基于LeakyMish 流行正則化半監(jiān)督生成對(duì)抗網(wǎng)絡(luò)的圖像分類模型
2020-08-07 14:42:30張鵬魏延胡將軍
現(xiàn)代計(jì)算機(jī) 2020年18期
張鵬,魏延,胡將軍
(重慶師范大學(xué)計(jì)算機(jī)與信息科學(xué)學(xué)院,重慶401331)
0 引言
隨著互聯(lián)網(wǎng)的普及和智能信息處理技術(shù)的迅速發(fā)展,大規(guī)模圖像資源不斷涌現(xiàn),而面對(duì)海量的圖像信息,如何準(zhǔn)確地對(duì)圖像進(jìn)行分類成為了近幾年的研究熱點(diǎn)。圖像分類就是根據(jù)圖像的不同特征將不同類別的圖像進(jìn)行區(qū)分。常用來測(cè)試圖像分類準(zhǔn)確率的數(shù)據(jù)集有SVHN、CIFAR-10 等數(shù)據(jù)集。
機(jī)器學(xué)習(xí)方法一般分為三大類:監(jiān)督學(xué)習(xí)、無監(jiān)督學(xué)習(xí)和半監(jiān)督學(xué)習(xí)。由于監(jiān)督學(xué)習(xí)需要大量的人工標(biāo)簽,在實(shí)際應(yīng)用中,需要消耗大量的人力財(cái)力;無監(jiān)督學(xué)習(xí)是通過讀取數(shù)據(jù)學(xué)習(xí)模型和規(guī)律,準(zhǔn)確率較差;半監(jiān)督學(xué)習(xí)是以少量的標(biāo)簽樣本訓(xùn)練大量無標(biāo)簽樣本,與監(jiān)督學(xué)習(xí)相比較,半監(jiān)督學(xué)習(xí)需要消耗的人力財(cái)力較低,且可以取得較高的準(zhǔn)確率,因此半監(jiān)督學(xué)習(xí)成為了學(xué)者們的研究熱點(diǎn)。
在深度學(xué)習(xí)[1]中,雖然圖像分類現(xiàn)有的方法如卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,CNN)[2]等已經(jīng)有了很高的準(zhǔn)確率,但這些方法需要大量數(shù)據(jù)并且收斂速度較慢。生成對(duì)抗網(wǎng)絡(luò)(Generative Adversarial Network,GAN)[3]的出現(xiàn)迅速被研究應(yīng)用的到了各個(gè)領(lǐng)域,圖像分類就是其中之一,生成對(duì)抗網(wǎng)絡(luò)模型生成的樣本可以彌補(bǔ)一些數(shù)據(jù)集,可以彌補(bǔ)CNN 的一些缺陷,且取得不錯(cuò)的準(zhǔn)確率。
1 生成對(duì)抗網(wǎng)絡(luò)
GAN 是Goodfellow 在2014 年提出的一種深度學(xué)習(xí)模型,GAN 的優(yōu)點(diǎn)在于,GAN 是一種生成式模型、可以產(chǎn)生更加真實(shí)的樣本,并且是一種無監(jiān)督的學(xué)習(xí)方式訓(xùn)練,故在近幾年引起了深度學(xué)習(xí)界的廣泛關(guān)注。GAN 也因此迅速發(fā)展,不斷地被改進(jìn)并應(yīng)用到的各個(gè)領(lǐng)域,如計(jì)算機(jī)視覺、文本、語音和圖像等等領(lǐng)域。GAN 是Goodfellow 受二人零和博弈游戲啟發(fā)提出的,在零和博弈游戲中,極小極大兩個(gè)玩家相互競(jìng)爭(zhēng);而在GAN 模型中,有兩模塊,分別是生成器和鑒別器,故是生成器和鑒別器相互競(jìng)爭(zhēng)。生成器通過學(xué)習(xí)真實(shí)樣本生成類似真實(shí)樣本的生成樣本,盡可能地欺騙鑒別器,而鑒別器區(qū)分真實(shí)樣本和生成樣本,盡可能地不被生成樣本欺騙,兩者相互競(jìng)爭(zhēng),最終達(dá)到納什均衡,它表述為:
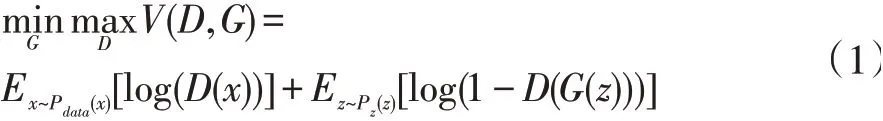
其中,x 為真實(shí)圖像庫中的圖像,Pdata為其分布,z為隨機(jī)噪聲,Pz為其分布,一般為高斯白噪聲,D(x)是真實(shí)圖像輸入鑒別器后的輸出概率值,G(z)是隱變量通過生成器得到的生成圖像,D(G(z))是生成圖像通過鑒別器后的輸出概率值。生成對(duì)抗網(wǎng)絡(luò)模型結(jié)構(gòu)如圖1 所示。
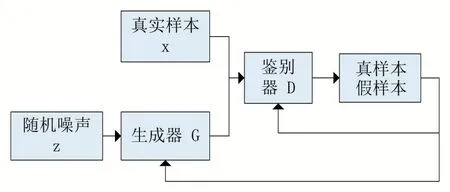
圖1 生成對(duì)抗網(wǎng)絡(luò)結(jié)構(gòu)模型
從圖1 中可以看出,原始的生成對(duì)抗網(wǎng)絡(luò)是一個(gè)二分類模型,真實(shí)樣本和生成器生成的樣本傳輸給鑒別器,鑒別器判斷是真樣本還是假樣本,并反饋給生成器和鑒別器,從而提高了生成器生成真實(shí)樣本的能力和鑒別器判別真假的能力。
2 流行正則化半監(jiān)督生成對(duì)抗網(wǎng)絡(luò)
2.1 半監(jiān)督生成對(duì)抗網(wǎng)絡(luò)
半監(jiān)督生成對(duì)抗網(wǎng)絡(luò)(Semi-Supervised Learning with Generative Adversarial Networks,SSLGAN)[4]是Augustus Odena 提出的模型,SSLGAN 在GAN 的基礎(chǔ)上進(jìn)行的改進(jìn),并將GAN 應(yīng)用到了半監(jiān)督領(lǐng)域中,即用少量的標(biāo)記樣本來訓(xùn)練大量的無標(biāo)記樣本。監(jiān)督學(xué)習(xí)需要大量的標(biāo)記樣本,而這需要消耗大量的人力和財(cái)力,故半監(jiān)督學(xué)習(xí)成為重點(diǎn)的研究方向之一,SSLGAN也為GAN 帶來了新的潛力。SSLGAN 模型結(jié)構(gòu)如圖2所示。
從圖2SSLGAN 模型可以看出,真實(shí)樣本變?yōu)榱薻類樣本,在半監(jiān)督學(xué)習(xí)遇到的都是多分類問題,故SSLGAN 模型由原始GAN 的二分類模型改進(jìn)為多分類模型。k類真實(shí)樣本和生成器生成的樣本傳輸給鑒別器,鑒別器區(qū)分樣本是k類中的一類真實(shí)樣本還是生成器的生成樣本。

圖2 SSLGAN模型結(jié)構(gòu)
2.2 Improved GAN+Manifold Reg模型
Improved GAN+Manifold Reg 模型[5]是Bruno Lecouat 和Chuan-Sheng Foo 等人提出的模型。Improved GAN+Manifold Reg 模型是在知名半監(jiān)督GAN 中Improved GAN[6]模型上進(jìn)行改進(jìn)的模型。
Bruno Lecouat 和Chuan-Sheng Foo 提出拉普拉斯范數(shù)估計(jì)可近似為:
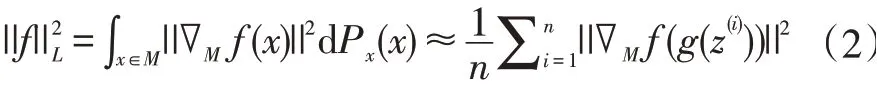
GAN 可以對(duì)圖像流形進(jìn)行建模[6-7]。生成器g 定義了一個(gè)圖像上的流形[8],從而計(jì)算相對(duì)于潛在表示的所需梯度,梯度是雅可比矩陣,故表示為:
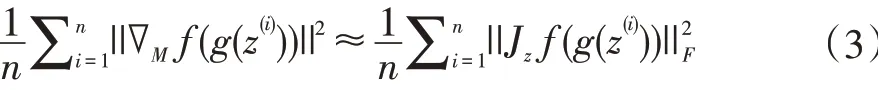
J 是雅可比矩陣。
由公式(2)和(3)得公式(4):

Bruno Lecouat 和Chuan-Sheng Foo 使用有限差分法來近似最終的雅可比矩陣正則化器。雅可比矩陣正則化器表示如公式(5)所示:
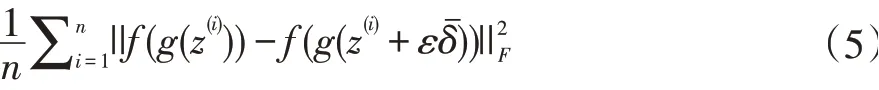
Bruno Lecouat 和Chuan-Sheng Foo 又將雅可比矩陣正則化器應(yīng)用于半監(jiān)督生成對(duì)抗網(wǎng)絡(luò)的鑒別器中,鑒別器的損失函數(shù)如公式(6)~(8)所示:

Improved GAN + Manifold Reg 模型的鑒別器損失函數(shù)使用是上述鑒別器的損失函數(shù),生成器使用的是Salimans 等人提出的特征匹配[5],防止當(dāng)前鑒別器過度訓(xùn)練。生成器的損失函數(shù)表示如公式(9)所示:
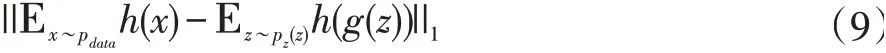
h(x)表示的鑒別器中間層的激活值。Improved GAN+Manifold Reg 模型在穩(wěn)定性和準(zhǔn)確率上都比Improved GAN 模型有了進(jìn)一步的提高。
3 Improved GAN+Manifold Reg+LMM模型
針對(duì)Improved GAN+Manifold Reg 模型的學(xué)習(xí)能力,為提高圖像分類的準(zhǔn)確率,提出了Improved GAN+Manifold Reg+LMM 模型,該模型是一半監(jiān)督圖像分類模型。
3.1 激活函數(shù)
常用的激活函數(shù)有ReLU、LeakyReLU 等。
線性整流單元(Rectified Linear Unit,ReLU),ReLU函數(shù)的數(shù)學(xué)公式可表示為:
ReLU=max(0,x) (10)
從公式(10)可以看出,在x 軸正軸ReLU 函數(shù)為正比例函數(shù),在x 軸負(fù)軸ReLU 函數(shù)為0。ReLU 函數(shù)可以有效的進(jìn)行梯度下降和反向傳播。
泄露修正線性單元(Leaky Rectified Linear Unit,LeakyReLU),LeakyReLU 函數(shù)是在ReLU 函數(shù)上進(jìn)行了一個(gè)改進(jìn),LeakyReLU 函數(shù)的數(shù)學(xué)公式可表示為:

leaky 是(0,1)區(qū)間內(nèi)的固定參數(shù)。LeakyReLU 函數(shù)對(duì)負(fù)值輸入有很小的坡度,減少了靜默神經(jīng)元的出現(xiàn),故效果要比ReLU 好。
然而針對(duì)激活函數(shù)的研究卻一直沒有停過。D Misra 提出了一種新的深度學(xué)習(xí)激活函數(shù)——Mish[9]激活函數(shù)。在D Misra 的論文中,Mish 函數(shù)在最終準(zhǔn)確度上比Swish 和ReLU 都有提高。類似于Swish,Mish是一個(gè)平穩(wěn)和非單調(diào)激活函數(shù)可以定義為:

Mish 函數(shù)的圖形如圖3 所示。
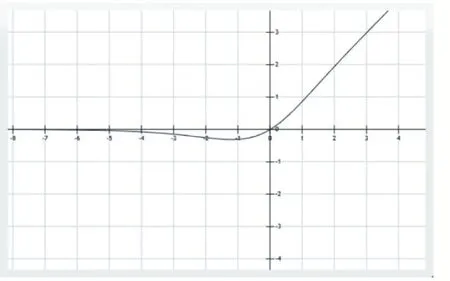
圖3 Mish函數(shù)圖形
對(duì)Mish 函數(shù)進(jìn)行求導(dǎo),得出表達(dá)式如下:
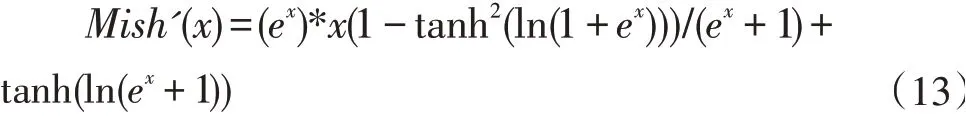
Mish 函數(shù)導(dǎo)數(shù)圖形如圖4 所示。
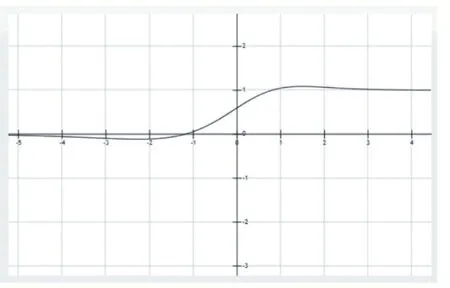
圖4 Mish函數(shù)導(dǎo)數(shù)圖形
從圖3 可以看出,Mish 函數(shù)在x 正半軸接近成正比例,在x 負(fù)半軸接近0-。Mish 函數(shù)表現(xiàn)良好正是因?yàn)楹瘮?shù)正值可以達(dá)到任何高度,避免了由于封頂而導(dǎo)致的飽和,從圖4 可以看出Mish 函數(shù)導(dǎo)數(shù)圖形是光滑的,即Mish 函數(shù)以光滑的曲線,故平滑的Mish 激活函數(shù)允許更好的信息深入神經(jīng)網(wǎng)絡(luò),從而得到更好的準(zhǔn)確性和泛化。
針對(duì)生成對(duì)抗網(wǎng)絡(luò)的鑒別器和生成器的激活函數(shù)進(jìn)行了研究,生成器卷積神經(jīng)網(wǎng)絡(luò)的激活函數(shù)使用ReLU 函數(shù),鑒別器則使用的是LeakyReLU 函數(shù)。由此,針對(duì)生成器的激活函數(shù)是Mish 函數(shù),提出了激活函數(shù)LeakyReLU 函數(shù),鑒別器的激活函數(shù)為L(zhǎng)eakyMish函數(shù)。LeakyMish 函數(shù)表達(dá)式如下:
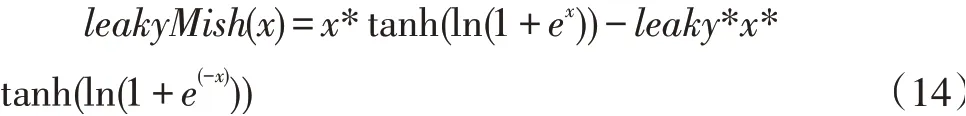
leaky 是(0,1)區(qū)間內(nèi)的固定參數(shù)。
leaky=0.2 時(shí),Leaky Mish 函數(shù)圖形如圖5 所示。
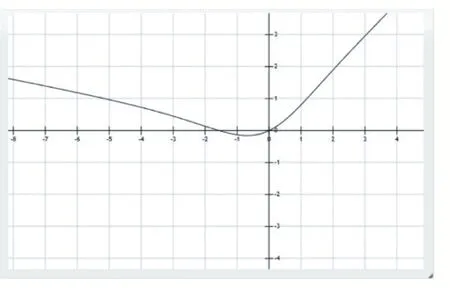
圖5 Leaky Mish函數(shù)圖形
對(duì)leakyMish(x)求導(dǎo),得出如下表達(dá)式:
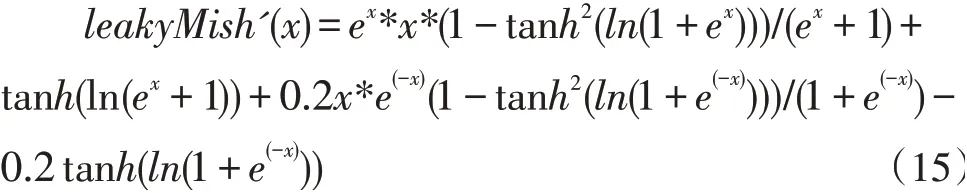
LeakyMish 函數(shù)導(dǎo)數(shù)圖形如圖6 所示。

圖6 Leaky Mish函數(shù)導(dǎo)數(shù)圖形
通過圖5 發(fā)現(xiàn),LeakyMish 函數(shù)也是在x 軸正軸正值比例,避免了由于封頂而導(dǎo)致的飽和。從圖5 和圖6看出LeakyMish 函數(shù)圖形及其導(dǎo)數(shù)圖形都是光滑的,從圖4 和圖6 可以看出LeakyMish 函數(shù)的導(dǎo)數(shù)圖形和Mish 函數(shù)的導(dǎo)數(shù)圖形相似,故LeakyMish 是光滑的曲線,可用做激活函數(shù)。故LeakyMish 激活函數(shù)允許更好的信息深入神經(jīng)網(wǎng)絡(luò),從而得到更好的準(zhǔn)確性和泛化數(shù)。
3.2 優(yōu)化器
Adam[9]優(yōu)化器是常用的一種優(yōu)化器,它是由OpenAI 的Diederik Kingma 和多倫多大學(xué)的Jimmy Ba 提出來的。Adam 可以基于訓(xùn)練數(shù)據(jù)迭代更新神經(jīng)網(wǎng)絡(luò)的權(quán)重,但是Adam 在訓(xùn)練的初期,因?yàn)槿鄙贁?shù)據(jù)導(dǎo)致方差大,學(xué)習(xí)率的方差較大,但可以控制自適應(yīng)率的方差來改變效果。SGD[9]優(yōu)化器另一種常用的優(yōu)化器,它能夠自動(dòng)逃離鞍點(diǎn)和比較差的局部最優(yōu)點(diǎn),但是速度相對(duì)要慢。
因此,在選擇優(yōu)化器中,一個(gè)較好的優(yōu)化器是能夠在收斂速度和收斂效果都比較好的。SGD 優(yōu)化器收斂較好,但是慢;Adam 優(yōu)化器收斂較快,但容易收斂到局部解。
RAdam(Rectified Adam)[10]優(yōu)化器能夠在收斂速度和收斂效果都表現(xiàn)的比較好。RAdam 優(yōu)化器是Liyuan Liu、HaomingJiang 和PengchengHe 等人提出一種新的優(yōu)化器,它是經(jīng)典Adam 優(yōu)化器的一個(gè)新變種,在自動(dòng)的、動(dòng)態(tài)的調(diào)整自適應(yīng)學(xué)習(xí)率的基礎(chǔ)上進(jìn)行了進(jìn)一步改進(jìn),構(gòu)建了一個(gè)整流器項(xiàng),允許自適應(yīng)動(dòng)量作為一個(gè)潛在的方差的函數(shù)緩慢但穩(wěn)定地得到充分表達(dá)。在某些情況下,由于衰減速率和潛在方差的驅(qū)動(dòng),RAdam退化為具有等效動(dòng)量的SGD。故,RAdam 根據(jù)方差的潛在散度動(dòng)態(tài)地打開或關(guān)閉自適應(yīng)學(xué)習(xí)率,彌補(bǔ)了Adam的缺點(diǎn)。故,選用RAdam 優(yōu)化器。
3.3 生成器和鑒別器架構(gòu)
Improved GAN + Manifold Reg + LMM 模型生成器架構(gòu)如表1 所示。
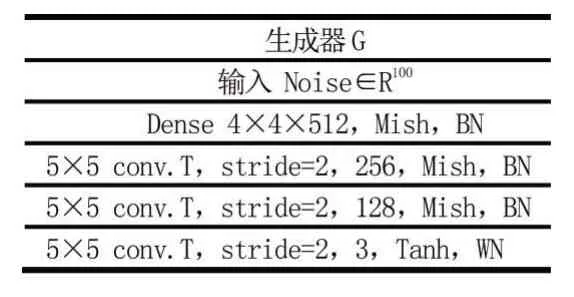
表1 生成器架構(gòu)
從表1 展示出,生成器是一個(gè)帶有批處理歸一化的4 層深度卷積神經(jīng)網(wǎng)絡(luò),前3 層網(wǎng)絡(luò)都使用Mish 激活函數(shù),第4 層使用Tanh 激活函數(shù)。Tanh 函數(shù)是0均值,更加有利于提高訓(xùn)練效率,在特征相差明顯時(shí)的效果會(huì)很好,在循環(huán)過程中會(huì)不斷擴(kuò)大特征效果,在CIFAR-10 實(shí)驗(yàn)和Svhn 實(shí)驗(yàn)中,以不同的方式初始化鑒別器WN(WeightNorm)層的權(quán)值,故在實(shí)驗(yàn)中分別展示鑒別器的架構(gòu)。
4 實(shí)驗(yàn)
4.1 實(shí)驗(yàn)
實(shí)驗(yàn)部分檢驗(yàn)Improved GAN + Manifold Reg +LMM 模型對(duì)圖像分類的能力,為了展示Improved GAN+Manifold Reg+LMM 模型對(duì)復(fù)雜數(shù)據(jù)都有較好的學(xué)習(xí)能力,實(shí)驗(yàn)在CIFAR-10 數(shù)據(jù)庫和SVHN 數(shù)據(jù)庫兩個(gè)數(shù)據(jù)庫上進(jìn)行測(cè)試。RAdam 優(yōu)化器初始學(xué)習(xí)率
設(shè)為3*10-4,正則化權(quán)值λ設(shè)為10-3,?設(shè)為10-5。模型中同樣使用WN、BN(BatchNorm)以及dropout 策略。實(shí)驗(yàn)在TensorFlow 深度學(xué)習(xí)框架實(shí)現(xiàn)的,在單塊GPU型號(hào)為Tesla P40 上運(yùn)行。
4.2 CIFAR-10實(shí)驗(yàn)
CIFAR-10 數(shù)據(jù)集較為復(fù)雜,數(shù)據(jù)集中的圖像均為自然圖像,圖像中存在很多細(xì)節(jié),而且同一種類別的不同的圖像之間也有較大的差異,所以該數(shù)據(jù)集對(duì)分類模型的魯棒性要求較高。CIFAR-10 數(shù)據(jù)集包含10 類彩色圖像,圖像大小為32×32,數(shù)據(jù)集有50000 個(gè)訓(xùn)練樣本,10000 個(gè)測(cè)試樣本。
鑒別器架構(gòu)如表2。

表2 鑒別器架構(gòu)
從表2 可以看出,鑒別器使用了帶有dropout 的9層深度卷積網(wǎng)絡(luò)和權(quán)值歸一化,而9 層深度卷積網(wǎng)絡(luò)都是用的LeakyMish 激活函數(shù)。在9 層深度卷積網(wǎng)絡(luò)中有3 個(gè)dropout,取值分別為0.2、0.5 和0.5,提高了模型的泛化能力。初始化鑒別器WN 層的權(quán)值為96。
在實(shí)驗(yàn)中,Epoch 設(shè)為1300,Batch size 設(shè)為50。
CIFAR-10 實(shí)驗(yàn)中鑒別器的損失變化如圖7 所示。
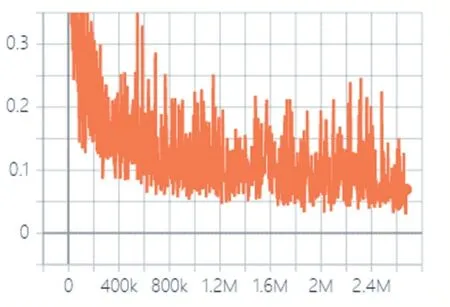
圖7 CIFAR-10實(shí)驗(yàn)中鑒別器的損失變化
從圖7 可以看出,鑒別器的損失值也是由開始的快速下降到逐漸平穩(wěn),說明鑒別器在訓(xùn)練時(shí)可以快速收斂并趨向穩(wěn)定,鑒別器的鑒別能力在開始快速提高,然后逐漸平穩(wěn)。
CIFAR-10 實(shí)驗(yàn)中測(cè)試集的準(zhǔn)確率如圖8 所示。
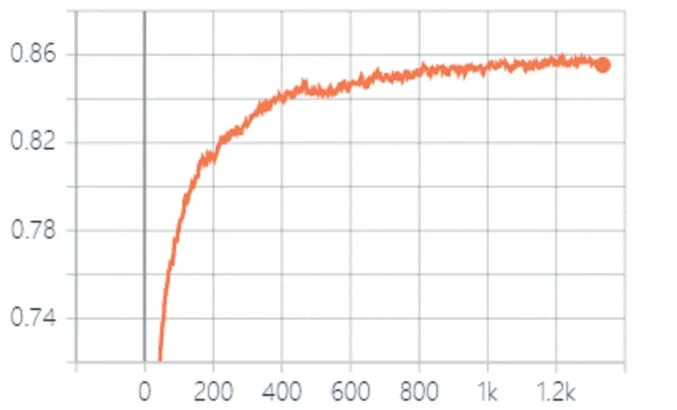
圖8 CIFAR-10實(shí)驗(yàn)中測(cè)試集的準(zhǔn)確率
從圖8 可以看出,CIFAR-10 實(shí)驗(yàn)中測(cè)試集的準(zhǔn)確率先是快速上升,然后逐漸減緩,也反映出了Improved GAN+Manifold Reg+LMM 模型收斂較快。
將Improved GAN+Manifold Reg+LMM 模型與一些知名的、準(zhǔn)確率高的算法在CIFAR-10 數(shù)據(jù)庫進(jìn)行對(duì) 比,如Improved semi-GAN[13]、Improved GAN[14]等。CIFAR-10 上各種方法準(zhǔn)確率對(duì)比如表3 所示。
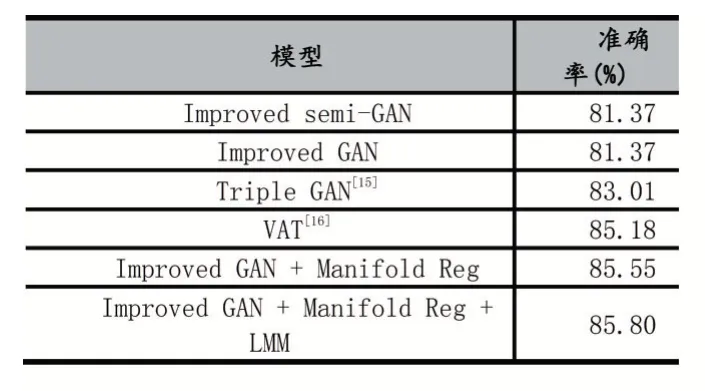
表3 CIFAR-10 上各種方法準(zhǔn)確率對(duì)比
從表3 可以看出,Improved GAN + Manifold Reg +LMM 模型在CIFAR-10 數(shù)據(jù)集中取得了較好的結(jié)果,準(zhǔn)確率為85.75%,相比Improved GAN + Manifold Reg模型提高了0.25%。
4.3 SVHN實(shí)驗(yàn)
SVHN 數(shù)據(jù)庫是彩色街牌號(hào)圖像數(shù)據(jù)庫,每張圖像上都有一個(gè)或多個(gè)數(shù)字,但圖像的類別以正中間的數(shù)字為基準(zhǔn)。SVHN 數(shù)據(jù)庫的圖像大小為32×32,共有73257 個(gè)訓(xùn)練樣本,26032 個(gè)測(cè)試樣本。
鑒別器架構(gòu)如表4。

表4 鑒別器架構(gòu)
從表4 可以看出,鑒別器同樣使用了帶有dropout的9 層深度卷積網(wǎng)絡(luò)和權(quán)值歸一化,9 層深度卷積網(wǎng)絡(luò)都是用的LeakyMish 激活函數(shù)。在9 層深度卷積網(wǎng)絡(luò)中有3 個(gè)dropout,取值分別為0.2、0.5 和0.5,從而提高了模型的泛化能力。與CIFAR-10 實(shí)驗(yàn)不同的是初始化鑒別器WN 層的權(quán)值為64。
在實(shí)驗(yàn)中,Epoch 設(shè)為1300,Batch size 設(shè)為50。
SVHN 實(shí)驗(yàn)中鑒別器的損失變化如圖9 所示。

圖9 SVHN實(shí)驗(yàn)中鑒別器的損失變化
從圖7 可以看出,鑒別器的損失值是由開始的快速下降到逐漸平穩(wěn),同理,說明了鑒別器的鑒別能力在開始快速提高,然后逐漸平穩(wěn)。
SVHN 實(shí)驗(yàn)中測(cè)試集的準(zhǔn)確率如圖10 所示。
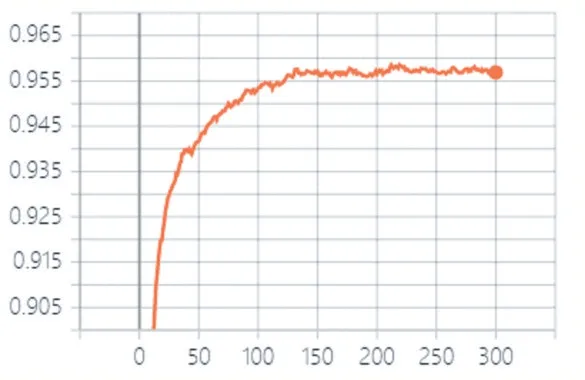
圖10 SVHN實(shí)驗(yàn)中測(cè)試集的準(zhǔn)確率
從圖10 可以看出,SVHN 實(shí)驗(yàn)中測(cè)試集的準(zhǔn)確率先是快速上升,然后逐漸減緩,也反映出了Improved GAN+Manifold Reg+LMM 模型收斂較快。
將Improved GAN+Manifold Reg+LMM 模型與一些知名的、準(zhǔn)確率高且是在半監(jiān)督領(lǐng)域先進(jìn)的算法在SVHN 數(shù)據(jù)庫進(jìn)行對(duì)比,如VAT、Improved GAN 等。
SVHN 實(shí)驗(yàn)中多種方法準(zhǔn)確率對(duì)比如表5 所示。

表5 Svhn 實(shí)驗(yàn)中多種方法準(zhǔn)確率對(duì)比
從表5 中,可以看出,流形正則化半監(jiān)督生成對(duì)抗網(wǎng)絡(luò)在SVHN 數(shù)據(jù)集中取得了較好的結(jié)果,測(cè)試集準(zhǔn)確率為95.74%,相比之前,提高了0.29%,準(zhǔn)確率也比Improved semi-GAN 模型略高。
4.4 實(shí)驗(yàn)分析
從圖7 和圖9 可以得出,Improved GAN+Manifold Reg+LMM 模型收斂較快;鑒別器損失值較低,鑒別器鑒別能力較高。從圖8 和圖10 可以得出,測(cè)試集的準(zhǔn)確率開始上升然后逐漸平穩(wěn),收斂較好。從表3 和表5可以得出,在多個(gè)算法對(duì)比中,Improved GAN + Manifold Reg+LMM 模型的準(zhǔn)確率較高,效果較好。
5 結(jié)語
本文主要針對(duì)提高圖像分類準(zhǔn)確率進(jìn)行了研究,提出了Improved GAN + Manifold Reg + LMM 模型,Improved GAN+Manifold Reg+LMM 模型是一種半監(jiān)督生成對(duì)抗網(wǎng)絡(luò)模型,并在CIFAR-10 實(shí)驗(yàn)和SVHN實(shí)驗(yàn)中取得較好的實(shí)驗(yàn)結(jié)果,在和Improved GAN、Triple GAN、Improved semi-GAN 和VAT 等經(jīng)典算法對(duì)比中,Improved GAN+Manifold Reg+LMM 模型的準(zhǔn)確率較高,在訓(xùn)練時(shí)模型也收斂速度較快。Improved GAN+ Manifold Reg 算法在半監(jiān)督生成對(duì)抗網(wǎng)絡(luò)中屬于先進(jìn)的算法,故在此基礎(chǔ)上改進(jìn)是可行的。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
人大建設(shè)(2020年4期)2020-09-21 03:39:12
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
人大建設(shè)(2017年2期)2017-07-21 10:59:25
人大建設(shè)(2017年9期)2017-02-03 02:53:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
