中使用WSC,來降低算法角色權限指派成本;同時在產生新角色時考慮角色相似度,得到全局最優化函數,計算如下:

本文中最優化函數是一個多目標優化問題,從公式(5)可知,本文算法的優化目標是最小化WSC,是為了減少指派成本,同時最大化兩角色間的相似度,這是為了考慮角色優化時的情況。其中a取值在0和1之間,是一個權重因子,可根據實際需要進行調整。在公式(5)中當a的值取0時,此時全局優化函數L只考慮加權結構復雜度;當a的值取1時,此時全局優化函數L考慮角色間的相似度。
2.6 YMiner算法
GO算法在設計時因沒有考慮角色相似度、角色指派成本等因素,導致算法存在生成角色集精度低、冗余角色多等問題。本文針對GO算法存在問題,設計新的算法全局優化函數,得到新的算法YMiner(YM),在YM算法中,處理角色間關系時考慮角色權限集之間的四種情況,分別為:第一,兩角色權限集相同;第二,一個角色權限集是另一角色權限集的超集;第三,兩個角色有共同權限集;第四,兩角色間的權限集無任何關系。在YM算法中處理完角色間的不同的情況后更新角色狀態,得到最終的角色集合,算法的流程如圖6所示。
圖7、圖8、圖9所示分別為YM算法中在處理不同角色集情況時的處理方法。圖7所示為處理兩個角色擁有相同權限集時的情況。如果兩個角色擁有相同權限集,則根據角色相似度計算公式,則相似度為1,此時刪除其中一個角色,剩下一個角色的用戶集是處理前兩角色用戶集之和。將兩個角色合并為一個角色將改善優化指標,減少了角色數量,并且減少邊的數量,這種情況將有效降低加權結構復雜度,有利于降低優化指標。
圖8所示為處理一個角色權限集是另一角色權限集的超集時的情況,此時創建一條從超集權限集角色到子集權限集角色的鏈接,保留超集到除子集對應權限的鏈接,刪除超集到其他權限的鏈接,此時擁有超集權限的用戶不直接得到子集權限,而是間接通過得到子集角色得到權限。當進行上述操作時,角色數沒有發生變化,對優化指標可能沒有影響。
圖9所示為處理兩個角色擁有相同權限集的情況,此時創建一個包含公共權限集的角色,此角色的用戶集是兩個父角色用戶集的并集;之后分別創建兩條父角色到子角色的邊,以顯示角色間的層次關系;最后新創建的角色的權限集是原來兩個父角色權限集的交集。當進行上述操作時邊數可能會降低,有利于降低優化指標。
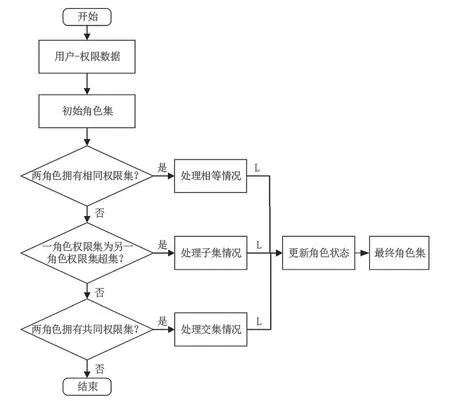
圖6 YMiner算法流程圖

圖7 兩角色擁有相同權限集

圖8 一角色權限集是另一角色權限集超集


圖9 兩角色擁有相同權限集
第四種情況兩角色權限集不存在任何關系時,對兩角色不做任何處理。
YM算法具體如下:
YM算法
輸入:用戶集USERS、權限集PERMS、用戶-權限指派關系UPA
輸出:最終的角色集ROLES
1:使用角色生成方法將UPA數據生成初始角色集
2:whilethere can be more mergesdo
3:從初始角色集中選擇兩個角色R1和R2
4:if(兩角色R1和R2權限集相同)
5:處理相等情況
6:end if
7:計算全局最優化函數L1=(1-a)*WSC
+a*RoleSim
8:if(一角色權限集是另一角色權限集子集)
9:處理子集情況
10:計算處理后全局最優化函數L2=(1-a)
*WSC+a*RoleSim
11:if(L2>L1)
12:then
13:撤銷子集操作
14:else
15:L2=L1
16:end if
17:end if
18:計算當前的全局最優化函數L1
19:if(兩角色擁有共同權限集)
20:處理交集情況
21:計算處理后全局最優化函數L3
=(1-a)*WSC+a*RoleSim
22:if(L3>L1)
23:then
24:撤銷交集操作
25:else
26:L1=L3
27:end if
28:end if
29:end while
30:return Roles
3 實驗結果
在本節中,將上節中所得YM算法和另外四種經典角色挖掘算法在真實數據集上通過加權結構復雜度和算法運行時間進行對比實驗,來說明其性能,這四種算法分別為HP Role Minimization (HPr),HP Edge Minimization (HPe),Complete Miner(CM),GO。其中HPr算法主要目標是找到最小角色集,HPe算法的主要目標是最小化角色間邊的數量,CM算法的時間復雜度呈指數增長,不合適使用于數據量很大的情況。本文的實驗環境如表1所示。

表1 實驗環境
3.1 真實數據集
本實驗使用的真實數據集總共包括七個數據集,相關數據如表2所示,這些數據集被經常用于各類角色挖掘算法的對比實驗。

表2 真實數據集
其中,|users|代表用戶數,|permissions|代表權限數,|UPA|代表用戶-權限分配關系中1的個數;|Density|代表數據中1的個數占總數的比例。數據集APJ和EMEA是從惠普公司網絡的思科防火墻中抽取得到[11],這些數據描述了公司授權的外部用戶對于企業內部資源的訪問情況;Healthcare數據集來源于美國退伍軍人管理局;Domino數據集是從Lotus軟件用戶訪問數據中獲得;University數據集是從某大學得到的訪問控制數據;數據集Firewall1和Firewall2是從防火墻監測點得到的訪問控制數據。
3.2 算法評價標準
(1)加權結構復雜度。在上文中已經對WSC進行了詳細介紹并給出了計算方式,當四元組取不同值時,在RBAC系統中評價標準不同,算法結果不同。當W=<1,0,0,0>時,算法的目標最小化角色數;W=<0,1,1,1>時,算法的目標是最小化邊數;W=<1,1,1,1>時,算法的目標是最小化邊數和角色數,WSC已成為角色挖掘算法的主要評價標準之一。
(2)算法運行時間。WSC提供了一種統一的評價標準來評價角色挖掘算法,但是在算法分析中算法運行時間同樣重要。在本文實驗的綜合評價中加入算法運行時間,通過多種評價標準可以更全面、更綜合的對算法進行評價。
3.3 實驗結果分析
本文將YMiner算法與另外四種經典角色挖掘算法,在加權結構復雜度、算法運行時間等指標下分別進行對比實驗,作詳細對比分析。將每個算法在不同數據集上得到的結果進行升序排序,之后將該算法在所有數據集上的排名進行綜合排名,得到Ranking,根據Ranking可非常直觀判斷算法性能,具體計算方式如下:如當W=<1,0,0,0>時,算法CM在七個數據集上結果分別為1,2,3,2,5,5,4,Ranking=(1+2+3+2+5+5+4)/7=3.14,Ranking的值越小說明該算法在這項比較中綜合性能越好。
表3是W=<1,0,0,0>時的實驗結果,此時f(τ,W)=|ROLES|*WR,算法的目標是產生角色數最少。表中第一列是數據集名稱,后序列是各算法在不同數據集產生的角色數。在上文中提到HPr算法優化目標是最小化生成角色數,在生成角色最少這一指標上表現非常出色,GO算法的結果也表現突出,YM算法同其他算法相比明顯減少了產生的角色數量,同時YM算法產生角色數相比GO算法平均少4.3%,CM算法設計時最大缺點便是生成角色數眾多,實驗結果說明了這一特征。

表3 W=<1,0,0,0>,即算法的目標是角色數最少
表4是W=<0,1,1,1>時的實驗結果,此時f(τ,W)=|UA|*WUA+|PA|*WPA+|RH|*WRH,此時算法的目標是產生的邊數最小。HPe算法的主要目標是最小化角色間邊的數量,從上述實驗數據便可說明這一特點;YM算法產生邊數相比GO算法平均少15.9%,YM算法在小數據集上表現優異,但在大數據集Domino、EMEA、APJ上不如小數據集優異,需進一步分析和改進。

表4 W=<0,1,1,1>,即算法的目標是邊數最少
表5是W=<1,1,1,1>時的實驗結果,此時f(τ,W)=|ROLES|*WR+|UA|*WUA+|PA|*WPA+|RH|*WRH算法目標是產生角色數和邊數最小。GO算法的優化指標為最小化角色數和邊數,上述實驗結果驗證了GO算法的這一特點;因為YM算法在優化指標中考慮了角色指派后對用戶進行權限指派,導致此項結果算法產生角色數和邊數多于GO算法,不過與其他算法相比,性能表現依然出色。

表5 W=<1,1,1,1>,即算法目標是最小化邊數和角色數
表6是算法運行時間對比,從上述數據中可以明顯看到,YM算法在各個數據集上運行速度最快,其他算法則運行效率相差不大,YM相比其他算法運行效率得到極大提升,這是因為YM算法在設計時考慮了角色間相似度,這有助于在后續步驟角色處理時大幅提高效率,進而提升算法運行效率。

表6 算法運行時間(單位:秒)
總結:表3、表4、表5、表6中給出了YM算法在不同評價指標下在真實數據集上的實驗。在產生角色數方面,平均比GO算法少4.3%,比其他算法均有不同幅度的減少;在產生邊數方面比GO算法平均低15.9%;在最小化邊數和角色數方面,YM算法在小數據集上優于GO算法,但在大數據集上性能欠佳,需進一步分析和改進;在算法運行效率方面,YM算法相比其他算法大幅提升,這也是YM算法將WSC和角色相似度作為優化函數的優點。經過不同算法評價指標下的綜合比較,本文設計的YM的綜合性能相比GO算法及其他算法均有明顯的提升,這為以后YM算法的持續改進和實際應用打下堅實的基礎。
4 結語
在本文中,首先介紹了RBAC,之后詳細解釋了角色挖掘概念,總結了目前角色挖掘算法研究中存在的一些難點。通過介紹GO算法,指出其存在的問題,針對GO算法在設計時存在的缺陷,本文設計了新的算法全局優化函數來改進,并在真實數據集上與其他四種角色挖掘算法進行對比實驗,結果說明了本文設計算法的優異性能。由于個人研究能力和時間的限制,仍有一些問題有待后續改進完善,如沒有考慮生成角色的精確度,沒有考慮角色之間的約束關系等,值得進一步的研究。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
現代企業(2015年2期)2015-02-28 18:45:09
創業家(2015年10期)2015-02-27 07:55:08
