基于注意力機制的Bi-LSTM 結合CRF的新聞命名實體識別及其情感分類
2020-08-06 08:28:06胡甜甜但雅波李少波
計算機應用 2020年7期
胡甜甜,但雅波,胡 杰,李 想,李少波
(1.貴州大學計算機科學與技術學院,貴陽 550025;2.貴州大學機械工程學院,貴陽 550025;3.貴州財經大學大數據統計學院,貴陽 550025)
(*通信作者電子郵箱2506062823@qq.com)
0 引言
21 世紀是一個數據爆炸式增長的時代,也是各種媒體應運而生的時代。新聞、教育、醫療等不同領域每時每刻都在產生大量的文本數據,往往這些數據中蘊藏著大量有價值的信息,對社會性的研究有著非常重要的意義[1]。面對這些海量文本數據,如何準確高效地進行信息抽取和數據挖掘成為學術界和工業界關注的熱點問題,作為其中主要技術的命名實體識別(Named Entity Recognition,NER)技術受到研究者們的高度重視。NER 是指從文本中識別出命名性指稱項,為關系抽取等任務做鋪墊,是構建知識圖譜的最初步驟[2]。狹義上,NER 是識別出人命、地名和組織機構名這三類命名實體(時間、貨幣名稱等構成規律明顯的實體類型可以用正則表達式等方式識別)。NER 方法主要用三種:基于規則的方法、基于特征模板的方法、基于神經網絡的方法。基于規則的方法常用的是利用手工編寫的規則,將文本與規則進行匹配來識別出命名實體[3]。例如,對于中文來說,“說”“老師”等詞語可作為人名的下文,“大學”“醫院”等詞語可作為組織機構名的結尾,還可以利用到詞性、句法信息。在構建規則的過程中往往需要大量的語言學知識,不同語言的識別規則不盡相同,而且需要謹慎處理規則之間的沖突問題;此外,構建規則的過程費時費力、可移植性不好。基于特征模板的方法利用大規模語料來學習出標注模型,從而對句子的各個位置進行標注,通常與條件隨機場(Conditional Random Field,CRF)[4]結合使用。特征模板通常是人工定義的一些二值特征函數,試圖挖掘命名實體內部以及上下文的構成特點。對于句子中的給定位置來說,提取特征的方式是采用一個特征模板在該位置上進行數學運算。而且,不同的特征模板(窗口)之間可以進行組合來形成一個新的特征模板。CRF的優點在于其為一個位置進行標注的過程中可以利用到此前已經標注的信息,利用Viterbi 解碼來得到最優序列[5]。對句子中的各個位置提取特征時,滿足條件的特征取值為1,不滿足條件的特征取值為0;然后,把特征喂給CRF,訓練階段建模標簽的轉移,進而在預測階段為測試句子的各個位置做標注。近年來,人工智能(Artificial Intelligence,AI)取得了突破性的進展。其中,機器學習(Machine Learning,ML)和深度學習(Deep Learning,DL)技術的應用為人類在各個領域的任務帶來了優異表現,包括圖像識別[6]、語音識別[7]和自然語言處理(Natural Language Processing,NLP)[8]。神經網絡方法使得模型的訓練成為一個端到端的整體過程,而非傳統的Pipeline,不依賴特征工程,是一種數據驅動的方法。
研究者們用神經網絡在自然語言處理方面做了大量研究:Huang 等[9]提出將多種神經網絡模型應用到自然語言處理中的序列標注問題上,并證明雙向長短期記憶神經網絡結合條件隨機場(Bi-directional Long Short-Term Memory neural network and Conditional Random Field,Bi-LSTM-CRF)模型在序列標注上能取得很好的結果,在CoNLL corpus 語料庫上進行命名實體識別時,F1 值達到了90.10%。Ma 等[10]將長短期記憶神經網絡(Long Short-Term Memory neural network,LSTM)、卷積神經網絡(Convolutional Neural Network,CNN)、CRF 結合構建出Bi-LSTM-CNNs-CRF 模型,并應用在命名實體識別任務上,在CoNLL 2003 corpus 語料庫取得F1 得分為0.912 1的成績。Luo等[11]提出了一個自我注意力的雙向長短期記憶網絡(Self-Attentive Bi-LSTM)來預測情緒挑戰中的多種情緒,Self-Attentive Bi-LSTM 模型能夠捕獲文本之間的上下文依賴關系,有助于對模糊情緒進行分類,它在Friends 和EmotionPush 測試集中分別獲得了59.6 和55.0 的未加權準確性分數。雖然這些方法在NLP 的NER 任務和情感分析方面取得了顯著的效果,但這些方法都是將實體識別與情感分析分別建立預測模型,沒有挖掘這兩個任務之間的聯系。
針對上述問題,本文提出了一種基于注意力機制的雙向長短期記憶神經網絡結合條件隨機場(Attention-based Bidirectional Long Short-Term Memory neural network and Conditional Random Field,AttBi-LSTM-CRF)的深度神經模型來同時完成對新聞中核心實體的提取和核心實體的情感分類,并與雙向長短期記憶神經網絡(Bi-directional Long Short-Term Memory,Bi-LSTM)、帶注意力機制的雙向長短期記憶神經網絡(Attention-based Bi-directional Long Short-Term Memory neural network,AttBi-LSTM)、Bi-LSTM-CRF 等算法進行了比較。實驗結果表明,本文采用的AttBi-LSTM-CRF 在同時識別核心實體及分類其情感時取得了最好的結果,準確率為0.786,召回率為0.756,F1值為0.771。
1 數據預處理與數據標定
1.1 數據來源
本文模型實驗數據集來源于2019 搜狐校園算法大賽中的比賽數據(https://biendata.com/competition/sohu2019/data/),其中包含4 萬條訓練數據(帶標簽)和4 萬條測試數據(不帶標簽)。該數據集文本主要由中文構成,偶爾會出現幾個英文單詞,每條數據包含一篇不限定主題的新聞標題和新聞主體內容,訓練數據同時會給出新聞主題內容對應的1到3個的核心實體以及這些核心實體相對應的情感標簽。該數據集來自于搜狐新聞文本,包括娛樂、情感、體育、旅游、時政、時尚、財經等各種常見新聞題材,涵蓋內容廣泛,種類豐富,語法規范,數據中的核心實體標注和情感分析都由人工標注。
1.2 數據預訓練
本文選取北京師范大學中文信息處理研究所與中國人民大學DBIIR 實驗開源的中文詞向量語料庫Chinese Word Vectors(https://github.com/Embedding/Chinese-Word-Vectors)中的搜狐新聞(Sogou News)(http://www.sogou.com/labs/resource/cs.php)中文預訓練詞向量包對每個句子進行預訓練,將每個字映射成300 維度的向量。搜狐中文預訓練詞向量包是通過對大量搜狐新聞文章用ngram2vec 工具包訓練得到。由于本文的數據來自于搜狐新聞文本和搜狐新聞文章在各個方面都有非常大的相似度,因此選用搜狐新聞中文預訓練詞向量包對數據進行預訓練會比較適合。最后,每個句子將會用矩陣Tn×d表 示,d表示詞向量的維度(300),n=[Max_length×0.8],[·]表示取數值的整數部分,Max_length表示語料庫中最大句子長度。對于句子長度小于Max_length的用0填充。
1.3 數據標注
在本文實驗中,模型訓練集的標簽是給每個字向量標注上對應類別標號,標注標簽一共有10 類,分別是:①Null,②B_pos,③I_pos,④E_pos,⑤B_neg,⑥I_neg,⑦E_neg,⑧B_norm,⑨I_norm,⑩E_norm。其中:空標簽(Null)表示非核心實體;B 表示核心實體詞的第一個字;I 表示核心實體詞中間的字;E 表示核心實體詞的最后一個字;pos 表示積極的情感;neg 表示消極的情感;norm 表示中立的情感。例如,B_pos 標簽表示的是積極情感的核心實體的第一個字。標注實例如表1所示。
2 模型構建
2.1 AttBi-LSTM
AttBi-LSTM 模型將Attention 機制[12]融合到Bi-LSTM[13]中。深度學習中,Attention 機制可以理解為將注意力放在更重要的信息上,它與Bi-LSTM 融合的基本思想是:打破了傳統Bi-LSTM 結構在編解碼時都依賴于內部一個固定長度向量的限制。AttBi-LSTM 機制的實現是通過保留Bi-LSTM 編碼器對輸入序列的中間輸出結果,然后訓練一個模型來對這些輸入進行選擇性的學習,并且在模型輸出時將輸出序列與之進行關聯。圖1為AttBi-LSTM的模型框架。
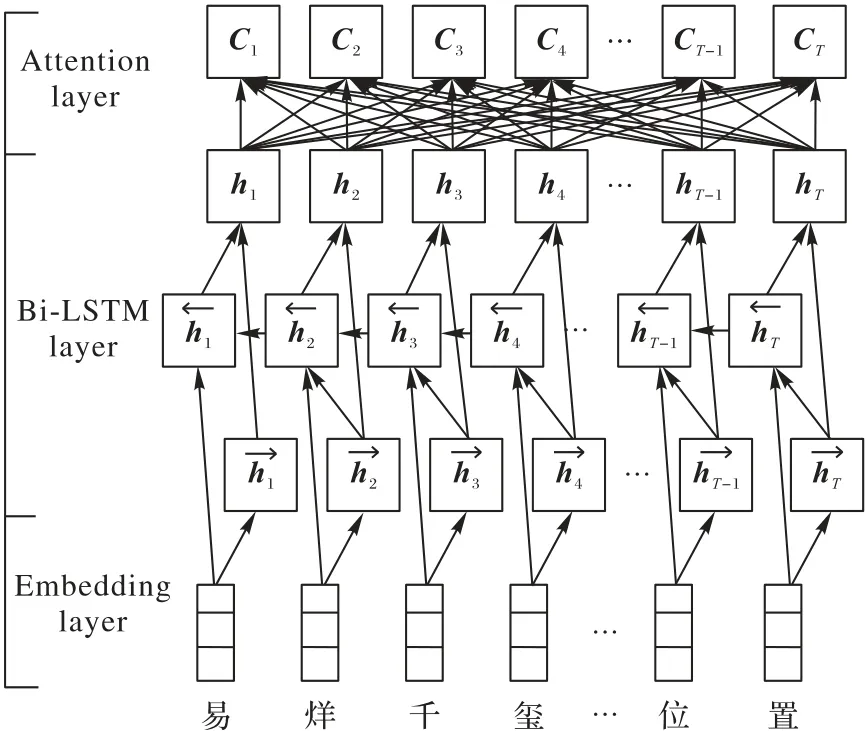
圖1 AttBi-LSTM模型框架Fig.1 AttBi-LSTM model framework
對于時間序列標記任務來說,每一個時刻的歷史信息和未來信息的特征對于當前實體標簽的預測都很重要,然而標準的LSTM 并不能捕獲未來信息的特征。Bi-LSTM 模型將前向的LSTM 和后向的LSTM 結合,具有能夠捕獲前后信息特征的作用,因此,本文采用了Bi-LSTM 模型,其輸出可以表示為。Bi-LSTM 層輸入的向量結合表示為H:[h1,h2,…,hT]。Attention 層權重矩陣由M=tanh(H)、α=softmax(WTM)、γ=HαT的方式得到。其中,H∈Rdw·WT,dw為詞向量的維度,WT是一個訓練學習得到的參數向量的轉置,最后AttBi-LSTM的輸出為h*=tanh(r)。
2.2 CRF
AttBi-LSTM 模型最終的輸出是相互獨立的,AttBi-LSTM學習到了輸入中前后信息的特征,但是沒有利用輸出標簽的作用。CRF 也是一種序列建模算法,它綜合了隱馬爾可夫模型和最大熵模型的優點。它根據給定觀察序列推測對應的狀態序列,可以利用相鄰前后的標簽關系來獲取當前的最優的標記。因此,本文在AttBi-LSTM 的輸出層后疊加一層線性CRF來標注核心實體及其情感分析的類別。
定義矩陣Pn×m為AttBi-LSTM 層的輸出,n在1.2 節中已經進行了定義,m表示標簽類別的個數,Pij表示句中第i個字是第j個標簽的概率。定義狀態轉移矩陣A(m+2)×(m+2),其中,Aij表示在連續的一段時間內,第i個標簽轉移到第j個標簽的概率。對于預測序列y的概率可以表示為:,再通過softmax層計算出所有類別標簽的概率。
2.3 核心實體識別與情感分析框架
圖2為本文的AttBi-LSTM-CRF中文核心實體識別及其情感分析模型框架。AttBi-LSTM-CRF 框架共分為4 步:1)預訓練[14]部分,將待訓練的文本序列進行文本向量化,將其每個字轉換為對應的有特定意義的固定長度的向量。2)將處理好的詞向量序列輸入Bi-LSTM,提取文本雙向長距離依賴特征。3)通過Attention 機制,提取輸入和輸出之間的相關性進行重要度計算,根據重要度獲取文本整體特征。4)用線性CRF 層處理標簽之間的狀態關系,得到全局最優標注序列。
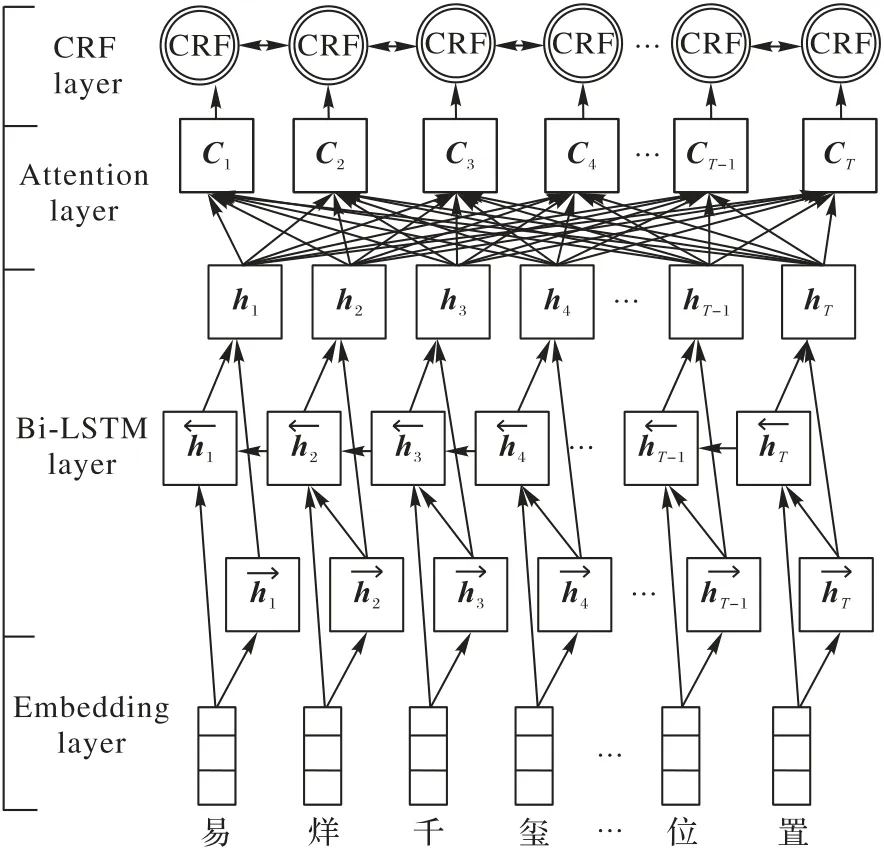
圖2 AttBi-LSTM-CRF模型框架Fig.2 AttBi-LSTM-CRF model framework
3 實驗與結果分析
3.1 實驗環境
本文的實驗環境為:操作系統Ubuntu 16.04,CUDA 8.0,cudnn 6;處理器4 個CPU 核心,1 顆Nvidia Tesla P100 共享GPU 核;內 存60 GB,顯 存16 GB;編譯平臺Pycharm Profession,Python 3.5,TensorFlow 1.5.1。
3.2 實驗參數設置
本文采用網格搜索法(grid search)進行主要參數調節,獲取模型的最優參數集合,模型參數取值及其說明如表2 所示。其中,模型的部分超參數主要是來自于現有研究中的經驗,如學習速率、Dropout 比例;一些參數是由數據集的特性而設置,如最長序列長度取值范圍根據句子長度統計得到;一些參數根據模型訓練和硬件的條件配置,如每批數據量大小、LSTM 隱藏層單元數。

表2 AttBi-LSTM-CRF模型的超參數Tab.2 Hyperparameters of AttBi-LSTM-CRF model
3.3 實驗結果評估方法
訓練好的模型輸出結果是文本對應的標簽,連續的BIE標簽對應的詞表示一個核心實體,其中,可能一個核心實體會有幾種不同的情感標簽,這時候通過投票機制,即少數服從多數,得到這個核心實體的情感分析。
本文模型效果評估指標有準確率(Precision)、召回率(Recall)和F1 值(F1-score)[15]。每個指標都有實體詞的得分和實體情感的得分兩部分,計算每個樣本單獨的指標值,然后取所有樣本指標值的平均數作為最后的結果。情感分析的指標值由實體_情緒的組合標簽進行判斷,只有實體與情緒都正確才算正確的標簽。其中,兩條實例數據的預測結果如表3所示,對應的預測得分如表4所示。

表3 預測標注實例Tab.3 Predictive labeling examples
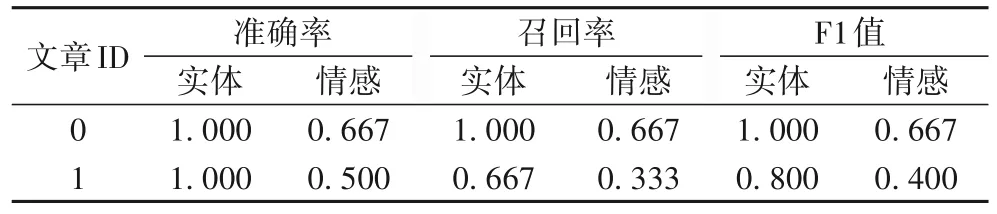
表4 預測得分Tab.4 Predictive scores
3.4 實驗對比分析
3.4.1 不同模型的性能對比
為了驗證AttBi-LSTM-CRF 模型中每個模塊的作用,本文選擇了Bi-LSTM、Bi-LSTM-CRF、AttBi-LSTM 這三種模型進行相同的實驗作為實驗對照。這些模型的參數與AttBi-LSTMCRF 模型使用的參數相同。為使實驗結果更加穩定可靠,每種模型都將重復實驗10次,并取10次實驗的平均值作為最終的結果,如表5所示。
由表5可知,與AttBi?LSTM 相比,Bi?LSTM的結果較差,原因是其沒有引入注意力機制,無法捕捉到核心實體之間的依賴關系。AttBi-LSTM 和Bi-LSTM-CRF 的結果相當,注意力機制的引入能有效解決長文本間的長期依賴關系,條件隨機場(CRF)通過求解最大概率得到最優序列,能很好地標注序列標簽。本文提出的AttBi-LSTM-CRF 模型在準確率、召回率、F1 值上取得了最好的結果。模型訓練時的F1 值變化和召回率變化如圖3~4 所示。由圖3 和圖4 可知,本文提出的AttBi-LSTM-CRF 模型的F1 值、召回率和收斂速度均取得了最好的結果
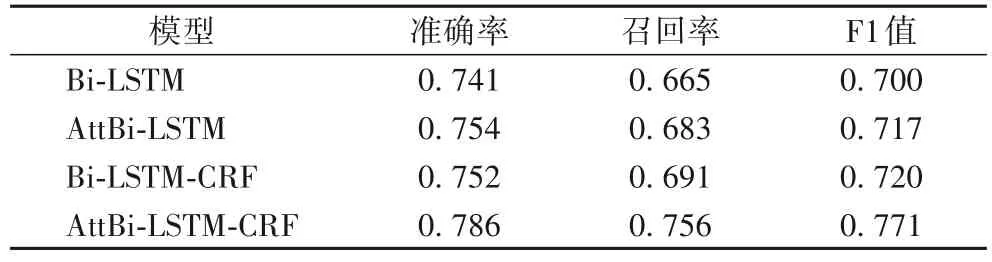
表5 不同模型的準確率、召回率和F1值對比Tab.5 Comparison of accuracy,recall rate and F1 value among different models

圖3 模型訓練時的F1值變化Fig.3 Change of F1 value during model training
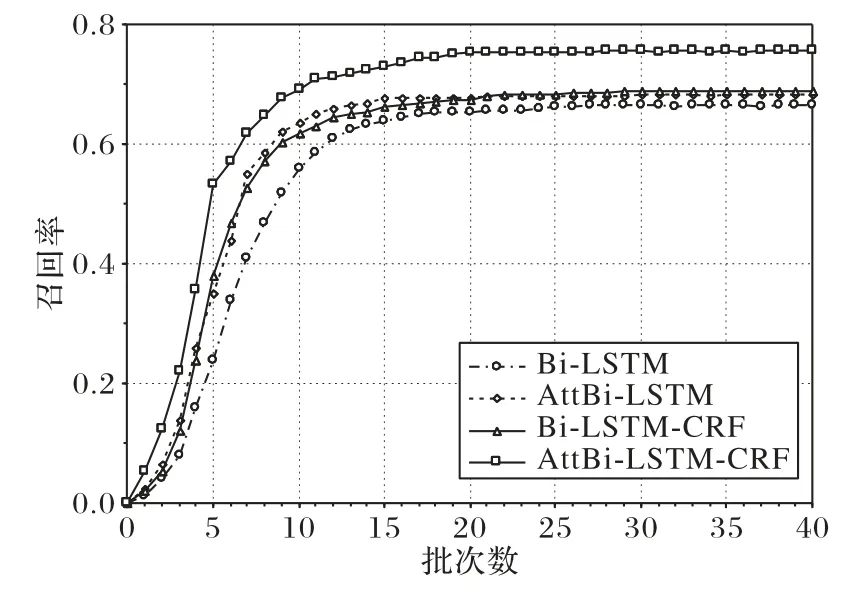
圖4 模型訓練時的召回率變化Fig.4 Change of recall rate during model training
3.4.2 Attention模塊
從表5中可以看出:AttBi-LSTM 模型的準確率為0.754,召回率為0.683,F1 值為0.717,相較Bi-LSTM 模型F1 值高出0.017,準確率和召回率也有相應的提升。比較Bi-LSTM 模型和AttBi-LSTM 模型的實驗數據可知,AttBi-LSTM 模型在coreEntityEmotion_train 語料的核心實體識別及其情感分析任務上的表現更好。這是由于采用的Bi-LSTM 模型存在一個問題:不論輸入長短都將其編碼成一個固定長度的向量表示,這使模型對于長輸入序列的學習效果很差。而Attention 機制則克服了上述缺陷,原理是Attention 模塊能高效地分配有限的注意力資源,有選擇性地將注意力投放到高價值的信息上,在模型輸出時會選擇性地專注考慮輸入中對應高度相關的信息。獲取的信息價值越高,實驗的結果越好。
3.4.3 線性CRF模塊
表5 給出了Bi-LSTM 模型和Bi-LSTM-CRF 模型的實驗結果對比。Bi-LSTM-CRF 模型的實驗結果數據是準確率為0.752,召回率為0.691,F1 值為0.720,相較Bi-LSTM 模型F1值高出0.020,準確率和召回率也有相應的提升,表明線性CRF模塊可以獲得更好的效果。線性CRF是一種序列標注模型,它和LSTM 等分類器標注模型不同,它考慮的不是長遠的上下文信息,它是計算某個序列中的最優聯合概率,優化整個序列(最終目標)。
3.4.4 AttBi-LSTM-CRF模型
通過實驗結果數據對比可以看到,本文使用的AttBi-LSTM-CRF 模型相較于傳統的Bi-LSTM,核心實體的識別及其情感分類的準確性有了大幅度的提升,相較于在Bi-LSTM 基礎上只增加Attention 或者線性CRF 任意一種模塊的模型,也有更優的結果。
4 結語
針對搜狐coreEntityEmotion_train 語料核心實體識別和核心實體情感分析的任務,本文提出了AttBi-LSTM-CRF 模型。Bi-LSTM 網絡可以獲取長遠的上下文信息對文本標注產生影響,加入Attention 模塊可以從輸入中獲取與輸出的標注有關的重要信息,在AttBi-LSTM 層后加上線性CRF 層獲取整個序列最優標注。在搜狐coreEntityEmotion_train 語料上進行的對比實驗結果表明,本文使用的AttBi-LSTM-CRF 模型在核心實體識別和核心實體的情感分析任務上取得了較高的準確值、召回率和F1 值,相較Bi-LSTM、AttBi-LSTM、Bi-LSTM-CRF 三種模型有一定的優越性。最近Devlin 等[16]提出了基于BERT的神經語音模型,該模型在上10 種自然語言任務中都取得了最好的結果,因此,可以使用本文的數據對BERT 進行遷移訓練后改變輸出層的網絡結構進行核心實體的識別與情感分類。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
